1 MapReduce流程

上述就是一个MapReduce处理数据的流程:经由:数据输入→map阶段→Shuffle阶段→数据输出。以下将根据这整个流程解析MapReduce的框架原理
2 InputFormat数据输入
2.1 数据切片和数据块概念
- 数据块:
Block是HDFS物理上把数据分成一块一块 - 数据切片:数据切片只是在
逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。也就是通过文件是完整的文件而不是像数据块去直接在物理层面上划分为多个块,而是使用指针在源文件中置顶处理的范围
切片和数据块都是按照
一定的单位处理的,例如切分数据块在hadoop3.x中是按照128M进行切分,200M的数据,就会被分为128M和72M两个块
2.2 数据切片和MapTask并行度决定机制
一个切片是由一个
MapTask负责处理,有多少个切片就启用多少个MapTask,并且MapTask是并行处理的,切片的个数影响MapTask并行度。MapTask并行度不是越高越好,他也由切片的数据量决定
2.3 数据块与数据切片的关系
上述概念中,数据切片是对整个文件的逻辑上进行划分,并且一个切片由一个MapTask负责。实际在服务器集群中,文件的存储默认是使用的副本策略,也就是说MapReduce程序在集群中输入的数据其实就是服务器上的数据块
那么数据块在一定程度上就影响数据的切片,因为输入的数据与服务器的副本机制的问题,那么输入的数据最好是一个块的大小,并且默认情况下,切片大小的值=块大小的值,块大小计算是通过一个公式的,切片也同样,并且使用到了块大小的量,默认情况下计算出来切片大小跟块大小是相同的,而不是直接取块的大小作为切片的大小
为什么使用块大小作为一个切片的大小呢?例如一个200M的数据,分成128M和72M的块,那么两个块就根据副本的选择策略,副本相关的块分散到不同的DataNode中,那么对于一个副本的128M和72M在不同机器上例如分别是d1和d2,如果切片大小是100M,那么就会从d1的数据上得到切片是0~100M,那么剩下部分就是100M~128M,不够100M,那么就会跨服务器到d2进行读取,处理过程相对复杂。如果切片刚好是块的大小就能避免这种情况
MapReduce对切片的处理是对基于整个文件的,而不是数据的整体,例如一个200M的文件和100M的文件同时输入,那么切片仅仅是相对于200M和100M文件本身,而不是整体的数据流,也就是默认情况下最终200M的文件只会被切分为128M和72M两个切片,而100M也是一个单独的切片- 切片大小是可以设置的,默认情况下
切片大小的值=块大小的值
上述策略在大文件处理过程中是很有效的,但是也不是一直适用的,例如大量的小文件,例如一个10M,那么如果按照默认情况下切片,那就有多少个文件就有多少个切片,同时启用同等数量的MapTask,虽然MapTask是并行处理,但是大量的并行调度处理小文件,其中的调度过程就会耗费资源,而这种资源的耗费仅仅是处理一些小文件,这是得不偿失的,所以通过设置切片大小并配合一定策略处理这种的大量小文件的场景
2.4 源码上的切片大小计算策略
从FileInputFormat可以看到getSplits方法

经过一系列的计算与配置会在getSplits方法中调用computeSplitSize方法,也就是切片的计算方法,其中传入了三个参数blockSize, minSize, maxSize

computeSplitSize方法源码如下,事实就是如下的一个比较方法

maxSize的获取如下
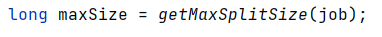
可以看到通过job对象获取他的配置并通过getLong方法获取参数值
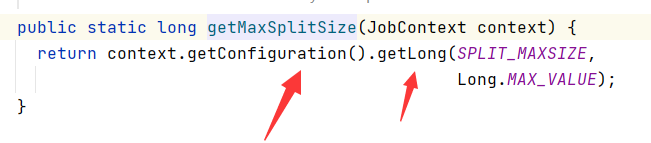
SPLIT_MAXSIZE和Long.MAX_VALUE如下
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
public static final long MAX_VALUE = 0x7fffffffffffffffL; // 2^63-1
通过getLong方法,第一个参数就是获取mapred-site.xml或者mapred-default.xml配置文件的mapreduce.input.fileinputformat.split.maxsize配置属性,而第二个出参数是一个默认值,也就是当配置文件的参数没有配置时会使用第二个参数,这里也就是Long类型的最大值
获取blockSize公式如下,这里blockSize可以是集群配置文件配置的blockSize,如果在本地执行,如果没有定义,那么默认是32MB
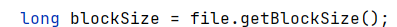
这里做的意义是通过maxSize和blockSize进行比较,如果maxSize没有定义或者比blockSize大,那么就取blockSize
minSize获取过程类似
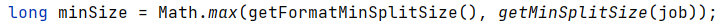
getFormatMinSplitSize和getMinSplitSize方法以及相关字段如下
protected long getFormatMinSplitSize() {
return 1;
}
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); /
}
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
结合上述computeSplitSize方法,当minSize相关的属性没有配置的时候,会返回1。上述例子中maxSize相关配置没有配置,那么就返回blockSize,当minSize也没有配置,那么1和blockSize取最大值,最终就拿到了blockSize,也就是最终切片大小等于blokcSize
2.5 源码上的小切片处理策略
小切片处理,就例如配有额外配置的情况下,对于128.1MB的文件,如果blokcSize=128MB,那么就切分成128MB和0.1MB的切片,切片过小造成资源浪费。hadoop的处理是通过一个比例进行限制的

其中SPLIT_SLOP定义如下
private static final double SPLIT_SLOP = 1.1; // 10% slop
splitSize是上述computeSplitSize方法的返回值,也就是切片的大小,bytesRemaining)/splitSize,表示剩余文件与切片大小的值的比例,如果大于1.1那么就允许切片,小于等于就不允许,也就是允许10%的溢出
3 InputFormat解析
3.1 FileInputFormat和TextInputFormat
InputFormat类用以处理输入以及切片,如下两个抽象方法。这里是为了在源码角度概要解析之前数据输入处理的流程
如果使用
IDEA查看源码,可以通过快捷键ctrl+h查看他的实现类

// 获取切片
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
// 创建RecordReader对象,负责读取
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
上述方法是一个抽象的方法,要进一步了解就需要通过他的实现类,这里首先是介绍这个FileInputFormat类,该方法主要是实现了getSplits和isSplitable方法
getSplits:默认的切片规则的实现isSplitable:判断一个文件是否可切片,统一的实现,返回的是true
切片大小相关逻辑如上述,可查看上述标题2.3,在FileInputFormat类中是对isSplitable做了一个统一的处理,也就是返回true

切片相关的大小获取逻辑如
2.3标题,其他这里先不介绍
在我们默认的输入流程中,默认使用的是FileInputFormat类的实现类TextInputFormat类

其中重要的方法如下:
createRecordReader:创建LineRecordReader对象,所以初始对文件的处理,都是一行一行输入到map方法处理的isSplitable:重写了该方法,对各种压缩文件进行了判断是否可切分。切片的规则用的是FileInputFormat中的getSplits方法实现
其中重写的isSplitable方法中对于压缩文件的编解码处理,普通文件我们都是可以直接切分的
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
3.2 CombineTextInputFomat处理大量小文件场景
框架默认的TextInptFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下
3.2.1 CombineTextInputFomat切片最大值设置
CombineTextInputFomat是通过设置虚拟切片来处理小文件问题,该处理机制重要配置之一是虚拟切片的设置,如下为设置最大虚拟切片大小的方法
// 一个参数设置的job对象,第二个参数是设置最大虚拟切片的值,单位是字节,下述例子是1024*1024*4
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304) // 这里就是4MB
3.2.2 CombineTextInputFomat切片机制
CombineTextInputFomat是通过设置虚拟切片机制来处理小文件,也就是在生成切片之前会有一个虚拟的过程,然后再到切片过程,处理过程如下
1、首先准备假设输入数据如下(缺省字节B后缀),并且最大虚拟切片是4MB

2、数据切片前会先经过虚拟过程

处理过程大致如下:
- 文件大小 ≤
4MB:划分为1块 4MB< 文件大小 <8MB:文件对半分,例如上述5.1MB的文件就是符合该范围,那么就分成2.55MB两个块- 文件大小 ≥
8MB:那么首先按顺序切分出4MB,例如9MB的内容,首先切分4MB,然后剩下的5MB内容符合2,那么对半分两块是2.5MB,最终得到三块:4MB、2.5MB、2.5MB
总的而言,就是最后划分的块不能比设置的最大虚拟切片大,这里是
4MB
最后切分的块大小如上图所示,也就是最终切分剩下的文件大小
3、最后是切片阶段,切片阶段主要是一下
- . 判断上述划分的块是否等于设置的最大虚拟存储的值,如果
等于,那么就会作为一个切片 - 如果块大小不等于设置的最大虚拟切片(上述在设置的是
4MB),那么就会与其他块进行合并,直到切片大小比设置的最大虚拟切片的值要大,那么上述存储的文件,最终会分为以下三个切片,这个时候就相对于4个小文件生成一个单独的切片要少。这里仅仅是相对于设置的4MB的最大虚拟切片,根据实际情况设置相应的值

- 最大的虚拟切片的大小,最好是趋于一个
块的大小- 上述构成产生的分块是按
文件的输入顺序的,上述例子在虚拟过程中产生的块,都是按照这个文件的输入顺序,例如上述是a.txt~b.txt,按照文件ASCII值排序,那么最先输入的就是a.txt,最后输入的是d.txt,块的产生也是按这个顺讯,最后按照上述规则进行组合
3.2.3 CombineTextInputFomat实践案例(基于官方wordcount案例需求)
基本的客户端编写wordcount程序以及项目配置可以参考这里:MapReduce学习2-1:以官方wordcount实例为例的MapReduce程序学习的本地实操案例中(本次主要是本地测试,用于学习比较方便)
1、输入案例文件准备

直接案例测试(无小文件处理),如果需要打印以下日志信息,可以参考:Hadoop学习9:Maven项目跟中进行HDFS客户端测试(hadoop3.1.2)中POM.xml的配置(我是JDK 1.8)

这里我是本地进行测试,没有设置块大小,本地测试默认是32MB(集群默认128MB)。如上述箭头所示,可以看到是切片是4个
按照上述理论,如果使用CombineTextInputFormat处理,那么就是3个切片
2、在WordcountDriver.class中添加CombineTextInputFormat相关的配置
package com.ctfwc.maven;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("E:\\bigdata\\study\\test_files\\combineinput"));
FileOutputFormat.setOutputPath(job, new Path("E:\\bigdata\\study\\test_files\\combineoutput"));
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
job.waitForCompletion(true);
}
}
上述的设置了最大的虚拟切片是4MB
3、结果
 上述可以看到结果是
上述可以看到结果是3,也就是切片是3,符合上述
4 Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
4.1 Shuffle整体概述
Shffle阶段Map方法之后,Reduce方法之前,主要是包含两次排序以及一次数据的拷贝
1、在源码中MapTask.class中的启动方法run(),可以看到

// 是否为MapTask
if (this.isMapTask()) {
// 判断是否有reduce阶段
if (this.conf.getNumReduceTasks() == 0) {
// 没有reduce阶段,就只有map阶段,阶段占总进程为100%
this.mapPhase = this.getProgress().addPhase("map", 1.0F);
} else {
// 有reduce阶段,map阶段占用总进程的66.7%,sort阶段占用33.3%
this.mapPhase = this.getProgress().addPhase("map", 0.667F);
this.sortPhase = this.getProgress().addPhase("sort", 0.333F);
}
}
2、ReduceTask.class可以看到以下

if (this.isMapOrReduce()) {
// 数据拷贝阶段
this.copyPhase = this.getProgress().addPhase("copy");
// 排序阶段
this.sortPhase = this.getProgress().addPhase("sort");
// reduce阶段
this.reducePhase = this.getProgress().addPhase("reduce");
}
3、总的Shuffle阶段就是:sort(map阶段) → copy(reduce阶段) → sort(reduce阶段)