1. HBase 相关过程图解
1.1 写入数据
1.1.1 写入阶段
三个阶段:
- 第一阶段:当 Client 提交 put(增删改)请求后,Hbase 客户端会根据写入的表以及 rowkey 在 Meta Cache 进行查找,如果找到该 rowkey 所在的 RegionServer 以及 Region,就直接进入到第三阶段;如果客户端中没有找到 rowkey 的相关信息,就需要访问 Zookeeper 上的
/hbase/meta-region-server节点,查找 Habse 元数据所在的 RegionServer。 - 第二阶段:向 hbase:meta 所在的 RegionServer 发送查询请求,获取 hbase:meta 表,根据请求的 namespace:table/rowkey 查找到 rowkey 所在的 RegionServer 以及所在的 Region。将 Region 信息以及 meta 表的位置信息缓存在 Client 的 MetaCache,以便下次访问。
- 第三阶段:Client 根据 rowkey 相关元数据信息将 put 请求发送给目标 RegionServer,RegionServer 接收到请求后,解析出具体的 Region 信息,并将数据写入到目标 Region 的 MemStore,最终向 Client 返回 ack。
![[外链图片转存中...(img-E12jvnIf-1641190014723)]](https://img-blog.csdnimg.cn/293673b786bb4b90befde8d6091bc007.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASk9FTC1UOTk=,size_20,color_FFFFFF,t_70,g_se,x_16)
具体流程:
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个Region Server。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey, 查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以 及meta 表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server 进行通讯;
- 将数据顺序写入(追加)到WAL;
- 将数据写入对应的 MemStore,数据会在MemStore 进行排序;
- 向客户端发送 ack;
- 等达到MemStore 的刷写时机后,将数据刷写到HFile
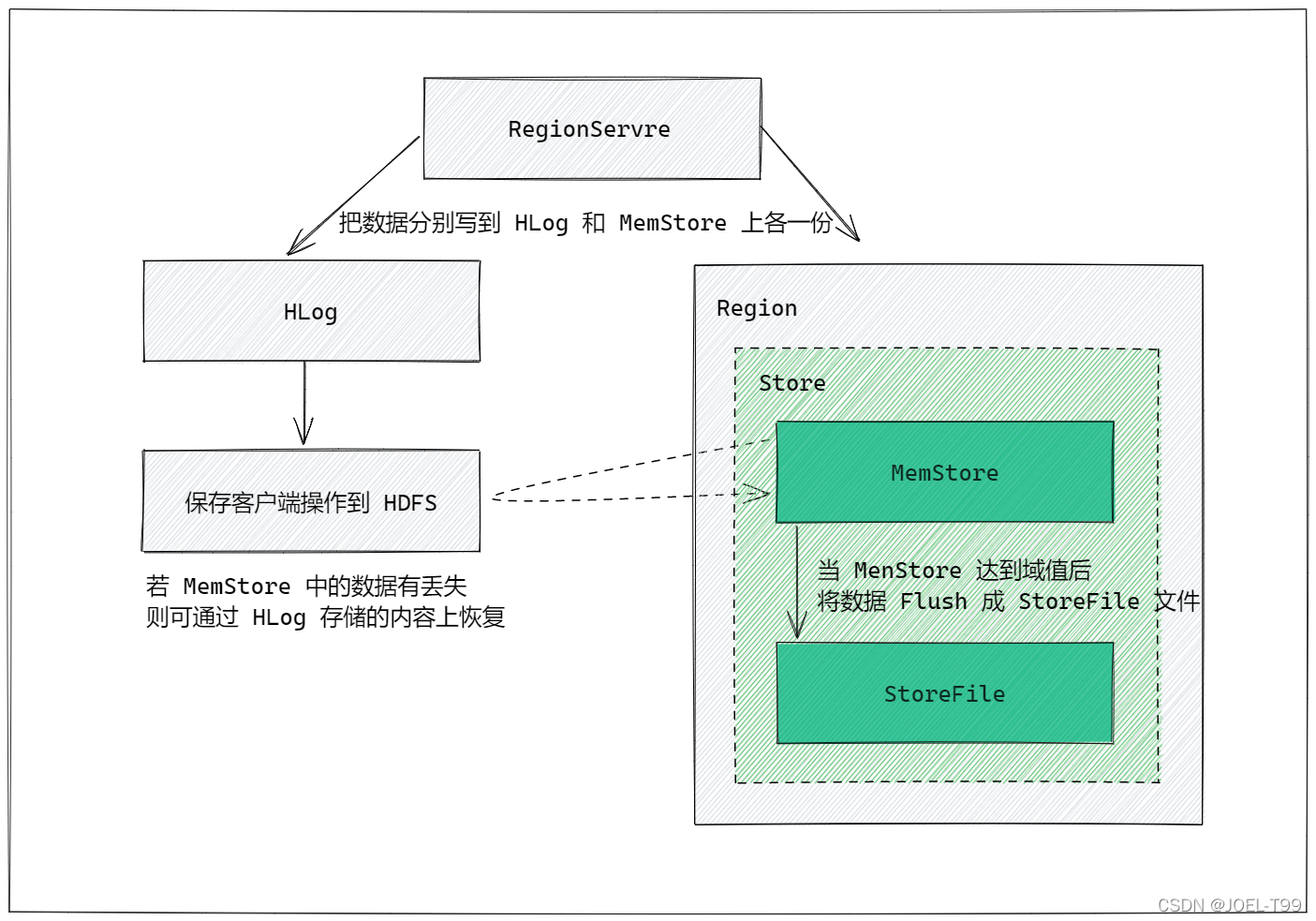
1.1.2 写入过程
1.1.3 写入(源码)过程
![[外链图片转存中...(img-sscWJmy2-1641190014738)]](https://img-blog.csdnimg.cn/698a2eb5cdaf471180719a293c207672.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASk9FTC1UOTk=,size_20,color_FFFFFF,t_70,g_se,x_16)
WAL 机制:
Hbase的 Write Ahead Log(WAL) 提供了一种高并发、持久化的日志保存和回放机制。数据的写入操作(PUT/DELETE))执行前,都会先写HLog。
1.2 MemStore Flush 机制
1.2.1 Flush 触发条件
Memstore 大小限制
当 Region 中的某个 MemStore 大小到达了域值,会触发 Flush 机制,所有的 MemStore 都会 Flush。
域值(默认值 128 MB)参数如下:
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>

Region 总和限制
当 Region 中所有的 MenStore 总和到达域值,会触发 Flush 机制,所有的 MemStore 都会 Flush。
总和限制的倍数:
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>2</value>
</property>

域值(默认值 256 MB)计算公式:
h
b
a
s
e
.
h
r
e
g
i
o
n
.
m
e
m
s
t
o
r
e
.
f
l
u
s
h
.
s
i
z
e
(
128
)
?
h
b
a
s
e
.
h
r
e
g
i
o
n
.
m
e
m
s
t
o
r
e
.
b
l
o
c
k
.
m
u
l
t
i
p
l
i
e
r
(
2
)
hbase.hregion.memstore.flush.size(128) * hbase.hregion.memstore.block.multiplier(2)
hbase.hregion.memstore.flush.size(128)?hbase.hregion.memstore.block.multiplier(2)
RegionServer 总和限制
当 RegionServer 中 MemStore 总和到达域值,会触发 Flush 机制,Region 会按照其所有 MenStore 由大到小依次刷写,直到 RegionServer 中 MemStore 总和减小到域值以下。
限制条件:
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>

域值计算公式:
j
a
v
a
H
e
a
p
s
i
z
e
?
h
b
a
s
e
.
r
e
g
i
o
n
s
e
r
v
e
r
.
g
l
o
b
a
l
.
m
e
m
s
t
o
r
e
.
s
i
z
e
(
0.4
)
?
h
b
a
s
e
.
r
e
g
i
o
n
s
e
r
v
e
r
.
g
l
o
b
a
l
.
m
e
m
s
t
o
r
e
.
s
i
z
e
.
l
o
w
e
r
.
l
i
m
i
t
(
0.95
)
javaHeapsize * hbase.regionserver.global.memstore.size(0.4) * hbase.regionserver.global.memstore.size.lower.limit(0.95)
javaHeapsize?hbase.regionserver.global.memstore.size(0.4)?hbase.regionserver.global.memstore.size.lower.limit(0.95)
🌈 javaHeapsize:JVM 堆内存大小!
WAL 数量限制
当一个特定区域服务器的WAL的日志条目的数量达到 hbase.regionserver.max.logs 中指定的值时。日志,来自不同区域的 MemStores 将被刷新到磁盘,以减少 WAL 中的日志数量。
flush顺序是基于时间的。
具有最老 MemStores 的区域将首先刷新,直到 WAL 计数降到 hbase.regionserver.max.logs 以下。
配置中以移除该项参数,无需手动配置,最大值为32!
HLog 数量限制(不确定)
当一个 RegionServer 中 HLog 数量到达域值时,会触发 Flush 机制,将选取最早的一个 HLog 对应的一个或多个 Region 进行刷写。
域值参数:hbase.regionserver.maxlogs,(配置中没找到该项)

阻塞机制
触发条件一:
当 MemStore 大小达到了一定域值后,会触发阻塞机制,阻止继续向 MenStore 写数据。
域值(默认值 512 MB)计算公式:
h
b
a
s
e
.
h
r
e
g
i
o
n
.
m
e
m
s
t
o
r
e
.
f
l
u
s
h
.
s
i
z
e
(
128
)
?
h
b
a
s
e
.
h
r
e
g
i
o
n
.
m
e
m
s
t
o
r
e
.
.
b
l
o
c
k
.
m
u
l
t
i
p
l
i
e
r
(
4
)
hbase.hregion.memstore.flush.size(128) * hbase.hregion.memstore..block.multiplier(4)
hbase.hregion.memstore.flush.size(128)?hbase.hregion.memstore..block.multiplier(4)
触发条件二:
当 RegionServer 中 MenStore 的总合到达一定域值后,会触发阻塞机制,阻止继续向所有的 MenStore 写数据。
域值计算公式:
j
a
v
a
H
e
a
p
s
i
z
e
?
h
b
a
s
e
.
r
e
g
i
o
n
s
e
r
v
e
r
.
g
l
o
b
a
l
.
m
e
m
s
t
o
r
e
.
s
i
z
e
(
0.4
)
javaHeapsize * hbase.regionserver.global.memstore.size(0.4)
javaHeapsize?hbase.regionserver.global.memstore.size(0.4)
1.2.2 Flush 阶段
- prepare 阶段: 遍历当前所有 MemStore,将 MemStore 中当前数据集(CellSkipListSet)做一个快照(snapshot),然后再创建一个 CellSkipListSet ,用于后期数据的写入。整个 flush 阶段读操作会分别遍历 CellSkipListSet 和 snapshot,如果查找不到会到HFile中查找。该阶段需要获取 updateLock 阻塞写请求,结束后释放该锁。
- **flush 阶段: ** 遍历所有的 MemStore,将 prepare 阶段生成的 snapshot 持久化为一个临时文件,临时文件会统一放到
.tmp目录下,这个过程涉及磁盘 IO 操作,相对耗时。 - commit 阶段: 遍历所有的 MemStore,将 flush 阶段生成的临时文件移到指定的 ColumnFamily 目录下,针对 HFile 生成对应的 storefile 和 Reader,把 storefile 添加到 HStore 的 storefiles 列表中,最后再清空 prepare 阶段生成的 snapshot。
源码参见:
- MemStoreFlusher
- HRegion
- HRegionServer
- …
1.3 读取数据
![[外链图片转存中...(img-QsGQGDEp-1641190014747)]](https://img-blog.csdnimg.cn/857896dcd76446ad9da9657f43e18a55.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASk9FTC1UOTk=,size_20,color_FFFFFF,t_70,g_se,x_16)
具体流程:
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个Region Server。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey, 查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以 及meta 表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server 进行通讯;
- 分别在Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不 同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到 Block Cache。
- 将合并后的最终结果返回给客户端。
1.4 StoreFile Compaction 过程
当多个 StoreFile 达到一定大小后,会触发 Compact 合并操作。
Compaction 分为 MinorCompaction、MagorCompaction:
- MinorCompaction:将临近的若干个较小的 HFile 合并为一个较大的 HFile;不清除过期和被删除的数据
- MaiorCompaction:将一个 Store 下的所有 HFile 合并成一个大 HFile;会清除掉过期和被删除的数据

1.5 Region Split 过程
Region 中存储的是?量的 rowkey 数据 ,随着数据的写入,当 Region 中的数据条数过多的时,将会影响查询效率。当 Region 过?的时候,HBase 会拆分 Region。刚拆分时,两个 Region 都位于当前的 RegionServer,考虑到负载均衡,HMaster 有可能将某个 Region 转移给其他的 RegionServer。
Region Split 策略:
-
0.94 版本之前:当一个 Region 下的某个 Store 中所有的 StoreFile 总和?于某个域值(
hbase.hregion.max.filesize=10G)之后就会触发 split,?个 Region 等分为2个 Region; -
0.94 版本之后:当一个 Region 下的某个 Store 中所有的 StoreFile 总和?于某个域值(
Min(R^2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize")),就会触发 split。R 为当前 RegionServer 中属于该 table 的 region 个数
?