前言
序列化想必大家都很熟悉了,对象在进行网络传输过程中,需要序列化之后才能传输到客户端,或者客户端的数据序列化之后送达到服务端
序列化的标准解释如下:
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输
对应的反序列化为序列化的逆向过程
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象
为什么要序列化
一般来说,程序动态创建出来的“活的” 对象只生存在内存里,一旦服务停机或断电就没了。而且“活”对象只能存活于本地进程,不能发送到网络上其他的服务器或者进程中使用。 然而通过序列化之后,则可以存储“活的”对象,从而进行网络传输,提供给其他进程或机器使用。
为什么不使用Java序列化
在Java中,创建一个对象如果希望这个对象是序列化的对象,只需要实现Serializable接口即可,但Java的序列化在Hadoop看来,是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),从而不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制,只需要对象实现Writable接口,重写里面的两个方法。
Hadoop序列化特点
- 紧凑 :高效使用存储空间
- 快速:读写数据的额外开销小
- 互操作:支持多语言的交互
Hadoop序列化业务场景
在真实的业务场景中,类似于wordcount那样的单个字符串的场景很少,而且无法应对各种复杂的大数据场景和海量数据的处理业务,因此在传输过程中,为了更加灵活的进行数据在Map、Reduce中的传输,将解析到的数据以序列化对象的方式传输,是非常便捷的
在Hadoop中,具体实现bean对象序列化步骤如下7步:
- 实现Writable接口
- 反序列化时,需要反射调用空参构造函数,即类对象中必须有空参构造
- 重写序列化write的方法
- 重写反序列化的readFields方法
- 注意反序列化的顺序和序列化的顺序完全一致
- 若想把结果显示在文件中,需重写toString(),可用"\t"分开,方便后续用
- 如果需将自定义的bean放在key中传输,还需要实现Comparable接口,因为MapReduce框中Shuffle过程要求对key必须能排序
案例业务描述
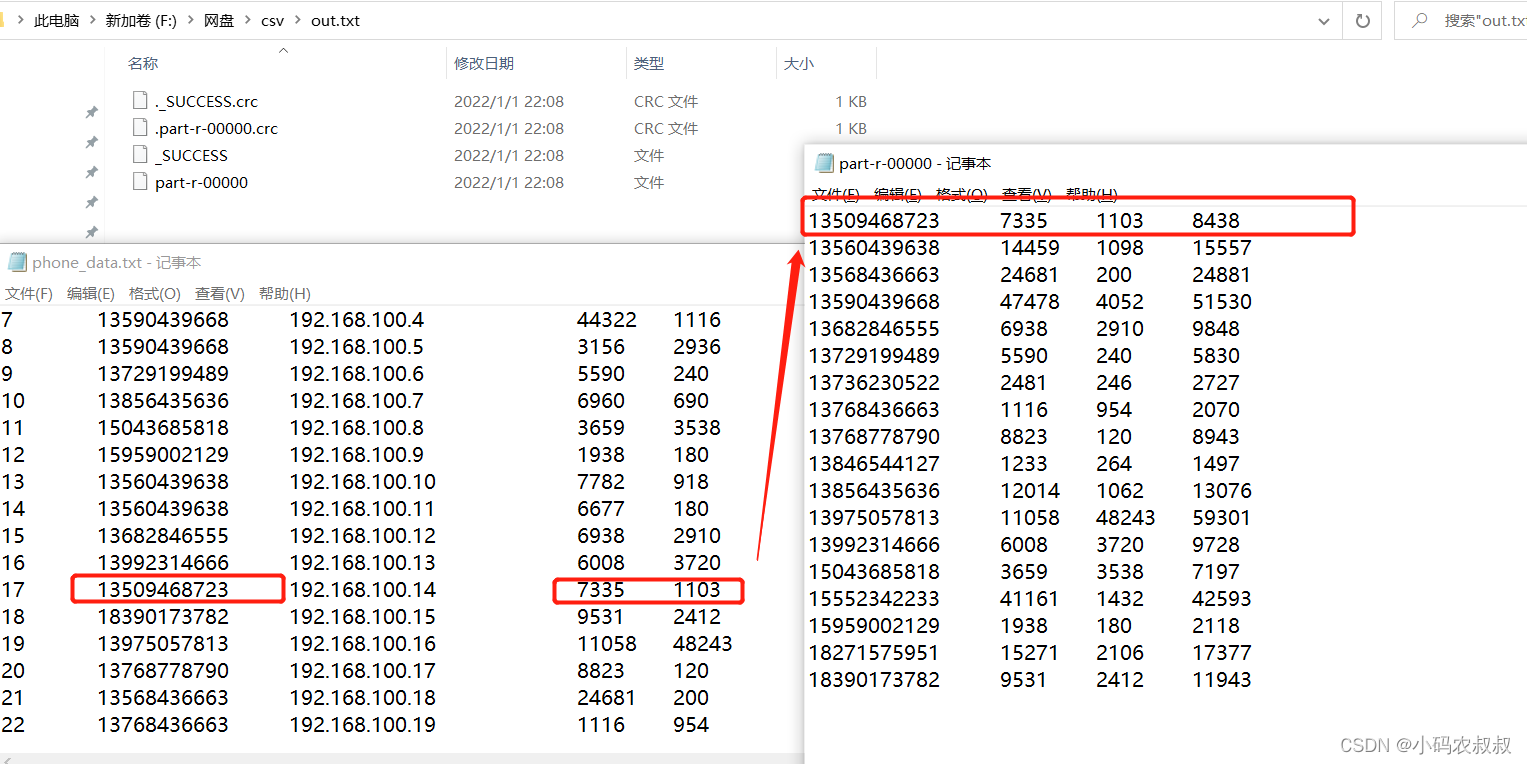
业务需求描述,如下数据为从某个地方导出来的一批统计手机号峰值流量和低谷流量的文本文件,现在的业务需求是,通过程序,最终输出各个手机号对应的峰值流量、低谷流量以及总流量的统计分析文件
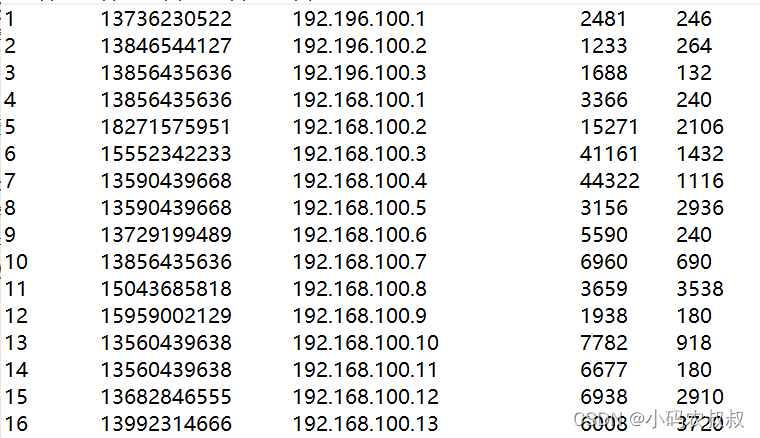
那么最终的效果可按如下格式输出

了解了上面的业务后,下面开始按照前面描述的几个步骤进行编码实现
编码实现
1、定义一个封装手机流量各个属性的对象
从wordcount的案例中我们了解了使用mapreduce编码的基本编码套路,即map逻辑中读取原始数据文件,然后传递到reduce中
同样,在这里的map逻辑中,需要读取上面的原始的流量文本文件,但是既然在reduce中要能实现最终的统计输出,那么从map中出来的数据格式,必然是已经处理好的bean对象,key为手机号,而value值则为封装了当前手机号对应的峰值流量、低谷流量以及计算的总流量信息
了解了这一点,就大概知道这个bean对象该如何定义了
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PhoneBean implements Writable {
//峰值流量
private long upFlow;
//低谷流量
private long downFlow;
//总流量
private long sumFlow;
//提供无参构造
public PhoneBean() {
}
//提供三个参数的getter和setter方法
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
//实现序列化和反序列化方法,注意顺序一定要保持一致
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
}
//重写ToString方法
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}
2、自定义Mapper类
该类读取和解析文本文件,将各个手机号的属性封装到PhoneBean对象中,并输出到Reduce使用
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PhoneMapper extends Mapper<LongWritable, Text, Text, PhoneBean> {
private Text outK = new Text();
private PhoneBean outV = new PhoneBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//分割数据
String[] split = line.split("\t");
//抓取需要的数据:手机号,上行流量,下行流量
String phone = split[1];
String max = split[3];
String mine = split[4];
//封装outK outV
outK.set(phone);
outV.setUpFlow(Long.parseLong(max));
outV.setDownFlow(Long.parseLong(mine));
outV.setSumFlow();
//写出outK outV
context.write(outK, outV);
}
}
4、自定义Reduce类
关于Reduce中的入参类型和出参类型,到这里想必都已经了解,就不再过多解释了
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.LinkedList;
public class PhoneMapper extends Mapper<LongWritable, Text, Text, PhoneBean> {
private Text outK = new Text();
private PhoneBean outV = new PhoneBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//分割数据
String[] splits = line.split("\t");
LinkedList<String> linkedList = new LinkedList<>();
for(String str:splits){
if(StringUtils.isNotEmpty(str)){
linkedList.add(str.trim());
}
}
//抓取需要的数据:手机号,上行流量,下行流量
String phone = linkedList.get(1);
String max = linkedList.get(3);
String mine = linkedList.get(4);
//封装outK outV
outK.set(phone);
outV.setUpFlow(Long.parseLong(max));
outV.setDownFlow(Long.parseLong(mine));
outV.setSumFlow();
//写出outK outV
context.write(outK, outV);
}
}
5、job类
依照wordcount案例中的模板做即可
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PhoneJob {
public static void main(String[] args) throws Exception {
//1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 关联本Driver类
job.setJarByClass(PhoneJob.class);
//3 关联Mapper和Reducer
job.setMapperClass(PhoneMapper.class);
job.setReducerClass(PhoneReducer.class);
//4 设置Map端输出KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneBean.class);
//5 设置程序最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PhoneBean.class);
//6 设置程序的输入输出路径
String inPath = "F:\\网盘\\csv\\phone_data.txt";
String outPath = "F:\\网盘\\csv\\out.txt";
FileInputFormat.setInputPaths(job, new Path(inPath));
FileOutputFormat.setOutputPath(job, new Path(outPath));
//7 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
}
运行这段程序,观察是否在输出的目标路径下,生成了统计结果

打开最后那个文件,然后对比下原始的文件,正好满足预期的业务需求