������ô��ļ�����,�������������������ڶ������º�ѧ��ʲô��?
��������˵__�����»���������

��������˵
��������������������ĸ���~
44ƪԭ������
���ں�
-
����������������������ܸ�С����Ǵ���ʲô����,��С�������ֱ�����ײ�������˼
-
��������ʵ�ʵ�Ӧ�ó����Ͱ�������,��ֻ��֪ʶ��ļ���
-
���������Ҫ��֪ʶ���ԭ����������,��С�������������dz��
1.��ƪ
Դ�빫�ںź�̨�ظ�1.13.2 sql batch lookup join��ȡ��
[

flink sql ֪������Ȼ(ʮ��):ά�� join �������Ż�֮·(��)��Դ��
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489814&idx=1&sn=085b93194dfd0feae5ac43ab6d3fb524&chksm=c15495eef6231cf8df60f1c0b1d2f7f277732090888f6b52ae02181a4f1fb688aad540fbccb6&scene=21#wechat_redirect)
����ϻ�,�Ͻ�˵���˲������������� flink sql �� lookup join �����ⲿά�����ڵ��������⡣
�ɴ˵�����һ���뷨,�� Redis ά��Ϊ��,Redis ֧�� pipeline ��������ģʽ,��� flink sql lookup join �ܲ��ܰ��� DataStream ��ʽһ��,����һ������ ,Ȼ��ʹ�� Redis pipeline ���������ⲿ�洢���������еĽ�������ܳ�Ϊ flink sql batch lookup join,���ھ��ǽ����������� flink Դ��Դ˹��ܵ�ʵ�֡�
�ϻ�����˵,������ֱ���ϱ��ĵ�Ŀ¼�ͽ���,С�������ȿ����ۿ����˽ⲩ�����������ܸ�С����Ǵ���ʲô����:
-
ֱ����һ��ʵս����:�������ع��û���־�������û�����(���䡢�Ա�)ά��Ϊ������ batch lookup join ���еĻ�������(��ô���ò���,��ôд sql,����Ч��զ��)��
-
batch lookup join:��Ҫ���� batch lookup join �Ĺ����Ǵ� flink transformation ����,ȷ��Ҫ batch lookup join �漰�Ķ��ĵط��Լ���ʵ��˼·��ԭ����Ҳ��̸����һЩ�Ķ�Դ����ʵ���Լ���Ҫ��һЩ���ܵ�˼·��
-
�ܽἰչ��:Ŀǰ�� batch lookup join ʵ����ʵ������ sql ��ԭʼ����,������ҿ����� sql ���Լ���һЩʵ��
2.��һ��ʵս����
2.1.Ԥ�ڵ����롢�������
�������ھ��峡����,��Ӧ����ֵ�����ֵӦ�ó�ɶ����
����ָ��:ʹ���ع��û���־��(show_log)�����û�����ά��(user_profile)�������û��Ļ���(�Ա�,�����)���ݡ�
��һ����������:
�ع��û���־��(show_log)����(���ݴ洢�� kafka ��):
| log_id | timestamp | user_id |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | a |
| 2 | 2021-11-01 00:03:00 | b |
| 3 | 2021-11-01 00:05:00 | c |
| 4 | 2021-11-01 00:06:00 | b |
| 5 | 2021-11-01 00:07:00 | c |
�û�����ά��(user_profile)����(���ݴ洢�� redis ��):
| user_id(����) | age | sex |
|---|---|---|
| a | 12-18 | �� |
| b | 18-24 | Ů |
| c | 18-24 | �� |
ע��:redis �е����ݽṹ�洢�ǰ��� key,value ȥ�洢�ġ����� key Ϊ user_id,value Ϊ age,sex �� json������ͼ��ʾ:
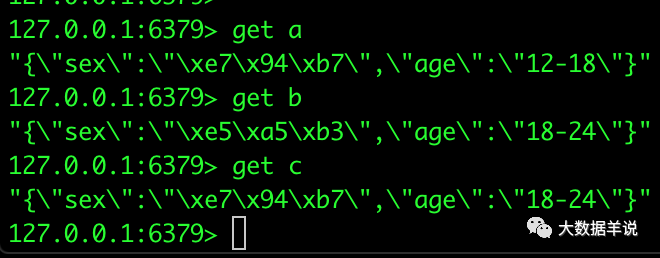
user_profile redis
Ԥ�������������:
| log_id | timestamp | user_id | age | sex |
|---|---|---|---|---|
| 1 | 2021-11-01 00:01:03 | a | 12-18 | �� |
| 2 | 2021-11-01 00:03:00 | b | 18-24 | Ů |
| 3 | 2021-11-01 00:05:00 | c | 18-24 | �� |
| 4 | 2021-11-01 00:06:00 | b | 18-24 | Ů |
| 5 | 2021-11-01 00:07:00 | c | 18-24 | �� |
2.2.batch lookup join sql ����
batch lookup join sql �����ԭ���� lookup join sql ����һģһ�������� sql��
CREATE?TABLE?show_log?(
????log_id?BIGINT,
????`timestamp`?as?cast(CURRENT_TIMESTAMP?as?timestamp(3)),
????user_id?STRING,
????proctime?AS?PROCTIME()
)
WITH?(
??'connector'?=?'datagen',
??'rows-per-second'?=?'10',
??'fields.user_id.length'?=?'1',
??'fields.log_id.min'?=?'1',
??'fields.log_id.max'?=?'10'
);
CREATE?TABLE?user_profile?(
????user_id?STRING,
????age?STRING,
????sex?STRING
????)?WITH?(
??'connector'?=?'redis',
??'hostname'?=?'127.0.0.1',
??'port'?=?'6379',
??'format'?=?'json',
??'lookup.cache.max-rows'?=?'500',
??'lookup.cache.ttl'?=?'3600',
??'lookup.max-retries'?=?'1'
);
CREATE?TABLE?sink_table?(
????log_id?BIGINT,
????`timestamp`?TIMESTAMP(3),
????user_id?STRING,
????proctime?TIMESTAMP(3),
????age?STRING,
????sex?STRING
)?WITH?(
??'connector'?=?'print'
);
--?lookup?join?��?query?��
INSERT?INTO?sink_table
SELECT?
????s.log_id?as?log_id
????,?s.`timestamp`?as?`timestamp`
????,?s.user_id?as?user_id
????,?s.proctime?as?proctime
????,?u.sex?as?sex
????,?u.age?as?age
FROM?show_log?AS?s
LEFT?JOIN?user_profile?FOR?SYSTEM_TIME?AS?OF?s.proctime?AS?u
ON?s.user_id?=?u.user_id
���Կ��� lookup join �� batch lookup join �Ĵ�������ȫ��ͬ��,Ψһ�IJ�֮ͬ������,batch lookup join ��Ҫ���� table config ����,����ͼ��ʾ:
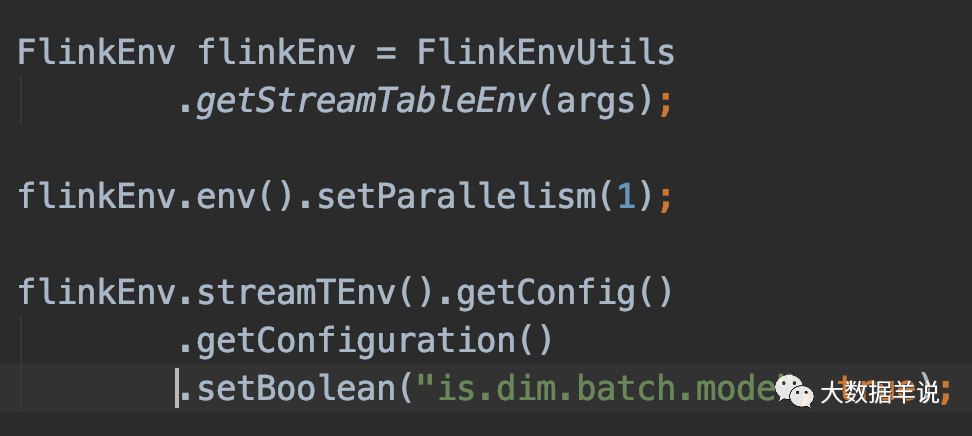
table config
2.2.batch lookup join ��
��ԭ�� lookup join �� batch lookup join ��Ч�������Ա�:
ԭ���� lookup join:ÿ����һ������,�����ⲿά����ȡ��������һ������,����ͼ��ʾ��
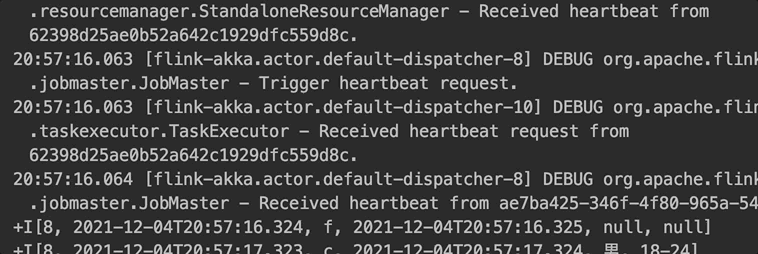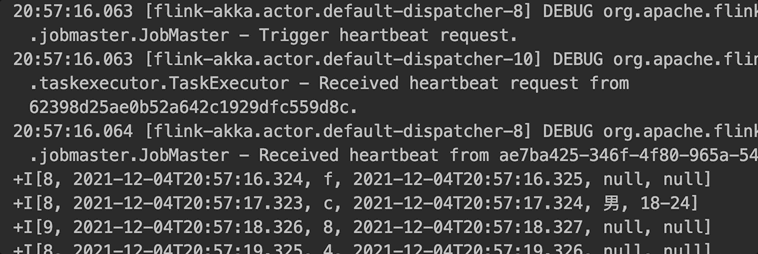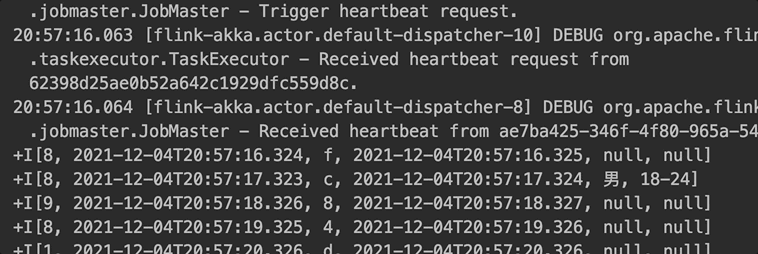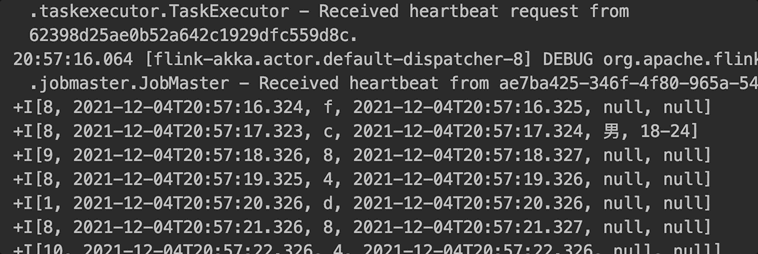
lookup join
����ʵ�ֵ� batch lookup join:��ÿ�ܹ� 30 ����������ÿ 5s(��ֹ�������ٵ������,��ʱ�䲻�������) ������ redis pipeline ���������ⲿ�洢һ�Ρ�Ȼ������������,����ͼ��ʾ�������������¡�

batch lookup join
3.batch lookup join ʵ��
3.1.��ô֪��Ӧ�ø��IJ���Դ��?
������ͨ�����漸������ȥ���������ô��Դ��ȥʵ���Լ��Ĺ��ܡ�
- ��Դ�������Щ�ȽϺõ�˼·?
- ����:���Ⱦ��Dzο�����ģ���ʵ��(����д,�����һ᳭��!),���籾��Ҫʵ�� batch lookup join,��ȻҪ�ο�ԭ���� lookup join ȥʵ�֡�
- ����ڸ� flink Դ��ʱ,��Ϊ flink Դ���ģ��̫����,��Ŀ�dz��Ӵ�,������һ�����������ⲻ����ôȥʵ���������,����Ӧ����ʲô�ط�ȥ�IJ���ʵ��!
- ����:һ�� flink ������(DataStream\Table\SQL)���еľ������������������� transformation ��!!!ֻҪ���漰������ʵ�ֵĶ���,С����ȾͿ��Ե� transformation ��ȥѰ�ҡ����Խ��ϵ����ÿһ�� operator �Ĺ��������� open �����оͿ��Կ�����ʵ����һ������ͳ�ʼ���ġ���������˳�ŵ���ջ��ǰ���ݶ�ȷ��Ҫ���IJ��ִ����ˡ�
3.2.lookup join ԭ��
3.2.1.transformation
��ʵ�� batch lookup join ֮ǰ,��ȻҪ��ԭ���� lookup join ��ʵ�ֿ�ʼ����,���� flink �ٷ��������ôʵ�ֵ�,���� transformation ����ͼ��ʾ:
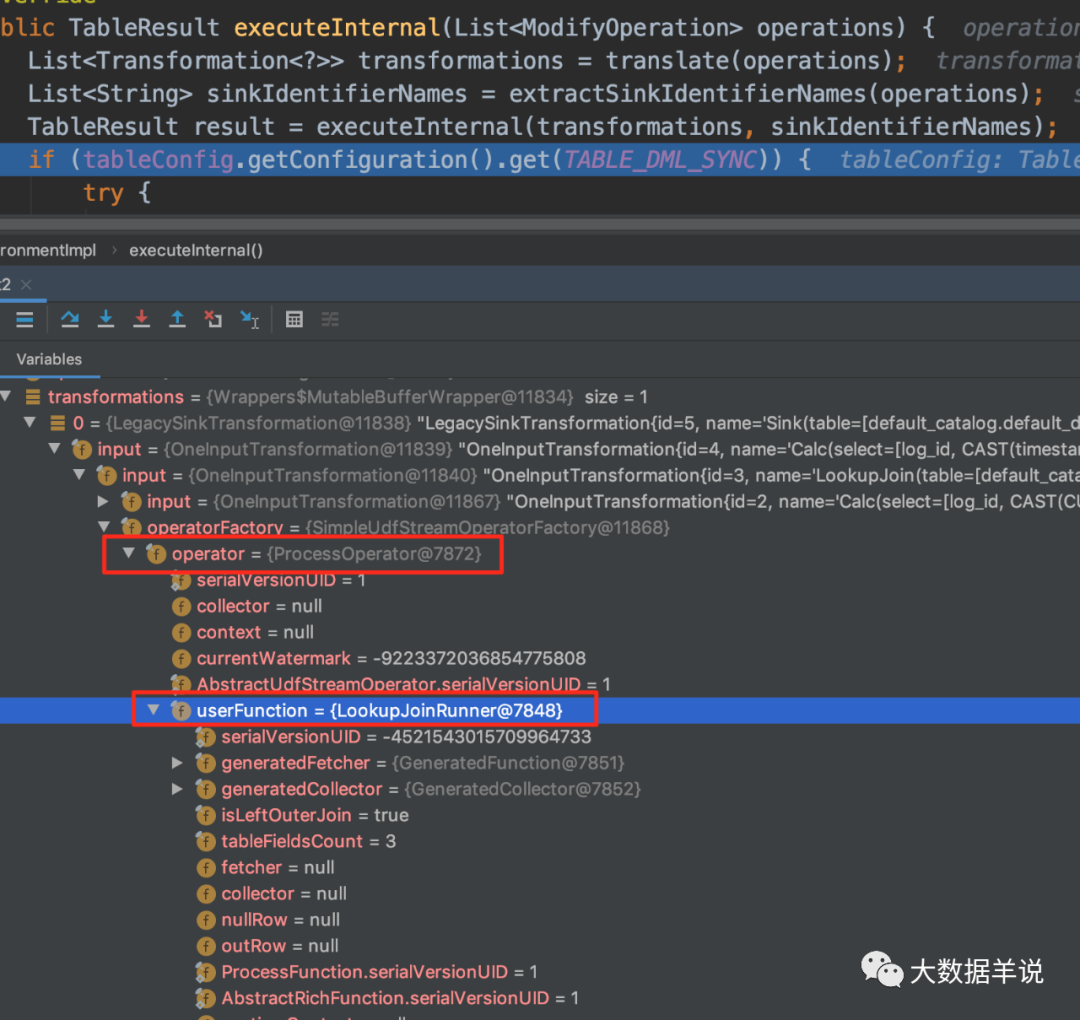
transformation
�����ʵ���������� org.apache.flink.streaming.api.operators.ProcessOperator,org.apache.flink.table.runtime.operators.join.lookup.LookupJoinRunner �С�
3.2.2.LookupJoinRunner
LookupJoinRunner �е����ݴ����������� processElement �С�
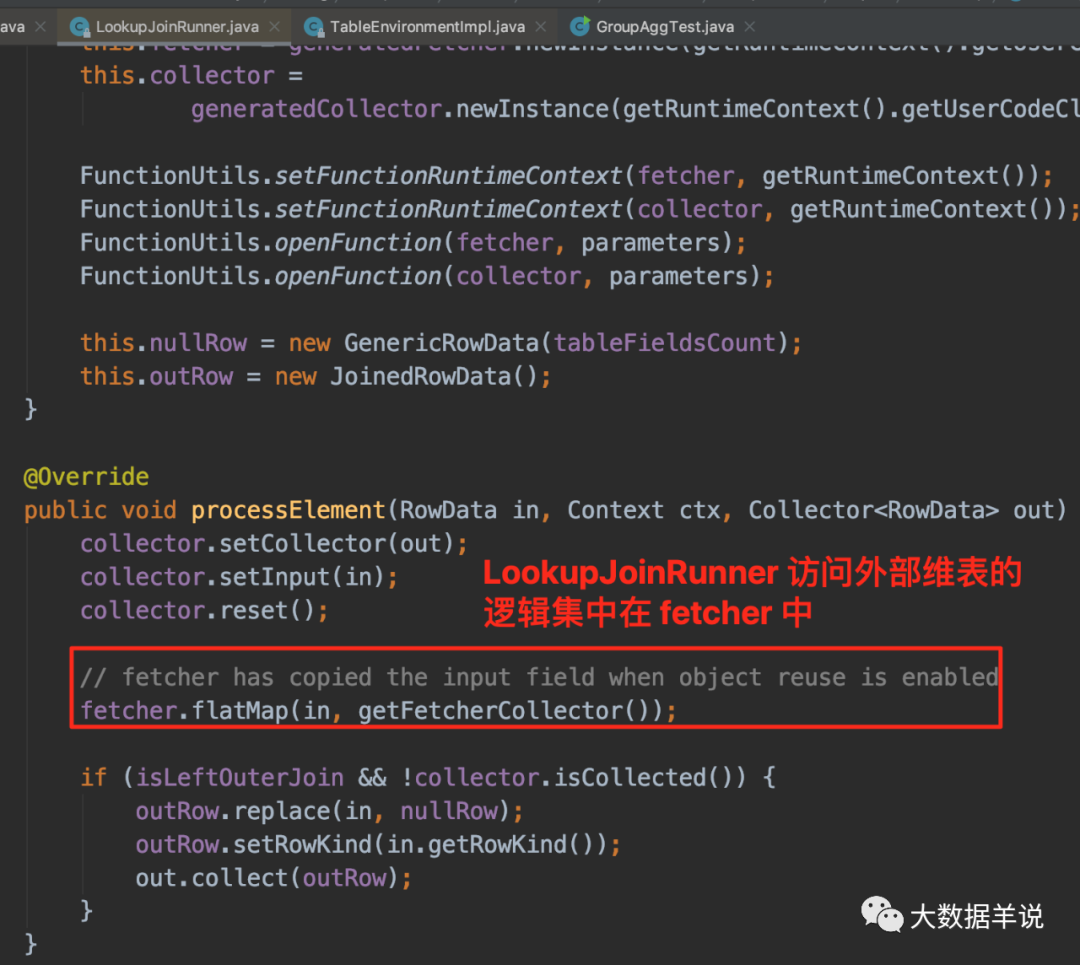
LookupJoinRunner
���Կ�����ͼ,LookupJoinRunner ����Ƕ��һ�� fetcher ��ʵ�־���� lookup ����
-
���� fetcher:���Ǹ��� flink sql lookup join �����ɵ� lookup join �Ĵ���ʵ��;
-
���� collector:collector ����Ҫ���ܾ��ǽ�
ԭʼ���� RowData��lookup ���� RowData�����ݺϲ�ΪJoinedRowData���,Ȼ�������
��������ϸ���� fetcher �� collector��
3.2.3.fetcher
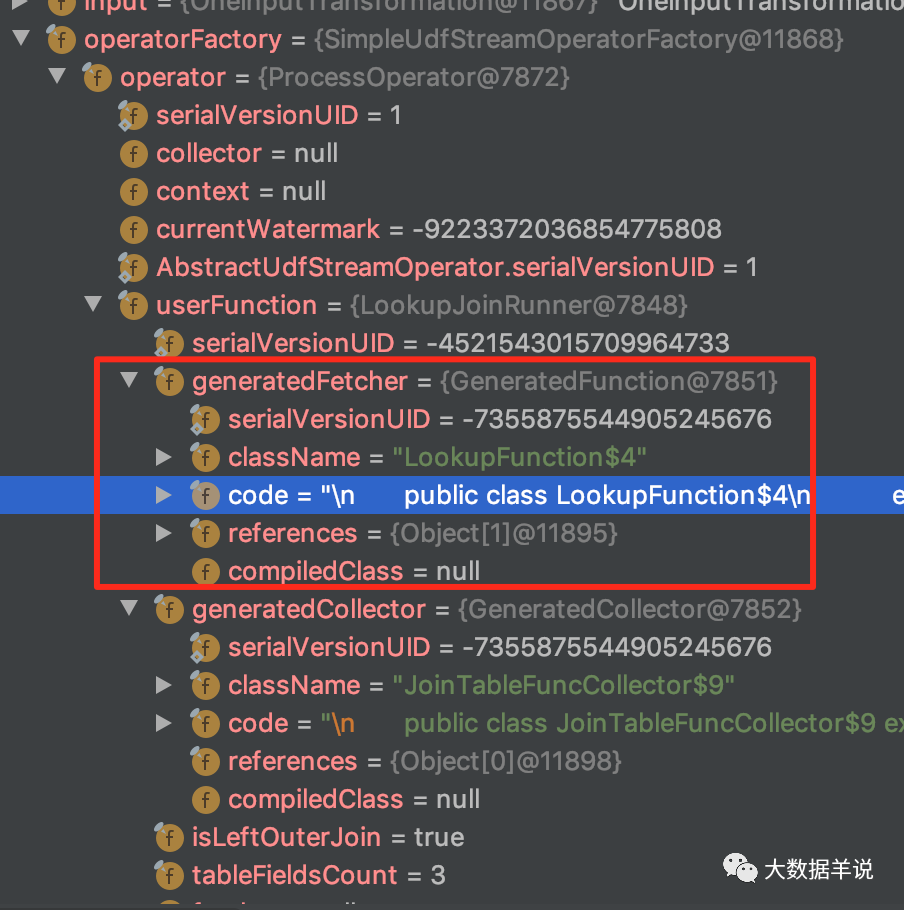
transformation fetcher
����� fetcher �Ĵ��� copy �������
fetcher
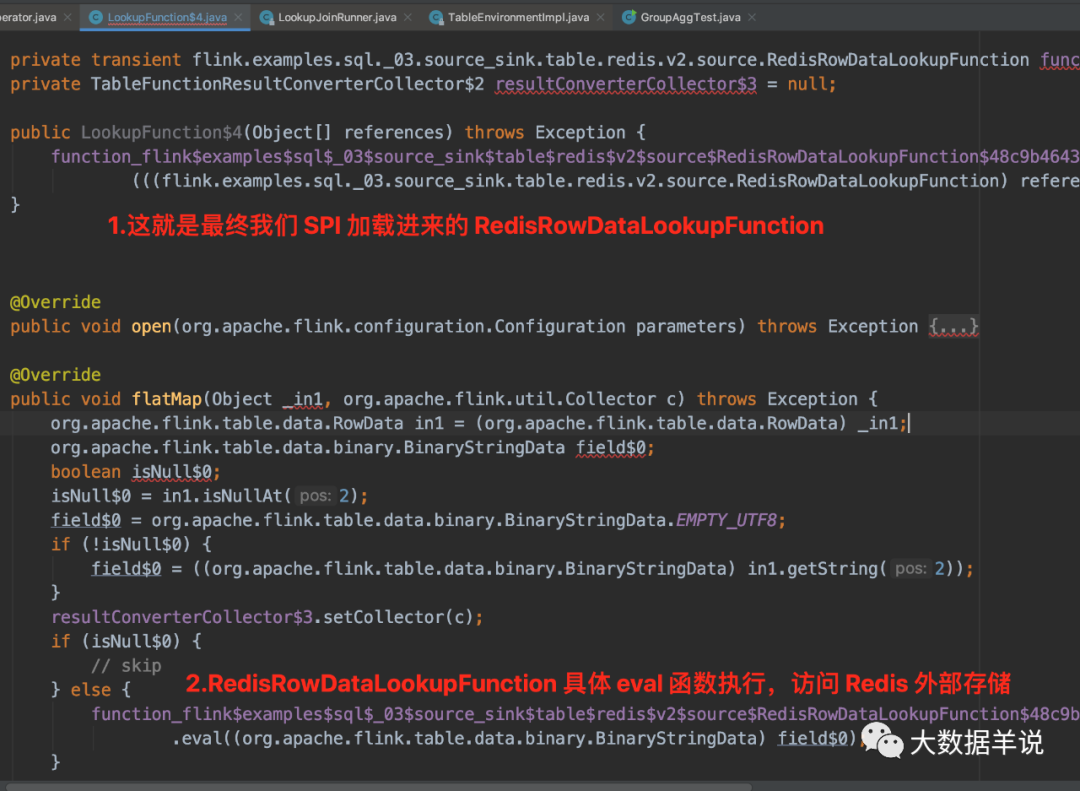
fetcher ��Ƕ�� RedisRowDataLookupFunction ����Ϊ���շ����ⲿά���ĺ�����
3.2.4.RedisRowDataLookupFunction
���� redis ��ȡ�����ݡ�
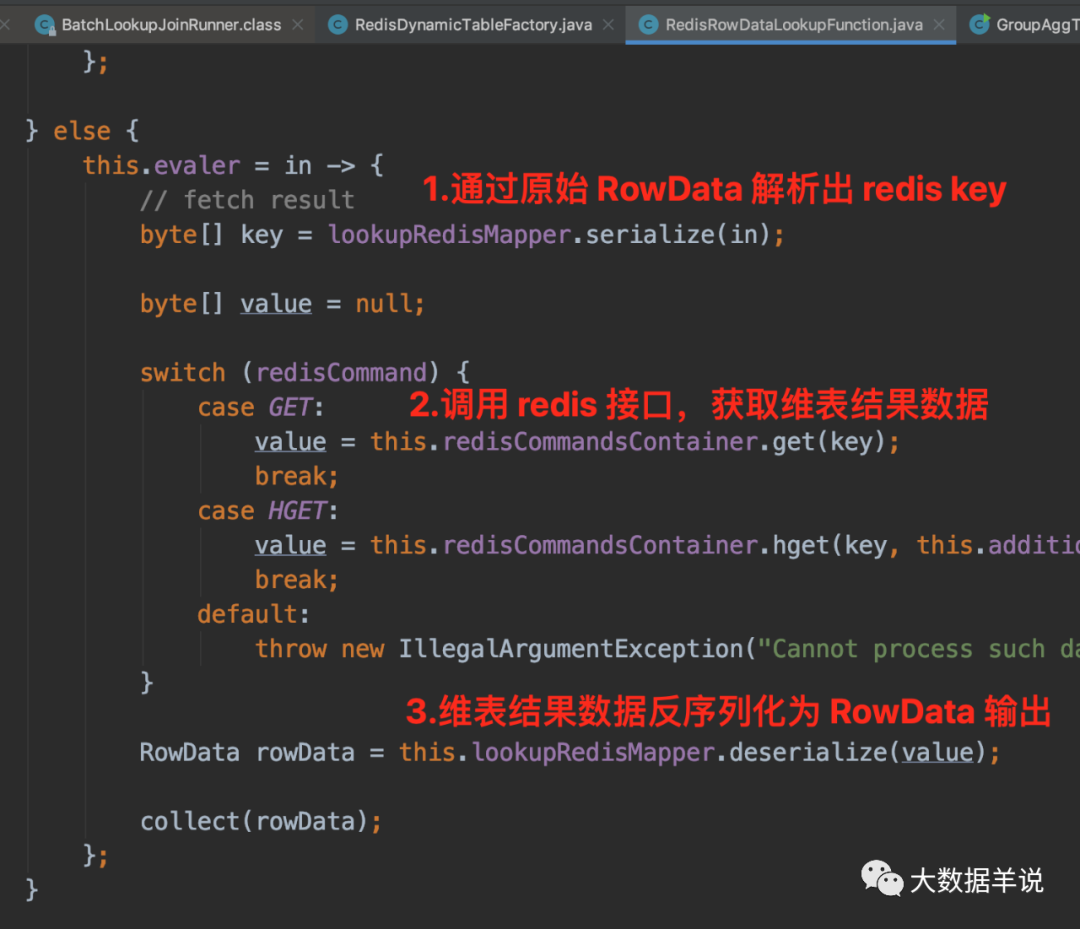
RedisRowDataLookupFunction
3.2.5.collector
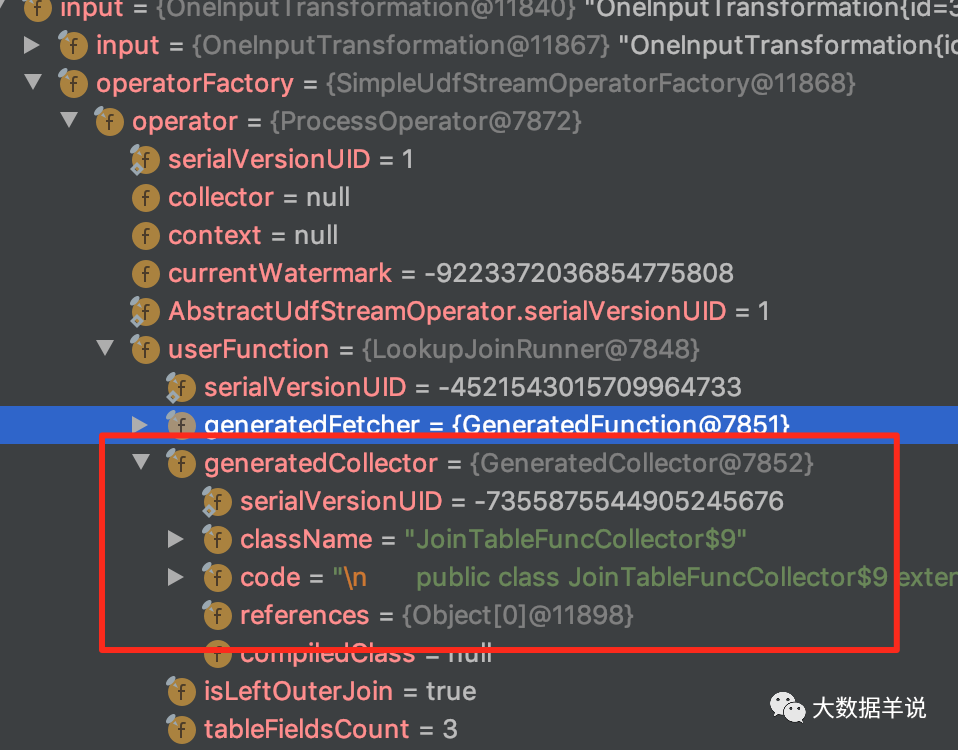
transformation collector
����� collector �Ĵ��� copy �������
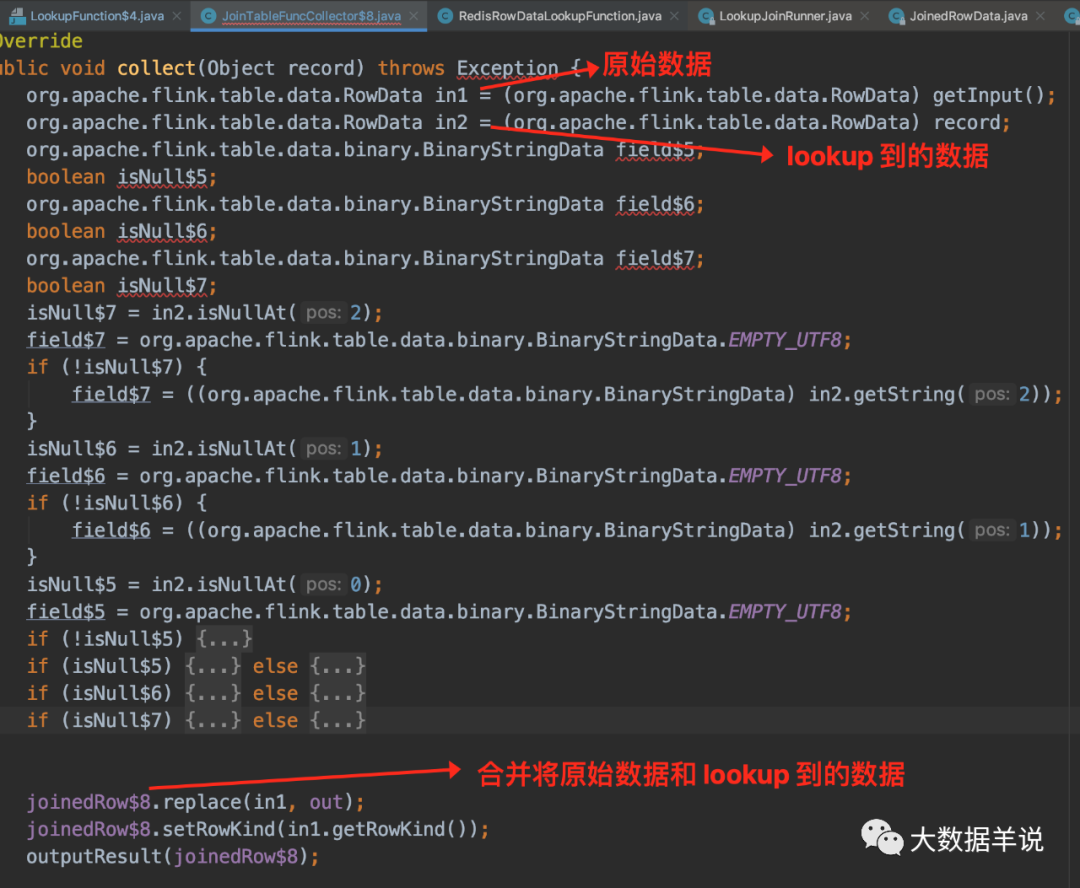
collector
3.3.lookup join ����ʵ�ֵ�����
�Dz��Ǹо�һ�� lookup join �ĵ����������ӡ�
��Ϊ batch lookup join ����ȫ�ο� lookup join ȥʵ�ֵ�,���Խ�������������һ������ĵ�������ϵ,��ͻ᷽�������� batch lookup join ʵ�ַ�����ʱ��ȥȷ����������һ���ִ��롣
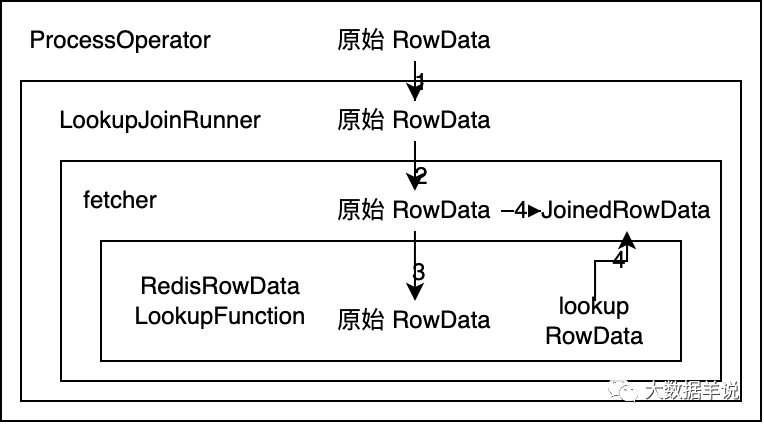
������
����ĵ���������:
-
ProcessOpeartor��ԭʼ RowData����LookupJoinRunner -
LookupJoinRunner��ԭʼ RowData�������� sql �������ɵ�fetcher -
fetcher�а�ԭʼ RowData����RedisRowDataLookupFunctionȻ��ȥ lookup ά��,lookup ���Ľ������Ϊlookup RowData -
collector��ԭʼ RowData��lookup RowData���ݺϲ�ΪJoinedRowDataȻ�������
3.4.batch lookup join ���˼·
����һ��,�ȿ������˼·���յĽ���,batch lookup join ���ӵ������������:
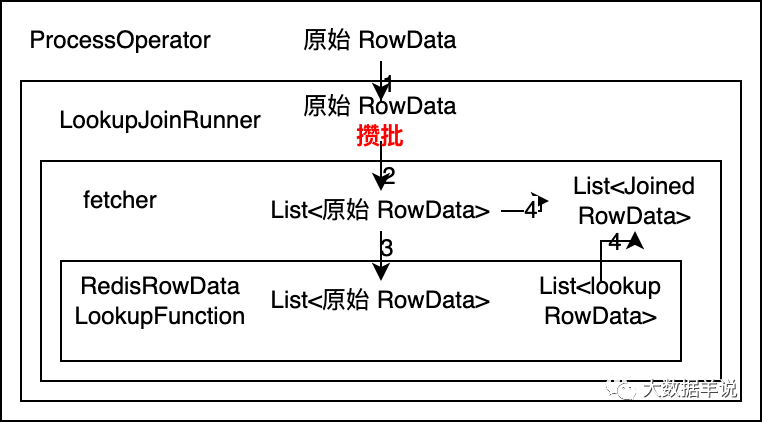
batch lookup ������
��ϸ˵��һ�����˼·:
-
������������������ⲿ�洢(Redis)�����ݡ������ƶϳ�
RedisRowDataLookupFunction��������Ҫ��List<ԭʼ RowData>,�����Ҫ��List<lookup RowData>�����������������뵽RedisRowDataLookupFunction�к�,ʹ�� Redis pipeline ȥ���������ⲿ�洢,Ȼ��ѽ��List<lookup RowData>����� -
��
RedisRowDataLookupFunction���������ΪList<lookup RowData>�ƶϳ�collector�������ݸ�ʽ��Ȼ��List<ԭʼ RowData>�������� lookup join ��collector�������ǽ�ԭʼ RowData��lookup RowData�ϲ�ΪJoinedRowData,�������������collector������ǽ�List<ԭʼ RowData>��List<lookup RowData>���б����ϲ�,һ��һ�������JoinedRowData�� -
ͬ��
RedisRowDataLookupFunction������������fetcher�����,���ƶϳ�fetcher�������ݸ�ʽ��Ȼ��List<ԭʼ RowData>�� -
����
fetcher������List<ԭʼ RowData>,��LookupJoinRunner�����fetcher������Ҳ��Ҫ��List<ԭʼ RowData>������ProcessOpeartorֻ�ܴ���LookupJoinRunnerԭʼ RowData,��˿��Եó����ǵ�ÿ�� 30 ����������ÿ�� 5s��������ȷ����Ҫ��LookupJoinRunner�����ˡ�
˼·����,��ô batch lookup join �漰���ĸĶ���Ҳ����ȷ���ˡ�
-
�½�һ��
BatchLookupJoinRunner:ʵ��������(ÿ�� 30 ����������ÿ�� 5s),�������������ݷ��� ListState ��,�Է�ֹ��ʧ,�� table config �е�is.dim.batch.mode����Ϊ true ʱʹ�ô�BatchLookupJoinRunner�� -
�������ɵ�
fetcher:��ԭ�������ԭʼ RowData��ΪList<ԭʼ RowData>�� -
�½�һ��
RedisRowDataBatchLookupFunction:ʵ�ֽ��������������List<ԭʼ RowData>�õ�֮��ʹ�� redis pipeline ���������ⲿ�洢,��ȡ��List<lookup RowData>������ݸ�collector�� -
�������ɵ�
collector:��ԭ�� lookup join �е�����ԭʼ RowData,lookup RowData��ΪList<ԭʼ RowData>,List<lookup RowData>,���ӱ���ѭ��List<ԭʼ RowData>,List<lookup RowData>,��˳��ϲ� List �е�ÿһ��ԭʼ RowData,lookup RowData���JoinedRowData������
3.5.batch lookup join ��������
3.5.1.transformation
���Կ��� is.dim.batch.mode ����Ϊ true ʱ,transformation ���¡�transformation �е��ص㴦�������� BatchLookupJoinRunner
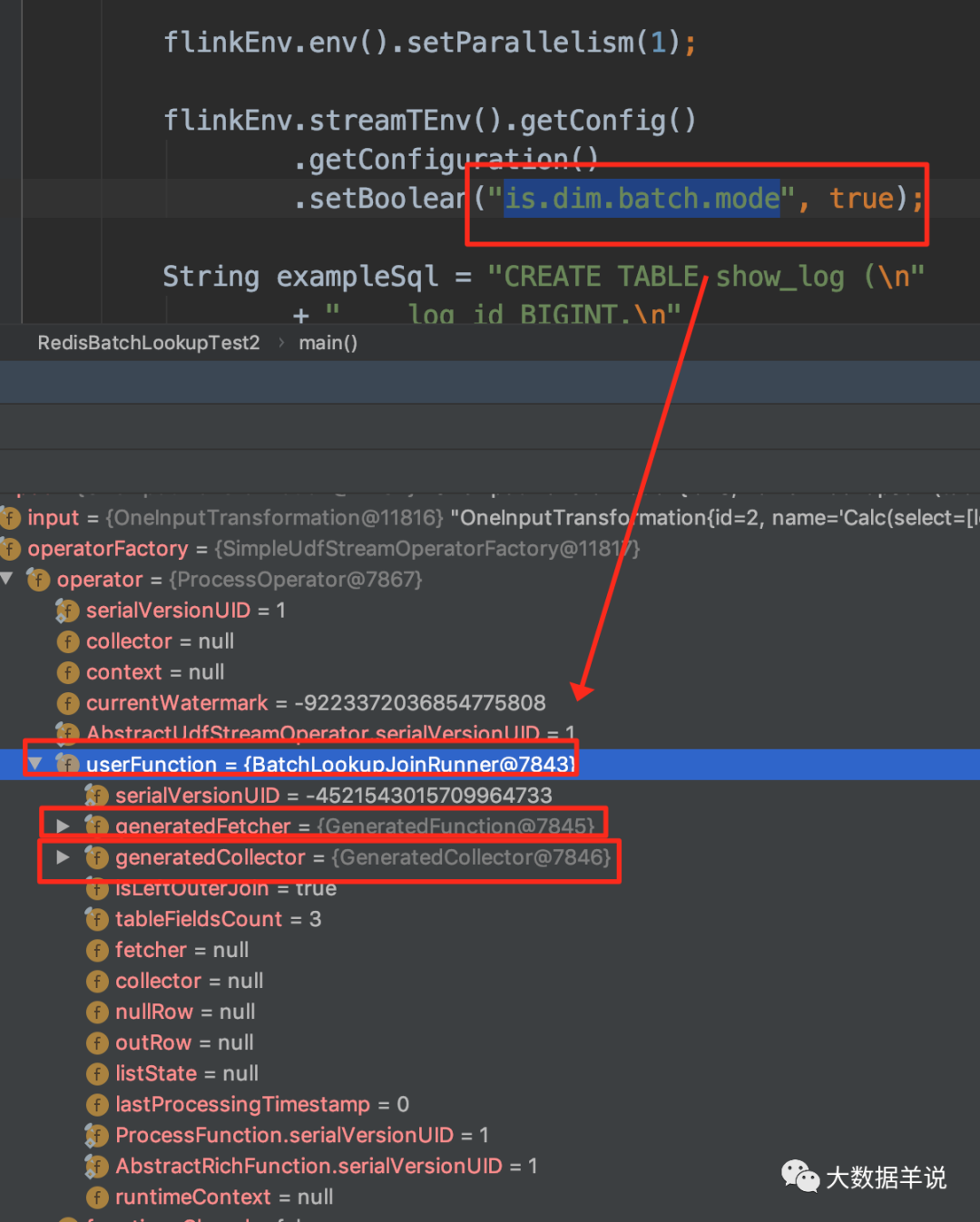
batch transformation
3.5.2.BatchLookupJoinRunner
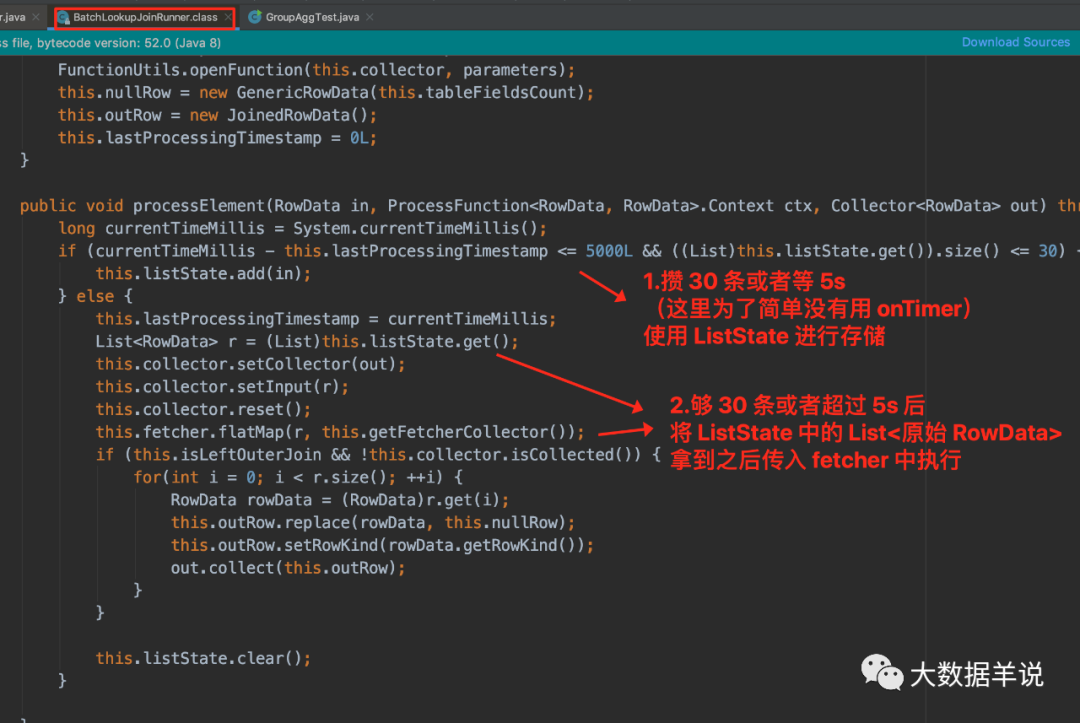
BatchLookupJoinRunner
3.5.3.fetcher
sql ���ɵ� fetcher ��������:
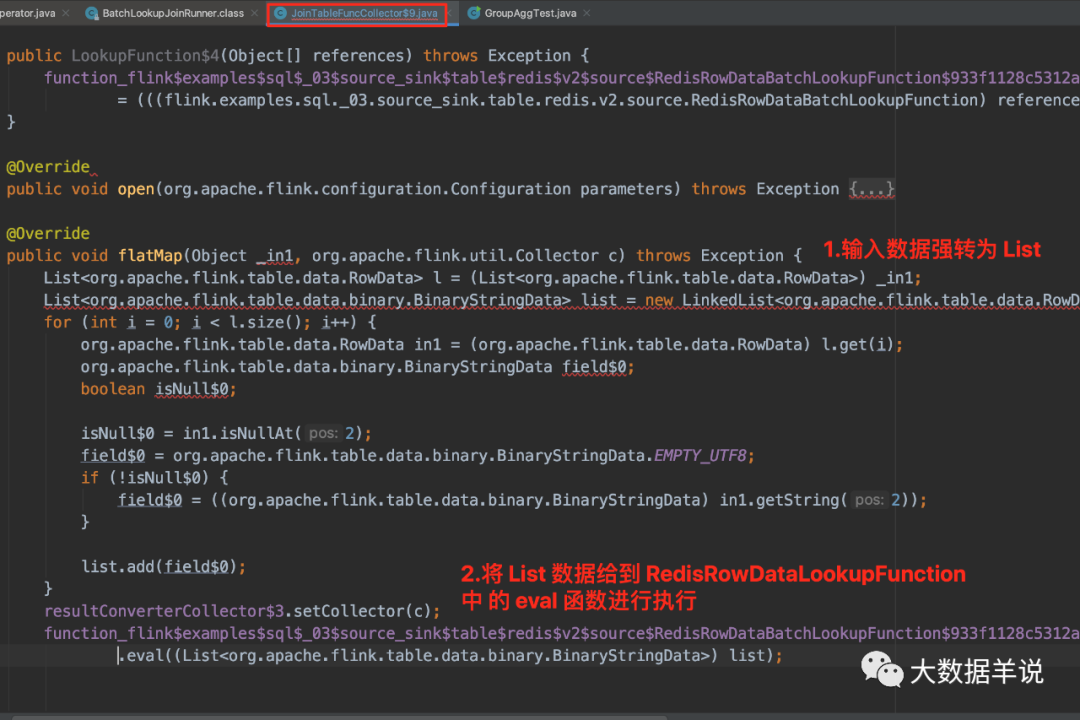
fetcher
3.5.4.RedisRowDataBatchLookupFunction
RedisRowDataBatchLookupFunction �õ������ List ����,���� Redis pipeline ���������ⲿ�洢��
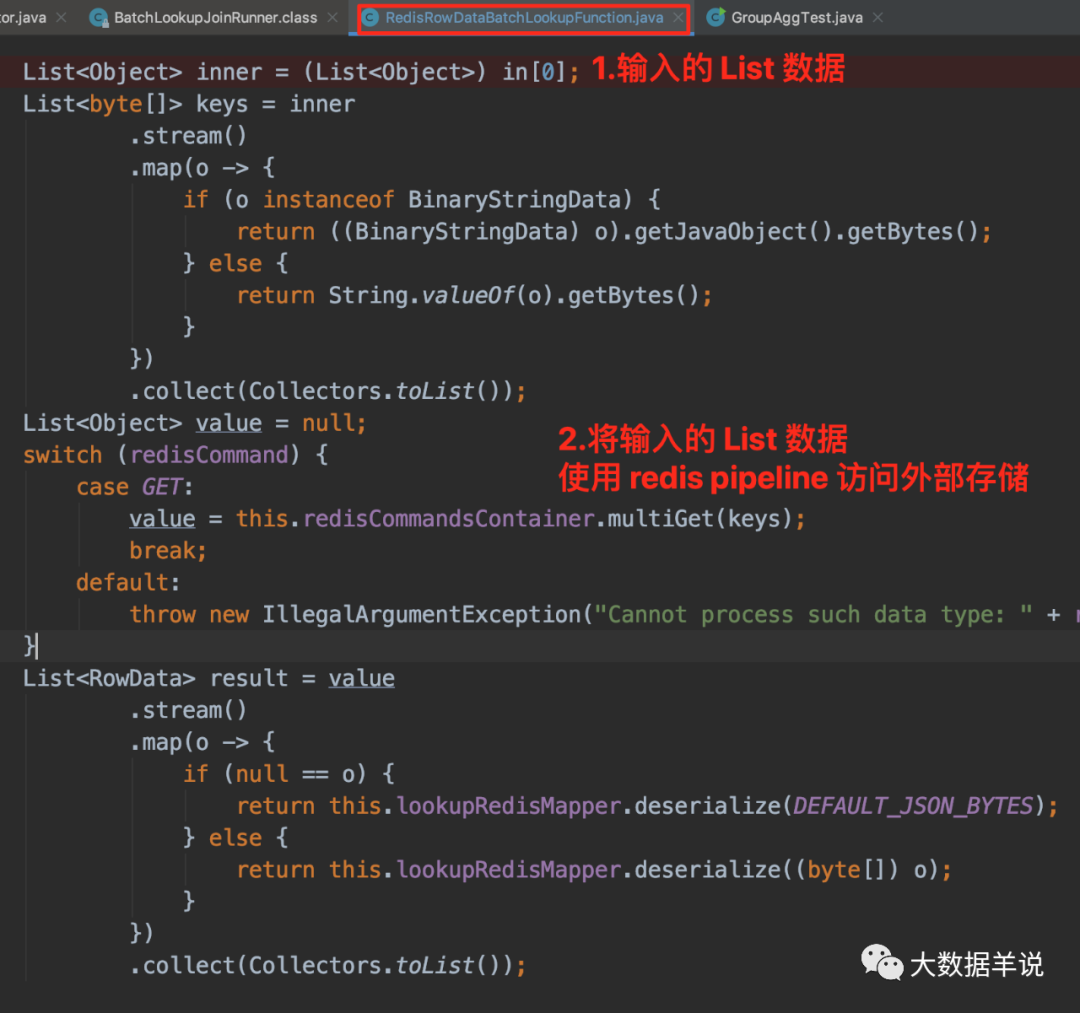
RedisRowDataBatchLookupFunction
3.5.5.collector
sql ���ɵ� collector ��������:
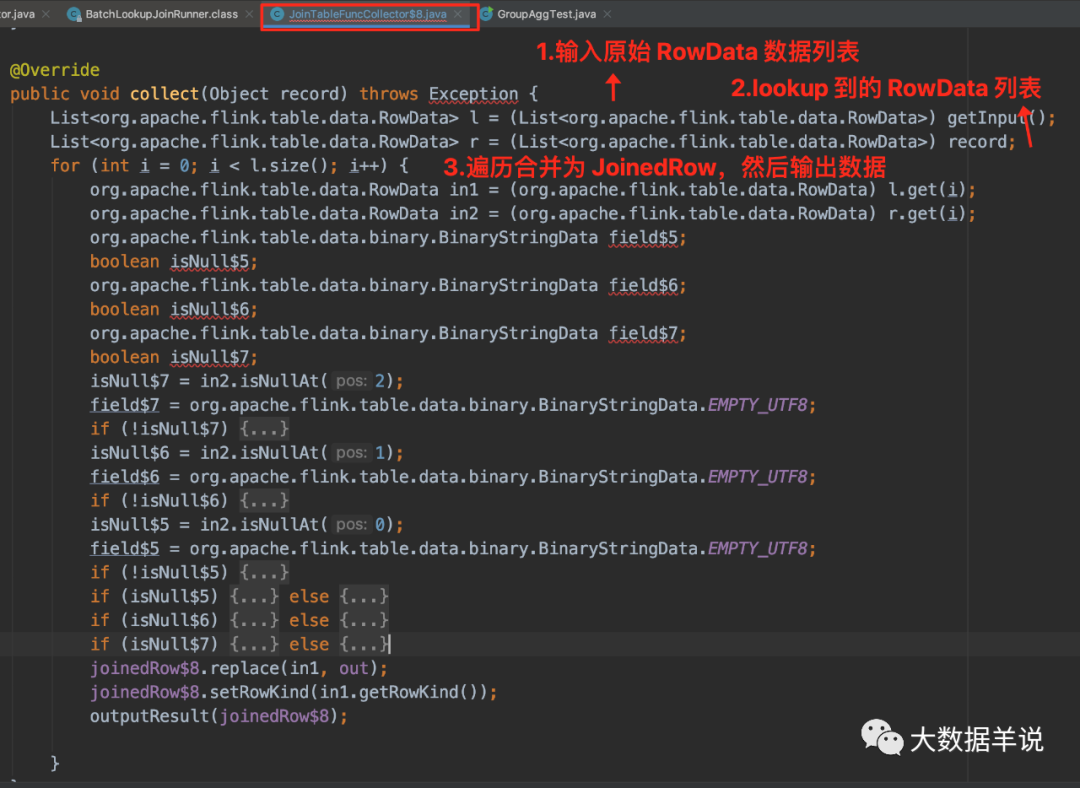
collector
3.6.���Ľ���
Ŀǰ��������ʵ�ֵIJ���֮������:
-
batch ��ִ������ sql ԭʼ�����岻һ�¡���Ϊ�� sql �Ͽ�����ȫû������ batch lookup join ������ġ�
-
����
ÿ 5s������ʵ������,��ȫ��������������ÿ 5s ��һ��,���ǻ��� onTimer �����ġ����ܻ��������һ������֮��,5 min �ڶ�û��������,�����ݾͲ�����ˡ� -
û�п���ʵ�ִ���ij���,��ʵ�ֹ���Ϊ��,���Ժܶ����Դ��ĸĶ�����ֱ�� copy ��������һ������ʵ�֡�
4.xdm ��ôʹ���������?
-
git clone https://github.com/yangyichao-mango/flink/tree/release-1.13.2
-
�� clone ��������Ŀ����,���°���������ģ�� install (mvn clean install) �����زֿ��С�
-
Ȼ���������Ŀ���������� blink ������ʹ�á�ʹ�÷�������ֻ��Ҫ�� table config ��
is.dim.batch.mode����Ϊ true,���뻹���� lookup join �ķ�ʽд���ɡ�
4.�ܽ���չ��
Դ�빫�ںź�̨�ظ�1.13.2 sql batch lookup join��ȡ��
������Ҫ������ flink sql batch lookup join ��ʹ�÷�ʽ,����������ʵ��˼·�Լ�Ч��,��Ҫ��������:
-
ֱ����һ��ʵս����:�������ع��û���־�������û�����(���䡢�Ա�)ά��Ϊ������ batch lookup join ���еĻ�������(��ô���ò���,��ôд sql,����Ч��զ��)��
-
batch lookup join:��Ҫ���� batch lookup join �Ĺ����Ǵ� flink transformation ����,ȷ��Ҫ batch lookup join �漰�Ķ��ĵط��Լ���ʵ��˼·��ԭ����Ҳ��̸����һЩ�Ķ�Դ����ʵ���Լ���Ҫ��һЩ���ܵ�˼·��
-
�ܽἰչ��:Ŀǰ�� batch lookup join ʵ����ʵ������ sql ��ԭʼ����,������ҿ����� sql ���Լ���һЩʵ��
�����Ƽ�
[
flink sql ֪������Ȼ(ʮ��):ά�� join �������Ż�֮·(��)��Դ��
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489814&idx=1&sn=085b93194dfd0feae5ac43ab6d3fb524&chksm=c15495eef6231cf8df60f1c0b1d2f7f277732090888f6b52ae02181a4f1fb688aad540fbccb6&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ(ʮ��):�� join ������???(��)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489658&idx=1&sn=6004d88772d473d4f5f446b8ffd3e14f&chksm=c1549482f6231d94a2c2841ff2b1ba840573dfd5acb6360ba84b9205cebd5a4a7c7f0aba61fc&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ(ʮ��):�� join ������???(��)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489633&idx=1&sn=24b418a8192116306eb3aab00ff24600&chksm=c1549499f6231d8ff40cdacd0504a21e605c07ba37fcfb4f5877523bac727e7955702882d7a2&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ(ʮһ):ȥ�ز������� count distinct ����ǿ��� deduplication
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489624&idx=1&sn=2738ec774dad30ae69b475dce45bfe4a&chksm=c15494a0f6231db6479fc45d18a3bdd69472d60240e9227edb4424cac420ed9f06381fd52a28&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ(ʮ):��Ҷ��� cumulate window �����ۼ�ָ����
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489554&idx=1&sn=275ca7bd853a762912f43bc51ef5c65f&chksm=c15494eaf6231dfca785e01632b8194db1817fb326c2698098e3eaeae430448596d73bc4a9e4&scene=21#wechat_redirect)
�CEND�C

�dz���ӭ��Ҽ���������,�йش����ݵ���������һ������

�����Ϸ�ɨ���ά��,������


��������˵
��������������������ĸ���~
44ƪԭ������
���ں�

����С��,�ø�����Ҫ���˿���~
