目录
Mysql数据库的安装
Mysql数据库安装:oracle官网下载
Mysql数据库的Sql语句
Mysql的Sql语句的分类
查询当前使用的数据库:select 数据库名();
查询数据库版本:select version();
查看其他库中的表:show tables from 数据库名;
查看创建表的语句:show create table 表名;
查看表的结构:desc 表名;
sql语句不区分大小写
终止语句:\c
退出mysql:\q或者exit
使用数据库:use 数据库名;
创建数据库:create database 数据库名;
删除数据库:drop database 数据库名;
DQL(数据查询语言):查询语句,select语句都是DQL
DML(数据操作语言):insert,delete,update,对表中的数据进行增删改
DDL(数据定义语言):create,drop,alter,对表的结构增删改
TCL(事务控制语言):commit提交事务,rollback回滚事务
DCL(数据控制语言):grant授权,revoke撤销权限等
导入数据
创建文件(任意位置)创建temp.sql的文件(名字随意后缀一定要是.sql)
复制以下信息到文件内:
DROP TABLE IF EXISTS EMP;
DROP TABLE IF EXISTS DEPT;
DROP TABLE IF EXISTS SALGRADE;
CREATE TABLE DEPT
(DEPTNO int(2) not null ,
DNAME VARCHAR(14) ,
LOC VARCHAR(13),
primary key (DEPTNO)
);
CREATE TABLE EMP
(EMPNO int(4) not null ,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR INT(4),
HIREDATE DATE DEFAULT NULL,
SAL DOUBLE(7,2),
COMM DOUBLE(7,2),
primary key (EMPNO),
DEPTNO INT(2)
)
;
CREATE TABLE SALGRADE
( GRADE INT,
LOSAL INT,
HISAL INT );
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
20, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
30, 'SALES', 'CHICAGO');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
40, 'OPERATIONS', 'BOSTON');
commit;
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7369, 'SMITH', 'CLERK', 7902, '1980-12-17'
, 800, NULL, 20);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20'
, 1600, 300, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7521, 'WARD', 'SALESMAN', 7698, '1981-02-22'
, 1250, 500, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7566, 'JONES', 'MANAGER', 7839, '1981-04-02'
, 2975, NULL, 20);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28'
, 1250, 1400, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01'
, 2850, NULL, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7782, 'CLARK', 'MANAGER', 7839, '1981-06-09'
, 2450, NULL, 10);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19'
, 3000, NULL, 20);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7839, 'KING', 'PRESIDENT', NULL, '1981-11-17'
, 5000, NULL, 10);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08'
, 1500, 0, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7876, 'ADAMS', 'CLERK', 7788, '1987-05-23'
, 1100, NULL, 20);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7900, 'JAMES', 'CLERK', 7698, '1981-12-03'
, 950, NULL, 30);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7902, 'FORD', 'ANALYST', 7566, '1981-12-03'
, 3000, NULL, 20);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
7934, 'MILLER', 'CLERK', 7782, '1982-01-23'
, 1300, NULL, 10);
commit;
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
1, 700, 1200);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
2, 1201, 1400);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
3, 1401, 2000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
4, 2001, 3000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
5, 3001, 9999);
commit;
打开mysql创建自己的数据库:create database testmysql;

然后使用数据库testmysql数据库:use testmysql;
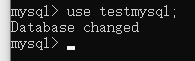
导入数据(需要填写自己的temp.sql路径 注意不加分号):source D:\sql\temp.sql

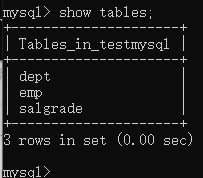
查看数据库的所有表:show tables;
删除数据库的指令:drop database 数据库名;
表的介绍:
dept:部门表
emp:员工表
salgrade:工资等级表
查看表结构语句:desc 表名;

查询语句
简单查询
语法格式:
select 字段名1,字段名2 from 表名;
列子:
select ename from emp;
*的意思是查询所有字段


起别名:
语法格式:
select 字段名 as 别名,字段名 as 别名 from 表名;
例子:
select ename as e,sal as s from emp;

条件查询
where语法格式:
select 字段名列表 from 表名 where 条件;
select 字段列表 from 表名 where 条件 and 条件
select 字段列表 from 表名 where 条件 or 条件
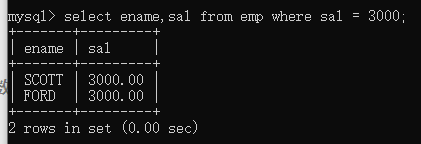
例子:查出员工工资等于三千的员工
select ename,sal from emp where sal = 3000;
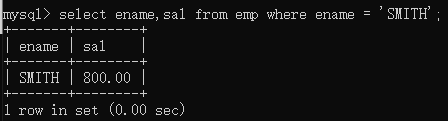
查询名字如果是字符串类型需要加单引号:
select ename,sal from emp where ename = ‘SMITH’;
between and语法格式:
between and表示在什么什么之间的数据
select 字段名列表 from 表名 where 字段数据 between 条件 and 条件;
例子:查出工资在1100到3000之间的员工(左闭右开)
select ename,sal from emp where sal between 1100 and 3000;

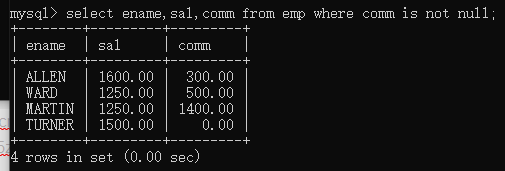
is null和is not null
语法格式:
数据库中0代表有数据的而null表示为空不是一个值
select 字段名列表 from 表名 where 字段数据 is null;
例子:
select ename,sal,comm from emp where comm is null;
select ename,sal,comm from emp where comm is not null;

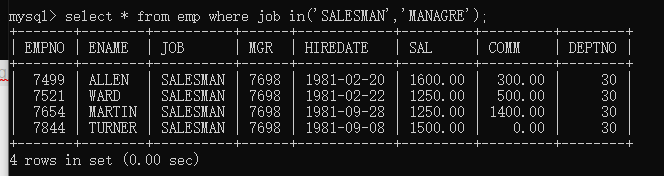
in语法格式
select 字段名列表 from 表名 where 字段数据 in(条件数据);
例子:
select * from emp where job in(‘SALESMAN’,‘MANAGRE’);
模糊查询
语法格式:
在模糊查询中两个特殊符号:%和_
%代表任意多个字符
_代表任意一个字符
select ename from emp where 字段数据 like 条件;
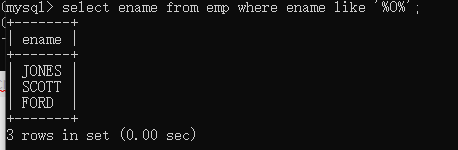
例子:查询名字中有O的
select ename from emp where ename like ‘%O%’;
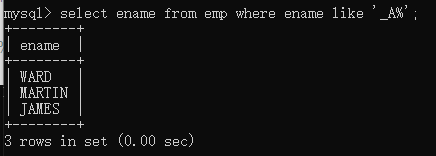
查出第二个字母是A的
select ename from emp where ename like ‘_A%’;
转义字符查出名字中带有_的
select ename from emp where ename like ‘%_%’
找出名字中最后一个字母是T的
select ename from emp where ename like ‘%T’;

数据排序
语法格式:
排序(升序asc,降序desc)默认是升序排序
select 字段列表 from 列表 order by 条件;
例子:
select ename,sal from emp order by sal;
select ename,sal from emp order by sal desc;
按照工资降序排序,如果工资相同则按照名字的升序排
select ename,sal from emp order by sal desc,ename asc;



分组函数
| 函数名 | 函数作用 |
|---|---|
| count() | 取个数 |
| sum() | 取和 |
| avg() | 取平均数 |
| max() | 取最大值 |
| min() | 取最小值 |
例子:
分组函数自动忽略空null
只要语句中有null出现和分组函数结果一定是null
要用到空处理函数ifnull(字段数据,指定数据)这个函数如果是null的话会转为指定数据
注意:分组函数没法在where条件使用
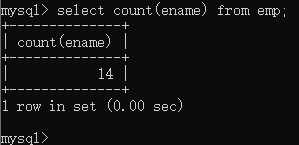
计算有多少位员工
select count(ename) from emp;
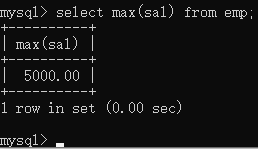
找出最高工资
select max(sal) from emp;
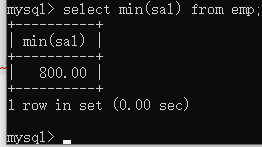
找出最低工资
select min(sal) from emp;
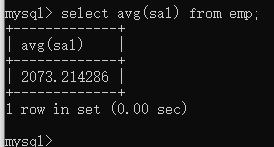
找出平均工资
select avg(sal) from emp;
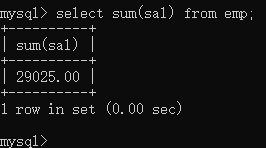
计算所有人工资总和
select sum(sal) from emp;
分组查询
group by 和 having
group by 是按照某个字段或某些字段进行分组
having是分组之后进行条件过滤的
语法格式:
select 字段名列表 from 表名 group by 字段数据 having 条件;
例子:按照工作岗位进行分组
select job from emp group by job;
找出每个岗位的最高薪资


多字段分组
找出每个部门不同工作岗位的最高薪资
select max(sal),job from emp group by job,deptno;

having和where选择
找出每个部门的最高薪资,要求显示薪资大于2900的数据
select max(sal) as maxsal,deptno from emp group by deptno having maxsal > 2900;
这种方式效率很低,建议直接用where条件,因为先执行大于2900的条件在进行分组查询,提前过滤掉条件

连接查询
笛卡尔积现象
笛卡尔积例子:
案例:找出每一个员工的部门名称,要求显示员工名和部门名
代码:select e.ename,d.dname from emp e,dept d;

如果两张表进行连接查询没有条件限制的话,查询结果条数是两张表的查询结果乘积
避免笛卡尔积现象方法:增加条件过滤(不会避免查询次数,但会优化查询结果)
select e.ename,d.dname from emp e,dept d where e. deptno = d.deptno;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k3KL0w2R-1638863732459)(../AppData/Roaming/Typora/typora-user-images/image-20211207120902240.png)]](https://img-blog.csdnimg.cn/6fd703cbfc5949e08a619130e06fb18b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
内连接
等值连接
特点:条件是等量关系
找出每一个员工的部门名称,要求显示员工名和部门名
语句:select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
两张表的deptno是等量关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-85paGscm-1638863732460)(../AppData/Roaming/Typora/typora-user-images/image-20211207121146020.png)]](https://img-blog.csdnimg.cn/eb5e417648b94653b25e247ea675fdb7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
非等值连接
特点:连接条件关系是非等量关系
案例:找出每个员工的工资等级,要求显示员工名,工资,工资等级
select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FYBQJUUJ-1638863732461)(../AppData/Roaming/Typora/typora-user-images/image-20211207135112067.png)]](https://img-blog.csdnimg.cn/3736707602c5407d83c556b87c5bf8ef.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
自连接
特点:一张表看做两张表,自己连自己
案例:找出每个员工的上级领导,要求显示员工名和对应的领导名
select a.ename,b.ename from emp a join emp b on a.mgr = b.empno;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uY1jwFSa-1638863732461)(../AppData/Roaming/Typora/typora-user-images/image-20211207135523709.png)]](https://img-blog.csdnimg.cn/297f353f030c45e8a97888903d890303.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
外连接
内外连接区别:
内连接:
? 假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,就是内连接
? AB表没有主副之分
外连接:
? 假设A和B表进行连接,使用外连接的话,AD表有一张是主表,主要查询主表中的数据
外连接的分类:左外连接(左表是主表),右外连接(右表是主表)
案例:找出每个员工的上级领导,要求显示员工名和对应的领导名(显示king)
select a.ename,b.ename from emp a left join emp b on a.mgr = b.empno;
使用左外连接(左表为主表,查询对应副表记录如果没有记录则用null表示):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dY5wNuC6-1638863732461)(../AppData/Roaming/Typora/typora-user-images/image-20211207140947467.png)]](https://img-blog.csdnimg.cn/3f241cbbb708468f8ed50856bb567fcd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
嵌套子查询
子查询是select语句中嵌套select语句,被嵌套的select语句是子查询
子查询可以出现在:select后,from后,where后
where子查询
案例:找出高于平均薪资的员工信息
select * from emp where sal > (select avg(sal) from emp);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VfoJ4cKz-1638863732462)(../AppData/Roaming/Typora/typora-user-images/image-20211207142530891.png)]](https://img-blog.csdnimg.cn/1d61de6ef99b4e419e96c1e5026f52c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
from子查询
案例:找出每个部门平均薪水的薪资等级
select * from salgrade s join (select deptno,avg(sal) as avgsal from emp group by deptno) t on t.avgsal between s.losal and s.hisal;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-imBrU9e3-1638863732462)(../AppData/Roaming/Typora/typora-user-images/image-20211207143050507.png)]](https://img-blog.csdnimg.cn/745c7efedabe476d9218ee03fc8b8d61.png)
select子查询
案例:找出每个员工所在的部门名称,要求显示员工名和部门名
select e.ename,(select d.dname from dept d where e.deptno = d.deptno) as dname from emp e;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VPhybZYR-1638863732462)(../AppData/Roaming/Typora/typora-user-images/image-20211207143617275.png)]](https://img-blog.csdnimg.cn/12524a00a9054c09a4afbee7b11cbc14.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
union
特点:可以将查询结果集相加
案例:找出工作岗位是SALESMAN和MANAGER的员工
select ename,job from emp where job = ‘SALESMAN’ union select ename,job from emp where job = ‘MANAGER’;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Izwdzq8O-1638863732463)(../AppData/Roaming/Typora/typora-user-images/image-20211207144110209.png)]](https://img-blog.csdnimg.cn/84966936caf04bf9aee319e5e5b4f96a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
注:使用union的时候字段数量必须一样
limit分页
limit取结果集中的部分数据
语法机制:limit startIndex length
startIndex 表示起始位置
length表示取几个
案例:取出工资前5名的员工
select ename,sal from emp order by sal desc limit 0,5;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bjuGL06i-1638863732463)(../AppData/Roaming/Typora/typora-user-images/image-20211207144601936.png)]](https://img-blog.csdnimg.cn/80da170dc93843d8848e9d5a338698c1.png)
表的操作
1:表的创建
建表语句格式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MBUca4RS-1638863732464)(../AppData/Roaming/Typora/typora-user-images/image-20211207145447468.png)]](https://img-blog.csdnimg.cn/3a8b58be8a4a41deb36a97d994843366.png)
字段的数据类型:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0lquilwe-1638863732464)(../AppData/Roaming/Typora/typora-user-images/image-20211207145602928.png)]](https://img-blog.csdnimg.cn/95d68037e5554b41b98cafd83f8d2d63.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yQe3iol8-1638863732465)(../AppData/Roaming/Typora/typora-user-images/image-20211207145918704.png)]](https://img-blog.csdnimg.cn/5ece51dd92b449649dd4858549cb8a69.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zQr97rqq-1638863732465)(../AppData/Roaming/Typora/typora-user-images/image-20211207145622971.png)]](https://img-blog.csdnimg.cn/c0912f6246cc4acebfd69d239720a8a3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATG90eg==,size_20,color_FFFFFF,t_70,g_se,x_16)
create table tbl_user
(
id bigint,
name varchar(255),
sex char(1)
);
2:向表中插入数据
语法格式:insert into 表名(字段名…) values(值…)
要求:字段要和值的数量相同,并且类型相同
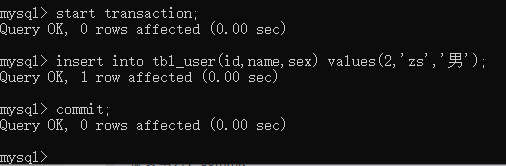
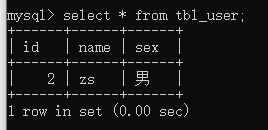
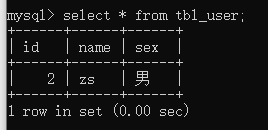
insert into tbl_user(id,name,sex) values(1,‘zs’,‘男’);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6LtjQ9Q-1638863732465)(../AppData/Roaming/Typora/typora-user-images/image-20211207152108275.png)]](https://img-blog.csdnimg.cn/33c3c0ec85544116a009415e15584e8f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VdKy7rlc-1638863732466)(../AppData/Roaming/Typora/typora-user-images/image-20211207152213386.png)]](https://img-blog.csdnimg.cn/3e18dfd14af84908acb1ffae92893b65.png)
3:表的复制以及批量插入
表的复制:
语法:
create table 表名 as select语句;
将查询出的结果当做表来创建
将查询结果插入到一张表中:
insert into 表名 select语句;
4:修改表的数据
语法格式:
update 表名 set 字段=值,字段=值 where 条件;
注:没有where条件整张表的数据全部更新
update tbl_user set name=‘李四’ where id = 1;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wl6Td0PS-1638863732466)(../AppData/Roaming/Typora/typora-user-images/image-20211207154144182.png)]](https://img-blog.csdnimg.cn/3f542a9e93b545138b75acee63095ccc.png)
5:删除表中的数据
语法格式:
delete from 表名 where 条件;
注:没有where条件删除所有数据
delete from tbl_user where id = 1;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9onS98ok-1638863732466)(../AppData/Roaming/Typora/typora-user-images/image-20211207154240121.png)]](https://img-blog.csdnimg.cn/9f375834403d477a9c7e4841963d2536.png)
截断表:truncate table 表名;
截断表是不能找回数据的,并且删除全部数据
常见约束
1:非空约束
语法:not null
(需要用户的id不能为空,必须有值):
create table tbl_user
(
id bigint not null,
name varchar(255),
sex char(1)
);
2:唯一性约束
特点:唯一约束修饰的字段不能唯一,不能重复,但可以为null
语法:
列级约束:
create table tbl_user
(
id bigint unique,
name varchar(255),
sex char(1)
);
表级约束:(如果约束两个字段,那这两个字段不能一起重复,有一个重复不算重复)
create table tbl_user
(
id bigint,
name varchar(255),
sex char(1),
unique(id)
);
3:主键约束
特点:不能重复,不能为空,为一行记录的唯一标识
语法:
列级约束:
create table tbl_user
(
id bigint primary key,
name varchar(255),
sex char(1)
);
主键的分类:
根据主键字段的字段数量来划分:
单一主键
复合主键(多个字段联合起来添加一个主键约束)
根据主键性质来划分:
自然主键
业务主键
一张表的主键约束只能有1个
4:主键值自增
特点:添加记录时不需要添加主键,主键会自己按照从小到大生成数字
语法:
create table tbl_user
(
id bigint auto_increment,
name varchar(255),
sex char(1)
);
5:外键约束
语法:foreign key
主表:
create table tbl_user
(
id bigint primary key,
name varchar(255),
sex char(1),
foreign key(no) references tbl_user1(no)
);
子表:
create table tbl_user1
(
no bigint primary key,
name varchar(255),
sex char(1)
);
注:被外键关联的字段不一定是主键,但至少具有unique约束
删除有外键约束的表时,需要先删除子表数据,再删除主表数据
添加时先添加主表,再添加字表
创建时必须先创建主表,再创建子表
事务
事务的概述
事务是一个完整的业务逻辑单元,不可再分
执行多条sql语句必须同时成功,或者同时失败,不允许出现一条成功,一条失败
想要保证多条sql语句同时成功或失败,那么就需要使用事务机制
只有DML语句才支持事务(insert delete update)
事务的四大特性
事务包括四大特性:ACID
A:原子性:事务是最小的工作单元,不可再分
C:一致性:事务必须保证多条DML语句同时成功或者同时失败
I:隔离性:事务A与事务B之间具有隔离
D:持久性:持久性是最终数据必须持久化到硬盘文件中,是事务的保障,事务才算成功(事务的提交)
事务的隔离性
隔离级别:一般都是从二级开始,mysql是三级起步
第一级别:读未提交(read uncommitted)
对方事务还未提交就可以读取到对方未提交的数据
读未提交存在脏读现象:不稳定
第二级别:读已提交(read committed)
对方提交的事务可以读取到
读已提交存在的问题:不可以重复读
第三级别:可重复读(repeatable read)
没有不可以重复读的问题
第四级别:序列化读
解决了所有问题
存在效率低的问题,需要事务排队执行
事务语法
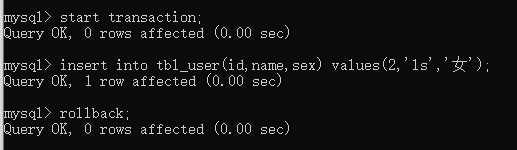
开启事务(关闭mysql的自动提交):start transaction
提交事务:commit
回滚事务:rollback

设置隔离级别
查看事务的全局隔离级别:select @@global.tx isolation
读未提交:set global transaction isolation level read uncommitted;
读已提交:set global transaction isolation level read committed;
可重复读:set global transaction isolation level repeatable read;
序列化读:set global transaction isolation level serializable;
索引
索引特点:
索引相当于一本书的目录,通过目录可以快速的找到对应的资源
在数据库方面,查询一张表有两种检索方式:
第一种方式:全表扫描
第二种方式:根据索引检索(效率高)
因为索引原理是缩小了扫描的范围
索引底层采用的数据结构是:B+Tree
给字段添加索引的条件:
1:数据量庞大
2:字段很少的DML操作
注:主键和unique约束的字段会自动添加索引
创建索引的语法:
create index 索引名 on 表名(字段名);
create index emp_index on emp(sal);
删除索引:
drop index 索引名 on 表名;
drop index emp_index on emp;
查询sql语句的执行计划:
explain select ename,sal from emp where sal = 5000;

rows扫描了14行记录
添加索引后的执行计划:

rows扫描了1行记录
索引的实现原理
通过B+Tree缩小扫描范围,底层索引进行了排序,分区,索引会携带数据在表中的物理地址
最终通过索引检索到数据之后,获取到关联的物理地址,通过物理地址定位表中的数据,效率是最高的
索引的分类
单一索引:给单个字段添加索引
复合索引:给多个字段联合添加一个索引
主键索引:主键上自动添加索引
唯一索引:unique约束的字段上会自动添加索引
索引的失效:模糊查询的时候,第一个通配符使用的是%,这个时候索引失效
识图
特点:
不会看到表的真实字段名
创建识图语法:
create view 视图名 as select 字段名 from 表名;
create view myview as select name from tbl_user;
更安全的方式(用n代表name的字段别名):create view myview as select name n from tbl_user;
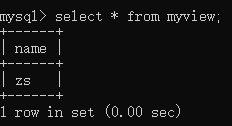
查看识图:select * from myview;

删除识图:
drop view 视图名;

对识图进行增删查改,会影响到原表数据
只能DQL语句才能以识图对象的方式创建出来(但可以对识图进行增删查改)
数据库设计三范式
设计范式:
按照三范式设计的表不会出现数据冗余
第一范式:任何一张表都应该有主键,并且每一个字段原子性不可再分
第二范式:建立在第一范式基础之上,所有非主键字段完全依赖主键,不能产生补分依赖(多对多,三张表,关系表两个外键)
第三范式:建立在第二范式基础之上,所有非主键字段直接依赖主键,不产生重复依赖
在实际开发中,以满足客户的需求为主,有的时候会拿冗余换执行速度