Kafka�����������Ӧ��
kafka�Ľ���
Kafka ��������һ�� MQ(Message Queue),ʹ����Ϣ���еĺô�?
- ����:�������Ƕ�������չ���Ķ������ߵĴ������̡�
- �ɻָ���:��ʹһ��������Ϣ�Ľ��̹ҵ�,��������е���Ϣ��Ȼ������ϵͳ�ָ�������
- ����:�����ڽ��������Ϣ��������Ϣ�Ĵ����ٶȲ�һ�µ������
- �����&��ֵ��������:������Ϊͻ���ij����ɵ��������ȫ����,��Ϣ�����ܹ�ʹ�ؼ������
סͻ���ķ���ѹ����
�첽ͨ��:��Ϣ���������û�����Ϣ������е���������������
����Ӧ��: ԭ����
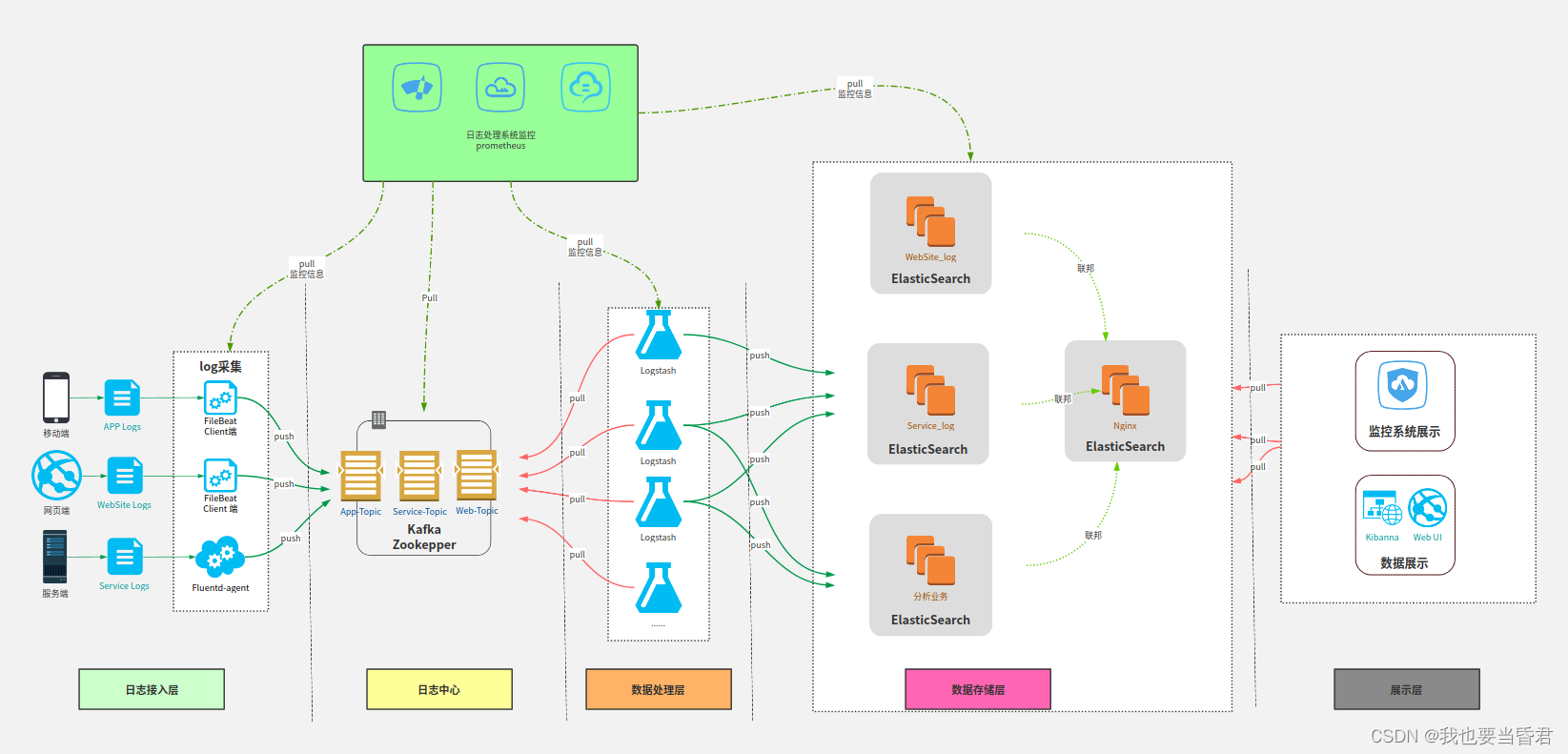 Logstash��һ����Դ�����ռ�����,����ʵʱ�ܵ����ܡ�Logstash���Զ�̬�ؽ����Բ�ͬ����Դ������ͳһ����,�������ݱ���������ѡ���Ŀ�ĵ�
Logstash��һ����Դ�����ռ�����,����ʵʱ�ܵ����ܡ�Logstash���Զ�̬�ؽ����Բ�ͬ����Դ������ͳһ����,�������ݱ���������ѡ���Ŀ�ĵ�
Elasticsearch ��һ���ֲ�ʽ��RESTful ?������������ݷ�������,�ܹ��������ӿ�ֳ��ĸ���������
��Ϊ Elastic Stack �ĺ���,�����д洢��������,��������������֮���Լ�����֮��������
�ܹ�
ע��:����ԭ������û�л���zookeeper, broker������zookeeper������
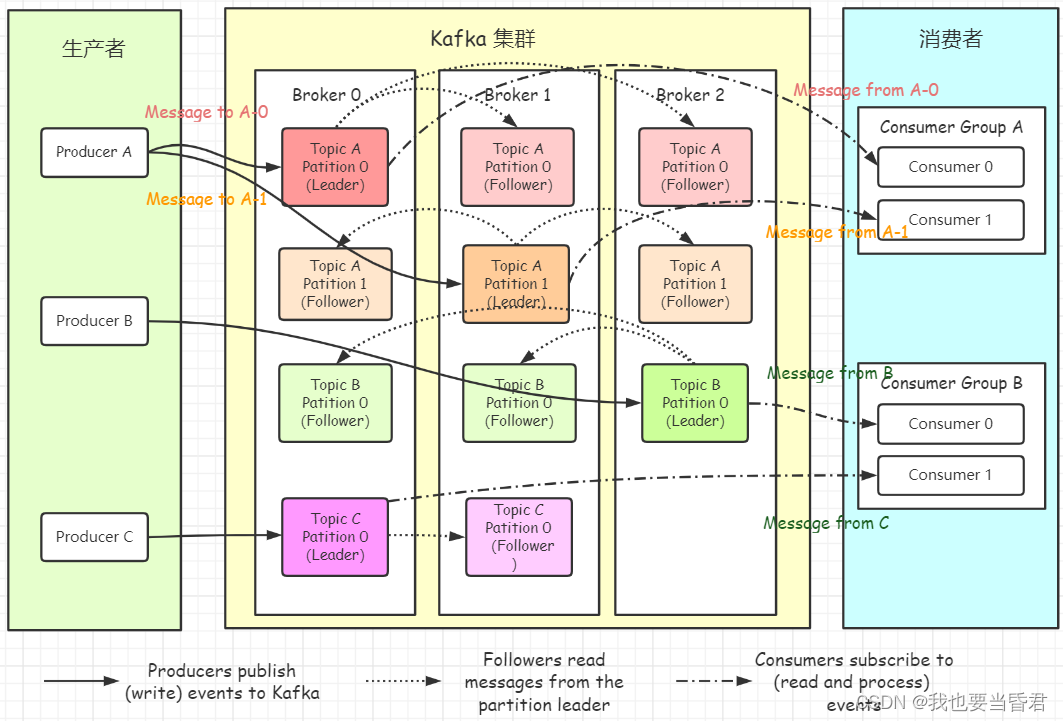
Kafka �洢����Ϣ��������౻��Ϊ Producer �����ߵĽ��̡����ݴӶ����Ա���������ͬ��Topic �����µIJ�ͬ Partition ������
��һ��������,��Щ��Ϣ����������ͬʱ����洢��һ����������Ϊ Consumer �����ߵĽ��̿��Դӷ���������Ϣ��
Kafka ������һ����һ̨���̨��������ɵļ�Ⱥ��,���ҷ������Կ缯Ⱥ���ֲ���
������� Kafka һЩ��Ҫ����,�ô�Ҷ� Kafka �и��������ʶ��֪,���滹����ϸ�Ľ���ÿһ������������Լ��������ԭ��:
- Producer:��Ϣ������,�� Kafka Broker ����Ϣ�Ŀͻ��ˡ�
- Consumer:��Ϣ������,�� Kafka Broker ȡ��Ϣ�Ŀͻ��ˡ�
- Consumer Group:��������(CG),����������ÿ�������߸������Ѳ�ͬ����������,�������������һ������ֻ��������һ������������,��������֮�以��Ӱ�졣���е������߶�����ij����������,���������������ϵ�һ�������ߡ�
- Broker:һ̨ Kafka ��������һ�� Broker��һ����Ⱥ( kafka cluster )�ɶ�� Broker ��ɡ�һ�� Broker �������ɶ�� Topic��
- Topic:��������Ϊһ������,Topic ����Ϣ����,�����ߺ��������������ͬһ�� Topic��
- Partition:Ϊ��ʵ����չ��,��߲�������,һ���dz���� Topic ���Էֲ������ Broker(��������)��,һ�� Topic ���Է�Ϊ��� Partition, ͬһ��topic�ڲ�ͬ�ķ����������Dz��ظ���, ÿ�� Partition ��һ������Ķ���,�� ������ʽ����һ��һ�����ļ��� ��
- Replication : ÿһ���������ж������,����������������̥����������(Leader)���ϵ�ʱ���ѡ��һ����̥(Follower)��λ,��ΪLeader����kafka��Ĭ�ϸ��������������10��,�Ҹ������������ܴ���Broker������,follower��leader�������ڲ�ͬ�Ļ���,ͬһ������ͬһ������Ҳֻ���ܴ��һ������(�����Լ�)��
- Message:ÿһ�����͵���Ϣ���塣
- Leader:ÿ��������������ġ���������,�����߷������ݵĶ���,�Լ��������������ݵĶ���,���� Leader��
- Follower:ÿ��������������ġ��ӡ�����,ʵʱ�� Leader ��ͬ������,���ֺ� Leader ���ݵ�ͬ����Leader ��������ʱ,ij�� Follower �����Ϊ�µ� Leader��
- Offset:���������ѵ�λ����Ϣ,����������ѵ�ʲôλ��,�������߹ҵ������»ָ���ʱ��,���Դ�����λ�ü������ѡ�
- ZooKeeper:Kafka ��Ⱥ�ܹ���������,��Ҫ������ ZooKeeper,ZooKeeper ���� Kafka�洢������Ⱥ��Ϣ��
��������
Kafka��Ⱥ�� Record ���洢�ڳ�Ϊ Topic �������,ÿ����¼��һ������һ��ֵ��һ��ʱ�����ɡ�
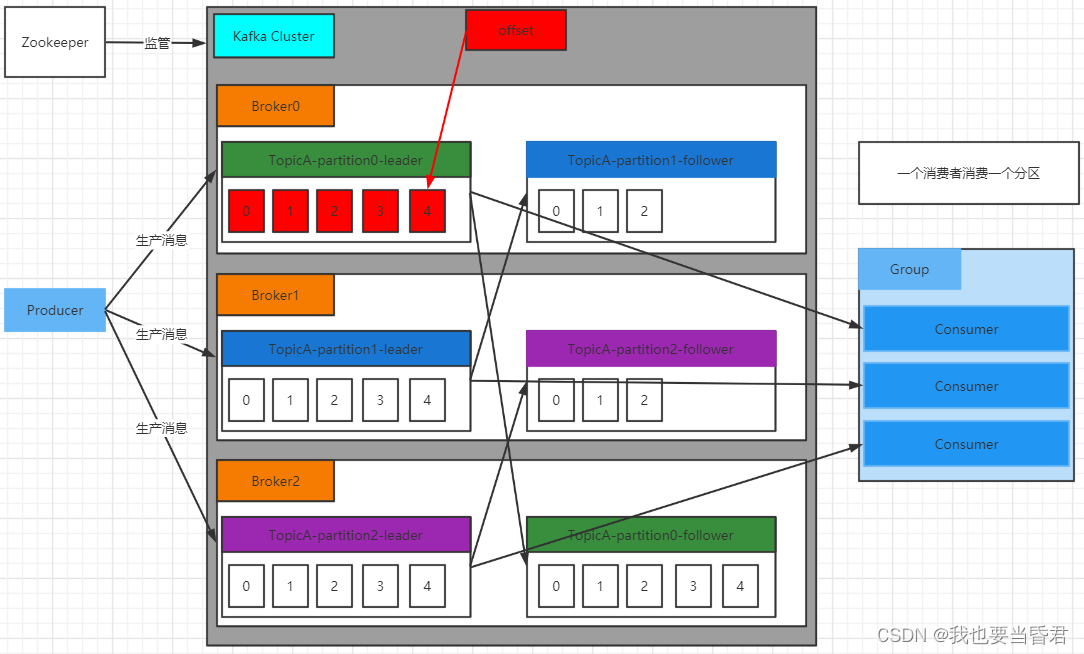 Kafka ��һ���ֲ�ʽ��ƽ̨,�����ʲô��˼?
Kafka ��һ���ֲ�ʽ��ƽ̨,�����ʲô��˼?
- �����Ͷ��ļ�¼��,��������Ϣ���л���ҵ��Ϣ����ϵͳ��
- ���ݴ��ij־÷�ʽ�洢��¼����
- ������¼����
Kafka ����Ϣ���� Topic ���з����,������������Ϣ,������������Ϣ,����Ķ���ͬһ��Topic��
Topic �����ϵĸ���,�� Partition �������ϵĸ���,ÿ�� Partition ��Ӧ��һ�� log �ļ�,��log �ļ��д洢�ľ��� Producer ���������ݡ�
Producer ���������ݻ���ӵ��� log �ļ�ĩ��,��ÿ�����ݶ����Լ��� Offset��
���������е�ÿ��������,����ʵʱ��¼�Լ����ѵ����ĸ� Offset,�Ա�����ָ�ʱ,���ϴε�λ�ü������ѡ�
��־Ĭ����: /tmp/kafka-logs
�洢����
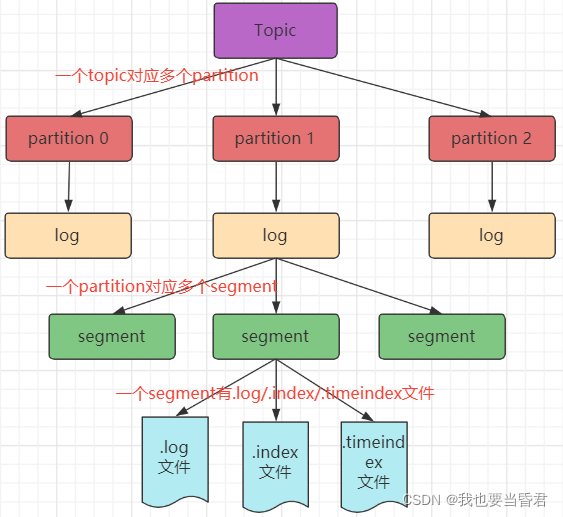 ������������������Ϣ����ӵ� log �ļ�ĩβ,Ϊ��ֹ log �ļ����������ݶ�λЧ�ʵ���,Kafka ��ȡ�˷�Ƭ���������ơ�
������������������Ϣ����ӵ� log �ļ�ĩβ,Ϊ��ֹ log �ļ����������ݶ�λЧ�ʵ���,Kafka ��ȡ�˷�Ƭ���������ơ�
����ÿ�� Partition ��Ϊ��� Segment,ÿ�� Segment ��Ӧ�����ļ�:��.index�� �����ļ��͡�.log�� �����ļ���
��Щ�ļ�λ��ͬһ�ļ���,���ļ��е���������Ϊ:topic ��-�����š�����,test��� topic �����ַ���,�����Ӧ���ļ���Ϊ test-0,test-1,test-2��
ls /tmp/kafka-logs/test-1
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
leader-epoch-checkpoint
index �� log �ļ��Ե�ǰ Segment �ĵ�һ����Ϣ�� Offset ��������ͼΪ index �ļ��� log �ļ�
�Ľṹʾ��ͼ:
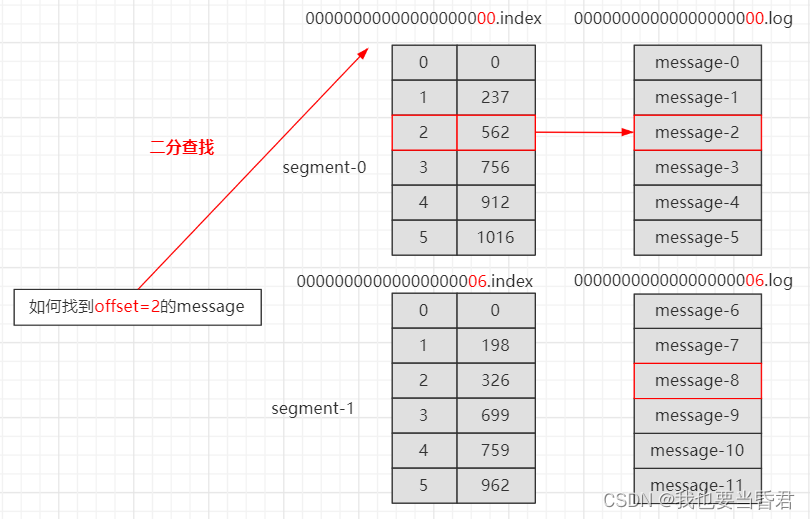 ��.index�� �ļ��洢������������Ϣ,��.log�� �ļ��洢����������,�����ļ��е�Ԫ����ָ���Ӧ�����ļ��� Message ������ƫ������
��.index�� �ļ��洢������������Ϣ,��.log�� �ļ��洢����������,�����ļ��е�Ԫ����ָ���Ӧ�����ļ��� Message ������ƫ������
�鿴����:./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index
������
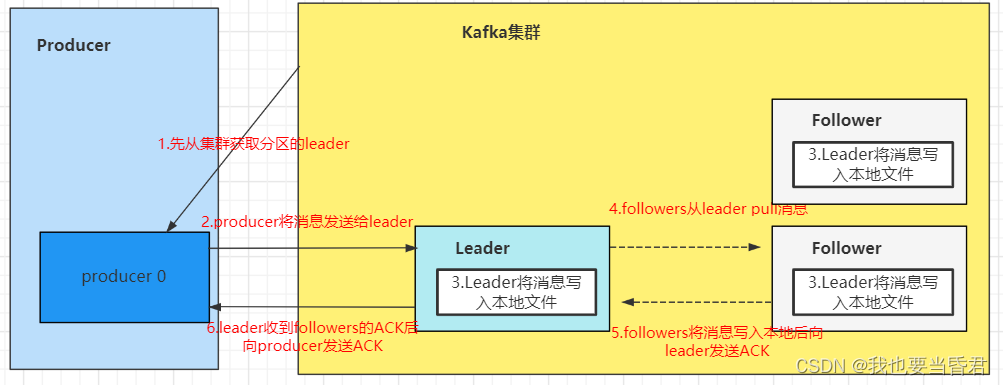
producer����������,�����ݵ���ڡ�Producer��д�����ݵ�ʱ����Զ����leader,����ֱ�ӽ�����д��follower��
��������
����ԭ��:
- �����ڼ�Ⱥ����չ,ÿ�� Partition ����ͨ����������Ӧ�����ڵĻ���,��һ�� Topic �ֿ����ж�� Partition ���,��˿����� Partition Ϊ��λ��д�ˡ�
- ������߲���,��˿����� Partition Ϊ��λ��д�ˡ�
����ԭ��:������Ҫ�� Producer ���͵����ݷ�װ��һ�� ProducerRecord ����
�ö�����Ҫָ��һЩ����:
- topic:string ����,NotNull��
- partition:int ����,��ѡ��
- timestamp:long ����,��ѡ��
- key:string ����,��ѡ��
- value:string ����,��ѡ��
- headers:array ����,Nullable��
ָ�� Partition �������,ֱ�ӽ������� Value ��Ϊ Partition ��ֵ��
û��ָ�� Partition ���� Key �������,�� Key �� Hash ֵ�������ȡ��õ� Partition ֵ��
��û�� Partition ��û�� Key �������,��һ�ε���ʱ�������һ������(����ÿ�ε��ö����������������),�����ֵ����õķ�����ȡ��,�õ� Partition ֵ,Ҳ���dz�˵�� Round-Robin��ѯ�㷨��
���ݿɿ��Ա�֤
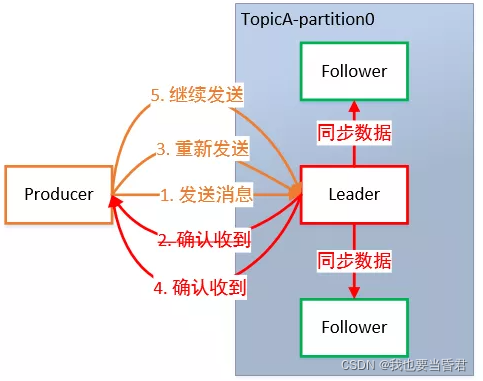
Ϊ��֤ Producer ���͵�����,�ܿɿ��ط��͵�ָ���� Topic,Topic ��ÿ�� Partition �յ�Producer ���͵����ݺ�,����Ҫ�� Producer ���� ACK(ACKnowledge ȷ���յ�)����� Producer �յ� ACK,�ͻ������һ�ֵķ���,�������·������ݡ�
��������ͬ������
��ʱ���� ACK?ȷ���� Follower �� Leader ͬ�����,Leader �ٷ��� ACK,�������ܱ�֤Leader �ҵ�֮��,���� Follower ��ѡ�ٳ��µ� Leader ���������ݡ�
���ٸ� Follower ͬ����ɺ��� ACK?ȫ�� Follower ͬ�����,�ٷ��� ACK��
| ���� | �ŵ� | ȱ�� |
|---|---|---|
| �����������ͬ��,�ͷ���ack | �ӳٵ� | ѡ���µ�leaderʱ,����n̨�ڵ����,��Ҫ2n+1�������� |
| ȫ�����ͬ��,�ŷ���ack | ѡ���µ�leaderʱ,����n̨�ڵ����,��Ҫn+1�������� | �ӳٸߡ� |
ISR
���õڶ��ַ���,���� Follower ���ͬ��,Producer ���ܼ�����������,������һ�� Follower��Ϊij��ԭ����ֹ���,�� Leader ��Ҫһֱ�ȵ������ͬ����
���������ô���?Leaderά����һ����̬�� in-sync replica set(ISR):�� Leader ����ͬ���� Follower ���ϡ�
�� ISR �����е� Follower ������ݵ�ͬ��֮��,Leader �ͻ�� Follower ���� ACK��
��� Follower ?ʱ��δ�� Leader ͬ������,��� Follower �����߳� ISR ����,��ʱ����ֵ��replica.lag.time.max.ms �����趨��Leader �������Ϻ�,�ͻ�� ISR ��ѡ�ٳ��µ� Leader��
ACK Ӧ�����
����ijЩ��̫��Ҫ������,�����ݵĿɿ���Ҫ���Ǻܸ�,�ܹ��������ݵ�������ʧ,����û��Ҫ�� ISR �е� Follower ȫ�����ܳɹ���
���� Kafka Ϊ�û��ṩ�����ֿɿ��Լ���,�û����ݿɿ��Ժ��ӳٵ�Ҫ�����Ȩ��,ѡ�����µ����á�

ACK ��������:
- 0:Producer ���ȴ� Broker �� ACK,���ṩ������ӳ�,Broker һ�յ����ݻ�û��д����̾��Ѿ�����,�� Broker ����ʱ�п��ܶ�ʧ���ݡ�
- 1:Producer �ȴ� Broker �� ACK,Partition �� Leader ���̳ɹ��� ACK,�����Follower ͬ���ɹ�֮ǰ Leader ����,��ô���ᶪʧ���ݡ�
- -1(all):Producer �ȴ� Broker �� ACK,Partition �� Leader �� Follower ȫ�����̳ɹ���ŷ��� ACK�������� Broker ���� ACK ʱ,Leader ��������,�����������ظ���
�ɿ���ָ��
û��һ���м���ܹ������ٷ�֮�ٵ���ȫ�ɿ�,�ɿ��Ը���Ļ��ǻ��ڼ���9�ĺ���ָ��,����4��9��5��9������ϵͳ�Ŀɿ���ֻ�ܹ�����ȥ�ӽ�100%,�������ܴﵽ100%������kafka�����ʵ�������ܵĿɿ�����?
- ��������,����Դ�������ķ����������ɿ���,���Ƿ���������Ҳ����������ϵĿ���,һ����˵,3��������������Դֳ����Ŀɿ���Ҫ��
- acks,�����߷�����Ϣ�Ŀɿ���,Ҳ������Ҫ��֤�������Ϣһ���ǵ���broker��������˶ั���ij־û�,������Ҫ��Ҳͬ������������ϵĿ��������м�����ѡ��
- 1,�����߰���Ϣ���͵�leader����,leader�����ڳɹ�д�뵽������־֮�������������Ϣ�ύ�ɹ�,�������isr�����е�follower������û���ü�ͬ��leader��������Ϣ,leader����,�ͻ������Ϣ��ʧ
- -1,��Ϣ������д�뵽leader����,���ұ�ISR���������и���ͬ�����֮��Ÿ����������Ѿ��ύ�ɹ�,���ʱ��ʹleader��������Ҳ����������ݶ�ʧ��
- 0:��ʾproducer����Ҫ�ȴ�broker����Ϣȷ�ϡ����ѡ��ʱ����С��ͬʱ?�����(��Ϊ��server崻�ʱ,���ݽ��ᶪʧ)�� - ������Ϣ����broker֮��,������Ҳ��Ҫ��һ���ı�֤,��Ϊ������Ҳ���ܳ���ijЩ�������Ϣû�����ѵ���
- enable.auto.commitĬ��Ϊtrue,Ҳ�����Զ��ύoffset,�Զ��ύ������ִ�е�,��һ��ʱ�䴰��,���ַ�ʽ������ظ��ύ������Ϣ��ʧ������,���Զ��ڸ߿ɿ���Ҫ��ij���,Ҫʹ���ֶ��ύ�� ���ڸ߿ɿ�Ҫ���Ӧ����˵,��Ը�ظ�����Ҳ��Ӧ����Ϊ�����쳣��������Ϣ��ʧ��
������
���ѷ�ʽ
Consumer ���� Pull(��ȡ)ģʽ�� Broker �ж�ȡ���ݡ�
Pull ģʽ����Ը��� Consumer �������������ʵ�������������Ϣ��Pull ģʽ����֮����,���Kafka û������,�����߿��ܻ�����ѭ����,һֱ���ؿ����ݡ�
��Ϊ�����ߴ� Broker ������ȡ����,��Ҫά��һ��?��ѯ,�����һ��, Kafka ������������������ʱ�ᴫ��һ��ʱ?���� timeout��
�����ǰû�����ݿɹ�����,Consumer ��ȴ�һ��ʱ��֮���ٷ���,���ʱ?��Ϊ timeout��
�����������
һ�� Consumer Group ���ж�� Consumer,һ�� Topic �ж�� Partition,���Ա�Ȼ���漰��Partition �ķ�������,��ȷ���ĸ� Partition ���ĸ� Consumer �����ѡ�
Kafka �����ַ������:
- RoundRobin
- Range,Ĭ��ΪRange
- Sticky
�����������������߷����仯ʱ,�ᴥ�������������(�������·���)��
������Ҫ��Range��RoundRobin��
Range(Ĭ�ϲ���)
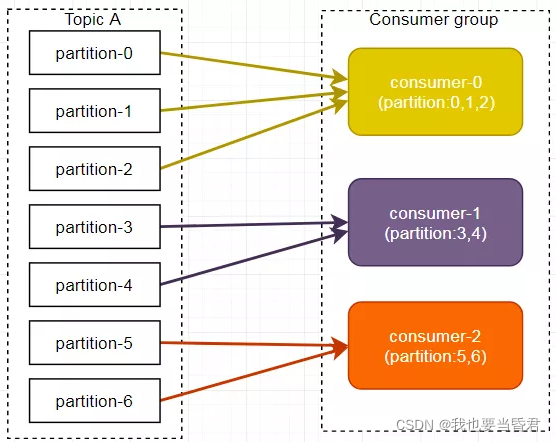 Range ��ʽ�ǰ����������ֵ�,���������ѯ��ʽ�����ѻ������⡣
Range ��ʽ�ǰ����������ֵ�,���������ѯ��ʽ�����ѻ������⡣
����������10������,3��������,������ķ���������0,1,2,3,4,5,6,7,8,9;�������߳���������C1-0,C2-0,C3-0��Ȼ��partitions�ĸ��������������̵߳�����������ÿ���������߳����Ѽ������������������,��ôǰ�漸���������߳̽��������һ�������������ǵ���������,������10���� ��,3���������߳�, 10/3 = 3,���ҳ�����,��ô�������߳� C1-0���������һ������
�����������������:
C1-0 ������ 0, 1, 2, 3 ����
C2-0������ 4,5,6����
C3-0������ 7,8,9����
����������11������,��ô����������Ľ����������������:
C1-0������ 0,1,2,3����
C2-0������ 4,5,6,7����
C3-0 ������ 8, 9, 10 ����
����������2������(T1��T2),�ֱ���10������,��ô����������Ľ����������������:
C1-0 ������ T1����� 0, 1, 2, 3 �����Լ� T2����� 0, 1, 2, 3����
C2-0������ T1����� 4,5,6�����Լ� T2����� 4,5,6����
C3-0������ T1����� 7,8,9�����Լ� T2����� 7,8,9����
���Կ���,C1-0 �������̱߳������������̶߳�������2������,�����Range strategy��һ�������Եı�
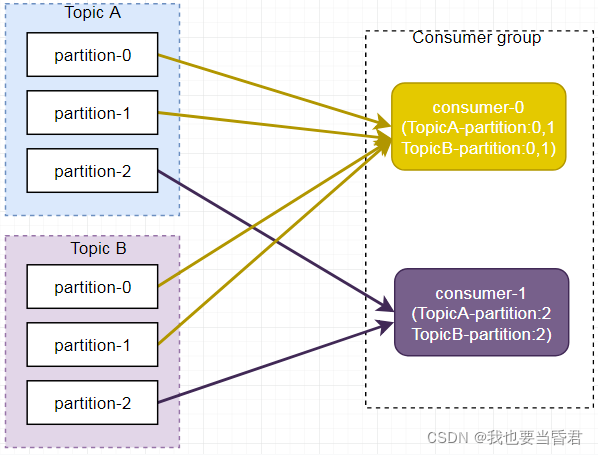
����,����ͼ��ʾ,Consumer0��Consumer1 ͬʱ���������� A �� B,���������Ϣ���䲻�Ե�����,�����������ڶ��ĵ�����Խ��,�����������Խ�����⡣
 RoundRobin
RoundRobin
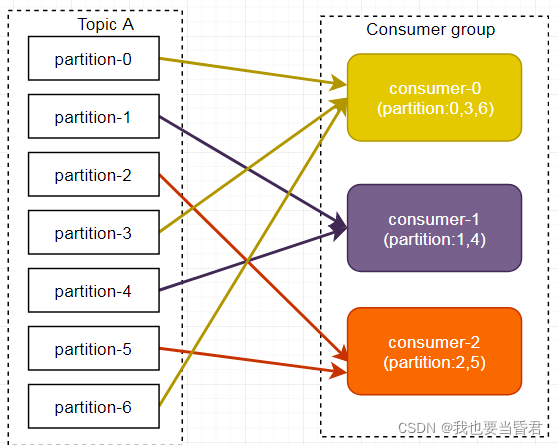 RoundRobin ��ѯ��ʽ������������Ϊһ��������� Hash ����,���������ڷ���������������Ϊ 1,�ǰ��������ֵ�,���Խ������������������ݲ���������⡣
RoundRobin ��ѯ��ʽ������������Ϊһ��������� Hash ����,���������ڷ���������������Ϊ 1,�ǰ��������ֵ�,���Խ������������������ݲ���������⡣
��ѯ���������ǰ�����partition������consumer�̶߳��г���,Ȼ����hashcode�����������ͨ����ѯ�㷨����partition�������̡߳��������consumerʵ���Ķ�������ͬ��,��ôpartition����� �ֲ���
�����ǵ���������,���簴�� hashCode�������topic-partitions������ΪT1-5,T1-3,T1-0,T1-8,T1-2,T1-1,T1-4,T1-7,T1-6,T1-9,���ǵ��������߳�����ΪC1-0,C1-1,C2-0,C2-1,����������Ľ��Ϊ:
C1-0������ T1-5,T1-2,T1-6����;
C1-1������ T1-3,T1-1,T1-9����;
C2-0������ T1-0,T1-4����;
C2-1������ T1-8,T1-7����;
����,�����������ڶ��IJ�ͬ����ʱ,����������ѻ���,����ͼ��ʾ,Consumer0 ��������A,Consumer1 �������� B��
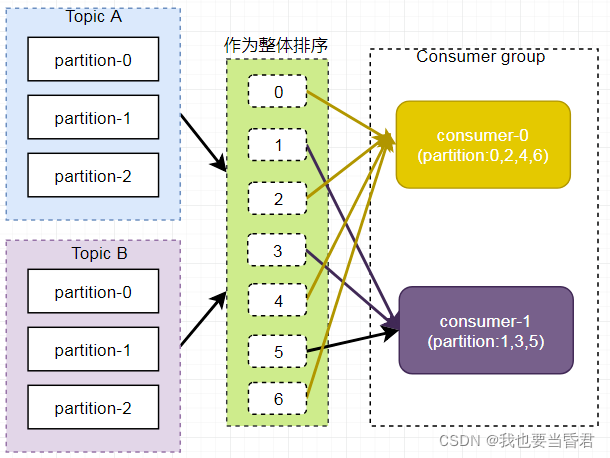 �� A��B ����ķ��������������������,TopicB �����е����ݿ��ܷ��䵽 Consumer0 �С�
�� A��B ����ķ��������������������,TopicB �����е����ݿ��ܷ��䵽 Consumer0 �С�
ʹ����ѯ�������Ա���������������
- ÿ�������������ʵ��������ͬ��������
- ÿ�������߶��ĵ������������ͬ��
kafka��������
��װJava����
����linux�µİ�װ��
��½��ַ: link.
 ������ɺ�,LinuxĬ������λ���ڵ�ǰĿ¼�µ�Download�������ļ�����,ͨ������cd ~/Downloads��cd ~/���ؼ��ɲ鿴����Ӧ���ļ���
������ɺ�,LinuxĬ������λ���ڵ�ǰĿ¼�µ�Download�������ļ�����,ͨ������cd ~/Downloads��cd ~/���ؼ��ɲ鿴����Ӧ���ļ���
��ѹ��װ��jdk-8u202-linux-x64.tar.gz
tar -zxvf jdk-8u291-linux-x64.tar.gz
��ѹ����ļ���Ϊjdk1.8.0_291
�����ļ��кͲ鿴�ļ�
cd jdk1.8.0_291
ls
���Կ���binĿ¼

����ѹ����ļ��Ƶ�/usr/libĿ¼��
��/usr/binĿ¼���½�jdkĿ¼
sudo mkdir /usr/lib/jdk
����ѹ��jdk�ļ��ƶ����½���/usr/lib/jdkĿ¼����
sudo mv jdk1.8.0_291 /usr/lib/jdk/
ִ�������ɵ� usr/lib/jdk Ŀ¼�²鿴�Ƿ��ƶ��ɹ���
����java��������
�����ǽ���������������etc/profile,��Ϊ�����û�����JDK������
ʹ�������/etc/profile�ļ�
sudo vim /etc/profile
��ĩβ�������¼�������:
#set java env
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_291
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

ִ������ʹ��������Ч
���ն�����,���ְ汾��˵����װ�ɹ���
java -version
Kafka�İ�װ����
����kafka
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
��װkafka
�������ص�kafka���Ѿ�����õij���,ֻ��Ҫ��ѹ���ɵõ�ִ�г���
tar -zxvf kafka_2.11-2.0.0.tgz
����kafkaĿ¼,�Լ��鿴��Ӧ���ļ���Ŀ¼
cd kafka_2.11-2.0.0
ls
 bin:Ϊִ�г���
bin:Ϊִ�г���
config:Ϊ�����ļ�
libs:Ϊ���ļ�
���ú�����zookeeper
���ص�kafka�������Դ���zookeeper,kafka�Դ���Zookeeper����ű��������ļ�����ԭ��Zookeeper���в�ͬ��
kafka�Դ���Zookeeper����ʹ��bin/zookeeper-server-start.sh,�Լ�bin/zookeeper-server-stop.sh��������ֹͣZookeeper��
kafka������zookeeper����masterѡ��һ���������ݵ�ά����
- ����zookeeper:zookeeper-server-start.sh
- ֹͣzookeeper:zookeeper-server-stop.sh
��configĿ¼��,����һЩ�����ļ�
zookeeper.properties
server.properties
�������ǿ���ͨ������Ľű�������zk����,��Ȼ,Ҳ�����Լ������zk�ļ�Ⱥ��ʵ�֡���������ֱ��ʹ��kafka�Դ���zookeeper��
����zookeeper
sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
Ĭ�϶˿�Ϊ:2181,����ͨ������lsof -i:2181 �鿴zookeeper�Ƿ������ɹ���
������ֹͣkafka
- ��server.properties(��configĿ¼), ����zookeeper������
zookeeper.connect=localhost:2181
- ����kafka
sh kafka-server-start.sh -daemon ../config/server.properties
Ĭ�������˿�9092
- ֹͣkafka
sh kafka-server-stop.sh -daemon ../config/server.properties
kafka�Ļ�������
����topic
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Replication-factor ��ʾ��topic��Ҫ�ڲ�ͬ��broker�б��漸��,�������ó�1,��ʾ������broker�б�������Partitions������
�鿴topic
sh kafka-topics.sh --list --zookeeper localhost:2181
�鿴topic����
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
������Ϣ
sh kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning
������Ϣ
sh kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
kafka-topics.sh ʹ�÷�ʽ
Χ�ƴ������ġ�ɾ���Լ��鿴�ȹ��ܡ�
�鿴�����Chelp
/binĿ¼�µ�ÿһ���ű�����,�������ڶ�IJ���ѡ��,��������������ǵ�ס,��Щ�ű�������ʹ
�� --help ��������ӡ�г�������IJ�����Ϣ��
$ sh kafka-topics.sh --help
����������ѡ����ʹ����ΪƵ������Ҫ�IJ�������˵��,�Լ�����һЩ�ӽ��б�����
�����������ܴ���broker������
kafka ���������ʱ���丱���������ܴ���broker������,�������� topic ʧ��.
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic test1
��������Ccreate
��������ʱ��,��3�������DZ����,�ֱ��� --partitions(��������)�� --topic(������) �� --replication-factor(����ϵ��), ͬʱ����ʹ�� --create �����������β�������Ҫ����һ�����������
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
����:
Created topic ��test1��.
��ʱ���� test1 ���Ѿ������ˡ������ڴ��������ʱ��,�����Ը�����������ѡ��:�Cif-not-exists �ͨCif-exists . ��һ�������������������ⲻ����ʱ��,����; �ڶ��������������Ļ�ɾ���������ʱ��,���ڸ�������ڵ�ʱ��ȥִ�в�����
�鿴broker�����е����� --list
sh kafka-topics.sh --list --zookeeper localhost:2181
����:test1
����test1��Ϊ���Ǵ��������⡣
�鿴ָ������ topic ����ϸ��Ϣ --describe
�ò����Ὣ�������������Ϣһһ�г���ӡ����,�����������������ϵ�����쵼�ߵȴ���
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic test1
����:
Topic:test1 PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test1
Partition: 0
Leader: 0 Replicas: 0
Isr: 0
��������Ϣ --alter(���������������)
sh kafka-topics.sh --zookeeper localhost:2181 --topic test1 --alter -- partitions 2
WARNING: If partitions are increased for a topic that has a key, the
partition logic or ordering of the messages will be affected
Adding partitions succeeded!
���Կ����Ѿ��ɹ��Ľ�����ķ���������1��Ϊ��2��
**���ȥ��һ�������ڵ�topic��Ϣ����ô��?**���������� test2,��ǰ�������Dz����ڵġ�
sh kafka-topics.sh --zookeeper localhost:2181 --topic test2 --alter --
partitions 2
Error while executing topic command : Topic test2 does not exist on ZK path
localhost:2181
[2021-07-12 17:28:59,253] ERROR java.lang.IllegalArgumentException: Topic
test2 does not exist on ZK path localhost:2181
at kafka.admin.TopicCommand$.alterTopic(TopicCommand.scala:123)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:65)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
ע��:��Ҫʹ�� --alter ȥ���Լ��ٷ���������,�����Ҫ���ٷ���������,ֻ��ɾ����������topic, Ȼ�����´���
ɾ������ topic --delete
sh kafka-topics.sh --zookeeper localhost:2181 --delete --topic test1
Topic test1 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
��־��Ϣ��ʾ,���� test1�Ѿ������ɾ��״̬,������delete.topic.enable û������Ϊ true , ��
�������κ����á�
����������:sh kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test1
����������:sh kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test1 --from-beginning
���ִ�ʱ���ǿ��Է�����Ϣ�ͽ�����Ϣ��
���Ҫ֧���ܹ�ɾ������IJ���,����Ҫ�� /bin ��ͬ��Ŀ¼ /configĿ¼�µ��ļ�server.properties
��,������delete.topic.enable=true(�����Ϊfalse,��kafka broker �Dz�����ɾ�������)��

��Ҫserver.properties������delete.topic.enable=true����ֻ�DZ��ɾ������ֱ��������
����kafka
ֹͣ:sh kafka-server-stop.sh -daemon ��/config/server.properties
����:sh kafka-server-start.sh -daemon ��/config/server.properties
�ٴ�ɾ��
sh kafka-topics.sh --zookeeper localhost:2181 --delete --topic test1
�ο�
2����?��������� Kafka,��Դ�뵽�ܹ�ȫ����
https://mp.weixin.qq.com/s/dOiNT0a_dRytwatzdrJNCg
Kafka ��־�洢
https://zhuanlan.zhihu.com/p/65415304
���IJ��ּ��������,C/C++Linux����������/��̨�ܹ�ʦ:https://ke.qq.com/course/417774?flowToken=1041622