Kafka是一种高吞吐量、分布式、基于发布-订阅模型的消息系统,最初由LinkedIn公司开发,使用Scala语言编写,目前是Apache的开源项目,已被许多数据处理框架用作默认消息队列,比如Hadoop,Spark等。
1 基本概念
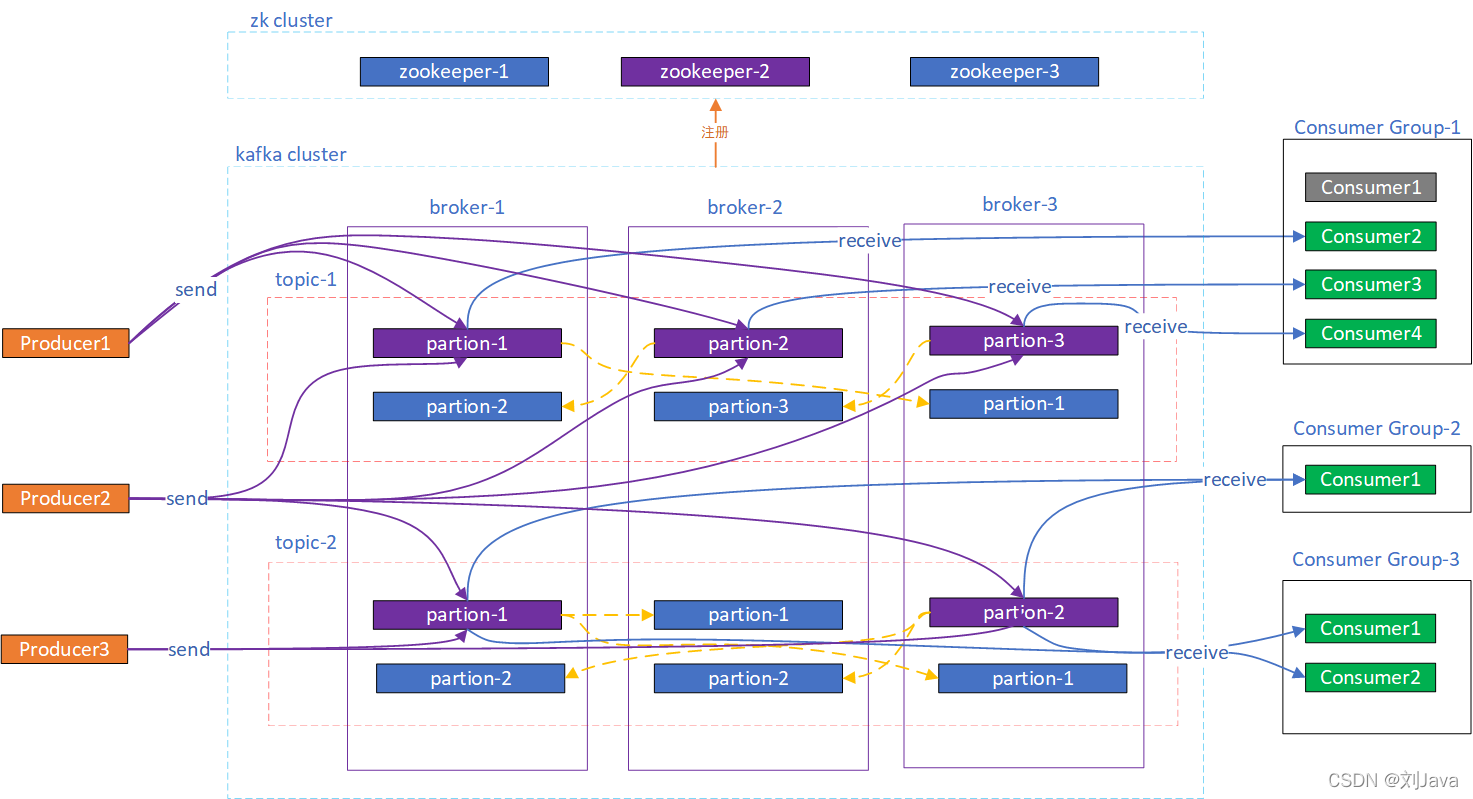
broker:代理服务器。Kafka 集群中的一台服务器统就称为一个Broker,多个 Kafka Broker 组成一个 Kafka Cluster。Broker负责消息存储和转发,还保存着topic和其他broker的元数据信息。
Topic:主题。Topic 用于存储某一类消息的逻辑概念,可用来区分业务系统。不同的 Topic 的消息是分开存储的,每个Topic可以有多个生产者向它发送消息,也可以有多个消费者去订阅其中的消息。
Partition:分区,可以看作是队列,类比RocketMQ中的messageQueue。一个Topic可以有多个分区,至少有一个分区,同一Topic下的不同分区包含的消息是不同的发送到Topic的消息实际上被存储在不同的分区下,消费时也是从分区下面获取消息。这样就提高一个队列(topic)的吞吐量。
一个 Topic 可以横跨多个 Broker ,实际上就是Topic的不同Partition 分散在kafka集群的不同Broker节点上,实现了Topic数据的分片存储。Kafka是一个天然的分布式系统。
每个patition实际对应一个文件夹,文件夹下面是一个个的commit log文件。消息以追加的方式顺序写入commit log文件中,然后以先入先出的顺序读取。而RocketMQ则是一个Broker中的所有消息都存储在同一个CommitLog文件中。
offset:一个partition上的每个消息都有一个offset偏移量,也是代表该消息的唯一序号,从0开始。Kafka 通过offset保证消息在一个分区内是有序的顺序。kafka内部还维护了每个Consumer Group的最新消费消息的offset,方便继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为"__consumer_offsets" ,该topic默认50个分区。
Producer:消息生产者,就是向kafka broker发送消息的客户端;
Consumer:消息消费者,就是向kafka broker消费消息的客户端;
Consumer Group:消费者分组,每个Consumer必须属于一个group,可以指定group,没指定就属于默认的group。实际上kafka是以消费者组为单位消费全部消息的。
Topic下的一个Pratition允许多个Consumer group消费,但是一个Consumer group内最多只能有一个Consumer去消费同一个Pratition,但一个Consumer可以消费多个不同的Pratition。
2 Zookeeper的作用
broker需要直接连接Zookeeper,Producer和Consumer则直接连接Broker。zookeeper用于管理kafka broker集群,partition的leader选举 和 follower 信息同步,实现消费者负载均衡等功能。
老版本中(0.8.2及更早),消费者将直接连接到zookeeper,新的 Kafka 消费者(0.9及以上)则是直接连接到bootstrap-server,即broker集群。新的版本中不再在Zookeeper上保存消费者offset,而是在Kafka broker上使用名为__consumer_offsets的内置的特定topic保存offset。
Broker 管理 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上的/brokers/ids 下创建属于自己的临时节点,即进行注册。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去。由于是临时节点,Broker崩溃或者网络异常之后,对应的节点会被ZK删除。
Topic 管理 : Zookeeper 还维护了Topic 的分区信息及与 Broker 的对应关系。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些节点:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1
分区管理:维护所有partition的领导者/从属者关系(主分区和备份分区),如果主分区挂了,需要通过ZK选举出备份分区作为主分区。
负载均衡:每个consumer客户端被创建时,会向zookeeper注册自己的信息,用于实现消费者的负载均衡。
3 Replica多副本机制
Kafka的每个topic都可以分为多个Partition,并且多个 partition 会均匀分布在集群的各个节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个partition 来说,都是单点的,当其中一个 partition 不可用的时候,那么这部分消息就没办法消费。为了提高 partition 的可靠性,所以Kafka 0.8 以后,提供了 HA 机制,即提供了多副本(Replica)的概,通过副本机制来实现冗余备份。
每个分区可以设置多个副本,即备份。在多个副本中会存在一个leader副本,其他的副本则都是follower副本。所有的读写请求都是由 leader 副本处理,剩余的follower副本只用作数据备份,只是为了保证消息存储的安全性。follower 副本会从leader副 本 同 步 消 息 日 志。
同一个分区的多个副本会被均匀分配到集群中的不同 broker 上,当 leader 副本所在的 broker 出现故障后,会重新从其他follower副本中选举一个新的 leader 副本继续对外提供服务,通过这样的选举机制来提高 kafka 集群的可用性。
3.1 Partition分配算法
将所有 N 个Broker 和待分配的 i 个 Partition 排序。
将第 i 个 Partition 分配到第(i mod n)个 Broker 上(这个就是leader)。
将第 i 个 Partition 的第 j 个副本分配到第 ((i + j) mod n) 个Broker 上。
3.2 副本协同机制
消息的读写操作都只会由 leader 节点来接收和处理。follower 副本只负责同步数据以及当 leader 副本所在的 broker 挂了以后,会从 follower 副本中选取新的leader。
写请求首先由 Leader 副本处理,之后 follower 副本会从leader 上拉取写入的消息,这个过程会有一定的延迟,导致 follower 副本中保存的消息略少于 leader 副本,但是只要没有超出阈值都可以容忍。
但是如果一个 follower 副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候,leader 就会把它踢出去ISR 副本集合(包含了 leader 副本和所有与 leader 副本保持同步的 follower 副本集合)。kafka 通过 ISR集合来维护一个分区副本信息。
3.3 数据的同步过程
Producer 在 发 布 消 息 到 某 个 Partition 时 , 先 通 过ZooKeeper 找到该 Partition 的 Leader,无论该 Partition 有多少个 Replica,Producer 只将该消息发送到该 Partition 的Leader,Leader 会将该消息写入其本地 Log,每个 Follower都从 Leader 的log中pull 数据。
当 follower 副本延迟过高,leader 副本则会把该 follower 副本剔除ISR 集合,消息依然可以快速提交。当 leader 副本所在的 broker 突然宕机,会优先将 ISR集合中follower 副本选举为 leader,新 leader 副本包含了之前的全部消息,这样就避免了消息的丢失。
相关文章:
如有需要交流,或者文章有误,请直接留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!