��1�� HDFS
1.1 HDFS��������������
? ����������Խ��Խ��,��һ������ϵͳ�治�����е�����,��ô�ͷ��䵽����IJ���ϵͳ�����Ĵ�����,���Dz����������ά��,������Ҫһ��ϵͳ��������̨�����ϵ��ļ�,����Ƿֲ�ʽ�ļ�����ϵͳ��HDFSֻ�Ƿֲ�ʽ�ļ�����ϵͳ�е�һ����
- HDFS(Hadoop Distributed File System):����һ���ļ�ϵͳ�����ڴ洢�ļ�,ͨ��Ŀ¼������λ�ļ�;���,���Ƿֲ�ʽ��,�ɺܶ��������������ʵ���书��,��Ⱥ�еķ������и��ԵĽ�ɫ��
- ʹ�ó���:�ʺ�һ��д��,��ζ����ij�����һ���ļ�����������д��ر�֮��Ͳ���Ҫ�ı䡣
1.2 HDFS��ȱ��
�ŵ�
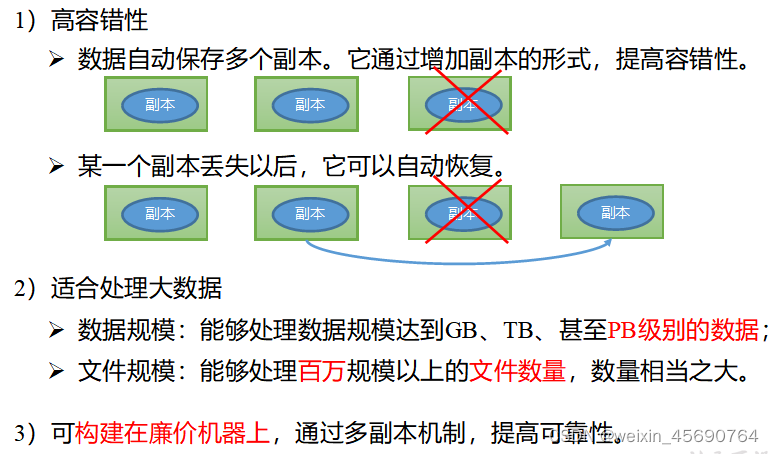
ȱ��

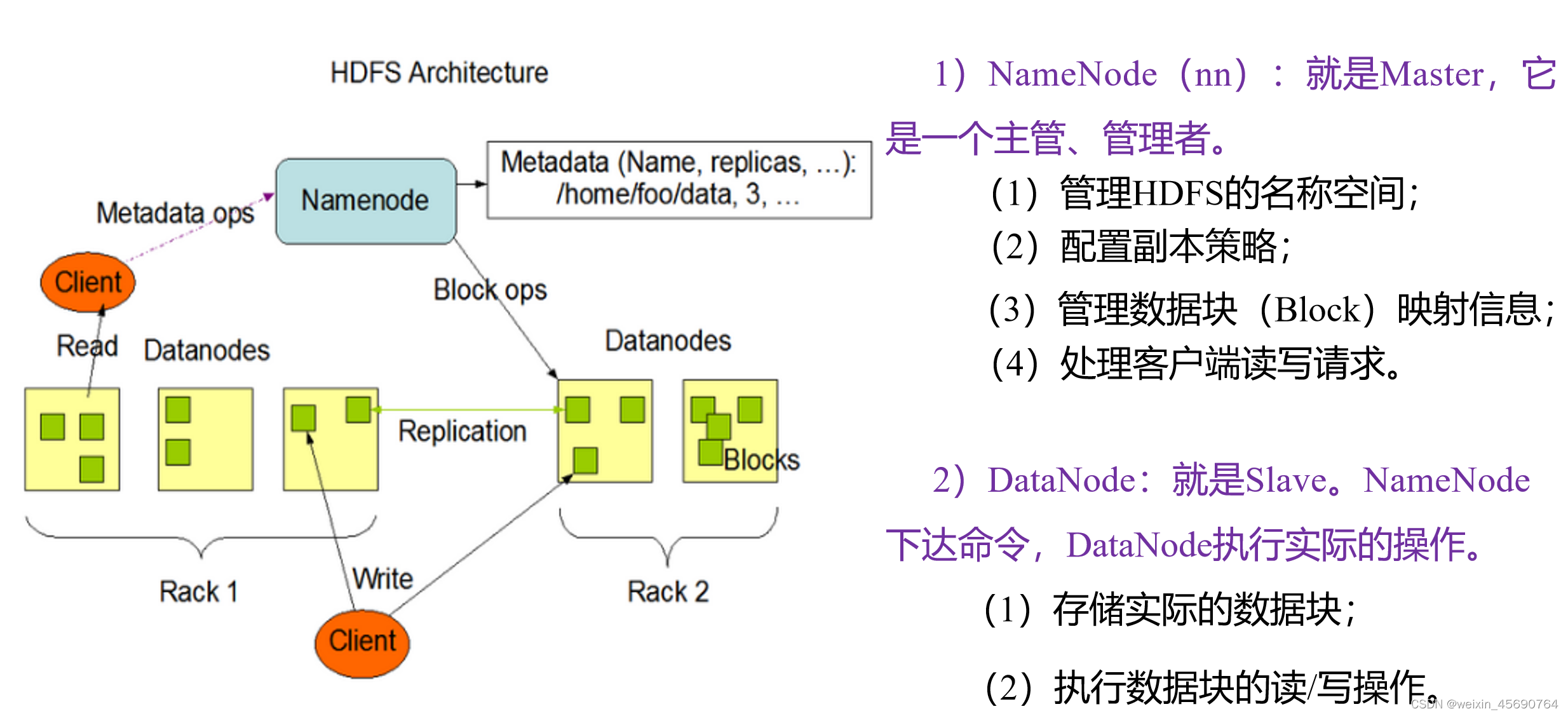
1.3 HDFS��ɼܹ�
1.4 HDFS�ļ����С(�����ص�)
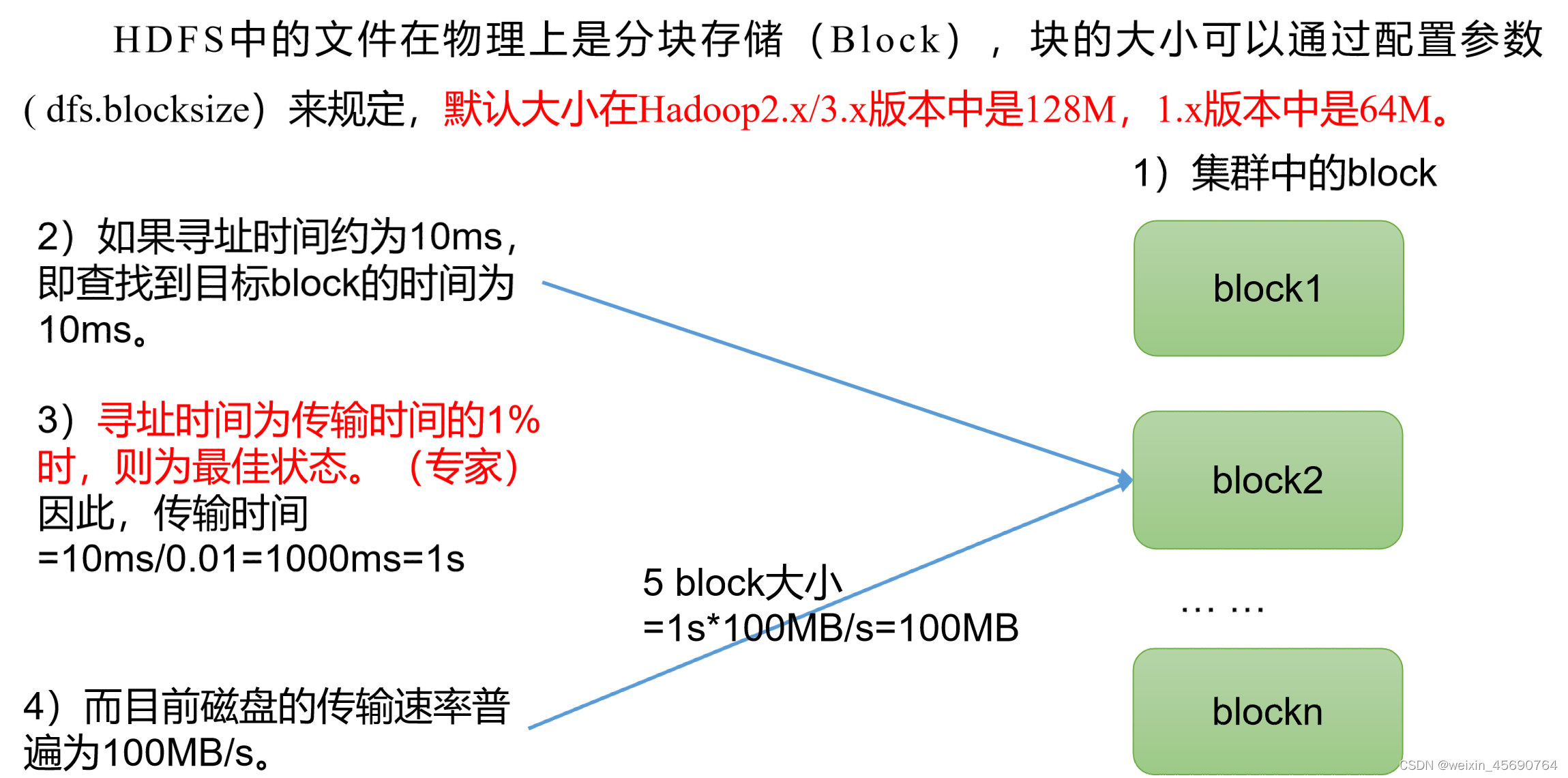
˼����:Ϊʲô��Ĵ�С��������̫С,Ҳ��������̫��?
- HDFS�Ŀ�����̫С,������Ѱַʵ��,����һֱ���ҿ�Ŀ�ʼλ��;
- ��������õ�̫��,�Ӵ��̴������ݵ�ʱ������Դ��ڶ�λ����鿪ʼλ������Ҫ��ʱ�䡣���³����ڴ����������ʱ,��dz�����
�ܽ�:HDFS��Ĵ�С������Ҫȡ���ڴ��̴����ٶȡ�
��2�� HDFS��Shell����(�����ص�)
2.1 �����
hadoop fs �������� OR hdfs dfs �������� �C ��������ȫ��ͬ�ġ�
2.2 �����ȫ
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop fs
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
2.3 �����������
2.3.1 ������
1)����Hadoop��Ⱥ(��������IJ���)
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2)-help:�������������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
3)����/sanguo�ļ���
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo
2.3.2 �ϴ�
1)-moveFromLocal:�ӱ��ؼ���ճ����HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
����:
shuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
2)-copyFromLocal:�ӱ����ļ�ϵͳ�п����ļ���HDFS·��ȥ
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
����:
weiguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:��ͬ��copyFromLocal,����������ϰ����put**(��Ҫ)**
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
����:
wuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:��һ���ļ����Ѿ����ڵ��ļ�ĩβ
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
����:
liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2.3.3 ����
1)-copyToLocal:��HDFS����������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:��ͬ��copyToLocal,����������ϰ����get(��Ҫ)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
2.3.4 ֱ�Ӳ���
1)-ls: ��ʾĿ¼��Ϣ
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:��ʾ�ļ�����
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
chgrp �ı��û��顢chmod�ı��û�Ȩ�ޡ�chown�ı�������
3)-chgrp��-chmod��-chown:Linux�ļ�ϵͳ�е��÷�һ��,���ļ�����Ȩ��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4)-mkdir:����·��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:��HDFS��һ��·��������HDFS����һ��·��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:��HDFSĿ¼���ƶ��ļ�
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:��ʾһ���ļ���ĩβ1kb������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:ɾ���ļ����ļ���
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:�ݹ�ɾ��Ŀ¼��Ŀ¼��������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-duͳ���ļ��еĴ�С��Ϣ(��ʾ�ļ�Ŀ¼�����ļ���С)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
? ˵��:27��ʾ�ļ���С;81��ʾ27*3������;/jinguo��ʾ�鿴��Ŀ¼
11)-setrep:����HDFS���ļ��ĸ�������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jj3dfwvw-1639145573073)(file:///C:\Users\10853\AppData\Local\Temp\ksohtml19728\wps2.jpg)]
? �������õĸ�����ֻ�Ǽ�¼��NameNode��Ԫ������,�Ƿ���Ļ�����ô�ั��,���ÿ�DataNode����������ΪĿǰֻ��3̨�豸,���Ҳ��3������,ֻ�нڵ��������ӵ�10̨ʱ,���������ܴﵽ10��
��3�� HDFS ��API����
3.1 �ͻ��˻�����
1)�ҵ����ϰ�·���µ�Windows�����ļ���,����hadoop-3.1.0��������·��(����d:\)��
2)����HADOOP_HOME��������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-wweNDQzc-1639145573074)(C:\Users\10853\AppData\Roaming\Typora\typora-user-images\image-20211210185010809.png)]
3)����Path����������
*ע��:�������������������,���������������ԡ�*
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-5admeGYR-1639145573074)(C:\Users\10853\AppData\Roaming\Typora\typora-user-images\image-20211210185051699.png)]
4)��IDEA�д���һ��Maven����HdfsClientDemo,��������Ӧ����������+��־����
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
? ����Ŀ��src/main/resourcesĿ¼��,�½�һ���ļ�,����Ϊ��log4j.properties��,���ļ�������
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5)��������:com.atguigu.hdfs
6)����HdfsClient��
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException, InterruptedException {
// 1 ��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
// FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration,"atguigu");
// 2 ����Ŀ¼
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
// 3 �ر���Դ
fs.close();
}
}
7)ִ�г���
�ͻ���ȥ����HDFSʱ,����һ���û����ݵġ�Ĭ�������,HDFS�ͻ���(hdfs://hadoop102:8020)API��Ӳ���WindowsĬ���û�����HDFS,�ᱨȨ���쳣���������ڷ���HDFSʱ,һ��Ҫ�����û���web��(http://hadoop102:9870)
org.apache.hadoop.security.AccessControlException: Permission denied: user=56576, access=WRITE, inode="/xiyou/huaguoshan":atguigu:supergroup:drwxr-xr-x
3.2 HDFS��API����ʵ��
3.2.1 HDFS�ļ��ϴ�(���Բ������ȼ�)
1)��дԴ����
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 ��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 �ϴ��ļ�
fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new Path("/xiyou/huaguoshan"));
// 3 �ر���Դ
fs.close();
}
2)��hdfs-site.xml��������Ŀ��resources��ԴĿ¼��
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3)�������ȼ�
? �������ȼ�����:(1)�ͻ��˴��������õ�ֵ >(2)ClassPath�µ��û��Զ��������ļ� >(3)Ȼ���Ƿ��������Զ�������(xxx-site.xml) >(4)��������Ĭ������(xxx-default.xml)
3.2.2 HDFS�ļ�����
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 ��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 ִ�����ز���
// boolean delSrc ָ�Ƿ�ԭ�ļ�ɾ��
// Path src ָҪ���ص��ļ�·��
// Path dst ָ���ļ����ص���·��
// boolean useRawLocalFileSystem �Ƿ����ļ�У��
fs.copyToLocalFile(false, new Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("d:/sunwukong2.txt"), true);
// 3 �ر���Դ
fs.close();
}
? ע��:���ִ���������,���ز����ļ�,�п���������Ե���֧�ֵ����п���,��Ҫ��װһ�������п⡣
3.2.3 HDFS�ļ��������ƶ�
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{
// 1 ��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 ���ļ�����
fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("/xiyou/huaguoshan/meihouwang.txt"));
// 3 �ر���Դ
fs.close();
}
3.2.4 HDFSɾ���ļ���Ŀ¼
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 ��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 ִ��ɾ��
fs.delete(new Path("/xiyou"), true);
// 3 �ر���Դ
fs.close();
}
3.2.5 HDFS �ļ�����鿴
? �鿴�ļ����ơ�Ȩ�ޡ����ȡ�����Ϣ
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException {
// 1��ȡ�ļ�ϵͳ
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 ��ȡ�ļ�����
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// ��ȡ����Ϣ
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 �ر���Դ
fs.close();
}
3.2.6 HDFS �ļ����ļ����ж�
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 ��ȡ�ļ�������Ϣ
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 �ж����ļ������ļ���
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// ������ļ�
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 �ر���Դ
fs.close();
}