Hadoop期末复习城科专用
根据老师给出的知识点范围整理,有的知识点太长了,就标了一部分黑色字体,把黑色字体记住答上也应该能得分,其余的方便记忆理清思路,列出来的全是给的知识点范围,还没有写完,晚上和明天继续写,太多了
共44个考点,目前写了26个
一、Hadoop集群
概念解释:
1.Yarn
Yarn是Hadoop2.0中的资源管理器,它可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来巨大好处。
简答题
1.Hadoop集群6个核心配置文件以及它的作用
| 配置文件 | 功能描述 |
|---|---|
| hadoop-env.sh | 配置Hadoop运行所需的环境变量 |
| yarn-env.sh | 配置Yarn运行所需环境变量 |
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用该文件 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | MapReduce配置文件,继承core-site.xml配置文件 |
| yarn-site.xml | YARN配置文件,继承core-site.xml文件 |
2.Hadoop集群部署方式以及各方式使用场景
(1)独立模式:又称单例模式,在该模式下,无须运行任何守护进程,所有的程序都在单个JVM上执行,
(2)伪分布模式:Hadoop程序的守护进程运行在一台主机节点上,通常使用伪分布式模式来调试Hadoop分布式程序的代码,以及程序执行是否正确,伪分布式模式是完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
3.Hadoop版本的区别
借用尚硅谷一张图
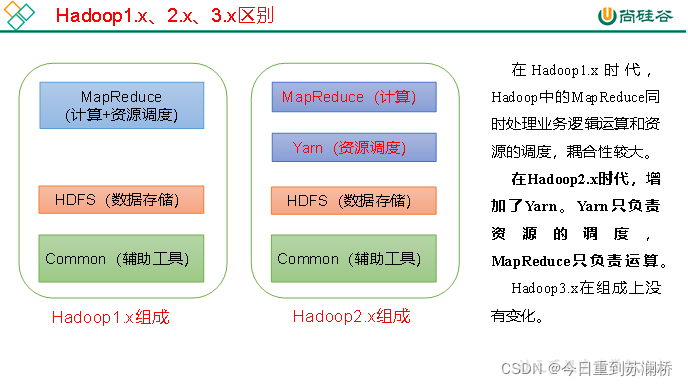
4.大数据的意义(围绕这个写就行)
研究大数据,最重要的意义在于预测。因为数据从根本上来讲,是对过去和现在的归纳和总结,其本身不具备趋势和方向性的特征,但是可以应用大数据去了解事物发展的客观规律、了解人类行为,并且能够帮助我们改变过去的思维方式,建立新的数据思维模式,从而对未来进行预测和推测。
二、HDFS
概念解释:
1.NameNode
**NameNode是HDFS集群的主服务器,通常称为名称节点或主节点。**一旦NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称的空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中,可以设置备份数量,这些信息都由NameNode存储。
2.Secondary NameNode
HDFS中提供了Secondary NameNode(辅助名称节点),它并不是要取代NameNode也不是NameNode的备份,它的职责是周期性地把NameNode中地EditLog日志文件合并到FsImage镜像文件中,从而减小EditLog日志文件大小,缩短集群重启时间,保证了HDFS系统地完整性。
3.DataNode
DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存在DataNode节点上的,因此DataNode机器需要配置大量磁盘空间。它与NameNode不断地保持通信,DataNode在客户端或者NameNode地调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储地数据块列表,每当DataNode启动时,它将负责把持有地数据块列表发送到NameNode集群中。
4.元数据
元数据从类型上可分为三种信息形式,一是维护HDFS中文件和目录的信息,如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等;二是记录文件内容,存储相关信息,如文件分块情况、副本个数、每个副本所在的DataNode信息等;三是用来记录HDFS中所有DataNode的信息,用于DataNode管理。
简答题:
1.HDFS文件上传流程(HDFS写数据原理,详细看书53页,感觉没必要)
配个尚硅谷的流程图,理解一下
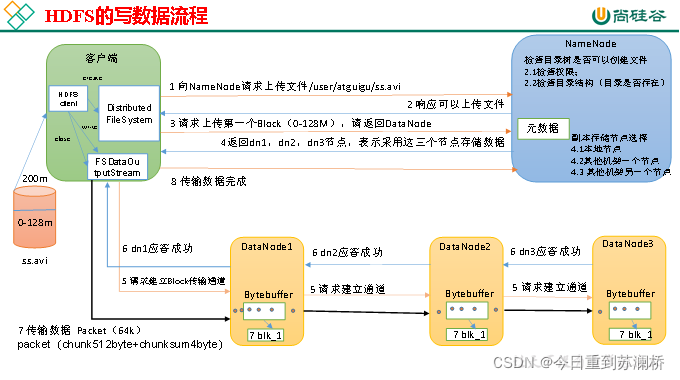
(1)客户端向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
2.NameNode管理分布式文件系统的命名空间
NameNode内部以元数据的形式,维护着两个文件,分别是FsImage镜像文件和EditLog日志文件。其中,FsImage镜像文件用于存储整个文件系统命名空间的信息,EditLog日志文件用于持久化记录文件系统元数据发生的变化。当NameNode启动的时候,FsImage镜像文件就会被加载到内存中,然后对内存里的数据执行记录的操作,以确保内存所保留的数据处于最新状态,这样就加快了元数据的读取和更新操作。
3.HDFS Block与MapReduce split之间的联系
- split是MapReduce里的概念,是切片的概念,split是逻辑切片 ;而block是hdfs中切块的大小,block是物理切块;
- split的大小在默认的情况下和HDFS的block切块大小一致,为了是MapReduce处理的时候减少由于split和block之间大小不一致,可能会完成多余的网络之间的传输。
如果blockSize小于maxSize && blockSize 大于 minSize之间,那么split就是blockSize;
如果blockSize小于maxSize && blockSize 小于 minSize之间,那么split就是minSize;
如果blockSize大于maxSize && blockSize 大于 minSize之间,那么split就是maxSize;
三、MapReduce
1.核心思想及概念
”分而治之“:把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决
MapReduce作为一种分布式计算模型,它主要解决海量数据的计算问题。使用MapReduce分析海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段,具体介绍如下:
-
Map阶段:负责将任务分解,即把复杂的任务分解成若干个“简单的任务”来并行处理,但前提是这些任务没有必然的依赖关系,可以单独执行任务
-
Reduce阶段:负责将任务合并,即把Map阶段的结果进行全局汇总
2.MapReduce工作过程
-
分片、格式化数据源**(对数据进行分片和格式化)**
输入Map阶段的数据源,必须经过分片和格式化操作。
分片操作:指的是将源文件划分为大小相等的小数据块(Hadoop 2. x中默认128MB) ,也就是分片(split),Hadoop会为每一个分片构建一个Map任务,并由该任务运行自定义的map()函数,从而处理分片里的每一-条记录。格式化操作:将划分好的分片(split)格式化为键值对<key,value>形式的数据其中,key代表偏移量,value代表每一-行内容。
-
执行MapTask**(处理任务,并将任务处理结果写入内存缓冲区,若缓冲区将满则写入磁盘)**
每个Map任务都有一个内存缓冲区(缓冲区大小100MB),输入的分片(split)数据经过Map任务处理后的中间结果会写入内存缓冲区中。如果写入的数据达到内存缓冲的阈值(80MB),会启动一个线程将内存中的溢出数据写入磁盘,同时不影响map中间结果继续写入缓冲区。
在溢写过程中,MapReduce框架会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为-一个文件。 -
执行Shuffle过程**(将MapTask处理结果发给ReduceTask,并对数据进行分区和排序)**
MapReduce工作过程中,Map阶段处理的数据如何传递给Reduce 阶段,这是MapReduce框架中关键的一个过程,这个过程叫作Shuffle. Shuffle 会将MapTask输出的处理结果数据分发给ReduceTask,并在分发的过程中,对数据按key进行分区和排序。
-
执行ReduceTask**(逻辑处理并输出)**
输入ReduceTask的数据流是<key, {value list}>形式,用户可以自定义reduce()方法进行逻辑处理,最终以<key,value>的形式输出。
-
写入文件**(将结果写入文件)**
MapReduce框架会自动把ReduceTask生成的< key, value>传入OutputFormat的write方法,实现文件的写入操作。
3.Shuffle工作流程
1.Map阶段
(1)MapTask处理的结果会暂且放入一个内存缓冲区(默认大小100MB)内,当缓冲区快要溢出时(达到80%),会在本地文件系统创建一个溢出文件,将该缓冲区的数据写入这个文件。(若MapTask缓冲区将要溢出,则把缓冲区数据写入本地溢出文件)
(2)写入磁盘前,线程会根据ReduceTask的数量将数据分区,一个Reduce任务对应一个分区的数据。这样做目的是为了避免有些ruduce任务分配大量数据,而有些reduce任务分到很少的数据,甚至没有分到数据的尴尬局面(将数据进行分区)
(3)分完数据后,会对每个分区的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combine操作,这样做目的时尽可能少地执行数据写入磁盘的操作。(对分区数据进行排序,进行Combine操作)
(4)当Map任务输出最后一个记录时,可能有很多溢出文件,这时需要将这些文件合并,合并过程中不断地进行排序和Combine操作,其目的有两个:一是尽量减少每次写入磁盘的数据量;二是尽量减少下一复制阶段网络传输的数据量。最后合并成一个已分区且排序的文件**(对溢出文件进行合并,合并时进行排序和Combine操作)**
(5)将分区数据复制给对应的Reduce任务。
2.Reduce阶段
(1)Reduce会接受到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果Reduce阶段接受到的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。(Reduce接受到的数据量小,存在内存中,否则将数据合并后存在磁盘)
(2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。(后台线程会将溢出文件合并成一个大的有序的文件)
(3)合并的过程中产生了许多中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并地结果没有写入磁盘,而是直接输入到reduce函数。
组件
4.InputFormat组件
InputFormat组件主要用于描述输入数据的格式,它提供一下两个功能。
- 数据切分:按照某个策略将输入数据切分成若干个分片,以便确定MapTask个数以及对应的分片。
- 为Mapper提供输入数据:给定某个分片,将其解析成一个一个的key/value键值对。
5.Mapper组件
MapReduce程序会根据输入文件产生多个map任务。Hadoop提供的Mapper类是实现Map任务的一个抽象类,该基类提供了一个map()方法,默认情况下,Mapper类中的map方法是没有做任何处理的。如果想自定义map()方法,只需要继承Mapper类并重写map()方法即可。
6.Reducer组件
Map过程输出的键值对,将由Reducer组件进行合并处理。Hadoop提供了一个抽象类Reducer,当用户调用Reducer类时,会直接调用Reducer类里的run()方法,该方法中定义了setup(),reduce(),cleanup()三个方法的执行顺序:setup->reduce->cleanup。默认情况下,setup()和cleanup()方法内部不做任何处理,reduce()方法是处理数据的核心方法,该方法接受Map阶段输出的键值对数据,对传入的键值对数据进行处理,并产生最终某种形式的结果并输出。
7.Partitoner组件
Partitioner组件可以让Map对Key进行分区,从而根据不同的key分发到不同的Reduce中去处理,其目的是将key均匀分布在ReduceTask上。Hadoop自带一个默认的分区类HashPartitioner,它继承了Partitioner类,并提供了一个getPartition方法。如果想自定义一个Partitioner组件,需要继承Partitioner类并重写getPartition()方法。重写getPartitioner方法时,通常做法是使用hash函数对文件数量进行分区,即通过hash操作,获得一个非负整数的hash码,然后用当前作业的reduce节点数进行驱魔运算,从而实现数据均匀分布在ReduceTask的目的。
8.Combiner组件
在Map阶段输出可能会产生大量相同的数据,势必会降低Reduce聚合阶段的执行效率。Combiner组件的作用就是对Map阶段的输出的重复数据先做一次合并计算,然后把新的(key,value)作为Reduce阶段的输入。如果想自定义Combiner,需要继承Reducer类,并且重写reduce()方法。
9.JobTracker
- 概述:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
- JobTracker的主要功能:
1.作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
*最重要的是状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
2.资源管理。
10.TaskTracker:
- TaskTracker概述:TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。
- TaskTracker的功能:
1.汇报心跳:Tracker周期性将所有节点上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:
机器级别信息:节点健康情况、资源使用情况等。
任务级别信息:任务执行进度、任务运行状态等。
2.执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、
杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
:节点健康情况、资源使用情况等。
任务级别信息:任务执行进度、任务运行状态等。
2.执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、
杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
四、Zookeeper
概念解释:
1.zookeeper
zookeeper是一个分布式协调服务的开源框架,本质上是一个分布式的小文件存储系统,提供基于类似文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理,从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,从而达到基于数据的集群管理。如同一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等功能。
2.Znode
**Zookeeper是由节点组成的树,树中的每个节点被称为Znode树中每个节点被称为都可以拥有子节点。每一个Znode默认能够存储1MB的数据,每个Znode都可以通过其路径唯一标识。**Zookeeper数据模型中的每个Znode都是由3部分组成,分别是stat(状态信息,描述Znode的版本,权限信息等组成)、data(与该Znode关联的数据)和Children(该Znode下的子节点)。
简答题:
3.Zookeeper集群选举机制(书上107)
这个很多,实在背不下来就写这个黑体,黑体下面就别看了
Zookeeper选举机制有两种类型,分别为全新集群选举和非全新集群选举。全新集群选举是新搭建起来的,没有数据ID和逻辑时钟的数据影响集群的选举;非全新集群选举时是优中选优,保证Leader是Zookeeper集群中数据最完整、最可靠的一台服务器。
首先明白几个概念:
服务器ID:每个服务器都有不同的ID,假设我们有服务器1,服务器2,服务器3,数字编号越大当选leader的权重越大。
选举状态:每个Zookerper服务器都有4种状态,分别为竞选状态(LOOKING)、随从状态(FOLLOWING,同步leader状态,参与投票),观察状态(OBSERVING,同步leader状态,不参与投票)和领导者状态(LEADING)。
数据ID:代表服务器中存放的最新数据版本号,值越大说明数据越新。
逻辑时钟:投票次数。起始值为0,每投完一次票,这个数据就会增加。然后与接收到其他服务器返回的投票信息中的数值相比较,根据不同的值做出不同判断。
全新集群选举:
假设现在有5台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动。过程如下:
- 服务器 1 启动,给自己投票,然后发投票信息给其他服务器,由于其他服务器没有启动,所以它收不到反馈信息,但是由于投票还没有到达半数(服务器 1 怎么知道一共有多少台服务器参与选举呢, 那是因为在zk配置文件中配置了集群信息,所有配置了3888端口的服务器均会参与投票,假设这5台都参与投票,则超过半数应为至少3台服务器参与投票。),所以服务器 1 的状态一直处于 LOOKING。
- 服务器 2 启动, 给自己投票,然后与其他服务投票信息交换结果, 由于服务器 2 的编号大于服务器 1, 所以服务器 2 胜出,但是由于投票仍未到达半数,所以服务器 2 同样处于 LOOKING 状态。
- 服务器 3 启动, 给自己投票,然后与其他服务投票信息交换结果, 由于服务器 3 的编号大于服务器 2,1,所以服务器 3胜出, 并且此时投票数正好大于半数, 所以选举结束,服务器 3 处于LEADING 状态, 服务器 1, 服务器 2 处于 FOLLOWING 状态。
- 服务器 4 启动, 给自己投票, 同时与之前的服务器 1 ,2,3交换信息,尽管服务器 4 的编号最大,但之前服务器 3 已经胜出,所以服务器 4 只能处于 FOLLOWING 状态。
- 服务器 5 启动, 同上。FOLLOWING状态。
- 整个zookeeper集群启动以后,领导者就使用2888端口向从属机开始通信。
非全新集群选举:
对于运行正常的zookeeper集群,中途有机器down掉,需要重新选举时,选举过程就需要加入数据ID、服务器ID、和逻辑时钟。
这样选举就变成:
- 逻辑时钟小的选举结果被忽略,重新投票;(除去选举次数不完整的服务器)
- 统一逻辑时钟后,数据id大的胜出;(选出数据最新的服务器)
- 数据id相同的情况下,服务器id大的胜出。(数据相同的情况下, 选择服务器id最大,即权重最大的服务器)
4.Watch机制
在ZooKeeper中,引入了Watch机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事件触发了这个Watch,那么就会向指定客户端发送一个事件通知,来实现分布式的通知功能。
特点:
- 一次性触发
- 事件封装
- 异步发送
- 先注册再触发