文章目录
1. 基本概念
Ignite是: 一个以内存为中心的分布式数据库、缓存和处理平台,可以在PB级数据中,以内存级的速度进行事务性、分析性以及流式负载的处理。

固化内存
Ignite的固化内存组件不仅仅将内存作为一个缓存层,还视为一个全功能的存储层。这意味着可以按需将持久化打开或者关闭。如果持久化关闭,那么Ignite就可以作为一个分布式的内存数据库或者内存数据网格,这完全取决于使用SQL和键-值API的喜好。如果持久化打开,那么Ignite就成为一个分布式的,可水平扩展的数据库,它会保证完整的数据一致性以及集群故障的可恢复能力。
Ignite持久化
Ignite的原生持久化是一个分布式的、支持ACID以及兼容SQL的磁盘存储,它可以作为一个可选的磁盘层与Ignite的固化内存透明地集成,然后将数据和索引存储在SSD、闪存、3D XPoint以及其它类型的非易失性存储中。
打开Ignite的持久化之后,就不需要将所有的数据和索引保存在内存中,或者在节点或者集群重启后对数据进行预热,因为固化内存和持久化紧密耦合之后,会将其视为一个二级存储层,这意味着在内存中数据和索引的一个子集如果丢失了,固化内存会从磁盘上进行获取。
ACID兼容
存储在Ignite中的数据,在内存和磁盘上是同时支持ACID的,使Ignite成为一个强一致的系统,Ignite可以在整个拓扑的多台服务器上保持事务。
完整的SQL支持
Ignite提供了完整的SQL、DDL和DML的支持,可以使用纯SQL而不用写代码与Ignite进行交互,这意味着只使用SQL就可以创建表和索引,以及插入、更新和查询数据。有这个完整的SQL支持,Ignite就可以作为一种分布式SQL数据库。
键-值
Ignite的内存数据网格组件是一个完整的事务型分布式键值存储,它可以在有几百台服务器的集群上进行水平扩展。在打开持久化时,Ignite可以存储比内存容量更大的数据,并且在整个集群重启之后仍然可用。
并置处理
大多数传统数据库是以客户机-服务器的模式运行的,这意味着数据必须发给客户端进行处理,这个方式需要在客户端和服务端之间进行大量的数据移动,通常来说不可扩展。而Ignite使用了另外一种方式,可以将轻量级的计算发给数据,即数据的并置计算,从结果上来说,Ignite扩展性更好,并且使数据移动最小化。
可扩展性和持久性
Ignite是一个弹性的、可水平扩展的分布式系统,它支持按需地添加和删除节点,Ignite还可以存储数据的多个副本,这样可以使集群从部分故障中恢复。如果打开了持久化,那么Ignite中存储的数据可以在集群的完全故障中恢复。Ignite集群重启会非常快,因为数据从磁盘上获取,瞬间就具有了可操作性。从结果上来说,数据不需要在处理之前预加载到内存中,而Ignite会缓慢地恢复内存级的性能。
安装启动
可以从下面的步骤开始:
- 从官网下载zip格式压缩包;
- 解压到系统中的一个安装文件夹;
- (可选)配置
IGNITE_HOME环境变量,指向安装文件夹,确保路径不以/结尾。
其它的安装选项 除了二进制包,Ignite还支持源代码安装、docker、云镜像以及RPM格式,具体可以看下面的说明。 在应用中,建议使用maven,后面会介绍。
下一步,使用默认的命令行接口可以启动第一个Ignite集群,还可以加上自定义的配置文件,可以启动任意多个节点,它们之间会自动发现。
使用默认的配置
使用默认的配置启动集群,打开命令行,转到IGNITE_HOME(Ignite安装文件夹),然后输入:
Linux:
$ bin/ignite.sh
Windows:
$ bin\ignite.bat
输出大致如下:
[02:49:12] Ignite node started OK (id=ab5d18a6)
[02:49:12] Topology snapshot [ver=1, nodes=1, CPUs=8, heap=1.0GB]
ignite.sh会使用config/default-config.xml这个默认配置文件启动节点。
传入配置文件
如果要使用一个定制配置文件,可以将其作为参数传给ignite.sh/bat,如下:
Linux:
$ bin/ignite.sh examples/config/example-ignite.xml
Windows:
$ bin\ignite.bat examples\config\example-ignite.xml
配置文件的路径,可以是绝对路径,也可以是相对于IGNITE_HOME(Ignite安装文件夹)的相对路径,也可以是类路径中的META-INF文件夹。
交互模式 如果要使用交互模式选择一个配置文件,传入-i参数即可,就是ignite.sh -i。
好,这样就成功了!
使用Maven
下一步是将Ignite嵌入自己的应用,Java中的最简单方式是使用Maven依赖系统。
Ignite中只有ignite-core模块是必须的,一般来说,要使用基于Spring的xml配置,还需要ignite-spring模块,要使用SQL查询,还需要ignite-indexing模块。
下面中的${ignite-version}需要替换为实际使用的版本。
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>
Maven****配置
关于如何包含个别的ignite maven模块的更多信息,可以参考Maven设置章节。
每个二进制包中,都会有一个示例工程,在开发环境中打开这个工程,然后转到{ignite_version}/examples文件夹找到pom.xml文件,依赖引入之后,各种示例就可以演示Ignite的各种功能了。
客户端和服务端
概述
Ignite有一个可选的概念,就是客户端节点和服务端节点,服务端节点参与缓存、计算执行、流式处理等等,而原生的客户端节点提供了远程连接服务端的能力。Ignite原生客户端可以使用完整的Ignite API集合,包括近缓存、事务、计算、流、服务等等。 所有的Ignite节点默认都是以服务端模式启动的,客户端模式需要显式地启用。
配置客户端和服务端
可以通过IgniteConfiguration.setClientMode(...)属性配置一个节点,或者为客户端,或者为服务端。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<!-- Enable client mode. -->
<property name="clientMode" value="true"/>
...</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();
// Enable client mode.
cfg.setClientMode(true);
// Start Ignite in client mode.
Ignite ignite = Ignition.start(cfg);
方便起见,也可以通过Ignition类来打开或者关闭客户端模式作为替代,这样可以使客户端和服务端共用一套配置。
Ignition.setClientMode(true);
// Start Ignite in client mode.
Ignite ignite = Ignition.start();
创建分布式缓存
当在Ignite中创建缓存时,不管是通过XML方式,还是通过Ignite.createCache(...)或者Ignite.getOrCreateCache(...)方法,Ignite会自动地在所有的服务端节点中部署分布式缓存。
当分布式缓存创建之后,它会自动地部署在所有的已有或者未来的服务端节点上。
// Enable client mode locally.
Ignition.setClientMode(true);
// Start Ignite in client mode.
Ignite ignite = Ignition.start();
CacheConfiguration cfg = new CacheConfiguration("myCache");
// Set required cache configuration properties....
// Create cache on all the existing and future server nodes.
// Note that since the local node is a client, it will not
// be caching any data.
IgniteCache<?, ?> cache = ignite.getOrCreateCache(cfg);
2. 键-值数据网格
数据网格
Ignite针对越来越火的水平扩展概念而构建,具有实时按需增加节点的能力。它可以支持线性扩展到几百个节点,通过数据位置的强语义以及关联数据路由来降低冗余数据噪声。
Ignite数据网格是一个基于内存的分布式键值存储,它可以视为一个分布式的分区化哈希,每个集群节点都持有所有数据的一部分,这意味着随着集群节点的增加,就可以缓存更多的数据。

与其它键值存储系统不同,Ignite通过可插拔的哈希算法来决定数据的位置,每个客户端都可以通过一个加入一个哈希函数决定一个键属于哪个节点,而不需要任何特定的映射服务器或者name节点。
Ignite数据网格支持本地、复制的、分区化的数据集,允许使用标准SQL语法方便地进行跨数据集查询,同时还支持在数据中进行分布式SQL关联。
Ignite数据网格轻量快速,是目前在集群中支持数据的事务性和原子性的最快的实现之一。
数据一致性 只要集群仍然处于活动状态,即使节点崩溃或者网络拓扑发生变化,Ignite都会保证不同集群节点中的数据的一致性。
JCache (JSR107) Ignite实现了JCache(JSR107)规范。
超越JCache
概述
Ignite是**JCache(JSR107)**规范的一个实现,JCache为数据访问提供了简单易用且功能强大的API。不过规范忽略了任何有关数据分布以及一致性的细节来允许开发商在自己的实现中有足够的自由度。
可以通过JCache实现:
- 基本缓存操作
- ConcurrentMap API
- 并行处理(EntryProcessor)
- 事件和度量
- 可插拔的持久化
在JCache之外,Ignite还提供了ACID事务,数据查询的能力(包括SQL),各种内存模型等。
IgniteCache
IgniteCache接口是Ignite缓存实现的一个入口,提供了保存和获取数据,执行查询,包括SQL,迭代和扫描等等的方法。 IgniteCache是基于**JCache(JSR107)**的,所以在非常基本的API上可以减少到javax.cache.Cache接口,不过IgniteCache还提供了JCache规范之外的、有用的功能,比如数据加载,查询,异步模型等。 可以从Ignite中直接获得IgniteCache的实例:
Ignite ignite = Ignition.ignite();
// Obtain instance of cache named "myCache".
// Note that different caches may have different generics.
IgniteCache<Integer, String> cache = ignite.cache("myCache");
动态缓存 也可以动态地创建缓存的一个实例,这时,Ignite会在所有的符合条件的集群成员中创建和部署该缓存。一个动态缓存启动后,它也会自动的部署到新加入的符合条件的节点上。
Ignite ignite = Ignition.ignite();
CacheConfiguration cfg = new CacheConfiguration();
cfg.setName("myCache");
cfg.setAtomicityMode(TRANSACTIONAL);
// Create cache with given name, if it does not exist.
IgniteCache<Integer, String> cache = ignite.getOrCreateCache(cfg);
XML****配置 在任意的缓存节点上定义的基于Spring的XML配置的所有缓存同时会自动地在所有的集群节点上创建和部署(不需要在每个集群节点上指定同样的配置)。
基本操作
下面是一些JCache基本原子操作的例子: Put和Get:
try (Ignite ignite = Ignition.start("examples/config/example-cache.xml")) {
IgniteCache<Integer, String> cache = ignite.cache(CACHE_NAME);
// Store keys in cache (values will end up on different cache nodes).
for (int i = 0; i < 10; i++)
cache.put(i, Integer.toString(i));
for (int i = 0; i < 10; i++)
System.out.println("Got [key=" + i + ", val=" + cache.get(i) + ']');
}
原子操作:
// Put-if-absent which returns previous value.
Integer oldVal = cache.getAndPutIfAbsent("Hello", 11);
// Put-if-absent which returns boolean success flag.
boolean success = cache.putIfAbsent("World", 22);
// Replace-if-exists operation (opposite of getAndPutIfAbsent), returns previous value.
oldVal = cache.getAndReplace("Hello", 11);
// Replace-if-exists operation (opposite of putIfAbsent), returns boolean success flag.
success = cache.replace("World", 22);
// Replace-if-matches operation.
success = cache.replace("World", 2, 22);
// Remove-if-matches operation.
success = cache.remove("Hello", 1);
死锁 如果批量(比如IgniteCache#putAll, IgniteCache#invokeAll等)操作以并行方式执行,那么键应该是有序的,以避免死锁,建议使用TreeMap而不是HashMap以保证一致性、有序性,注意这个对于原子化和事务化缓存都是一样的。
分区和复制
概述
Ignite提供了三种不同的缓存操作模式,分区、复制和本地。缓存模型可以为每个缓存单独配置,缓存模型是通过CacheMode枚举定义的。
数据分区内部实现 如果想了解Ignite分区的内部实现,以及再平衡的工作机制,可以看这个Wiki页面。
分区模式
分区模式是扩展性最好的分布式缓存模式,这种模式下,所有数据被均等地分布在分区中,所有的分区也被均等地拆分在相关的节点中,实际上就是为缓存的数据创建了一个巨大的内存内分布式存储。这个方式可以在所有节点上只要匹配总可用存储(内存和磁盘)就可以存储尽可能多的数据,因此,可以在集群的所有节点的内存中可以存储TB级的数据。也就是说,只要有足够多的节点,就可以存储足够多的数据。
与复制模式不同,它更新是很昂贵的,因为集群内的每个节点都需要更新,而分区模式更新就很廉价,因为对于每个键只需要更新一个主节点(可选择一个或者多个备份节点),不过读取变得较为昂贵,因为只有特定节点才持有缓存的数据。
为了避免额外的数据移动,总是访问恰好缓存有要访问的数据的节点是很重要的,这个方法叫做关联并置,当工作在分区化缓存时强烈建议使用。
分区化缓存适合于数据量很大而更新频繁的场合。
下图简单描述了一下一个分区缓存,实际上,键A赋予了运行在JVM1上的节点,B赋予了运行在JVM3上的节点,等等。
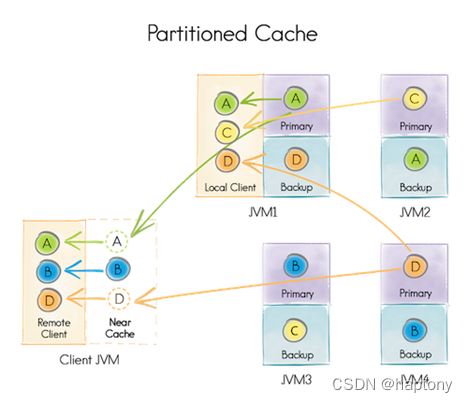
下面的配置章节显示了如何配置缓存模式的例子。
复制模式
复制模式中,所有数据都被复制到集群内的每个节点,因为每个节点都有效所以这个缓存模式提供了最大的数据可用性。不过这个模式每个数据更新都要传播到其它所有节点,因而会对性能和可扩展性产生影响。
Ignite中,复制缓存的实现类似于分区缓存,每个键都有一个主拷贝而且在集群内的其它节点也会有备份。比如下图中,对于键A,运行于JVM1的节点为主节点,但是同时它还存储了其它数据的拷贝(B、C、D)。
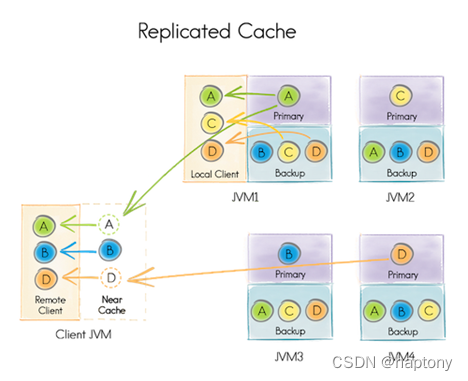
因为相同的数据被存储在所有的集群节点中,复制缓存的大小受到节点的有效存储(内存和磁盘)的限制。这个模式适用于读缓存比写缓存频繁的多而且数据集较小的场景,如果应用超过80%的时间用于查找缓存,那么就要考虑使用复制缓存模式了。
复制缓存适用于数据集不大而且更新不频繁的场合。
本地模式
本地模式是最轻量的模式,因为没有数据被分布化到其它节点。它适用于或者数据是只读的,或者需要定期刷新的场景中。当缓存数据失效需要从持久化存储中加载数据时,它也可以工作与通读模式。除了分布化以外,本地缓存包括了分布式缓存的所有功能,比如自动数据回收,过期,磁盘交换,数据查询以及事务。
配置
缓存可以每个缓存分别配置,通过设置CacheConfiguration的cacheMode属性实现:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- Set a cache name. -->
<property name="name" value="cacheName"/>
<!-- Set cache mode. -->
<property name="cacheMode" value="PARTITIONED"/>
<!-- Other cache configurations. -->
...
</bean>
</property>
</bean>
Java:
CacheConfiguration cacheCfg = new CacheConfiguration("myCache");
cacheCfg.setCacheMode(CacheMode.PARTITIONED);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCacheConfiguration(cacheCfg);
// Start Ignite node.
Ignition.start(cfg);
主备副本
概述
在分区模式下,赋予键的节点叫做这些键的主节点,对于缓存的数据,也可以有选择地配置任意多个备份节点。如果副本数量大于0,那么Ignite会自动地为每个独立的键赋予备份节点,比如,如果副本数量为1,那么数据网格内缓存的每个键都会有2个备份,一主一备。
因为性能原因备份默认是被关闭的。
配置备份
备份可以通过CacheConfiguration的backups属性进行配置,像下面这样:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- Set a cache name. -->
<property name="name" value="cacheName"/>
<!-- Set cache mode. -->
<property name="cacheMode" value="PARTITIONED"/>
<!-- Number of backup nodes. -->
<property name="backups" value="1"/>
...
</bean>
</property>
</bean>
Java:
CacheConfiguration cacheCfg = new CacheConfiguration();
cacheCfg.setName("cacheName");
cacheCfg.setCacheMode(CacheMode.PARTITIONED);
cacheCfg.setBackups(1);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCacheConfiguration(cacheCfg);
// Start Ignite
node.Ignition.start(cfg);
同步和异步备份
CacheWriteSynchronizationMode枚举可以用来配置主备之间的同步和异步更新。同步写模式告诉Ignite在完成写或者提交之前客户端节点是否要等待来自远程节点的响应。
同步写模式可以设置为下面的三种之一:
| 同步写模式 | 描述 |
|---|---|
FULL_SYNC | 客户端节点要等待所有相关远程节点的写入或者提交完成(主和备)。 |
FULL_ASYNC | 这种情况下,客户端不需要等待来自相关节点的响应。这时远程节点会在获得它们的状态在任意的缓存写操作完成或者Transaction.commit()方法调用完成之后进行小幅更新。 |
PRIMARY_SYNC | 这是默认模式,客户端节点会等待主节点的写或者提交完成,但不会等待备份节点的更新完成。 |
缓存数据一致性 注意不管那种写同步模式,在使用事务时缓存数据都会保持在所有相关节点上的完整一致性。
写同步模式可以通过CacheConfiguration的writeSynchronizationMode属性进行配置,像下面这样:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- Set a cache name. -->
<property name="name" value="cacheName"/>
<!-- Set write synchronization mode. -->
<property name="writeSynchronizationMode" value="FULL_SYNC"/>
...
</bean>
</property>
</bean>
Java:
CacheConfiguration cacheCfg = new CacheConfiguration();
cacheCfg.setName("cacheName");
cacheCfg.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCacheConfiguration(cacheCfg);
// Start Ignite
node.Ignition.start(cfg);