本文原载于我的博客:https://ziyang.moe/article/mapreducepaper.html
前言
MapReduce,是 Google 早年提出了一种软件架构模型,支持大规模数据集的并行运算。现在这个概念被运用在大量分布式系统中。
相关的理论由 Google 在 2004 年发表在论文《MapReduce: Simplified Data Processing on Large Clusters》中,可以在这里阅读全文。13 页的小论文,信息密度比某些小论文不知道高到哪里去了。
由于本文是边阅读论文边记录下来的笔记,所以内容可能比较混乱。
编程模型
MapReduce 是一个很简单的并行处理模型,使用 MapReduce 框架,用户只需要指定两个函数:
- Map 函数,负责将一个键值对处理成一系列中间键值对
- Reduce 函数,负责将所有具有相同 key 的中间值合并
剩下的,就由框架自行处理,包括数据分发、任务分发、错误处理、负载均衡等等细节。用户无需掌握这些细节,更能关注于业务逻辑。
一个大致的处理流程是这样的:
Map 接受一个输入键值对,产生一系列中间键值对。MapReduce 框架将所有具有相同的中间 key 的中间值组织到一起,传递给 Reduce 函数。Reduce 函数,接收一个中间 key 和一系列中间值,函数通常将这些值聚合成一个较小的集合,有时每次 Reduce 函数调用只会产生一个结果值,甚至不产生结果。
以大规模文本单词计数为例:
map(String key, String value):
// key:文章名称
// value:文章内容
for 单词 w in value:
增加中间计数(w, "1")
reduce(String key, Iterator values):
// key:一个单词
// value:一系列计数
int result = 0;
for v in values:
result += ParseInt(v);
输出(ToString(result))
实现
执行流程
MapReduce 作为一种编程模型或者说编程思想,实现方式可以有很多。Google 在论文中给出了一种实现方法,用于局域网内互相连接的大量机器。执行流程如下图:
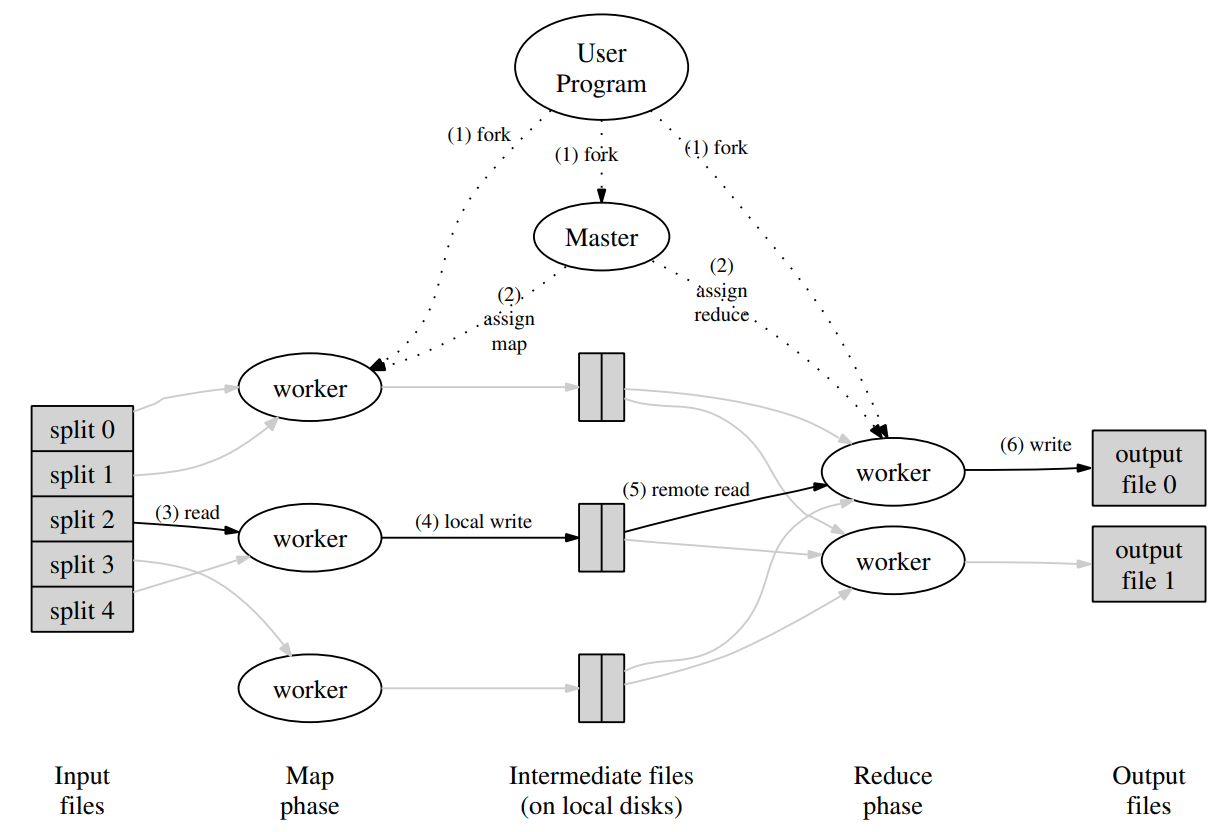
- MapReduce 框架首先将输入文件划分为 M 片,每片通常为 16MB 到 64MB 大小。随后会启动集群中的机器(进程)。
- 集群中的一个进程是一个特殊的 master 进程。剩余的 worker 进程都由 master 分配任务。一共有 M 个 map 任务和 R 个 reduce 任务需要分配。master 会挑选空闲的 worker,一次分配一个 map 任务或者一个 reduce 任务。
- 被分配到 map 任务的 worker 读入对应分片的输入,从输入中解析出键值对,并分别将其传给用户定义的 map 函数。map 函数返回的中间键值对会被暂时缓存在内存里。
- worker 内存中缓存的键值对,会被分片函数分成 R 个分片,并周期性地写进本地磁盘。这些键值对在磁盘上的位置会被发生给 master,master 负责将位置发送给被分配到 reduce 任务的 worker。
- 当一个 reduce worker 接收到 master 发送的这些位置,它会向保存这些内容的 map worker 发送 RPC 请求来读取这些内容。当一个 reducer worker 读取完所有的中间数据,就会将其根据 key 进行排序,这样所有相同 key 的数据就会聚合在一起。这种排序是必要的,因为通常许多不同的 key 会由同一个 reduce 任务处理。如果数据过大,可能会使用外部排序。
- reduce worker 遍历有序的中间数据,对遇到的所有 key,都会将 key 和对应的值集合传给用户定义的 reduce 函数。reduce 函数的输出会被追加到一个最终的输出文件(每个 reduce 分片一个)。
- 当所有的 map 任务和 reduce 任务都完成后,MapReduce 的任务也就完成了。
运行结束后,MapReduce 的运行结果保存在 R 个输出文件中,通常这些文件会被用作下一个 mapreduce 任务的输入。
容错
这里只考虑 worker 挂掉的情况,不考虑 master 挂掉的情况,因为这可能涉及选举共识等复杂情况。
master 和 worker 会维持一个心跳,如果一段时间没有收到 worker 的回应,就会认为这个 worker 挂掉了。所有由这个 worker 完成的 map 任务都会被重新变成未开始状态,会被重新分配给其他 worker 执行。所有挂掉时正在进行的 map 或者 reduce 任务会被标记为未开始。
已完成的 map 任务需要重新执行是因为它们的结果存储在已经挂掉机器的本地硬盘上,而已经完成的 reduce 任务无需重新执行,reduce 任务的结果被放在全局的文件系统上。
如果一个 map 任务最初由 A 执行,后来 A 挂掉了,被重新分配给 B 执行,这个消息会被通知到所有执行 reduce 任务的 worker。所有还没有从 A 中读取数据的 reduce 任务会转而选择从 B 读取数据。
有时,会出现这种情况:部分机器的性能很低,但是由于网络通畅,不会被判定为挂掉,这种机器就会成为整个系统的短板,整个系统不得不等待慢速机器慢吞吞地执行完他们的任务。对于这种情况,Google 的实现采用的一种机制来提升:在整体 MapReduce 操作快要结束时,master 会将所有仍然在进行的任务分配给其他空闲的 worker 执行。无论是原来的 worker,还是二次分配的 worker 完成了任务,这个任务都算是成功完成。
性能提升与小优化小扩展略去。