・前言
- 之前在学校学习理论知识的时候,总是错误的认为当涉及到多张表,且有冗余数据的时候,就使用联表操作。但是直到自己深一步学习后,才发现事实并不是如此。
- 首先可以拿阿里巴巴的代码规范来证明我那错误观点:其有一条强制性建议:执行三张表以上的多表联合查询,因为对数据量不大的应用来说, 多表联合查询开发高效, 但是多表联合查询在表数据量大, 并且没有索引的时候, 如果进行笛卡儿积, 那数据量会非常大, sql 执行效率会非常低。
・联表缺点
- 联表操作即是通过sql代替业务代码进行业务逻辑操作,虽说执行sql消耗的时间会比执行代码的稍微快一点点,但是当大量的业务规则和逻辑放在数据库来执行,数据库压力无疑会加大,尤其当数据量大的时候,数据库消耗的cpu、内存等资源将会达到一定瓶颈,数据库服务器的维护费用不用我多说了吧,贵啊,企业是要盈利的啊!
- 正如阿里巴巴代码规范里强调的,如果关联查询遇到索引失效的时候,如果进行笛卡尔积,全表扫描的话,那带来的后果简直不敢想象。再例如一个分页列表页面,联表操作会使得数据库进行扫描得到所有的结果,但是分页列表只需要当前页的分页结果,这也使得数据库消耗了额外的资源。
- 在高可用和开发难度来讲,大量的关联查询会导致集中式的数据库架构很难向分布式架构转换,伸缩性方面的优化难度高。例如当公司业务规模不断增大的时候,业务需求不断迭代变更,如果要进行分库分表操作,大量的关联操作会使得你十分头疼,这就给以后留下了很大的开发难度,如果没有一个很好的开发设计,这将会牵一发而动全身,使得你业务要想迭代,将要重构项目架构,而无法很好地重复利用了。不仅如此,一些复杂的关联操作也是你需要很好的sql设计能力。
・单表优点概述
- 好了,说完了联表操作的痛点,接下来该说说单表的优点了(你语文谁教的?拿别人的短处跟你的长处相比?这有可比性嘛?)其实不然,我接下来所说的都是单表设计能很好地解决联表的痛点。联表操作只需要执行一次数据库操作就能将数据结果返回,而单表查询将会进行多次数据库操作,这不就使得io资源浪费了?还有就是,进行数据库操作还要涉及数据库连接的建立与释放,多张单表的多次操作不是更加耗费性能嘛?
- 哈哈,针对这个疑惑,我之前也是很疑惑(我上次那么无语还是上次),于是乎我去请教了我的导师德哥,他说,对于这个问题,得分具体业务场景,如果是数据量不大,且对性能要求比较高的情况下,确实是联表一次查询操作,效率会更加高效。但是如果是数据量比较庞大,且业务对时间性能要求不高情况下(其实程序里面做SQL组合牺牲的是IO性能而已,而且在大多数场景下,这种IO是牺牲得起的。)还是建议使用单表,且使用后端代码处理业务,将需要联表操作的数据,用代码封装在业务层进行操作,利用微服务特点,加上负载均衡,可以将数据库压力减到最低,增加了可扩展性。这时候还可以设计单表的数据适当冗余。比如出库单有个单价,我们结算单也有个单价。我们结算单的单价依赖出库单的单价,然后可以修改。然后我们数据库设计就会在出库单加一个单价,结算单也加一个单价。这样子结算单的单价才支持修改。如果产品说,结算单不需要修改单价,界面展示而已。那么我们结算单完全可以不需要这个单价字段。直接依赖出库单的单价查询就行。因此,如果查询频率高,查询数据量大等等,数据冗余可以提高查询性能。假设这个字段改动比较多。你去冗余,又会涉及到同步数据的问题,每次修改都要去同步对方的数据,这时候就不建议冗余了。
- 不仅如此,当涉及到联表操作时候,如果是非常复杂的需求,用sql去解决业务的话,写出来的sql语句将会少则几十行,多则成百上千行,这样的sql我想看到都十分倒胃吧,如果产品那边需要更改需求,那将会让人无从下手。因此,针对此问题,建议拆分为单表,将业务逻辑(除了那种聚合函数、分组、排序等数据库具有明显优势的)用后端代码去实现,业务代码阅读起来也更加有逻辑性,虽然代码会很长,但是可以借助调试debug、postmen测试或者打日志等各种方式去帮助你理解业务。
・单表优点总结
因此,单表设计有如下优点:(摘自《高性能MySQL(第3版)》_宁海元等译)
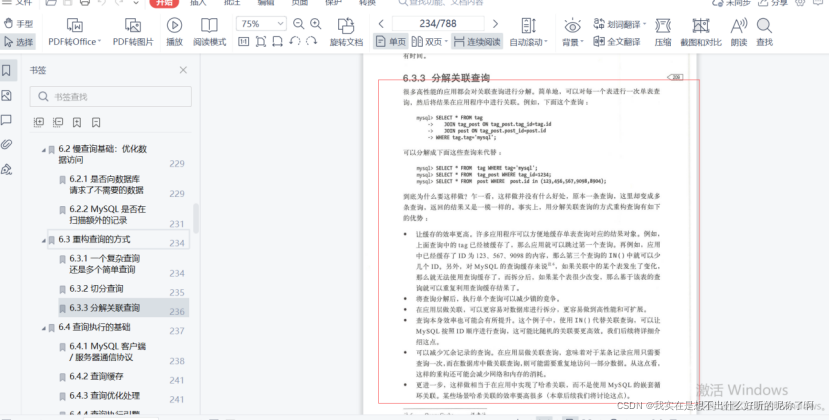
(需要文档的可以私聊我哦)
文中说到:
- 缓存效率更高, 许多应用程序可以方便地缓存单表查询对应的结果对象. 如果关联中的某个表发生了变化, 那么就无法使用查询缓存了, 而拆分后, 如果某个表很少改变, 那么基于该表的查询就可以重复利用查询缓存结果了。
- 多表信息联合的列表页面分页显示, 只需要显示一部分的数据, 如果是多表联合查询那要把所有数据联结查出来再执行 limit, 如果是多次单表查询, 先对单表进行筛选, 先执行 limit 再与其余表去关联, 数据量会大大减小。
- 如果数据库没有进行读写分离 (主从备份), 在并发量高的时候, 由于写表会加排他锁, 把多表联合查询改成单表查询后锁的粒度变小, 减少了锁的竞争。
- 在数据量变大之后, 普遍会采用分库分表的方法来缓解数据库的压力, 采用单表查询比多表联合查询更容易进行分库, 不需要对 sql 语句进行大量的修改, 更易扩展. 分库分表的中间件一般对跨库 join 都支持不好。
- 查询本身效率也可能会有所提升. 查询 id 集的时候, 使用 IN() 代替关联查询, 可以让 MySQL 按照 ID 顺序进行查询, 这可能比随机的关联要更高效。
- 业务高速增长时, 数据库作为最底层, 最容易遇到瓶颈, 单机数据库计算资源很贵, 数据库同时要服务写和读, 都需要消耗 CPU, 为了能让数据库的吞吐变得更高,而大部分业务又不在乎那几百微妙到毫秒级的延时差距, 业务会把更多计算放到 service 层做, 毕竟计算资源很好水平扩展, 数据库很难啊, 这是一种重业务, 轻 DB 的架构。
- 可以减少冗余记录的查询, 在应用层做关联查询, 意味着对于某条记录应用只需要查询一次, 而在数据库中做关联查询, 则可能需要重复地访问一部分数据。更进一步, 这样做相当于在应用中实现了哈希关联, 而不是使用 MySQL 的嵌套循环关联. 某些场景哈希关联的效率要高很多。
・单表缺点
- 正如前面所讲,多次单表查询需要涉及多次数据库连接,在这方面耗费的时间会比一次联表查询久一点。
- 当业务需要单表数据进行联合时候,这时候或许使用一条联合sql便能轻松解决,但是单表这里需要将业务代码在Service层进行数据封装和填充,所以这里单表所涉及的业务代码会相对复杂点。
・展望
- 正所谓有利必有弊,很多时候我们也不能直接下定论说我就一定要用单表或者联表,正如上面所说,单表和联表都有其在特定业务场景下的优缺点,我们要做的就是在某种场景下,选择最合适,利大于弊的,且考虑到日后的高可用、可移植性、可扩展性和是否追求高性能等问题进行综合考虑。
- 我想,技术总是不断迭代的,也许未来,我对现在的看法又会像我在前言所说的理解一样被推翻。好比如小时候想到圆,就会想到月亮,月饼;现在看到圆就不仅会想到月亮,月饼,还会想到团圆,人名币;等到以后想到圆,又会有在之前的认知上更深的一步理解了,我想这就是成长吧。