一,kafka producer基本使用
kafka生产则代码如下:
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties conf = new Properties();
conf.setProperty(ProducerConfig.ACKS_CONFIG, "0");
conf.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
conf.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
conf.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
conf.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(conf);
ProducerRecord<String, String> msg = new ProducerRecord<String, String>("topic", "key", "value");
Future<RecordMetadata> future = producer.send(msg);
RecordMetadata recordMetadata = future.get();
// Future<RecordMetadata> send = producer.send(msg, new Callback() {
// @Override
// public void onCompletion(RecordMetadata metadata, Exception exception) {
//
// }
// });
}
从上面的 API 可以得知,用户在使用 KafkaProducer 发送消息时,首先需要将待发送的消息封装成 ProducerRecord,返回的是一个 Future 对象,典型的 Future 设计模式。在发送时也可以指定一个 Callable 接口用来执行消息发送的回调。
我们看一下ProducerRecord构造函数:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {...}
- topic:消息所属的主题。
- partition:可以直接指定msg发送到哪个分区,如果不指定partition而指定key,会使用key的hashCode与队列总数进行取模来选择分区,如果前面两者都未指定,则会轮询主题下的所有分区。
- timestamp:消息时间戳,根据 topic 的配置信息 message.timestamp.type 的值来赋予不同的值。CreateTime:发送客户端发送消息时的时间戳。LogAppendTime:消息在 broker 追加时的时间戳。
- key:消息键,如果指定该值,则会使用该值的 hashcode 与 队列数进行取模来选择分区。
- value:消息体。
- headers:该消息的额外属性对,与消息体分开存储,是一系列的 key-value 键值对。
二,kafka send源码分析
KafkaProducer 的 send 方法,并不会直接向 broker 发送消息,kafka 将消息发送异步化,即分解成两个步骤:
- send 方法的职责是将消息追加到内存中(分区的缓存队列中)。
- 由专门的 Send 线程异步将缓存中的消息批量发送到 Kafka Broker 中。
send方法
public class KafkaProducer<K, V> implements Producer<K, V> {
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 获取 topic 的分区列表,如果本地没有该topic的分区信息,则需要向远端 broker 获取,
// 该方法会返回拉取元数据所耗费的时间。在消息发送时的最大等待时间时会扣除该部分损耗的时间。
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
Cluster cluster = clusterAndWaitTime.cluster;
// key value序列化,用于后面网络发送.
// 注意:参与序列化的只有key value
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
}
// 根据分区负载算法计算本次消息发送该发往的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// 根据使用的版本号,按照消息协议来计算消息的长度,并是否超过指定长度,如果超过则抛出异常。
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
// 对传入的 Callable(回调函数) 加入到拦截器链中
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 如果事务处理器不为空,执行事务管理相关的
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
// 将消息追加到缓存区,如果当前缓存区已写满或创建了一个新的缓存区,则唤醒 Sender(消息发送线程),
// 将缓存区中的消息发送到 broker 服务器,最终返回 future。
// 从这里也能得知,doSend 方法执行完成后,此时消息还不一定成功发送到 broker。
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 由于目标partition的当前batch没有空间了,需要更换一个partition,再次尝试
if (result.abortForNewBatch) {
int prevPartition = partition;
// 更换目标partition,同时也会更换StickyPartitionCache黏住的partition
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// 计算新的目标partition
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 再次调用append()方法向RecordAccumulator写入message,如果该partition缓冲区中的batch也没有空间,
// 则创建新batch了,不会再次尝试了
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}
}
}
以上send核心方法主要分为如下几步:
- 获取 topic 的分区列表,如果本地没有该topic的分区信息,则需要向远端 broker 获取。
- 根据分区负载算法计算本次消息发送该发往的分区。
- 将消息追加到缓存区,如果当前缓存区已写满或创建了一个新的缓存区,则唤醒 Sender(消息发送线程),将缓存区中的消息发送到 broker 服务器,最终返回 future。
三,waitOnMetadata获取元数据
在我们通过 KafkaProducer 发送 message 的时候,我们只明确指定了 message 要写入哪个 topic ,并没有明确指定要写入的 partition。
但是同一个 topic 的 partition 可能位于 kafka 的不同 broker 上,所以 producer 需要明确的知道该 topic 下所有 partition 的元信息(即所在 broker 的 IP、端口等信息),这样才能与 partition 所在 broker 建立网络连接并发送 message。
在 KafkaProducer 中,使用 Node、TopicPartition、PartitionInfo 三个类来记录 Kafka 集群元数据:
- Node 表示 kafka 集群中的一个节点,其中维护了节点的 host、ip、port 等基础信息。
- TopicPartition 用来抽象一个 topic 中的的一个 partition,其中维护 topic 的名称以及 partition 的编号信息。
- PartitionInfo 用来抽象一个 partition 的信息,其中:leader 字段记录了 leader replica 所在节点的 id;replica 字段记录了全部 replica 所在的节点信息;inSyncReplicas 字段记录了 ISR 集合中所有 replica 所在的节点信息。
kafka producer 会将上述三个维度的基础信息封装成 Cluster 对象使用,下面是 Cluster 包含的信息:
public final class Cluster {
// 标识当前元数据信息是初始化的配置还是启动之后的
private final boolean isBootstrapConfigured;
// kafka集群中全部Node的集合
private final List<Node> nodes;
// topic信息,这里根据topic属性进行分类
private final Set<String> unauthorizedTopics;
private final Set<String> invalidTopics;
private final Set<String> internalTopics;
// kafka集群中controller所在的节点
private final Node controller;
// 可以根据TopicPartition来查询该partition的具体信息
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition;
// 根据topic来查询其下partition具体信息数组
private final Map<String, List<PartitionInfo>> partitionsByTopic;
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic;
// 根据nodeId来查询落到其上的partition具体信息数组
private final Map<Integer, List<PartitionInfo>> partitionsByNode;
// 根据nodeId来查询Node对象
private final Map<Integer, Node> nodesById;
// 集群的唯一标识
private final ClusterResource clusterResource;
// 维护了topic名称和唯一标识
private final Map<String, Uuid> topicIds;
}
再向上一层,Cluster 对象会被维护到 Metadata 中,Metadata 同时还维护了 Cluster 的版本号、过期时间、监听器等等信息,如下图所示:
public class Metadata implements Closeable {
// 两次更新元数据最小时间差,默认是100ms,这是为了防止更新就操作过于频繁而造成网络阻塞和服务端压力
private final long refreshBackoffMs;
// 元数据失效时间,需要更新元数据的时间间隔,默认5分钟
private final long metadataExpireMs;
...
// 原数据缓存,更新的元数据都在MetadataCache中村粗
private MetadataCache cache = MetadataCache.empty();
...
}
接下来,我们来看 KafkaProducer.waitOnMetadata()方法是如何工作的:
public class KafkaProducer<K, V> implements Producer<K, V> {
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// 先去本地获取cluster信息,如果是第一次获取集群信息,那么应该只有我们本地配置的cluster node信息。
Cluster cluster = metadata.fetch();
// 省略部分源码...
do {
metadata.add(topic, nowMs + elapsed);
int version = metadata.requestUpdateForTopic(topic);
// 唤醒Sender线程,由Sender线程去完成元数据的更新
sender.wakeup();
// 阻塞等待元数据更新,停止阻塞的条件是:更新后的updateVersion大于当前version,超时的话会直接抛出异常
try {
metadata.awaitUpdate(version, remainingWaitMs);
}
// 获取更新最新的cluster信息
cluster = metadata.fetch();
elapsed = time.milliseconds() - nowMs;
// 获取当前topic下的分区数量
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
return new ClusterAndWaitTime(cluster, elapsed);
}
}
以上代码主要完成对sender线程的唤醒,阻塞等待sender线程去broker拉取最新的cluster元数据信息,并返回。
由于Sender线程内容太多,我们放到后面来章节来详细分析。
此时我们应该知道,发送msg之前我们要先获取cluster集群的元数据信息,然后再根据TopicPartition来获取具体要发送到哪个broker上,根据目标broker的ip,port来建立socket链接,然后发送msg。
四,partition 选择
在 waitOnMetadata() 方法拿到最新的集群元数据之后,下面就要开始确定待发送的 message 要发送到哪个 partition 了。
如果我们明确指定了目标 partition,则以用户指定的为准,但是一般情况下,业务并不会指定 message 需要写入到哪个 partition,此时就会通过 Partitioner 接口结合元数据计算出一个目标 partition。
public interface Partitioner extends Configurable, Closeable {
// 根据传参获取一个分区
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
void close();
default void onNewBatch(String topic, Cluster cluster, int prevPartition) {
}
}
Partitioner接口实现类可以通过KafkaProducer配置项partitioner.class指定,默认值为DefaultPartitioner,其主要功能为:
- 如果 message 存在的 key 的话,则取 key 的 hash 值(使用的是 murmur2 这种高效率低碰撞的 Hash 算法),然后与 partition 总数取模,得到目标 partition 编号,这样可以保证同一 key 的 message 进入同一 partition。
- 如果 message 没有 key,则通过 StickyPartitionCache.partition() 方法计算目标 partition。
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
public void configure(Map<String, ?> configs) {}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
public void close() {}
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
}
这里解释一下 StickyPartitionCache 的功能,RecordAccumulator 是一个缓冲区,主线程发送的 message 会先进入 RecordAccumulator,然后 Sender 线程攒够了 message 的时候进行批量发送。
触发 Sender 线程批量发送堆积 message 的条件主要有两方面:
- message 的延迟时间到了,也就是说,我们的业务场景对 message 发送有延迟要求,message 不能一直在 producer 端缓存。我们可以通过 linger.ms 配置降低 message 的发送延迟。
- message 堆积的足够多,达到了一定阈值,才适合批量发送,这样有效负载较高。批量发送的 batch.size 默认值是 16KB。
StickyPartitionCache 主要实现的是"黏性选择",就是尽可能的先往一个 partition 发送 message,让发往这个 partition 的缓冲区快速填满,这样的话,就可以降低 message 的发送延迟。我们不用担心出现 partition 数据量不均衡的情况,因为只要业务运行时间足够长,message 还是会均匀的发送到每个 partition 上的。
下面来看 StickyPartitionCache 的实现,其中维护了一个 ConcurrentMap(indexCache 字段),key 是 topic,value 是当前黏住了哪个 partition。
public class StickyPartitionCache {
private final ConcurrentMap<String, Integer> indexCache;
public StickyPartitionCache() {
this.indexCache = new ConcurrentHashMap<>();
}
public int partition(String topic, Cluster cluster) {
// 先从 indexCache 字段中获取黏住的 partition
Integer part = indexCache.get(topic);
// 如果没有,则调用 nextPartition() 方法向 indexCache 中写入一个.
if (part == null) {
return nextPartition(topic, cluster, -1);
}
return part;
}
// 在 nextPartition() 方法中,会先获取目标 topic 中可用的 partition,并从中随机选择一个写入 indexCache
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = indexCache.get(topic);
Integer newPart = oldPart;
if (oldPart == null || oldPart == prevPartition) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
} else if (availablePartitions.size() == 1) {
newPart = availablePartitions.get(0).partition();
} else {
while (newPart == null || newPart.equals(oldPart)) {
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
// Only change the sticky partition if it is null or prevPartition matches the current sticky partition.
if (oldPart == null) {
indexCache.putIfAbsent(topic, newPart);
} else {
indexCache.replace(topic, prevPartition, newPart);
}
return indexCache.get(topic);
}
return indexCache.get(topic);
}
}
在 partition() 方法中,StickyPartitionCache 会先从 indexCache 字段中获取黏住的 partition,如果没有,则调用 nextPartition() 方法向 indexCache 中写入一个。在 nextPartition() 方法中,会先获取目标 topic 中可用的 partition,并从中随机选择一个写入 indexCache。
那么,什么时候更新黏住的 partition 呢?我们看一下 KafkaProducer.doSend()方法中,有这么一个片段:
// 尝试向RecordAccumulator中追加message
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 由于目标partition的当前batch没有空间了,需要更换一个partition,再次尝试
if (result.abortForNewBatch) {
int prevPartition = partition;
// 更换目标partition,同时也会更换StickyPartitionCache黏住的partition
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// 计算新的目标partition
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 再次调用append()方法向RecordAccumulator写入message,如果该partition缓冲区中的batch也没有空间,
// 则创建新batch了,不会再次尝试了
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
五,append 消息
业务线程使用 KafkaProducer.send() 方法发送 message 的时候,会先将其写入RecordAccumulator 中进行缓冲,当 RecordAccumulator 中缓存的 message 达到一定阈值的时候,会由 IO 线程批量形成请求,发送到 kafka 集群。
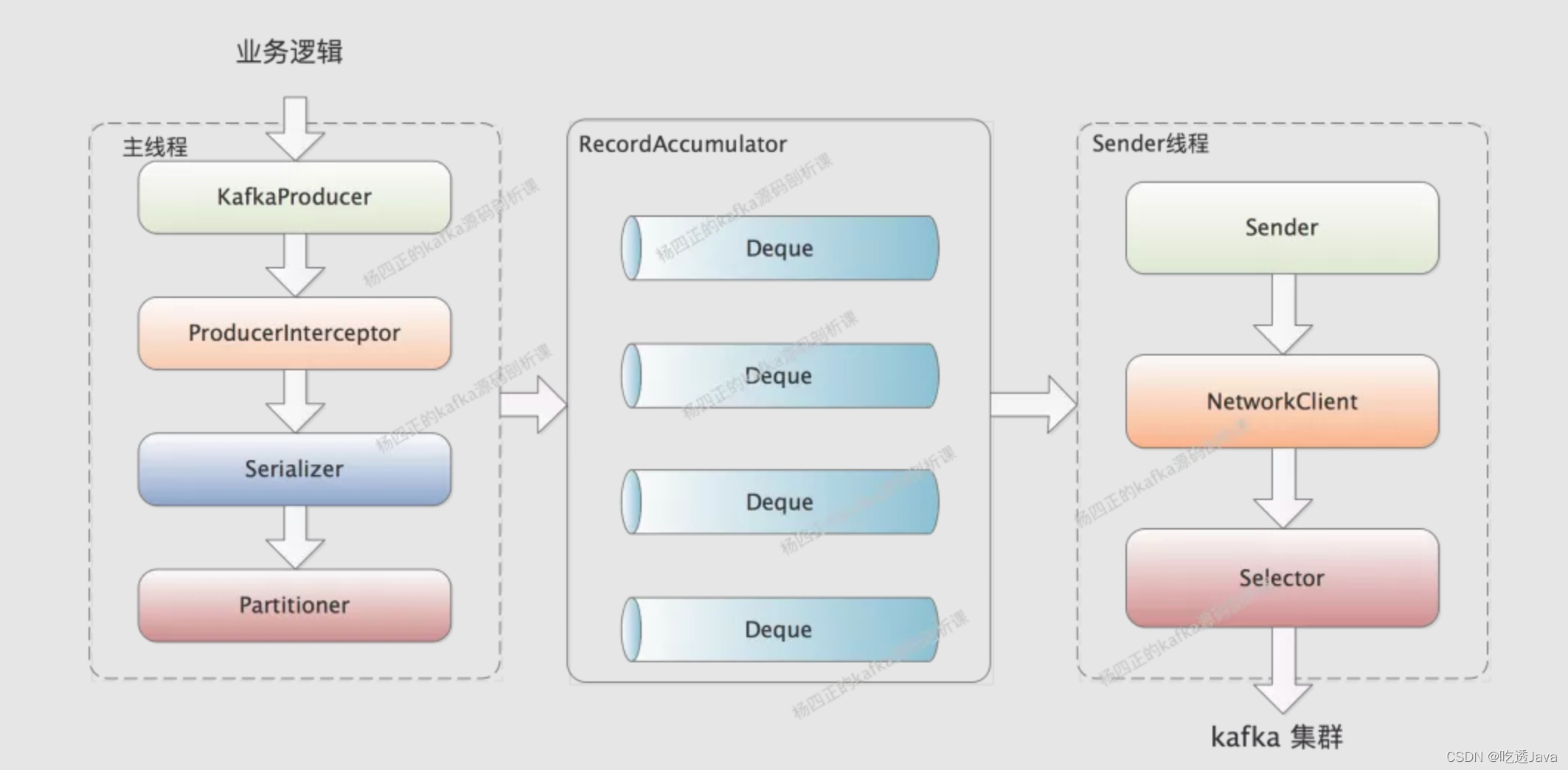
我们从上图中可以看出,RecordAccumulator 会由业务线程写入、Sender 线程读取,这是一个非常明显的生产者-消费者模式,所以我们需要保证 RecordAccumulator 是线程安全的。
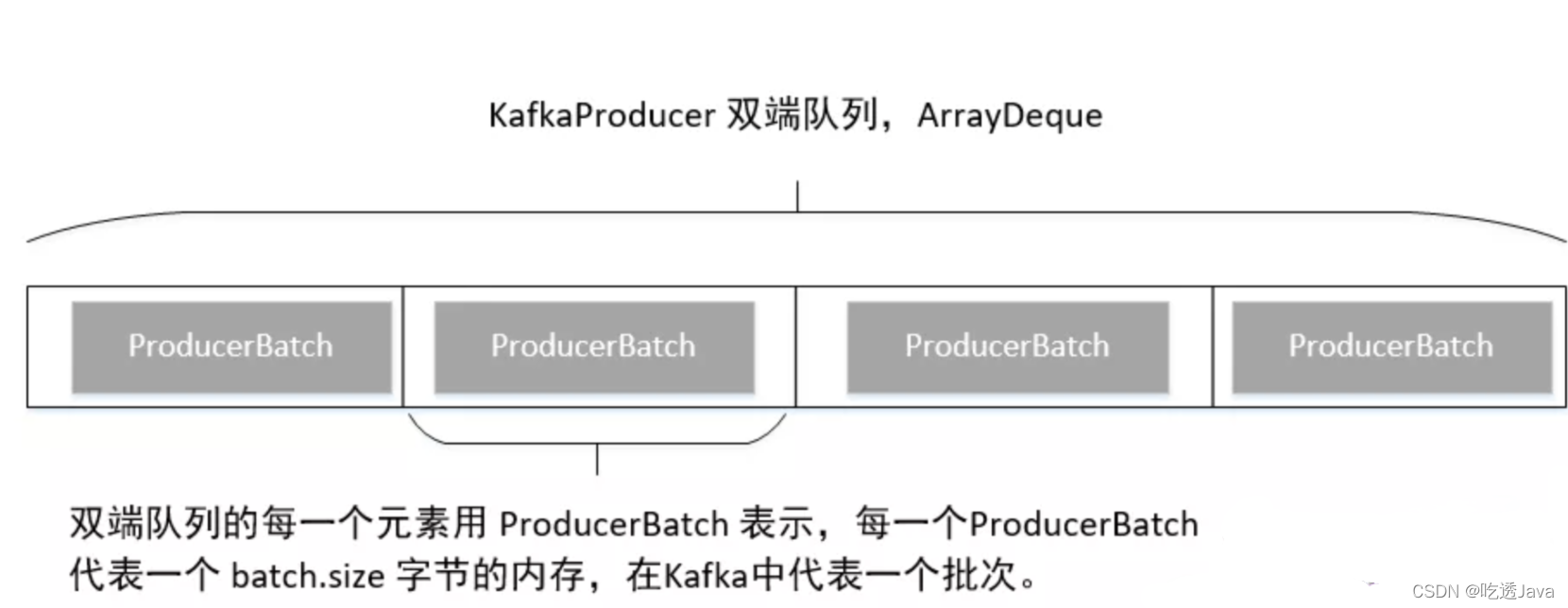
RecordAccumulator 中维护了一个 ConcurrentMap<TopicPartition, Deque> 类型的集合,其中的 Key 是 TopicPartition 用来表示目标 partition,Value 是 ArrayDeque 队列,用来缓冲发往目标 partition 的消息。这里的 ArrayDeque 并不是线程安全的集合,后面我们会看到加锁的相关操作。
步骤1
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
尝试根据 topic与分区在 kafka 中获取一个双端队列,如果不存在,则创建一个,然后调用 tryAppend 方法将消息追加到缓存中。Kafka 会为每一个 topic 的每一个分区创建一个消息缓存区,消息先追加到缓存中,然后消息发送 API 立即返回,然后由单独的线程 Sender 将缓存区中的消息定时发送到 broker 。这里的缓存区的实现使用的是 ArrayQeque。然后调用 tryAppend 方法尝试将消息追加到其缓存区,如果追加成功,则返回结果。
我们先来看一下 Kafka 双端队列的存储结构:
步骤2
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(),tp.partition());
buffer = free.allocate(size, maxTimeToBlock);
如果第一步未追加成功,说明当前没有可用的 ProducerBatch,则需要创建一个 ProducerBatch,故先从 BufferPool 中申请 batch.size 的内存空间,为创建 ProducerBatch 做准备,如果由于 BufferPool 中未有剩余内存,则最多等待 maxTimeToBlock ,如果在指定时间内未申请到内存,则抛出异常。
步骤3
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 省略部分代码
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
创建一个新的批次 ProducerBatch,并将消息写入到该批次中,并返回追加结果,这里有如下几个关键点:
- 创建 ProducerBatch ,其内部持有一个 MemoryRecordsBuilder对象,该对象负责将消息写入到内存中,即写入到 ProducerBatch 内部持有的内存,大小等于 batch.size。
- 将消息追加到 ProducerBatch 中。
- 将新创建的 ProducerBatch 添加到双端队列的末尾。
- 将该批次加入到 incomplete 容器中,该容器存放未完成发送到 broker 服务器中的消息批次,当 Sender 线程将消息发送到 broker 服务端后,会将其移除并释放所占内存。
- 返回追加结果。
纵观 RecordAccumulator append 的流程,基本上就是从双端队列获取一个未填充完毕的 ProducerBatch(消息批次),然后尝试将其写入到该批次中(缓存、内存中),如果追加失败,则尝试创建一个新的 ProducerBatch 然后继续追加。
接下来我们继续探究如何向 ProducerBatch 中写入消息。
tryAppend方法详解
RecordAccumulator#tryAppend()方法会调用ProducerBatch#tryAppend()方法进行消息追加,所以这里直接来看ProducerBatch#tryAppend()方法
public final class ProducerBatch {
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
// 首先判断 ProducerBatch 是否还能容纳当前消息,如果剩余内存不足,将直接返回 null。
// 如果返回 null ,会尝试再创建一个新的ProducerBatch。
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
// 通过 MemoryRecordsBuilder 将消息写入按照 Kafka 消息格式写入到内存中
this.recordsBuilder.append(timestamp, key, value, headers);
// 更新 ProducerBatch 的 maxRecordSize、lastAppendTime 属性,
// 分别表示该批次中最大的消息长度与最后一次追加消息的时间
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers));
this.lastAppendTime = now;
// 构建 FutureRecordMetadata 对象
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
Time.SYSTEM);
// 将 callback 、本条消息的凭证(Future) 加入到该批次的 thunks 中,该集合存储了 一个批次中所有消息的发送回执
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
}
- 首先判断 ProducerBatch 是否还能容纳当前消息,如果剩余内存不足,将直接返回 null。如果返回 null ,会尝试再创建一个新的ProducerBatch。
- 通过 MemoryRecordsBuilder 将消息写入按照 Kafka 消息格式写入到内存中,即写入到 在创建 ProducerBatch 时申请的 ByteBuffer 中。
- 更新 ProducerBatch 的 maxRecordSize、lastAppendTime 属性,分别表示该批次中最大的消息长度与最后一次追加消息的时间。
- 构建 FutureRecordMetadata 对象,这里是典型的 Future模式,里面主要包含了该条消息对应的批次的 produceFuture、消息在该批消息的下标,key 的长度、消息体的长度以及当前的系统时间。
- 将 callback 、本条消息的凭证(Future) 加入到该批次的 thunks 中,该集合存储了 一个批次中所有消息的发送回执。
流程执行到这里,KafkaProducer 的 send 方法就执行完毕了,返回给调用方的就是一个 FutureRecordMetadata 对象。
注意:本文参考了《丁威的kafka源码解读》