大数据技术训练舱,手把手从零教你大数据技术开发:
大数据技术训练舱:从零开始部署Hadoop3高可用集群(基于CentOS7)
Spark架构
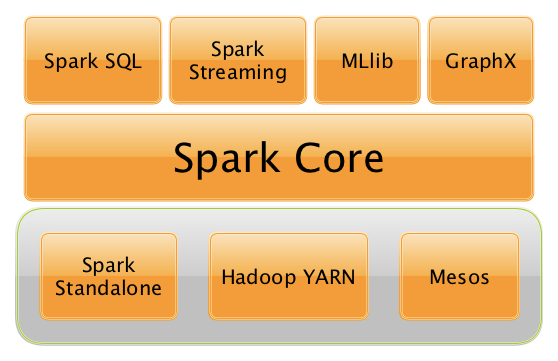
作为大数据处理计算的大一统软件栈Spark,或将是大数据处理领域里面的Spring framework。我们从下图中可以看到Spark core之上具有了四种面向不同计算领域或方式的Spark模块,Spark streaming模块面向实时流计算,具体方式采用微批处理;MLlib模块面向Spark的机器学习库,尤其是Spark默认对Python的支持,成为Python开发者接入Hadoop生态平台的绝佳入口;GraphX面向图处理,有了GraphX,对于社交网络、知识库、超文本关联度分析、传染病传播预测等应用领域,都可以使用Spark来处理。
我们本次主要分析了解到是Spark SQL,一个将不同来源数据进行关系结构化再进行计算处理的模块。
DataFrame
示例
Spark SQL可以支持从很多种数据源的结构化抽象,Spark SQL从数据源中抽取数据集后抽象成一种具有schema结构的rdd对象:DataFrame,有点类似拿到了一个Hibernate的Session与实体对象的合体(类似,可能不太恰当),可以执行类似下面例子中DataFrame(df)的查询操作。? ??
大家可以看到DataFrame实际上就是将数据源结构化为SQL表列。因为DataFreame也需要进行schema定义。类似下图:

数据源
Spark SQL可以从哪些数据源建立DataFrame结构化模型呢?
-
json:Spark自动推断数据结构和类型
-
Parquet????Spark的默认数据源,自动保存schema
-
Hive table? Spark支持直接读取Hive数据
-
JDBC? Spark通过Jdbc驱动拉取Rdbms数据表数据
-
CSV????可根据CSV行头定义列
-
等等......
架构
如下图所示:
-
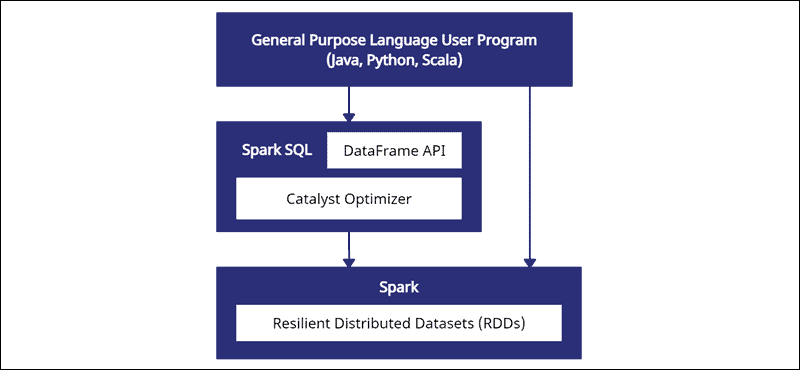
客户端根据自己的目标语言,Java、Python、Scala进行Spark SQL操作。
-
Spark SQL访问上述的各种数据源,创建DataFrame对象。
-
通过对DataFrame API的调用,实现SQL方式操作数据(查询、聚合、分组等、连接等)。
-
Spark SQL将SQL操作语句调入Catalyst Optimizer引擎形成执行计划。
-
执行计划进入Spark处理引擎,由分布在不同节点的Spark集群任务并行处理SchemaRDD(DataFrame)。
Catalyst优化器
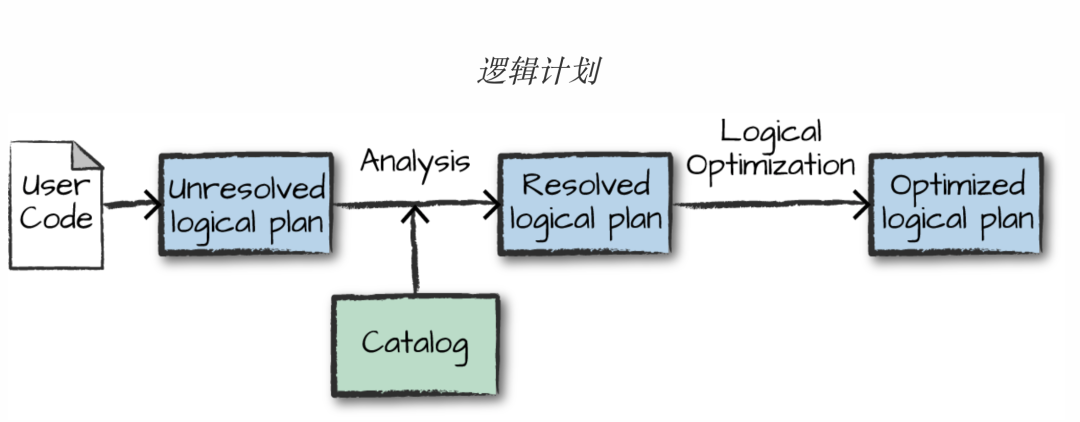
Spark SQL执行的SQL语句在Catalyst优化器中经历了逻辑计划、物理计划两个过程,逻辑计划过程主要依赖Antlr。首先SQL语句在unresolved logical plan阶段由antlr转换成抽象语法树,这时候会根据Catalog中(存储了所有的表信息、DataFrame信息)的元数据,对unresolved?logical plan进行表达式解析,确定表、列都存在后,才会形成真正的resolved?logical plan,最后交付Catalyst优化器进行优化逻辑计划(Optimized logical plan)。如下图所示:
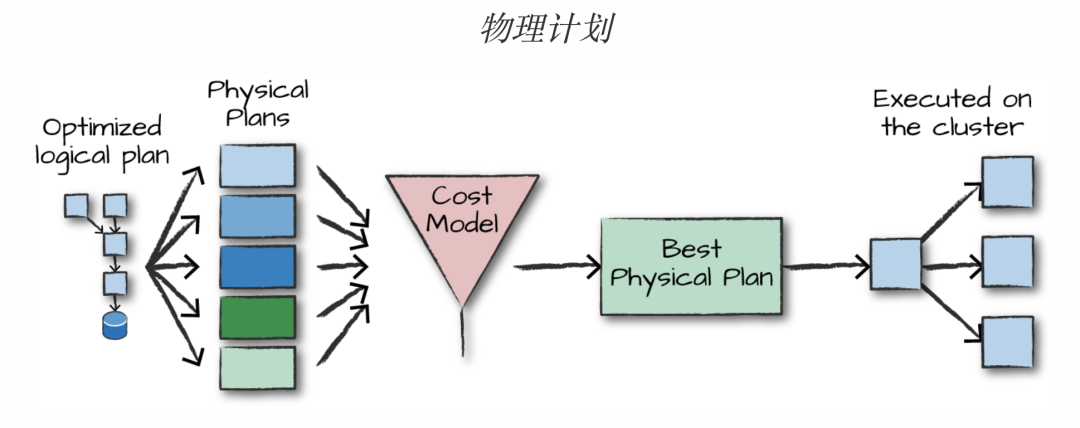
转换成功的逻辑计划将进入物理计划阶段,Optimized logical plan会分解为多个物理计划(Physical Plans),最终进入代价模型(Cost Model),根据资源开销成本,去选择最佳的物理计划(Best Physical Plan),最终进入到集群中运行。如下图所示:
Dataset
在Dataframe之后Spark推出了一个新的数据抽象:DataSet,DataSet可以理解为DataFrame的扩展,对象类型更为显性,这种优势就是在开发起来具有更友好的API风格,更适合工程化管理。
例如:我们定义了一个叫Flight的Dataset实体类

我们可以将DataFrame转换成Flight class类型的Dataset,这时候的变量flights就是Dataset[Flight]强类型了,即具有类型安全检查,也具有Dataframe的查询优化特性。

Dataset在编译时就会检查类型是否符合规范。Dataset仅适合用于基于JVM的Scala、Java,通过case类或Javabeans指定类型。
当调用DataFrame的API时,返回的结果结构就是Row类型;当使用DatasetAPI时,就可以将将Row格式的每一行转换为指定的业务领域对象(case类或Java类)
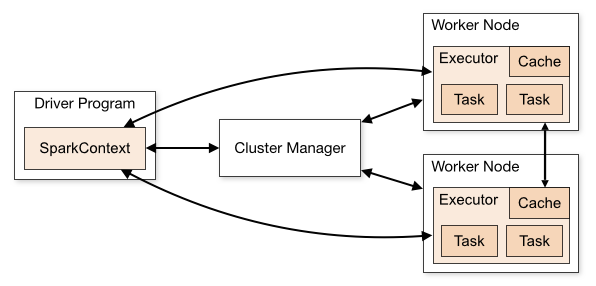
Spark集群架构
我们可以将Hive、Impala、Presto理解为比较独立的数仓工具,在上一篇中Impala和Presto的对比,我们甚至可以看到它们俩具有独立的分布式架构。Hive则是Hadoop生态独立性很高SQL解析与执行工具,插接Mapreduce、Spark、Tez计算引擎,高度依赖HDFS存储系统。
反观Spark SQL,它并不独立,应是Spark平台上的一组模块,彻底与Spark糅合在一起,因此谈Spark SQL的分布式架构,其实就是在讲Spark架构。我们从下图可以看到Spark架构的特征,在集群计算资源调度方面与Spark无关,主要依赖Hadooop Yarn或者Mesos实现分布式集群计算资源的调度管理。
同理Spark SQL解析完成物理计划后就完成交由Spark集群进行并行任务处理,Spark集群中Driver提交作业、实现调度,Executor具体执行任务、返回结果。
Executor中通过多线程方式运行任务(Task),而且Executor通过堆内内存、堆外内存管理,实现高性能的内存计算,这点是Spark性能上优于Mapreduce将中间过程数据写入磁盘导致性能慢的关键原因之一。
您觉得文章写得不错就点赞、分享一下吧!
本文由公众号「守护石」出品,转载请注明来源和作者。?