�Ķ�����֮ǰ,Ĭ���Ѿ������Hadoop��Ⱥ��
ǰ��
��ʾ:�����DZ�ƪ������������,���永���ɹ��ο�
һ��HDFS
����:
HDFS��hadoop��һ���ֲ�ʽ�ļ�ϵͳ,���ڴ洢�ļ�,ͨ��Ŀ¼��Ŀ¼������λ�ļ�����ΪHDFS�Ƿֲ�ʽ��,��ô����Ҫ��̨���������������ļ��Ĵ洢��
HDFS������һ��д��,��ζ����ij�����һ���ļ�һ����������,д��,�ر�֮��Ͳ���Ҫ�ı䡣����һ���ļ��Ѿ�д�벿������,���������Ҫ��ԭ��������,�Dz�֧�ֵ�,���ǿ��Լ���������ļ���������ݡ�
�ŵ�:
- ���ݴ���,���ݻ��Զ�����������,�Ӷ�ͨ�����Ӹ�������ʽ,����ݴ��ԡ���ijһ��������ʧʱ,���Զ��ָ���
- �����ڴ�����,���������ﵽGB,TB����PB��ʱ��,ʹ��HDFS���ܹ��ܺõĴ�����
- �����ڴ����ļ�,���ļ������ﵽ�����ģ��������,HDFSҲ�ܴ�����
- ���Թ��������ۻ����ϡ�
ȱ��:
- �������ڵ��ӳٵ����ݷ��ʡ�������뼶������ݴ洢�Լ�����,���������ġ�
- ����Ч�Ĵ�������С�ļ��Ĵ洢����Ϊ�ļ�̫С,�洢��NameNode�ϵĿ���Ϣ��Խ��,�ᵼ��NameNode���ڴ�����ı�ռ�á�����С�ļ�����,ռ�õĿ���Ϣ�ͱȽ϶�,��ô���ҿ���Ϣ��ʱ����ܶ�Ҫ�ȶ�ȡ�ļ���ʱ�䶼Ҫ�ࡣ
- ��֧�ֶ��߳�д�ļ�,һ���ļ�ֻ����һ���߳���д,�������ж���߳�ͬʱд��
- ֻ֧���ļ�����,���Dz�֧���ļ����ġ�
HDFS���:
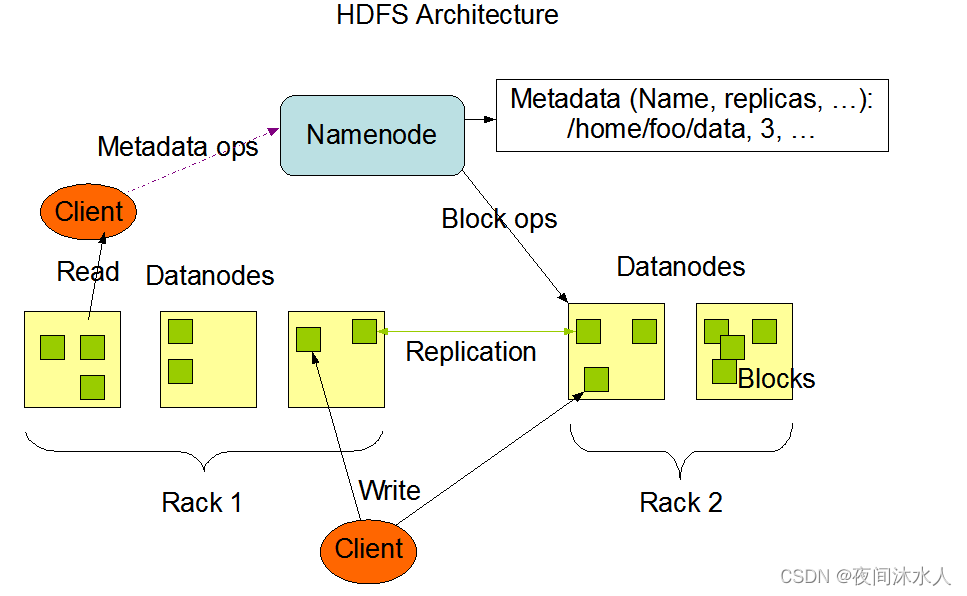
NameNode:
Master��ɫ,����һ�������ߡ�����DataNode�Ļ,NameNodeÿ3����յ�DataNode�������,�������10����û���յ�DataNode������,��ô������ȴ�30��,�������û���յ�DataNode������,��ô��ʱ�Ż��ж���DataNode�����á�
- ����HDFS�����ƿռ�
- ������������,����ÿһ���ļ���ĸ�������,��ͬ���ļ�������趨��ͬ�ĸ�������
- �������ļ���Ĵ洢��Ϣ,ÿһ���ļ����СĬ��Ϊ128M��
- �����ͻ��˵Ķ�д����,��ΪNameNode�д洢�����е��ļ������Ϣ��
DataNode:
Slave��ɫ,NameNode�´��д����,DataNodeִ��ʵ�ʵIJ�������DataNode������,��������NameNodeע��,ע��ɹ���,������(Ĭ��6Сʱ)���ϱ���������ŵ����е�block�����Ϣ,����ÿ3���NameNode�����������,ͬʱ����NameNode��DataNode�´�����
- ����ʵ���ǵ����ݡ�
- ִ��ʵ�ʵĶ�д������
Client:
���ǿͻ��ˡ�
- �ļ��з�,�ļ����ϴ���ʱ��,����NameNode���ļ���Ĵ�С�����ļ��з�,�ļ����СĬ��Ϊ128M,����Ļ���256M��С���ļ��顣
- ��NameNode���н���,�����ļ�λ����Ϣ��
- ��DataNode���н���,ʵ���϶�д�ļ���
- �ṩAPI����DataNode��
Secondary NameNode:
������NameNode���ȱ���,Ҳ����˵,��NameNode����֮��,��������ȡ��NameNode,��ֻ�Ƿֵ�NameNode�Ĺ�����,�����ڽ��������,Э���ָ�NameNode��2NN�ᶨ�ڵĶ�NN�����ݽ��кϲ�������
HDFS��������:
NN��DN��������:
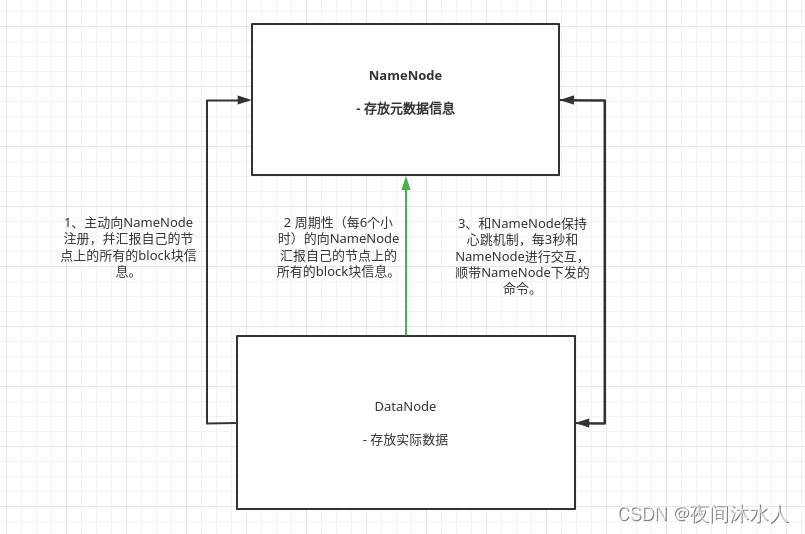
-
NN������,�Ὣfsimage��edits���ص��ڴ�,����һ����ɵ�Ԫ������Ϣ��
-
����client�˵IJ���,NN���ȼ�¼��־,�ӵ�Edits��,�ٸ����ڴ档
-
DN������,������������NN����ע��,���Ҹ����Լ��ڵ��ϵ�block��Ϣ,�Ժ�������Ե���NN�㱨�Լ���block��Ϣ(Ĭ��6Сʱ,dfs.blockreport.intervalMsec,�㱨ǰ,DN���Բ��Լ���block��Ϣ,Ĭ��6Сʱ,dfs.datanode.directoryscan.interval)��
-
DN�������Եĺ�NN��������(Ĭ��3��,dfs.heartbeat.interval),�����лḽ��NN�·���DN������,NN�������10����û���յ�DN������,�ڵȴ�30���,�϶���DN������,������DN�Ӽ�Ⱥ���������㹫ʽ:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval = 10���� + 30�롣
NN��2NN��������:
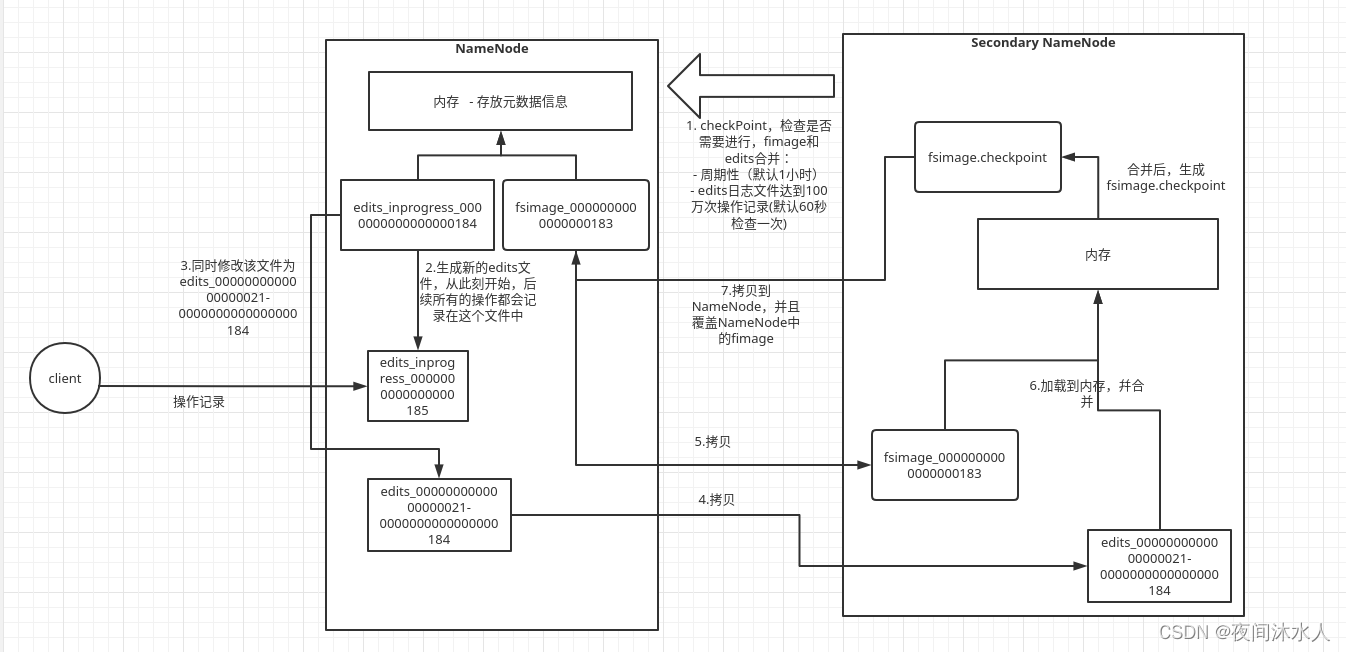
-
NN������,�Ὣfsimage��edits���ص��ڴ�,����һ����ɵ�Ԫ������Ϣ��
-
����client�˵IJ���,NN���ȼ�¼��־,�ӵ�Edits��,�ٸ����ڴ档
-
2NN�������Եķ���NN(checkPoint):(1)��ʱ����ʱ�䵽(Ĭ��1Сʱ,dfs.namenode.checkpoint.period)��(2)Edits����־д����(һ��������¼,dfs.namenode.checkpoint.txns,Ҳ�������Ե�ȥ����ļ��Ƿ�ﵽһ��������¼,(Ĭ��60��,dfs.namenode.checkpoint.check.period))�������ڼ�,NN���ȹ���edits_inprogress_0000000000000000184��־�ļ�����edits_inprogress_0000000000000000185,��ͬʱ��edits_inprogress_0000000000000000184�ļ��ij�edits_0000000000000000021-0000000000000000184�ļ�,��ô�Ӵ˿̿�ʼ,�����ĵĿͻ��˵IJ���������¼��edits_inprogress_0000000000000000185�ļ��С�
-
ͬʱ,2NN������fsimage_0000000000000000183��edits_inprogress_0000000000000000184���Լ��ķ������ϲ����ص��ڴ�,����fsimage.checkpoint,��ô��ʱ��fsimage.checkpoint���ǵ�ǰʱ�����µ�Ԫ������Ϣ������fsimage.checkpoint������NN,�������Ƹ���ԭ��NN�ϵ����µ�fimage����ʱ��fimage�����edits_inprogress_0000000000000000185���������������һ��ʱ�����µ�Ԫ����,Ҳ����һ��2NN��Ҫ���кϲ����ļ���
��չ,NameNode����ʽ����,���������¼����ļ�:
-
fimage�ļ�:HDFS�ļ����ݵ�һ�������Լ���,������HDFS�ļ�ϵͳ�����е�Ŀ¼��Ϣ�Լ��ļ�inode�����л���Ϣ����ʹ��hdfs oiv -p XML -i fsimage_0000000000000000183 -o /opt/fsimage_0000000000000000183.xml���fimage�ļ�ת����xml�ļ��鿴(hdfs oiv -p �ļ����� -i �����ļ� -o ת������ļ�·��)��
-
edits�ļ�:�����˶Լ�Ⱥ�������ݵIJ�����¼,ֻ�ܲ��ϵ��Ӳ�������ʹ��hdfs oev -p XML -i edits_inprogress_0000000000000000273 -o /opt/edits_inprogress_0000000000000000273.xml���edits�ļ�ת����xml�ļ��鿴(hdfs oev -p �ļ����� -i edits�ļ� -o ת������ļ�·��)��
-
seen_txid�ļ�:�������һ������,������ݾ��ǵ�ǰ���µ�fimage��š�
-
VERSION:�����˵�ǰNameNode�ռ�ID,��ȺID�ȡ�NameNode����ͨ��jiqunID��DataNode���н����ġ�
-
HDFS�ļ���:
HDFS���������Ƿֿ��洢����,��Ĵ�С����ͨ������(dfs.blocksize)����,Hadoop2.X/3.x��Ĭ����128M,1.XĬ����64M��
- ���Ѱַʱ��Ϊ10ms,��ô����˵�Ӳ���block1��Ŀ��block��ʱ��Ϊ10ms��
- Ѱַʱ��Ϊ����ʱ���1%ʱΪ���״̬,���,����ʱ��=10ms/1%=1000ms=1s��
�ܽ�:�ļ���Ĵ�С����Ӧ��ȡ������̵Ķ�д���ʡ�
HDFS��shell����:
hadoop fs ����hdfs dfs,�÷�����һ���ġ�
(1). -mkdir
����һ�������ļ���:hadoop fs -mkdir /xiyouji
(2). -moveFromLocal
�������ļ�sunwukong.txt�����ϴ���hdfs:hadoop fs -moveFromLocal ./sunwukong.txt /xiyouji

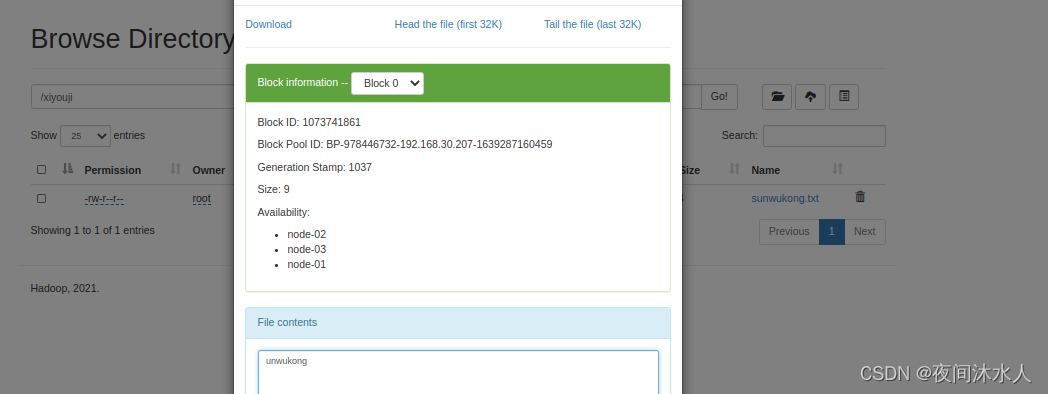
(3). -copyFromLocal
�������ļ�sunwukong.txt�����ϴ���hdfs:hadoop fs -copyFromLocal ./shaseng.txt /xiyouji

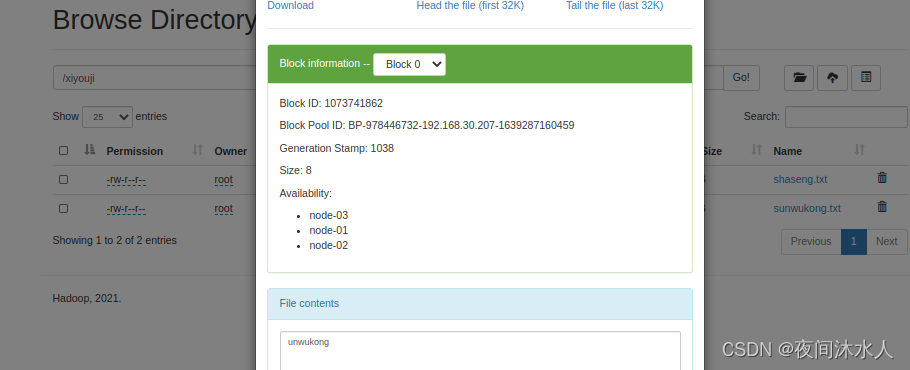
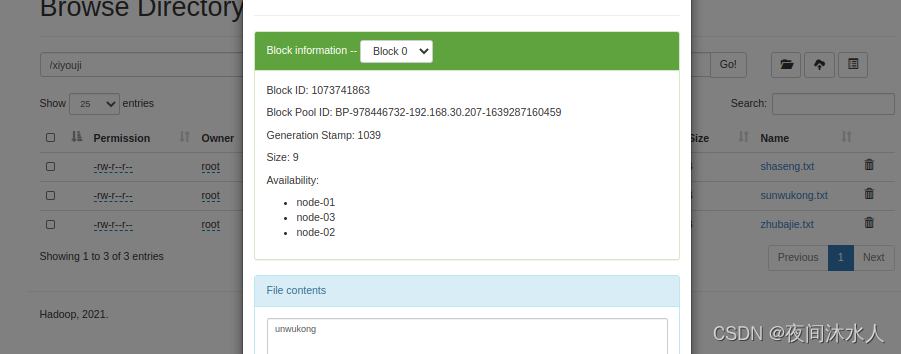
(4). -put (��-copyFromLocalЧ����һ����)
�������ļ�zhubajie.txt�����ϴ���hdfs:hadoop fs -put ./zhubajie.txt /xiyouji
(5). -appendToFile
��һ���ļ����Ѿ����ڵ��ļ�ĩβ,��jingunbang.txt�ӵ�sunwukong.txt���:hadoop fs -appendToFile ./jingunbang.txt /xiyouji/sunwukong.txt
(6). -copyToLocal
��HDFS�Ͽ����ļ�������,���Ը����ļ����֡�:hadoop fs -copyToLocal /xiyouji/sunwukong.txt ./sunwukong1.txt

(7). -get(�÷���-copyToLocalһ��)
��HDFS�Ͽ����ļ�������,���Ը����ļ����֡�:hadoop fs -get /xiyouji/sunwukong.txt ./sunwukong2.txt

(8). -ls | -cat | -chmod | -chown | -mkdir | -cp | -mv | -tail | -rm | -rm -r(�ݹ�ɾ��Ŀ¼����������ļ�)
��Щ�����linux������÷���һ���ġ�
(9). -du
ͳ���ļ��е��ܵĴ�С��Ϣ: hadoop fs -du -s -h /xiyouji

ͳ���ļ����е�ÿ���ļ��Ĵ�С��Ϣ: hadoop fs -du -h /xiyouji

(10). -setrep
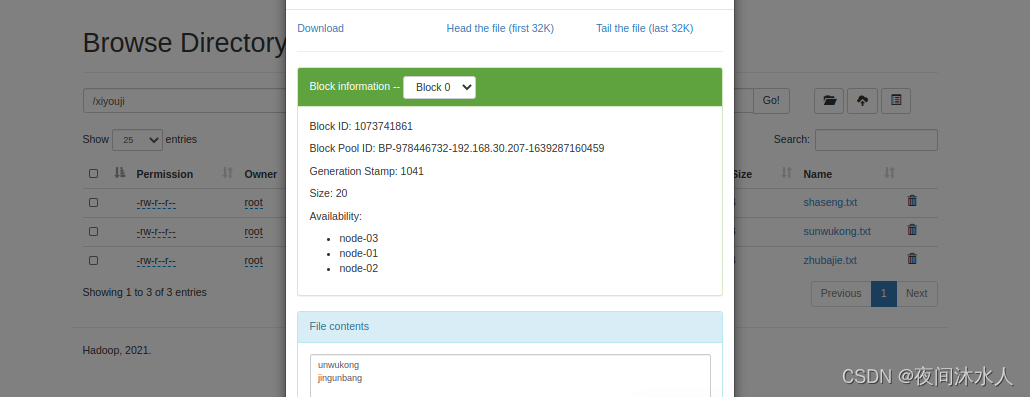
�����ļ��ĸ�������:hadoop fs -setrep 5 /xiyouji/sunwukong.txt

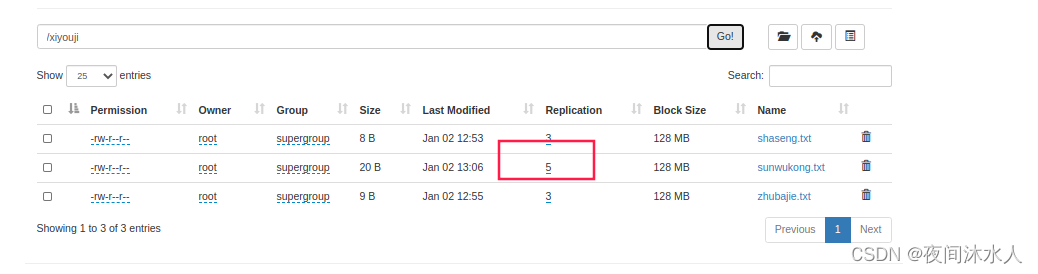
������Ȼ������sunwukong.txt�ĸ�������Ϊ5,������Ϊֻ����̨����,��ôʵ����sunwukong.txt�ĸ�����������3,ֱ�����������ﵽ5̨��ʱ��,sunwukong.txt�ĸ����������������ı��5��
HDFS����������:
��żλУ��:���ݴ���ʱ,�������һ��У��λ,���2���������е�1�ĸ�����־,���Ϊż��,��Ϊ0,����Ϊ1��
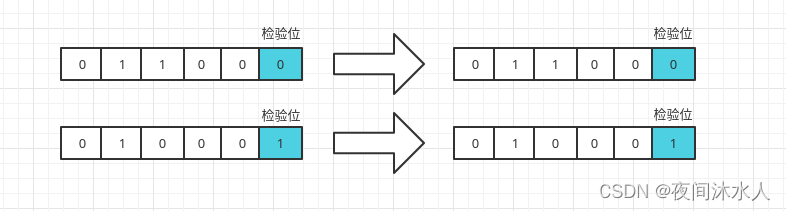
crcУ��λ:����żλУ��ԭ����ͬ,����Ҫ����żλУ�����ȷ,�߱����ߵIJ���������,��һ���ձ������У�鷽ʽ��

HDFS�ı������������Եķ���:
- DN��ȡblock��ʱ��,�������ݵ�CheckSum��
- ����������CheckSum�ʹ洢���ݵ�ʱ����CheckSum��һ��,��������Ч����ʱ��������DN�϶�ȡblock���ݡ�
- ����������У�鷽ʽ:crc(32λ),md5(128λ)��
- DN�������Եļ���block���ݿ��CheckSum��
HDFS�����:
HDFS�ж�д�����漰�����ݵ�λ:
- block:�ͻ����ϴ��ļ�ʱ���������ݵ�λ,Ĭ��Ϊ128M,����ͨ��������,�ʹ��̵Ķ�д�����йء�block̫��,�ᵼ��Map��������,��������ִ���ٶ���,block̫С,��ŵ�λ�þͶ�,������Ѱַʱ�䡣
- packet:���ݴ���ĵڶ�����λ,ʵ���Ͽͻ��˵����ݴ�С�ﵽһ��packet��ʱ��Żᷢ�����ݰ���DN,Ĭ��64KB��ÿһ��packet�ɶ��chunk��䡣
- chunk:���ݴ������С�ĵ�λ,�����Ƕ����ݽ���У��,Ĭ��512Byte,����4���ֽڵ�У��λ,ʵ����д��packet��ʱ�����516Byte��pakcet��chunkռ��λԼΪ128:1(64 * 1024 / 512)��
HDFS�������:
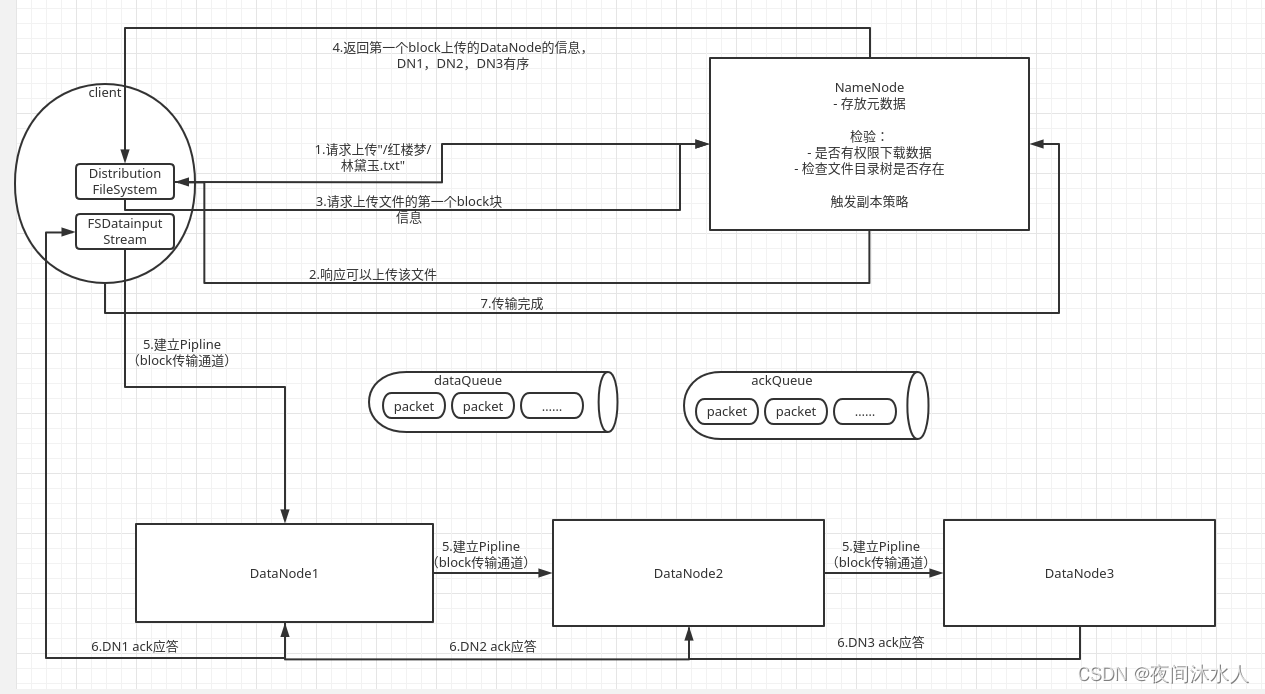
1���ͻ���ͨ��Distributed FileSystem��NN�����ϴ��ļ�����,�����ϴ�"/��¥��/������.txt"��
2��NN���ܵ�����1��,����ļ��Ƿ�����ϴ������ؼ�������ͻ���:
- ����Ƿ���Ȩ���ϴ��ļ���
- ����ļ�Ŀ¼���Ƿ���ڡ�
3���ͻ��˵õ�NN�����ϴ����ļ�����Ӧ��,������NN���������ϴ����ļ��ĵ�һ��block�������,��Ҫ��NN���ؿ�ʹ�õ�DN�����б���
4��NN���ܵ�����3��,���ݸ�������(������Ĭ��Ϊ3),���������ʹ�õ�DN1,DN2,DN3,������ʹ�õ�DN�����б����ظ��ͻ��ˡ�
- ��������:��������������,�ܹ���̨����,ÿ����������̨����,r1(r1dn1,r1dn2,r1dn3),r2(r2dn1,r2dn2,r2dn3).
- �����ϴ��ļ������������r1dn1�����,��ô��һ�������ͱ�����r1dn1������һ�����������ڿͻ������ڻ��ܲ������ڽڵ���(�ͻ���ֱ�����Լ����ڵĽڵ���д����,�����ʡ��Դ��)��
- �ڶ����������������һ��������ͬ�Ļ��ܵĽڵ���(r1dn1��r2dn1��д������Ϊ�˱�֤�ɿ���,���r1����,��ôr2dn1�л���һ������)��
- ���������������ڵڶ����������ڻ��ܵIJ�ͬ�Ľڵ���(r2dn1��r2dn2�еĽڵ�д������Ϊ�˽�Լ��Դ,r2dn1��r2dn2��д���ݲ���Ҫ�������)��
- ����ڵ㡢������ܵ������,�ڵ����ѡ��
5���ͻ��˵õ�NN���صĿ�ʹ�õ�DN�����б���,����DFSOutputStream,��ʼ�Ϳ�ʹ�õ�DN�����б��еĵ�һ��DN1����Pipline,����Ҳ�ῼ�Ǹ��ؾ���,Ȼ������DN1��DN2����Pipline,����DN2��DN3����Pipline��
6���ͻ�����DN1����Pipline��,��ʼ��DN1����packet,DN1���ܵ�packet��,��дEditsLog,Ȼ������ڴ�,�ٽ�packetͨ��Pipline���͵�DN2,��ô��ʱ�ͻ��˾Ϳ��Լ������͵ڶ���packet��DN1,DN2���ܵ�packet��,DN2��ͬ���IJ���,�ٷ��͵�DN3,��ô��ʱDN1�Ϳ��Լ������͵ڶ���packet��DN2��
7����DN3,DN2,DN1�������,��������Ӧ�������,�����DN1��ͻ��˷���,֮��ͻ�����NN������
ע��:����,���ͻ��˷���packet��ʱ��,�Ὣpacket����һ��dataqueue��,��DataStreamer���ϵ���ȡ,������DN1,����ͬʱ�Ὣ��packet�����ƶ���ackququeue�еȴ����еĽڵ��Ӧ����,ֻҪ��һ���ڵ�Ӧ��ɹ�,��ô�ͽ���packet��ackqueue���Ƴ������������һ���ڵ�Ӧ��ʧ��,��ô�Ὣackququeue�е�packet�ƶ���dataqueue��,��������Ͻڵ�,���½���Pipline���д��䡣 ����ڶ���block��ʱ��,�ظ��������еIJ��衣
HDFS����������:
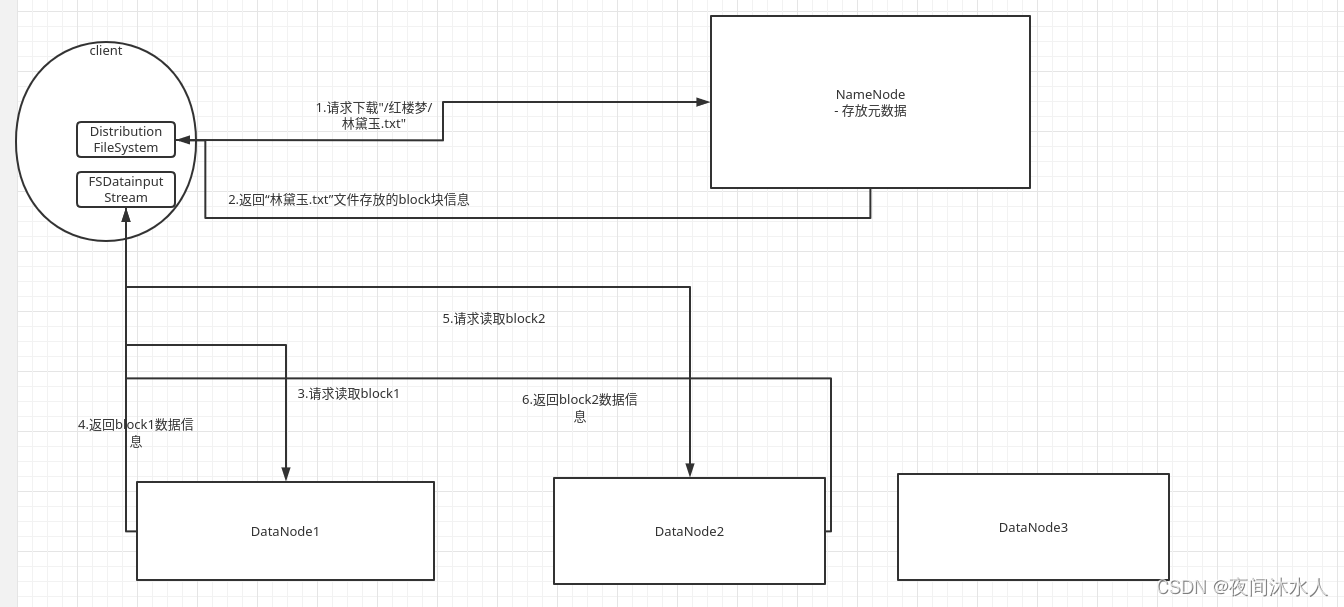
1���ͻ���ͨ��Distributed FileSystem��NN���������ļ�����,��������"/��¥��/������.txt"��
2�� NN���ܵ�����1��,����ļ��Ƿ�����ϴ�,����ͨ����ѯԪ������Ϣ,�ҵ����ļ���Ԫ����,�������е�block�����Ϣ���ڵ�DNλ����Ϣ,������ء�
- ����Ƿ���Ȩ�������ļ���
- ����ļ�Ŀ¼���Ƿ���ڡ�
3���ͻ��˿�ʼ��DN(�ͽ�ԭ��ѡ��һ��DN)���������ļ�������,DN�ӱ����ļ�ϵͳ��ȡ�ļ���Ϣ��,��packetΪ��λ���ظ��ͻ��ˡ�
ע��:��ΪNN���ص���Ԫ����,��ô�ͻ���Ҳ����������ȡָ��λ�õ��ļ���Ϣ,Ҳ��˵,�ͻ���A���Զ�ȡblock1����Ϣ,�ͻ���B���Զ�ȡblock2����Ϣ,���ȡ�����е���Ϣ���л���,��ôҲ�ܵõ������ļ�����Ϣ,����������һ�����ε�˼��,Ҳ��֧�ֲַ�ʽ����ĺ��ġ�
��������:
1.hadoop��Ⱥ������,jps�������е�nodemanager��û����ʾ,�鿴nodemanager��־,�������±���,ԭ����yarn.nodemanager.aux-services��ֵ�ڸ߰汾��Hadoop��ֻ�ܰ���a-zA-Z0-9_,���������ֿ�ͷ,��Ϊmapreduce_shuffle
2021-12-12 01:36:37,592 INFO org.apache.hadoop.service.AbstractService: Service NodeManager failed in state INITED
java.lang.IllegalArgumentException: The ServiceName: mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid.The valid service name should only contain a-zA-Z0-9_ and can not start with numbers
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:141)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:146)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:323)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:519)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:977)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1057)
2.ִ�йٷ��ṩ��wordcountʱ,�������´�����ʾ,ԭ��etc/hadoop/mapred-site.xml�ļ�����Ҫ����hadopp�ĸ�Ŀ¼��������Ϣ�г��������������ӵ�etc/hadoop/mapred-site.xml�м��ɡ�
[2021-12-12 01:53:05.088]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=
f
u
l
l
p
a
t
h
o
f
y
o
u
r
h
a
d
o
o
p
d
i
s
t
r
i
b
u
t
i
o
n
d
i
r
e
c
t
o
r
y
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
m
a
p
r
e
d
u
c
e
.
m
a
p
.
e
n
v
<
/
n
a
m
e
>
<
v
a
l
u
e
>
H
A
D
O
O
P
M
A
P
R
E
D
H
O
M
E
=
{full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=
fullpathofyourhadoopdistributiondirectory</value></property><property><name>mapreduce.map.env</name><value>HADOOPM?APREDH?OME={full path of your hadoop distribution directory}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
[2021-12-12 01:53:05.088]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
3.namende��datanodeͬʱֻ������һ��
ԭ����namenode�һ�֮��,ֱ�Ӹ�ʽ��format��������namenode����Ϊnamenode��һformat֮������ɼ�ȺID,�ٴθ�ʽ���������µļ�ȺID,����datanode�еļ�ȺID����������namenode�м�ȺID��һ�¡�
�������:�����еĽڵ���ɾ��datanode�����е���Ϣ(Ĭ����tempĿ¼��,�������������,��ô���ڶ�Ӧ��Ŀ¼��ȫ��ɾ��),Ȼ����format namenode��
�ܽ�
�������ؽ�����HDFS��һЩ�����Լ�dz�Ե�˵������HDFS�ڴ洢����ʱ��һЩ����ԭ����