MySQL���IJ���
��������
�:
insert into (�ֶ�1,�ֶ�2��)values(ֵ1,ֵ2��);
�������� + ȫ�в���
��:����һ��ѧ����,Ȼ����в�������:
�C ����һ��ѧ����
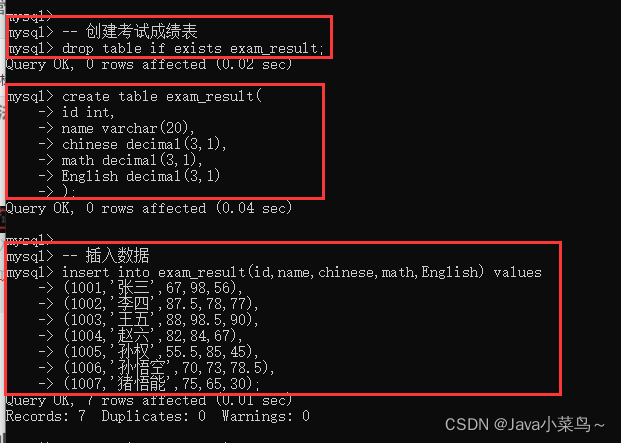
drop table if exists student ;
create table student (
id int,
sn int comment ��ѧ�š�,
name varchar(20) comment ��������,
qq_mail varchar(20) comment ��qq���䡯
);
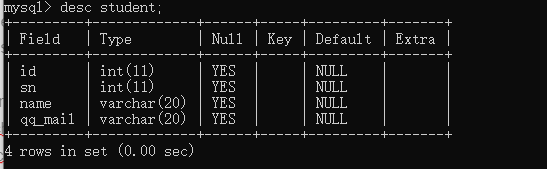
������������:
-
id :1,ѧ��:1001 ,����:����,����:123qq.com;

-
id :2,ѧ��:1002 ,����:����,����:456qq.com;

�������� + ָ���в���
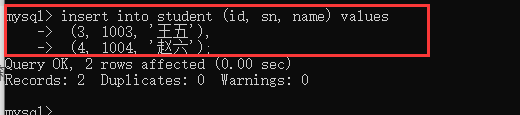
��ѯ����
�:
SELECT
[DISTINCT] {* | {column [, column] ��}
[FROM table_name]
[WHERE ��]
[ORDER BY column [ASC | DESC], ��]
LIMIT ��
ע:
[]:��ʾ��ѡ��,����дҲ���Բ�д;
��д��ʾ�ؼ���;
SELECT:��ѯ�ؼ���;
DISTINCT:ȥ�عؼ���;
FROM table_name:�����ű���ѯ;
WHERE:��������;
ORDER BY:����ָ�����ֶ�(�����ж��)������,ASC��ʾ����,DESC��ʾ����,Ĭ��Ϊ����;
LIMIT:��ҳ;
����:
1.����һ�ſ��Գɼ���;2.��������;3.���в�ѯ����;
����ʱ�������������Ĵ�����ʾ,��Ҫ��,(
ԭ��:�������ݿ�ʱ,û��ָ���ַ����뼯utf8mb4;
����취:ɾ�����ݿ�,������utf8mb4�ķ�ʽ����;
������Ϣ:

����취:
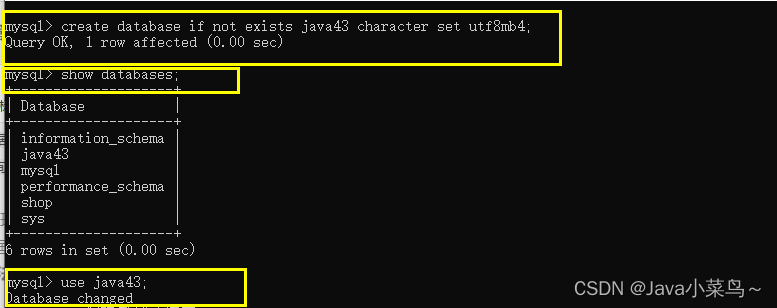
�����ɹ���:
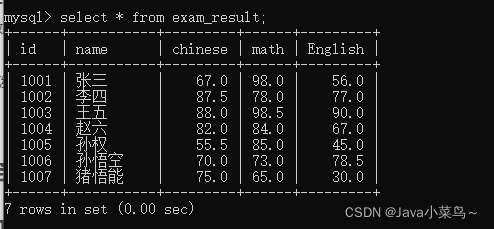
ȫ�в�ѯ
�:
select * from ����;
ע��:һ�㲻����ʹ��*����ȫ�в�ѯ,��ѯ��Խ��,�������������Խ��;
ȫ�в�ѯ�������:
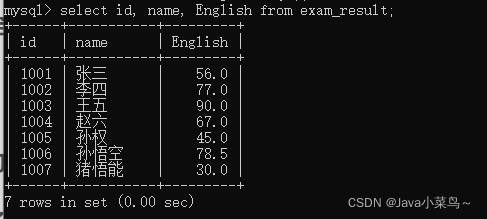
ָ���в�ѯ
�:
select id, name, English from ����;
ָ���в�ѯ�������:
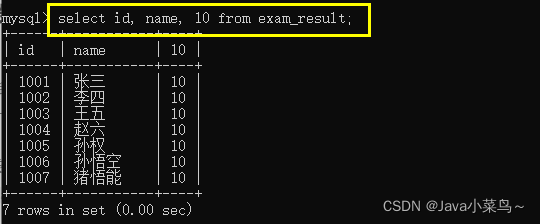
��ѯ�ֶ�Ϊ����ʽ
- ����ʽ�������ֶ�:
select id, name, 10 from ����;
�������:
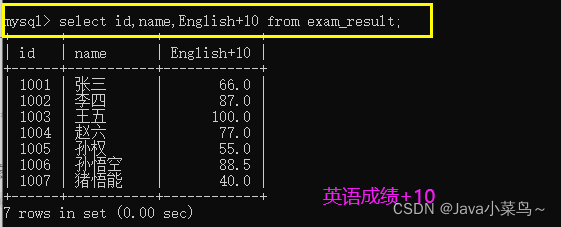
- ����ʽ����һ���ֶ�:
select id,name,English+10 from ����;
�������:
- ����ʽ��������ֶ�:
select id,name,English+math+Chinese from ����;
�������:
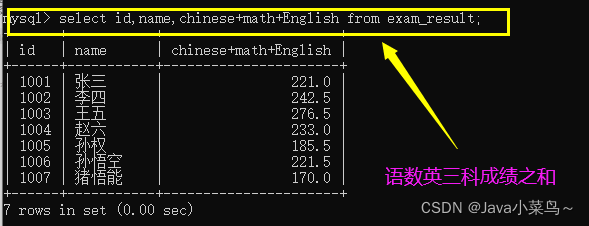
����
����:����Ϊ��ѯ����е���ָ��һ������,��ʾ���صĽ������,�Ըñ�����Ϊ���е�����;
�:
select �ֶ� as ���� from ����;
�������:

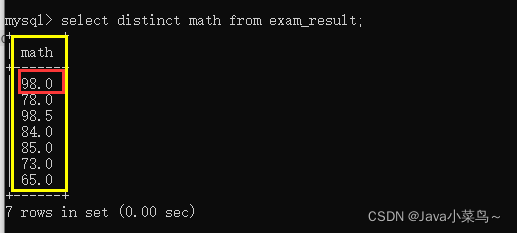
ȥ��:DISTINCT
ʹ��DISTINCT�ؼ��ֶ�ij�����ݽ���ȥ��;
�������:
(1)������û���ظ�������,�Ȳ���һ������,���Կ�����ѧ�оͳ����ظ�����98��;
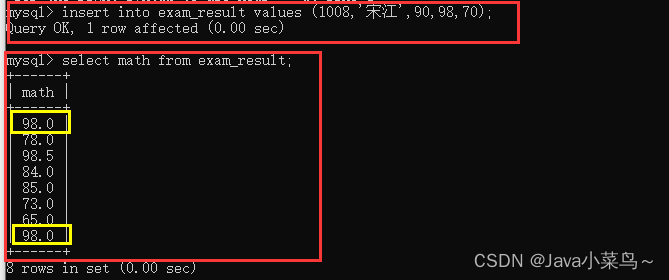
(2)ʹ�� distinct ����ȥ�ش���;
�������:
����:ORDER BY
�����:
select... from ����[where ...]
order by column [asc|desc], [...];
asc:Ĭ��Ϊ����;desc:��������
�������: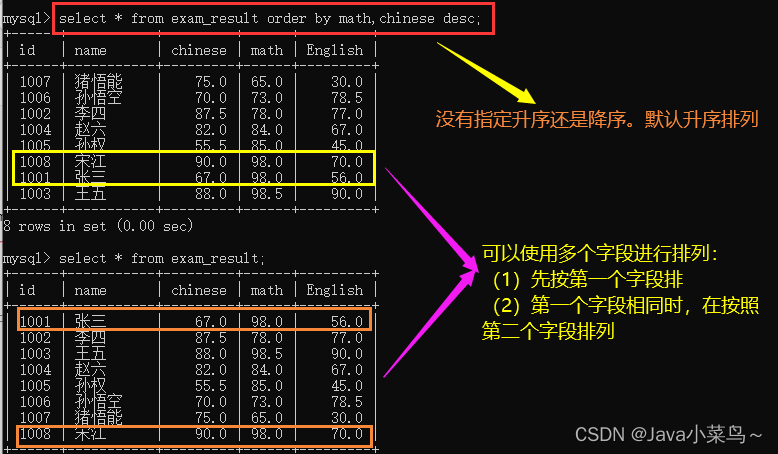
- ����ֶ�ֵΪ��,���ݸ��ֶ�����ʱ,��������ǰ,���������;
- ����ʹ�ñ���ʽ�������������;

�������˲�ѯ:WHERE
- �Ƚ������
| ����� | ˵�� |
|---|---|
| > >= < <= | ����,���ڵ���,С��,С�ڵ��� |
| == | ����,NULL ����ȫ,���� NULL = NULL �Ľ���� NULL |
| <=> | ����,NULL ��ȫ,���� NULL <=> NULL �Ľ���� TRUE(1) |
| !=,<> | ������ |
between A and B | ��Χƥ�� [A,B],������������ TRUE(1) |
in(option) | ����� option �е�����һ��,���� TRUE(1) |
| is null | �ǿ� |
| is not null | ���ǿ� |
like | ģ��ƥ��,% ��ʾ������(���� 0 ��)�����ַ�;_ ��ʾ����һ���ַ� |
- �������
| ����� | ˵�� |
|---|---|
and | ����������붼Ϊ TRUE(1),������� TRUE(1) |
or | ����һ������Ϊ TRUE(1), ���Ϊ TRUE(1) |
not | ����Ϊ TRUE(1),���Ϊ FALSE(0) |
ע:
(1)
WHERE��������ʹ�ñ���ʽ,������ʹ�ñ�����
(2)AND�����ȼ�����OR,��ͬʱʹ��ʱ,��Ҫʹ��С����()��������ִ�еIJ���
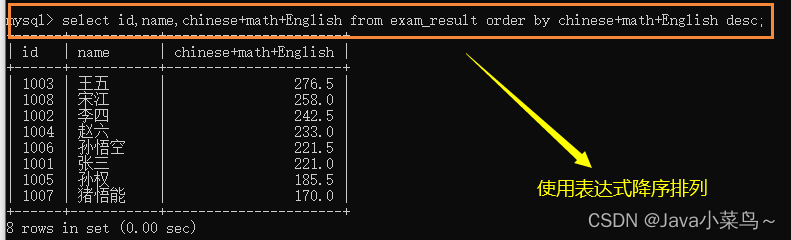
����ͼ��ʾ:
(1)��ѯӢ��ɼ�С��60��;
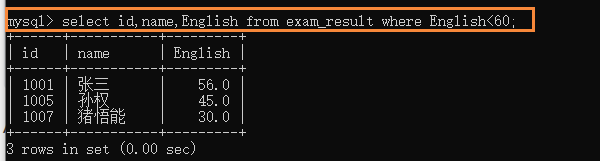
(2)��ѯ���ijɼ�����80����Ӣ��ɼ�����80�ֵ�ͬѧ;
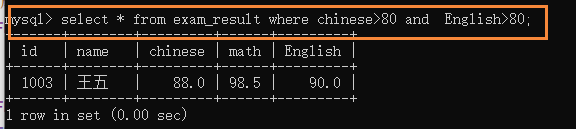
(3)��ѯ���ijɼ�����80 ��Ӣ��ɼ�����80
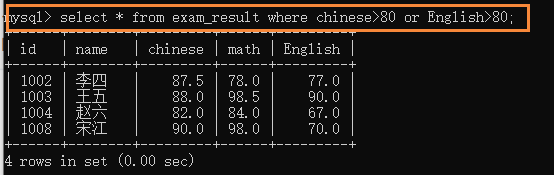
(3)or �� and �����ȼ�����;

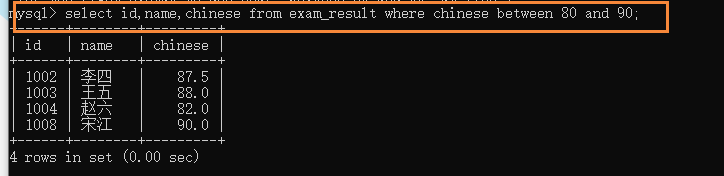
(4)��Χ��ѯ(between and): ��ѯ���ijɼ���[80-90]��ͬѧ;
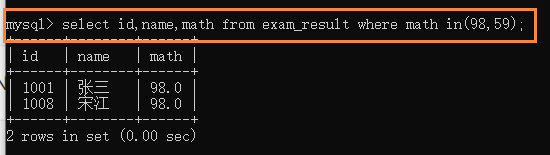
(5)in(option)��ѯ(����һ������,���᷵��)
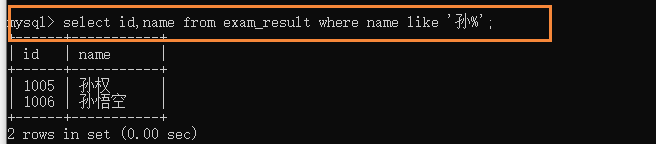
(6)ģ����ѯ:like
-
ƥ���������ַ�(����0��);
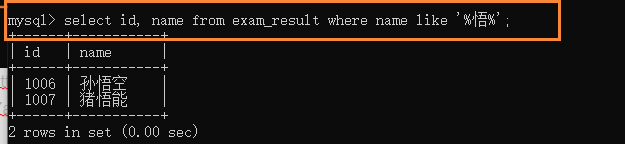
-
ƥ���ϸ��һ�������ַ�;
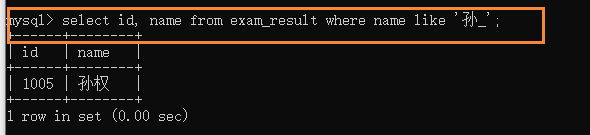
��ҳ��ѯ:LIMIT
�:
limit n;��0(����)��ʼ,ȡn������
limit s,n;��s(����)��ʼ,ȡn������
����:ȡӢ��ڶ�����ͬѧ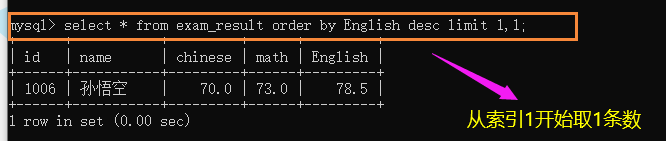
ȡ�ڶ����͵�������ͬѧ:

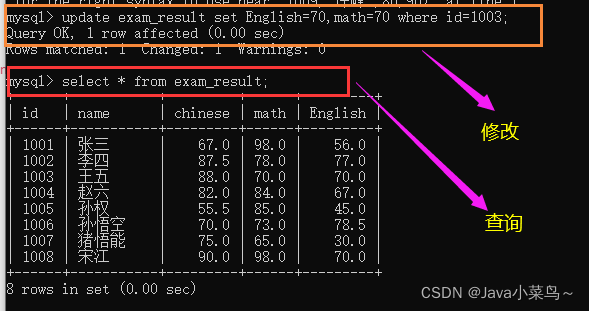
������(Update)
�:
UPDATE ���� SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
��id=1003��ͬѧ,��ѧ��Ӣ��ɼ���Ϊ70;
�������:
ע��:
(1)�ĺ�ɾ������һ��Ҫ����,
������ת��Ϊ��ѯ���,���Ƿ�����Ҫ�Ľ��,Ȼ���ڲ���!!!
(2)���û�и�where��������,update����������ȫ����!
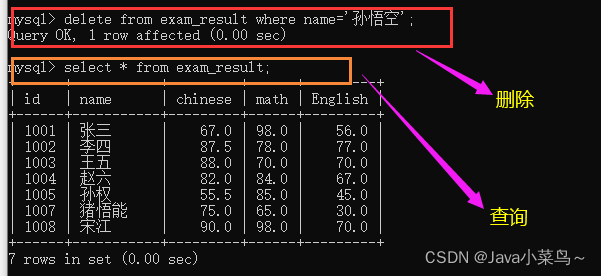
ɾ������(Delete)
�:
DELETE FROM ���� [WHERE ...] [ORDER BY ...] [LIMIT ...]
����:ɾ�������ͬѧ�Ŀ��Գɼ�;
ע��:
- ���IJ���һ��,������ת��Ϊ��ѯ���,����ɾ������;
- û�м�
where��������,ɾ��ȫ������;
�����ܽ�
- ����
�����:
insert into ��(�ֶ�1,�ֶ�2���ֶ�n) values (ֵ1,ֵ2��ֵn)
�����:
insert into ��(�ֶ�1, ��, �ֶ�N) values
(ֵ1, ��),
(ֵ2, ��),
(ֵ n);
- ��ѯ
--ȫ�в�ѯ
select * from ��;
--ָ���в�ѯ
select �ֶ�1,�ֶ�2�� from ��;
--����ʽ�ֶβ�ѯ
select �ֶ�1+100,�ֶ�2+�ֶ�3 from ��;
--������ѯ
select �ֶ�1 ����1, �ֶ�2 ����2 from ��;
--ȥ��distinct
select distinct �ֶ� from ��;
-- ����order by
select * from �� order by �����ֶ�;
-- ������ѯwhere
select * from �� where ����;
- ��
update �� set �ֶ�1=value1, �ֶ�2=value2�� where ����;
- ɾ��
delete from �� where ����;