下面代码使用map对所有元素加一,并不会使得list元素改变,也就是新的加一的集合开启了新的空间
val list= List(1,2,3,4,5,6)
list.foreach(println)
list.map(_ + 1)
list.foreach(println)
同理,下面是wordcount的部分代码,会浪费很多内存空间
val wordCount= List("hello world","hello scala","hello spark")
val word = wordCount.flatMap(_.split(" "))
val wordTuple = word.map((_, 1))
这就产生了迭代器模式,来节省来内存
val wordCount= List("hello world","hello scala","hello spark")
val iterator = wordCount.iterator
val word = iterator.flatMap(_.split(" "))
val wordTuple = word.map((_, 1))
wordTuple.foreach(println)
输出:
(hello,1)
(world,1)
(hello,1)
(scala,1)
(hello,1)
(spark,1)
为什么可以减少内存呢?scala迭代器源码分析
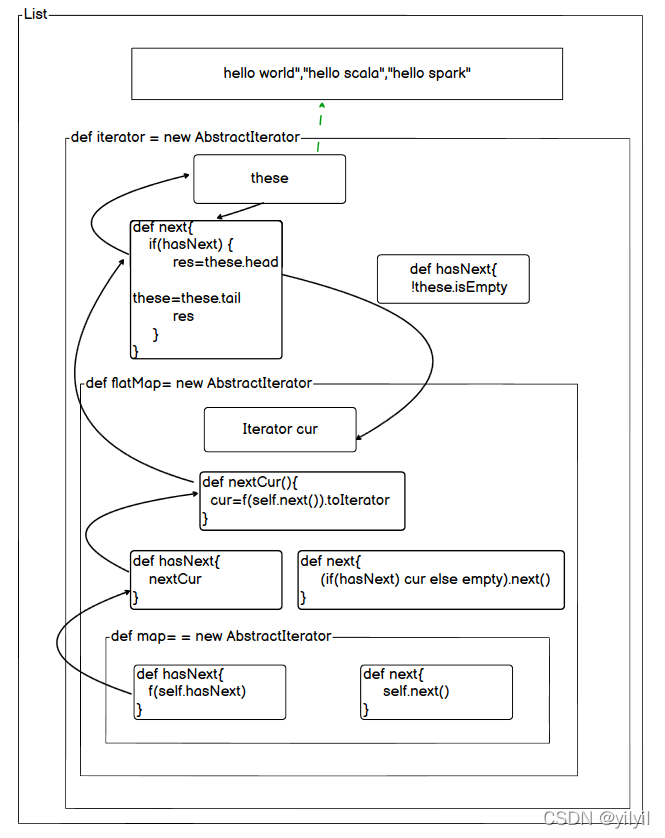
上面是形象化代码嵌套的过程
每次.iterator 都会new AbstractIterator,得到第一个迭代器器,之后迭代器每次调用的方法得到的都是迭代器,AbstractIterator有重要的两个方法hasNext和next
同样迭代器没有做真正的计算,只是new AbstractIterator,以及隐式的调用链的构造
在真正调用hasNext 或者 next才会触发调用过程