MySQLѧϰ
- ��1�� MySQL����
- ��2�� DQL����:���ݲ�ѯ����
- ��3�� DDL����:���ݶ�������
- ��4�� DML����:���ݲ�������
- ��5�� Լ��
- ��6�� �洢����
- ��7�� ����
- ��8�� ����:index
- ��9�� ��ͼ:view
- ��10�� ���ݿ��������ʽ
����������Bվ�϶ŵ�ѧϰ��Ƶ,��ѧϰ��¼,�������ѧϰ��ϰ,����������;��
��Ƶ����:https://www.bilibili.com/video/BV1Vy4y1z7EX?spm_id_from=pageDriver
�����1:https://blog.csdn.net/qq_43167873/article/details/120632442
�����2:https://blog.csdn.net/qq_38490457/article/details/107640904
��1�� MySQL����
1.1 ǰ��
- DB:���ݿ�,�洢���ݵIJֿ�
- DBMS:���ݿ����ϵͳ,�ֳ�Ϊ���ݿ������������ݿ��Ʒ,���ڴ����������ݿ�,��������MySQL��Oracle��SQL Server
- DBS:���ݿ�ϵͳ,���ݿ�ϵͳ��һ��ͨ��,�������ݿ⡢���ݿ����ϵͳ�����ݿ������Ա��,�����ķ���
- SQL:�ṹ����ѯ����,���ں����ݿ�ͨ�ŵ�����,����ij�����ݿ��������е�,���Ǽ������е��������ݿ�����ͨ�õ�����
1.2 MySQL��װ
��1��mysql5.5�汾��������ȡ��ʽ:
����:https://pan.baidu.com/s/1ocwLwFxfPVXUb4jfKyJsSQ
��ȡ��:��ע��?���ں�zdbѽ��ȡ,�ظ��ؼ�����ȡ��,�Ҹ������,����ҼӸ�������
��2�����尲װ��ж�ؽ̳̿���Ƶ����,����Ͳ�������ͼ��Bվ��װ��Ƶ����:https://www.bilibili.com/video/BV1Vy4y1z7EX?p=3&spm_id_from=pageDriver
��3�������װ�����г��ֺ���ͬ��������,���Բο�����һƪ����:�����������mysql5.5��װ���ɹ�:���һ��δ��Ӧ
��4����ƪ���͵ĵ����ĵ���ȡ��ʽ:
����:https://pan.baidu.com/s/1eyw8XZlIRB0fnnqm2D8NIg
��ȡ��:��ȡ��ʽͬ�ϡ�1��
1.3 ������ָ��
�鿴mysql����
������C>�Ҽ��C>�����C>�����Ӧ�ó���C>����C>��mysql����
MySQL�ķ���,Ĭ���ǡ���������״̬,ֻ��������mysql�����á�Ĭ��������ǡ��Զ�������,�Զ�������ʾ��һ����������ϵͳ��ʱ��,�Զ������÷���
(1)MySQL�������ر����
������ָ����ر�mysql����
net stop MySQL
net start MySQL
ע��:��Ҫ������Ա������cmd����!

���������ֹͣ������Ҳ����ͨ������netָ��
(2)MySQL�ĵ�¼���
��binĿ¼�µ�mysql.exe����������mysql���ݿ������
mysql -uroot -t����
��ʾ������ɹ�!
(3)MySQL���˳����
exit
���·�ʽ�������������¼:

(4)�鿴MySQL�İ汾��
select version();
+-----------+
| version() |
+-----------+
| 5.5.36 |
+-----------+
1 row in set (0.01 sec)
(5)�鿴�������ݿ�
ע��:�зֺ�
show databases;

һ��ʼĬ���Դ��ĸ����ݿ�
(6)ʹ���ض����ݿ�
use ���ݿ���;

(7)�������ݿ�
create ���ݿ���;
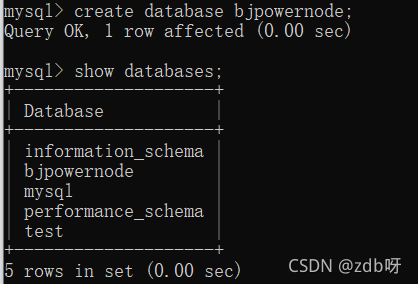
(8)�鿴��ǰʹ�õ����ݿ������б�
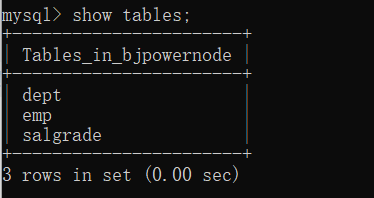
show tables;
mysql> show tables;
+-----------------------+
| Tables_in_bjpowernode |
+-----------------------+
| dept |
| emp |
| salgrade |
| t_class |
| t_student |
| t_user |
| t_vip |
+-----------------------+
7 rows in set (0.00 sec)
ע��:�����нм�¼;�н��ֶ���ÿһ���ֶζ����ֶ������������͡�Լ�������ԡ�
��������:�ַ��������ݡ����ڵ�
Լ��:Լ���кܶ���,����Ψһ��Լ����
(9)�鿴��ǰʹ�õ����ݿ�
select database();
+-------------+
| database() |
+-------------+
| bjpowernode |
+-------------+
1 row in set (0.00 sec)
ע��: ��;����ʾ������!
ע��:\c������ֹһ����������롣

ע��:����������������ִ�Сд!!!
1.4 SQL�������ַ���
- DQL:���ݲ�ѯ����:select��from��where
- DML:���ݲ�������:insert(��)��update(ɾ)��delete(��)����Ҫ�Dz����������ݵIJ���
- DDL:���ݶ�������:create(��)��drop(ɾ)��alter(��)��truncate����Ҫ�ǶԱ��ṹ���в�����
- DCL:���ݿ�������:grant(����)��revoke(����Ȩ��)
- TCL:�����������:commit(�����ύ)��rollback(����ع�)
��2�� DQL����:���ݲ�ѯ����
DQL:���ݲ�ѯ����:select��from��where
2.1 ������ѯ
(1)���ݵĵ���
source ·����.sql
ע��:·���в�Ҫ������!!
���絼��bjpowernode.sql,��ô����?
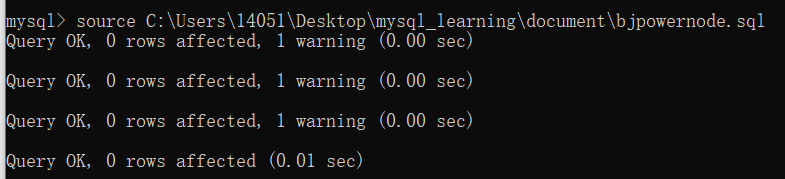
����������������ű�:dept�Dz��ű�,emp��Ա����,salgrade �ǹ��ʵȼ���
(2)�鿴���е�����
�:select * from ����;
mysql> select * from emp;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
(3)�鿴���Ľṹ
desc ����;
mysql> desc emp;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| EMPNO | int(4) | NO | PRI | NULL | |
| ENAME | varchar(10) | YES | | NULL | |
| JOB | varchar(9) | YES | | NULL | |
| MGR | int(4) | YES | | NULL | |
| HIREDATE | date | YES | | NULL | |
| SAL | double(7,2) | YES | | NULL | |
| COMM | double(7,2) | YES | | NULL | |
| DEPTNO | int(2) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
8 rows in set (0.01 sec)
(4)��ѯDQL
1����ѯһ���ֶ�
select �ֶ��� from ����;
����Ҫע��:select��from���ǹؼ��֡��ֶ����ͱ������DZ�ʶ����
����1.��ѯ��������
mysql> SELECT DNAME FROM DEPT; //ע��,�����ִ�Сд,���Ҳ��
mysql> select dname from dept;
+------------+
| dname |
+------------+
| ACCOUNTING |
| RESEARCH |
| SALES |
| OPERATIONS |
+------------+
4 rows in set (0.00 sec)
2����ѯ����ֶ�:ʹ�ö��Ÿ���
����2:��ѯ���ű�źͲ�����
mysql> select deptno,dname from dept;
+--------+------------+
| deptno | dname |
+--------+------------+
| 10 | ACCOUNTING |
| 20 | RESEARCH |
| 30 | SALES |
| 40 | OPERATIONS |
+--------+------------+
4 rows in set (0.00 sec)
3����ѯ�����ֶ�
����һ:��ÿ���ֶ�д��,���Ÿ���
select a,b,c,d,e from tablename;
������:
select * from tablename;
��������ȱ��:Ч�ʵ�,�ɶ��Բ�;ʵ�ʿ����в�����ʹ��,�����ѧϰΪ�˷��������
(5)����ѯ���������
select �ֶ��� as �ֶα��� from ����;
mysql> select deptno,dname as name from dept;
+--------+------------+
| deptno | name |
+--------+------------+
| 10 | ACCOUNTING |
| 20 | RESEARCH |
| 30 | SALES |
| 40 | OPERATIONS |
+--------+------------+
4 rows in set (0.00 sec)
ע��:ֻ�ǽ���ʾ�IJ�ѯ�����ʾΪname,ԭ������:dname
��ס:select��䲻������ݽ����ġ�
as�ؼ��ֿ���ʡ����?���Ե�
mysql> select deptno,dname deptname from dept;
+--------+------------+
| deptno | deptname |
+--------+------------+
| 10 | ACCOUNTING |
| 20 | RESEARCH |
| 30 | SALES |
| 40 | OPERATIONS |
+--------+------------+
4 rows in set (0.00 sec)
�����������ʱ��,���������пո�,��ô��?
mysql> select deptno,dname dept name from dept;
DBMS�������������,����SQL���ı���,�������,���뱨������ô���?������
select deptno,dname ��dept name�� from dept; //�ӵ�����
select deptno,dname ��dept name�� from dept; //��˫����
mysql> select deptno,dname 'dept name' from dept;
+--------+------------+
| deptno | dept name |
+--------+------------+
| 10 | ACCOUNTING |
| 20 | RESEARCH |
| 30 | SALES |
| 40 | OPERATIONS |
+--------+------------+
4 rows in set (0.00 sec)
ע��:�����е����ݿ��,�ַ���ͳһʹ�õ�������������
�������DZ�,˫������oracle���ݿ����ò���,mysql�п���ʹ�á�
����:����Ա����н
1.��Ա�����ֺ���:sal * 12
mysql> select ename, sal as monthsal, (sal*12) as yearsal from emp;
+--------+----------+----------+
| ename | monthsal | yearsal |
+--------+----------+----------+
| SMITH | 800.00 | 9600.00 |
| ALLEN | 1600.00 | 19200.00 |
| WARD | 1250.00 | 15000.00 |
| JONES | 2975.00 | 35700.00 |
| MARTIN | 1250.00 | 15000.00 |
| BLAKE | 2850.00 | 34200.00 |
| CLARK | 2450.00 | 29400.00 |
| SCOTT | 3000.00 | 36000.00 |
| KING | 5000.00 | 60000.00 |
| TURNER | 1500.00 | 18000.00 |
| ADAMS | 1100.00 | 13200.00 |
| JAMES | 950.00 | 11400.00 |
| FORD | 3000.00 | 36000.00 |
| MILLER | 1300.00 | 15600.00 |
+--------+----------+----------+
14 rows in set (0.00 sec)
2.�����ı����ӵ�����
mysql> select ename, sal '��н', (sal*12) '��н' from emp;
+--------+---------+----------+
| ename | ��н | ��н |
+--------+---------+----------+
| SMITH | 800.00 | 9600.00 |
| ALLEN | 1600.00 | 19200.00 |
| WARD | 1250.00 | 15000.00 |
| JONES | 2975.00 | 35700.00 |
| MARTIN | 1250.00 | 15000.00 |
| BLAKE | 2850.00 | 34200.00 |
| CLARK | 2450.00 | 29400.00 |
| SCOTT | 3000.00 | 36000.00 |
| KING | 5000.00 | 60000.00 |
| TURNER | 1500.00 | 18000.00 |
| ADAMS | 1100.00 | 13200.00 |
| JAMES | 950.00 | 11400.00 |
| FORD | 3000.00 | 36000.00 |
| MILLER | 1300.00 | 15600.00 |
+--------+---------+----------+
14 rows in set (0.00 sec)
2.2 ������ѯ:where
���ǽ������������ݶ���������Dz�ѯ�������������ġ�
���ʽ:
select
�ֶ�1,�ֶ�2,�ֶ�3....
from
����
where
����;
1. ���ڡ�С�ڡ����ڡ�������
��������1:��ѯн�ʵ���800��Ա�������ͱ�ź�н��
mysql> select empno, ename, sal from emp where sal=800;
+-------+-------+--------+
| empno | ename | sal |
+-------+-------+--------+
| 7369 | SMITH | 800.00 |
+-------+-------+--------+
1 row in set (0.00 sec)
����������2:��ѯн�ʲ�����800��Ա�������ͱ�ź�н��,���ֱ�ʾ��ʽ:
mysql> select empno, ename, sal from emp where sal!=800;
mysql> select empno, ename, sal from emp where sal<>800; //�����ѯ�Ľ����һ��
+-------+--------+---------+
| empno | ename | sal |
+-------+--------+---------+
| 7499 | ALLEN | 1600.00 |
| 7521 | WARD | 1250.00 |
| 7566 | JONES | 2975.00 |
| 7654 | MARTIN | 1250.00 |
| 7698 | BLAKE | 2850.00 |
| 7782 | CLARK | 2450.00 |
| 7788 | SCOTT | 3000.00 |
| 7839 | KING | 5000.00 |
| 7844 | TURNER | 1500.00 |
| 7876 | ADAMS | 1100.00 |
| 7900 | JAMES | 950.00 |
| 7902 | FORD | 3000.00 |
| 7934 | MILLER | 1300.00 |
+-------+--------+---------+
13 rows in set (0.00 sec)
��������3:��ѯн��С��2000��Ա�������ͱ�ź�н��
mysql> select empno, ename, sal from emp where sal>2000;
+-------+-------+---------+
| empno | ename | sal |
+-------+-------+---------+
| 7566 | JONES | 2975.00 |
| 7698 | BLAKE | 2850.00 |
| 7782 | CLARK | 2450.00 |
| 7788 | SCOTT | 3000.00 |
| 7839 | KING | 5000.00 |
| 7902 | FORD | 3000.00 |
+-------+-------+---------+
6 rows in set (0.00 sec)
���ڵ�������4:��ѯн�ʴ��ڵ���3000��Ա�������ͱ�ź�н��
mysql> select empno, ename, sal from emp where sal>=3000;
+-------+-------+---------+
| empno | ename | sal |
+-------+-------+---------+
| 7788 | SCOTT | 3000.00 |
| 7839 | KING | 5000.00 |
| 7902 | FORD | 3000.00 |
+-------+-------+---------+
3 rows in set (0.00 sec)
С�ں�ͬ��,�㲻�ٽ��ܡ�
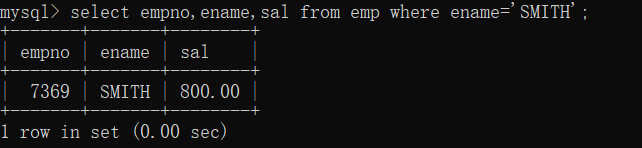
����:��ѯSMITH�ı�ź�н��
select empno,ename,sal from emp where ename='SMITH'; //�ַ���ʹ�õ�����
2. between �� and ��. ����ֵ֮��
��ͬ�� >= and <=,������
����:��ѯн����2450��3000֮���Ա����Ϣ?����2450��3000
mysql> select empno, ename, sal from emp where sal>=2450 and sal<=3000;
mysql> select empno, ename, sal from emp where sal between 2450 and 3000; //���书��һ��
+-------+-------+---------+
| empno | ename | sal |
+-------+-------+---------+
| 7566 | JONES | 2975.00 |
| 7698 | BLAKE | 2850.00 |
| 7782 | CLARK | 2450.00 |
| 7788 | SCOTT | 3000.00 |
| 7902 | FORD | 3000.00 |
+-------+-------+---------+
5 rows in set (0.00 sec)
ע��:ʹ��between and������С�Ҵ�;between and�DZ�����
3. is null (is not null )
����:��ѯ��ЩԱ���Ľ���/����Ϊnull
mysql> select empno, ename, sal from emp where comm is null;
+-------+--------+---------+
| empno | ename | sal |
+-------+--------+---------+
| 7369 | SMITH | 800.00 |
| 7566 | JONES | 2975.00 |
| 7698 | BLAKE | 2850.00 |
| 7782 | CLARK | 2450.00 |
| 7788 | SCOTT | 3000.00 |
| 7839 | KING | 5000.00 |
| 7876 | ADAMS | 1100.00 |
| 7900 | JAMES | 950.00 |
| 7902 | FORD | 3000.00 |
| 7934 | MILLER | 1300.00 |
+-------+--------+---------+
10 rows in set (0.00 sec)
mysql> select empno, ename, sal from emp where comm is not null;
+-------+--------+---------+
| empno | ename | sal |
+-------+--------+---------+
| 7499 | ALLEN | 1600.00 |
| 7521 | WARD | 1250.00 |
| 7654 | MARTIN | 1250.00 |
| 7844 | TURNER | 1500.00 |
+-------+--------+---------+
4 rows in set (0.00 sec)
ע��:�����ݿ��null����ʹ�õȺŽ��к�������Ҫʹ��is null��Ϊ���ݿ��е�null����ʲôҲû��,������һ��ֵ��
4. and��or
����:��ѯ������λ��MANAGER**����(����)**���ʴ���2500��Ա����Ϣ
mysql> select empno, ename, job, sal from emp where job='MANAGER' and sal>2500;
+-------+-------+---------+---------+
| empno | ename | job | sal |
+-------+-------+---------+---------+
| 7566 | JONES | MANAGER | 2975.00 |
| 7698 | BLAKE | MANAGER | 2850.00 |
+-------+-------+---------+---------+
2 rows in set (0.00 sec)
mysql> select empno, ename, job, sal from emp where job='MANAGER' or sal>2500;
+-------+-------+-----------+---------+
| empno | ename | job | sal |
+-------+-------+-----------+---------+
| 7566 | JONES | MANAGER | 2975.00 |
| 7698 | BLAKE | MANAGER | 2850.00 |
| 7782 | CLARK | MANAGER | 2450.00 |
| 7788 | SCOTT | ANALYST | 3000.00 |
| 7839 | KING | PRESIDENT | 5000.00 |
| 7902 | FORD | ANALYST | 3000.00 |
+-------+-------+-----------+---------+
6 rows in set (0.00 sec)
ע��:and���ȼ���or�ߡ�
select * from emp where sal > 2500 and deptno = 10 or deptno = 20; //����书��һ��
select * from emp where (sal > 2500 and deptno = 10) or deptno = 20;
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
+-------+-------+-----------+------+------------+---------+------+--------+
6 rows in set (0.00 sec)
select * from emp where sal > 2500 and (deptno = 10 or deptno = 20); //��������治һ��
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
+-------+-------+-----------+------+------------+---------+------+--------+
4 rows in set (0.00 sec)
5. in��not in
����:��ѯ������λ��MANAGER��SALESMAN��Ա��;��ѯн����800��5000��Ա����Ϣ
mysql> select empno,ename,job from emp where job in('MANAGER', 'SALESMAN');
+-------+--------+----------+
| empno | ename | job |
+-------+--------+----------+
| 7499 | ALLEN | SALESMAN |
| 7521 | WARD | SALESMAN |
| 7566 | JONES | MANAGER |
| 7654 | MARTIN | SALESMAN |
| 7698 | BLAKE | MANAGER |
| 7782 | CLARK | MANAGER |
| 7844 | TURNER | SALESMAN |
+-------+--------+----------+
7 rows in set (0.00 sec)
mysql> select * from emp where sal in (800,5000);
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
+-------+-------+-----------+------+------------+---------+------+--------+
2 rows in set (0.00 sec)
����:��ѯн�ʲ���800,5000,3000��Ա����Ϣ
mysql> select * from emp where sal not in (800,5000,3000);
+-------+--------+----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+----------+------+------------+---------+---------+--------+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+----------+------+------------+---------+---------+--------+
10 rows in set (0.00 sec)
6. like:����python�������ʽ
��Ϊģ����ѯ,֧��%���»���ƥ��
? %:ƥ���������ַ�
? �»���:����һ���ַ�
1.? �ҳ������к���O��
mysql> select ename from emp where ename like '%O%';
+-------+
| ename |
+-------+
| JONES |
| SCOTT |
| FORD |
+-------+
3 rows in set (0.00 sec)
2.�ҳ�������T��β��
mysql> select ename from emp where ename like '%T';
+-------+
| ename |
+-------+
| SCOTT |
+-------+
1 row in set (0.00 sec)
3.�ҳ�������K��ʼ��
mysql> select ename from emp where ename like 'K%';
+-------+
| ename |
+-------+
| KING |
+-------+
1 row in set (0.00 sec)
4.�ҳ��ڶ�����ÿ��A��
mysql> select ename from emp where ename like '_A%';
+--------+
| ename |
+--------+
| WARD |
| MARTIN |
| JAMES |
+--------+
3 rows in set (0.00 sec)
5.�ҳ��������С� _����,ת���ַ�ʵ��
mysql> select name from t_student where name like '%\_%'; // \ת���ַ���
+----------+
| name |
+----------+
| jack_son |
+----------+
2.3 �����ѯ:order by
(1)����:asc
��ѯ����Ա��н��,��������
select ename,sal from emp order by sal; //�������һ��,Ĭ�Ͼ�Ϊ����
select ename,sal from emp order by sal asc;
+--------+---------+
| ename | sal |
+--------+---------+
| SMITH | 800.00 |
| JAMES | 950.00 |
| ADAMS | 1100.00 |
| WARD | 1250.00 |
| MARTIN | 1250.00 |
| MILLER | 1300.00 |
| TURNER | 1500.00 |
| ALLEN | 1600.00 |
| CLARK | 2450.00 |
| BLAKE | 2850.00 |
| JONES | 2975.00 |
| FORD | 3000.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
+--------+---------+
14 rows in set (0.00 sec)
(2)����:desc
select ename,sal from emp order by sal desc;
+--------+---------+
| ename | sal |
+--------+---------+
| KING | 5000.00 |
| SCOTT | 3000.00 |
| FORD | 3000.00 |
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| ALLEN | 1600.00 |
| TURNER | 1500.00 |
| MILLER | 1300.00 |
| MARTIN | 1250.00 |
| WARD | 1250.00 |
| ADAMS | 1100.00 |
| JAMES | 950.00 |
| SMITH | 800.00 |
+--------+---------+
14 rows in set (0.00 sec)
(3)����ֶε�����
����:��ѯԱ�����ֺ�н��,Ҫ����н������,���н��һ���Ļ�,�ٰ��������������С�
��������:��������sal��ǰ,������,ֻ��sal��ȵ�ʱ��,�Żῼ������ename����
mysql> select ename,sal from emp order by sal asc, ename asc;
+--------+---------+
| ename | sal |
+--------+---------+
| SMITH | 800.00 |
| JAMES | 950.00 |
| ADAMS | 1100.00 |
| MARTIN | 1250.00 |
| WARD | 1250.00 |
| MILLER | 1300.00 |
| TURNER | 1500.00 |
| ALLEN | 1600.00 |
| CLARK | 2450.00 |
| BLAKE | 2850.00 |
| JONES | 2975.00 |
| FORD | 3000.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
+--------+---------+
14 rows in set (0.00 sec)
(4)���ֶ�λ������
�˽�һ��,����������������Ϊ����׳,��������˳�����ı䡣
mysql> select * from emp;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
select ename,sal from emp order by 2; //���յڶ������� ������1��ʼ
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
�ܽ�:
��������ִ��˳���������:
��һ��:from
�ڶ���:where
������:select
���IJ�:order by(�������������ִ��!)
2.4 ���������
�����ݴ�����������Ȼ���ж��д�������
���д����������ص�:һ�������Ӧһ�����
���д����������ص�:��������Ӧһ�����
(1)lower() :ת����Сд
select lower(ename) as ename from emp;
+--------+
| ename |
+--------+
| smith |
| allen |
| ward |
| jones |
| martin |
| blake |
| clark |
| scott |
| king |
| turner |
| adams |
| james |
| ford |
| miller |
+--------+
14 rows in set (0.00 sec)
(2)upper(): ת���ɴ�д
select upper(ename) as ename from emp;
(3)substr()
ע��:��ʼ������1��ʼ
mysql> select substr(ename,1,1) as ename from emp;
+-------+
| ename |
+-------+
| S |
| A |
| W |
| J |
| M |
| B |
| C |
| S |
| K |
| T |
| A |
| J |
| F |
| M |
+-------+
14 rows in set (0.01 sec)
����:��ѡ����ĸΪA������
mysql> select ename from emp where ename like 'A%';
mysql> select ename from emp where substr(ename,1,1)='A'; //���书��һ��
+-------+
| ename |
+-------+
| ALLEN |
| ADAMS |
+-------+
2 rows in set (0.00 sec)
(4)length():��
����:��ȡ���ֵij���
mysql> select ename, length(ename) enameLength from emp;
+--------+-------------+
| ename | enameLength |
+--------+-------------+
| SMITH | 5 |
| ALLEN | 5 |
| WARD | 4 |
| JONES | 5 |
| MARTIN | 6 |
| BLAKE | 5 |
| CLARK | 5 |
| SCOTT | 5 |
| KING | 4 |
| TURNER | 6 |
| ADAMS | 5 |
| JAMES | 5 |
| FORD | 4 |
| MILLER | 6 |
+--------+-------------+
14 rows in set (0.01 sec)
(5)concat():�ַ���ƴ��
����:��empno�ֶκ�ename�ֶ�ƴ������
mysql> select concat(empno,ename) from emp;
+---------------------+
| concat(empno,ename) |
+---------------------+
| 7369SMITH |
| 7499ALLEN |
| 7521WARD |
| 7566JONES |
| 7654MARTIN |
| 7698BLAKE |
| 7782CLARK |
| 7788SCOTT |
| 7839KING |
| 7844TURNER |
| 7876ADAMS |
| 7900JAMES |
| 7902FORD |
| 7934MILLER |
+---------------------+
14 rows in set (0.00 sec)
(6)trim():ȥ�ո�
mysql> select * from emp where ename=' KING';
Empty set (0.00 sec)
mysql> select * from emp where ename=trim(' KING');
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
+-------+-------+-----------+------+------------+---------+------+--------+
1 row in set (0.00 sec)
(7)case��when��then��when��then��else��end
����:��Ա���Ĺ�����λ��MANAGER��ʱ��,�����ϵ�10%,��������λ��SALESMAN��ʱ��,�����ϵ�50%,����������
mysql> select ename,job,sal oldsal, (case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal from emp;
+--------+-----------+---------+---------+
| ename | job | oldsal | newsal |
+--------+-----------+---------+---------+
| SMITH | CLERK | 800.00 | 800.00 |
| ALLEN | SALESMAN | 1600.00 | 2400.00 |
| WARD | SALESMAN | 1250.00 | 1875.00 |
| JONES | MANAGER | 2975.00 | 3272.50 |
| MARTIN | SALESMAN | 1250.00 | 1875.00 |
| BLAKE | MANAGER | 2850.00 | 3135.00 |
| CLARK | MANAGER | 2450.00 | 2695.00 |
| SCOTT | ANALYST | 3000.00 | 3000.00 |
| KING | PRESIDENT | 5000.00 | 5000.00 |
| TURNER | SALESMAN | 1500.00 | 2250.00 |
| ADAMS | CLERK | 1100.00 | 1100.00 |
| JAMES | CLERK | 950.00 | 950.00 |
| FORD | ANALYST | 3000.00 | 3000.00 |
| MILLER | CLERK | 1300.00 | 1300.00 |
+--------+-----------+---------+---------+
14 rows in set (0.00 sec)
ע��:����ֵ����Ҳ���Ը�����ֵ:
select ��abc�� from emp;
mysql> select 100 from emp;
+-----+
| 100 |
+-----+
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
+-----+
14 rows in set (0.00 sec)
mysql> select 'abc' from emp;
+-----+
| abc |
+-----+
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
| abc |
+-----+
14 rows in set (0.00 sec)
(8)round() �������뱣��С��
����:��������
mysql> select round(123.456, 0) as result from emp limit 5; //��������
+--------+
| result |
+--------+
| 123 |
| 123 |
| 123 |
| 123 |
| 123 |
+--------+
5 rows in set (0.00 sec)
mysql> select round(123.456, 1) as result from emp limit 5; //�������뱣��һλС��
+--------+
| result |
+--------+
| 123.5 |
| 123.5 |
| 123.5 |
| 123.5 |
| 123.5 |
+--------+
5 rows in set (0.00 sec)
mysql> select round(123.456, 2) as result from emp limit 5;
+--------+
| result |
+--------+
| 123.46 |
| 123.46 |
| 123.46 |
| 123.46 |
| 123.46 |
+--------+
5 rows in set (0.00 sec)
mysql> select round(123.456, -2) as result from emp limit 5; //�������ٷ�λ
+--------+
| result |
+--------+
| 100 |
| 100 |
| 100 |
| 100 |
| 100 |
+--------+
5 rows in set (0.00 sec)
(9)rand() ���������
����:����1���ڵ������
mysql> select rand() from emp limit 5;
+----------------------+
| rand() |
+----------------------+
| 0.3314896806436495 |
| 0.41996393764388185 |
| 0.10535067702210571 |
| 0.2668616029125281 |
| 0.018256014229968205 |
+----------------------+
5 rows in set (0.00 sec)
����:����100���ڵ������,round��rand���ʹ��
mysql> select round(rand()*100,0) from emp limit 10;
+---------------------+
| round(rand()*100,0) |
+---------------------+
| 22 |
| 4 |
| 55 |
| 61 |
| 40 |
| 18 |
| 68 |
| 85 |
| 22 |
| 57 |
+---------------------+
10 rows in set (0.00 sec)
(10)ifnull():���Խ� null ת����һ������ֵ
ifnull�ǿմ���������ר�Ŵ����յġ�
���������ݿ��,ֻҪ��NULL�������ѧ����,���ս������NULL��
mysql> select * from emp;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
mysql> select ename,sal+comm as salcomm from emp;
+--------+---------+
| ename | salcomm |
+--------+---------+
| SMITH | NULL |
| ALLEN | 1900.00 |
| WARD | 1750.00 |
| JONES | NULL |
| MARTIN | 2650.00 |
| BLAKE | NULL |
| CLARK | NULL |
| SCOTT | NULL |
| KING | NULL |
| TURNER | 1500.00 |
| ADAMS | NULL |
| JAMES | NULL |
| FORD | NULL |
| MILLER | NULL |
+--------+---------+
14 rows in set (0.00 sec)
ע��:NULLֻҪ��������,���ս��һ����NULL��Ϊ�˱����������,��Ҫʹ��ifnull������
(11)ifnull()����
ifnull�����÷�:ifnull(����, NULL��������ֵ)
��:����ΪNULL��ʱ��,����������0
mysql> select ename, (sal+ ifnull(comm,0))*12 as yearsal from emp;
+--------+----------+
| ename | yearsal |
+--------+----------+
| SMITH | 9600.00 |
| ALLEN | 22800.00 |
| WARD | 21000.00 |
| JONES | 35700.00 |
| MARTIN | 31800.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| SCOTT | 36000.00 |
| KING | 60000.00 |
| TURNER | 18000.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| FORD | 36000.00 |
| MILLER | 15600.00 |
+--------+----------+
14 rows in set (0.01 sec)
2.5 ���������
�����麯��
ע��:���麯����ʹ��ʱ�����ȷ���,Ȼ������á�������ж����ݽ��з���,���ű�Ĭ��Ϊһ�顣
1. ������麯��
- count():����
- sum():���
- avg():ƽ��ֵ
- max():���ֵ
- min():��Сֵ
mysql> select min(sal) from emp;
+----------+
| min(sal) |
+----------+
| 800.00 |
+----------+
1 row in set (0.00 sec)
mysql> select sum(sal) from emp;
+----------+
| sum(sal) |
+----------+
| 29025.00 |
+----------+
1 row in set (0.00 sec)
mysql> select count(sal) from emp;
+------------+
| count(sal) |
+------------+
| 14 |
+------------+
1 row in set (0.00 sec)
2. ʹ��ʱע������
��һ��:���麯���Զ�����NULL,����Ҫ��ǰ��NULL���д�����
����:��sumʱ�����NULL�ӽ�ȥ��
�ڶ���:���麯����count(*)��count(�����ֶ�)��ʲô����?
mysql> select count(*) from emp;
+----------+
| count(*) |
+----------+
| 14 |
+----------+
1 row in set (0.00 sec)
mysql> select count(comm) from emp;
+-------------+
| count(comm) |
+-------------+
| 4 |
+-------------+
1 row in set (0.00 sec)
count(�����ֶ�):��ʾͳ�Ƹ��ֶ������в�ΪNULL��Ԫ�ص�������
count(*):ͳ�Ʊ����е���������
������:���麯�����ܹ�ֱ��ʹ����where�Ӿ���
��:�ҳ�������ʸߵ�Ա����Ϣ
mysql> select ename,sal from emp where sal>min(sal);
ERROR 1111 (HY000): Invalid use of group function
���ĵ�:���еķ��麯�������������һ����
mysql> select sum(sal),max(sal),min(sal),avg(sal),count(*) from emp;
+----------+----------+----------+-------------+----------+
| sum(sal) | max(sal) | min(sal) | avg(sal) | count(*) |
+----------+----------+----------+-------------+----------+
| 29025.00 | 5000.00 | 800.00 | 2073.214286 | 14 |
+----------+----------+----------+-------------+----------+
1 row in set (0.00 sec)
2.6 �����ѯ:group by
ʲô�Ƿ����ѯ?
��ʵ�ʵ�Ӧ����,����������������,��Ҫ�Ƚ��з���,Ȼ���ÿһ������ݽ��в�����
��:
����ÿ�����ŵĹ��ʺ�
����ÿ��������λ��ƽ��н��
�ҳ�ÿ��������λ�����н��
���ʱ��������Ҫʹ�÷����ѯ,��ô���з����ѯ��?
�ؼ��ֵ�ִ��˳��
select
...
from
...
where
...
group by
...
order by
...
����:select�����,�����group by���,select����ֻ�ܸ��μӷ�����ֶ�,�Լ����麯��,������һ�ɲ��ܸ���
��:�ҳ�ÿ��������λ�Ĺ��ʺ�
mysql> select job, sum(sal) from emp group by job order by sal;
+-----------+----------+
| job | sum(sal) |
+-----------+----------+
| CLERK | 4150.00 |
| SALESMAN | 5600.00 |
| MANAGER | 8275.00 |
| ANALYST | 6000.00 |
| PRESIDENT | 5000.00 |
+-----------+----------+
5 rows in set (0.00 sec)
mysql> select job, sum(sal) from emp group by job order by sum(sal);
+-----------+----------+
| job | sum(sal) |
+-----------+----------+
| CLERK | 4150.00 |
| PRESIDENT | 5000.00 |
| SALESMAN | 5600.00 |
| ANALYST | 6000.00 |
| MANAGER | 8275.00 |
+-----------+----------+
5 rows in set (0.00 sec)
��:�ҳ�ÿ�����ŵ����н��
mysql> select * from emp;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
mysql> select * from emp order by deptno;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
mysql> select deptno,max(sal) from emp group by deptno;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
| 20 | 3000.00 |
| 30 | 2850.00 |
+--------+----------+
3 rows in set (0.00 sec)
ʵ��:�ҳ���ÿ������,��ͬ������λ�������н��
mysql> select deptno,job,max(sal) from emp group by deptno,job;
+--------+-----------+----------+
| deptno | job | max(sal) |
+--------+-----------+----------+
| 10 | CLERK | 1300.00 |
| 10 | MANAGER | 2450.00 |
| 10 | PRESIDENT | 5000.00 |
| 20 | ANALYST | 3000.00 |
| 20 | CLERK | 1100.00 |
| 20 | MANAGER | 2975.00 |
| 30 | CLERK | 950.00 |
| 30 | MANAGER | 2850.00 |
| 30 | SALESMAN | 1600.00 |
+--------+-----------+----------+
9 rows in set (0.00 sec)
1. having
having���ԶԷ�����֮������ݽ�һ������;having�����group by����ʹ�á�
having���ܵ���ʹ��,having���ܴ���where
�Ż�����:where��having,����ѡ��where,whereʵ����ɲ�����,��ѡ��having��
ʵ��:�ҳ�ÿ���������н��,Ҫ����ʾ���н�ʴ���3000��
mysql> select deptno,max(sal) from emp group by deptno;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
| 20 | 3000.00 |
| 30 | 2850.00 |
+--------+----------+
3 rows in set (0.00 sec)
mysql> select deptno,max(sal) from emp where sal >3000 group by deptno;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
mysql> select deptno,max(sal) from emp group by deptno having max(sal)>3000;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
��ʹ�õ�where�����:�ҳ�ÿ������ƽ��н��,Ҫ����ʾƽ��н�ʸ���2500�ġ�
mysql> select deptno,avg(sal) from emp group by deptno;
+--------+-------------+
| deptno | avg(sal) |
+--------+-------------+
| 10 | 2916.666667 |
| 20 | 2175.000000 |
| 30 | 1566.666667 |
+--------+-------------+
3 rows in set (0.00 sec)
mysql> select deptno,avg(sal) from emp group by deptno having avg(sal)>2500;
+--------+-------------+
| deptno | avg(sal) |
+--------+-------------+
| 10 | 2916.666667 |
+--------+-------------+
1 row in set (0.00 sec)
2. �ܽ�
select
...
from
...
where
...
group by
...
having
...
order by
...
ִ��˳��?
- from
- where
- group by
- having
- select
- order by
ʵ��:�ҳ�ÿ����λ��ƽ��н��,Ҫ����ʾƽ��н�ʴ���1500��,��MANAGER��λ֮��,Ҫ����ƽ��н�ʽ����š�
mysql> select job,avg(sal) from emp where job <> 'MANAGER' group by job having avg(sal) >1500 order by avg(sal) desc;
mysql> select job,avg(sal) from emp where job not in ('MANAGER') group by job having avg(sal) >1500 order by avg(sal) desc;
mysql> select job,avg(sal) from emp where job != 'MANAGER' group by job having avg(sal)>1500 order by avg(sal) desc; //���书��һ��
+-----------+-------------+
| job | avg(sal) |
+-----------+-------------+
| PRESIDENT | 5000.000000 |
| ANALYST | 3000.000000 |
+-----------+-------------+
3. ȥ��distinct
ע��:ԭ�����ݲ��ᱻ��,ֻ�Dz�ѯ���ȥ��
mysql> select job from emp;
+-----------+
| job |
+-----------+
| CLERK |
| SALESMAN |
| SALESMAN |
| MANAGER |
| SALESMAN |
| MANAGER |
| MANAGER |
| ANALYST |
| PRESIDENT |
| SALESMAN |
| CLERK |
| CLERK |
| ANALYST |
| CLERK |
+-----------+
14 rows in set (0.00 sec)
mysql> select distinct job from emp;
+-----------+
| job |
+-----------+
| CLERK |
| SALESMAN |
| MANAGER |
| ANALYST |
| PRESIDENT |
+-----------+
5 rows in set (0.00 sec)
������д�Ǵ����,�����:select ename, distinct job from emp;
ע��:distinctֻ�ܳ����������ֶε���ǰ��
��:distinct������job,deptno�����ֶ�֮ǰ,��ʾ�����ֶ���������ȥ��
mysql> select job, deptno from emp;
+-----------+--------+
| job | deptno |
+-----------+--------+
| CLERK | 20 |
| SALESMAN | 30 |
| SALESMAN | 30 |
| MANAGER | 20 |
| SALESMAN | 30 |
| MANAGER | 30 |
| MANAGER | 10 |
| ANALYST | 20 |
| PRESIDENT | 10 |
| SALESMAN | 30 |
| CLERK | 20 |
| CLERK | 30 |
| ANALYST | 20 |
| CLERK | 10 |
+-----------+--------+
14 rows in set (0.00 sec)
mysql> select distinct job, deptno from emp;
+-----------+--------+
| job | deptno |
+-----------+--------+
| CLERK | 20 |
| SALESMAN | 30 |
| MANAGER | 20 |
| MANAGER | 30 |
| MANAGER | 10 |
| ANALYST | 20 |
| PRESIDENT | 10 |
| CLERK | 30 |
| CLERK | 10 |
+-----------+--------+
9 rows in set (0.00 sec)
��:ȥ���ظ�֮��ͳ��һ�¹�����λ������
mysql> select count(distinct job) from emp;
+---------------------+
| count(distinct job) |
+---------------------+
| 5 |
+---------------------+
1 row in set (0.01 sec)
2.7 ���Ӳ�ѯ
1. ���Ӳ�ѯ���
(1)ʲô�����Ӳ�ѯ
��һ�ű��е�����ѯ,��Ϊ������ѯ��
emp����dept������������ѯ����,��emp����ȡԱ������,��dept����ȡ��������;���ֿ����ѯ,���ű�����������ѯ����,����Ϊ���Ӳ�ѯ��
(2)���Ӳ�ѯ�ķ���
���������ķ���:
SQL92:1992���ʱ����ֵ��
SQL99:1999���ʱ����ֵ��
���������ص�ѧϰSQL99.(��������м���ʾһ��SQL92������)
���ݱ����ӵķ�ʽ����:
������:��ֵ���ӡ��ǵ�ֵ���ӡ�������
������:��������(������)����������(������)��ȫ����(����)
(3)�����ű��������Ӳ�ѯʱ,û���κ����������ƻᷢ��ʲô����?
����:��ѯÿ��Ա�����ڲ�������?
mysql> select ename,deptno from emp;
+--------+--------+
| ename | deptno |
+--------+--------+
| SMITH | 20 |
| ALLEN | 30 |
| WARD | 30 |
| JONES | 20 |
| MARTIN | 30 |
| BLAKE | 30 |
| CLARK | 10 |
| SCOTT | 20 |
| KING | 10 |
| TURNER | 30 |
| ADAMS | 20 |
| JAMES | 30 |
| FORD | 20 |
| MILLER | 10 |
+--------+--------+
14 rows in set (0.00 sec)
mysql> select * from dept;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> select ename, dname from emp,dept;
+--------+------------+
| ename | dname |
+--------+------------+
| SMITH | ACCOUNTING |
| SMITH | RESEARCH |
| SMITH | SALES |
| SMITH | OPERATIONS |
| ALLEN | ACCOUNTING |
| ALLEN | RESEARCH |
| ALLEN | SALES |
| ALLEN | OPERATIONS |
| WARD | ACCOUNTING |
| WARD | RESEARCH |
| WARD | SALES |
| WARD | OPERATIONS |
| JONES | ACCOUNTING |
| JONES | RESEARCH |
| JONES | SALES |
| JONES | OPERATIONS |
| MARTIN | ACCOUNTING |
| MARTIN | RESEARCH |
| MARTIN | SALES |
| MARTIN | OPERATIONS |
| BLAKE | ACCOUNTING |
| BLAKE | RESEARCH |
| BLAKE | SALES |
| BLAKE | OPERATIONS |
| CLARK | ACCOUNTING |
| CLARK | RESEARCH |
| CLARK | SALES |
| CLARK | OPERATIONS |
| SCOTT | ACCOUNTING |
| SCOTT | RESEARCH |
| SCOTT | SALES |
| SCOTT | OPERATIONS |
| KING | ACCOUNTING |
| KING | RESEARCH |
| KING | SALES |
| KING | OPERATIONS |
| TURNER | ACCOUNTING |
| TURNER | RESEARCH |
| TURNER | SALES |
| TURNER | OPERATIONS |
| ADAMS | ACCOUNTING |
| ADAMS | RESEARCH |
| ADAMS | SALES |
| ADAMS | OPERATIONS |
| JAMES | ACCOUNTING |
| JAMES | RESEARCH |
| JAMES | SALES |
| JAMES | OPERATIONS |
| FORD | ACCOUNTING |
| FORD | RESEARCH |
| FORD | SALES |
| FORD | OPERATIONS |
| MILLER | ACCOUNTING |
| MILLER | RESEARCH |
| MILLER | SALES |
| MILLER | OPERATIONS |
+--------+------------+
56 rows in set (0.00 sec)
���ղ�ѯ�������,�����ű������ij˻�,��������Ϊ:�ѿ�����������
(4)��ô����ѿ���������
����ʱ������,������������ļ�¼��ɸѡ����
select
ename, dname
from
emp, dept
where
emp.deptno = dept.deptno;
����
select
emp.ename, dept.dname
from
emp, dept
where
emp.deptno = dept.deptno;
��������:
mysql> select emp.ename, dept.dname from emp, dept where emp.deptno = dept.deptno;
mysql> select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno; //�������һ��
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.01 sec)
˼��:���ղ�ѯ�Ľ��������14��,����ƥ��Ĺ�����,ƥ��Ĵ�����������?
����56��,ֻ������������ѡһ������û�м��١�
ע��:�������Ӵ���Խ��Ч��Խ��,���Ծ�������������Ӵ�����
2. ������:inner
(1)������֮��ֵ����
����:��ѯÿ��Ա�����ڲ�������,��ʾԱ�����Ͳ�����
SQL92�:
select
e.ename,d.dname
from
emp e, dept d
where
e.deptno = d.deptno;
sql92��ȱ��:�ṹ������,������������,�ͺ��ڽ�һ��ɸѡ������,���ŵ���where���档
SQL99�:
inner����ʡ��(����inner�ɶ��Ը���)
mysql> select
-> e.ename,d.dname
-> from
-> emp e
-> inner join //inner����ʡ��
-> dept d
-> on
-> e.deptno = d.deptno; // �����ǵ�����ϵ,���Ա���Ϊ��ֵ���ӡ�
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.00 sec)
sql99�ŵ�:�����ӵ������Ƕ�����,����֮��,�������Ҫ��һ��ɸѡ,�������������where
select
...
from
a
join
b
on
a��b����������
where
ɸѡ����
(2)�ǵ�ֵ����
����:�ҳ�ÿ��Ա����н�ʵȼ�,Ҫ����ʾԱ������н�ʡ�н�ʵȼ�
select
e.ename, e.sal, s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal; // ��������һ��������ϵ,��Ϊ�ǵ�ֵ���ӡ�
mysql> select e.ename, e.sal, s.grade from emp e join salgrade s
-> on e.sal between s.losal and s.hisal;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+
14 rows in set (0.00 sec)
(3)������֮������
ʵ��:��ѯԱ�����ϼ��쵼,Ҫ����ʾԱ�����Ͷ�Ӧ���쵼��
mysql> select empno, ename, mgr from emp limit 5;
+-------+--------+------+
| empno | ename | mgr |
+-------+--------+------+
| 7369 | SMITH | 7902 |
| 7499 | ALLEN | 7698 |
| 7521 | WARD | 7698 |
| 7566 | JONES | 7839 |
| 7654 | MARTIN | 7698 |
+-------+--------+------+
5 rows in set (0.00 sec)
mysql> select a.ename as 'Ա����', b.ename as '�쵼��' from emp a join emp b on a.mgr = b.empno;
+--------+--------+
| Ա���� | �쵼�� |
+--------+--------+
| SMITH | FORD |
| ALLEN | BLAKE |
| WARD | BLAKE |
| JONES | KING |
| MARTIN | BLAKE |
| BLAKE | KING |
| CLARK | KING |
| SCOTT | JONES |
| TURNER | BLAKE |
| ADAMS | SCOTT |
| JAMES | BLAKE |
| FORD | JONES |
| MILLER | CLARK |
+--------+--------+
13 rows in set (0.00 sec)
���Ͼ����������е�:������,����:һ�ű��������ű���
13����¼û��KING,��ΪKINGû���쵼
3. ������
�����ӵ��ص�:����ܹ�ƥ����������������ݲ�ѯ������
mysql> select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.00 sec)
mysql> select e.ename,d.dname from emp e right join dept d on e.deptno = d.deptno;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
| NULL | OPERATIONS |
+--------+------------+
15 rows in set (0.00 sec)
right����ʲô:��ʾ��join�ؼ����ұߵ����ű���������,��Ҫ��Ϊ�˽����ű�������ȫ����ѯ����,�Ӵ��Ź�����ѯ��ߵı����������ӵ���,���ű�����,���������ι�ϵ��
(1)(��������)
outer�ǿ���ʡ�Ե�,���ſɶ���ǿ�����������ӻ��������ӵ�outer������ʡ��
select
e.ename,d.dname
from
dept d
left outer join //outer����ʡ��
emp e
on
e.deptno = d.deptno;
ע��:
- ����right������������,�ֽ��������ӡ�
- ����left������������,�ֽ��������ӡ�
- �κ�һ�������Ӷ��������ӵ�д����
- �κ�һ�������Ӷ��������ӵ�д����
˼��:�����ӵIJ�ѯ�������һ���� >= �����ӵIJ�ѯ�����������? ��ȷ
ʵ��:��ѯÿ��Ա�����ϼ��쵼,Ҫ����ʾ����Ա�������ֺ��쵼��
mysql> select a.ename, b.ename from emp a left join emp b on a.mgr=b.empno;
+--------+-------+
| ename | ename |
+--------+-------+
| SMITH | FORD |
| ALLEN | BLAKE |
| WARD | BLAKE |
| JONES | KING |
| MARTIN | BLAKE |
| BLAKE | KING |
| CLARK | KING |
| SCOTT | JONES |
| KING | NULL |
| TURNER | BLAKE |
| ADAMS | SCOTT |
| JAMES | BLAKE |
| FORD | JONES |
| MILLER | CLARK |
+--------+-------+
14 rows in set (0.00 sec)
4. ���ű�����
select
...
from
a
join
b
on
a��b����������
join
c
on
a��c����������
right join
d
on
a��d����������
һ��SQL�������Ӻ������ӿ��Ի�ϡ������Գ���!
����:�ҳ�ÿ��Ա���IJ��������Լ����ʵȼ�,Ҫ����ʾԱ��������������н�ʡ�н�ʵȼ�
mysql> select * from emp;
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
mysql> select * from salgrade;
+-------+-------+-------+
| GRADE | LOSAL | HISAL |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
mysql> select * from dept;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
mysql> select e.ename, e.sal, d.dname, s.grade
-> from emp e join dept d on e.deptno=d.deptno
-> join salgrade s on e.sal between s.losal and s.hisal;
+--------+---------+------------+-------+
| ename | sal | dname | grade |
+--------+---------+------------+-------+
| SMITH | 800.00 | RESEARCH | 1 |
| ALLEN | 1600.00 | SALES | 3 |
| WARD | 1250.00 | SALES | 2 |
| JONES | 2975.00 | RESEARCH | 4 |
| MARTIN | 1250.00 | SALES | 2 |
| BLAKE | 2850.00 | SALES | 4 |
| CLARK | 2450.00 | ACCOUNTING | 4 |
| SCOTT | 3000.00 | RESEARCH | 4 |
| KING | 5000.00 | ACCOUNTING | 5 |
| TURNER | 1500.00 | SALES | 3 |
| ADAMS | 1100.00 | RESEARCH | 1 |
| JAMES | 950.00 | SALES | 1 |
| FORD | 3000.00 | RESEARCH | 4 |
| MILLER | 1300.00 | ACCOUNTING | 2 |
+--------+---------+------------+-------+
14 rows in set (0.00 sec)
5. �Ӳ�ѯ
select�����Ƕ��select���,��Ƕ��select����Ϊ�Ӳ�ѯ��
�Ӳ�ѯ�����Գ�����������?
select
..(select).
from
..(select).
where
..(select).
(1)where�Ӿ��е��Ӳ�ѯ
����:�ҳ�������ʸߵ�Ա����������
mysql> select ename,sal from emp where sal>min(sal);
ERROR 1111 (HY000): Invalid use of group function
����ԭ��:where�Ӿ��в���ֱ��ʹ�÷��麯����
ʵ��˼·:
��һ��:��ѯ������Ƕ���
mysql> select ename, min(sal) from emp;
+-------+----------+
| ename | min(sal) |
+-------+----------+
| SMITH | 800.00 |
+-------+----------+
1 row in set (0.00 sec)
�ڶ���:�ҳ�����800��
mysql> select sal from emp where sal > 800;
+---------+
| sal |
+---------+
| 1600.00 |
| 1250.00 |
| 2975.00 |
| 1250.00 |
| 2850.00 |
| 2450.00 |
| 3000.00 |
| 5000.00 |
| 1500.00 |
| 1100.00 |
| 950.00 |
| 3000.00 |
| 1300.00 |
+---------+
�������ϲ�:
mysql> select ename,sal from emp where sal>(select min(sal) from emp);
+--------+---------+
| ename | sal |
+--------+---------+
| ALLEN | 1600.00 |
| WARD | 1250.00 |
| JONES | 2975.00 |
| MARTIN | 1250.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| TURNER | 1500.00 |
| ADAMS | 1100.00 |
| JAMES | 950.00 |
| FORD | 3000.00 |
| MILLER | 1300.00 |
+--------+---------+
13 rows in set (0.00 sec)
(2)from�Ӿ��е��Ӳ�ѯ
ע��:from������Ӳ�ѯ,���Խ��Ӳ�ѯ�IJ�ѯ�������һ����ʱ����(����)
����:�ҳ�ÿ����λ��ƽ�����ʵ�н�ʵȼ���
mysql> select * from salgrade;
+-------+-------+-------+
| GRADE | LOSAL | HISAL |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
5 rows in set (0.00 sec)
��һ��:�ҳ�ÿ��������λ��ƽ������
mysql> select avg(sal) from emp group by job;
+-------------+
| avg(sal) |
+-------------+
| 3000.000000 |
| 1037.500000 |
| 2758.333333 |
| 5000.000000 |
| 1400.000000 |
+-------------+
5 rows in set (0.00 sec)
�ڶ���:�˷������ϰ�,�����ϵIJ�ѯ����͵���һ����ʵ���ڵı�t��
mysql> select t.*, s.grade from t join salgrade s on t.avg(sal) between s.losal and s.hisal;
ERROR 1146 (42S02): Table 'bjpowernode.t' doesn't exist
mysql> select t.*, s.grade
-> from (select job,avg(sal) as avgsal from emp group by job) t
-> join salgrade s
-> on t.avgsal between s.losal and s.hisal;
+-----------+-------------+-------+
| job | avgsal | grade |
+-----------+-------------+-------+
| CLERK | 1037.500000 | 1 |
| SALESMAN | 1400.000000 | 2 |
| ANALYST | 3000.000000 | 4 |
| MANAGER | 2758.333333 | 4 |
| PRESIDENT | 5000.000000 | 5 |
+-----------+-------------+-------+
5 rows in set (0.00 sec)
(3)select������ֵ��Ӳ�ѯ(������ݲ���Ҫ����,�˽⼴��!!!)
ʵ��:�ҳ�ÿ��Ա���IJ�������,Ҫ����ʾԱ����,������
mysql> select e.ename, (select d.dname from dept d where e.deptno=d.deptno) as dname from emp e;
+--------+------------+
| ename | dname |
+--------+------------+
| SMITH | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| JONES | RESEARCH |
| MARTIN | SALES |
| BLAKE | SALES |
| CLARK | ACCOUNTING |
| SCOTT | RESEARCH |
| KING | ACCOUNTING |
| TURNER | SALES |
| ADAMS | RESEARCH |
| JAMES | SALES |
| FORD | RESEARCH |
| MILLER | ACCOUNTING |
+--------+------------+
14 rows in set (0.00 sec)
6. �ϲ���ѯ:union
����:��ѯ������λ��MANAGER��SALESMAN��Ա��
mysql> select ename, job from emp where job='MANAGER' or job='SALESMAN';
mysql> select ename,job from emp where job in ('MANAGER', 'SALESMAN');
mysql> select ename, job from emp where job='MANAGER'
-> union
-> select ename, job from emp where job='SALESMAN'; //���������һ��
+--------+----------+
| ename | job |
+--------+----------+
| ALLEN | SALESMAN |
| WARD | SALESMAN |
| JONES | MANAGER |
| MARTIN | SALESMAN |
| BLAKE | MANAGER |
| CLARK | MANAGER |
| TURNER | SALESMAN |
+--------+----------+
7 rows in set (0.01 sec)
union��Ч��Ҫ��һЩ�����ڱ�������˵,ÿ����һ���±�,��ƥ��Ĵ�������ѿ�����,�ɱ��ķ���
����union���Լ���ƥ��Ĵ������ڼ���ƥ������������,��������������������ƴ�ӡ�
����:
a ���� b ���� c
a 10����¼
b 10����¼
c 10����¼
ƥ�������:1000
a ���� bһ�����:10 * 10 --> 100��
a ���� cһ�����:10 * 10 --> 100��
ʹ��union�Ļ���:100�� + 100�� = 200�Ρ�(union�ѳ˷�����˼ӷ�����)
ע������:
����:union�ڽ��н�����ϲ���ʱ��,Ҫ�������������������ͬ��
select ename,job from emp where job = 'MANAGER'
union
select ename from emp where job = 'SALESMAN';
ERROR 1222 (21000): The used SELECT statements have a different number of columns
MYSQL����,oracle��ϸ� ,������,������ Ҫ��:������ϲ�ʱ�к��е���������ҲҪһ�¡�
mysql> select ename,job from emp where job = 'MANAGER'
-> union
-> select ename,sal from emp where job = 'SALESMAN';
+--------+---------+
| ename | job |
+--------+---------+
| JONES | MANAGER |
| BLAKE | MANAGER |
| CLARK | MANAGER |
| ALLEN | 1600 |
| WARD | 1250 |
| MARTIN | 1250 |
| TURNER | 1500 |
+--------+---------+
7. ��ҳ����:limit
����:��ʾ���ֲ�ѯ���,ͨ��ʹ���ڷ�ҳ��ѯ���С�
�����÷�:limit startIndex, length
ʵ��:����н�ʽ���,ȡ��������ǰ5����Ա��
mysql> select ename,sal from emp order by sal desc limit 5;
mysql> select ename,sal from emp order by sal desc limit 0,5; //��һ������Ϊ��ʼ����,Ĭ�ϴ�0��ʼ �ڶ�������Ϊ����
+-------+---------+
| ename | sal |
+-------+---------+
| KING | 5000.00 |
| SCOTT | 3000.00 |
| FORD | 3000.00 |
| JONES | 2975.00 |
| BLAKE | 2850.00 |
+-------+---------+
5 rows in set (0.01 sec)
ע��:mysql����limit��order by֮��ִ��!
ʵ��:ȡ������������[3-5]����Ա��
mysql> select ename,sal from emp order by sal desc limit 2,3; //�±�2��ʼ,����Ϊ3
+-------+---------+
| ename | sal |
+-------+---------+
| FORD | 3000.00 |
| JONES | 2975.00 |
| BLAKE | 2850.00 |
+-------+---------+
3 rows in set (0.00 sec)
��ҳ
ÿҳ��ʾ3����¼
��1ҳ:limit 0,3
��2ҳ:limit 3,3
��3ҳ:limit 6,3
��4ҳ:limit 9,3
��pageNoҳ:limit (pageNo - 1) * pageSize , pageSize
2.8 DQL�����ܽ�
select
...
from
...
where
...
group by
...
having
...
order by
...
limit
...
��3�� DDL����:���ݶ�������
DDL:���ݶ�������:create(��)��drop(ɾ)��alter(��)��truncate����Ҫ�ǶԱ��ṹ���в�����
3.1 MySQL����������
| ���� | ���� |
|---|---|
| varchar | �ɱ䳤���ַ�������,����ʵ�ʳ��ȶ�߯����ռ䡣�ŵ�:��ʡ�ռ䡣ȱ��:��Ҫ��̬����ռ�,�ٶ������255 |
| char | �����ַ�������, ����ʵ�ʵ����ݳ����Ƕ���,����̶����ȵĿռ�ȥ�洢���ݡ���ȱ���������෴���255 |
| int | ���͡���ͬ��java��int���11 |
| bigint | �����͡���ͬ��java�е�long�� |
| float | �����ȸ����� |
| double | ˫���ȸ����� |
| date | ���������� |
| datetime | ���������� |
| clob | Character Large OBject:CLOB���ַ������, ���洢4G���ַ����� ����255���ַ��IJ���CLOB�洢�� ����:�洢һƪ����,һƪ˵���� |
| blob | Binary Large OBject; �����ƴ����, �����洢ͼƬ����������Ƶ����ý�����ݡ� BLOB�����ֶ��ϲ�������ʱ,��Ҫʹ��IO���� |
varchar��char����Ӧ����ôѡ��?
�Ա��ֶ�ѡ:�Ա��ǹ̶������ַ���,ѡ��char��
�����ֶ�ѡ:ÿ�������ֳ��Ȳ�ͬ,ѡ��varchar��
����:t_movie ��Ӱ��,�洢��Ӱ��Ϣ
��� ���� ������� ��ӳ���� ʱ�� ���� ����
no(bigint) name(varchar) history(clob) playtime(date) time(double) image(blob) type(char)
------------------------------------------------------------------------------------------------------------------
10000 ��߸ .......... 2019-10-11 2.5 .... '1'
10001 ��մ� .......... 2019-11-11 1.5 .... '2'
....
3.2 ���Ĵ���:create
���������ʽ:create table ����(�ֶ���1 ��������, �ֶ���2 ��������, �ֶ���3 ��������);
create table ����(
�ֶ���1 ��������,
�ֶ���2 ��������,
�ֶ���3 ��������
);
����:������t_ ���� tbl_��ʼ,�ɶ���ǿ������֪�⡣
�ֶ���:����֪�⡣
�������ֶ��������ڱ�ʶ����
3.3 ����ɾ��:drop
drop table t_student; //ע��:�����ű������ڵ�ʱ��ᱨ��!
drop table if exists t_student; //���䶼����,�Ƽ����
ʵ��:����һ��ѧ����,ѧ�š����������䡢�Ա������ַ
mysql> create table t_student(
-> no int,
-> name varchar(32),
-> sex char(1),
-> age int(3),
-> email varchar(255)
-> );
Query OK, 0 rows affected (0.01 sec)
3.4 ���ٴ�����
�˽�����, ����ѯ�������һ�ű��½�,ʵ�ֱ������ݵĿ��ٸ���
mysql> create table emp2 as select * from emp; //���ű�������һģһ��
Query OK, 14 rows affected (0.01 sec)
Records: 14 Duplicates: 0 Warnings: 0
mysql> create table mytable as select empno,ename from emp where job='MANAGER';
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from mytable;
+-------+-------+
| empno | ename |
+-------+-------+
| 7566 | JONES |
| 7698 | BLAKE |
| 7782 | CLARK |
+-------+-------+
3 rows in set (0.00 sec)
3.5 ����ɾ�����е�����:truncate
delete from dept_bak; //����ɾ�����ݵķ�ʽ�Ƚ�����
deleteԭ��: �������ݱ�ɾ����,����������Ӳ���ϵ���ʵ�洢�ռ䲻�ᱻ�ͷ�!
ȱ��:ɾ��Ч�ʱȽϵ�; �ŵ�:֧�ֻع�(���ɻָ�)
�ع�ʵ��
mysql> select * from dept_bak;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from dept_bak;
Query OK, 4 rows affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from dept_bak;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
truncateԭ��:����һ�νض�,����ɾ����
ȱ��:��֧�ֻع��� �ŵ�:Ч�ʸ�,���١�
�:truncate table dept_bak;
mysql> truncate table dept_bak; //ɾ����,����ɾ��
Query OK, 0 rows affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak; //�ع�Ҳû��
Empty set (0.00 sec)
truncateɾ���ٶȺܿ�,�������ݲ��ɻָ���
ע��:truncate��ɾ�����е�����,�����ڡ�ɾ������drop
3.6 �ı��ṹ:alter
��˼:����һ���ֶ�,ɾ��һ���ֶ�,��һ���ֶ�!!!
��һ:ʵ�ʿ�����,����һ��ȷ��,��һ��������,���ٶԱ��ṹ�ġ���Ϊ�����������Ľ���ɱ��ϸ�,��Ӧ��java������Ҫ���д����ġ��������Ӧ���������Ա���е�!
�ڶ�:�����ı��ṹ��������,���Dz���Ҫ����,�����Ҫ��,����ʹ�ù���!
�ı��ṹ��������Ҫд��java������,Ҳ����java����Ա�ķ��롣
��4�� DML����:���ݲ�������
DML:���ݲ�������:insert(��)��update(ɾ)��delete(��)����Ҫ�Dz����������ݵIJ���
4.1 DML��:insert
���ʽ:insert into ����(�ֶ���1,�ֶ���2,�ֶ���3��) values(ֵ1,ֵ2,ֵ3);
ע��:�ֶ�����ֵҪһһ��Ӧ,������Ҫ��Ӧ����������Ҫ��Ӧ��
mysql> insert into t_student(no,name,sex,age,email) values(1,'zhangsan','m',20,'zhangsan@123.com');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
+------+----------+------+------+------------------+
1 row in set (0.00 sec)
mysql> insert into t_student(email,name,sex,age,no) values('lisi@123.com','lisi','m',22,2);
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
| 2 | lisi | m | 22 | lisi@123.com |
+------+----------+------+------+------------------+
2 rows in set (0.00 sec)
mysql> insert into t_student(no) values(3);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
| 2 | lisi | m | 22 | lisi@123.com |
| 3 | NULL | NULL | NULL | NULL |
+------+----------+------+------+------------------+
3 rows in set (0.00 sec)
mysql> insert into t_student(name) values('wangwu');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
| 2 | lisi | m | 22 | lisi@123.com |
| 3 | NULL | NULL | NULL | NULL |
| NULL | wangwu | NULL | NULL | NULL |
+------+----------+------+------+------------------+
4 rows in set (0.00 sec)
ע��:insert���ִ�гɹ�,��Ȼ��һ����¼����û�и��������ֶ�ֵ,Ĭ��ΪNULL��
(1)����Ĭ��ֵ:defalut
drop table if exists t_student;
create table t_student(
no int,
name varchar(32),
sex char(1) default 'm', //default����Ĭ��ֵ Ĭ���Ա�:'m'
age int(3),
email varchar(255)
);
�鿴������������
mysql> desc t_student;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| no | int(11) | YES | | NULL | |
| name | varchar(32) | YES | | NULL | |
| sex | char(1) | YES | | m | |
| age | int(3) | YES | | NULL | |
| email | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
5 rows in set (0.01 sec)
mysql> insert t_student(no) values(1);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_student;
+------+------+------+------+-------+
| no | name | sex | age | email |
+------+------+------+------+-------+
| 1 | NULL | m | NULL | NULL |
+------+------+------+------+-------+
1 row in set (0.00 sec)
mysql> insert into t_student values(2);
ERROR 1136 (21S01): Column count doesn't match value count at row 1
ע��:ǰ���ֶ���ʡ�ԵĻ�,���ڶ�д����!����ֵҲҪ��д��!
mysql> insert into t_student values(2);
ERROR 1136 (21S01): Column count doesn't match value count at row 1
mysql> insert into t_student values(2, 'lisi', 'f', 20, 'lisi@123.com');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+------+------+------+--------------+
| no | name | sex | age | email |
+------+------+------+------+--------------+
| 1 | NULL | m | NULL | NULL |
| 2 | lisi | f | 20 | lisi@123.com |
+------+------+------+------+--------------+
2 rows in set (0.00 sec)
(2)���ָ�ʽ��:format()����
��ʽ:format(����, ����ʽ��)
mysql> select ename,sal from emp limit 5;
+--------+---------+
| ename | sal |
+--------+---------+
| SMITH | 800.00 |
| ALLEN | 1600.00 |
| WARD | 1250.00 |
| JONES | 2975.00 |
| MARTIN | 1250.00 |
+--------+---------+
5 rows in set (0.00 sec)
mysql> select ename, format(sal,'$999,999') as sal from emp limit 5;
+--------+-------+
| ename | sal |
+--------+-------+
| SMITH | 800 |
| ALLEN | 1,600 |
| WARD | 1,250 |
| JONES | 2,975 |
| MARTIN | 1,250 |
+--------+-------+
5 rows in set, 5 warnings (0.00 sec)
(3)��������:str_to_date()
str_to_date:��varchar����ת����date����
date_format:��date����ת����varchar����
ע��:��ʶ��ȫ��Сд,����֮��ʹ���»��ߡ�
drop table if exists t_user; //ɾ����
create table t_user( //���´�����
id int,
name varchar(32),
birth date
);
mysql> desc t_user;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(32) | YES | | NULL | |
| birth | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
mysql> insert into t_user(id,name,birth) values(1,'zs','01-10-1990'); //��������
ERROR 1292 (22007): Incorrect date value: '01-10-1990' for column 'birth' at row 1
��������:ԭ�������Ͳ�ƥ�䡣���ݿ�birth��date����,�������һ���ַ���varchar��
����ʹ��str_to_date������������ת��,���ַ���ת������������date
���ʽ:str_to_date('�ַ�������', '���ڸ�ʽ')
mysql�����ڸ�ʽ
%Y ��
%m ��
%d ��
%h ʱ
%i ��
%s ��
mysql> insert into t_user(id,name,birth) values(1,'zs',str_to_date('01-10-1990','%d-%m-%Y'));
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_user;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| 1 | zs | 1990-10-01 |
+------+------+------------+
1 row in set (0.00 sec)
str_to_date�������ַ���varcharת��������date����,ͨ���ڲ���insertʱʹ��
ע��:������ṩ�������ַ����������ʽ:%Y-%m-%d,����ֱ�Ӳ���,str_to_date�����Ͳ���Ҫ��
mysql> insert into t_user(id,name,birth) values(2, 'lisi', '1990-10-01');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+------+------------+
| id | name | birth |
+------+------+------------+
| 1 | zs | 1990-10-01 |
| 2 | lisi | 1990-10-01 |
+------+------+------------+
2 rows in set (0.00 sec)
��ѯ��ʱ�������ij���ض������ڸ�ʽչʾ��date_format��������������ת�����ض���ʽ���ַ�����
�: date_format(������������, �����ڸ�ʽ��)
mysql> select id,name,date_format(birth,'%m/%d/%y') as birth from t_user;
+------+------+----------+
| id | name | birth |
+------+------+----------+
| 1 | zs | 10/01/90 |
| 2 | lisi | 10/01/90 |
+------+------+----------+
2 rows in set (0.00 sec)
mysql> select id,name,birth from t_user;
+------+----------+------------+
| id | name | birth |
+------+----------+------------+
| 1 | zhangsan | 1990-10-01 |
| 2 | lisi | 1990-10-01 |
+------+----------+------------+
������������Ĭ�ϸ�ʽת��,�Զ������ݿ��е�date����ת����varchar���͡�Ĭ�ϵ����ڸ�ʽ:��%Y-%m-%d��
(4)date��datetime��������
date�Ƕ�����:ֻ������������Ϣ��
datetime�dz�����:����������ʱ������Ϣ��
mysql������Ĭ�ϸ�ʽ:%Y-%m-%d
mysql������Ĭ�ϸ�ʽ:%Y-%m-%d %h:%i:%s
mysql> create table t_user( //������
-> id int,
-> name varchar(32),
-> birth date,
-> create_time datetime //����������
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_user(id,name,birth,create_time) values(1,'zhangsan','1990-10-01','2021-09-14 15:49:50');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t_user values(1,'zhangsan','1990-10-01','2021-09-14 15:49:50');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
+------+----------+------------+---------------------+
2 rows in set (0.00 sec)
(5)��ȡϵͳ��ǰʱ��:new()
now() ������ȡ��ʱ�����ʱ������Ϣ!��datetime���͡�
mysql> insert into t_user values(3,'lisi','1990-10-01',now());
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
| 3 | lisi | 1990-10-01 | 2021-11-25 15:50:02 |
+------+----------+------------+---------------------+
3 rows in set (0.00 sec)
(6)һ�β����������
�:insert into t_user(�ֶ���1,�ֶ���2) values(), (), (), ();
mysql> insert into t_user values
-> (1, 'zs', '1980-10-11', now()),
-> (2, 'ls', '1981-10-11', now()),
-> (3, 'ww', '1982-10-11', now());
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t_user;
+------+------+------------+---------------------+
| id | name | birth | create_time |
+------+------+------------+---------------------+
| 1 | zs | 1980-10-11 | 2021-11-29 20:55:54 |
| 2 | ls | 1981-10-11 | 2021-11-29 20:55:54 |
| 3 | ww | 1982-10-11 | 2021-11-29 20:55:54 |
+------+------+------------+---------------------+
3 rows in set (0.00 sec)
(7)select��ѯ��������
��insert����ѯ���Ľ���������,�����õ�(�˽�����)
drop table if exists dept_bak; //ɾ����
create table dept_bak as select * from dept; //������
mysql> select * from dept_bak;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> insert into dept_bak select * from dept;
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from dept_bak;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
8 rows in set (0.00 sec)
4.2 DML��:update
���ʽ:update ���� set �ֶ���1=ֵ1,�ֶ���2=ֵ2,�ֶ���3=ֵ3�� where ����;
ע��:û���������ƻᵼ����������ȫ�����¡�
mysql> update t_user set name = 'jack',birth = '2000-10-11' where id = 3; //��id=3������
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
| 1 | zhangsan | 1990-10-01 | 2021-09-14 15:49:50 |
| 3 | jack | 2000-10-11 | 2021-11-25 15:50:02 |
+------+----------+------------+---------------------+
mysql> update t_user set create_time = now() where id =1; //��id=1������
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
| 3 | jack | 2000-10-11 | 2021-11-25 15:50:02 |
+------+----------+------------+---------------------+
3 rows in set (0.00 sec)
4.3 DMLɾ:delete
���ʽ: delete from ���� where ����;
ע��:û������,���ű������ݻ�ȫ��ɾ��!
mysql> delete from t_user where id = 3; //ɾ��id=3������
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
+------+----------+------------+---------------------+
2 rows in set (0.00 sec)
mysql> insert into t_user(id) values(2); //��
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
| 1 | zhangsan | 1990-10-01 | 2021-11-25 15:54:20 |
| 2 | NULL | NULL | NULL |
+------+----------+------------+---------------------+
3 rows in set (0.00 sec)
mysql> delete from t_user; //ɾȫ��
Query OK, 3 rows affected (0.01 sec)
mysql> select * from t_user;
Empty set (0.00 sec)
��5�� Լ��
constraint
�ڴ�����ʱ,���Ը������ֶμ���Լ��,����֤���ݵ������ԡ���Ч��
Լ��������Щ:
-
�ǿ�Լ��:not null
-
Ψһ��Լ��: unique
-
����Լ��: primary key (PK)
-
���Լ��:foreign key(FK)
-
���Լ��:check(mysql��֧��,oracle֧��)
5.1 �ǿ�Լ��:not null
�ǿ�Լ��not nullԼ�����ֶβ���ΪNULL��
not null ֻ���м�Լ��,û�б���Լ��
vip.sql,���ļ�ΪSQL�ű��ļ�
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255) not null
);
insert into t_vip(id,name) values(1,'zhangsan');
insert into t_vip(id,name) values(2,'lisi');
mysql> source C:\Users\14051\Desktop\mysql_learning\document\vip.sql //ִ�������ű��ļ�
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
����ִ��sql�ű��ļ���ʱ��,���ļ������е�sql����ȫ��ִ��!
����ʵ�ʵĹ�����,��һ�쵽�˹�˾,��Ŀ���������һ��xxx.sql�ļ�,��ִ������ű��ļ�,������ϵ����ݿ����ݾ�����!
5.2 Ψһ��Լ��: unique
Ψһ��Լ��uniqueԼ�����ֶβ����ظ�,���ǿ���ΪNULL��
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255) unique, //nameֻ��Ψһ
email varchar(255)
);
insert into t_vip(id,name,email) values(1, 'zhangsan', 'zhangsan@123.com');
insert into t_vip(id,name,email) values(2, 'lisi', 'lisi@123.com');
insert into t_vip(id,name,email) values(3, 'wangwu', 'wangwu@123.com');
mysql> insert into t_vip(id,name,email) values(4, 'wangwu', 'wangwu@163.com'); //���ֲ������ظ�
ERROR 1062 (23000): Duplicate entry 'wangwu' for key 'name'
mysql> insert into t_vip(id) values(4); //����ΪNULL
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_vip;
+------+----------+------------------+
| id | name | email |
+------+----------+------------------+
| 1 | zhangsan | zhangsan@123.com |
| 2 | lisi | lisi@123.com |
| 3 | wangwu | wangwu@123.com |
| 4 | NULL | NULL |
+------+----------+------------------+
4 rows in set (0.00 sec)
������:name��email�����ֶ�������������Ψһ��!
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255),
email varchar(255),
unique(name,email) // Լ��û���������еĺ���,����Լ������Ϊ����Լ����
);
insert into t_vip(id,name,email) values(1,'zhangsan','zhangsan@123.com');
mysql> insert into t_vip(id,name,email) values(2,'zhangsan','zhangsan@163.com');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_vip;
+------+----------+------------------+
| id | name | email |
+------+----------+------------------+
| 1 | zhangsan | zhangsan@123.com |
| 2 | zhangsan | zhangsan@163.com |
+------+----------+------------------+
2 rows in set (0.00 sec)
mysql> insert into t_vip(id,name,email) values(3,'zhangsan','zhangsan@123.com');
ERROR 1062 (23000): Duplicate entry 'zhangsan-zhangsan@123.com' for key 'name'
ʲôʱ��ʹ�ñ���Լ��
��Ҫ������ֶ�������������ijһ��Լ����ʱ��,��Ҫʹ�ñ���Լ����
ʵ��:unique ��not null��������
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255) not null unique //����ʹ��
);
mysql> desc t_vip;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(255) | NO | PRI | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.01 sec)
��mysql����,���һ���ֶ�ͬʱ��not null��uniqueԼ���Ļ�,���ֶ��Զ���������ֶ���(ע��:oracle�в�һ��!)
5.3 ����Լ��:primary key
��Ҫ����
�������
- ����Լ��:һ��Լ����
- �����ֶ�:���ֶ�������������Լ��
- ����ֵ:�����ֶ��е�ÿһ��ֵ��������ֵ
ʲô������?��ɶ��?
����ֵ��ÿһ�м�¼��Ψһ��ʶ����ֵ��ÿһ�м�¼������֤��!
��ס:�κ�һ�ű���Ӧ��������,û������,����Ч!
����������:not null + unique(����ֵ������NULL,ͬʱҲ�����ظ�!)
��ô��һ�ű���������Լ����?
drop table if exists t_vip;
create table t_vip(
id int primary key, //�м�Լ��
name varchar(255)
);
mysql> insert into t_vip(id,name) values(1,'z');
mysql> insert into t_vip(id,name) values(2,'a');
mysql> insert into t_vip(id,name) values(2,'s'); //�����ظ�
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
mysql> insert into t_vip(name) values('c'); //������
ERROR 1364 (HY000): Field 'id' doesn't have a default value
(1)ʹ�ñ���Լ��,��������
ͬ��ʵ�ֹ���
create table t_vip(
id int,
name varchar(255),
primary key(id)); //����Լ��
����Լ����Ҫ�Ǹ�����ֶ�������������Լ��
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255),
email varchar(255),
primary key(id,name) // id��name��������������:��������!!!!
);
mysql> insert into t_vip(id,name,email) values(1,'zhangsan','zhangsan@123.com');
mysql> insert into t_vip(id,name,email) values(1,'lisi','lisi@123.com');
mysql> insert into t_vip(id,name,email) values(1,'lisi','lisi@123.com');
ERROR 1062 (23000): Duplicate entry '1-lisi' for key 'PRIMARY'
��ʵ�ʿ����в�����ʹ��:��������������ʹ�õ�һ����!
��Ϊ����ֵ���ڵ�����������м�¼������֤��,ֻҪ����ﵽ����,��һ��������������
(2)��������Լ����������
mysql> create table t_vip(
-> id int primary key,
-> name varchar(255) primary key);
ERROR 1068 (42000): Multiple primary key defined
����:һ�ű�,����Լ��ֻ������1����(����ֻ����1����)
����ֵ����ʹ��:int,bigint,char�����͡�
������ʹ��:varchar��������������ֵһ�㶼������,һ�㶼�Ƕ�����!
��������:��һ������������֮��,�������������з���
��Ȼ����:����ֵ��һ����Ȼ��,��ҵ��û��ϵ��
ҵ������:����ֵ��ҵ����ܹ���,���������п��˺�������ֵ�������ҵ������!
��ʵ�ʿ�����ʹ��ҵ��������,����ʹ����Ȼ������һЩ?
��Ȼ����ʹ�ñȽ϶�,��Ϊ����ֻҪ�������ظ�����,����Ҫ�����塣
��Ϊ����һ����ҵ��ҹ�,��ҵ�����䶯ʱ,��Ӱ�쵽����ֵ,����ҵ������������ʹ�á�
(3)auto_increment
��mysql����,��һ�ֻ���,�����������Զ�ά��һ������ֵ
create table t_vip(
id int primary key auto_increment, //auto_increment��ʾ����,��1��ʼ,��1����!
name varchar(255)
);
insert into t_vip(name) values('zhangsan');
insert into t_vip(name) values('zhangsan');
insert into t_vip(name) values('zhangsan');
mysql> select * from t_vip;
+----+----------+
| id | name |
+----+----------+
| 1 | zhangsan |
| 2 | zhangsan |
| 3 | zhangsan |
+----+----------+
3 rows in set (0.00 sec)
5.4 ���Լ��:foreign key
���FK
ҵ��:��������ݿ��,���������༶��ѧ��������Ϣ
��һ�ַ���:�༶��ѧ���洢��һ�ű���
t_student
no(pk) name classno classname
----------------------------------------------------------------------------------
1 jack 100 �����д�������ׯ��ڶ���ѧ����1��
2 lucy 100 �����д�������ׯ��ڶ���ѧ����1��
3 lilei 100 �����д�������ׯ��ڶ���ѧ����1��
4 hanmeimei 100 �����д�������ׯ��ڶ���ѧ����1��
5 zhangsan 101 �����д�������ׯ��ڶ���ѧ����2��
6 lisi 101 �����д�������ׯ��ڶ���ѧ����2��
7 wangwu 101 �����д�������ׯ��ڶ���ѧ����2��
8 zhaoliu 101 �����д�������ׯ��ڶ���ѧ����2��
���Ϸ���ȱ��:��������,�ռ��˷�!�������DZȽ�ʧ�ܵ�!
�ڶ��ַ���:�༶һ�ű���ѧ��һ�ű�
t_class �༶��
classno(pk) classname
------------------------------------------------------
100 �����д�������ׯ��ڶ���ѧ����1��
101 �����д�������ׯ��ڶ���ѧ����1��
t_student ѧ����
no(pk) name cno(FK����t_class���ű���classno)
----------------------------------------------------------------
1 jack 100
2 lucy 100
3 lilei 100
4 hanmeimei 100
5 zhangsan 101
6 lisi 101
7 wangwu 101
8 zhaoliu 101
��cno�ֶ�û���κ�Լ����ʱ��,���ܻᵼ��������Ч�����ܳ���һ��102,����102�༶�����ڡ�
����Ϊ�˱�֤cno�ֶ��е�ֵ����100��101,��Ҫ��cno�ֶ��������Լ����
��ô:cno�ֶξ�������ֶΡ�cno�ֶ��е�ÿһ��ֵ�������ֵ��
ע��:
t_class�Ǹ���
t_student���ӱ�
- ɾ������˳��:��ɾ��,��ɾ����
- ��������˳��:�ȴ�����,�ٴ����ӡ�
- ɾ�����ݵ�˳��:��ɾ��,��ɾ����
- �������ݵ�˳��:�Ȳ��븸,�ٲ����ӡ�
drop table if exists t_student;
drop table if exists t_class;
create table t_class(
classno int primary key,
classname varchar(255)
);
create table t_student(
no int primary key auto_increment,
name varchar(255),
cno int,
foreign key(cno) references t_class(classno)
);
insert into t_class(classno,classname) values(100,'�����д�������ׯ��ڶ���ѧ����1��');
insert into t_class(classno,classname) values(101,'�����д�������ׯ��ڶ���ѧ����1��');
insert into t_student(name,cno) values('jack',100);
insert into t_student(name,cno) values('lucy',100);
insert into t_student(name,cno) values('lilei',100);
insert into t_student(name,cno) values('hanmeimei',100);
insert into t_student(name,cno) values('zhangsan',101);
insert into t_student(name,cno) values('lisi',101);
insert into t_student(name,cno) values('wangwu',101);
insert into t_student(name,cno) values('zhaoliu',101);
˼��:�ӱ��е�������õĸ����е�ij���ֶ�,�����õ�����ֶα�����������?
��һ��������,�����پ���uniqueԼ����
����:�������ΪNULL��?
���ֵ����ΪNULL
mysql> insert into t_student(name,cno) values('zhaoliu',NULL);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_student;
+----+-----------+------+
| no | name | cno |
+----+-----------+------+
| 1 | jack | 100 |
| 2 | lucy | 100 |
| 3 | lilei | 100 |
| 4 | hanmeimei | 100 |
| 5 | zhangsan | 101 |
| 6 | lisi | 101 |
| 7 | wangwu | 101 |
| 8 | zhaoliu | 101 |
| 10 | zhaoliu | NULL |
+----+-----------+------+
9 rows in set (0.00 sec)
��6�� �洢����
(�˽�����)
�洢������MySQL�����е�һ������,�������ݿ���û�С�(Oracle����,���Dz����������)
�洢������һ�����洢/��֯���ݵķ�ʽ��
��ͬ�Ĵ洢����,���洢���ݵķ�ʽ��ͬ��
6.1 �鿴���Ĵ洢����
mysql> show create table t_student;
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_student | CREATE TABLE `t_student` (
`no` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cno` int(11) DEFAULT NULL,
PRIMARY KEY (`no`),
KEY `cno` (`cno`),
CONSTRAINT `t_student_ibfk_1` FOREIGN KEY (`cno`) REFERENCES `t_class` (`classno`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8 |
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
����:
mysqlĬ�ϵĴ洢������:InnoDB
mysqlĬ�ϵ��ַ����뷽ʽ��:utf8
6.2 ָ���洢����ͱ���
����ʱָ���洢����,�Լ��ַ����뷽ʽ
create table t_product(
id int primary key,
name varchar(255)
)engine=InnoDB default charset=gbk;
mysql> desc t_product;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.02 sec)
6.3 �鿴mysql֧����Щ�洢����
mysql> desc t_product;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.02 sec)
mysql> show engines \G
*************************** 1. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
*************************** 2. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 6. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 7. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 9. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Transactions: NO
XA: NO
Savepoints: NO
9 rows in set (0.01 sec)
mysql֧�־Ŵ�洢����,��ǰ5.5.36֧��8�����汾��֧ͬ�������ͬ��
6.4 mysql�����洢����
(1)MyISAM�洢����
�������ı�������������:
ʹ�������ļ���ʾÿ����:
��ʽ�ļ� �� �洢���ṹ�Ķ���(mytable.frm)
�����ļ� �� �洢���е�����(mytable.MYD)
�����ļ� �� �洢��������(mytable.MYI):������һ�����Ŀ¼,��Сɨ�跶Χ,��߲�ѯЧ�ʵ�һ�ֻ��ơ�
�ɱ�ת��Ϊѹ����ֻ��������ʡ�ռ�
����һ�ű���˵,ֻҪ������,������uniqueԼ�����ֶ��ϻ��Զ�����������
MyISAM�洢�����ص�:
�ɱ�ת��Ϊѹ����ֻ��������ʡ�ռ�
�������ִ洢���������!!!!
MyISAM��֧���������,��ȫ�Ե͡�
(2)InnoDB�洢����
����mysqlĬ�ϵĴ洢����,ͬʱҲ��һ���������Ĵ洢���档
InnoDB֧������,֧�����ݿ�������Զ��ָ����ơ�
InnoDB�洢��������Ҫ���ص���:�dz���ȫ��
�������ı�����������Ҫ����:
�C ÿ�� InnoDB �������ݿ�Ŀ¼����.frm ��ʽ�ļ���ʾ
�C InnoDB ���ռ� tablespace �����ڴ洢��������(���ռ���һ�������ơ����ռ�洢����+������)
�C �ṩһ��������¼�����Ի����־�ļ�
�C �� COMMIT(�ύ)��SAVEPOINT ��ROLLBACK(�ع�)֧��������
�C �ṩȫ ACID ����
�C �� MySQL �������������ṩ�Զ��ָ�
�C ��汾(MVCC)���м�����
�C ֧����������õ�������,��������ɾ������
InnoDB�����ص����֧������:
�Ա�֤���ݵİ�ȫ��Ч�ʲ��Ǻܸ�,����ѹ��,����ת��Ϊֻ��,���ܺܺõĽ�ʡ�洢�ռ䡣
(3)MEMORY�洢����
ʹ�� MEMORY �洢����ı�,�����ݴ洢���ڴ���,���еij��ȹ̶�,
�������ص�ʹ�� MEMORY �洢����dz��졣
MEMORY �洢��������ı�������������:
�C �����ݿ�Ŀ¼��,ÿ��������.frm ��ʽ���ļ���ʾ��
�C �����ݼ��������洢���ڴ��С�(Ŀ�ľ��ǿ�,��ѯ��!)
�C ���������ơ�
�C ���ܰ��� TEXT �� BLOB �ֶΡ�
MEMORY �洢������ǰ����ΪHEAP ���档
MEMORY�����ŵ�:��ѯЧ������ߵġ�����Ҫ��Ӳ�̽�����
MEMORY����ȱ��:����ȫ,�ػ�֮��������ʧ����Ϊ���ݺ������������ڴ浱�С�
��7�� ����
һ��������ʵ����һ��������ҵ����,����С�Ĺ�����Ԫ,�����ٷ֡�
ʲô��һ��������ҵ����?
����ת��,��A�˻���B�˻���ת��10000.
��A�˻���Ǯ��ȥ10000(update���)
��B�˻���Ǯ����10000(update���)
�����һ��������ҵ������
���ϵIJ�����һ����С�Ĺ�����Ԫ,Ҫôͬʱ�ɹ�,Ҫôͬʱʧ��,�����ٷ֡�
������update���Ҫ�����ͬʱ�ɹ�����ͬʱʧ��,�������ܱ�֤Ǯ����ȷ�ġ�
ֻ��DML���Ż���������һ˵:insert,delete,update�������,������û�й�ϵ��
һ��������ʵ���Ƕ���DML���ͬʱ�ɹ�,����ͬʱʧ��!
����:����������DML���ͬʱ�ɹ�,����ͬʱʧ��
InnoDB�洢����:�ṩһ��������¼�����Ի����־�ļ�
��������:
insert
insert
insert
delete
update
update
update
���������!
�������ִ�й�����,ÿһ��DML�IJ��������¼���������Ի����־�ļ����С�
�������ִ�й�����,���ǿ����ύ����,Ҳ���Իع�����
�ύ����
��������Ի����־�ļ�,������ȫ�����׳־û������ݿ���С�
�ύ�����־��,����Ľ�����������һ��ȫ���ɹ��Ľ�����
�ع�����
��֮ǰ���е�DML����ȫ������,������������Ի����־�ļ�
�ع������־��,����Ľ�����������һ��ȫ��ʧ�ܵĽ�����
7.1 ��ô�ύ����,��ô�ع�����
�ύ����:commit; ���
�ع�����:rollback; ���(�ع���Զ����ֻ�ܻع�����һ�ε��ύ��!)
�����Ӧ��Ӣ�ﵥ����:transaction
����һ��,��mysql����Ĭ�ϵ�������Ϊ��������
mysqlĬ���������֧���Զ��ύ�������(�Զ��ύ)
�Զ��ύ:ÿִ��һ��DML���,���ύһ��!
�����Զ��ύʵ�����Dz��������ǵĿ���ϰ��,��Ϊһ��ҵ��ͨ������Ҫ����DML��乲ִͬ�в�����ɵ�,Ϊ�˱�֤���ݵİ�ȫ,����Ҫ��ͬʱ�ɹ�֮�����ύ,���Բ���ִ��һ�����ύһ����
��ô��mysql���Զ��ύ���ƹرյ���
��ִ���������:start transaction;
�ع�����
mysql> select * from dept_bak;
Empty set (0.00 sec)
mysql> start transaction; //�ر��Զ��ύ����
Query OK, 0 rows affected (0.00 sec)
mysql> insert into dept_bak values(10,'abc', 'tj');
Query OK, 1 row affected (0.00 sec)
mysql> insert into dept_bak values(10,'abc', 'tj');
Query OK, 1 row affected (0.00 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | tj |
| 10 | abc | tj |
+--------+-------+------+
2 rows in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak;
Empty set (0.00 sec)
�ύ����
mysql> select * from dept_bak;
Empty set (0.00 sec)
mysql> insert into dept_bak values(10,'abc','tj');
Query OK, 1 row affected (0.00 sec)
mysql> insert into dept_bak values(20,'abc','tj');
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | tj |
| 10 | abc | tj |
+--------+-------+------+
2 rows in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | tj |
| 10 | abc | tj |
+--------+-------+------+
2 rows in set (0.00 sec)
7.2 ������ĸ�����
A:ԭ����:˵����������С�Ĺ�����Ԫ�������ٷ֡�
C:һ����:��������Ҫ��,��ͬһ��������,���в�������ͬʱ�ɹ�,����ͬʱʧ��,�Ա�֤���ݵ�һ���ԡ�
I:������
A�����B����֮�����һ���ĸ��롣
����A�ͽ���B֮����һ��ǽ,���ǽ���Ǹ����ԡ�
A�����ڲ���һ�ű���ʱ��,��һ������BҲ�������ű�������???
D:�־���
�������ս�����һ�����ϡ������ύ,���൱�ڽ�û�б��浽Ӳ���ϵ����ݱ��浽Ӳ����!
7.3 ���ָ�����
A���Һ�B�����м���һ��ǽ,���ǽ���Ժܺ�,Ҳ���Ժܱ������������ĸ��뼶�����ǽԽ��,��ʾ���뼶���Խ�ߡ�
���������֮��ĸ��뼶������Щ��?
(1)��δ�ύ:read uncommitted
(��͵ĸ��뼶��)��û���ύ�Ͷ����ˡ�
����A���Զ�ȡ������Bδ�ύ�����ݡ�
���ָ��뼶����ڵ��������:
�������!(Dirty Read)
���ָ��뼶��һ�㶼�������ϵ�,����������ݿ���뼶���Ƕ�����!
(2)�����ύ:read committed
�ύ֮����ܶ���
����Aֻ�ܶ�ȡ������B�ύ֮������ݡ�
�����ʲô����?: ��������������
����ʲô����?: �����ظ���ȡ���ݡ�
�����ظ���ȡ����ָ:��������֮��,��һ�ζ�����������3��,��ǰ����û�н���,���ܵڶ����ٶ�ȡ��ʱ��,������������4��,3������4��Ϊ�����ظ���ȡ��
���ָ��뼶���DZȽ���ʵ������,ÿһ�ζ����������Ǿ��Ե���ʵ��
oracle���ݿ�Ĭ�ϵĸ��뼶����:read committed
(3)���ظ���:repeatable read
���ύ֮��Ҳ������,��Զ��ȡ�Ķ��Ǹտ�������ʱ�����ݡ�
���ظ���:����A����֮��,�����Ƕ��,ÿһ��������A�ж�ȡ�������ݶ���һ�µġ���ʹ����B�������Ѿ���,�����ύ��,����A��ȡ�������ݻ���û�з����ı䡣
�������ʲô����?:����˲����ظ���ȡ���ݡ�
���ڵ�������ʲô?:���Ի������Ӱ����
ÿһ�ζ�ȡ�������ݶ��ǻ�������ʵ!
�糿9�㿪ʼ����������,ֻҪ������,������9��,���������ݻ�������!
�������Ǽ��������Ե���ʵ��
mysql��Ĭ�ϵ�������뼶��������!
(4)���л�/���л�:serializable
������߸��뼶��,Ч����͡���������е����⡣
���ָ��뼶���ʾ�����Ŷ�,���ܲ���!
synchronized,�߳�ͬ��(����ͬ��)
ÿһ�ζ�ȡ�������ݶ�������ʵ��,����Ч������͵ġ�
7.4 ��֤���ָ��뼶��
�鿴������:
mysql> SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ | //mysqlĬ�ϵĸ��뼶��
+-----------------+
1 row in set (0.00 sec)
��֤:read uncommited
mysql> set global transaction isolation level read uncommitted;
����A ����B
--------------------------------------------------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
select * from t_user;
start transaction;
u
select * from t_user;
��֤:read commited
mysql> set global transaction isolation level read committed;
����A ����B
--------------------------------------------------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('zhangsan');
select * from t_user;
commit;
select * from t_user;
��֤:repeatable read
mysql> set global transaction isolation level repeatable read;
����A ����B
--------------------------------------------------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('lisi');
insert into t_user values('wangwu');
commit;
select * from t_user;
��֤:serializable
mysql> set global transaction isolation level serializable;
����A ����B
--------------------------------------------------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('abc');
select * from t_user;
commit;
��8�� ����:index
�����������ݿ�����ֶ������ӵ�,��Ϊ����߲�ѯЧ�ʴ��ڵ�һ�ֻ��ơ�
һ�ű���һ���ֶο�������һ������,��Ȼ,����ֶ���������Ҳ��������������
�����൱��һ�����Ŀ¼,��Ϊ����Сɨ�跶Χ�����ڵ�һ�ֻ��ơ�
����һ���ֵ���˵,����ij�����������ַ�ʽ:
��һ�ַ�ʽ:һҳһҳ������,ֱ���ҵ�Ϊֹ;��ȫ�ֵ�ɨ��,Ч�ʵ�
�ڶ��ַ�ʽ:��ͨ��Ŀ¼(����)ȥ��λһ����ŵ�λ��,Ȼ��ֱ�Ӷ�λ�����
λ��,��������ɨ��,��Сɨ��ķ�Χ,���ٲ���
t_user
id(idIndex) name(nameIndex) email(emailIndex) address (emailAddressIndex)
----------------------------------------------------------------------------------
1 zhangsan...
2 lisi
3 wangwu
4 zhaoliu
5 hanmeimei
6 jack
select * from t_user where name='jack';
���ϵ�����SQL����ȥname�ֶ���ɨ��,��Ϊ��ѯ������:name=��jack��
���name�ֶ���û����������(Ŀ¼),����˵û�и�name�ֶδ�������,MySQL�����ȫɨ��,�Ὣname�ֶ��ϵ�ÿһ��ֵ���ȶ�һ�顣Ч�ʱȽϵ͡�
8.1 ��ѯ���ַ�ʽ
- ȫ��ɨ��
- ������������
ע��:
��ʵ����,�����ֵ�ǰ���Ŀ¼�������,����a b c d e f������,
Ϊʲô������?��Ϊֻ�������˲Ż������������һ˵!(��Сɨ�跶Χ��ʵ����ɨ��ij���������!)
��mysql���ݿ������Ҳ����Ҫ�����,������������������TreeSet
���ݽṹ��ͬ��TreeSet(TreeMap)�ײ���һ����ƽ��Ķ�����!��mysql����������һ��B-Tree���ݽṹ��
��ѭ��С�Ҵ�ԭ���š��������������ʽ����ȡ���ݡ�
8.2 ������ʵ��ԭ��
������һ���û���:t_user
id(PK) name ÿһ�м�¼��Ӳ���϶��������洢���
----------------------------------------------------------------------------------
100 zhangsan 0x1111
120 lisi 0x2222
99 wangwu 0x8888
88 zhaoliu 0x9999
101 jack 0x6666
55 lucy 0x5555
130 tom 0x7777
����1:�κ����ݿ��������������Զ���������,����id�ֶ����Զ��������� ����,һ���ֶ������uniqueԼ��,Ҳ���Զ�����������
����2:���κ����ݿ��,�κ�һ�ű����κ�һ����¼��Ӳ�̴洢�϶���һ��Ӳ�̵������洢�����
����3:��mysql����,������һ�������Ķ���,��ͬ�Ĵ洢�����Բ�ͬ����ʽ����,
��MyISAM�洢������,�����洢��һ��.MYI�ļ���;
��InnoDB�洢�����������洢��һ�������ƽ���tablespace�ĵ���;
��MEMORY�洢���浱���������洢���ڴ浱�С�
���������洢������,������mysql���ж���һ��������ʽ���ڡ�(��ƽ�������:B-Tree)

ʲôʱ���Ǹ��ֶ���������?
- �������Ӵ�
- ���ֶξ���������where�ĺ���,����������ʽ����;����˵���ֶ�Ƶ����ɨ����
- ���ֶκ��ٵ�DML(insert delete update)����;����˵��ɾ����
8.3 �����Ĵ�����ɾ��
��������:create index emp_ename_index on emp(ename);
��:��emp����ename�ֶ���������,����:emp_ename_index
mysql> create index emp_ename_index on emp(ename);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
ɾ������:drop index emp_ename_index on emp;
mysql> drop index emp_ename_index on emp;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
8.4 �鿴�Ƿ�ʹ����������:explain
mysql> explain select * from emp where ename='KING';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
ɨ��14����¼:˵��û��ʹ��������type=ALL
��:��������ɨ��:
mysql> create index emp_ename_index on emp(ename);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from emp where ename='KING';
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-------------+
| 1 | SIMPLE | emp | ref | emp_ename_index | emp_ename_index | 33 | const | 1 | Using where |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-------------+
1 row in set (0.01 sec)
8.5 ����ʧЧ���
��1��:ģ��ƥ��%��ͷ���
mysql> select * from emp where ename like '%T';
+-------+-------+---------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+---------+------+------------+---------+------+--------+
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
+-------+-------+---------+------+------------+---------+------+--------+
1 row in set (0.00 sec)
mysql> explain select * from emp where ename like '%T';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
ԭ��:ģ��ƥ���ԡ�%����ͷ��!
��2��:ʹ��or���
or���ߵ������ֶζ�Ҫ������,�Ż�������;
mysql> explain select * from emp where ename = 'KING' or job = 'MANAGER'; //job�ֶ�û�н�������
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | emp_ename_index | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
��3��:�����������:
��������:�����ֶ�,���߸�����ֶ�������������һ��������
ʹ�ø�������ʱ,��û��ʹ�������в���,����ʧЧ������ԭ��
mysql> create index emp_job_sal_index on emp(job,sal); //������������ ����ֶ���job
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from emp where job='MANAGER'; //����ԭ�� �����
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-------------+
| 1 | SIMPLE | emp | ref | emp_job_sal_index | emp_job_sal_index | 30 | const | 3 | Using where |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from emp where sal=800; //�ұ߲���
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.01 sec)
��4��:where���������вμ���������:
mysql> create index emp_sal_index on emp(sal); //��������
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from emp where sal=800; //�������û����
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------------+
| 1 | SIMPLE | emp | ref | emp_sal_index | emp_sal_index | 9 | const | 1 | Using where |
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from emp where sal+1 = 800; //�μ���������ʧЧ
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.01 sec)
��5��:where����������ʹ���˺��������:
mysql> explain select * from emp where lower(ename) = 'smith';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
8.6 ��������
- ��һ����:һ���ֶ�����������
- ��������:�����ֶλ��߸�����ֶ�����������
- ��������:��������������
- Ψһ������:����uniqueԼ�����ֶ�����������
��
ע��:Ψһ�ԱȽ������ֶ������������ô�����
��9�� ��ͼ:view
9.1 ��ͼ����Ĵ�����ɾ��
mysql> create table dept2 as select * from dept;
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from dept2;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> create view dept2_view as select * from dept2; //������ͼ
Query OK, 0 rows affected (0.01 sec)
mysql> drop view dept2_view; //ɾ����ͼ
Query OK, 0 rows affected (0.00 sec)
9.2 ��ͼ������
����:����������ͼ���������ɾ�IJ�,����ͼ�������ɾ��,�ᵼ��ԭ��������!:
mysql> create view dept2_view as select * from dept2;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from dept2_view;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> insert into dept2_view(deptno,dname,loc) values(60,'SALES', 'BEIJING'); //������ͼ��������
Query OK, 1 row affected (0.00 sec)
mysql> select * from dept2_view;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
| 60 | SALES | BEIJING |
+--------+------------+----------+
5 rows in set (0.00 sec)
mysql> select * from dept2; //ԭ��Ҳ������
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
| 60 | SALES | BEIJING |
+--------+------------+----------+
5 rows in set (0.00 sec)
mysql> delete from dept2_view; //������ͼɾ��
Query OK, 5 rows affected (0.01 sec)
mysql> select * from dept2; //ԭ��Ҳɾ����
Empty set (0.00 sec)
mysql> select e.ename,e.sal,d.dname from emp e join dept d on e.deptno = d.deptno;
+--------+---------+------------+
| ename | sal | dname |
+--------+---------+------------+
| CLARK | 2450.00 | ACCOUNTING |
| KING | 5000.00 | ACCOUNTING |
| MILLER | 1300.00 | ACCOUNTING |
| SMITH | 800.00 | RESEARCH |
| JONES | 2975.00 | RESEARCH |
| SCOTT | 3000.00 | RESEARCH |
| ADAMS | 1100.00 | RESEARCH |
| FORD | 3000.00 | RESEARCH |
| ALLEN | 1600.00 | SALES |
| WARD | 1250.00 | SALES |
| MARTIN | 1250.00 | SALES |
| BLAKE | 2850.00 | SALES |
| TURNER | 1500.00 | SALES |
| JAMES | 950.00 | SALES |
+--------+---------+------------+
14 rows in set (0.00 sec)
mysql> create view emp_dept_view as select e.ename,e.sal,d.dname from emp e join dept d on e.deptno = d.deptno;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from emp_dept_view;
+--------+---------+------------+
| ename | sal | dname |
+--------+---------+------------+
| CLARK | 2450.00 | ACCOUNTING |
| KING | 5000.00 | ACCOUNTING |
| MILLER | 1300.00 | ACCOUNTING |
| SMITH | 800.00 | RESEARCH |
| JONES | 2975.00 | RESEARCH |
| SCOTT | 3000.00 | RESEARCH |
| ADAMS | 1100.00 | RESEARCH |
| FORD | 3000.00 | RESEARCH |
| ALLEN | 1600.00 | SALES |
| WARD | 1250.00 | SALES |
| MARTIN | 1250.00 | SALES |
| BLAKE | 2850.00 | SALES |
| TURNER | 1500.00 | SALES |
| JAMES | 950.00 | SALES |
+--------+---------+------------+
14 rows in set (0.00 sec)
mysql> select * from emp; //������ͼ������Ӱ��ԭ��
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
mysql> update emp_dept_view set sal = 1000 where dname = 'ACCOUNTING'; //������ͼ����
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> select * from emp; //������ԭ��
+-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 1000.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 1000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1000.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
��ͼ������ʵ�ʿ����е�����:����,����,����ά��
create view
emp_dept_view
as
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
������һ���dz����ӵ�SQL���,����Ҫ�ڲ�ͬ��λ���Ϸ���ʹ�á�
ÿһ��ʹ�����sql����ʱ����Ҫ���±�д,�ܳ�,���鷳,��ô��?
**�����������ӵ�SQL�������ͼ�������ʽ�½�,**���Դ�������
�������ں��ڵ�ά��,��Ϊ�ĵ�ʱ��Ҳֻ��Ҫ��һ��λ�þ���,ֻ��Ҫ����ͼ������ӳ���SQL��䡣
�����Ժ�������ͼ������ʱ��,ʹ����ͼ��ʱ�������ʹ��tableһ�������Զ���ͼ������ɾ�IJ�Ȳ�������ͼ�������ڴ浱��,��ͼ����Ҳ���洢��Ӳ������,������ʧ��
����:
��ɾ�IJ�,�ֽ���CRUD�����ڹ�˾�г���Ա֮�乵ͨ�����
C:Create(��)
R:Retrive(��:����)
U:Update(��)
D:Delete(ɾ)
9.3 DBA��������
�ص�����:���ݵĵ���͵���(���ݵı���)
���������˽�һ�¼��ɡ�
(1)���ݵ���
ע��:��windows��dos�������:
mysqldump bjpowernode>D:\bjpowernode.sql -uroot -p123456
����ָ���ı�:emp
mysqldump bjpowernode emp>D:\bjpowernode.sql -uroot -p123456
(2)���ݵ���
ע��:��Ҫ�ȵ�¼��mysql���ݿ�������ϡ�
Ȼ�����ݿ�:create database bjpowernode;
ʹ�����ݿ�:use bjpowernode
Ȼ���ʼ�����ݿ�:source D:\bjpowernode.sql
��10�� ���ݿ��������ʽ
�ص�!
���ݿ���Ʒ�ʽ:���ݿ����������ݡ�
-
��һ��ʽ:Ҫ���κ�һ�ű�����������,ÿһ���ֶ�ԭ���Բ����ٷ֡�
-
�ڶ���ʽ:�����ڵ�һ��ʽ�Ļ���֮��,Ҫ�����з������ֶ���ȫ��������,��Ҫ��������������
-
������ʽ:�����ڵڶ���ʽ�Ļ���֮��,Ҫ�����з������ֶ�ֱ����������,��Ҫ��������������
�������Ϸ�ʽ������ݿ��,���Ա���������ݵ�����,�ռ���˷ѡ�
��һ��ʽ
�����,����Ҫ�ķ�ʽ,���б�����ƶ���Ҫ���㡣
����������,����ÿһ���ֶζ���ԭ���Բ����ٷ֡�
ѧ����� ѧ������ ��ϵ��ʽ
------------------------------------------
1001 ���� zs@gmail.com,1359999999
1002 ���� ls@gmail.com,13699999999
1001 ���� ww@163.net,13488888888
�ϱ��������һ��ʽ
ԭ��:��һ,û������;�ڶ�,��ϵ��ʽ���Է�Ϊ�����ַ�͵绰:
ѧ�����(pk) ѧ������ �����ַ ��ϵ�绰
---------------------------------------------------------
1001 ���� zs@gmail.com 1359999999
1002 ���� ls@gmail.com 13699999999
1003 ���� ww@163.net 13488888888
�ڶ���ʽ
�����ڵ�һ��ʽ�Ļ���֮��,Ҫ�����з������ֶα�����ȫ��������,��Ҫ������������
ѧ����� ѧ������ ��ʦ��� ��ʦ����
----------------------------------------------------
1001 ���� 001 ����ʦ
1002 ���� 002 ����ʦ
1003 ���� 001 ����ʦ
1001 ���� 002 ����ʦ
��Զ��ϵ!(1��ѧ�������ж����ʦ,1����ʦ�ж��ѧ��)
�ϱ������һ��ʽ;��
ѧ����� ��ʦ���,�����ֶ�����������,��������(PK: ѧ�����+��ʦ���)
ѧ�����+��ʦ���(pk) ѧ������ ��ʦ����
----------------------------------------------------
1001 001 ���� ����ʦ
1002 002 ���� ����ʦ
1003 001 ���� ����ʦ
1001 002 ���� ����ʦ
�ϱ�������ڶ���ʽ:����������1001,������ʦ������001,��Ȼ�����˲���������
��:ʹ�����ű�����ʾ��Զ�Ĺ�ϵ
ѧ����
ѧ�����(pk) ѧ������
------------------------------------
1001 ����
1002 ����
1003 ����
��ʦ��
��ʦ���(pk) ��ʦ����
--------------------------------------
001 ����ʦ
002 ����ʦ
ѧ����ʦ��ϵ��
id(pk) ѧ�����(fk) ��ʦ���(fk)
------------------------------------------------------
1 1001 001
2 1002 002
3 1003 001
4 1001 002
�ܽ�:��Զ����,���ű�,��ϵ���������!
������ʽ
������ʽ�����ڵڶ���ʽ�Ļ���֮��,Ҫ�����з������ֵ����ֱ����������,��Ҫ��������������
ѧ�����(PK) ѧ������ �༶��� �༶����
---------------------------------------------------------
1001 ���� 01 һ��һ��
1002 ���� 02 һ�����
1003 ���� 03 һ������
1004 ���� 03 һ������
1�Զ��ϵ!(һ���������ж��ѧ��)
�����һ��ʽ,������(ѧ�����)��
����ڶ���ʽ,��Ϊ�������Ǹ�������,û�в������������������ǵ�һ������
�����������ʽ:һ��һ������01,01����1001,�����˴���������
��:
�༶��:һ
�༶���(pk) �༶����
----------------------------------------
01 һ��һ��
02 һ�����
03 һ������
ѧ����:��
ѧ�����(PK) ѧ������ �༶���(fk)
-------------------------------------------
1001 ���� 01
1002 ���� 02
1003 ���� 03
1004 ���� 03
�ܽ�: һ�Զ�,���ű�,��ı������!
һ��һ: ʵ�ʿ�����,���ܴ���һ�ű��ֶ�̫��,̫�Ӵ����ʱ��Ҫ��ֱ���
û�в�ֱ�֮ǰ:һ�ű�
t_user
id login_name login_pwd real_name email address........
------------------------------------------------------------------------------------------------------
1 zhangsan 123 ���� zhangsan@xxx
2 lisi 123 ���� lisi@xxx
...
�����Ӵ�ı�������Ϊ����:
t_login ��¼��Ϣ��
id(pk) login_name login_pwd
------------------------------------------
1 zhangsan 123
2 lisi 123
t_user �û���ϸ��Ϣ��
id(pk) real_name email address........ login_id(fk+unique)
-----------------------------------------------------------------------------------------
100 ���� zhangsan@xxx 1
200 ���� lisi@xxx 2
�ܽ�:һ��һ,���Ψһ!
ע��:���ݿ��������ʽ�������ϵ�;��ɶ��ű�,��ѯ��ʱ�����Ҫ���Ӷ��ű�,���ڵѿ�����,��ѯ�ٶ�����
ʵ�����Կռ�(��������)��ȡʱ��(����)�ǿ��еġ����Ҳ����Ļ�,SQL����дҲ��