ЮЂаХЙЋжкКХ:дЫЮЌПЊЗЂЙЪЪТ,зїеп:wanger
ЙигкElastic Stack
elasticstackЪЧвЛИігІгУЬзМў,дУћЮЊELK Stack,гЩelasticЦьЯТЕФelasticsearchЁЂlogstashЁЂkibana,filebeatЫФИізщМўзщГЩ,етЫФИіЙЄОпзщКЯаЮГЩСЫвЛЬзЪЕгУЁЂвзгУЕФМрПиМмЙЙ,КмЖрЙЋЫОРћгУЫќРДДюНЈПЩЪгЛЏЕФКЃСПШежОЗжЮіЦНЬЈЁЃ
ElasticsearchМђНщ
ElasticsearchЪЧвЛИіИпЖШПЩРЉеЙЕФПЊдДШЋЮФЫбЫїКЭЗжЮів§ЧцЁЃЫќдЪаэФњПьЫй,НќЪЕЪБЕиДцДЂ,ЫбЫїКЭЗжЮіДѓСПЪ§ОнЁЃЫќЭЈГЃгУзїЕзВув§Чц/ММЪѕ,ЮЊОпгаИДдгЫбЫїЙІФмКЭвЊЧѓЕФгІгУГЬађЬсЙЉжЇГжЁЃ
LogstashМђНщ
logstashЪЧвЛПюЧсСПМЖЕФгУгкЪеМЏ,ЗсИЛКЭЭГвЛЫљгаЪ§ОнЕФПЊдДШежОЪеМЏв§Чц,ИіШЫРэНтlogstashОЭЯёвЛИљЙмЕР,гаЪфШыЕФвЛЖЫ,гаЪфГіЕФвЛЖЫ,ЙмЕРФкДцдкзХЙ§ТЫзАжУ,ПЩвдНЋЪеМЏЕФШежОзЊЛЛГЩЮвУЧЯывЊПДЕНЕФШежО,ЪфШыЕФвЛЖЫИКд№ЪеМЏШежО,ЙмЕРЪфГіЕФвЛЖЫЛсНЋШежОЪфГіЕНФуЯывЊДцЗХЕФЮЛжУ,ДѓЖрЪ§ЪЧЪфГіЕНelasticsearchРяУц
KibanaМђНщ
KibanaЪЧвЛИіПЊдДЗжЮіКЭПЩЪгЛЏЦНЬЈ,жМдкгыElasticsearchаЭЌЙЄзїЁЃПЩвдЧсЫЩЕижДааИпМЖЪ§ОнЗжЮі,ВЂдкИїжжЭМБэ,БэИёКЭЕиЭМжаПЩЪгЛЏФњЕФЪ§ОнЁЃKibanaЪЙФњПЩвдЧсЫЩРэНтДѓСПЪ§ОнЁЃЦфМђЕЅЕФЛљгкфЏРРЦїЕФНчУцЪЙФњФмЙЛПьЫйДДНЈКЭЙВЯэЖЏЬЌвЧБэАх,ЪЕЪБЯдЪОElasticsearchВщбЏЕФИќИФЁЃ
FilebeatМђНщ
FilebeatЪЧЪєгкBeatsЯЕСаЕФШежОЭадЫеп - вЛзщАВзАдкжїЛњЩЯЕФЧсСПМЖЭадЫШЫ,гУгкНЋВЛЭЌРраЭЕФЪ§ОнДЋЫЭЕНELKЖбеЛНјааЗжЮіЁЃУПИіНкХФзЈУХгУгкДЋЫЭВЛЭЌРраЭЕФаХЯЂ - Р§Шч,WinlogbeatЗЂВМWindowsЪТМўШежО,MetricbeatЗЂВМжїЛњжИБъЕШЕШЁЃЙЫУћЫМвх,FilebeatЬсЙЉШежОЮФМўЁЃ
дкЛљгкELKЕФШежОМЧТМЙмЕРжа,FilebeatАчбнШежОДњРэЕФНЧЩЋ - АВзАдкЩњГЩШежОЮФМўЕФМЦЫуЛњЩЯ,ВЂНЋЪ§ОнзЊЗЂЕНLogstashвдНјааИќИпМЖЕФДІРэ,ЛђепжБНгзЊЗЂЕНElasticsearchНјааЫїв§ЁЃвђДЫ,FilebeatВЛЪЧLogstashЕФЬцДњЦЗ,ЕЋдкДѓЖрЪ§ЧщПіЯТПЩвдВЂЧвгІИУЭЌЪБЪЙгУЁЃ
Elastic StackАВзАХфжУ
LogstashАВзА
1.АВзАlogstashашвЊвРРЕJava8ЕФЛЗОГ,ВЛжЇГжJava9
ЪЙгУyuminstall javaУќСюАВзА
2.ЯТдиВЂАВзАЙЋЙВЧЉУћУмдП
rpm --importhttps://artifacts.elastic.co/GPG-KEY-elasticsearch
3.ЬэМгlogstashЕФyumВжПт
vim/etc/yum.repos.d/logstash.repo
[logstash-6.x] name=Elastic repository for 6.xpackages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1autorefresh=1 type=rpm-md
4.ЪЙгУyuminstall logstashУќСюАВзАlogstash
ElasticsearchАВзА
elasticsearchЭЌбљашвЊJavaдЫааЛЗОГ
1.ЯТдиelasticsearchЕФtarАќ
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.0.tar.gz
2.НтбЙАќ
tar -xzfelasticsearch-6.4.0.tar.gz
3.аоИФХфжУЮФМў
[root@elasticelasticsearch-6.4.0]# vim config/elasticsearch.yml
аоИФФкШнШчЯТ:
cluster.name:my-elk #ЩшжУМЏШКЕФУћзж
node.name:es1 #МЏШКжаЕФНкЕуУћГЦ,ЭЌвЛМЏШКжаЕФНкЕуУћГЦВЛФмжиИД
path.data:/elasticsearch/elasticsearch-6.4.0/data #ЩшжУesМЏШКЕФЪ§ОнЮЛжУ
path.logs:/elasticsearch/elasticsearch-6.4.0/logs/ #ЩшжУДцЗХШежОЕФТЗОЖ
network.host:192.168.179.134 #АѓЖЈБОЕиipЕижЗ
http.port:9200 #ЩшжУПЊЗХЕФЖЫПк,ФЌШЯОЭЪЧ9200ЖЫПк
4.ЦєЖЏelasticsearch
cdelasticsearch-6.4.0/
./bin/elasticsearch
етРявЊЪЙгУЦеЭЈгУЛЇдЫаа,ЛЙвЊАбФПТМЪкгшЦеЭЈЮФМўШЈЯо
chown -Relker.elker /elasticsearch
5.ВщПДЦєЖЏзДЬЌ
ЪфШыnetstat -ntlp|grep 9200ВщПД9200ЖЫПкЪЧЗёМрЬ§,ПЩвдЪЙгУcurl192.168.179.134:9200ЛђепдкфЏРРЦїЩЯЪфШы192.168.179.134:9200НјааВщПДЦєЖЏКѓЕФзДЬЌ
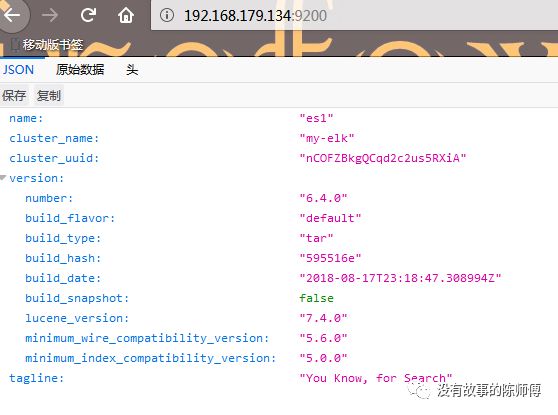
5.ЦєЖЏЙ§ГЬГіЯжЕФБЈДэ
[WARN][o.e.b.BootstrapChecks ] [PWm-Blt]max file descriptors [4096] for elasticsearch process is too low, increase toat least [65536]
НтОіАьЗЈ:
vim/etc/security/limits.conf
* softnofile 65536
* hardnofile 131072
* soft nproc2048
* hard nproc4096
[WARN][o.e.b.BootstrapChecks ] [PWm-Blt]max virtual memory areas vm.max_map_count [65530] is too low, increase to atleast [262144]
НтОіАьЗЈ:
vim/etc/sysctl.conf
vm.max_map_count=655360
аоИФЭъГЩжДааУќСю:
sysctl-p
Elasticsearch HeadВхМўАВзА
ЖдelasticsearchМЏШКЕФВйзївЛжБЭЈЙ§restЧыЧѓЪЧБШНЯТщЗГЕФ,elasticsearchЬсЙЉСЫвЛИіheadВхМўРДЖдelasticsearchМЏШКдкфЏРРЦїЩЯНјааВйзї,ElasticSearch-headЪЧвЛИіH5БраДЕФElasticSearchМЏШКВйзїКЭЙмРэЙЄОп,ПЩвдЖдМЏШКНјааЩЕЙЯЪНВйзїЁЃЯТУцЮвУЧРДНјааheadВхМўЕФАВзАЁЃ
1.АВзАnode.js
етРяЮвВЩгУЕФдДТыАВзА,ЦфЪЕЖўНјжЦАВзАЪЧБШНЯМђЕЅЕФ,ЕЋЮвжДааЕНзюКѓnodeЕФЖўНјжЦЮФМўЮоЗЈжДаа,вђДЫжЛФмдДТыАВзА,ЪБМфгаЕуГЄ,ДђСЫСНОжЭѕепШйвЋВХзАЭъ
wget https://nodejs.org/dist/v8.11.4/node-v8.11.4.tar.gz #ЯТдиnodeЕФдДТыАќ
tar -zxvfnode-v8.11.4 #НтбЙдДТыАќ
./configure && make && make install #жДааБрвыАВзА
echo $? #ВщПДжДааНсЙћ,ЪфГі0БэЪОАВзАГЩЙІ
node.jsФЌШЯАВзАТЗОЖдк/usr/local/bin/ФПТМЯТ
2.АВзАgrunt
gruntЪЧЛљгкNode.jsЕФЯюФПЙЙНЈЙЄОп,ПЩвдНјааДђАќбЙЫѕЁЂВтЪдЁЂжДааЕШЕШЕФЙЄзї,headВхМўОЭЪЧЭЈЙ§gruntЦєЖЏ
npm install -g grunt-cli
3.ЯТдиВЂАВзАheadВхМў
git clonegit://github.com/mobz/elasticsearch-head.git #ПЫТЁheadВхМўВжПт
cd elasticsearch-head/
npm install #жДааЭъЛсБЈвЛаЉДэЮѓ,ВЛвЊЙмжДааЯТвЛЬѕУќСюОЭЛсНтОі
npm install phantomjs-prebuilt@2.1.14 --ignore-scripts
4.аоИФelasticsearchЕФХфжУ
vim/elasticsearch/elasticsearch-6.4.0/config/elasticsearch.yml
http.cors.enabled: true #elasticsearchжаЦєгУCORShttp.cors.allow-origin: ЁА*ЁБ # дЪаэЗУЮЪЕФIPЕижЗЖЮ,* ЮЊЫљгаIPЖМПЩвдЗУЮЪ
5.ЦєгУheadВхМўВЂдкфЏРРЦїЩЯДђПЊ
npm run start #ЦєЖЏheadВхМў
дкфЏРРЦїЪфШыhttp://192.168.179.134:9100/МДПЩЪЙгУheadВхМў
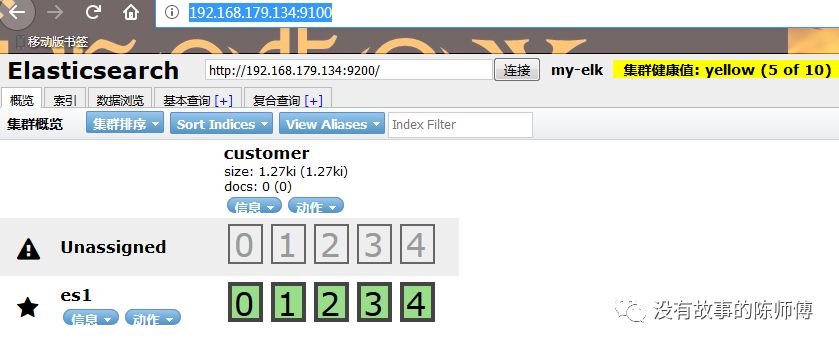
дквдКѓЕФУПДЮЦєЖЏжа,жЛашвЊдкheadВхМўЕФФПТМжДааgrunt serverОЭПЩвдСЫ
KibanaАВзА
1.ЯТдиВЂНтбЙkibanaАќ
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.0-linux-x86_64.tar.gz
tar -xzfkibana-6.4.0-linux-x86_64.tar.gz
2.аоИФkibanaФЌШЯХфжУ
vimkibana-6.4.0-linux-x86_64/config/kibana.yml
server.port:5601 #kibanaФЌШЯЖЫПкЪЧ5601
server.host:ЁА192.168.179.134ЁБ #ЩшжУАѓЖЈЕФkibanaЗўЮёЕФЕижЗ
elasticsearch.url:ЁАhttp://192.168.179.134:9200ЁБ #ЩшжУelasticsearchЗўЮёЦїЕФipЕижЗ,ВЛаоИФЕФЛАЦєЖЏЕФЪБКђЛсБЈ[elasticsearch] Unable to revive connection: http://localhost:9200/СЌНгВЛЩЯelasticsearchЕФДэЮѓ
kibana.index:".kibana" #ДДНЈвЛИіkibanaЕФЫїв§
3.ЦєЖЏkibana
/kibana-6.4.0-linux-x86_64/bin/kibana
netstat-ntlp |grep 5601 #ПЩвдВщПД5601ЖЫПкЪЧЗёЦєЖЏ
дкфЏРРЦїЪфШы192.168.179.134:5601МДПЩЗУЮЪkibana
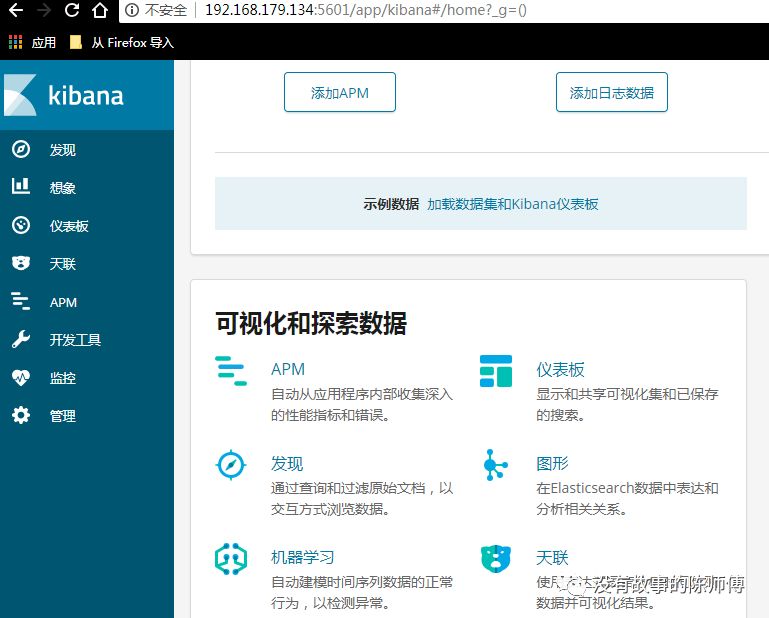
4.ГіЯжЕФОЏИцаХЯЂ
ЫфШЛГіЯжОЏИцаХЯЂ,ВЛЙ§ЛЙЪЧПЩвдЦєЖЏkibanaЕФ,БОШЫгаЕуЧПЦШжЂ,ВЛЯыПДЕНОЏИцаХЯЂ
ОЏИцаХЯЂ1:[security] Generating a random key for xpack.security.encryptionKey.To prevent sessions from being invalidated on restart, please setxpack.security.encryptionKey in kibana.yml
НтОіЗНЗЈ:аоИФХфжУЮФМўvimconfig/kibana.yml
дкХфжУЮФМўЕзВПЬэМг
xpack.reporting.encryptionKey:ЁАa_random_stringЁБ
ОЏИцаХЯЂ2:[security] Session cookies will be transmitted over insecureconnections. This is not recommended.
НтОіЗНЗЈ:аоИФХфжУЮФМўvimconfig/kibana.yml
дкХфжУЮФМўЕзВПЬэМг
xpack.security.encryptionKey:ЁАsomething_at_least_32_charactersЁБ
5.МьВщkibanaзДЬЌ
дкфЏРРЦїЪфШы192.168.179.134:5601/statusВщПДkibanaзДЬЌ,ЛђепЪфШыhttp://192.168.179.134:5601/api/statusВщПДjsonИёЪНЕФЯъЯИзДЬЌ
ElasticsearchЕФЯрЙиИХФюгыВйзї
МЏШК
МЏШКЪЧвЛИіЛђЖрИіНкЕу(ЗўЮёЦї)ЕФМЏКЯ,ЫќУЧЙВЭЌБЃДцФњЕФећИіЪ§Он,ВЂЬсЙЉПчЫљгаНкЕуЕФСЊКЯЫїв§КЭЫбЫїЙІФмЁЃ
МЏШКНЁПЕ
Elasticsearch ЕФМЏШКМрПиаХЯЂжаАќКЌСЫаэЖрЕФЭГМЦЪ§Он,ЦфжазюЮЊживЊЕФвЛЯюОЭЪЧМЏШКНЁПЕ,ЫќдкstatusзжЖЮжаеЙЪОЮЊ green ЁЂyellowЛђепred ЁЃ
ЫќЕФШ§жжбеЩЋКЌвхШчЯТ:
green
ЫљгаЕФжїЗжЦЌКЭИББОЗжЦЌЖМе§ГЃдЫааЁЃ
yellow
ЫљгаЕФжїЗжЦЌЖМе§ГЃдЫаа,ЕЋВЛЪЧЫљгаЕФИББОЗжЦЌЖМе§ГЃдЫааЁЃ
red
гажїЗжЦЌУЛФме§ГЃдЫааЁЃ
ПЩвддкУќСюааЪЙгУcurl -X GET"192.168.179.134:9200/_cluster/health"
ЛђепдкфЏРРЦїЩЯЪфШы192.168.179.134:9200/_cluster/healthВщПДМЏШКНЁПЕзДЬЌ
ЁАunassigned_shardsЁББэЪОУЛгаЗжХфЕНШЮКЮНкЕуЩЯЕФИББОЗжЦЌЪ§
НкЕу
НкЕуЪЧзїЮЊШКМЏвЛВПЗжЕФЕЅИіЗўЮёЦї,ДцДЂЪ§ОнВЂВЮгыШКМЏЕФЫїв§КЭЫбЫїЙІФмЁЃвЛИідЫаажаЕФElasticsearch ЪЕР§ГЦЮЊвЛИі НкЕу,ЖјМЏШКЪЧгЩвЛИіЛђепЖрИігЕгаЯрЭЌМЏШКУћХфжУЕФНкЕузщГЩ,ЫќУЧЙВЭЌГаЕЃЪ§ОнКЭИКдиЕФбЙСІЁЃЕБгаНкЕуМгШыМЏШКжаЛђепДгМЏШКжавЦГ§НкЕуЪБ,МЏШКНЋЛсжиаТЦНОљЗжВМЫљгаЕФЪ§ОнЁЃ
ЕБвЛИіНкЕуБЛбЁОйГЩЮЊ жїНкЕуЪБ, ЫќНЋИКд№ЙмРэМЏШКЗЖЮЇФкЕФЫљгаБфИќ,Р§ШчдіМгЁЂЩОГ§Ыїв§,ЛђепдіМгЁЂЩОГ§НкЕуЕШЁЃЖјжїНкЕуВЂВЛашвЊЩцМАЕНЮФЕЕМЖБ№ЕФБфИќКЭЫбЫїЕШВйзї,зїЮЊгУЛЇ,ЮвУЧПЩвдНЋЧыЧѓЗЂЫЭЕН_МЏШКжаЕФШЮКЮНкЕу_,АќРЈжїНкЕуЁЃУПИіНкЕуЖМжЊЕРШЮвтЮФЕЕЫљДІЕФЮЛжУ,ВЂЧвФмЙЛНЋЮвУЧЕФЧыЧѓжБНгзЊЗЂЕНДцДЂЮвУЧЫљашЮФЕЕЕФНкЕуЁЃЮоТлЮвУЧНЋЧыЧѓЗЂЫЭЕНФФИіНкЕу,ЫќЖМФмИКд№ДгИїИіАќКЌЮвУЧЫљашЮФЕЕЕФНкЕуЪеМЏЛиЪ§Он,вВОЭЪЧЫЕ,ФуЗЂЫЭЕФЧыЧѓЗЂЕНСЫећИіelasticsearchМЏШКЩЯ
Ыїв§
Ыїв§ЪЧОпгаФГаЉРрЫЦЬиеїЕФЮФЕЕМЏКЯЁЃР§Шч,ШчЙћФувЊЪеМЏЯЕЭГШежО,ФуПЩвдНЈСЂвЛИіЯЕЭГШежОЕФЫїв§ЁЃ Ыїв§ЪЕМЪЩЯЪЧжИЯђвЛИіЛђепЖрИіЮяРэЗжЦЌЕФТпМ_УќУћПеМф_ ЁЃ
ЗжЦЌ
вЛИіЗжЦЌЪЧвЛИіЕзВуЕФЙЄзїЕЅдЊ,ЫќНіБЃДцСЫШЋВПЪ§ОнжаЕФвЛВПЗжЁЃ ElasticsearchЪЧРћгУЗжЦЌНЋЪ§ОнЗжЗЂЕНМЏШКФкИїДІЕФЁЃЗжЦЌЪЧЪ§ОнЕФШнЦї,ЮФЕЕБЃДцдкЗжЦЌФк,ЗжЦЌгжБЛЗжХфЕНМЏШКФкЕФИїИіНкЕуРяЁЃЕБФуЕФМЏШКЙцФЃРЉДѓЛђепЫѕаЁЪБ, Elasticsearch ЛсздЖЏЕФдкИїНкЕужаЧЈвЦЗжЦЌ,ЪЙЕУЪ§ОнШдШЛОљдШЗжВМдкМЏШКРяЁЃУПИіЗжЦЌБОЩэЖМЪЧвЛИіЙІФмЦыШЋЧвЖРСЂЕФЁАЫїв§ЁБ,ПЩвдЭаЙмдкМЏШКжаЕФШЮКЮНкЕуЩЯЁЃвЛИіЗжЦЌПЩвдЪЧжїЗжЦЌЛђепИББОЗжЦЌЁЃ Ыїв§ФкШЮвтвЛИіЮФЕЕЖМЙщЪєгквЛИіжїЗжЦЌ,ЫљвджїЗжЦЌЕФЪ§ФПОіЖЈзХЫїв§ФмЙЛБЃДцЕФзюДѓЪ§ОнСПЁЃвЛИіИББОЗжЦЌжЛЪЧвЛИіжїЗжЦЌЕФПНБДЁЃ ИББОЗжЦЌзїЮЊгВМўЙЪеЯЪББЃЛЄЪ§ОнВЛЖЊЪЇЕФШпгрБИЗн,ВЂЮЊЫбЫїКЭЗЕЛиЮФЕЕЕШЖСВйзїЬсЙЉЗўЮёЁЃдкЫїв§НЈСЂЕФЪБКђОЭвбОШЗЖЈСЫжїЗжЦЌЪ§,ЕЋЪЧИББОЗжЦЌЪ§ПЩвдЫцЪБаоИФЁЃ
дкЯрЭЌНкЕуЪ§ФПЕФМЏШКЩЯдіМгИќЖрЕФИББОЗжЦЌВЂВЛФмЬсИпадФм,вђЮЊУПИіЗжЦЌДгНкЕуЩЯЛёЕУЕФзЪдДЛсБфЩйЁЃЕЋЪЧИќЖрЕФИББОЗжЦЌЪ§ЬсИпСЫЪ§ОнШпгрСПЁЃ
Ыїв§гыЗжЦЌЕФБШНЯ
БЛЛьЯ§ЕФИХФюЪЧ,вЛИі Lucene Ыїв§ ЮвУЧдк Elasticsearch ГЦзїЗжЦЌЁЃвЛИіelasticsearchЫїв§ЪЧЗжЦЌЕФМЏКЯЁЃЕБ Elasticsearch дкЫїв§жаЫбЫїЕФЪБКђ, ЫћЗЂЫЭВщбЏЕНУПвЛИіЪєгкЫїв§ЕФЗжЦЌ(Lucene Ыїв§),ШЛКѓЯё жДааЗжВМЪНМьЫї ЬсЕНЕФФЧбљ,КЯВЂУПИіЗжЦЌЕФНсЙћЕНвЛИіШЋОжЕФНсЙћМЏЁЃ
ДДНЈЫїв§
дкУќСюаажажДааcurl-X PUT "192.168.179.134:9200/custome?pretty"ПЩвдДДНЈвЛИіУћЮЊcustomeЕФЫїв§,ШчЙћвЊаоИФЫїв§ДДНЈФЌШЯЕФжїЗжЦЌЪ§КЭИББОЗжЦЌЪ§,ПЩвджДааШчЯТУќСю
[root@elastic~]# curl -X PUT ЁА192.168.179.134:9200/blogsЁБ -H ЁЎContent-Type:application/jsonЁЏ -dЁЏ
{
ЁАsettingsЁБ : {
ЁАnumber_of_shardsЁБ : 3,
ЁАnumber_of_replicasЁБ : 1
}
}
ЁЏ
вдЩЯУќСюБэЪОДДНЈСЫвЛИіАќКЌ3ИіжїЗжЦЌКЭвЛИіИББО(МДШ§ИіИББОЗжЦЌ)ЕФblogsЫїв§
ЮвУЧЛЙПЩвддкфЏРРЦїЪЙгУhttp://192.168.179.134:9200/_cat/indices?vЛђепдкУќСюаажаЪЙгУcurl -X GET "http://192.168.179.134:9200/_cat/indices?v"ВщПДМЏШКжаЕФЫїв§

ПЩвдПДЕНЮввбОДДНЈСЫШ§ИіЫїв§,ВЂЧвЛЙПЩвдПДЕНЮвЕФМЏШКНЁПЕзДЬЌЯдЪОЮЊyellow,ЩЯУцЫЕСЫyellowБэЪОДцдкИББОЗжЦЌУЛгае§ГЃдЫаа,вђЮЊЮвЕФelasticsearchМЏШКжЛгавЛИіНкЕу,elasticsearchВЛФмАбЭЌвЛЫїв§ЕФжїЗжЦЌКЭИББОЗжХфдквЛИіНкЕуЩЯ,етбљвВЪЧУЛгавтвхЕФ,вђЮЊжЛвЊвЛИіНкЕуЙвСЫ,НкЕуЩЯЕФжїЗжЦЌКЭИББОЩЯЕФЪ§ОнОЭЖМЖЊЪЇСЫ,вВОЭВЛДцдкЪВУДИпПЩгУадСЫ
ДДНЈЮФЕЕ
дкУќСюааЯТжДааЯТУцЕФУќСюПЩвдДДНЈЮФЕЕ
curl -X PUT"192.168.179.134:9200/customer/_doc/1?pretty" -H ЁЎContent-Type:application/jsonЁЏ -dЁЏ
{
ЁАnameЁБ: ЁАJohn DoeЁБ
}
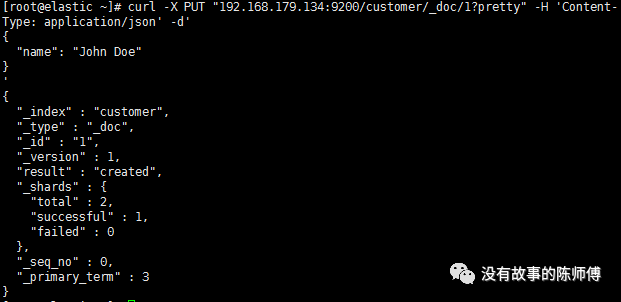
ШчЭМЫљЪО,ЮвУЧИеИедкcustomerЫїв§жаДДНЈСЫвЛИіУћЮЊJohn Doe,IDЮЊ1ЕФЮФЕЕ
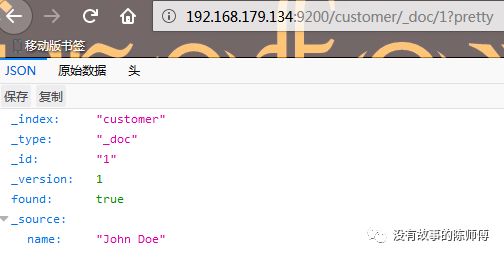
ПЩвддкфЏРРЦїЪЙгУhttp://192.168.179.134:9200/customer/_doc/1?prettyЛђепдкУќСюаажаЪфШыcurl -X GET192.168.179.134:9200/customer/_doc/1?prettyВщПДИеИеДДНЈЕФЮФЕЕ
ЩОГ§Ыїв§
дкУќСюаажаЪЙгУcurl-X DELETE "192.168.179.134:9200/customer"УќСюПЩвдЩОГ§Ыїв§
дйДЮВщПДМЏШКжаЕФЫїв§,ЛсЗЂЯжcustomerЫїв§вбОВЛМћСЫ

ШчЙћвЊЩОГ§ШЋВПЫїв§ЕФЛАПЩвджДааcurl -X DELETE "192.168.179.134:9200/_all"Лђепcurl -X DELETE ЁА192.168.179.134:9200/*ЁБ
ЦфЪЕПЩвдЗЂЯж,вдЩЯЕФМИЬѕУќСюЖМЪЧгаЙЬЖЈЕФУќСюИёЪН
<RESTЖЏзї>/<Ыїв§>/<РраЭ>/
ЩОГ§ЮФЕЕ
дкУќСюаажДааУќСюcurl-X DELETE "192.168.179.134:9200/customer/_doc/1?pretty"ПЩвдЩОГ§customerЫїв§IDЮЊ1ЕФЮФЕЕ
гЩгкБЪМЧЛЙУЛгаЭъГЩ,ЯШНЋВПЗжБЪМЧЗЂЙЋжкКХ,ЕШШЋВПаДЭъдйЖЊgithub
ВЮПМСДНг:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
ШчЙћгаЯывЛЦ№НЛСїЕФХѓгбПЩвдЩЈУшЯТЗНЖўЮЌТыНјШыШКСФ