������ʵս��ϰ
��һ�� �����İ�װ����
ǰ��
Hadoop��һ�ַ����ʹ��������ݵ�����ƽ̨,��Appach��һ����Java������ʵ�ֵĿ�Դ�����ļӿ�,�ڴ����������ɵļ�Ⱥ����ʵ���˶��ں��������ݽ��еķֲ�ʽ���㡣
������(Big Data)ָ����һ��ʱ�䷶Χ���ó����������߽��в��������ʹ��������ݼ���,����Ҫ�´���ģʽ���ܾ��и�ǿ�ľ����������췢�����������Ż������ĺ������������ʺͶ���������Ϣ�ʲ���
һ���ڵ���
ʹ��CentOS������а�װ��̨�����,�˴������н���;�����ڰ����ƹ���������������������,��������Ҫ��һ��������Hadoop֮ǰ�������ڵ���ġ�
1.����SSH���ܵ�¼
�����������¼��Ŀ����Ϊ���ܹ�������֮�������,����Ҫ���뼴�ɷá���������Կ��һ����
��������:
#! ÿ̨����������~/.ssh Ŀ¼���в���
[root@xja66 ~]# cd ~/.ssh
#! ������������,һ·�س�,���Բ�����Կ����Կ
[root@xja66 .ssh]# ssh-keygen -t rsa -P ''
#! ����������Ϣ˵�����ɳɹ�
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
******************** root@xja66
The key's randomart image is:
+---[RSA 2048]----+
| . ...o.|
|.. . o ..... |
|o.. . o = ...+. |
| Eoo + * o .. oo |
| =o* + S . o.|
| o =.* . . .. |
|..o.. o . . . |
| o+o.. . o |
| .++. .o |
+----[SHA256]-----+
#! �����е�id_rsa.pub�ļ����кϲ�(��ķ����ǽ����нڵ���ļ������ӵ�xja66������)
[root@xja66 .ssh]# cat ~/.ssh/id_rsa.pub | ssh root@xja66 'cat >> ~/.ssh/authorized_keys'
[root@xja67 .ssh]# cat ~/.ssh/id_rsa.pub | ssh root@xja66 'cat >> ~/.ssh/authorized_keys'
[root@xja68 .ssh]# cat ~/.ssh/id_rsa.pub | ssh root@xja66 'cat >> ~/.ssh/authorized_keys'
#! �鿴xja66�ϵ�authorized_keys�ļ�����,�������¼���
[root@xja66 .ssh]# more authorized_keys
ssh-rsa ***************************
ssh-rsa ***************************
ssh-rsa ***************************
#! ��xja66�ϵ�authorized_keys�ļ��ַ�������������
[root@xja66 .ssh]# scp ~/.ssh/authorized_keys root@xja67:~/.ssh/
[root@xja66.ssh]# scp ~/.ssh/authorized_keys root@xja68:~/.ssh/
#! ÿ̨����֮�����ssh�������¼����,�����Լ����Լ�
[root@xja66 ~]# ssh xja66
[root@xja66 ~]# ssh xja67
[root@xja67 ~]# ssh xja66
[root@xja66 ~]# ssh xja68
[root@xja68 ~]# ssh xja66
[root@xja66 ~]# ssh xja67
[root@xja67 ~]# ssh xja67
[root@xja67 ~]# ssh xja68
[root@xja68 ~]# ssh xja67
[root@xja67 ~]# ssh xja68
[root@xja68 ~]# ssh xja68
��������Ҫ���õ������ڵ��SSH���ܵ�¼,�������õ�ʱ�����������,�����Լ�����Ҫ���á�
2.������ͨ�û�admin
����������ʹ����ͨ�û�,������֪,���빫˾�����Dz���õ�root�û�,����root�û���Ȩ����,������ʹ��ѧϰ�Ȳ����á�
useradd admin ����admin�û�
Passwd admin ��admin�û���������
3.Ϊ��ͨ�û�����sudo�л�
sudo ������ Linux ϵͳ������,��ͨ�û�����ͨ�û�״̬��,��ɳ����û�����Ҫ��ɵ�����ʱִ�е����
��װ�����ĵ����ò���,�ֱ�װxja66,xja67,xja68��̨������
chmod u+w /etc/sudoers
��/etc/sudoers�ļ�,�ҵ�����һ��(91��),��root��������һ��,������ʾ:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
#whell ALL=(ALL) ALL
admin ALL=(ALL) NOPASSWD: ALL
����֮�� �ٰ�Ȩ�Ļ�ȥ
chmod u-w /etc/sudoers
4.���ļ�
��/optĿ¼�´����ļ���
(1)��/optĿ¼�´���module��software�ļ���
sudo mkdir module
sudo mkdir software
(2)��module��software�ļ��е�������cd
sudo mkdir /opt/module /opt/software
sudo chown bw:bw /opt/module /opt/software
�ϴ��ļ���software�ļ�����
[admin@xja66 ~]$ cd /opt/software/
[admin@xja66 software]$ ll
������ 1392412
-rw-rw-r--. 1 admin admin 277604 12�� 5 02:36 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 2237116 12�� 5 02:36 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 2112700 12�� 5 02:36 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 25034716 12�� 5 02:36 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 159295840 12�� 5 02:37 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 67938106 12�� 5 02:37 apache-flume-1.9.0-bin.tar.gz
-rw-rw-r--. 1 admin admin 314027421 12�� 5 02:37 apache-hive-3.1.2-bin.tar.gz
-rw-rw-r--. 1 admin admin 9311744 12�� 5 02:37 apache-zookeeper-3.5.7-bin.tar.gz
-rw-rw-r--. 1 admin admin 224565455 12�� 5 02:37 bigtable.lzo
-rw-rw-r--. 1 admin admin 338075860 12�� 5 02:36 hadoop-3.1.3.tar.gz
-rw-rw-r--. 1 admin admin 195013152 12�� 5 02:36 jdk-8u212-linux-x64.tar.gz
-rw-rw-r--. 1 admin admin 70159813 12�� 5 02:36 kafka_2.11-2.4.1.tgz
-rw-rw-r--. 1 admin admin 872303 12�� 5 02:37 mysql-connector-java-5.1.27-bin.jar
-rw-rw-r--. 1 admin admin 16870735 12�� 5 02:36 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
����
software�ļ����Ǵ������ѹ������,��module�ļ�����������װ��
5.�JDK
��ʹ�ð����Ʒ�����ʱ,ÿ���ڵ㶼�Ǵ�����,���Խڵ�����û���Դ���JDK,��������Ҫ������
[admin@xja66 ~]$ rpm -qa|grep java
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
tzdata-java-2018c-1.el7.noarch
java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
[admin@xja66 ~]$ rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 tzdata-java-2018c-1.el7.noarch java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 javapackages-tools-3.4.1-11.el7.noarch java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
����:can't create ���� lock on /var/lib/rpm/.rpm.lock (Ȩ����)
[admin@xja66 ~]$ su root
����:
[root@xja66 admin]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 tzdata-java-2018c-1.el7.noarch java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 javapackages-tools-3.4.1-11.el7.noarch java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
����
��һ��:�Ȳ� rpm -qa|grep java �������һ��Ѷ��� ȫɾ
�ڶ���:rpm -e --nodeps ��һ��Ѷ��� ������ �ո����
����,ɾ��������root�û��µ�Ȩ��,��������ͳ����˴���,���л���root�û��¡�
�����ڵ㶼��Ҫɾ��!!!
6.���û�������
����ʹ�� root
sudo vi /etc/profile.d/my-env.sh
ʹ����Ч ����sudo
source /etc/profile.d/my-env.sh
��������ǰ��������������ˡ�
����Hadoop�����
���ε���ϰ�в�ʹ��MapReduce��������,��ʹ��hdfs�������,yarn����,���Զ�MapReduce������û�й��ི��,�������˻���������,��Ҫ���������á�
1.��װJDK
��ѹ
[admin@xja66 ~]$ tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
���û�������
(1)�½�/etc/profile.d/my_env.sh�ļ�
[admin@xja66 ~]$ sudo vim /etc/profile.d/my_env.sh
[sudo] admin ������:
[admin@xja66 ~]$ source /etc/profile.d/my_env.sh
������������,Ȼ��(:wq)�˳�
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2) ����װ�ɹ�
[admin@xja66 ~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
(3)�ַ�JDK
[admin@xja66 ~]$ scp -r /opt/module/jdk1.8.0_212/ admin@xja67:/opt/module/
[admin@xja66 ~]$ scp -r /opt/module/jdk1.8.0_212/ admin@xja68:/opt/module/
ע��
�ַ�����Ҫ�����������������ڵ�Ļ���������source
2.Hadoop��װ
(1)��ѹ��װ��
[admin@xja66 ~]$ tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
[admin@xja66 ~]$ cd /opt/module/
[admin@xja66 module]$ ll
������ 8
drwxr-xr-x. 9 admin admin 4096 9�� 12 2019 hadoop-3.1.3
drwxr-xr-x. 7 admin admin 4096 4�� 2 2019 jdk1.8.0_212
(2)���û�������
[admin@xja66 module]$ sudo vim /etc/profile.d/my_env.sh
[sudo] admin ������:
[admin@xja66 module]$ source /etc/profile.d/my_env.sh
������������
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
ע��
�ں�������������ļ���,����Hadoop�ķַ�,��Ҫ������Ҫ�����������ڵ��Ͻ��л������������á�
(3)���ü�Ⱥ
������Ҫ��Hadoop�ĺ����ļ�core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,workers��������ļ�����Hadoop��/etc/hadoop�ļ���������ļ��к�Լ����ļ����������ġ�
[admin@xja66 ~]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[admin@xja66 hadoop]$ ls
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
container-executor.cfg log4j.properties
core-site.xml mapred-env.cmd
hadoop-env.cmd mapred-env.sh
hadoop-env.sh mapred-queues.xml.template
hadoop-metrics2.properties mapred-site.xml
hadoop-policy.xml shellprofile.d
hadoop-user-functions.sh.example ssl-client.xml.example
hdfs-site.xml ssl-server.xml.example
httpfs-env.sh user_ec_policies.xml.template
httpfs-log4j.properties workers
httpfs-signature.secret yarn-env.cmd
httpfs-site.xml yarn-env.sh
kms-acls.xml yarnservice-log4j.properties
kms-env.sh yarn-site.xml
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ��NameNode�ĵ�ַ -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://xja66:8020</value>
</property>
<!-- ָ��hadoop���ݵĴ洢Ŀ¼ -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- ����HDFS��ҳ��¼ʹ�õľ�̬�û�Ϊadmin -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>admin</value>
</property>
<!-- ���ø�admin(superUser)����ͨ���������ʵ������ڵ� -->
<property>
<name>hadoop.proxyuser.admin.hosts</name>
<value>*</value>
</property>
<!-- ���ø�bw(superUser)����ͨ�������û������� -->
<property>
<name>hadoop.proxyuser.admin.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web�˷��ʵ�ַ-->
<property>
<name>dfs.namenode.http-address</name>
<value>xja66:9870</value>
</property>
<!-- 2nn web�˷��ʵ�ַ-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xja68:9868</value>
</property>
<!-- ���Ի���ָ��HDFS����������1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ��MR��shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ָ��ResourceManager�ĵ�ַ-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xja67</value>
</property>
<!-- task�̳�nodemanager��������-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn������������������С�ڴ� -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn�������������������ڴ��С -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- �ر�yarn�������ڴ�������ڴ�����Ƽ�� -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ��MapReduce����������Yarn�� -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
workers
xja66
xja67
xja68
ע��
���ļ������ӵ����ݽ�β�������пո�,�ļ��в������п��С�
(4)������־�ľۼ�
��־�ۼ�����:Ӧ����������Ժ�,������������־��Ϣ�ϴ���HDFSϵͳ�ϡ�
��־�ۼ����ܺô�:���Է���IJ鿴��������������,���㿪�����ԡ�
ע��:������־�ۼ�����,��Ҫ��������NodeManager ��ResourceManager��HistoryManager��
����yarn-site.xml
vim yarn-site.xml
�ڸ��ļ����������������á�
<!-- ������־�ۼ����� -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- ������־�ۼ���������ַ -->
<property>
<name>yarn.log.server.url</name>
<value>http://xja66:19888/jobhistory/logs</value>
</property>
<!-- ������־����ʱ��Ϊ7�� -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(5)�ַ�
[admin@xja66 ~]$ scp -r /opt/module/hadoop-3.1.3/ admin@xja67:/opt/module/
[admin@xja66 ~]$ scp -r /opt/module/hadoop-3.1.3/ admin@xja68:/opt/module/
ע��
�ַ������������ڵ�Ļ���������������
(6)������Ⱥ
1.��ʽ��
�����Ⱥ�ǵ�һ������,��Ҫ��bw33�ڵ��ʽ��NameNode(ע���ʽ��֮ǰ,һ��Ҫ��ֹͣ�ϴ�����������namenode��datanode����,Ȼ����ɾ��data��log����)
[admin@xja66 ~]$ hdfs namenode -format
2.����HDFS
[admin@xja66 ~]$ start-dfs.sh
Starting namenodes on [xja66]
xja66: Warning: Permanently added the ECDSA host key for IP address '192.168.189.76' to the list of known hosts.
Starting datanodes
xja68: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
xja67: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [xja68]
3.����YARN
[admin@xja67 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
xja68: Warning: Permanently added the ECDSA host key for IP address '192.168.189.78' to the list of known hosts.
xja67: Warning: Permanently added the ECDSA host key for IP address '192.168.189.77' to the list of known hosts.
4.�鿴webҳ��
HDFS��webҳ��
�ر�
�ȹر�yarn
[admin@xja67 ~]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
�ٹر�hdfs
[admin@xja66 ~]$ stop-dfs.sh
Stopping namenodes on [xja66]
Stopping datanodes
Stopping secondary namenodes [xja68]
����
Ϊ�˸��ӱ�ݵĿ���Hadoop��Ⱥ,���ǿ��Ա�дһ���ű�һ������Hadoop,���������ǽ���һ����α�д,�˴���������,����Ȥ����ѧϰһ�¡�
����������Ҫ����һ��binĿ¼��Žű�
1.�ڼ�Ŀ¼�´���binĿ¼
2.����binĿ¼
3.��дhdp.sh�ű�
4.����:wq
5.�Ľű���Ȩ��
[admin@xja66 ~]$ mkdir bin
[admin@xja66 ~]$ cd bin
[admin@xja66 bin]$ vim hdp.sh
#��hdp.sh������������
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== ���� hadoop��Ⱥ ==================="
echo " --------------- ���� hdfs ---------------"
ssh xja66 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- ���� yarn ---------------"
ssh xja67 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- ���� historyserver ---------------"
ssh xja66 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== �ر� hadoop��Ⱥ ==================="
echo " --------------- �ر� historyserver ---------------"
ssh xja66 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- �ر� yarn ---------------"
ssh xja67 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- �ر� hdfs ---------------"
ssh xja66 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
[admin@xja66 bin]$ sudo chmod 777 hdp.sh
[sudo] admin ������:
[admin@xja66 ~]$ hdp.sh start
=================== ���� hadoop��Ⱥ ===================
--------------- ���� hdfs ---------------
Starting namenodes on [xja66]
Starting datanodes
Starting secondary namenodes [xja68]
--------------- ���� yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- ���� historyserver ---------------
Ϊ�˸��ӱ�ݵIJ鿴��Ⱥ���,���ǿ��Ա�дһ���ű�һ���鿴��
1.����binĿ¼
2.��дxcall.sh�ű�
3.����:wq
4.�Ľű���Ȩ��
[admin@xja66 ~]$ cd bin
[admin@xja66 bin]$ vim xcall.sh
#��xcall.sh����������:
#! /bin/bash
for i in xja66 xja67 xja68
do
echo --------- $i ----------
ssh $i "$*"
done
[admin@xja66 bin]$ sudo chmod 777 xcall.sh
[sudo] admin ������:
[admin@xja66 bin]$ xcall.sh jps
--------- xja66 ----------
7043 Jps
6360 DataNode
6682 NodeManager
6188 NameNode
6877 JobHistoryServer
--------- xja67 ----------
6500 Jps
5909 ResourceManager
5702 DataNode
6055 NodeManager
--------- xja68 ----------
5411 SecondaryNameNode
5283 DataNode
5752 Jps
5517 NodeManager
3.LZOѹ��
hadoop��������֧��lzoѹ��,����Ҫʹ��twitter�ṩ��hadoop-lzo��Դ�����hadoop-lzo������hadoop��lzo���б���,���벽�����¡�
1.������ú��hadoop-lzo-0.4.20.jar ����hadoop-3.1.3/share/hadoop/common/
2.ͬ��hadoop-lzo-0.4.20.jar�����������ڵ�
3.core-site.xml��������֧��LZOѹ��
4.�����������ڵ��core-site.xml��������
[admin@xja66 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[admin@xja66 common]$ rz -E
rz waiting to receive.
[admin@xja66 common]$ ll
������ 7352
-rw-r--r--. 1 admin admin 4096811 9�� 12 2019 hadoop-common-3.1.3.jar
-rw-r--r--. 1 admin admin 2878235 9�� 12 2019 hadoop-common-3.1.3-tests.jar
-rw-r--r--. 1 admin admin 129977 9�� 12 2019 hadoop-kms-3.1.3.jar
-rw-r--r--. 1 admin admin 193831 12�� 7 15:34 hadoop-lzo-0.4.20.jar
-rw-r--r--. 1 admin admin 201616 9�� 12 2019 hadoop-nfs-3.1.3.jar
drwxr-xr-x. 2 admin admin 4096 9�� 12 2019 jdiff
drwxr-xr-x. 2 admin admin 4096 9�� 12 2019 lib
drwxr-xr-x. 2 admin admin 4096 9�� 12 2019 sources
drwxr-xr-x. 3 admin admin 4096 9�� 12 2019 webapps
[admin@xja66 ~]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[admin@xja66 hadoop]$ vim core-site.xml
#core-site.xml��������������:
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
��������
1.Zookeeper��װ
��Ⱥ�滮
| ��Ŀ | ������1 | ������2 | ������3 |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
1.��ѹ
[admin@xja66 ~]$ tar -zxvf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
2.������
[admin@xja66 ~]$ cd /opt/module/
[admin@xja66 module]$ ll
������ 12
drwxrwxr-x. 6 admin admin 4096 12�� 9 19:07 apache-zookeeper-3.5.7-bin
drwxr-xr-x. 11 admin admin 4096 12�� 9 07:05 hadoop-3.1.3
drwxr-xr-x. 7 admin admin 4096 4�� 2 2019 jdk1.8.0_212
[admin@xja66 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
3.���÷��������
����zkData�ļ���,����zkData���дmyid�ļ�,��ÿ���ڵ��myid�������ӷ��������1,2,3
[admin@xja66 module]$ cd zookeeper-3.5.7/
[admin@xja66 zookeeper-3.5.7]$ mkdir zkData
[admin@xja66 zookeeper-3.5.7]$ cd zkData/
[admin@xja66 zkData]$ vim myid
ע�� �ڷַ���ÿ���ڵ㶼��Ҫ��myid�ļ�,ÿ���ڵ�ı�Ŷ���һ��������

4.����zoo.cfg�ļ�
��1��������zoo_sample_cfg�ļ�
[admin@xja66 conf]$ ll
������ 12
-rw-r--r--. 1 admin admin 535 5�� 4 2018 configuration.xsl
-rw-r--r--. 1 admin admin 2712 2�� 7 2020 log4j.properties
-rw-r--r--. 1 admin admin 922 2�� 7 2020 zoo_sample.cfg
[admin@xja66 conf]$ mv zoo_sample.cfg zoo.cfg
[admin@xja66 conf]$ ll
������ 12
-rw-r--r--. 1 admin admin 535 5�� 4 2018 configuration.xsl
-rw-r--r--. 1 admin admin 2712 2�� 7 2020 log4j.properties
-rw-r--r--. 1 admin admin 922 2�� 7 2020 zoo.cfg
��2����zoo_cfg�ļ�
�����ݴ洢·������
dataDir=/opt/module/zookeeper-3.5.7/zkData
������������
#######################cluster##########################
server.1=xja66:2888:3888
server.2=xja67:2888:3888
server.3=xja68:2888:3888
5.�ַ������������ڵ�
[admin@xja66 conf]$ scp -r /opt/module/zookeeper-3.5.7/ admin@xja67:/opt/module/
[admin@xja66 conf]$ scp -r /opt/module/zookeeper-3.5.7/ admin@xja68:/opt/module/
6.����3���ڵ㻷������
[admin@xja66 conf]$ sudo vim /etc/profile.d/my_env.sh
[sudo] admin ������:
##�ڻ�������������ZOOKEEPER
##ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[admin@xja66 conf]$ source /etc/profile.d/my_env.sh
7.�ķ��������
��������鿴����3
8.��д�����ű�
����binĿ¼
��дzk.sh�ű�
����zk.shȨ��
����
�ر�
[admin@xja66 ~]$ cd bin
[admin@xja66 bin]$ ll
������ 8
-rwxrwxrwx. 1 admin admin 1104 12�� 9 07:33 hdp.sh
-rwxrwxrwx. 1 admin admin 99 12�� 9 07:39 xcall.sh
[admin@xja66 bin]$ vim zk.sh
[admin@xja66 bin]$ sudo chmod u+x zk.sh
[sudo] admin ������:
[admin@xja66 bin]$ zk.sh start
---------- zookeeper xja66 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper xja67 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper xja68 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
�ű�����
#!/bin/bash
case $1 in
"start"){
for i in xja66 xja67 xja68
do
echo ---------- zookeeper $i ���� ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in xja66 xja67 xja68
do
echo ---------- zookeeper $i ֹͣ ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in xja66 xja67 xja68
do
echo ---------- zookeeper $i ״̬ ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
2.Kafka��װ
��Ⱥ�滮
| ������1 | ������2 | ������3 | |
|---|---|---|---|
| Kafka | Kafka | Kafka | Kafka |
1.��ѹ
[admin@xja66 ~]$ tar -zxvf /opt/software/kafka_2.11-2.4.1.tgz -C /opt/module/
2.���ļ���
[admin@xja66 ~]$ mv /opt/module/kafka_2.11-2.4.1/ /opt/module/kafka
[admin@xja66 ~]$ cd /opt/module/
[admin@xja66 module]$ ll
������ 16
drwxr-xr-x. 11 admin admin 4096 12�� 9 07:05 hadoop-3.1.3
drwxr-xr-x. 7 admin admin 4096 4�� 2 2019 jdk1.8.0_212
drwxr-xr-x. 6 admin admin 4096 3�� 3 2020 kafka
drwxrwxr-x. 8 admin admin 4096 12�� 9 23:28 zookeeper-3.5.7
3.������־�ļ�
[admin@xja66 module]$ cd kafka/
[admin@xja66 kafka]$ mkdir logs
[admin@xja66 kafka]$ ll
������ 56
drwxr-xr-x. 3 admin admin 4096 3�� 3 2020 bin
drwxr-xr-x. 2 admin admin 4096 3�� 3 2020 config
drwxr-xr-x. 2 admin admin 4096 12�� 9 23:43 libs
-rw-r--r--. 1 admin admin 32216 3�� 3 2020 LICENSE
drwxrwxr-x. 2 admin admin 4096 12�� 9 23:45 logs
-rw-r--r--. 1 admin admin 337 3�� 3 2020 NOTICE
drwxr-xr-x. 2 admin admin 4096 3�� 3 2020 site-docs
4.�������ļ�
[admin@xja66 kafka]$ cd config/
[admin@xja66 config]$ vim server.properties
##����������
#broker��ȫ��Ψһ���,�����ظ�(��)
broker.id=1
#ɾ��topic����ʹ��(����)
delete.topic.enable=true
#kafka������־��ŵ�·��(��)
log.dirs=/opt/module/kafka/logs
#��������Zookeeper��Ⱥ��ַ(��)
zookeeper.connect=xja66:2181,xja67:2181,xja68:2181
ע��:broker.id��ÿ���ڵ㶼��һ��,�ڷַ��������ڵ��,Ҫ�����������ڵ��broker.id�ֱ��Ϊ2,3��
5.���û�������
[admin@xja66 ~]$ sudo vim /etc/profile.d/my_env.sh
[sudo] admin ������:
##KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[admin@xja66 ~]$ source /etc/profile.d/my_env.sh
6.�ַ�
[admin@xja66 ~]$ scp -r /opt/module/kafka/ admin@xja67:/opt/module/
[admin@xja66 ~]$ scp -r /opt/module/kafka/ admin@xja68:/opt/module/
�ַ���ɺ�Ҫ�������û�������,����нڵ��broker.idҲ��Ҫ�ġ�
7.��д�ű�
�ű��ı�д��֮ǰ�Ĺ�������,������binĿ¼��,��дkf.sh�ļ�,���ű�����д��ȥ,��ɺ��ļ���Ȩ��,����ʹ�á�
[admin@xja66 ~]$ cd bin
[admin@xja66 bin]$ vim kf.sh
[admin@xja66 bin]$ sudo chmod u+x kf.sh
[sudo] admin ������:
[admin@xja66 bin]$ zk.sh start
---------- zookeeper xja66 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper xja67 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper xja68 ���� ------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[admin@xja66 bin]$ kf.sh start
--------���� xja66 Kafka-------
--------���� xja67 Kafka-------
--------���� xja68 Kafka-------
[admin@xja66 bin]$ xcall.sh jps
--------- xja66 ----------
3248 QuorumPeerMain
3786 Jps
3724 Kafka
--------- xja67 ----------
4023 Jps
3484 QuorumPeerMain
3948 Kafka
--------- xja68 ----------
4004 Kafka
3545 QuorumPeerMain
4061 Jps
�ű�����
#! /bin/bash
case $1 in
"start"){
for i in xja66 xja67 xja68
do
echo " --------���� $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in xja66 xja67 xja68
do
echo " --------ֹͣ $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
Kafka��������
1)�鿴Kafka Topic�б�
kafka-topics.sh --zookeeper xja66:2181/kafka --list
2)����Kafka Topic
������־����
kafka-topics.sh --zookeeper xja66:2181,xja67:2181,xja68:2181 --create --replication-factor 1 --partitions 1 --topic topic_log
3)ɾ��Kafka Topic
kafka-topics.sh --delete --zookeeper xja66:2181,xja67:2181,xja68:2181 --topic topic_log
4)Kafka������Ϣ
kafka-console-producer.sh --broker-list xja66:9092 --topic topic_log
hello world
5)Kafka������Ϣ
kafka-console-consumer.sh --bootstrap-server xja67:9092 --topic topic_log
�Cfrom-beginning:����������������е����ݶ���ȡ����������ҵ��ѡ���Ƿ����Ӹ����á�
6)�鿴Kafka Topic����
kafka-topics.sh --zookeeper bw33:2181/kafka
�Cdescribe --topic topic_log
����topic_logΪ�������ʹ��
kafka-topics.sh --topic topic_log --partitions 3 --zookeeper xja66:2181 --create --replication-factor 3
3.Flume��װ
��־�ɼ�Flume
��Ⱥ�滮
| ������1 | ������2 | ������3 | |
|---|---|---|---|
| Flume(�ɼ���־) | Flume | Flume |
1.��ѹ
��ѹapache-flume-1.9.0-bin.tar.gz��/opt/module/Ŀ¼��
[admin@xja66 ~]$ tar -zxvf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
2.���ļ���
[admin@xja66 ~]$ mv /opt/module/apache-flume-1.9.0-bin/ /opt/module/flume
[admin@xja66 ~]$ cd /opt/module/
[admin@xja66 module]$ ll
������ 20
drwxrwxr-x. 7 admin admin 4096 12�� 10 06:05 flume
drwxr-xr-x. 11 admin admin 4096 12�� 9 07:05 hadoop-3.1.3
drwxr-xr-x. 7 admin admin 4096 4�� 2 2019 jdk1.8.0_212
drwxr-xr-x. 7 admin admin 4096 12�� 9 23:45 kafka
drwxrwxr-x. 8 admin admin 4096 12�� 9 23:28 zookeeper-3.5.7
3.ɾ���ܰ�
��lib�ļ����µ�guava-11.0.2.jarɾ���Լ���Hadoop 3.1.3
[admin@xja66 module]$ rm /opt/module/flume/lib/guava-11.0.2.jar
4.�����ļ�
��flume/conf�µ�flume-env.sh.template�ļ���Ϊflume-env.sh,������flume-env.sh�ļ�
��/opt/module/flume/confĿ¼�´���������file-flume-kafka.conf�ļ�
[admin@xja66 flume]$ cd conf/
[admin@xja66 conf]$ mv flume-env.sh.template flume-env.sh
[admin@xja66 conf]$ vim flume-env.sh
[admin@xja66 conf]$ vim file-flume-kafka.conf
flume-env.sh
##��JAVA_HOMEΪ�Լ���JDK��װĿ¼����
export JAVA_HOME=/opt/module/jdk1.8.0_212
file-flume-kafka.conf
#���������
a1.sources = r1
a1.channels = c1
#����source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
#����channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = xja66:9092,xja67:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#��source��channel�Լ�sink��channel�Ĺ�ϵ
a1.sources.r1.channels = c1
5.���û�������
##FLUME_HOME
export FLUME_HOME=/opt/module/flume
export PATH=$PATH:$FLUME_HOME/bin
6.�ַ�
������־�ɼ�ֻ��Ҫǰ�����ڵ�,����ֻ��Ҫ��flume�ַ����ڶ����ڵ�Ϳ�����,�ַ���ɺ�Ҫ�������û�������,�ַ���������:
[admin@xja66 conf]$ scp -r /opt/module/flume/ admin@xja67:/opt/module/
��������
flume-ng agent --name a1 --conf-file /opt/module/flume/conf/file-flume-kafka.conf &
��־�ɼ�Flume����ֹͣ�ű�
f1.sh
#! /bin/bash
case $1 in
"start"){
for i in xja66 xja67
do
echo " --------���� $i �ɼ�flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"
done
};;
"stop"){
for i in xja66 xja67
do
echo " --------ֹͣ $i �ɼ�flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs kill -9 "
done
};;
esac
ע��:��Ҫ������Ȩ��
����Kafka����Flume
��Ⱥ�滮
| ������1 | ������2 | ������3 | |
|---|---|---|---|
| Flume(����Kafka) | Flume |
��װ
����һ���ڵ��ϵ�flume�ַ����������ڵ�,Ȼ���ٽ�������,��Ҫ�������û�������
����
�ڽڵ�3��/opt/module/flume/confĿ¼�´���kafka-flume-hdfs.conf�ļ�
kafka-flume-hdfs.conf
## ���
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
##ÿ������д�뵽channel�е�event����
a1.sources.r1.batchSize = 5000
##���ʱ��д��һ�� ����������˭�ȴﵽ��˭��
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = xja66:9092,xja67:9092,xja68:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bw.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
##���������յĴ����ļ����ڵ�Ŀ¼
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
##����������ݵ�Ŀ¼
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
ÿ���ļ�����ֵ
a1.channels.c1.maxFileSize = 2146435071
##����ܴ�Ŷ��ٸ�����
a1.channels.c1.capacity = 1000000
##putд�뵽channel֮ǰ ��Ҫ�ȼ��channel���Ƿ��пռ����������� �����
##��ô��ȥд ���û�� �͵� ��� ����ʱ�� �ͻع�
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
##��������ÿ��Сʱ����һ��Ŀ¼���д?
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.rounvUnit = hour
##�����������Ǵ���С�ļ�ר�õ� rollInterval ����ʱ�������ļ�
##Rollsize �������������� 128mһ���ļ�
##Rollcount �������ݸ�������
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## ��������ļ���ԭ���ļ���
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## ƴװ
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
��־����Flume����ֹͣ�ű�
f2.sh
#! /bin/bash
case $1 in
"start")
for i in xja68
do
echo " --------���� $i ����flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka_flume_hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &"
done
;;
"stop")
for i in xja68
do
echo " --------ֹͣ $i ����flume-------"
ssh $i "ps -ef | grep kafka_flume_hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
;;
esac
ע��:��Ҫ������Ȩ��
�ġ�����
�����Ѿ���ν�����α�д�ű�,�˴��Ͳ����н��⡣
1.�ɼ�ͨ������/ֹͣ�ű�
Ϊ�˼���������,����ʹ��һ�������ű���
����������һ�²ɼ�ͨ������/ֹͣ�ű�
1.�����ļ�Ⱥ������Zookeeper,Hadoop,Kafka,Flume
2.�ű���������Ϊcluster.sh,����Ϊstart,�ر�Ϊstop
#!/bin/bash
case $1 in
"start"){
echo ================== ���� ��Ⱥ ==================
#���� Zookeeper��Ⱥ
zk.sh start
#���� Hadoop��Ⱥ
hdp.sh start
#���� Kafka�ɼ���Ⱥ
kf.sh start
#���� Flume�ɼ���Ⱥ
f1.sh start
#���� Flume���Ѽ�Ⱥ
f2.sh start
};;
"stop"){
echo ================== ֹͣ ��Ⱥ ==================
#ֹͣ Flume���Ѽ�Ⱥ
f2.sh stop
#ֹͣ Flume�ɼ���Ⱥ
f1.sh stop
#ֹͣ Kafka�ɼ���Ⱥ
kf.sh stop
#ֹͣ Hadoop��Ⱥ
hdp.sh stop
#ֹͣ Zookeeper��Ⱥ
zk.sh stop
};;
esac
2.��Ⱥ���н��̲鿴�ű�
Ϊ�˿��ٲ���3���ڵ�,���DZ�д�˼�Ⱥ���н��̲鿴�ű�
#! /bin/bash
for i in bw33 bw34 bw35
do
echo --------- $i ----------
ssh $i "$*"
done
3.ģ������
Ϊ��ģ��ʵ���������,����������ģ���û���Ϊ��־,���潲����־���ɵ����ݡ�
1.������־Ŀ¼
��module·���´���applogĿ¼,���ڴ�����ɵ���־����־���ɼܰ���
2.����application.properties�ļ�
# �ⲿ���ô�
logging.config=./logback.xml
#ҵ������
#�����Լ������������,��2021-12-10
mock.date=****-**-**
#ģ�����ݷ���ģʽ
mock.type=log
#mock.type=http
#httpģʽ��,���͵ĵ�ַ
mock.url=http://localhost:8080/applog
#��������
mock.startup.count=100
#�豸���ֵ
mock.max.mid=50
#��Ա���ֵ
mock.max.uid=500
#��Ʒ���ֵ
mock.max.sku-id=10
#ҳ��ƽ������ʱ��
mock.page.during-time-ms=20000
#������� �ٷֱ�
mock.error.rate=3
#ÿ����־�����ӳ� ms
mock.log.sleep=10
#��Ʒ������Դ �û���ѯ,��Ʒ�ƹ�,�����Ƽ�, �����
mock.detail.source-type-rate=40:25:15:20
3.path.json
���ļ��������÷���·��
��������,������������û����·����
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":50 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comments","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comments","home"],"rate":10 }
]
4.logback�����ļ�
��������־����·��,����������
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
</configuration>
ע��:����Ӧ�û���һ����־���ɼܰ�,�������ϴ���applog�ļ�����
5.���мܰ�
java -jar �ܰ�
6.��־���ɽű�
lg.sh
#!/bin/bash
for i in xja66 xja67; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2020-05-10.jar >/dev/null 2>&1 &"
done
�塢�û���Ϊ��־�ռ�
1.������Ⱥ,ʹ�����ǵ�һ�������ű�cluster.sh
2.�����û���Ϊ��־��Ϣ,����ͨ��lg.sh�ֶ�ģ�����ݵ���
3.�鿴hdfs����������
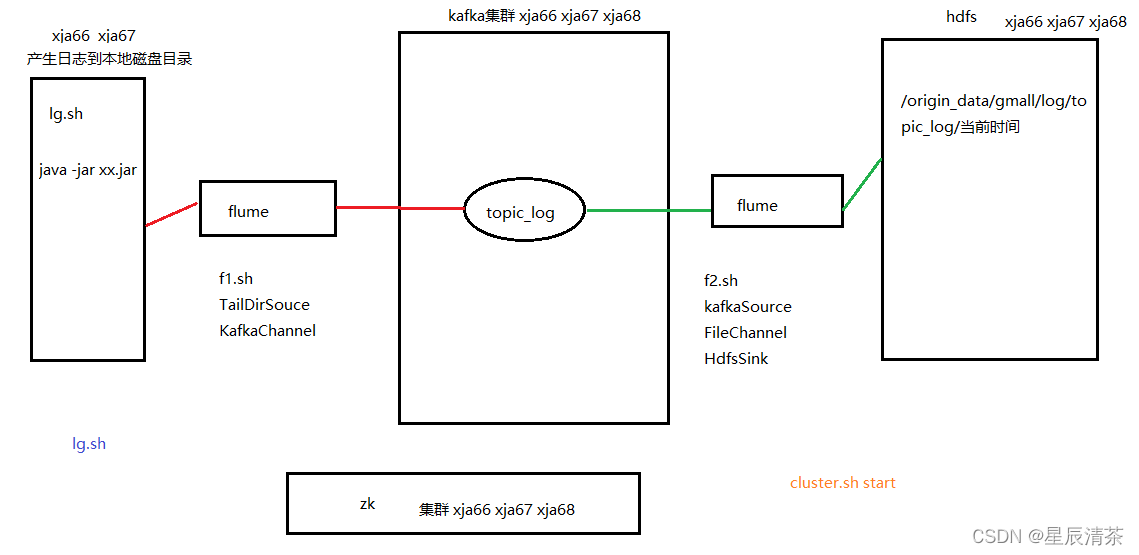
�ܽ�
������Ҫ���ڰ�װ����,����ͨ��flume�ɼ��û���Ϊ��־,���䴫��kafka,������һ��flume����kafka�ռ�����Ϣ,���ϴ���hdfs�ϡ�ͨ�����µ�ѧϰ,�����˽�˴����ݸ��������������ϵ��һ��,��������������ĵ�Ϊ����ѧϰʱ��¼,�����ο�ѧϰ,���漰��ҵ��;,������Ȩ,����ϵɾ��������Ȩ����ϵ��ɾ��