镜像队列
为什么要使用镜像?
如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此, 一般不希望遇到因单点故障导致的服务不可用。
引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
集群环境可参考
基于CentIOS7搭建RabbitMQ 集群
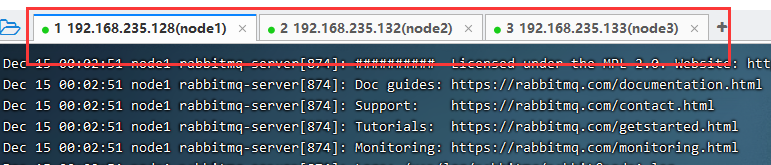
我们现在一某一台机器上创建队列,比如我在结点128的机器上创建一个hello队列,你会发现,只有128的机器有,另外两台机器是没有的。也就意味着一号机宕机了,队列就消失了

我们把node1机器关闭。

此时node1结点已经宕机了。
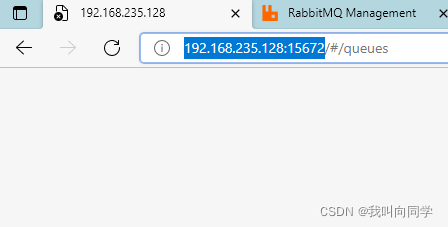
登录结点2看一下状态,红红的node1

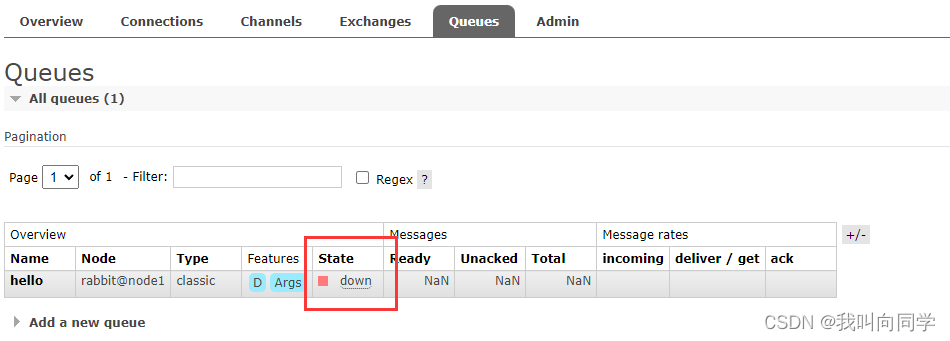
再看一下刚刚创建的hello队列的状态 down
如果RabbitMQ集群是由多个broker节点构成的,那么从服务的整体可用性上来讲,该集群对于单点失效是有弹性的,但是同时也需要注意:尽管exchange和binding能够在单点失效问题上幸免于难,但是queue和其上持有的message却不行,这是因为queue及其内容仅仅存储于单个节点之上,所以一个节点的失效表现为其对应的queue不可用。
引入RabbitMQ的镜像队列机制,将queue镜像到cluster中其他的节点之上。在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性。在通常的用法中,针对每一个镜像队列都包含一个master和多个slave,分别对应于不同的节点。slave会准确地按照master执行命令的顺序进行命令执行,故slave与master上维护的状态应该是相同的。除了publish外所有动作都只会向master发送,然后由master将命令执行的结果广播给slave们,故看似从镜像队列中的消费操作实际上是在master上执行的。
一旦完成了选中的slave被提升为master的动作,发送到镜像队列的message将不会再丢失:publish到镜像队列的所有消息总是被直接publish到master和所有的slave之上。这样一旦master失效了,message仍然可以继续发送到其他slave上
镜像队列实现
启动三台集群节点。
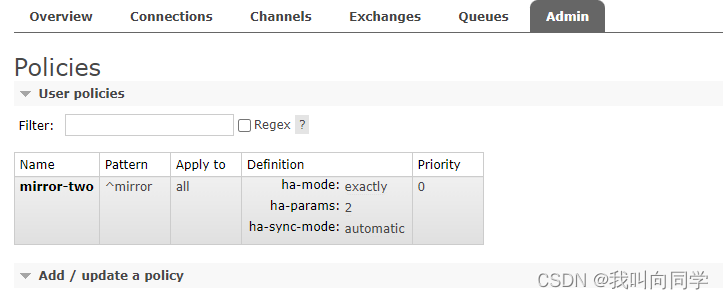
随便找一个节点添加 policy。
可视化界面添加
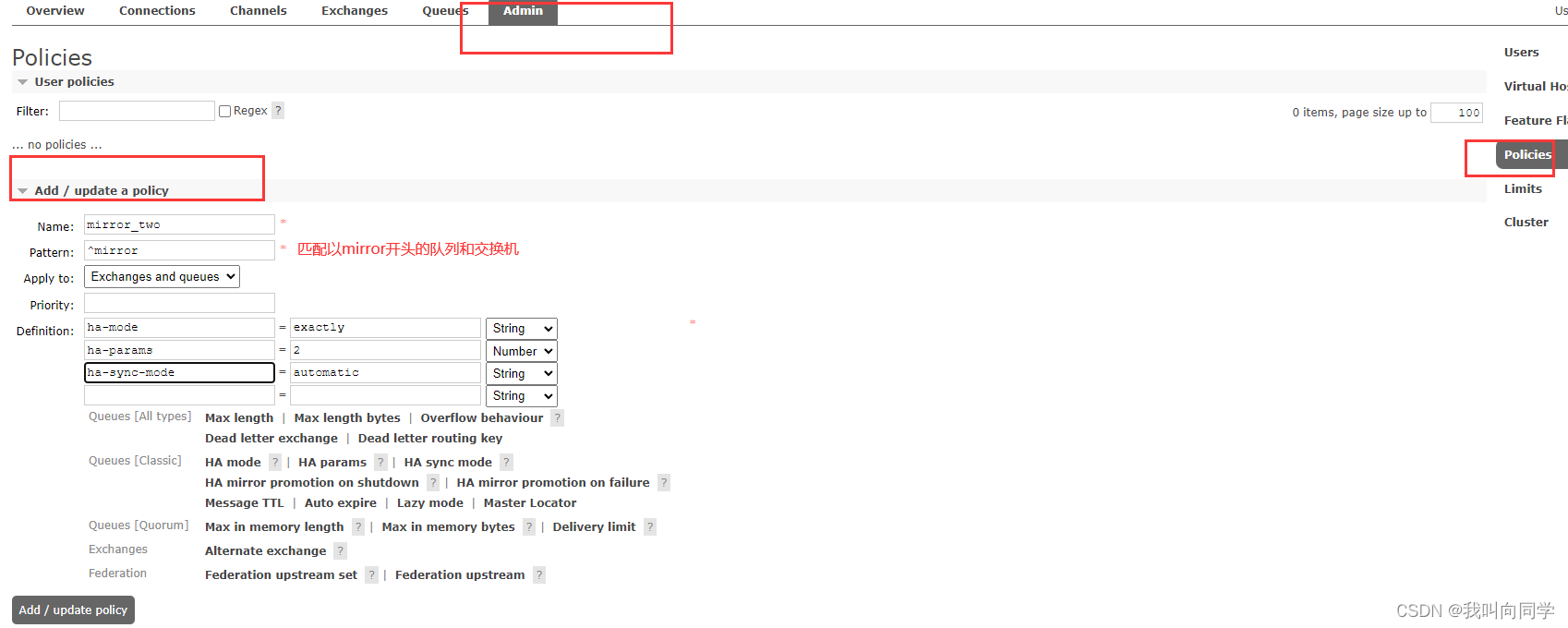
或者配置文件添加
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级
在创建一个队列mirror_hello

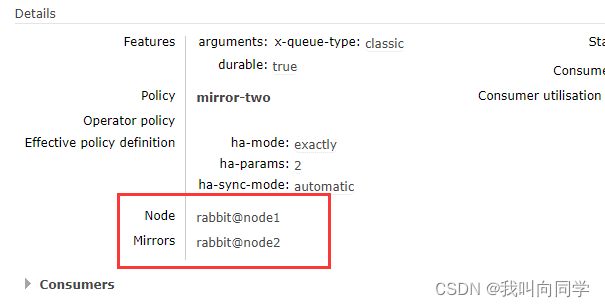
现在某个结点宕机了消息并不会丢失。