RDD屏障概念引入
Spark 3.0 引入了一种名为RDDBarrier[T]的新型 RDD ,它表示 RDD 需要使用屏障执行模式来处理。此 RDD 公开了普通 RDD 中不可用的新功能。
RDDBarrier的源码定义如下:
/**
* :: Experimental ::
* Wraps an RDD in a barrier stage, which forces Spark to launch tasks of this stage together
@Experimental
@Since("2.4.0")
class RDDBarrier[T: ClassTag] private[spark] (rdd: RDD[T]) {
...
}
注释中便是第一手的定义,首先RDDBarrier是实验性的,把一个Rdd封装在了一个屏障阶段,这样回强制Spark在运行task的时候在这个阶段一起执行。
关于Barrier概念其实和并发环境中的屏障是一样的,直白点说就是多个线程会在同一个时间点开始执行。
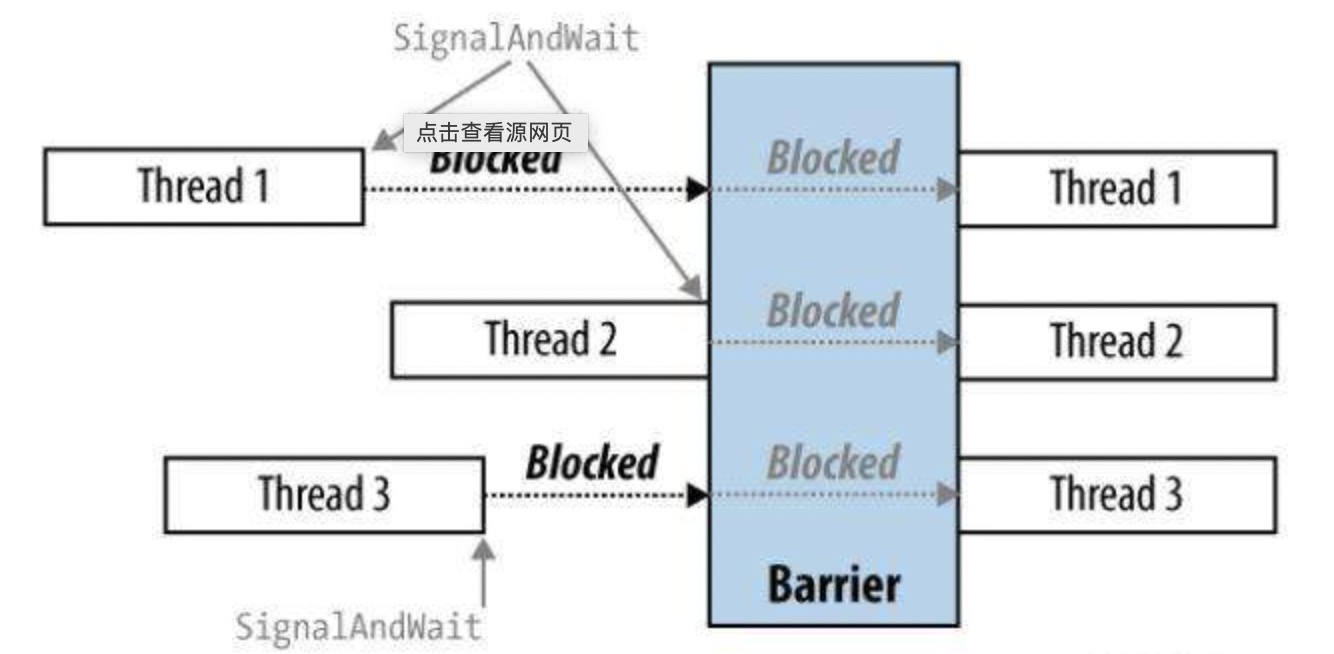
实操
来点例子,找找感觉。我们首先还是创建RDDBarrier Rdd
val df = sparkSession.range(0,100).repartition(4)
val barrierRdd = df.rdd.barrier()
val count = barrierRdd.mapPartitions(v => v).count()
println("count is " + count)
需要看出效果,我们把线程数量调整成1
val sparkSession = SparkSession.builder.
master("local[1]")
.appName("barrierRdd")
.getOrCreate()
我们运行,看效果,我找出关键的日志:
21/12/15 22:42:20 INFO SharedState: Warehouse path is 'file:/Users/zhuxuemin/IdeaProjects/spark-3.0-examples/spark-warehouse'.
21/12/15 22:42:22 INFO CodeGenerator: Code generated in 265.914341 ms
21/12/15 22:42:22 INFO SparkContext: Starting job: count at BarrierRddExample.scala:15
21/12/15 22:42:22 WARN DAGScheduler: Barrier stage in job 0 requires 4 slots, but only 1 are available. Will retry up to 40 more times
21/12/15 22:42:37 WARN DAGScheduler: Barrier stage in job 0 requires 4 slots, but only 1 are available. Will retry up to 39 more times
观察最后的提示,以上就是Barrier stage需要4个槽位,但是其实只有一个,因为我们repartition(4)是开了4个并发,线程数量不够4个,就会等着不执行了。
我们调整到线程数量为4,再看看效果:
21/12/15 22:48:36 INFO DAGScheduler: ResultStage 1 (count at BarrierRddExample.scala:15) finished in 0.325 s
21/12/15 22:48:36 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
21/12/15 22:48:36 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
21/12/15 22:48:36 INFO DAGScheduler: Job 0 finished: count at BarrierRddExample.scala:15, took 1.269630 s
count is 100
结果就是执行完成了。barrierRdd会等待资源足够的时候同时执行。
引入背景
可能最大的疑惑就是不知道有啥子用,这项特性是jira中提到的,原始链接:https://issues.apache.org/jira/browse/SPARK-24374,标题叫做 SPIP: Support Barrier Execution Mode in Apache Spark,页面里面是同时上传了pdf文档的

我简单翻译一下,前面是介绍背景吧啦吧啦,略去,捡中间部分
…考虑一个简单的场景:作为一名数据科学家,我想构建一个管道,从生产数据仓库中获取训练事件并拟合具有数据并行性的 DL 模型。这里,“生产数据仓库”因公司而异,例如 Apache Hive,来自 AWS 的 Redshift、来自 Azure 的 Data Lake、来自 Databricks 的 Delta 等。经过社区多年的发展,Spark 是从这些生产数据仓库读取数据的事实上的选择,而 TensorFlow 和 Horovod 是分布式 DL 训练的流行选择。作为末端用户,如何进行衔接(数仓->模型训练)?我们可以简化吗?这里的建议是在 Apache Spark 中添加一个新的调度模型,以便用户可以将分布式 DL 训练正确嵌入作为 Spark 阶段,以简化分布式训练工作流程。例如,Horovod 使用 MPI 实现 all-reduce 以加速分布式 TensorFlowtraining。计算模型与 Spark 使用的 MapReduce 不同。在 Spark 中,阶段中的任务不依赖于同一阶段中的任何其他任务,因此可以独立调度。在 MPI 中,所有Worker同时启动并传递消息。为了在 Spark 中嵌入这个工作负载,我们需要引入一个新的调度模型,暂命名为“barrierscheduling”,它在启动任务的同时,为用户提供足够的信息和工具来嵌入分布式 DL 训练。 Spark 还可以提供额外的容错层,以防某些任务在中间失败,Spark 会中止所有任务并重新启动阶段。
为什么需要新的执行模式
传统的Spark执行模式我们仍旧算作为Map/Reduce模式,那么这种执行模式多年来一直很好地适用于不同的工作负载。为什么我们现在需要不同的执行模式?
原因之一是在spark上支持深度学习框架。深度学习框架不适合 Map/Reduce 模型。它们与称为 MPI(消息传递接口)的其他类型的执行模型配合得很好。例如,Uber 的大规模深度学习开源框架 Horovod 使用 MPI 为各种 DL 框架实现分布式深度学习。
为了原生支持深度学习,spark 需要支持不同于 Map/Reduce 的执行模型。新的执行模型以 MPI 为模型。
屏障执行模式
- 工作是阶段的集合。在这些阶段之间通常会进行洗牌。这与 Map/Reduce 模型相同
- 每个阶段都是任务的集合。这些任务都是一起开始的,而且是相互依赖的。与 Map/Reduce 相比,这是主要的区别之一。在 MPI 模型中,任务可以相互通信并相互依赖。所以他们需要一起开始。
- 由于任务相互依赖,当其中一个任务失败时,所有任务都会重试。同样,这与 Map/Reduce 模型不同。
- 任务数量始终由开发人员决定。这是因为即使数据可能很小,计算也可能复杂得多,并且可能需要比典型处理更多的资源。还应该有足够的资源来一起运行所有任务。
后记
我们其实可以说,Spark的MPI时代来了~