1 NN��2NN�����ø���
NameNode (nn):����Master,����һ�����ܡ�������- ����
HDFS�����ƿռ� - ���ø�������
- �������ݿ�(
Block)ӳ����Ϣ - �����ͻ��˶�д����
- ����
Secondary NameNode:����NameNode���ȱ�����NameNode�ҵ���ʱ��,�������������滻NameNode���ṩ����- ����
NameNode,�ֵ��乤����,���綨�ںϲ�fsimage��fdits,������NameNode - �ڽ��������,�ɸ����ָ�
NameNode
- ����
fsimage : ������NameNode����ʱ�������ļ�ϵͳ�Ŀ���
edit:������NameNode������,���ļ�ϵͳ�ĸĶ�����
2 ����ԭ��
NameNode�洢Ŀ¼������Ϣ,��Ŀ¼������Ϣ������fsimage�ļ���,��NameNode������ʱ������ȶ�ȡ����fsimage�ļ�,����Ϣװ�ص��ڴ���edits�ļ��洢��־��Ϣ,��NameNode�����ж�Ŀ¼�IJ���,����,ɾ��,�ĵȶ��ᱣ�浽edits�ļ���,������ͬ����fsimage��,��NameNode�رյ�ʱ��,Ҳ���Ὣfsimage��edits���кϲ�
�ͻ��˵IJ���������д�뵽
edits�ļ���,Ȼ���ٽ��в����ڴ��е�����
- ���Ե�
NameNode������ʱ��,����װ��fsimage�ļ�,Ȼ����edits�еļ�¼ִ��һ�����м�¼�IJ���,������Ϣ��Ŀ¼��д��fsimage��,��ɾ��edits�ļ�,���������µ�edits�ļ� - ����úϲ�����ֻ��
NameNodeȥ��,��ô�ͻ�����NameNode��ѹ��,��Ϊ������Ҫ�����ϲ���Ҫ�����ͻ��˵����� - ��������
NameNode��fsimage��edits�ϲ�ֻ��NameNode������ʱ��Ż����,��������������,����NameNode��ʱ��edits�����dz���,��edits�б�����Dz�����ص�,����Ҳ���������ظ��Բ���,��ζ�������ù������Ч�� Secondary NameNode��ְ��ֵ�NameNode��ѹ��,��һ�������ϲ�NameNode��edits��fsimage�ļ��С����Һϲ����̲�Ӱ��NameNode�IJ���- �ϲ��ϲ�����:
- �����˶�ʱ,��ʱʱ�䵽��������ļ������кϲ�
edits�ļ���"��������",����ﵽһ���IJ�������
������ϸ���ܶ��߹���������
3 NNԪ������Ϣά��������?
- ����������ݵĿɿ���,��Ҫ��Ԫ����ά��������.�����������ǶԴ��̵�������Ч�ʵ�
- ����������ݷ��ʺ��ĵ�Ч��,��Ҫ��Ԫ����ά�����ڴ档���������������ݲ��ɿ�
- �ۺϿ���:����+�ڴ�
4 ����ͬʱά�������̺��ڴ����������
4.1 ��α�֤�ڴ�ʹ������ݵ�ͬ��
��������:��Ϊ���ݵĿɿ�����Ҫ������д�뵽������,���ǵ��������ݵ�Ч�ʾ���Ҫ������д�뵽�ڴ���,���ս��ڴ������д�뵽������,��ô���������ͬ���Ļ�,�ͻ�������ݶ�ʧ�Լ��ظ�д���ݵĿ�����
����: ���ڴ���ά��Ԫ����,���ڴ�����ͨ��fsimage(�����ļ�)��ά��Ԫ����,����ͨ��edits(�༭��־)�ļ���¼��Ԫ���ݵ��IJ���,��¼�ķ�ʽΪ�ļ�ĩβ�Ӳ�����Ԫ������Ϣ���Դ����ڴ���,fsimage(�����ļ�)��edits(�༭��־)���ڴ�����,�����ݵIJ���ֱ���ӵ�edits�ļ�ĩβ,������д��Ҫ��ܶ�
4.2 edits�ļ��м�¼�IJ���Խ��Խ����ô��?
��������:fsimage��edits�ϲ�ֻ��NameNode������ʱ��Ż����,���NameNode����,��ô����������,����NameNode��ʱ��edits�����dz���,��edits�б�����Dz�����ص�,����Ҳ���������ظ��Բ���,��ζ�������ù������Ч��
����:Secondary NameNode����NameNode�ϲ��ļ�
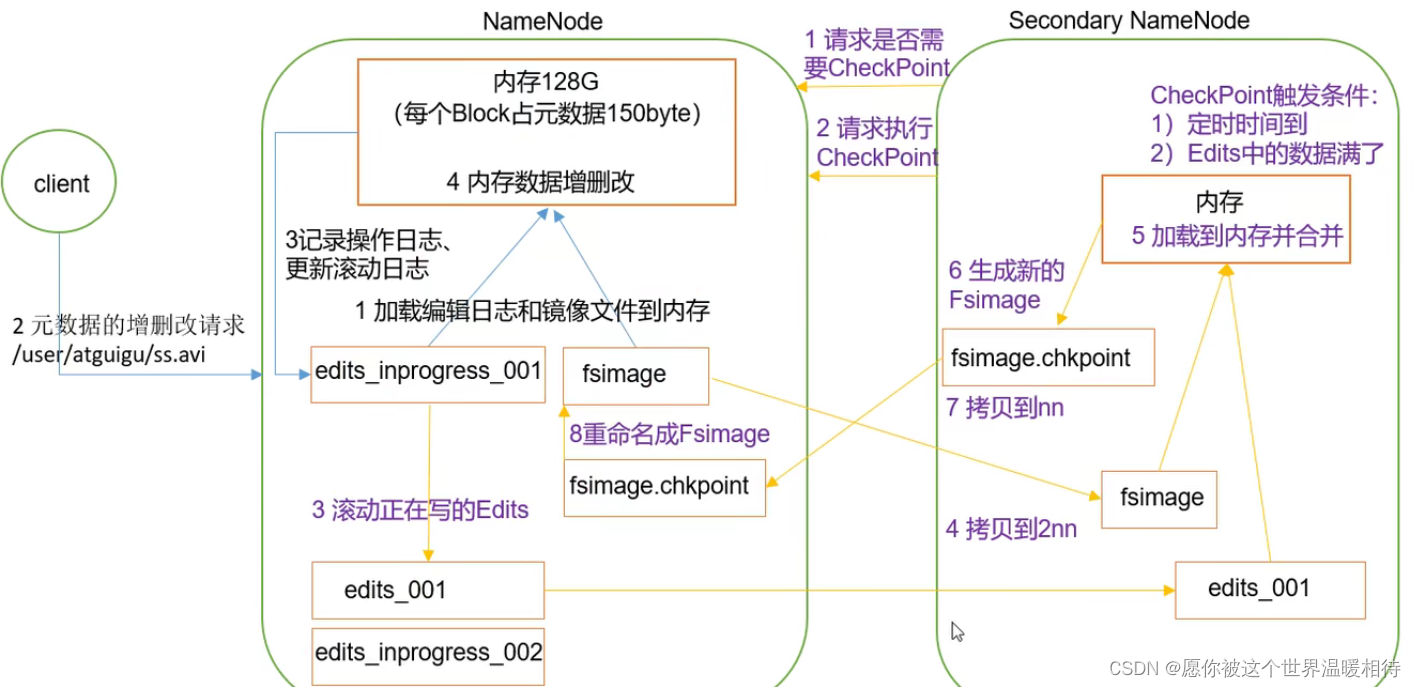
5 Secondary NameNode��������
Secondary NameNode�����Ƿ���ҪCheckPoint(Ҳ���Ǻϲ�������ļ��Ĺ���),NameNode�ظ�ִ��Secondary NameNode֪ͨNameNode���ύedits�ļ�,�����ʱ�ı༭��־�ļ���edits_inprogress_001,���еĿͻ��˵IJ��������ӵ�����־��,��NameNode�ύedits��־�ļ���ʱ�����־�Ͷ���Ϊedits_001,������������edits_inprogress_002,�������ύ��Secondary NameNode,�µIJ�����Ϣ�浽�µ���־�ļ���SecondaryNameNodeͨ��http get��ʽ��ȡNameNode��fsimage��edits�ļ�(��Secondary NameNode��currentͬ��Ŀ¼�¿ɼ���temp.check-point����previous-checkpointĿ¼,��ЩĿ¼�д洢�Ŵ�NameNode�������ľ����ļ�)
3.Secondary NameNode��ʼ�ϲ���ȡ�����������ļ�,����һ���µ�fsimage�ļ�fsimage.ckptSecondary NameNode��http post��ʽ����fsimage.ckpt��NameNode��
NameNode��fsimage.ckpt��edits.new�ļ��ֱ�������Ϊfsimage��edits,Ȼ�����fstime,����checkpoint���̵��˽���
6 fsimages��edits�ļ�
6.1 �ļ�����
NameNode����ʽ�������ָ����NameNode���ݴ洢Ŀ¼��,��Ŀ¼��hdfs-site.xmlָ��,����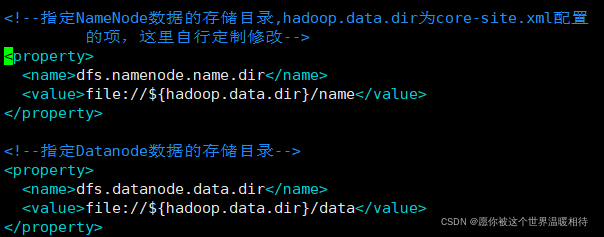
�ڸ�Ŀ¼��name/current�ļ����»���������ļ�

-
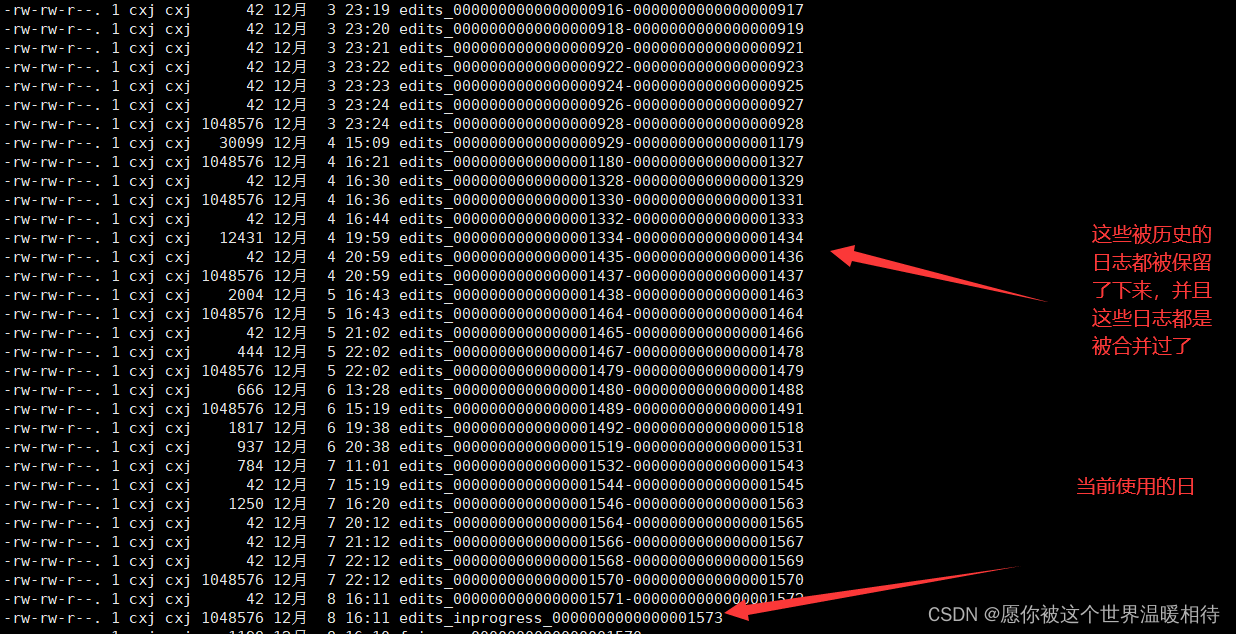
fsimage�ļ�:HDFS�ļ�ϵͳԪ���ݵ�һ�������Եļ���,���а���HDFS�ļ�ϵͳ������Ŀ¼���ļ�inode�����л���Ϣ����ͼ�д��������汾��fsimages,���ֱ�Ϊ1570��1572,1570Ϊ��һ�κϲ���fsimages�ļ�,1572��ʾ�ǵ�ǰ�� -
edits�ļ�:���HDFS�ļ�ϵͳ�����и��²�����·��,�ļ�ϵͳ�ͻ���ִ�е�����д�������Ȼᱻ��¼��edits�ļ��С���ǰ����־�ļ���������Ŀ¼�е�ǰ��־��edits_inprogress_0000000000000001573����ʷ��־�ļ�������ַ�Χ��ʾ���������Dz����Ĵ���,����edits_001-edits_101��ʾ����100�β���
-
seen_txid�ļ��������һ������,�������һ��edits_������,�統ǰ���Կ�����edits_inprogress_0000000000000001573,Ҳ����1573

-
ÿ��
NameNode������ʱ�Ὣfsimage�ļ������ڴ�,����edits����ĸ��²���,��֤�ڴ��е�Ԫ������Ϣ�����µġ�ͬ����,���Կ���NameNode������ʱ��ͽ�fsimage��edits�ļ������˺ϲ�
6.2 �ļ��鿴
6.2.1 ��ʽ��ѡ��
oiv:��ʽ�����fsimagesoev:��ʽ�����edits
#��XML�ĸ�ʽ���fsimage_0000000000000000975Ϊ��ǰĿ¼�µ�fsimage.xml
hdfs oiv -p XML -i fsimage_0000000000000000975 -o ./fsimage.xml
#��XML�ĸ�ʽ���edits_0000000000000000130-0000000000000000237Ϊ��ǰĿ¼�µ�edits .xml
hdfs oev -p XML -i edits_0000000000000000130-0000000000000000237 -o ./edits .xml
6.2.2 Ԫ���ݼ���
fsimages�ļ��б������Ԫ������Ϣ,���������ļ�ϵͳ��Ŀ¼�ṹ,HDFS���ļ�Ŀ¼�Dz�ʵ���ڷ�����������Ӧ���ļ��е�,������Ԫ���ݽ��б���,������ʽ�����fsimages.xml�ļ�,���ݲ�������:
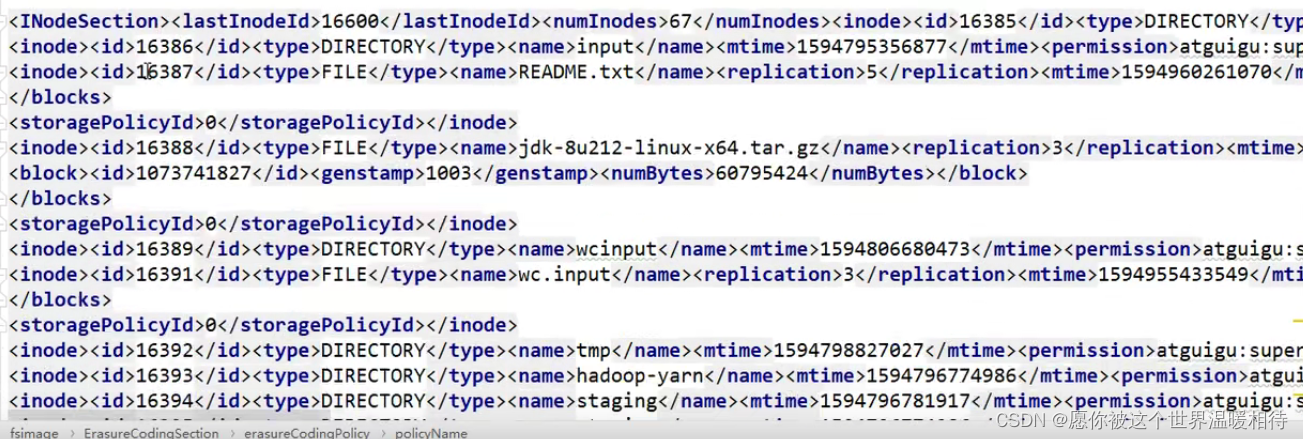
- ����ͼ��,ÿһ��
inode��ʾһ���ļ���Ԫ������Ϣ,����inode��id�Լ�����,��������������type��ǩ����ָ���Լ�ͨ��name��ǩָ����������,blockָ�����Ŀ��Լ���ʱ�����Ϣ

inode�ǵ����ļ���Ŀ¼��Ԫ������Ϣ,���Ӳ�ι�ϵ��ͨ��id����ʵ�ֵ�,Ҳ�����ĸ�Ŀ¼�±ߴ���ʲô�ļ�

parent��ʾ�Ǹ��ڵ��id,child��ʾ�ӽڵ��id,������ʾһ����εĹ�ϵ- �����ݽṹ�д��ڿ��
id��Ϣ,���Dz��ܴ��ڿ��Ǵ����ĸ�DataNode�ϱߵ�,�����õĸ�����С�ڷ������ڵ���,�ͻᰴһ����������ѡ��ȥ�洢��������ݿ鼰��洢�ķ�������Ϣ,����NameNode������ʱ����DataNode�����ύ��NameNode���ڴ��е�
6.2.3 edits������Ϣ

7 CheckPoint��������
Secondary NameNode���Զ�ʱ���ߵ���һ����������(��������)�ͻ�ȥ���кϲ�fsimages��edits�ļ�,����ǿ�����hdfs-site.xml�ļ��������õ�
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>ÿ3600�����һ�κϲ�</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>�������������ﵽ1000000�ν��кϲ�</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1���Ӽ��һ�β��������Ƿ�ﵽ���õ�ֵ</description>
</property>
8 NameNode���ϴ���
NameNode���Ϻ�,����ͨ�����·������д���:��Secondary NameNode�����ݿ�����NameNode�洢���ݵ�Ŀ¼����������:
- ����ǿ�����NameNode����:
shell kill -9 NameNode���� - ͨ��
rm -rfɾ��NameNode�洢������,�洢��λ�ÿ�����``hdfs-site.xml���в鿴:rm -rf /opt/module/hadoop3.1.3/data/name`
- ����ͨ��scp������п���
Secondary NameNode���������õ�Ŀ¼��NameNode��
#�ݹ鿽��Ŀ¼
scp -r 2NN�ϵ�nameĿ¼ NN�ϵ�nameĿ¼
scp -r cxj@hadoop103:/opt/module/hadoop3.1.3/data/name��* ./name/
Secondary NameNode���Իָ���������,��NameNode��Ҫ����,����Secondary NameNode��û��NameNode���µı༭��־,��Ϊ�༭��־�ǰ�һ����������ύ�ϲ���,������������edits�ļ��ʹ�����NameNode��,�����������������������Ҫ����NameNode�Ļָ�,��ôͨ��Secondary NameNode��һ��������ȫ�ָ����е�����
�������ϻָ���һ���˽�,Ŀǰʹ�õ���HA�ļܹ�,�ᴴ�����NameNode,���������ϻ��Զ��л����������õ�NameNode
9 ��Ⱥ��ȫģʽ
9.1 ��Ⱥ��ȫģʽ����
NaneNode����
NameNode����ʱ,���Ƚ������ļ�(fsimage) �����ڴ�,��ִ�б༭��־(edits) �еĸ��������һ�����ڴ��гɹ������ļ�ϵͳԪ���ݵ�ӳ��,��һ���µ�fsimage�ļ���һ���յı༭��־����ʱNameNode��ʼ����DataNode������������ڼ�,NameNodeһֱ�����ڰ�ȫ ģʽ,��NameNode���ļ�ϵͳ���ڿͻ���δ˵��ֻ����DataNode����
ϵͳ�е����ݿ��λ�ò�������NameNodeά����,�����Կ��б�����ʽ�洢��DataNode�С���ϵͳ�����������ڼ�,NameNode�����ڴ��б������п�λ�õ�ӳ����Ϣ���ڰ�ȫģʽ��,����DataNode����NameNode�������µĿ��б���Ϣ,NameNode�˽�㹻��Ŀ�λ����Ϣ֮��,���ɸ�Ч�����ļ�ϵ�y- ��ȫģʽ�˳��ж�
������㡰��С����������,NameNode����30����֮����˳���ȫģʽ����ν����С��������ָ�����������ļ�ϵͳ��99.9%�Ŀ�������С��������(Ĭ��ֵ:dfs replication.min=1),Ҳ����֪��ÿ��������һ�������Ϳ���������������������һ���ոո�ʽ����HDFS��Ⱥʱ,��Ϊϵͳ�л�û���κο�,����NameNode����� �밲ȫģʽ
��Ⱥ���밲ȫģʽ��ʱ��,������������,���粻��������
HDFS�ϵ��ļ���
����������Web�˿��Կ������ֶ�,SafemodeΪoff��ʾ�ر�

9.2 ��Ⱥ��ȫģʽ����
#��ȡ��ȫģʽ״̬
hdfs dfsadmin -safemode get
#������ȫģʽ
hdfs dfsadmin -safemode enter
##�رհ�ȫģʽ
hdfs dfsadmin -safemode leave
#�ȴ���ȫģʽ�ر�,һ�����ڽű���
hdfs dfsadmin -safemode wait
#waitʵ��:��дsafe.sh�ű�����
hdfs dfsadmin -safemode wait
echo "Hello World"
- �ڰ�ȫģʽ�رյ������ֱ��ִ�����Ͻű���ֱ�����
Hello World - ���ִ�������ű���ʱ���ڰ�ȫģʽ,��ô���������лᴦ��һ��������״̬,����ͨ�������ķ������رհ�ȫģʽ,��ִ�нű��ķ������ͻ�������״̬�����
Hello World
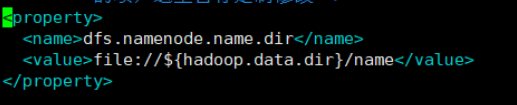
10 NameNode��Ŀ¼����
���
NameNode�洢Ŀ¼��֤NameNode�Ŀɿ���,���������϶���Ӧ��NameNode�Ĵ洢Ŀ¼Ҫ��������ͬ�Ĵ�����,��ΪNameNode��صĴ洢����һ̨�������ϵ�һ���������岢����,���½�������hdfs-site.xml��ָ����һ��Ŀ¼
- ��Ŀ¼�ļ�����,��
hdfs-site.xml�ļ���ֻ��Ҫ���ö��Ŀ¼����

- ���̹���
��ʱ����(��������������ʧ��ʧ)
#��name1Ŀ¼���ص�/dev/sda1���̷������Լ���name2 Ŀ¼���ص�/dev/sdb1��
mount /dev/sda1 ./name1
mount /dev/sdb1 ./name2
���ù���
vim /etc/fstab

���������ǿ�������ʽ�����̵�ʱ�����õ�,����ͨ��
lsblk -f�鿴

- ���úú�ʹ������
mount -a�����Զ�����