һ������
1����hadoopĿ¼�²�������,ll�鿴
cd /opt/module/hadoop-3.1.3/etc/hadoop/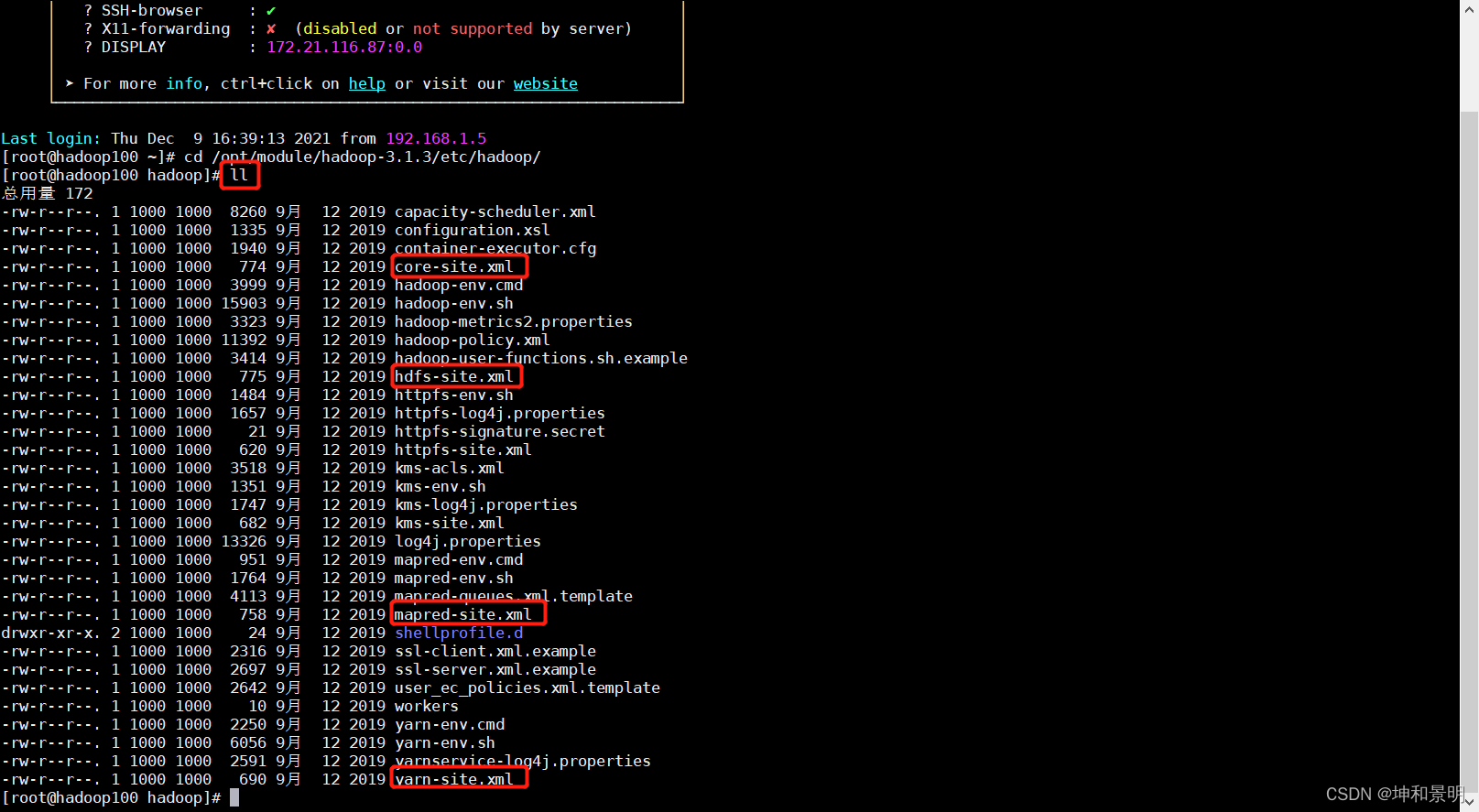
2�������ĸ��ļ��������ø��� ,������ŵ�configuration��ǩ��
(1)����core-site.xml�ļ�
����:vi?core-site.xml
<configuration>
<!-- ָ��HDFS��NameNode�ĵ�ַ -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9820</value>
</property>
<!-- ָ��Hadoop����ʱ�����ļ��Ĵ洢Ŀ¼ -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data/tmp</value>
</property>
</configuration>(2)����hdfs-site.xml
����:vi hdfs-site.xml
<configuration>
<!-- ָ��HDFS���������� -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>(3)����yarn-site.xml
����:vi?yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Reducer��ȡ���ݵķ�ʽ -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ָ��YARN��ResourceManager�ĵ�ַ -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,
HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>(4)����mapred-site.xml
����:vi?mapred-site.xml
<configuration>
<!-- ָ��MR������YARN�� -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>��������
1��?��ʽ��NameNode(��һ������ʱ��ʽ��,�Ժ�Ͳ�Ҫ�ܸ�ʽ��)��ʽ������:?
hdfs namenode �Cformat2������NameNode��DataNode,����:
hdfs --daemon start namenode
hdfs --daemon start datanode3������resourcemanager��nodemanager,����:
yarn --daemon start resourcemanager
yarn --daemon start nodemanager4������jps�鿴java����
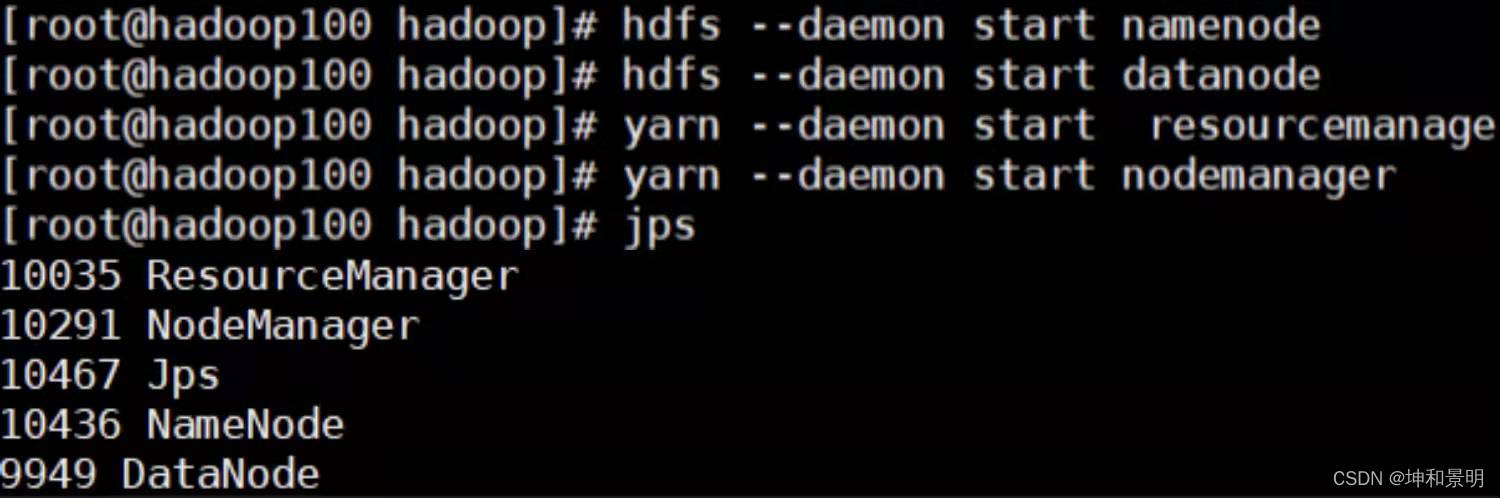
?��ʱ����ܻ�����������������,������һ����������Ӧ�þͿ�����,���������Ӧ�þ���vi�ļ����ô���,�����ľͿ����ˡ�
5��killɱ������
kill ���̺�