并发
- 事务和程序是两个概念
- 在关系数据库中,一个事务可以是一条 SQL 语句,一组SQL 语句或整个程序
- 一个程序通常包含多个事务
- 事务是恢复和并发控制的基本单位
- 一个事务的执行不能被其他事务干扰
- 一个事务内部的操作及使用的数据对其他并发事务是隔离的
- 并发执行的各个事务之间不能互相干扰
- 事务内部更多的故障是非预期的,是不能由应用程序处理的。
- 运算溢出
- 并发事务发生死锁而被选中撤销该事务
- 违反了某些完整性限制而被终止等
- 转储操作与用户事务并发进行
- 为保证数据库是可恢复的,登记日志文件时必须遵循两条原则
- 登记的次序严格按并发事务执行的时间次序
- 必须先写日志文件,后写数据库
- 写日志文件操作:把表示这个修改的日志记录写到日志文件中
- 写数据库操作:把对数据的修改写到数据库中
- 数据库镜像在没有出现故障时可用于并发操作:一个用户对数据加排他锁修改数据,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁。
- 数据库镜像不是对整个数据库进行镜像:在实际应用中用户往往只选择对关键数据和日志文件镜像
故障恢复
事务故障的恢复
事务故障:事务在运行至正常终止点前被终止
事务故障的恢复方法:由恢复子系统利用日志文件撤消( UNDO )此事务已对数据库进行的修改
事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预
事务故障的恢复步骤:
- 反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
- 对该事务的更新操作执行逆操作。即将日志记录中“更新前的值写入数据库。
- 插入操作,“更新前的值”为空,则相当于做删除操作
- 删除操作,“更新后的值”为空,则相当于做插入操作
- 若是修改操作,则相当于用修改前值代替修改后值
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
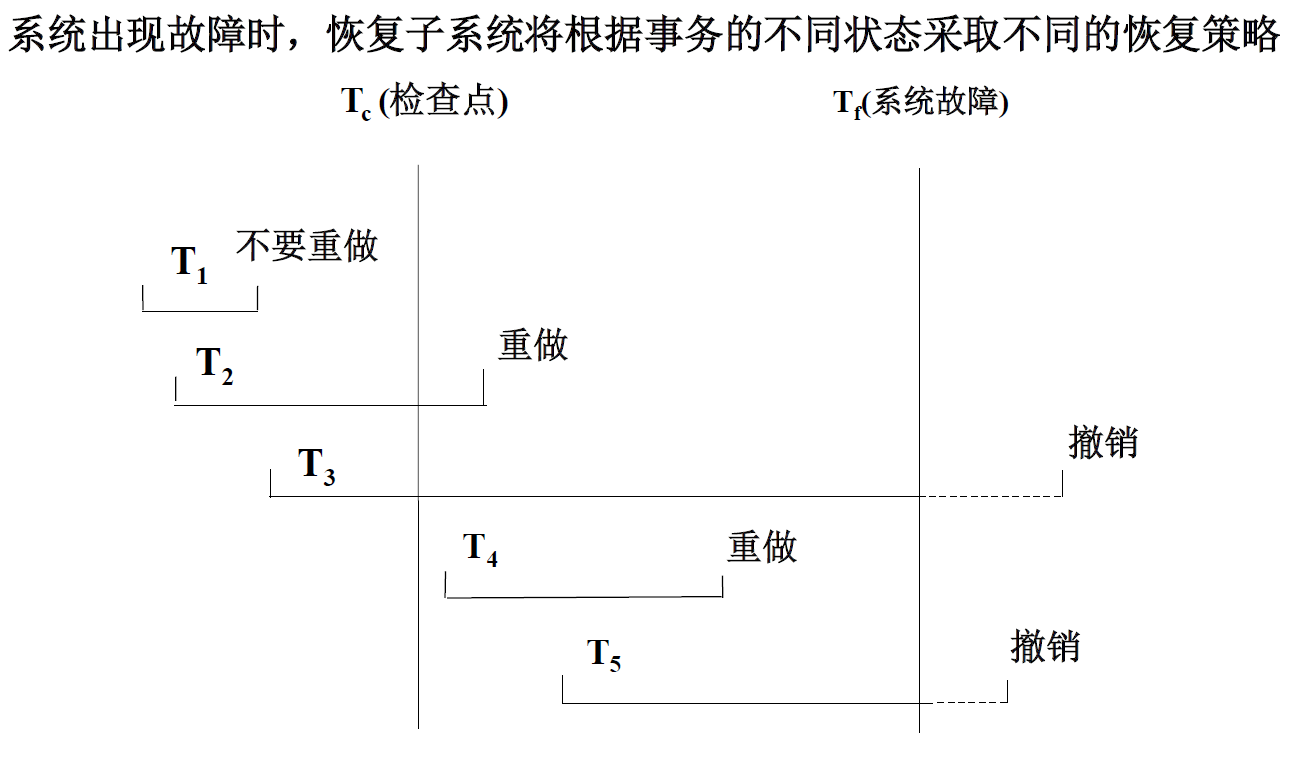
系统故障的恢复
系统故障造成数据库不一致状态的原因:
- 未完成事务对数据库的更新可能已写入数据库
- 已提交事务对数据库的更新可能还留在缓冲区没来得及写入数据库
系统故障的恢复方法:
- Undo故障发生时未完成的事务
- Redo已完成的事务
系统故障的恢复由系统在 重新启动时 自动完成,不需要用户干预
系统故障的恢复步骤:
-
正向扫描日志文件(即从头扫描日志文件)
- 重做 (REDO) 队列 : 在故障发生前已经提交的事务
- 这些事务既有 BEGIN TRANSACTION 记录,也有COMMIT 记录
- 撤销(队列):故障发生时尚未完成的事务
- 这些事务只有 BEGIN TRANSACTION 记录,无相应的COMMIT 记录
- 重做 (REDO) 队列 : 在故障发生前已经提交的事务
-
对撤销(UNDO)队列事务进行撤销(UNDO)处理
-
反向扫描日志文件,对每个撤销事务的更新操作执行逆操作
-
即将日志记录中“更新前的值”写入数据库
-
-
对重做(REDO)队列事务进行重做(REDO)处理
-
正向扫描日志文件,对每个重做事务重新执行登记的操作
-
即将日志记录中“更新后的值”写入数据库
-
介质故障的恢复
- 重装数据库
- 重做已完成的事务
介质故障的恢复步骤:
- 装入最新的后备数据库副本(离故障发生时刻最近的转储副本),使数据库恢复到最近一次转储时的一致性状态。
- 对于静态转储的数据库副本,装入后数据库即处于一致性状态
- 对于动态转储的数据库副本,还须同时装入转储时刻的日志文件副本,利用恢复系统故障的方法(即 REDO+UNDO),才能将数据库恢复到一致性状态。
- 装入有关的日志文件副本(转储结束时刻的日志文件副本 ) ,重做已完成的事务。
- 首先扫描日志文件,找出故障发生时已提交的事务的标识,将其记入重做队列。
- 然后正向扫描日志文件,对重做队列中的所有事务进行重做处理。即将日志记录中“更新后的值”写入数据库。
介质故障的恢复需要数据库管理员介入,数据库管理员的工作是:重装最近转储的数据库副本和有关的各日志文件副本、执行系统提供的恢复命令
注意:具体的恢复操作仍由数据库管理系统完成
利用检查点的恢复策略