Redis
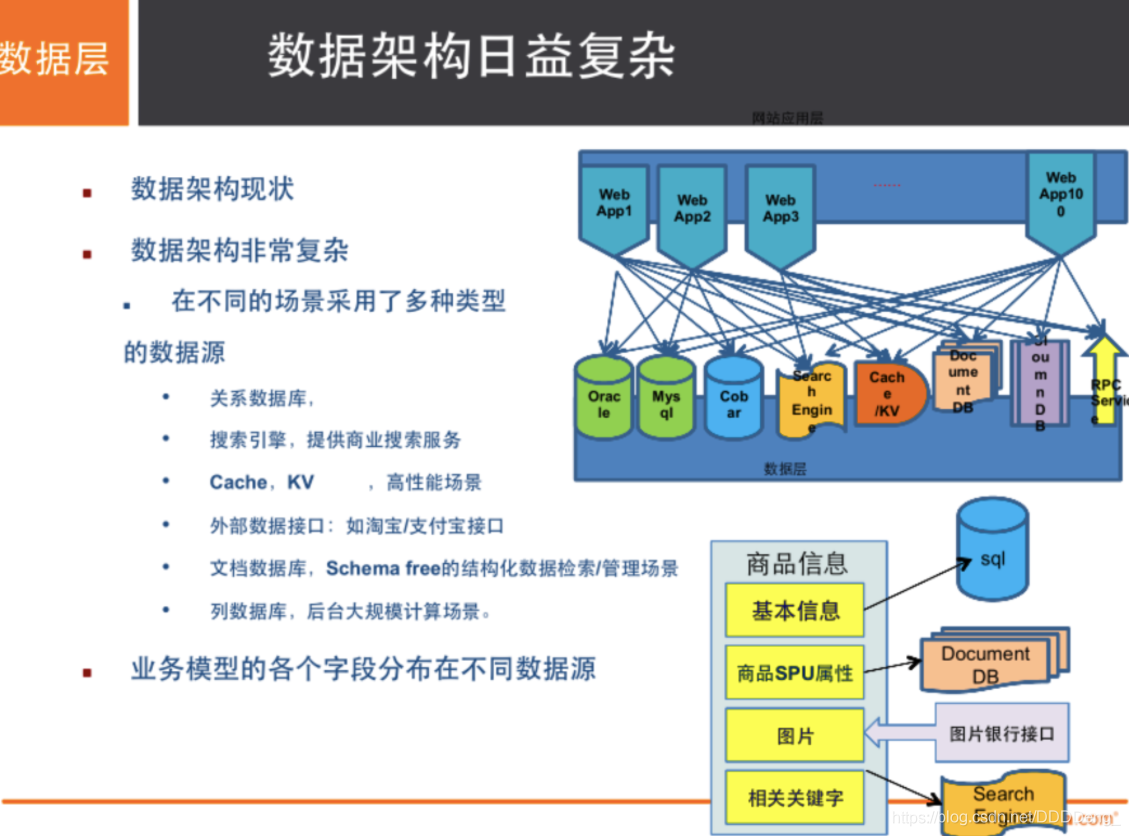
ЮФеТФПТМ
NosqlИХЪі
ЪВУДЪЧNosql
Not Only Structured Query Language
ЙиЯЕаЭЪ§ОнПт:Са+аа,ЭЌвЛИіБэЯТЪ§ОнЕФНсЙЙЪЧвЛбљЕФЁЃ
ЗЧЙиЯЕаЭЪ§ОнПт:Ъ§ОнДцДЂУЛгаЙЬЖЈЕФИёЪН,ВЂЧвПЩвдНјааКсЯђРЉеЙЁЃ
NoSQLЗКжИЗЧЙиЯЕаЭЪ§ОнПт,ЫцзХweb2.0ЛЅСЊЭјЕФЕЎЩњ,ДЋЭГЕФЙиЯЕаЭЪ§ОнПтКмФбЖдИЖweb2.0ЪБДњ!гШЦфЪЧГЌДѓЙцФЃЕФИпВЂЗЂЕФЩчЧј,БЉТЖГіРДКмЖрФбвдПЫЗўЕФЮЪЬт,NoSQLдкЕБНёДѓЪ§ОнЛЗОГЯТЗЂеЙЕФЪЎЗжбИЫй,RedisЪЧЗЂеЙзюПьЕФЁЃ
NosqlЬиЕу
- ЗНБуРЉеЙ(Ъ§ОнжЎМфУЛгаЙиЯЕ,КмКУРЉеЙ!)
- ДѓЪ§ОнСПИпадФм(RedisвЛУыПЩвдаД8ЭђДЮ,ЖС11ЭђДЮ,NoSQLЕФЛКДцМЧТММЖ,ЪЧвЛжжЯИСЃЖШЕФЛКДц,адФмЛсБШНЯИп!)
- Ъ§ОнРраЭЪЧЖрбљаЭЕФ!(ВЛашвЊЪТЯШЩшМЦЪ§ОнПт,ЫцШЁЫцгУ)
- ДЋЭГЕФ RDBMS КЭ NoSQL
ДЋЭГЕФ RDBMS(ЙиЯЕаЭЪ§ОнПт)
- НсЙЙЛЏзщжЏ
- SQL
- Ъ§ОнКЭЙиЯЕЖМДцдкЕЅЖРЕФБэжа row col
- Вйзї,Ъ§ОнЖЈвхгябд
- бЯИёЕФвЛжТад
- ЛљДЁЕФЪТЮё
- ...
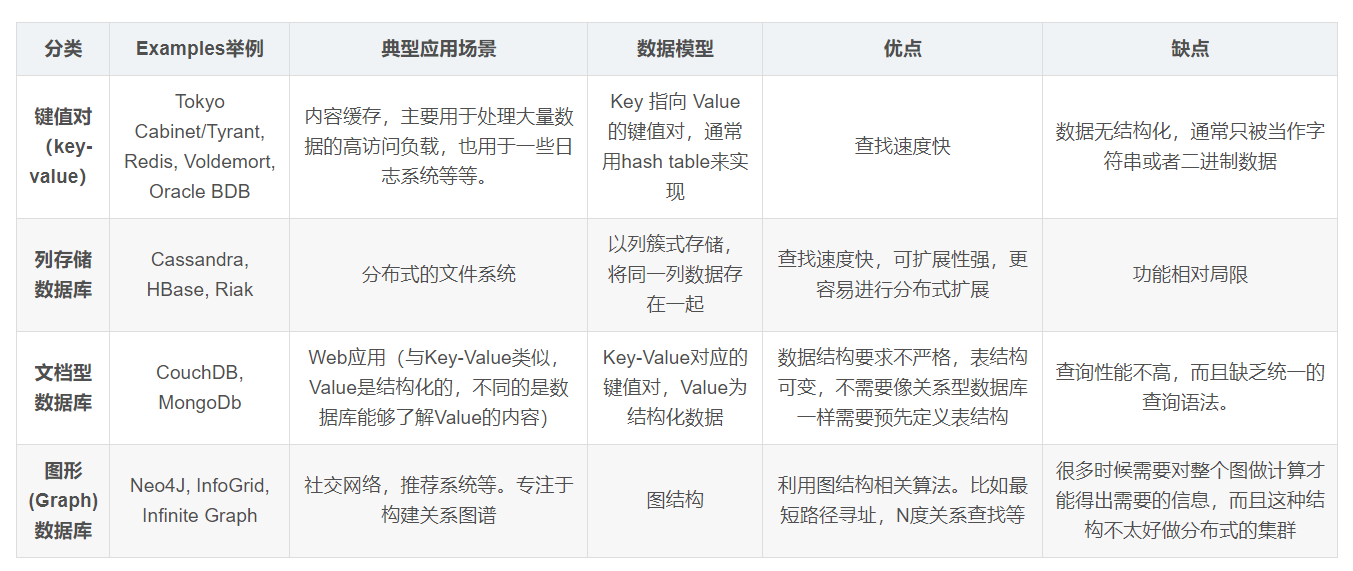
Nosql
- ВЛНіНіЪЧЪ§Он
- УЛгаЙЬЖЈЕФВщбЏгябд
- МќжЕЖдДцДЂ,СаДцДЂ,ЮФЕЕДцДЂ,ЭМаЮЪ§ОнПт(ЩчНЛЙиЯЕ)
- зюжевЛжТад
- CAPЖЈРэКЭBASE
- ИпадФм,ИпПЩгУ,ИпРЉеЙ
- ...
СЫНт:3V + 3Ип
ДѓЪ§ОнЪБДњЕФ3V :жївЊЪЧУшЪіЮЪЬтЕФ
КЃСПVelume
ЖрбљVariety
ЪЕЪБVelocity
ДѓЪ§ОнЪБДњЕФ3Ип : жївЊЪЧЖдГЬађЕФвЊЧѓ
ИпВЂЗЂ
ИпПЩРЉ
ИпадФм
еце§дкЙЋЫОжаЕФЪЕМљ:NoSQL + RDBMS вЛЦ№ЪЙгУВХЪЧзюЧПЕФЁЃ
АЂРяАЭАЭбнНјЗжЮі
ЭЦМідФЖС:АЂРядЦЕФетШКЗшзгhttps://yq.aliyun.com/articles/653511

# ЩЬЦЗаХЯЂ
- вЛАуДцЗХдкЙиЯЕаЭЪ§ОнПт:Mysql,АЂРяАЭАЭЪЙгУЕФMysqlЖМЪЧОЙ§ФкВПИФЖЏЕФЁЃ
# ЩЬЦЗУшЪіЁЂЦРТл(ЮФзжОгЖр)
- ЮФЕЕаЭЪ§ОнПт:MongoDB
# ЭМЦЌ
- ЗжВМЪНЮФМўЯЕЭГ FastDFS
- ЬдБІ:TFS
- Google: GFS
- Hadoop: HDFS
- АЂРядЦ: oss
# ЩЬЦЗЙиМќзж гУгкЫбЫї
- ЫбЫїв§Чц:solr,elasticsearch
- АЂРя:Isearch ЖрТЁ
# ЩЬЦЗШШУХЕФВЈЖЮаХЯЂ
- ФкДцЪ§ОнПт:Redis,Memcache
# ЩЬЦЗНЛвз,ЭтВПжЇИЖНгПк
- ЕкШ§ЗНгІгУ
NosqlЕФЫФДѓЗжРр
KVМќжЕЖд
- аТРЫ:Redis
- УРЭХ:Redis + Tair
- АЂРяЁЂАйЖШ:Redis + Memcache
ЮФЕЕаЭЪ§ОнПт(bsonЪ§ОнИёЪН):
- MongoDB(еЦЮе)
ЛљгкЗжВМЪНЮФМўДцДЂЕФЪ§ОнПтЁЃC++БраД,гУгкДІРэДѓСПЮФЕЕЁЃ MongoDBЪЧRDBMSКЭNoSQLЕФжаМфВњЦЗЁЃMongoDBЪЧЗЧЙиЯЕаЭЪ§ОнПтжаЙІФмзюЗсИЛЕФ,NoSQLжазюЯёЙиЯЕаЭЪ§ОнПтЕФЪ§ОнПтЁЃ
- ConthDB
СаДцДЂЪ§ОнПт
- HBase(ДѓЪ§ОнБибЇ)
- ЗжВМЪНЮФМўЯЕЭГ
ЭМЙиЯЕЪ§ОнПт
гУгкЙуИцЭЦМі,ЩчНЛЭјТч
- Neo4jЁЂInfoGrid
Redis ШыУХ
ИХЪі
RedisЪЧЪВУД?
Redis(Remote Dictionary Server ),МДдЖГЬзжЕфЗўЮёЁЃ
ЪЧвЛИіПЊдДЕФЪЙгУANSI CгябдБраДЁЂжЇГжЭјТчЁЂПЩЛљгкФкДцврПЩГжОУЛЏЕФШежОаЭЁЂKey-ValueЪ§ОнПт,ВЂЬсЙЉЖржжгябдЕФAPIЁЃ
гыmemcachedвЛбљ,ЮЊСЫБЃжЄаЇТЪ,Ъ§ОнЖМЪЧЛКДцдкФкДцжаЁЃЧјБ№ЕФЪЧredisЛсжмЦкадЕФАбИќаТЕФЪ§ОнаДШыДХХЬЛђепАбаоИФВйзїаДШызЗМгЕФМЧТМЮФМў,ВЂЧвдкДЫЛљДЁЩЯЪЕЯжСЫmaster-slave(жїДг)ЭЌВНЁЃ
RedisФмИУИЩЪВУД?
- ФкДцДцДЂЁЂГжОУЛЏ,ФкДцЪЧЖЯЕчМДЪЇЕФ,ЫљвдашвЊГжОУЛЏ(RDBЁЂAOF)
- ИпаЇТЪЁЂгУгкИпЫйЛКГх
- ЗЂВМЖЉдФЯЕЭГ
- ЕиЭМаХЯЂЗжЮі
- МЦЪБЦїЁЂМЦЪ§Цї(eg:фЏРРСП)
- ЁЃЁЃЁЃ
Ьиад
- ЖрбљЕФЪ§ОнРраЭ
- ГжОУЛЏ
- МЏШК
- ЪТЮё
- Ё Ё
LinuxАВзА
- ЯТдиАВзААќ!redis-5.0.8.tar.gz
- НтбЙRedisЕФАВзААќ!ГЬађвЛАуЗХдк /opt ФПТМЯТ

-
АВзАдЫааЛЗОГgcc

МьВщЪЧЗёАВзАЩЯСЫgcc

-
жДааmake
ШЛКѓжДаа make install
-
redisФЌШЯАВзАТЗОЖ /usr/local/bin

-
НЋredisЕФХфжУЮФМўИДжЦЕН ГЬађАВзАФПТМ /usr/local/bin/kconfigЯТ
-
redisФЌШЯВЛЪЧКѓЬЈЦєЖЏЕФ,ашвЊаоИФХфжУЮФМў!
-
ЭЈЙ§жЦЖЈЕФХфжУЮФМўЦєЖЏredisЗўЮё

-
ВщПДredisНјГЬЪЧЗёПЊЦє


-
ЙиБеRedisЗўЮё shutdown


ВтЪдадФм
redis-benchmark RedisЙйЗНЬсЙЉЕФадФмВтЪдЙЄОп,ВЮЪ§бЁЯюШчЯТ:
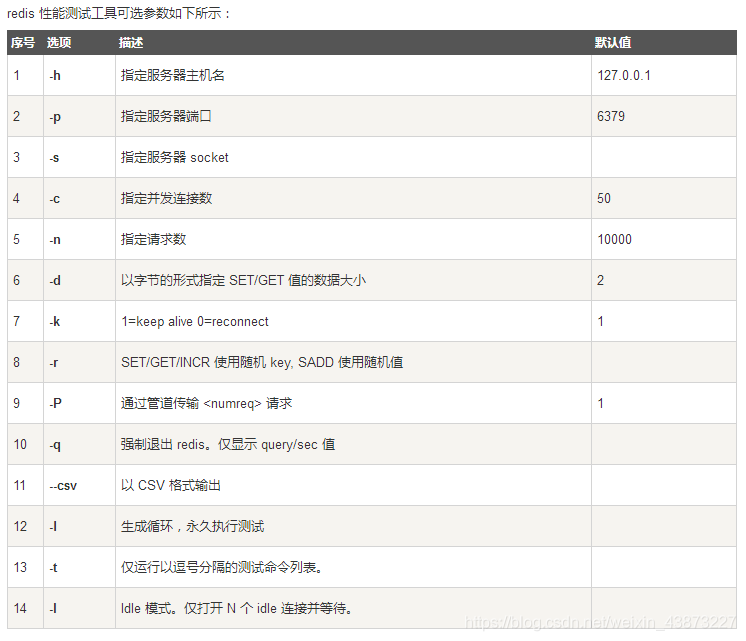
МђЕЅВтЪд:
# ВтЪд:100ИіВЂЗЂСЌНг 100000ЧыЧѓ
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
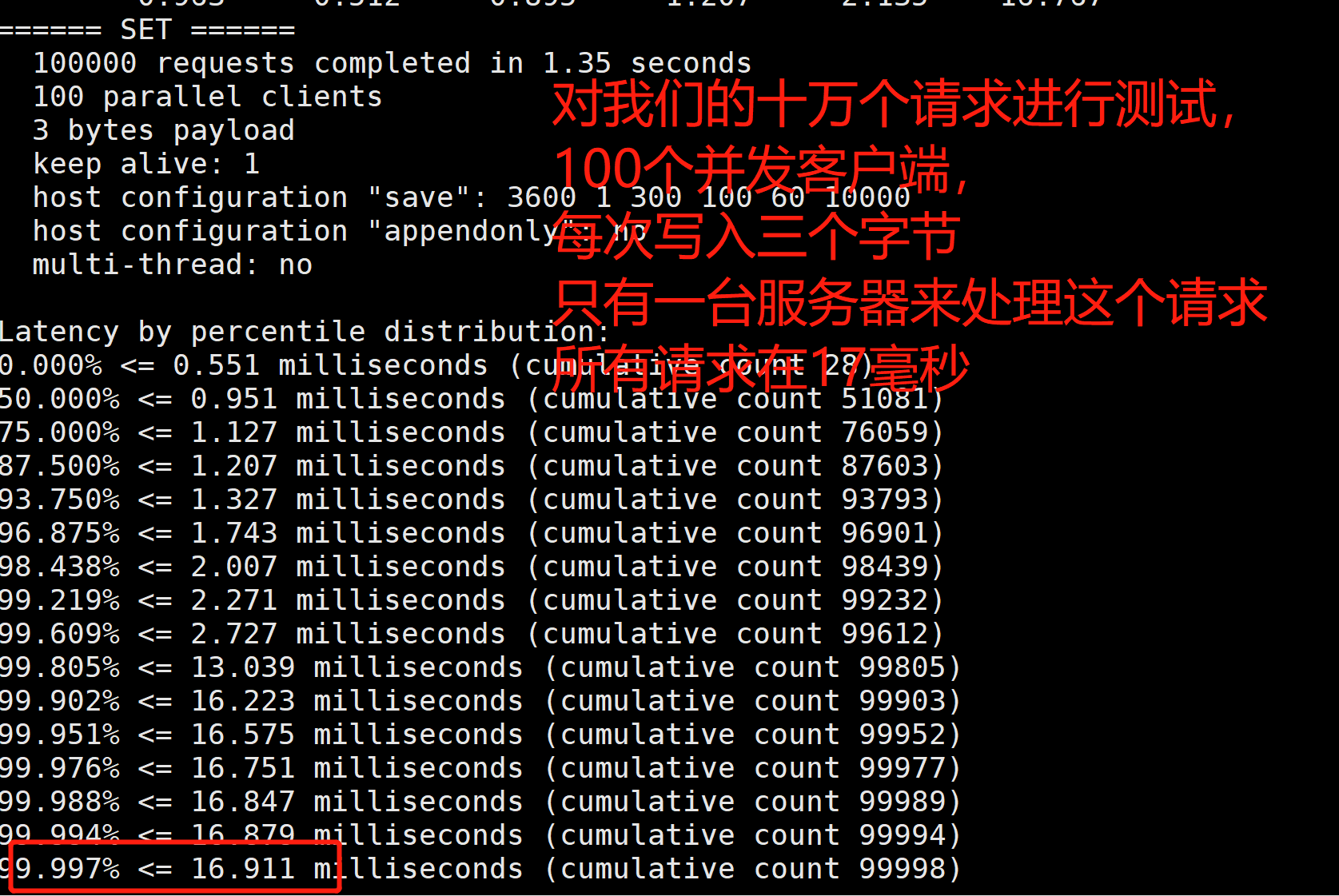
ЛљДЁжЊЪЖ
redisФЌШЯга16ИіЪ§ОнПт
ФЌШЯЪЙгУЕФЕк0Иі;
16ИіЪ§ОнПтЮЊ:DB 0~DB 15 ФЌШЯЪЙгУDB 0 ,ПЩвдЪЙгУselect nЧаЛЛЕНDB n,dbsizeПЩвдВщПДЕБЧАЪ§ОнПтЕФДѓаЁ,гыkeyЪ§СПЯрЙиЁЃ
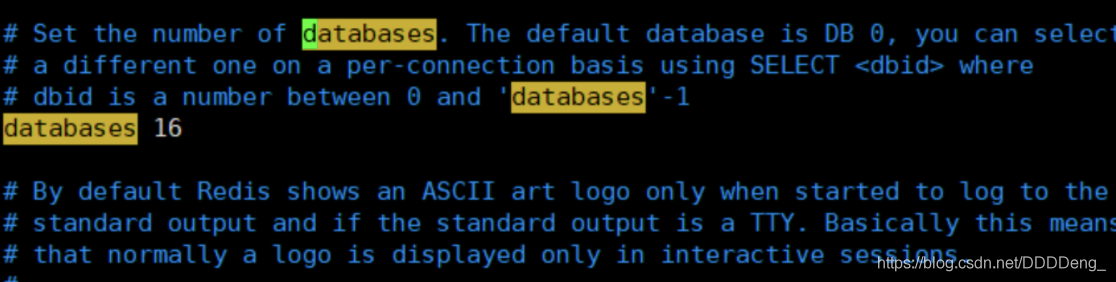
127.0.0.1:6379> config get databases # УќСюааВщПДЪ§ОнПтЪ§СПdatabases
1) "databases"
2) "16"
127.0.0.1:6379> select 8 # ЧаЛЛЪ§ОнПт DB 8
OK
127.0.0.1:6379[8]> dbsize # ВщПДЪ§ОнПтДѓаЁ
(integer) 0
# ВЛЭЌЪ§ОнПтжЎМф Ъ§ОнЪЧВЛФмЛЅЭЈЕФ,ВЂЧвdbsize ЪЧИљОнПтжаkeyЕФИіЪ§ЁЃ
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> SELECT 8
OK
127.0.0.1:6379[8]> get name # db8жаВЂВЛФмЛёШЁdb0жаЕФМќжЕЖдЁЃ
(nil)
127.0.0.1:6379[8]> DBSIZE
(integer) 0
127.0.0.1:6379[8]> SELECT 0
OK
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "name"
4) "key:__rand_int__"
5) "myset:__rand_int__"
127.0.0.1:6379> DBSIZE # sizeКЭkeyИіЪ§ЯрЙи
(integer) 5
keys * :ВщПДЕБЧАЪ§ОнПтжаЫљгаЕФkeyЁЃ
flushdb:ЧхПеЕБЧАЪ§ОнПтжаЕФМќжЕЖдЁЃ
flushall:ЧхПеЫљгаЪ§ОнПтЕФМќжЕЖдЁЃ
RedisЪЧЕЅЯпГЬЕФ
==RedisЪЧЕЅЯпГЬЕФ,RedisЪЧЛљгкФкДцВйзїЕФЁЃ==ЫљвдRedisЕФадФмЦПОБВЛЪЧCPU,ЖјЪЧЛњЦїФкДцКЭЭјТчДјПэЁЃ
ФЧУДЮЊЪВУДRedisЕФЫйЖШШчДЫПьФи,адФметУДИпФи?ЙйЗНЕФQPSДяЕН10W+,етИіЫЕУїВЛБШMemeacheВю
RedisЮЊЪВУДЕЅЯпГЬЛЙетУДПь?
- ЮѓЧј1:ИпадФмЕФЗўЮёЦївЛЖЈЪЧЖрЯпГЬЕФ?
- ЮѓЧј2:ЖрЯпГЬ(CPUЩЯЯТЮФЛсЧаЛЛ!)вЛЖЈБШЕЅЯпГЬаЇТЪИп!
КЫаФ:RedisЪЧНЋЫљгаЕФЪ§ОнЗХдкФкДцжаЕФ,ЫљвдЫЕЪЙгУЕЅЯпГЬШЅВйзїаЇТЪОЭЪЧзюИпЕФ,ЖрЯпГЬ(CPUЩЯЯТЮФЛсЧаЛЛ:КФЪБЕФВйзї!),ЖдгкФкДцЯЕЭГРДЫЕ,ШчЙћУЛгаЩЯЯТЮФЧаЛЛаЇТЪОЭЪЧзюИпЕФ,ЖрДЮЖСаДЖМЪЧдквЛИіCPUЩЯЕФ,дкФкДцДцДЂЪ§ОнЧщПіЯТ,ЕЅЯпГЬОЭЪЧзюМбЕФЗНАИЁЃ
RedisЮхДѓЪ§ОнРраЭ
RedisЪЧвЛИіПЊдД(BSDаэПЩ),ФкДцДцДЂЕФЪ§ОнНсЙЙЗўЮёЦї,ПЩгУзїЪ§ОнПт,ИпЫйЛКДцКЭЯћЯЂЖгСаДњРэЁЃЫќжЇГжзжЗћДЎЁЂЙўЯЃБэЁЂСаБэЁЂМЏКЯЁЂгаађМЏКЯ,ЮЛЭМ,hyperloglogsЕШЪ§ОнРраЭЁЃФкжУИДжЦЁЂLuaНХБОЁЂLRUЪеЛиЁЂЪТЮёвдМАВЛЭЌМЖБ№ДХХЬГжОУЛЏЙІФм,ЭЌЪБЭЈЙ§Redis SentinelЬсЙЉИпПЩгУ,ЭЈЙ§Redis ClusterЬсЙЉздЖЏЗжЧјЁЃ
Redis-key
дкredisжаЮоТлЪВУДЪ§ОнРраЭ,дкЪ§ОнПтжаЖМЪЧвдkey-valueаЮЪНБЃДц,ЭЈЙ§НјааЖдRedis-keyЕФВйзї,РДЭъГЩЖдЪ§ОнПтжаЪ§ОнЕФВйзїЁЃ
ЯТУцбЇЯАЕФУќСю:
-
exists key:ХаЖЯМќЪЧЗёДцдк
-
del key:ЩОГ§МќжЕЖд
-
move key db:НЋМќжЕЖдвЦЖЏЕНжИЖЈЪ§ОнПт
-
expire key second:ЩшжУМќжЕЖдЕФЙ§ЦкЪБМф
-
type key:ВщПДvalueЕФЪ§ОнРраЭ
-
unlink key ИљОнvalueбЁдёЗЧзшШћЩОГ§
вьВНЩОГ§НіНЋkeysДгkeyspaceдЊЪ§ОнжаЩОГ§,еце§ЕФЩОГ§ЛсдкКѓајвьВНВйзїЁЃ
-
expire key 10 10Уыжг:ЮЊИјЖЈЕФkeyЩшжУЙ§ЦкЪБМф
-
ttl key ВщПДЛЙгаЖрЩйУыЙ§Цк,-1БэЪОгРВЛЙ§Цк,-2БэЪОвбЙ§Цк
127.0.0.1:6379> keys * # ВщПДЕБЧАЪ§ОнПтЫљгаkey
(empty list or set)
127.0.0.1:6379> set name qinjiang # set key
OK
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> move age 1 # НЋМќжЕЖдвЦЖЏЕНжИЖЈЪ§ОнПт
(integer) 1
127.0.0.1:6379> EXISTS age # ХаЖЯМќЪЧЗёДцдк
(integer) 0 # ВЛДцдк
127.0.0.1:6379> EXISTS name
(integer) 1 # Дцдк
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> keys *
1) "age"
127.0.0.1:6379[1]> del age # ЩОГ§МќжЕЖд
(integer) 1 # ЩОГ§ИіЪ§
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> EXPIRE age 15 # ЩшжУМќжЕЖдЕФЙ§ЦкЪБМф
(integer) 1 # ЩшжУГЩЙІ ПЊЪММЦЪ§
127.0.0.1:6379> ttl age # ВщПДkeyЕФЙ§ЦкЪЃгрЪБМф
(integer) 13
127.0.0.1:6379> ttl age
(integer) 11
127.0.0.1:6379> ttl age
(integer) 9
127.0.0.1:6379> ttl age
(integer) -2 # -2 БэЪОkeyЙ§Цк,-1БэЪОkeyЮДЩшжУЙ§ЦкЪБМф
127.0.0.1:6379> get age # Й§ЦкЕФkey ЛсБЛздЖЏdelete
(nil)
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> type name # ВщПДvalueЕФЪ§ОнРраЭ
string
ЙигкTTLУќСю
RedisЕФkey,ЭЈЙ§TTLУќСюЗЕЛиkeyЕФЙ§ЦкЪБМф,вЛАуРДЫЕга3жж:
- ЕБЧАkeyУЛгаЩшжУЙ§ЦкЪБМф,ЫљвдЛсЗЕЛи-1.
- ЕБЧАkeyгаЩшжУЙ§ЦкЪБМф,ЖјЧвkeyвбОЙ§Цк,ЫљвдЛсЗЕЛи-2.
- ЕБЧАkeyгаЩшжУЙ§ЦкЪБМф,ЧвkeyЛЙУЛгаЙ§Цк,ЙЪЛсЗЕЛиkeyЕФе§ГЃЪЃгрЪБМф.
ЙигкжиУќУћRENAMEКЭRENAMENX
- RENAME key newkeyаоИФ key ЕФУћГЦ
- RENAMENX key newkeyНіЕБ newkey ВЛДцдкЪБ,НЋ key ИФУћЮЊ newkey ЁЃ
ИќЖрУќСюбЇЯА:https://www.redis.net.cn/order/
String
StringЪЧRedisзюЛљБОЕФРраЭ,ФуПЩвдРэНтГЩгыMemcachedвЛФЃвЛбљЕФРраЭ,вЛИіkeyЖдгІвЛИіvalueЁЃ
StringРраЭЪЧЖўНјжЦАВШЋЕФЁЃвтЮЖзХRedisЕФstringПЩвдАќКЌШЮКЮЪ§ОнЁЃБШШчjpgЭМЦЌЛђепађСаЛЏЕФЖдЯѓЁЃ
StringРраЭЪЧRedisзюЛљБОЕФЪ§ОнРраЭ,вЛИіRedisжазжЗћДЎvalueзюЖрПЩвдЪЧ512M
ГЃгУУќСю
-
get ВщбЏЖдгІМќжЕ
-
append НЋИјЖЈЕФ зЗМгЕНджЕЕФФЉЮВ
-
strlen ЛёЕУжЕЕФГЄЖШ
-
setnx жЛгадк key ВЛДцдкЪБ ЩшжУ key ЕФжЕ
-
incr
- НЋ key жаДЂДцЕФЪ§зжжЕді1
- жЛФмЖдЪ§зжжЕВйзї,ШчЙћЮЊПе,аТдіжЕЮЊ1
-
decr
- НЋ key жаДЂДцЕФЪ§зжжЕМѕ1
- жЛФмЖдЪ§зжжЕВйзї,ШчЙћЮЊПе,аТдіжЕЮЊ-1
-
incrby / decrby <ВНГЄ>НЋ key жаДЂДцЕФЪ§зжжЕдіМѕЁЃздЖЈвхВНГЄЁЃ
-
mset Ё
ЭЌЪБЩшжУвЛИіЛђЖрИі key-valueЖд
-
mget Ё
ЭЌЪБЛёШЁвЛИіЛђЖрИі value
-
msetnx Ё
ЭЌЪБЩшжУвЛИіЛђЖрИі key-value Жд,ЕБЧвНіЕБЫљгаИјЖЈ key ЖМВЛДцдкЁЃдзгад,гавЛИіЪЇАмдђЖМЪЇАм
-
getrange <Ц№ЪМЮЛжУ><НсЪјЮЛжУ>
ЛёЕУжЕЕФЗЖЮЇ,РрЫЦjavaжаЕФsubstring,ЧААќ,КѓАќ
-
setrange <Ц№ЪМЮЛжУ>
гУ ИВаДЫљДЂДцЕФзжЗћДЎжЕ,Дг<Ц№ЪМЮЛжУ>ПЊЪМ(Ыїв§Дг0ПЊЪМ**)ЁЃ**
-
setex <Й§ЦкЪБМф>**
ЩшжУМќжЕЕФЭЌЪБ,ЩшжУЙ§ЦкЪБМф,ЕЅЮЛУыЁЃ
-
getset
вдаТЛЛОЩ,ЩшжУСЫаТжЕЭЌЪБЛёЕУОЩжЕЁЃ
##########################################################################
127.0.0.1:6379> set key1 v1 # ЩшжУжЕ
OK
127.0.0.1:6379> get key1 # ЛёЕУжЕ
"v1"
127.0.0.1:6379> keys * # ЛёЕУЫљгаЕФkey
1) "key1"
127.0.0.1:6379> EXISTS key1 # ХаЖЯФГвЛИіkeyЪЧЗёДцдк
(integer) 1
127.0.0.1:6379> APPEND key1 "hello" # зЗМгзжЗћДЎ,ШчЙћЕБЧАkeyВЛДцдк,ОЭЯрЕБгкsetkey
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> STRLEN key1 # ЛёШЁзжЗћДЎЕФГЄЖШ!
(integer) 7
127.0.0.1:6379> APPEND key1 ",kaungshen"
(integer) 17
127.0.0.1:6379> STRLEN key1
(integer) 17
127.0.0.1:6379> get key1
"v1hello,kaungshen"
##########################################################################
# i++
# ВНГЄ i+=
127.0.0.1:6379> set views 0 # ГѕЪМфЏРРСПЮЊ0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views # здді1 фЏРРСПБфЮЊ1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> decr views # здМѕ1 фЏРРСП-1
(integer) 1
127.0.0.1:6379> decr views
(integer) 0
127.0.0.1:6379> decr views
(integer) -1
127.0.0.1:6379> get views
"-1"
127.0.0.1:6379> INCRBY views 10 # ПЩвдЩшжУВНГЄ,жИЖЈдіСП!
(integer) 9
127.0.0.1:6379> INCRBY views 10
(integer) 19
127.0.0.1:6379> DECRBY views 5
(integer) 14
##########################################################################
# зжЗћДЎЗЖЮЇ range
127.0.0.1:6379> set key1 "hello,kuangshen" # ЩшжУ key1 ЕФжЕ
OK
127.0.0.1:6379> get key1
"hello,kuangshen"
127.0.0.1:6379> GETRANGE key1 0 3 # НиШЁзжЗћДЎ [0,3]
"hell"
127.0.0.1:6379> GETRANGE key1 0 -1 # ЛёШЁШЋВПЕФзжЗћДЎ КЭ get keyЪЧвЛбљЕФ
"hello,kuangshen"
# ЬцЛЛ!
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> SETRANGE key2 1 xx # ЬцЛЛжИЖЈЮЛжУПЊЪМЕФзжЗћДЎ!
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
##########################################################################
# setex (set with expire) # ЩшжУЙ§ЦкЪБМф
# setnx (set if not exist) # ВЛДцдкдкЩшжУ (дкЗжВМЪНЫјжаЛсГЃГЃЪЙгУ!)
127.0.0.1:6379> setex key3 30 "hello" # ЩшжУkey3 ЕФжЕЮЊ hello,30УыКѓЙ§Цк
OK
127.0.0.1:6379> ttl key3
(integer) 26
127.0.0.1:6379> get key3
"hello"
127.0.0.1:6379> setnx mykey "redis" # ШчЙћmykey ВЛДцдк,ДДНЈmykey
(integer) 1
127.0.0.1:6379> keys *
1) "key2"
2) "mykey"
3) "key1"
127.0.0.1:6379> ttl key3
(integer) -2
127.0.0.1:6379> setnx mykey "MongoDB" # ШчЙћmykeyДцдк,ДДНЈЪЇАм!
(integer) 0
127.0.0.1:6379> get mykey
"redis"
##########################################################################
mset
mget
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # ЭЌЪБЩшжУЖрИіжЕ
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
3) "k3"
127.0.0.1:6379> mget k1 k2 k3 # ЭЌЪБЛёШЁЖрИіжЕ
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 # msetnx ЪЧвЛИідзгадЕФВйзї,вЊУДвЛЦ№ГЩЙІ,вЊУДвЛЦ№
ЪЇАм!
(integer) 0
127.0.0.1:6379> get k4
(nil)
# ЖдЯѓ
set user:1 {name:zhangsan,age:3} # ЩшжУвЛИіuser:1 ЖдЯѓ жЕЮЊ jsonзжЗћРДБЃДцвЛИіЖдЯѓ!
# етРяЕФkeyЪЧвЛИіЧЩУюЕФЩшМЦ: user:{id}:{filed} , ШчДЫЩшМЦдкRedisжаЪЧЭъШЋOKСЫ!
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 2
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"
2) "2"
##########################################################################
getset # ЯШgetШЛКѓдкset
127.0.0.1:6379> getset db redis # ШчЙћВЛДцдкжЕ,дђЗЕЛи nil
(nil)
127.0.0.1:6379> get db
"redis
127.0.0.1:6379> getset db mongodb # ШчЙћДцдкжЕ,ЛёШЁдРДЕФжЕ,ВЂЩшжУаТЕФжЕ
"redis"
127.0.0.1:6379> get db
"mongodb"
Ъ§ОнНсЙЙЪЧЯрЭЌЕФ!
StringРрЫЦЕФЪЙгУГЁОА:valueГ§СЫЪЧЮвУЧЕФзжЗћДЎЛЙПЩвдЪЧЮвУЧЕФЪ§зж! МЦЪ§Цї ЭГМЦЖрЕЅЮЛЕФЪ§СП ЗлЫПЪ§ ЖдЯѓЛКДцДцДЂ!
дзгад
ЫљЮНдзгВйзїЪЧжИВЛЛсБЛЯпГЬЕїЖШЛњжЦДђЖЯЕФВйзї;
етжжВйзївЛЕЉПЊЪМ,ОЭвЛжБдЫааЕННсЪј,жаМфВЛЛсгаШЮКЮ context switch (ЧаЛЛЕНСэвЛИіЯпГЬ)ЁЃ
(1)дкЕЅЯпГЬжа, ФмЙЛдкЕЅЬѕжИСюжаЭъГЩЕФВйзїЖМПЩвдШЯЮЊЪЧ"дзгВйзї",вђЮЊжаЖЯжЛФмЗЂЩњгкжИСюжЎМфЁЃ
(2)дкЖрЯпГЬжа,ВЛФмБЛЦфЫќНјГЬ(ЯпГЬ)ДђЖЯЕФВйзїОЭНадзгВйзїЁЃ
RedisЕЅУќСюЕФдзгаджївЊЕУвцгкRedisЕФЕЅЯпГЬЁЃ
javaжаЕФi++ЪЧЗёЪЧдзгВйзї?ВЛЪЧ
i=0;СНИіЯпГЬЗжБ№ЖдiНјаа++100ДЮ,жЕЪЧЖрЩй? 2~20
i= 0 i=0
i++
i=99
i++
i=1
i=1
i++
i=100
i++
i=2
зюКѓЕФЪ§зжПЩФмЪЧ2-200жЎМфШЮвтЕФвЛИі
ЮЊЪВУДзюаЁжЕвЛЖЈЪЧ2?
ЯпГЬA ФУСЫИі0,ЗХдкЪжРя,ЕШЯпГЬBМЦЫуЕНзюКѓвЛВН,аДШыi,iБфГЩСЫ1ЁЃ
ДЫЪБЯпГЬBФУЕНетИі1,вЛжБЕШЕНЯпГЬAМЦЫуЭъ,ЯпГЬBдйЭъГЩМЦЫу,iБфГЩ2ЁЃ
ЮЊЪВУДВЛФмИќаЁФи?БШШчi = 1.
вђЮЊБиаывЊСНДЮИВИЧВХФмзюаЁЁЃЯпГЬAКЭЯпГЬBвЛжБЖМдкЪЙiБфДѓЁЃiБфаЁЕФЮЈвЛЭООЖОЭЪЧБЛСэЭтвЛИіЯпГЬИВИЧЁЃ
ЫљвдвЊЯыЯпГЬAЕФжЕБфаЁ,ЯпГЬBБиаыИВИЧвЛДЮA,ЯпГЬBЕФжЕвЊЯыБфаЁОЭБиаыБЛЯпГЬAИВИЧвЛДЮЁЃ
ИВИЧвтЮЖзХЪВУД?
ИВИЧвтЮЖзХi++,ФУЕНi,iМг1,ШЛКѓаДЛиЁЃ
СНДЮИВИЧОЭМгСНДЮЁЃЫљвдiзюаЁЮЊ2.
List(СаБэ)
ЕЅМќЖржЕ
Redis СаБэЪЧМђЕЅЕФзжЗћДЎСаБэ,АДееВхШыЫГађХХађЁЃФуПЩвдЬэМгвЛИідЊЫиЕНСаБэЕФЭЗВП(зѓБп)ЛђепЮВВП(гвБп)ЁЃ
ЫќЕФЕзВуЪЕМЪЪЧИіЫЋЯђСДБэ,ЖдСНЖЫЕФВйзїадФмКмИп,ЭЈЙ§Ыїв§ЯТБъЕФВйзїжаМфЕФНкЕуадФмЛсНЯВюЁЃ

-
lpush/rpush Ё ДгзѓБп/гвБпВхШывЛИіЛђЖрИіжЕЁЃ
-
lpop/rpop ДгзѓБп/гвБпЭТГівЛИіжЕЁЃжЕдкМќдк,жЕЙтМќЭіЁЃ
-
rpoplpush ДгСаБэгвБпЭТГівЛИіжЕ,ВхЕНСаБэзѓБпЁЃ
-
lrange
АДееЫїв§ЯТБъЛёЕУдЊЫи(ДгзѓЕНгв)
-
lrange mylist 0 -1 0зѓБпЕквЛИі,-1гвБпЕквЛИі,(0-1БэЪОЛёШЁЫљга)
-
lindex АДееЫїв§ЯТБъЛёЕУдЊЫи(ДгзѓЕНгв)
-
llen ЛёЕУСаБэГЄЖШ
-
linsert before дкЕФКѓУцВхШыВхШыжЕ
-
lrem ДгзѓБпЩОГ§nИіvalue(ДгзѓЕНгв)
-
lsetНЋСаБэkeyЯТБъЮЊindexЕФжЕЬцЛЛГЩvalue
ЛљБОЕФЪ§ОнРраЭ,СаБэ
дкredisРяУц,ЮвУЧПЩвдАбlistЭцГЩ ,еЛЁЂЖгСаЁЂзшШћЖгСа! ЫљгаЕФlistУќСюЖМЪЧгУlПЊЭЗЕФ,RedisВЛЧјЗжДѓаЁУќСю
##########################################################################
127.0.0.1:6379> LPUSH list one # НЋвЛИіжЕЛђепЖрИіжЕ,ВхШыЕНСаБэЭЗВП (зѓ)
(integer) 1
127.0.0.1:6379> LPUSH list two
(integer) 2
127.0.0.1:6379> LPUSH list three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1 # ЛёШЁlistжажЕ!
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LRANGE list 0 1 # ЭЈЙ§ЧјМфЛёШЁОпЬхЕФжЕ!
1) "three"
2) "two"
127.0.0.1:6379> Rpush list righr # НЋвЛИіжЕЛђепЖрИіжЕ,ВхШыЕНСаБэЮЛВП (гв)
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "righr"
##########################################################################
LPOP
RPOP
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "righr"
127.0.0.1:6379> Lpop list # вЦГ§listЕФЕквЛИідЊЫи
"three"
127.0.0.1:6379> Rpop list # вЦГ§listЕФзюКѓвЛИідЊЫи
"righr"
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
##########################################################################
Lindex
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> lindex list 1 # ЭЈЙ§ЯТБъЛёЕУ list жаЕФФГвЛИіжЕ!
"one"
127.0.0.1:6379> lindex list 0
"two"
##########################################################################
Llen
127.0.0.1:6379> Lpush list one
(integer) 1
127.0.0.1:6379> Lpush list two
(integer) 2
127.0.0.1:6379> Lpush list three
(integer) 3
127.0.0.1:6379> Llen list # ЗЕЛиСаБэЕФГЄЖШ
(integer) 3
##########################################################################
вЦГ§жИЖЈЕФжЕ!
ШЁЙи uid
Lrem
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "three"
3) "two"
4) "one"
127.0.0.1:6379> lrem list 1 one # вЦГ§listМЏКЯжажИЖЈИіЪ§ЕФvalue,ОЋШЗЦЅХф
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "three"
3) "two"
127.0.0.1:6379> lrem list 1 three
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
127.0.0.1:6379> Lpush list three
(integer) 3
127.0.0.1:6379> lrem list 2 three
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
##########################################################################
trim аоМєЁЃ; list НиЖЯ!
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> Rpush mylist "hello"
(integer) 1
127.0.0.1:6379> Rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> Rpush mylist "hello2"
(integer) 3
127.0.0.1:6379> Rpush mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2 # ЭЈЙ§ЯТБъНиШЁжИЖЈЕФГЄЖШ,етИіlistвбОБЛИФБфСЫ,НиЖЯСЫ
жЛЪЃЯТНиШЁЕФдЊЫи!
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello1"
2) "hello2"
##########################################################################
rpoplpush # вЦГ§СаБэЕФзюКѓвЛИідЊЫи,НЋЫћвЦЖЏЕНаТЕФСаБэжа!
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> rpush mylist "hello2"
(integer) 3
127.0.0.1:6379> rpoplpush mylist myotherlist # вЦГ§СаБэЕФзюКѓвЛИідЊЫи,НЋЫћвЦЖЏЕНаТЕФ
СаБэжа!
"hello2"
127.0.0.1:6379> lrange mylist 0 -1 # ВщПДдРДЕФСаБэ
1) "hello"
2) "hello1"
127.0.0.1:6379> lrange myotherlist 0 -1 # ВщПДФПБъСаБэжа,ШЗЪЕДцдкИФжЕ!
1) "hello2"
##########################################################################
lset НЋСаБэжажИЖЈЯТБъЕФжЕЬцЛЛЮЊСэЭтвЛИіжЕ,ИќаТВйзї
127.0.0.1:6379> EXISTS list # ХаЖЯетИіСаБэЪЧЗёДцдк
(integer) 0
127.0.0.1:6379> lset list 0 item # ШчЙћВЛДцдкСаБэЮвУЧШЅИќаТОЭЛсБЈДэ
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> LRANGE list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 item # ШчЙћДцдк,ИќаТЕБЧАЯТБъЕФжЕ
OK
127.0.0.1:6379> LRANGE list 0 0
1) "item"
127.0.0.1:6379> lset list 1 other # ШчЙћВЛДцдк,дђЛсБЈДэ!
(error) ERR index out of range
##########################################################################
linsert # НЋФГИіОпЬхЕФvalueВхШыЕНСаАбФужаФГИідЊЫиЕФЧАУцЛђепКѓУц!
127.0.0.1:6379> Rpush mylist "hello"
(integer) 1
127.0.0.1:6379> Rpush mylist "world"
(integer) 2
127.0.0.1:6379> LINSERT mylist before "world" "other"
(integer) 3
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> LINSERT mylist after world new
(integer) 4
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
аЁНсbash
- ЫћЪЕМЪЩЯЪЧвЛИіСДБэ,before Node after , left,right ЖМПЩвдВхШыжЕ
- ШчЙћkey ВЛДцдк,ДДНЈаТЕФСДБэ
- ШчЙћkeyДцдк,аТдіФкШн
- ШчЙћвЦГ§СЫЫљгажЕ,ПеСДБэ,вВДњБэВЛДцдк!
- дкСНБпВхШыЛђепИФЖЏжЕ,аЇТЪзюИп! жаМфдЊЫи,ЯрЖдРДЫЕаЇТЪЛсЕЭвЛЕу~
ЯћЯЂХХЖг!ЯћЯЂЖгСа (Lpush Rpop), еЛ( Lpush Lpop)!
Set(МЏКЯ)
setжаЕФжЕЪЧВЛФмжиЖСЕФ!
Redis setЖдЭтЬсЙЉЕФЙІФмгыlistРрЫЦЪЧвЛИіСаБэЕФЙІФм,ЬиЪтжЎДІдкгкsetЪЧПЩвдздЖЏХХжиЕФ,ЕБФуашвЊДцДЂвЛИіСаБэЪ§Он,гжВЛЯЃЭћГіЯжжиИДЪ§ОнЪБ,setЪЧвЛИіКмКУЕФбЁдё,ВЂЧвsetЬсЙЉСЫХаЖЯФГИіГЩдБЪЧЗёдквЛИіsetМЏКЯФкЕФживЊНгПк,етИівВЪЧlistЫљВЛФмЬсЙЉЕФЁЃ
RedisЕФSetЪЧstringРраЭЕФЮоађМЏКЯЁЃЫќЕзВуЦфЪЕЪЧвЛИіvalueЮЊnullЕФhashБэ,ЫљвдЬэМг,ЩОГ§,ВщевЕФИДдгЖШЪЧO(1)ЁЃ
ГЃгУжИСю
-
sadd Ё
НЋвЛИіЛђЖрИі member дЊЫиМгШыЕНМЏКЯ key жа,вбОДцдкЕФ member дЊЫиНЋБЛКіТд
-
smembers ШЁГіИУМЏКЯЕФЫљгажЕЁЃ
-
sismember ХаЖЯМЏКЯЪЧЗёЮЊКЌгаИУжЕ,га1,УЛга0
-
scardЗЕЛиИУМЏКЯЕФдЊЫиИіЪ§ЁЃ
-
srem Ё ЩОГ§МЏКЯжаЕФФГИідЊЫиЁЃ
-
spop ЫцЛњДгИУМЏКЯжаЭТГівЛИіжЕЁЃ
-
srandmember ЫцЛњДгИУМЏКЯжаШЁГіnИіжЕЁЃВЛЛсДгМЏКЯжаЩОГ§ ЁЃ
-
smove valueАбМЏКЯжавЛИіжЕДгвЛИіМЏКЯвЦЖЏЕНСэвЛИіМЏКЯ
-
sinter ЗЕЛиСНИіМЏКЯЕФНЛМЏдЊЫиЁЃ
-
sunion ЗЕЛиСНИіМЏКЯЕФВЂМЏдЊЫиЁЃ
-
sdiff ЗЕЛиСНИіМЏКЯЕФВюМЏдЊЫи(key1жаЕФ,ВЛАќКЌkey2жаЕФ)
SetЪ§ОнНсЙЙЪЧdictзжЕф,зжЕфЪЧгУЙўЯЃБэЪЕЯжЕФЁЃ
JavaжаHashSetЕФФкВПЪЕЯжЪЙгУЕФЪЧHashMap,жЛВЛЙ§ЫљгаЕФvalueЖМжИЯђЭЌвЛИіЖдЯѓЁЃRedisЕФsetНсЙЙвВЪЧвЛбљ,ЫќЕФФкВПвВЪЙгУhashНсЙЙ,ЫљгаЕФvalueЖМжИЯђЭЌвЛИіФкВПжЕЁЃ
##########################################################################
127.0.0.1:6379> sadd myset "hello" # setМЏКЯжаЬэМгдШЫй
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset "lovekuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset # ВщПДжИЖЈsetЕФЫљгажЕ
1) "hello"
2) "lovekuangshen"
3) "kuangshen"
127.0.0.1:6379> SISMEMBER myset hello # ХаЖЯФГвЛИіжЕЪЧВЛЪЧдкsetМЏКЯжа!
(integer) 1
127.0.0.1:6379> SISMEMBER myset world
(integer) 0
##########################################################################
127.0.0.1:6379> scard myset # ЛёШЁsetМЏКЯжаЕФФкШндЊЫиИіЪ§!
(integer) 4
##########################################################################
rem
127.0.0.1:6379> srem myset hello # вЦГ§setМЏКЯжаЕФжИЖЈдЊЫи
(integer) 1
127.0.0.1:6379> scard myset
(integer) 3
127.0.0.1:6379> SMEMBERS myset
1) "lovekuangshen2"
2) "lovekuangshen"
3) "kuangshen"
##########################################################################
set ЮоађВЛжиИДМЏКЯЁЃГщЫцЛњ!
127.0.0.1:6379> SMEMBERS myset
1) "lovekuangshen2"
2) "lovekuangshen"
3) "kuangshen"
127.0.0.1:6379> SRANDMEMBER myset # ЫцЛњГщбЁГівЛИідЊЫи
"kuangshen"
127.0.0.1:6379> SRANDMEMBER myset
"kuangshen"
127.0.0.1:6379> SRANDMEMBER myset
"kuangshen"
127.0.0.1:6379> SRANDMEMBER myset
"kuangshen"
127.0.0.1:6379> SRANDMEMBER myset 2 # ЫцЛњГщбЁГіжИЖЈИіЪ§ЕФдЊЫи
1) "lovekuangshen"
2) "lovekuangshen2"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "lovekuangshen"
2) "lovekuangshen2"
127.0.0.1:6379> SRANDMEMBER myset # ЫцЛњГщбЁГівЛИідЊЫи
"lovekuangshen2"
##########################################################################
ЩОГ§ЖЈЕФkey,ЫцЛњЩОГ§key!
127.0.0.1:6379> SMEMBERS myset
1) "lovekuangshen2"
2) "lovekuangshen"
3) "kuangshen"
127.0.0.1:6379> spop myset # ЫцЛњЩОГ§вЛаЉsetМЏКЯжаЕФдЊЫи!
"lovekuangshen2"
127.0.0.1:6379> spop myset
"lovekuangshen"
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
##########################################################################
НЋвЛИіжИЖЈЕФжЕ,вЦЖЏЕНСэЭтвЛИіsetМЏКЯ!
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset2 "set2"
(integer) 1
127.0.0.1:6379> smove myset myset2 "kuangshen" # НЋвЛИіжИЖЈЕФжЕ,вЦЖЏЕНСэЭтвЛИіsetМЏ
КЯ!
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "world"
2) "hello"
127.0.0.1:6379> SMEMBERS myset2
1) "kuangshen"
2) "set2"
##########################################################################
ЮЂВЉ,BеО,ЙВЭЌЙизЂ!(ВЂМЏ)
Ъ§зжМЏКЯРр:
- ВюМЏ SDIFF
- НЛМЏ
- ВЂМЏ
127.0.0.1:6379[8]> sadd key2 a
(integer) 1
127.0.0.1:6379[8]> sadd key2 b
(integer) 1
127.0.0.1:6379[8]> sadd key2 c
(integer) 1
127.0.0.1:6379[8]> sadd key3 c
(integer) 1
127.0.0.1:6379[8]> sadd key3 d
(integer) 1
127.0.0.1:6379[8]> sadd key3 e
(integer) 1
127.0.0.1:6379> SDIFF key2 key3 # ВюМЏ
1) "b"
2) "a"
127.0.0.1:6379> SINTER key2 key3 # НЛМЏ ЙВЭЌКУгбОЭПЩвдетбљЪЕЯж
1) "c"
127.0.0.1:6379> SUNION key2 key3 # ВЂМЏ
1) "b"
2) "c"
3) "e"
4) "a"
5) "d"
ЮЂВЉ,AгУЛЇНЋЫљгаЙизЂЕФШЫЗХдквЛИіsetМЏКЯжа!НЋЫќЕФЗлЫПвВЗХдквЛИіМЏКЯжа! ЙВЭЌЙизЂ,ЙВЭЌАЎКУ,ЖўЖШКУгб,ЭЦМіКУгб!(СљЖШЗжИюРэТл)
Hash(ЙўЯЃ)
Redis hash ЪЧвЛИіМќжЕЖдМЏКЯЁЃ
Redis hashЪЧвЛИіstringРраЭЕФfieldКЭvalueЕФгГЩфБэ,hashЬиБ№ЪЪКЯгУгкДцДЂЖдЯѓЁЃ
РрЫЦJavaРяУцЕФMap<String,Object>
гУЛЇIDЮЊВщевЕФkey,ДцДЂЕФvalueгУЛЇЖдЯѓАќКЌаеУћ,ФъСф,ЩњШеЕШаХЯЂ,ШчЙћгУЦеЭЈЕФkey/valueНсЙЙРДДцДЂ
жївЊгавдЯТ2жжДцДЂЗНЪН:
MapМЏКЯ,key-map! ЪБКђетИіжЕЪЧвЛИіmapМЏКЯ! БОжЪКЭStringРраЭУЛгаЬЋДѓЧјБ№,ЛЙЪЧвЛИіМђЕЅЕФ key-vlaue!
set myhash field kuangshen
ГЃгУУќСю
- hset ИјМЏКЯжаЕФ МќИГжЕ
- hget ДгМЏКЯШЁГі value
- hmset Ё ХњСПЩшжУhashЕФжЕ
- hexistsВщПДЙўЯЃБэ key жа,ИјЖЈгђ field ЪЧЗёДцдкЁЃ
- hkeys СаГіИУhashМЏКЯЕФЫљгаfield
- hvals СаГіИУhashМЏКЯЕФЫљгаvalue
- hincrby ЮЊЙўЯЃБэ key жаЕФгђ field ЕФжЕМгЩЯдіСП 1 -1
- hsetnx НЋЙўЯЃБэ key жаЕФгђ field ЕФжЕЩшжУЮЊ value ,ЕБЧвНіЕБгђ field ВЛДцдк .
##########################################################################
127.0.0.1:6379> hset myhash field1 kuangshen # setвЛИіОпЬх key-vlaue
(integer) 1
127.0.0.1:6379> hget myhash field1 # ЛёШЁвЛИізжЖЮжЕ
"kuangshen"
127.0.0.1:6379> hmset myhash field1 hello field2 world # setЖрИі key-vlaue
OK
127.0.0.1:6379> hmget myhash field1 field2 # ЛёШЁЖрИізжЖЮжЕ
1) "hello"
2) "world"
127.0.0.1:6379> hgetall myhash # ЛёШЁШЋВПЕФЪ§Он,
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> hdel myhash field1 # ЩОГ§hashжИЖЈkeyзжЖЮ!ЖдгІЕФvalueжЕвВОЭЯћЪЇСЫ!
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
##########################################################################
hlen
127.0.0.1:6379> hmset myhash field1 hello field2 world
OK
127.0.0.1:6379> HGETALL myhash
1) "field2"
2) "world"
3) "field1"
4) "hello"
127.0.0.1:6379> hlen myhash # ЛёШЁhashБэЕФзжЖЮЪ§СП!
(integer) 2
##########################################################################
127.0.0.1:6379> HEXISTS myhash field1 # ХаЖЯhashжажИЖЈзжЖЮЪЧЗёДцдк!
(integer) 1
127.0.0.1:6379> HEXISTS myhash field3
(integer) 0
##########################################################################
# жЛЛёЕУЫљгаfield
# жЛЛёЕУЫљгаvalue
127.0.0.1:6379> hkeys myhash # жЛЛёЕУЫљгаfield
1) "field2"
2) "field1"
127.0.0.1:6379> hvals myhash # жЛЛёЕУЫљгаvalue
1) "world"
2) "hello"
##########################################################################
incr
127.0.0.1:6379> hset myhash field3 5 #жИЖЈдіСП!
(integer) 1
127.0.0.1:6379> HINCRBY myhash field3 1
(integer) 6
127.0.0.1:6379> HINCRBY myhash field3 -1
(integer) 5
127.0.0.1:6379> hsetnx myhash field4 hello # ШчЙћВЛДцдкдђПЩвдЩшжУ
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world # ШчЙћДцдкдђВЛФмЩшжУ
(integer) 0
hashБфИќЕФЪ§Он user name age,гШЦфЪЧЪЧгУЛЇаХЯЂжЎРрЕФ,ОГЃБфЖЏЕФаХЯЂ! hash ИќЪЪКЯгкЖдЯѓЕФ ДцДЂ,StringИќМгЪЪКЯзжЗћДЎДцДЂ!
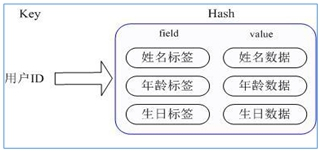
ЭЈЙ§ key(гУЛЇID) + field(ЪєадБъЧЉ) ОЭПЩвдВйзїЖдгІЪєадЪ§ОнСЫ,МШВЛашвЊжиИДДцДЂЪ§Он,вВВЛЛсДјРДађСаЛЏКЭВЂЗЂаоИФПижЦЕФЮЪЬт
Zset(гаађМЏКЯ)
ГЃгУУќСю:
-
zadd Ё
НЋвЛИіЛђЖрИі member дЊЫиМАЦф score жЕМгШыЕНгаађМЏ key ЕБжаЁЃ
-
zrange
[WITHSCORES] ЗЕЛигаађМЏ key жа,ЯТБъдк
жЎМфЕФдЊЫи ДјWITHSCORES,ПЩвдШУЗжЪ§вЛЦ№КЭжЕЗЕЛиЕННсЙћМЏЁЃ
-
zrangebyscore key minmax [withscores] [limit offset count]
ЗЕЛигаађМЏ key жа,Ыљга score жЕНщгк min КЭ max жЎМф(АќРЈЕШгк min Лђ max )ЕФГЩдБЁЃгаађМЏГЩдБАД score жЕЕнді(ДгаЁЕНДѓ)ДЮађХХСаЁЃ
-
zrevrangebyscore key maxmin [withscores] [limit offset count]
ЭЌЩЯ,ИФЮЊДгДѓЕНаЁХХСаЁЃ
-
zincrby ЮЊдЊЫиЕФscoreМгЩЯдіСП
-
zrem ЩОГ§ИУМЏКЯЯТ,жИЖЈжЕЕФдЊЫи
-
zcount ЭГМЦИУМЏКЯ,ЗжЪ§ЧјМфФкЕФдЊЫиИіЪ§
-
zrank ЗЕЛиИУжЕдкМЏКЯжаЕФХХУћ,Дг0ПЊЪМЁЃ
дкsetЕФЛљДЁЩЯ,діМгСЫвЛИіжЕ,set k1 v1 zset k1 score1 v1
127.0.0.1:6379> hvals myhash # жЛЛёЕУЫљгаvalue
1) "world"
2) "hello"
##########################################################################
incr decr
127.0.0.1:6379> hset myhash field3 5 #жИЖЈдіСП!
(integer) 1
127.0.0.1:6379> HINCRBY myhash field3 1
(integer) 6
127.0.0.1:6379> HINCRBY myhash field3 -1
(integer) 5
127.0.0.1:6379> hsetnx myhash field4 hello # ШчЙћВЛДцдкдђПЩвдЩшжУ
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world # ШчЙћДцдкдђВЛФмЩшжУ
(integer) 0
127.0.0.1:6379> zadd myset 1 one # ЬэМгвЛИіжЕ
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three # ЬэМгЖрИіжЕ
(integer) 2
127.0.0.1:6379> ZRANGE myset 0 -1
1) "one"
2) "two"
3) "three"
##########################################################################
ХХађШчКЮЪЕЯж
127.0.0.1:6379> zadd salary 2500 xiaohong # ЬэМгШ§ИігУЛЇ
(integer) 1
127.0.0.1:6379> zadd salary 5000 zhangsan
(integer) 1
127.0.0.1:6379> zadd salary 500 kaungshen
(integer) 1
# ZRANGEBYSCORE key min max
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # ЯдЪОШЋВПЕФгУЛЇ ДгаЁЕНДѓ!
1) "kaungshen"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> ZREVRANGE salary 0 -1 # ДгДѓЕННјааХХађ!
1) "zhangsan"
2) "kaungshen"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # ЯдЪОШЋВПЕФгУЛЇВЂЧвИНДјГЩ
МЈ
1) "kaungshen"
2) "500"
3) "xiaohong"
4) "2500"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 withscores # ЯдЪОЙЄзЪаЁгк2500дБЙЄЕФЩ§
ађХХађ!
1) "kaungshen"
2) "500"
3) "xiaohong"
4) "2500"
##########################################################################
# вЦГ§remжаЕФдЊЫи
127.0.0.1:6379> zrange salary 0 -1
1) "kaungshen"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> zrem salary xiaohong # вЦГ§гаађМЏКЯжаЕФжИЖЈдЊЫи
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) "kaungshen"
2) "zhangsan"
127.0.0.1:6379> zcard salary # ЛёШЁгаађМЏКЯжаЕФИіЪ§
(integer) 2
##########################################################################
127.0.0.1:6379> zadd myset 1 hello
(integer) 1
127.0.0.1:6379> zadd myset 2 world 3 kuangshen
(integer) 2
127.0.0.1:6379> zcount myset 1 3 # ЛёШЁжИЖЈЧјМфЕФГЩдБЪ§СП!
(integer) 3
127.0.0.1:6379> zcount myset 1 2
(integer) 2
ЦфгыЕФвЛаЉAPI,ЭЈЙ§ЮвУЧЕФбЇЯАТ№,ФуУЧЪЃЯТЕФШчЙћЙЄзїжагаашвЊ,етИіЪБКђФуПЩвдШЅВщВщПДЙйЗНЮФ ЕЕ!
АИР§ЫМТЗ:set ХХађ
- ДцДЂАрМЖГЩМЈБэ,ЙЄзЪБэХХађ!
- ЦеЭЈЯћЯЂ,1, живЊЯћЯЂ 2,ДјШЈжиНјааХаЖЯ!
- ХХааАёгІгУЪЕЯж,ШЁTop N ВтЪд!
SortedSet(zset)ЪЧRedisЬсЙЉЕФвЛИіЗЧГЃЬиБ№ЕФЪ§ОнНсЙЙ,вЛЗНУцЫќЕШМлгкJavaЕФЪ§ОнНсЙЙMap<String, Double>,ПЩвдИјУПвЛИідЊЫиvalueИГгшвЛИіШЈжиscore,СэвЛЗНУцЫќгжРрЫЦгкTreeSet,ФкВПЕФдЊЫиЛсАДееШЈжиscoreНјааХХађ,ПЩвдЕУЕНУПИідЊЫиЕФУћДЮ,ЛЙПЩвдЭЈЙ§scoreЕФЗЖЮЇРДЛёШЁдЊЫиЕФСаБэЁЃ
zsetЕзВуЪЙгУСЫСНИіЪ§ОнНсЙЙ
(1)hash,hashЕФзїгУОЭЪЧЙиСЊдЊЫиvalueКЭШЈжиscore,БЃеЯдЊЫиvalueЕФЮЈвЛад,ПЩвдЭЈЙ§дЊЫиvalueевЕНЯргІЕФscoreжЕЁЃ
(2)ЬјдОБэ,ЬјдОБэЕФФПЕФдкгкИјдЊЫиvalueХХађ,ИљОнscoreЕФЗЖЮЇЛёШЁдЊЫиСаБэЁЃ
Ш§жжЬиЪтЪ§Он
Geospatial ЕиРэЮЛжУ
Redis 3.2 жадіМгСЫЖдGEOРраЭЕФжЇГжЁЃGEO,Geographic,ЕиРэаХЯЂЕФЫѕаДЁЃИУРраЭ,ОЭЪЧдЊЫиЕФ2ЮЌзјБъ,дкЕиЭМЩЯОЭЪЧОЮГЖШЁЃredisЛљгкИУРраЭ,ЬсЙЉСЫОЮГЖШЩшжУ,ВщбЏ,ЗЖЮЇВщбЏ,ОрРыВщбЏ,ОЮГЖШHashЕШГЃМћВйзїЁЃ
етИіЙІФмПЩвдЭЦЫуЕиРэЮЛжУЕФаХЯЂ,СНЕижЎМфЕФОрРы,ЗНдВ МИРяЕФШЫ! ПЩвдВщбЏвЛаЉВтЪдЪ§Он:http://www.jsons.cn/lngcodeinfo/0706D99C19A781A3/ жЛга СљИіУќСю:
ЙйЗНЮФЕЕ:https://www.redis.net.cn/order/3685.html
getadd
# getadd ЬэМгЕиРэЮЛжУ
# Йцдђ:СНМЖЮоЗЈжБНгЬэМг,ЮвУЧвЛАуЛсЯТдиГЧЪаЪ§Он,жБНгЭЈЙ§javaГЬађвЛДЮадЕМШы!
# гааЇЕФОЖШДг-180ЖШЕН180ЖШЁЃ
# гааЇЕФЮГЖШДг-85.05112878ЖШЕН85.05112878ЖШЁЃ
# ЕБзјБъЮЛжУГЌГіЩЯЪіжИЖЈЗЖЮЇЪБ,ИУУќСюНЋЛсЗЕЛивЛИіДэЮѓЁЃ
# ВЮЪ§ key жЕ()
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqi 114.05 22.52 shengzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
getpos
ЛёЕУЕБЧАЖЈЮЛ:вЛЖЈЪЧвЛИізјБъжЕ!
127.0.0.1:6379> GEOPOS china:city beijing # ЛёШЁжИЖЈЕФГЧЪаЕФОЖШКЭЮГЖШ!
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> GEOPOS china:city beijing chongqi
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
GEODIST
СНШЫжЎМфЕФОрРы! ЕЅЮЛ:
- m БэЪОЕЅЮЛЮЊУзЁЃ
- km БэЪОЕЅЮЛЮЊЧЇУзЁЃ
- mi БэЪОЕЅЮЛЮЊгЂРяЁЃ
- ft БэЪОЕЅЮЛЮЊгЂГпЁЃ
127.0.0.1:6379> GEODIST china:city beijing shanghai km # ВщПДЩЯКЃЕНББОЉЕФжБЯпОрРы
"1067.3788"
127.0.0.1:6379> GEODIST china:city beijing chongqi km # ВщПДжиЧьЕНББОЉЕФжБЯпОрРы
"1464.0708"
georadius вдИјЖЈЕФОЮГЖШЮЊжааФ, евГіФГвЛАыОЖФкЕФдЊЫи
ЮвИННќЕФШЫ? (ЛёЕУЫљгаИННќЕФШЫЕФЕижЗ,ЖЈЮЛ!)ЭЈЙ§АыОЖРДВщбЏ! ЛёЕУжИЖЈЪ§СПЕФШЫ,200 ЫљгаЪ§ОнгІИУЖМТМШы:china:city ,ВХЛсШУНсЙћИќМгЧыЧѓ!
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # вд110,30 етИіОЮГЖШЮЊжааФ,бА
евЗНдВ1000kmФкЕФГЧЪа
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km
1) "chongqi"
2) "xian"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist # ЯдЪОЕНжаМфОрРыЕФЮЛжУ
1) 1) "chongqi"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withcoord # ЯдЪОЫћШЫЕФЖЈЮЛаХЯЂ
1) 1) "chongqi"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 1 #ЩИбЁГіжИЖЈЕФНсЙћ!
1) 1) "chongqi"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 2
1) 1) "chongqi"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
GEORADIUSBYMEMBER
# евГіЮЛгкжИЖЈдЊЫижмЮЇЕФЦфЫћдЊЫи!
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
GEOHASH УќСю - ЗЕЛивЛИіЛђЖрИіЮЛжУдЊЫиЕФ Geohash БэЪО
ИУУќСюНЋЗЕЛи11ИізжЗћЕФGeohashзжЗћДЎ
# НЋЖўЮЌЕФОЮГЖШзЊЛЛЮЊвЛЮЌЕФзжЗћДЎ,ШчЙћСНИізжЗћДЎдННгНќ,ФЧУДдђОрРыдННќ!
127.0.0.1:6379> geohash china:city beijing chongqing
1) "wx4fbxxfke0"
2) "xt4purb89n0"
GEO ЕзВуЕФЪЕЯждРэЦфЪЕОЭЪЧ Zset!ЮвУЧПЩвдЪЙгУZsetУќСюРДВйзїgeo!
127.0.0.1:6379> ZRANGE china:city 0 -1 # ВщПДЕиЭМжаШЋВПЕФдЊЫи
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> zrem china:city beijing # вЦГ§жИЖЈдЊЫи!
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"
Hyperloglog
ЪВУДЪЧЛљЪ§?
A {1,3,5,7,8,7} B{1,3,5,7,8}
ЛљЪ§(ВЛжиИДЕФдЊЫи) = 5,ПЩвдНгЪмЮѓВю!
МђНщ
Redis 2.8.9 АцБООЭИќаТСЫ Hyperloglog Ъ§ОнНсЙЙ! Redis Hyperloglog ЛљЪ§ЭГМЦЕФЫуЗЈ!
гХЕу:еМгУЕФФкДцЪЧЙЬЖЈ,2^64 ВЛЭЌЕФдЊЫиЕФЛљЪ§,жЛашвЊЗЯ 12KBФкДц!ШчЙћвЊДгФкДцНЧЖШРДБШНЯЕФ ЛА Hyperloglog ЪзбЁ!
дкЙЄзїЕБжа,ЮвУЧОГЃЛсгіЕНгыЭГМЦЯрЙиЕФЙІФмашЧѓ,БШШчЭГМЦЭјеОPV(PageViewвГУцЗУЮЪСП),ПЩвдЪЙгУRedisЕФincrЁЂincrbyЧсЫЩЪЕЯжЁЃ
ЕЋЯёUV(UniqueVisitor,ЖРСЂЗУПЭ)ЁЂЖРСЂIPЪ§ЁЂЫбЫїМЧТМЪ§ЕШашвЊШЅжиКЭМЦЪ§ЕФЮЪЬтШчКЮНтОі?етжжЧѓМЏКЯжаВЛжиИДдЊЫиИіЪ§ЕФЮЪЬтГЦЮЊЛљЪ§ЮЪЬтЁЃ
НтОіЛљЪ§ЮЪЬтгаКмЖржжЗНАИ:
(1)Ъ§ОнДцДЂдкMySQLБэжа,ЪЙгУdistinct countМЦЫуВЛжиИДИіЪ§
(2)ЪЙгУRedisЬсЙЉЕФhashЁЂsetЁЂbitmapsЕШЪ§ОнНсЙЙРДДІРэ
вдЩЯЕФЗНАИНсЙћОЋШЗ,ЕЋЫцзХЪ§ОнВЛЖЯдіМг,ЕМжТеМгУПеМфдНРДдНДѓ,ЖдгкЗЧГЃДѓЕФЪ§ОнМЏЪЧВЛЧаЪЕМЪЕФЁЃ
ФмЗёФмЙЛНЕЕЭвЛЖЈЕФОЋЖШРДЦНКтДцДЂПеМф?RedisЭЦГіСЫHyperLogLog
Redis HyperLogLog ЪЧгУРДзіЛљЪ§ЭГМЦЕФЫуЗЈ,HyperLogLog ЕФгХЕуЪЧ,дкЪфШыдЊЫиЕФЪ§СПЛђепЬхЛ§ЗЧГЃЗЧГЃДѓЪБ,МЦЫуЛљЪ§ЫљашЕФПеМфзмЪЧЙЬЖЈЕФЁЂВЂЧвЪЧКмаЁЕФЁЃ
дк Redis РяУц,УПИі HyperLogLog МќжЛашвЊЛЈЗб 12 KB ФкДц,ОЭПЩвдМЦЫуНгНќ 2^64 ИіВЛЭЌдЊЫиЕФЛљЪ§ЁЃетКЭМЦЫуЛљЪ§ЪБ,дЊЫидНЖрКФЗбФкДцОЭдНЖрЕФМЏКЯаЮГЩЯЪУїЖдБШЁЃ
ЕЋЪЧ,вђЮЊ HyperLogLog жЛЛсИљОнЪфШыдЊЫиРДМЦЫуЛљЪ§,ЖјВЛЛсДЂДцЪфШыдЊЫиБОЩэ,Ыљвд HyperLogLog ВЛФмЯёМЏКЯФЧбљ,ЗЕЛиЪфШыЕФИїИідЊЫиЁЃ
ВтЪдЪЙгУ
127.0.0.1:6379> PFadd mykey a b c d e f g h i j # ДДНЈЕквЛзщдЊЫи mykey
(integer) 1
127.0.0.1:6379> PFCOUNT mykey # ЭГМЦ mykey дЊЫиЕФЛљЪ§Ъ§СП
(integer) 10
127.0.0.1:6379> PFadd mykey2 i j z x c v b n m # ДДНЈЕкЖўзщдЊЫи mykey2
(integer) 1
127.0.0.1:6379> PFCOUNT mykey2
(integer) 9
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 # КЯВЂСНзщ mykey mykey2 => mykey3 ВЂМЏ
OK
127.0.0.1:6379> PFCOUNT mykey3 # ПДВЂМЏЕФЪ§СП!
(integer) 15
- pfadd
(1)ИёЪН
pfadd < element> [element Ё] ЬэМгжИЖЈдЊЫиЕН HyperLogLog жа
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-d8FIvlxD-1642577976053)(C:/Users/77/AppData/Local/Temp/ksohtml/wps665F.tmp.jpg)]
(2)ЪЕР§
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-kwqtIZCt-1642577976054)(C:/Users/77/AppData/Local/Temp/ksohtml/wps6660.tmp.jpg)]
? НЋЫљгадЊЫиЬэМгЕНжИЖЈHyperLogLogЪ§ОнНсЙЙжаЁЃШчЙћжДааУќСюКѓHLLЙРМЦЕФНќЫЦЛљЪ§ЗЂЩњБфЛЏ,дђЗЕЛи1,ЗёдђЗЕЛи0ЁЃ
2.pfcount
(1)ИёЪН
pfcount [key Ё] МЦЫуHLLЕФНќЫЦЛљЪ§,ПЩвдМЦЫуЖрИіHLL,БШШчгУHLLДцДЂУПЬьЕФUV,МЦЫувЛжмЕФUVПЩвдЪЙгУ7ЬьЕФUVКЯВЂМЦЫуМДПЩ
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-DBZDL2ek-1642577976054)(C:/Users/77/AppData/Local/Temp/ksohtml/wps6661.tmp.jpg)]
(2)ЪЕР§
- pfmerge
(1)ИёЪН
pfmerge [sourcekey Ё] НЋвЛИіЛђЖрИіHLLКЯВЂКѓЕФНсЙћДцДЂдкСэвЛИіHLLжа,БШШчУПдТЛюдОгУЛЇПЩвдЪЙгУУПЬьЕФЛюдОгУЛЇРДКЯВЂМЦЫуПЩЕУ
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-RyraT8SB-1642577976055)(C:/Users/77/AppData/Local/Temp/ksohtml/wps6673.tmp.jpg)]
(2)ЪЕР§
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-XE3FgZ2x-1642577976055)(C:/Users/77/AppData/Local/Temp/ksohtml/wps6674.tmp.jpg)]
**ШчЙћдЪаэШнДэ,ФЧУДвЛЖЈПЩвдЪЙгУ Hyperloglog ! **
ШчЙћВЛдЪаэШнДэ,ОЭЪЙгУ set ЛђепздМКЕФЪ§ОнРраЭМДПЩ!
Bitmap
ЯжДњМЦЫуЛњгУЖўНјжЦ(ЮЛ) зїЮЊаХЯЂЕФЛљДЁЕЅЮЛ, 1ИізжНкЕШгк8ЮЛ, Р§ШчЁАabcЁБзжЗћДЎЪЧгЩ3ИізжНкзщГЩ, ЕЋЪЕМЪдкМЦЫуЛњДцДЂЪБНЋЦфгУЖўНјжЦБэЪО, ЁАabcЁБЗжБ№ЖдгІЕФASCIIТыЗжБ№ЪЧ97ЁЂ 98ЁЂ 99, ЖдгІЕФЖўНјжЦЗжБ№ЪЧ01100001ЁЂ 01100010КЭ01100011,ШчЯТЭМ
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-umIBHqyR-1642577976055)(C:/Users/77/AppData/Local/Temp/ksohtml/wpsBAA6.tmp.jpg)]
КЯРэЕиЪЙгУВйзїЮЛФмЙЛгааЇЕиЬсИпФкДцЪЙгУТЪКЭПЊЗЂаЇТЪЁЃ
RedisЬсЙЉСЫBitmapsетИіЁАЪ§ОнРраЭЁБПЩвдЪЕЯжЖдЮЛЕФВйзї:
(1) BitmapsБОЩэВЛЪЧвЛжжЪ§ОнРраЭ, ЪЕМЪЩЯЫќОЭЪЧзжЗћДЎ(key-value) , ЕЋЪЧЫќПЩвдЖдзжЗћДЎЕФЮЛНјааВйзїЁЃ
(2) BitmapsЕЅЖРЬсЙЉСЫвЛЬзУќСю, ЫљвддкRedisжаЪЙгУBitmapsКЭЪЙгУзжЗћДЎЕФЗНЗЈВЛЬЋЯрЭЌЁЃ ПЩвдАбBitmapsЯыЯѓГЩвЛИівдЮЛЮЊЕЅЮЛЕФЪ§зщ, Ъ§зщЕФУПИіЕЅдЊжЛФмДцДЂ0КЭ1, Ъ§зщЕФЯТБъдкBitmapsжаНазіЦЋвЦСПЁЃ

ЮЛДцДЂ
ЭГМЦгУЛЇаХЯЂ,ЛюдО,ВЛЛюдО! ЕЧТМ ЁЂ ЮДЕЧТМ! ДђПЈ,365ДђПЈ! СНИізДЬЌЕФ,ЖМПЩвдЪЙгУ Bitmaps! Bitmap ЮЛЭМ,Ъ§ОнНсЙЙ! ЖМЪЧВйзїЖўНјжЦЮЛРДНјааМЧТМ,ОЭжЛга0 КЭ 1 СНИізДЬЌ!
365 Ьь = 365 bit
1зжНк = 8bit
46 ИізжНкзѓгв!
ВтЪд
ЪЙгУbitmap РДМЧТМ жмвЛЕНжмШеЕФДђПЈ!
жмвЛ:1
жмЖў:0
жмШ§:0
жмЫФ:1 Ё
ВщПДФГвЛЬьЪЧЗёгаДђПЈ!
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 6
(integer) 0
ЭГМЦВйзї,ЭГМЦ ДђПЈЕФЬьЪ§!
127.0.0.1:6379> bitcount sign # ЭГМЦетжмЕФДђПЈМЧТМ,ОЭПЩвдПДЕНЪЧЗёгаШЋЧк!
(integer) 3
ЪТЮё
Redis ЪТЮёБОжЪ:вЛзщУќСюЕФМЏКЯ! вЛИіЪТЮёжаЕФЫљгаУќСюЖМЛсБЛађСаЛЏ,дкЪТЮёжДааЙ§ГЬЕФжа,ЛсАДееЫГађжДаа!
вЛДЮадЁЂЫГађадЁЂХХЫћад!жДаавЛЯЕСаЕФУќСю!
------ ЖгСа set set set жДаа------
RedisЪТЮёУЛгаУЛгаИєРыМЖБ№ЕФИХФю! ЫљгаЕФУќСюдкЪТЮёжа,ВЂУЛгажБНгБЛжДаа!жЛгаЗЂЦ№жДааУќСюЕФЪБКђВХЛсжДаа!
RedisЪЧЕЅЬѕУќСюЪНБЃДцдзгадЕФ,ЕЋЪЧЪТЮёВЛБЃжЄдзгад! Exec
redisЕФЪТЮё:
- ПЊЦєЪТЮё(multi)
- УќСюШыЖг(Ё)
- жДааЪТЮё(exec)
- discardЗХЦњзщЖг
- watch
- unwatch
е§ГЃжДааЪТЮё!
127.0.0.1:6379> multi # ПЊЦєЪТЮё
OK
# УќСюШыЖг
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec # жДааЪТЮё
1) OK
2) OK
3) "v2"
4) OK
ЗХЦњЪТЮё!(DISCARD )
127.0.0.1:6379> multi # ПЊЦєЪТЮё
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> DISCARD # ШЁЯћЪТЮё
OK
127.0.0.1:6379> get k4 # ЪТЮёЖгСажаУќСюЖМВЛЛсБЛжДаа!
(nil)
БрвыаЭвьГЃ(ДњТыгаЮЪЬт! УќСюгаДэ!) ЪТЮёжаЫљгаЕФУќСюЖМВЛЛсБЛжДаа!
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3 # ДэЮѓЕФУќСю
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec # жДааЪТЮёБЈДэ!
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k5 # ЫљгаЕФУќСюЖМВЛЛсБЛжДаа!
(nil)
дЫааЪБвьГЃ(1/0), ШчЙћЪТЮёЖгСажаДцдкгяЗЈад,ФЧУДжДааУќСюЕФЪБКђ,ЦфЫћУќСюЪЧПЩвде§ГЃжДааЕФ,ДэЮѓУќСюХзГівьГЃ!
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr k1 # ЛсжДааЕФЪБКђЪЇАм!
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> exec
1) (error) ERR value is not an integer or out of range # ЫфШЛЕквЛЬѕУќСюБЈДэСЫ,ЕЋЪЧ
вРОЩе§ГЃжДааГЩЙІСЫ!
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
МрПи! Watch (УцЪдГЃЮЪ!)
БЏЙлЫј:
- КмБЏЙл,ШЯЮЊЪВУДЪБКђЖМЛсГіЮЪЬт,ЮоТлзіЪВУДЖМЛсМгЫј!
РжЙлЫј:
- КмРжЙл,ШЯЮЊЪВУДЪБКђЖМВЛЛсГіЮЪЬт,ЫљвдВЛЛсЩЯЫј! - - ИќаТЪ§ОнЕФЪБКђШЅХаЖЯвЛЯТ,дкДЫЦкМфЪЧЗёгаШЫаоИФЙ§етИіЪ§Он,
- ЛёШЁversion
- ИќаТЕФЪБКђБШНЯ version
RedisВтМрЪгВтЪд
е§ГЃжДааГЩЙІ
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # МрЪг money ЖдЯѓ
OK
127.0.0.1:6379> multi # ЪТЮёе§ГЃНсЪј,Ъ§ОнЦкМфУЛгаЗЂЩњБфЖЏ,етИіЪБКђОЭе§ГЃжДааГЩЙІ!
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY out 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
ВтЪдЖрЯпГЬаоИФжЕ , ЪЙгУwatch ПЩвдЕБзіredisЕФРжЙлЫјВйзї!
127.0.0.1:6379> watch money # МрЪг money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 10
QUEUED
127.0.0.1:6379> INCRBY out 10
QUEUED
127.0.0.1:6379> exec # жДаажЎЧА,СэЭтвЛИіЯпГЬ,аоИФСЫЮвУЧЕФжЕ,етИіЪБКђ,ОЭЛсЕМжТЪТЮёжДааЪЇ
Ам!
(nil)
ШчЙћаоИФЪЇАм,ЛёШЁзюаТЕФжЕОЭКУ

redisЪТЮёЕФШ§ДѓЬиад
- ЕЅЖРЕФИєРыВйзї
- ЪТЮёжаЕФЫљгаУќСюЖМЛсађСаЛЏЁЂАДЫГађЕижДааЁЃЪТЮёдкжДааЕФЙ§ГЬжа,ВЛЛсБЛЦфЫћПЭЛЇЖЫЗЂЫЭРДЕФУќСюЧыЧѓЫљДђЖЯЁЃ
- УЛгаИєРыМЖБ№ЕФИХФю
- ЖгСажаЕФУќСюУЛгаЬсНЛжЎЧАЖМВЛЛсЪЕМЪБЛжДаа,вђЮЊЪТЮёЬсНЛЧАШЮКЮжИСюЖМВЛЛсБЛЪЕМЪжДаа
- ВЛБЃжЄдзгад
- ЪТЮёжаШчЙћгавЛЬѕУќСюжДааЪЇАм,ЦфКѓЕФУќСюШдШЛЛсБЛжДаа,УЛгаЛиЙі
Jedis
ЮвУЧвЊЪЙгУ Java РДВйзї Redis,жЊЦфШЛВЂжЊЦфЫљвдШЛ,ЪкШЫвдгц! бЇЯАВЛФмМБдъ,Т§Т§РДЛсКмПь!
ЪВУДЪЧJedis ЪЧ Redis ЙйЗНЭЦМіЕФ javaСЌНгПЊЗЂЙЄОп! ЪЙгУJava ВйзїRedis жаМфМў!ШчЙћФувЊЪЙгУ javaВйзїredis,ФЧУДвЛЖЈвЊЖдJedis ЪЎЗжЕФЪьЯЄ!
ВтЪд
- ЕМШыЖдгІЕФвРРЕ
<!--ЕМШыjedisЕФАќ-->
<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
- БрТыВтЪд:
-
СЌНгЪ§ОнПт
-
ВйзїУќСю
-
ЖЯПЊСЌНг!
-
СЌНгАЂРядЦЕФВНжш
-
0.ШЗЖЈАЂРядЦАВШЋзщПЊЦєСЫ6379ЖЫПк
-
1.зЂЪЭbind 127.0.0.0
-
2.Абprotected-modeЩшжУЮЊno
-
3.ВщПДЗРЛ№ЧНЖЫПкЪЧЖМПЊЦєСЫ6379
-
firewall-cmd --list-ports -
4.ПЊЦє6379/tcpЗРЛ№ЧНЖЫПк
-
5.жиЦєredis
-
1ЁЂfirewall-cmd --zone=public --add-port=6379/tcp --permanet # ПЊЗХЖЫПк 2ЁЂsystemctl restart firewalld.service # жиЦє
-
package xiaoqi;
import redis.clients.jedis.Jedis;
public class TestPing {
public static void main(String[] args) {
// 1. new jedisЖдЯѓ
Jedis jedis = new Jedis("8.142.110.229",6379);
//jedis.auth("redisЕФУмТы,гаОЭаДУЛгаОЭВЛаД");
// jedis ЫљгаЕФУќСюОЭЪЧЮвУЧжЎЧАбЇЯАЕФЫљгажИСю!ЫљвджЎЧАЕФжИСюбЇЯАКмживЊ!
System.out.println(jedis.ping());
}
}
ЪфГі: 
ГЃгУЕФAPI
- String
- List
- Set
- Hash
- Zset
ЫљгаЕФapiУќСю,ОЭЪЧЮвУЧЖдгІЕФЩЯУцбЇЯАЕФжИСю,вЛИіЖМУЛгаБфЛЏ!
ЪТЮё
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","kuangshen");
// ПЊЦєЪТЮё
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(result)
try {
multi.set("user1",result);
multi.set("user2",result);
int i = 1/0 ; // ДњТыХзГівьГЃЪТЮё,жДааЪЇАм!
multi.exec(); // жДааЪТЮё!
} catch (Exception e) {
multi.discard(); // ЗХЦњЪТЮё
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close(); // ЙиБеСЌНг
}
}
}
SpringBootећКЯ
SpringBoot ВйзїЪ§Он:spring-data jpa jdbc mongodb redis!
SpringData вВЪЧКЭ SpringBoot ЦыУћЕФЯюФП!
ЫЕУї: дк SpringBoot2.x жЎКѓ,дРДЪЙгУЕФjedis БЛЬцЛЛЮЊСЫ lettuce
jedis : ВЩгУЕФжБСЌ,ЖрИіЯпГЬВйзїЕФЛА,ЪЧВЛАВШЋЕФ,ШчЙћЯывЊБмУтВЛАВШЋЕФ,ЪЙгУ jedis pool СЌНг Ги! ИќЯё BIO ФЃЪН
lettuce : ВЩгУnetty,ЪЕР§ПЩвддйЖрИіЯпГЬжаНјааЙВЯэ,ВЛДцдкЯпГЬВЛАВШЋЕФЧщПі!ПЩвдМѕЩйЯпГЬЪ§Он СЫ,ИќЯё NIO ФЃЪН
дДТыЗжЮі:
@Bean
@ConditionalOnMissingBean(name = "redisTemplate") // ЮвУЧПЩвдздМКЖЈвхвЛИіredisTemplateРДЬцЛЛетИіФЌШЯЕФ!
public RedisTemplate<Object, Object>redisTemplate(RedisConnectionFactory redisConnectionFactory)throws UnknownHostException {
// ФЌШЯЕФ RedisTemplate УЛгаЙ§ЖрЕФЩшжУ,redis ЖдЯѓЖМЪЧашвЊађСаЛЏ!
// СНИіЗКаЭЖМЪЧ Object, Object ЕФРраЭ,ЮвУЧКѓЪЙгУашвЊЧПжЦзЊЛЛ <String, Object>
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // гЩгк String ЪЧredisжазюГЃЪЙгУЕФРраЭ,ЫљвдЫЕЕЅЖРЬсГіРДСЫвЛИіbean!
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
ећКЯВтЪдвЛЯТ
- ЕМШывРРЕ
<!-- Вйзїredis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- ХфжУСЌНг
# ХфжУredis
spring.redis.host=127.0.0.1
spring.redis.port=6379
- ВтЪд!
@SpringBootTest
class Redis02SpringbootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
// redisTemplate ВйзїВЛЭЌЕФЪ§ОнРраЭ,apiКЭЮвУЧЕФжИСюЪЧвЛбљЕФ
// opsForValue ВйзїзжЗћДЎ РрЫЦString
// opsForList ВйзїList РрЫЦList
// opsForSet
// opsForHash
// opsForZSet
// opsForGeo
// opsForHyperLogLog
// Г§СЫНјБОЕФВйзї,ЮвУЧГЃгУЕФЗНЗЈЖМПЩвджБНгЭЈЙ§redisTemplateВйзї,БШШчЪТЮё,КЭЛљБОЕФ CRUD
// ЛёШЁredisЕФСЌНгЖдЯѓ
// RedisConnection connection =
redisTemplate.getConnectionFactory().getConnection();
// connection.flushDb();
// connection.flushAll();
redisTemplate.opsForValue().set("mykey","ЙизЂПёЩёЫЕЙЋжкКХ");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}
}
ЙигкЖдЯѓЕФБЃДц:
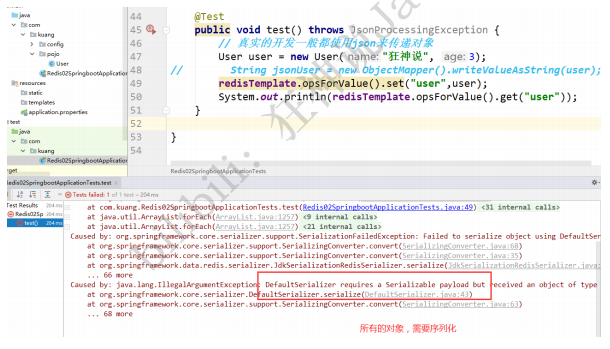
ЮвУЧРДБраДвЛИіздМКЕФ RedisTemplete
package com.kuang.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
// етЪЧЮвИјДѓМваДКУЕФвЛИіЙЬЖЈФЃАх,ДѓМвдкЦѓвЕжа,ФУШЅОЭПЩвджБНгЪЙгУ!
// здМКЖЈвхСЫвЛИі RedisTemplate
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// ЮвУЧЮЊСЫздМКПЊЗЂЗНБу,вЛАужБНгЪЙгУ <String,Object>
RedisTemplate<String, Object> template = new RedisTemplate<String,Object>();
template.setConnectionFactory(factory);
// JsonађСаЛЏХфжУ
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new
Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String ЕФађСаЛЏ
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// keyВЩгУStringЕФађСаЛЏЗНЪН
template.setKeySerializer(stringRedisSerializer);
// hashЕФkeyвВВЩгУStringЕФађСаЛЏЗНЪН
template.setHashKeySerializer(stringRedisSerializer);
// valueађСаЛЏЗНЪНВЩгУjackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hashЕФvalueађСаЛЏЗНЪНВЩгУjackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
ЫљгаЕФredisВйзї,ЦфЪЕЖдгкjavaПЊЗЂШЫдБРДЫЕ,ЪЎЗжЕФМђЕЅ,ИќживЊЪЧвЊШЅРэНтredisЕФЫМЯыКЭУПвЛжжЪ§ ОнНсЙЙЕФгУДІКЭзїгУГЁОА!
Redis.confЯъНт
ЦєЖЏЕФЪБКђ,ОЭЭЈЙ§ХфжУЮФМўРДЦєЖЏ! ЙЄзїжа,вЛаЉаЁаЁЕФХфжУ,ПЩвдШУФуЭбгБЖјГі!
ЕЅЮЛ
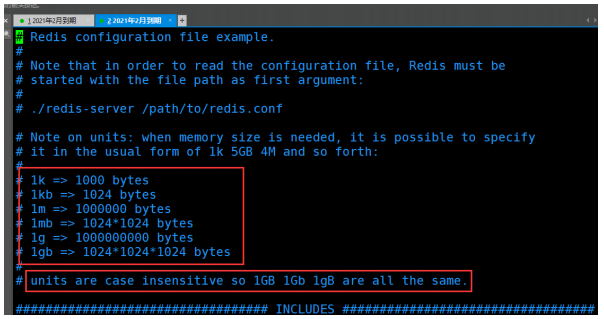
- ХфжУЮФМў unitЕЅЮЛ ЖдДѓаЁаДВЛУєИа!
АќКЌ ХфжУЖрИіЮФМў
ОЭЪЧКУБШЮвУЧбЇЯАSpringЁЂImprot, include
ЭјТч
bind 127.0.0.1 # АѓЖЈЕФБОЛњЕФip,дЖГЬСЌНгашвЊзЂЪЭ
protected-mode yes # БЃЛЄФЃЪН ВЛЪЧБОЕиашвЊИФЮЊno
port 6379 # ЖЫПкЩшжУ
ЭЈгУ GENERAL
daemonize yes # вдЪиЛЄНјГЬЕФЗНЪНдЫаа,ФЌШЯЪЧ no,ЮвУЧашвЊздМКПЊЦєЮЊyes!
pidfile /var/run/redis_6379.pid # ШчЙћвдКѓЬЈЕФЗНЪНдЫаа,ЮвУЧОЭашвЊжИЖЈвЛИі pid ЮФМў!
# ШежО
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) ЩњВњЛЗОГ
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" # ШежОЕФЮФМўЮЛжУУћ
databases 16 # Ъ§ОнПтЕФЪ§СП,ФЌШЯЪЧ 16 ИіЪ§ОнПт
always-show-logo yes # ЪЧЗёзмЪЧЯдЪОLOGO
Пьее
ГжОУЛЏ, дкЙцЖЈЕФЪБМфФк,жДааСЫЖрЩйДЮВйзї,дђЛсГжОУЛЏЕНЮФМў .rdb. aof
redis ЪЧФкДцЪ§ОнПт,ШчЙћУЛгаГжОУЛЏ,ФЧУДЪ§ОнЖЯЕчМАЪЇ!
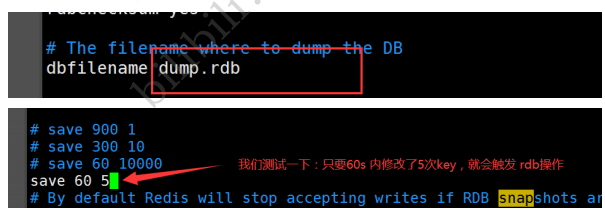
# ШчЙћ900sФк,ШчЙћжСЩйгавЛИі1 keyНјааСЫаоИФ,ЮвУЧМАНјааГжОУЛЏВйзї
save 900 1
# ШчЙћ300sФк,ШчЙћжСЩй10 keyНјааСЫаоИФ,ЮвУЧМАНјааГжОУЛЏВйзї
save 300 10
# ШчЙћ60sФк,ШчЙћжСЩй10000 keyНјааСЫаоИФ,ЮвУЧМАНјааГжОУЛЏВйзї
save 60 10000
# ЮвУЧжЎКѓбЇЯАГжОУЛЏ,ЛсздМКЖЈвхетИіВтЪд!
stop-writes-on-bgsave-error yes # ГжОУЛЏШчЙћГіДэ,ЪЧЗёЛЙашвЊМЬајЙЄзї!
rdbcompression yes # ЪЧЗёбЙЫѕ rdb ЮФМў,ашвЊЯћКФвЛаЉcpuзЪдД!
rdbchecksum yes # БЃДцrdbЮФМўЕФЪБКђ,НјааДэЮѓЕФМьВщаЃбщ!
dir ./ # rdb ЮФМўБЃДцЕФФПТМ!
REPLICATION ИДжЦ,ЮвУЧКѓУцНВНтжїДгИДжЦЕФ,ЪБКђдйНјааНВНт
SECURITY АВШЋ
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass # ЛёШЁredisЕФУмТы
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass "123456" # ЩшжУredisЕФУмТы
OK
127.0.0.1:6379> config get requirepass # ЗЂЯжЫљгаЕФУќСюЖМУЛгаШЈЯоСЫ
(error) NOAUTH Authentication required.
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456 # ЪЙгУУмТыНјааЕЧТМ!
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"
ЯожЦ CLIENTS
maxclients 10000 # ЩшжУФмСЌНгЩЯredisЕФзюДѓПЭЛЇЖЫЕФЪ§СП
maxmemory <bytes> # redis ХфжУзюДѓЕФФкДцШнСП
maxmemory-policy noeviction # ФкДцЕНДяЩЯЯожЎКѓЕФДІРэВпТд
1ЁЂvolatile-lru:жЛЖдЩшжУСЫЙ§ЦкЪБЕФkeyНјааLRU(ФЌШЯжЕ)
2ЁЂallkeys-lru : ЩОГ§lruЫуЗЈЕФkey
3ЁЂvolatile-random:ЫцЛњЩОГ§МДНЋЙ§Цкkey
4ЁЂallkeys-random:ЫцЛњЩОГ§
5ЁЂvolatile-ttl : ЩОГ§МДНЋЙ§ЦкЕФ
6ЁЂnoeviction : гРВЛЙ§Цк,ЗЕЛиДэЮѓ
APPEND ONLY ФЃЪН aofХфжУ
appendonly no # ФЌШЯЪЧВЛПЊЦєaofФЃЪНЕФ,ФЌШЯЪЧЪЙгУrdbЗНЪНГжОУЛЏЕФ,дкДѓВПЗжЫљгаЕФЧщПіЯТ,rdbЭъШЋЙЛгУ!
appendfilename "appendonly.aof" # ГжОУЛЏЕФЮФМўЕФУћзж
# appendfsync always # УПДЮаоИФЖМЛс syncЁЃЯћКФадФм
appendfsync everysec # УПУыжДаавЛДЮ sync,ПЩФмЛсЖЊЪЇет1sЕФЪ§Он!
# appendfsync no # ВЛжДаа sync,етИіЪБКђВйзїЯЕЭГздМКЭЌВНЪ§Он,ЫйЖШзюПь!
ОпЬхЕФХфжУ,ЮвУЧдк RedisГжОУЛЏ жаШЅИјДѓМвЯъЯИЯъНт!
RedisГжОУЛЏ
УцЪдКЭЙЄзї,ГжОУЛЏЖМЪЧжиЕу! Redis ЪЧФкДцЪ§ОнПт,ШчЙћВЛНЋФкДцжаЕФЪ§ОнПтзДЬЌБЃДцЕНДХХЬ,ФЧУДвЛЕЉЗўЮёЦїНјГЬЭЫГі,ЗўЮёЦїжа ЕФЪ§ОнПтзДЬЌвВЛсЯћЪЇЁЃЫљвд Redis ЬсЙЉСЫГжОУЛЏЙІФм!
RDB(Redis DataBase)
ЪВУДЪЧRDB
дкжїДгИДжЦжа,rdbОЭЪЧБИгУСЫ!ДгЛњЩЯУц!
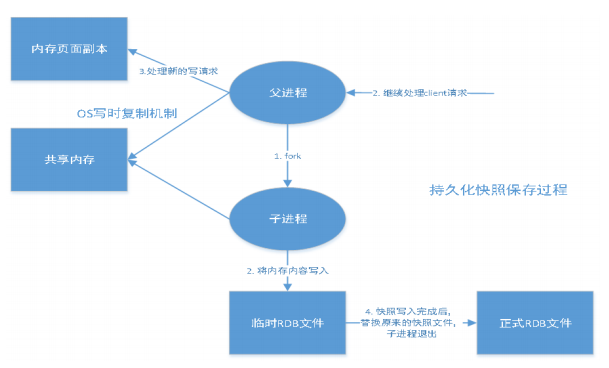
дкжИЖЈЕФЪБМфМфИєФкНЋФкДцжаЕФЪ§ОнМЏПьееаДШыДХХЬ,вВОЭЪЧааЛАНВЕФSnapshotПьее,ЫќЛжИДЪБЪЧНЋПьееЮФМўжБНгЖСЕНФкДцРяЁЃ
RedisЛсЕЅЖРДДНЈ(fork)вЛИізгНјГЬРДНјааГжОУЛЏ,ЛсЯШНЋЪ§ОнаДШыЕНвЛИіСйЪБЮФМўжа,Д§ГжОУЛЏЙ§ГЬ ЖМНсЪјСЫ,дйгУетИіСйЪБЮФМўЬцЛЛЩЯДЮГжОУЛЏКУЕФЮФМўЁЃећИіЙ§ГЬжа,жїНјГЬЪЧВЛНјааШЮКЮIOВйзїЕФЁЃ етОЭШЗБЃСЫМЋИпЕФадФмЁЃШчЙћашвЊНјааДѓЙцФЃЪ§ОнЕФЛжИД,ЧвЖдгкЪ§ОнЛжИДЕФЭъећадВЛЪЧЗЧГЃУєИа,ФЧ RDBЗНЪНвЊБШAOFЗНЪНИќМгЕФИпаЇЁЃRDBЕФШБЕуЪЧзюКѓвЛДЮГжОУЛЏКѓЕФЪ§ОнПЩФмЖЊЪЇЁЃЮвУЧФЌШЯЕФОЭЪЧ RDB,вЛАуЧщПіЯТВЛашвЊаоИФетИіХфжУ!
гаЪБКђдкЩњВњЛЗОГЮвУЧЛсНЋетИіЮФМўНјааБИЗн!
rdbБЃДцЕФЮФМўЪЧdump.rdbЖМЪЧдкЮвУЧЕФХфжУЮФМўжаПьеежаНјааХфжУЕФ!
ДЅЗЂЛњжЦ
- saveЕФЙцдђТњзуЕФЧщПіЯТ,ЛсздЖЏДЅЗЂrdbЙцдђ
- жДаа flushall УќСю,вВЛсДЅЗЂЮвУЧЕФrdbЙцдђ!
- ЭЫГіredis,вВЛсВњЩњ rdb ЮФМў!
БИЗнОЭздЖЏЩњГЩвЛИі dump.rdb

ШчЙћЛжИДrdbЮФМў!
- жЛашвЊНЋrdbЮФМўЗХдкЮвУЧredisЦєЖЏФПТМОЭПЩвд,redisЦєЖЏЕФЪБКђЛсздЖЏМьВщdump.rdb ЛжИДЦфжа ЕФЪ§Он!
- ВщПДашвЊДцдкЕФЮЛжУ
127.0.0.1:6379> config get dir
1) "dir"
2) "/usr/local/bin" # ШчЙћдкетИіФПТМЯТДцдк dump.rdb ЮФМў,ЦєЖЏОЭЛсздЖЏЛжИДЦфжаЕФЪ§Он
МИКѕОЭЫћздМКФЌШЯЕФХфжУОЭЙЛгУСЫ,ЕЋЪЧЮвУЧЛЙЪЧашвЊШЅбЇЯА!
гХЕу:
- ЪЪКЯДѓЙцФЃЕФЪ§ОнЛжИД!
- ЖдЪ§ОнЕФЭъећадвЊВЛИп!
ШБЕу:
- ашвЊвЛЖЈЕФЪБМфМфИєНјГЬВйзї!ШчЙћredisвтЭтхДЛњСЫ,етИізюКѓвЛДЮаоИФЪ§ОнОЭУЛгаЕФСЫ!
- forkНјГЬЕФЪБКђ,ЛсеМгУвЛЖЈЕФФкШнПеМф!!
AOF(Append Only File)
НЋЮвУЧЕФЫљгаУќСюЖММЧТМЯТРД,history,ЛжИДЕФЪБКђОЭАбетИіЮФМўШЋВПдкжДаавЛБщ!
ЪЧЪВУД
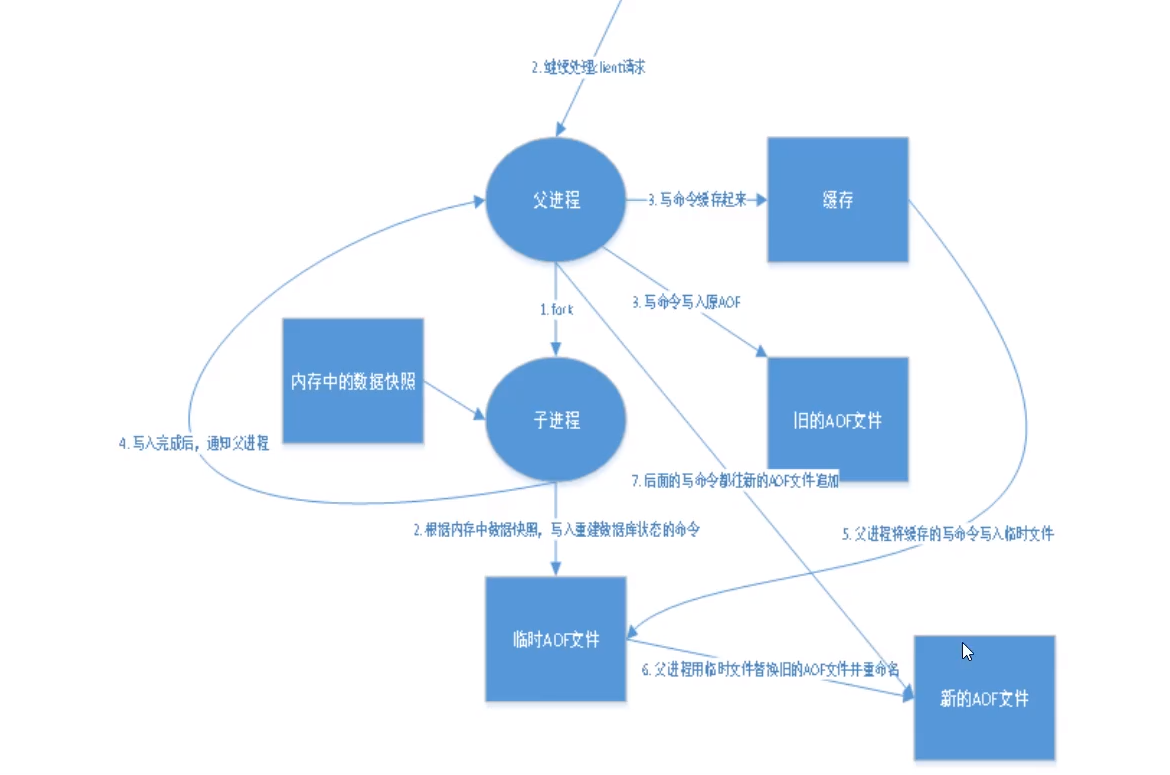
вдШежОЕФаЮЪНРДМЧТМУПИіаДВйзї,НЋRedisжДааЙ§ЕФЫљгажИСюМЧТМЯТРД(ЖСВйзїВЛМЧТМ),жЛаэзЗМгЮФМў ЕЋВЛПЩвдИФаДЮФМў,redisЦєЖЏжЎГѕЛсЖСШЁИУЮФМўжиаТЙЙНЈЪ§Он,ЛЛбджЎ,redisжиЦєЕФЛАОЭИљОнШежОЮФМў ЕФФкШнНЋаДжИСюДгЧАЕНКѓжДаавЛДЮвдЭъГЩЪ§ОнЕФЛжИДЙЄзї
AofБЃДцЕФЪЧ appendonly.aof ЮФМў
append
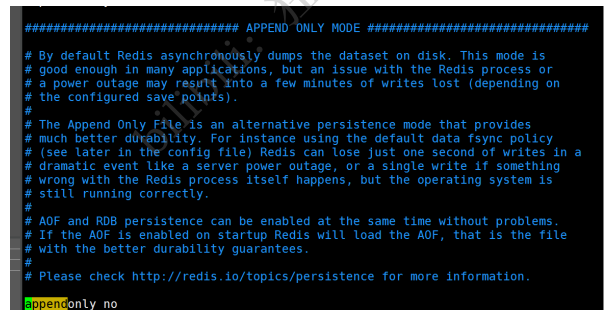
ФЌШЯЪЧВЛПЊЦєЕФ,ЮвУЧашвЊЪжЖЏНјааХфжУ!ЮвУЧжЛашвЊНЋ appendonly ИФЮЊyesОЭПЊЦєСЫ aof! жиЦє,redis ОЭПЩвдЩњаЇСЫ!
ШчЙћетИі aof ЮФМўгаДэЮЛ,етЪБКђ redis ЪЧЦєЖЏВЛЦ№РДЕФТ№,ЮвУЧашвЊаоИДетИіaofЮФМў
redis ИјЮвУЧЬсЙЉСЫвЛИіЙЄОп redis-check-aof --fix
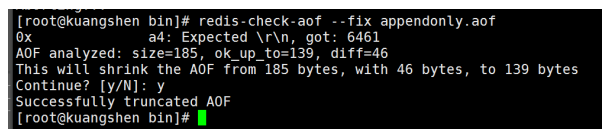
ШчЙћЮФМўе§ГЃ,жиЦєОЭПЩвджБНгЛжИДСЫ!
жиаДЙцдђЫЕУї
aof ФЌШЯОЭЪЧЮФМўЕФЮоЯозЗМг,ЮФМўЛсдНРДдНДѓ!
ШчЙћ aof ЮФМўДѓгк 64m,ЬЋДѓСЫ! forkвЛИіаТЕФНјГЬРДНЋЮвУЧЕФЮФМўНјаажиаД!
гХЕуКЭШБЕу!
appendonly no # ФЌШЯЪЧВЛПЊЦєaofФЃЪНЕФ,ФЌШЯЪЧЪЙгУrdbЗНЪНГжОУЛЏЕФ,дкДѓВПЗжЫљгаЕФЧщПіЯТ,
rdbЭъШЋЙЛгУ!
appendfilename "appendonly.aof" # ГжОУЛЏЕФЮФМўЕФУћзж
# appendfsync always # УПДЮаоИФЖМЛс syncЁЃЯћКФадФм
appendfsync everysec # УПУыжДаавЛДЮ sync,ПЩФмЛсЖЊЪЇет1sЕФЪ§Он!
# appendfsync no # ВЛжДаа sync,етИіЪБКђВйзїЯЕЭГздМКЭЌВНЪ§Он,ЫйЖШзюПь!
# rewrite жиаД,
гХЕу:
- УПвЛДЮаоИФЖМЭЌВН,ЮФМўЕФЭъећЛсИќМгКУ!
- УПУыЭЌВНвЛДЮ,ПЩФмЛсЖЊЪЇвЛУыЕФЪ§Он
- ДгВЛЭЌВН,аЇТЪзюИпЕФ!
ШБЕу:
- ЯрЖдгкЪ§ОнЮФМўРДЫЕ,aofдЖдЖДѓгк rdb,аоИДЕФЫйЖШвВБШ rdbТ§!
- Aof дЫаааЇТЪвВвЊБШrdbТ§,ЫљвдЮвУЧredisФЌШЯЕФХфжУОЭЪЧrdbГжОУЛЏ
РЉеЙ:
- RDB ГжОУЛЏЗНЪНФмЙЛдкжИЖЈЕФЪБМфМфИєФкЖдФуЕФЪ§ОнНјааПьееДцДЂ
- AOF ГжОУЛЏЗНЪНМЧТМУПДЮЖдЗўЮёЦїаДЕФВйзї,ЕБЗўЮёЦїжиЦєЕФЪБКђЛсжиаТжДааетаЉУќСюРДЛжИДдЪМ ЕФЪ§Он,AOFУќСювдRedis авщзЗМгБЃДцУПДЮаДЕФВйзїЕНЮФМўФЉЮВ,RedisЛЙФмЖдAOFЮФМўНјааКѓЬЈжи аД,ЪЙЕУAOFЮФМўЕФЬхЛ§ВЛжСгкЙ§ДѓЁЃ
- жЛзіЛКДц,ШчЙћФужЛЯЃЭћФуЕФЪ§ОндкЗўЮёЦїдЫааЕФЪБКђДцдк,ФувВПЩвдВЛЪЙгУШЮКЮГжОУЛЏ
- ЭЌЪБПЊЦєСНжжГжОУЛЏЗНЪН
- дкетжжЧщПіЯТ,ЕБredisжиЦєЕФЪБКђЛсгХЯШдиШыAOFЮФМўРДЛжИДдЪМЕФЪ§Он,вђЮЊдкЭЈГЃЧщПіЯТAOF ЮФМўБЃДцЕФЪ§ОнМЏвЊБШRDBЮФМўБЃДцЕФЪ§ОнМЏвЊЭъећЁЃ
- RDB ЕФЪ§ОнВЛЪЕЪБ,ЭЌЪБЪЙгУСНепЪБЗўЮёЦїжиЦєвВжЛЛсевAOFЮФМў,ФЧвЊВЛвЊжЛЪЙгУAOFФи?зїепНЈвщВЛвЊ,вђЮЊRDBИќЪЪКЯгУгкБИЗнЪ§ОнПт(AOFдкВЛЖЯБфЛЏВЛКУБИЗн),ПьЫйжиЦє,ЖјЧвВЛЛсга AOFПЩФмЧБдкЕФBug,СєзХзїЮЊвЛИіЭђвЛЕФЪжЖЮЁЃ
адФмНЈвщ
- вђЮЊRDBЮФМўжЛгУзїКѓБИгУЭО,НЈвщжЛдкSlaveЩЯГжОУЛЏRDBЮФМў,ЖјЧвжЛвЊ15ЗжжгБИЗнвЛДЮОЭЙЛ СЫ,жЛБЃСє save 900 1 етЬѕЙцдђЁЃ
- ШчЙћEnable AOF ,КУДІЪЧдкзюЖёСгЧщПіЯТвВжЛЛсЖЊЪЇВЛГЌЙ§СНУыЪ§Он,ЦєЖЏНХБОНЯМђЕЅжЛloadзд МКЕФAOFЮФМўОЭПЩвдСЫ,ДњМлвЛЪЧДјРДСЫГжајЕФIO,ЖўЪЧAOF rewrite ЕФзюКѓНЋ rewrite Й§ГЬжаВњ ЩњЕФаТЪ§ОнаДЕНаТЮФМўдьГЩЕФзшШћМИКѕЪЧВЛПЩБмУтЕФЁЃжЛвЊгВХЬаэПЩ,гІИУОЁСПМѕЩйAOF rewrite ЕФЦЕТЪ,AOFжиаДЕФЛљДЁДѓаЁФЌШЯжЕ64MЬЋаЁСЫ,ПЩвдЩшЕН5GвдЩЯ,ФЌШЯГЌЙ§дДѓаЁ100%ДѓаЁжи аДПЩвдИФЕНЪЪЕБЕФЪ§жЕЁЃ
- ШчЙћВЛEnable AOF ,НіПП Master-Slave Repllcation ЪЕЯжИпПЩгУадвВПЩвд,ФмЪЁЕєвЛДѓБЪIO,вВМѕЩйСЫrewriteЪБДјРДЕФЯЕЭГВЈЖЏЁЃДњМлЪЧШчЙћMaster/Slave ЭЌЪБЕЙЕє,ЛсЖЊЪЇЪЎМИЗжжгЕФЪ§Он, ЦєЖЏНХБОвВвЊБШНЯСНИі Master/Slave жаЕФ RDBЮФМў,диШыНЯаТЕФФЧИі,ЮЂВЉОЭЪЧетжжМмЙЙЁЃ
RedisЗЂВМЖЉдФ
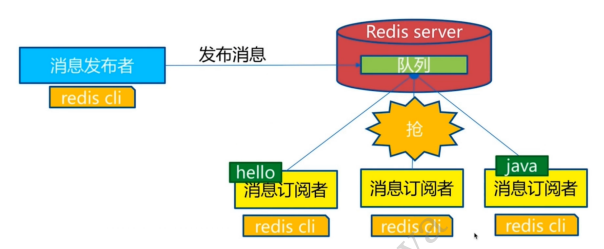
Redis ЗЂВМЖЉдФ(pub/sub)ЪЧвЛжжЯћЯЂЭЈаХФЃЪН:ЗЂЫЭеп(pub)ЗЂЫЭЯћЯЂ,ЖЉдФеп(sub)НгЪеЯћЯЂЁЃЮЂаХЁЂ ЮЂВЉЁЂЙизЂЯЕЭГ!
Redis ПЭЛЇЖЫПЩвдЖЉдФШЮвтЪ§СПЕФЦЕЕРЁЃ
ЖЉдФ/ЗЂВМЯћЯЂЭМ:
ЕквЛИі:ЯћЯЂЗЂЫЭеп, ЕкЖўИі:ЦЕЕР ЕкШ§Иі:ЯћЯЂЖЉдФеп!
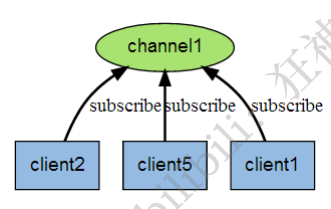
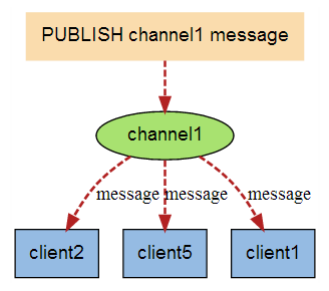
ЯТЭМеЙЪОСЫЦЕЕР channel1 , вдМАЖЉдФетИіЦЕЕРЕФШ§ИіПЭЛЇЖЫ ЁЊЁЊ client2 ЁЂ client5 КЭ client1 жЎМфЕФ ЙиЯЕ:
ЕБгааТЯћЯЂЭЈЙ§ PUBLISH УќСюЗЂЫЭИјЦЕЕР channel1 ЪБ, етИіЯћЯЂОЭЛсБЛЗЂЫЭИјЖЉдФЫќЕФШ§ИіПЭЛЇ ЖЫ:
УќСю
етаЉУќСюБЛЙуЗКгУгкЙЙНЈМДЪБЭЈаХгІгУ,БШШчЭјТчСФЬьЪв(chatroom)КЭЪЕЪБЙуВЅЁЂЪЕЪБЬсабЕШЁЃ
ВтЪд
ЖЉдФЖЫ:
127.0.0.1:6379> SUBSCRIBE kuangshenshuo # ЖЉдФвЛИіЦЕЕР kuangshenshuo Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "kuangshenshuo"
3) (integer) 1
# ЕШД§ЖСШЁЭЦЫЭЕФаХЯЂ
1) "message" # ЯћЯЂ
2) "kuangshenshuo" # ФЧИіЦЕЕРЕФЯћЯЂ
3) "hello,kuangshen" # ЯћЯЂЕФОпЬхФкШн
1) "message"
2) "kuangshenshuo"
3) "hello,redis"
ЗЂЫЭЖЫ:
127.0.0.1:6379> PUBLISH kuangshenshuo "hello,kuangshen" # ЗЂВМепЗЂВМЯћЯЂЕНЦЕЕР!
(integer) 1
127.0.0.1:6379> PUBLISH kuangshenshuo "hello,redis" # ЗЂВМепЗЂВМЯћЯЂЕНЦЕЕР!
(integer) 1
127.0.0.1:6379>
дРэ
RedisЪЧЪЙгУCЪЕЯжЕФ,ЭЈЙ§ЗжЮі Redis дДТыРяЕФ pubsub.c ЮФМў,СЫНтЗЂВМКЭЖЉдФЛњжЦЕФЕзВуЪЕЯж,МЎ ДЫМгЩюЖд Redis ЕФРэНтЁЃ
Redis ЭЈЙ§ PUBLISH ЁЂSUBSCRIBE КЭ PSUBSCRIBE ЕШУќСюЪЕЯжЗЂВМКЭЖЉдФЙІФмЁЃ
ЮЂаХ:
ЭЈЙ§ SUBSCRIBE УќСюЖЉдФФГЦЕЕРКѓ,redis-serverРяЮЌЛЄСЫвЛИізжЕф,зжЕфЕФМќЪЧвЛИіИі ЦЕЕР!, ЖјзжЕфЕФжЕдђЪЧвЛИіСДБэ,СДБэжаБЃДцСЫЫљгаЖЉдФетИіchannelПЭЛЇЖЫЁЃSUBSCRIBE УќСюЕФЙиМќ, ОЭЪЧНЋПЭЛЇЖЫЬэМгЕНИјЖЈ channelЕФЖЉдФСДБэжаЁЃ
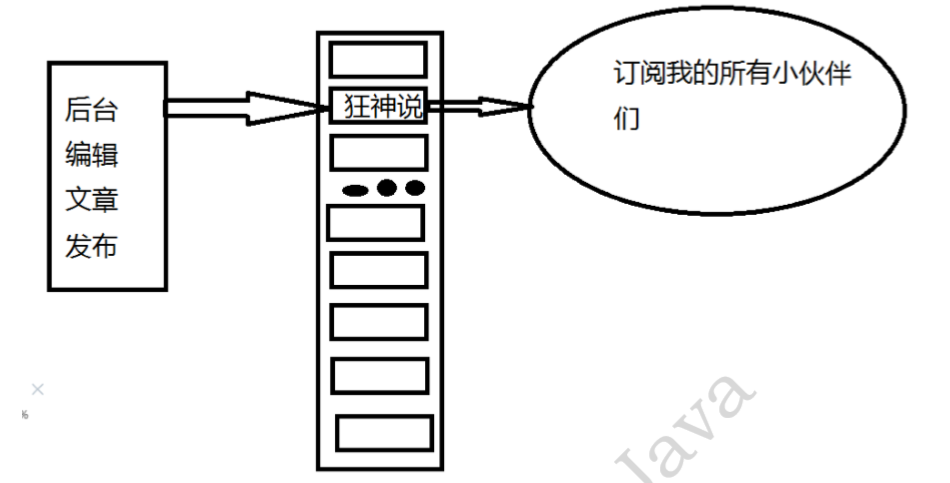
ЭЈЙ§ PUBLISH УќСюЯђЖЉдФепЗЂЫЭЯћЯЂ,redis-serverЛсЪЙгУИјЖЈЕФЦЕЕРзїЮЊМќ,ЫќЫљЮЌЛЄЕФ channel зжЕфжаВщевМЧТМСЫЖЉдФетИіЦЕЕРЕФЫљгаПЭЛЇЖЫЕФСДБэ,БщРњетБэ,НЋЯћЯЂЗЂВМИјЫљгаЖЉдФепЁЃ
Pub/Sub ДгзжУцЩЯРэНтОЭЪЧЗЂВМ(Publish)гыЖЉдФ(Subscribe),дкRedisжа,ПЩвдЩшЖЈЖдФГвЛИі keyжЕНјааЯћЯЂЗЂВММАЯћЯЂЖЉдФ,ЕБвЛИіkeyжЕЩЯНјааСЫЯћЯЂЗЂКѓ,ЫљгаЖЉдФЫќЕФПЭЛЇЖЫЖМЛсЪеЕНЯргІЕФЯћЯЂЁЃетвЛЙІФмУїЯдЕФгУЗЈОЭЪЧгУзїЪЕЪБЯћЯЕЭГ,БШШчЦеЭЈЕФМДЪБСФЬь,ШКСФЕШЙІФмЁЃ
ЪЙгУГЁОА:
- ЪЕЪБЯћЯЂЯЕЭГ!
- ЪТЪЕСФЬь!(ЦЕЕРЕБзіСФЬьЪв,НЋаХЯЂЛиЯдИјЫљгаШЫМДПЩ!)
- ЖЉдФ,ЙизЂЯЕЭГЖМЪЧПЩвдЕФ! ЩдЮЂИДдгЕФГЁОАЮвУЧОЭЛсЪЙгУЯћЯЂжаМфМўMQ()
RedisжїДгИДжЦ
ИХФю
жїДгИДжЦ,ЪЧжИНЋвЛЬЈRedisЗўЮёЦїЕФЪ§Он,ИДжЦЕНЦфЫћЕФRedisЗўЮёЦїЁЃЧАепГЦЮЊжїНкЕу(Master/Leader),КѓепГЦЮЊДгНкЕу(Slave/Follower), Ъ§ОнЕФИДжЦЪЧЕЅЯђЕФ!жЛФмгЩжїНкЕуИДжЦЕНДгНкЕу(жїНкЕувдаДЮЊжїЁЂДгНкЕувдЖСЮЊжї)ЁЃ
ФЌШЯЧщПіЯТ,УПЬЈRedisЗўЮёЦїЖМЪЧжїНкЕу,
вЛИіжїНкЕуПЩвдга0ИіЛђепЖрИіДгНкЕу,ЕЋУПИіДгНкЕужЛФмгЩвЛИіжїНкЕуЁЃ
жїДгИДжЦЕФзїгУжївЊАќРЈ:
- Ъ§ОнШпгр:жїДгИДжЦЪЕЯжСЫЪ§ОнЕФШШБИЗн,ЪЧГжОУЛЏжЎЭтЕФвЛжжЪ§ОнШпгрЕФЗНЪНЁЃ
- ЙЪеЯЛжИД:ЕБжїНкЕуЙЪеЯЪБ,ДгНкЕуПЩвдднЪБЬцДњжїНкЕуЬсЙЉЗўЮё,ЪЧвЛжжЗўЮёШпгрЕФЗНЪН
- ИКдиОљКт:дкжїДгИДжЦЕФЛљДЁЩЯ,ХфКЯЖСаДЗжРы,гЩжїНкЕуНјаааДВйзї,ДгНкЕуНјааЖСВйзї,ЗжЕЃЗўЮёЦїЕФИКди;гШЦфЪЧдкЖрЖСЩйаДЕФГЁОАЯТ,ЭЈЙ§ЖрИіДгНкЕуЗжЕЃИКди,ЬсИпВЂЗЂСПЁЃ
- ИпПЩгУ(МЏШК)ЛљЪЏ:жїДгИДжЦЛЙЪЧЩкБјКЭМЏШКФмЙЛЪЕЪЉЕФЛљДЁЁЃ
вЛАуРДЫЕ,вЊНЋRedisдЫгУгкЙЄГЬЯюФПжа,жЛЪЙгУвЛЬЈRedisЪЧЭђЭђВЛФмЕФ(хДЛњ),двђШчЯТ:
- ДгНсЙЙЩЯ,ЕЅИіRedisЗўЮёЦїЛсЗЂЩњЕЅЕуЙЪеЯ,ВЂЧввЛЬЈЗўЮёЦїашвЊДІРэЫљгаЕФЧыЧѓИКди,бЙСІНЯ Дѓ;
- ДгШнСПЩЯ,ЕЅИіRedisЗўЮёЦїФкДцШнСПгаЯо,ОЭЫувЛЬЈRedisЗўЮёЦїФкДцШнСПЮЊ256G,вВВЛФмНЋЫљга ФкДцгУзїRedisДцДЂФкДц,вЛАуРДЫЕ,ЕЅЬЈRedisДѓЪЙгУФкДцВЛгІИУГЌЙ§20GЁЃ
- ЕчЩЬЭјеОЩЯЕФЩЬЦЗ,вЛАуЖМЪЧвЛДЮЩЯДЋ,ЮоЪ§ДЮфЏРРЕФ,ЫЕзЈвЕЕувВОЭЪЧ"ЖрЖСЩйаД"ЁЃ
ЖдгкетжжГЁОА,ЮвУЧПЩвдЪЙШчЯТетжжМмЙЙ:
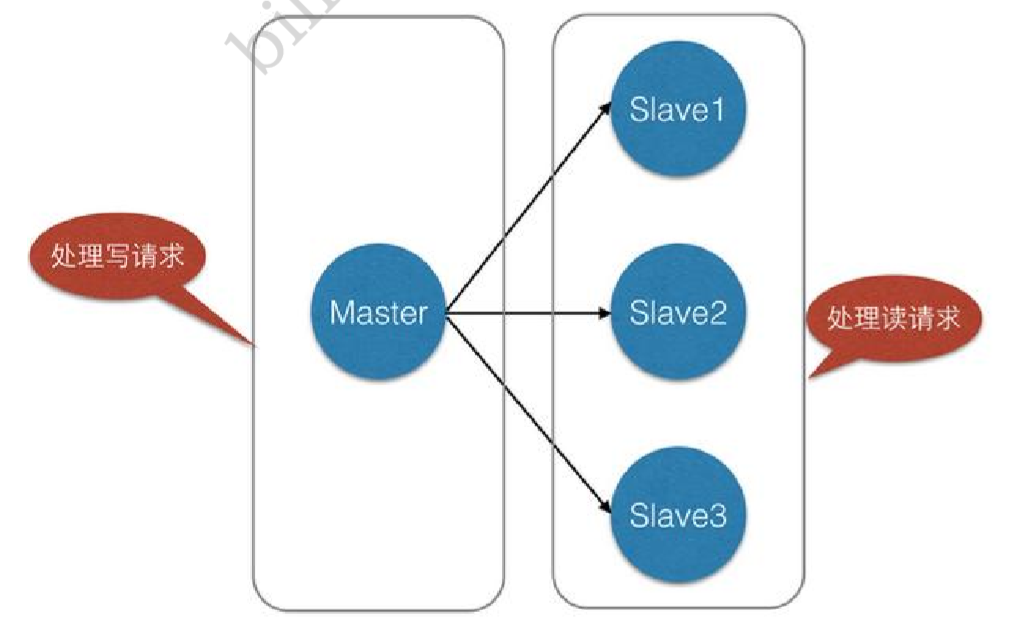
жїДгИДжЦ,ЖСаДЗжРы!80%ЕФЧщПіЯТЖМЪЧдкНјааЖСВйзї!МѕЛКЗўЮёЦїЕФбЙСІ!МмЙЙжаОГЃЪЙгУ! вЛжїЖўДг!
жЛвЊдкЙЋЫОжа,жїДгИДжЦОЭЪЧБиаывЊЪЙгУЕФ,вђЮЊдкецЪЕЕФЯюФПжаВЛПЩФмЕЅЛњЪЙгУRedis!
ЛЗОГХфжУ
жЛХфжУДгПт,ВЛгУХфжУжїПт!
127.0.0.1:6379> info replication # ВщПДЕБЧАПтЕФаХЯЂ # Replication
role:master # НЧЩЋ
master connected_slaves:0 # УЛгаДгЛњ
master_replid:b63c90e6c501143759cb0e7f450bd1eb0c70882a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
ИДжЦ3ИіХфжУЮФМў,ШЛКѓаоИФЖдгІЕФаХЯЂ
- ЖЫПк
- pid Ућзж
- logЮФМўУћзж
- dump.rdb Ућзж
аоИФЭъБЯжЎКѓ,ЦєЖЏЮвУЧЕФ3ИіredisЗўЮёЦї,ПЩвдЭЈЙ§НјГЬаХЯЂВщПД!
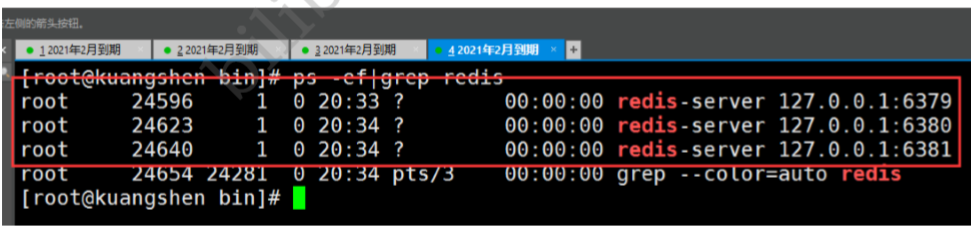
вЛжїЖўДг
ФЌШЯЧщПіЯТ,УПЬЈRedisЗўЮёЦїЖМЪЧжїНкЕу;
ЮвУЧвЛАуЧщПіЯТжЛгУХфжУДгОЭКУСЫ!
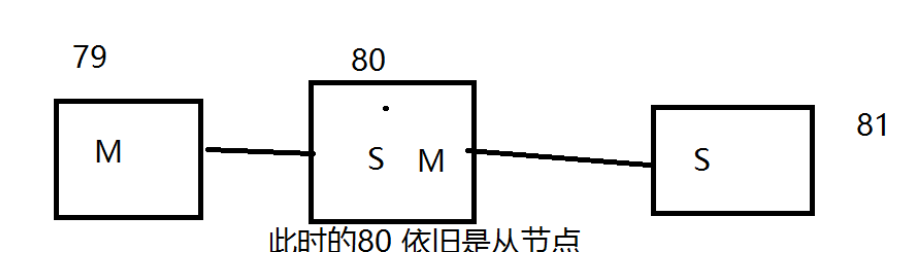
ШЯРЯДѓ! вЛжї (79)ЖўДг(80,81)
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # SLAVEOF host 6379 евЫЕБздМКЕФРЯДѓ!
OK
127.0.0.1:6380> c
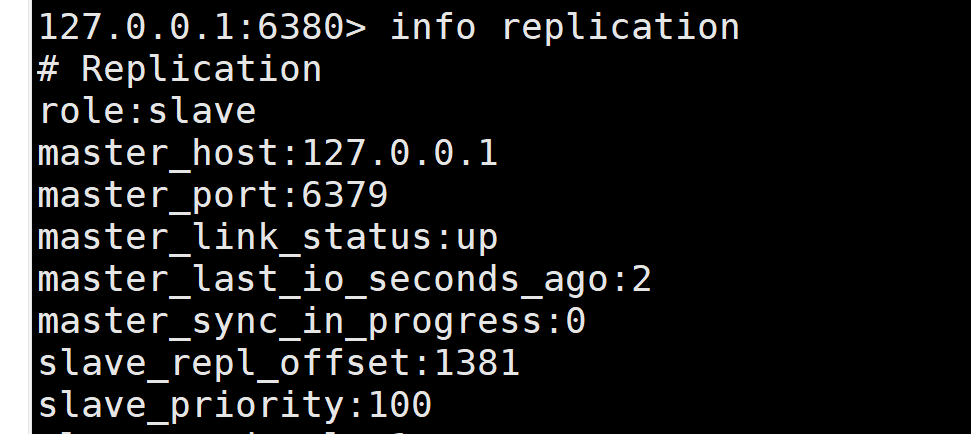
# Replication
role:slave # ЕБЧАНЧЩЋЪЧДгЛњ
master_host:127.0.0.1 # ПЩвдЕФПДЕНжїЛњЕФаХЯЂ
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0 master_replid:a81be8dd257636b2d3e7a9f595e69d73ff03774e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
# дкжїЛњжаВщПД!
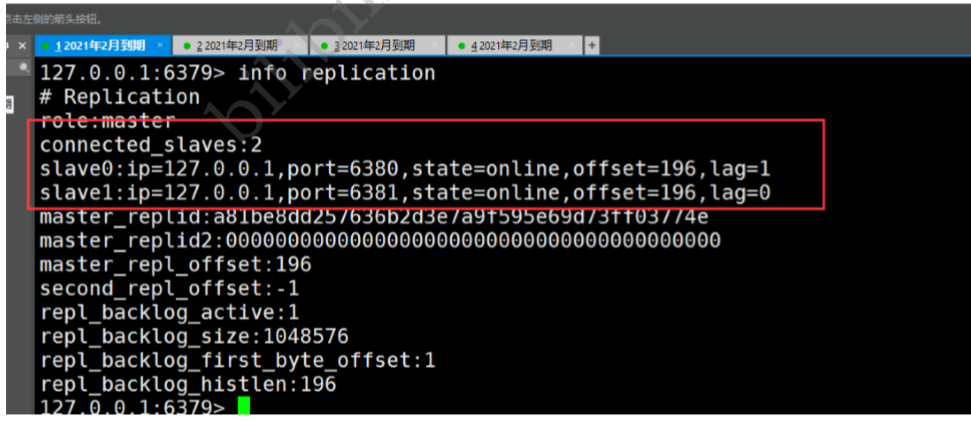
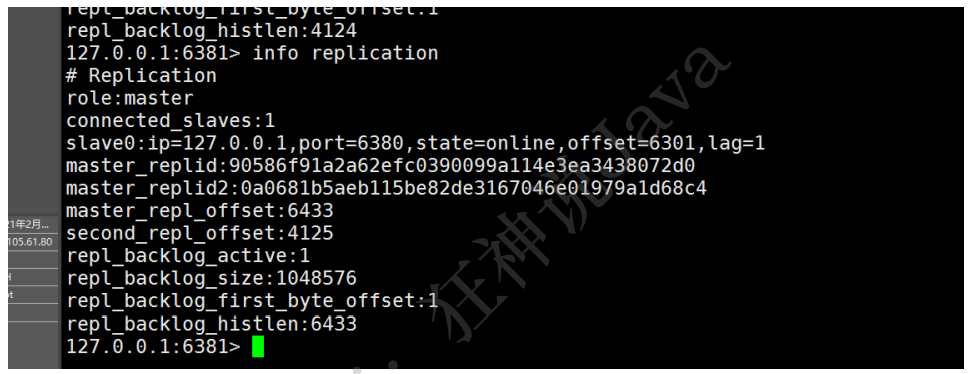
127.0.0.1:6379> info replication
# Replication
role:master connected_slaves:1 # ЖрСЫДгЛњЕФХфжУ
slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1 # ЖрСЫДгЛњЕФХфжУ
master_replid:a81be8dd257636b2d3e7a9f595e69d73ff03774e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42
ШчЙћСНИіЖМХфжУЭъСЫ,ОЭЪЧгаСНИіДгЛњ
ецЪЕЕФДгжїХфжУгІИУдкХфжУЮФМўжаХфжУ,етбљЕФЛАЪЧгРОУЕФ,ЮвУЧетРягУЕФЪЧУќСю,днЪБЕФ!
ЯИНк
жїЛњПЩвдаД,ДгЛњВЛФмаДжЛФмЖС!жїЛњжаЕФЫљгааХЯЂКЭЪ§Он,ЖМЛсздЖЏДгЛњБЃДц! жїЛњаД: 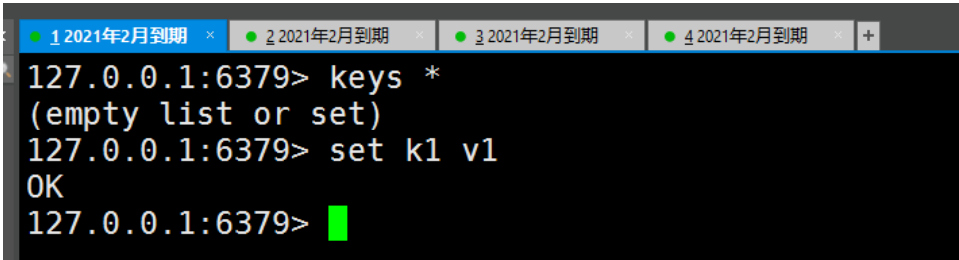
ДгЛњжЛФмЖСШЁФкШн!
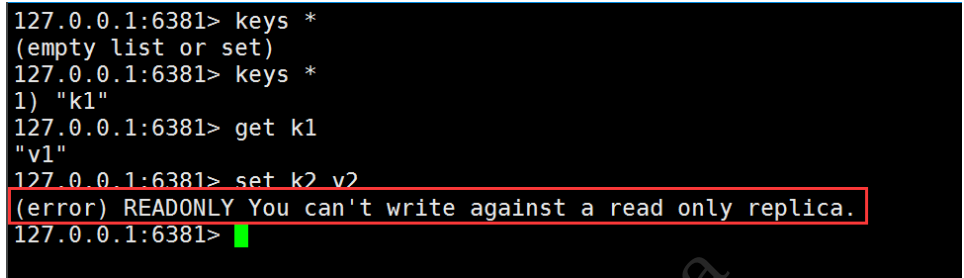
ВтЪд:жїЛњЖЯПЊСЌНг,ДгЛњвРОЩСЌНгЕНжїЛњЕФ,ЕЋЪЧУЛгааДВйзї,етИіЪБКђжїЛњШчЙћЛиРДСЫ,ДгЛњвРОЩПЩвджБНгЛёШЁЕНжїЛњаДЕФаХЯЂ!
ШчЙћЪЧЪЙгУУќСюаа,РДХфжУЕФжїДг,етИіЪБКђШчЙћжиЦєСЫ,ОЭЛсБфЛижїЛњ!жЛвЊБфЮЊДгЛњ,СЂТэОЭЛсДгжїЛњжаЛёШЁжЕ!
ИДжЦдРэ
Slave ЦєЖЏГЩЙІСЌНгЕН master КѓЛсЗЂЫЭвЛИіsyncЭЌВНУќСю
Master НгЕНУќСю,ЦєЖЏКѓЬЈЕФДцХЬНјГЬ,ЭЌЪБЪеМЏЫљгаНгЪеЕНЕФгУгкаоИФЪ§ОнМЏУќСю,дкКѓЬЈНјГЬжДааЭъБЯжЎКѓ,masterНЋДЋЫЭећИіЪ§ОнЮФМўЕНslave,ВЂЭъГЩвЛДЮЭъШЋЭЌВНЁЃ
ШЋСПИДжЦ:slaveЗўЮёдкНгЪеЕНЪ§ОнПтЮФМўЪ§ОнКѓ,НЋЦфДцХЬВЂМгдиЕНФкДцжаЁЃ - ЕквЛДЮСДНг
діСПИДжЦ:Master МЬајНЋаТЕФЫљгаЪеМЏЕНЕФаоИФУќСювРДЮДЋИјslave,ЭъГЩЭЌВН
ЕЋЪЧжЛвЊЪЧжиаТСЌНгmaster,вЛДЮЭъШЋЭЌВН(ШЋСПИДжЦ)НЋБЛздЖЏжДаа! ЮвУЧЕФЪ§ОнвЛЖЈПЩвддкДгЛњжаПДЕН!
ВуВуСДТЗ
ЩЯвЛИіMСДНгЯТвЛИі S!
етЪБКђвВПЩвдЭъГЩЮвУЧЕФжїДгИДжЦ!
80ЖЫПкаХЯЂ,вРОЩЪЧвЛИіДгНкЕу
81ЖЫПкаХЯЂ
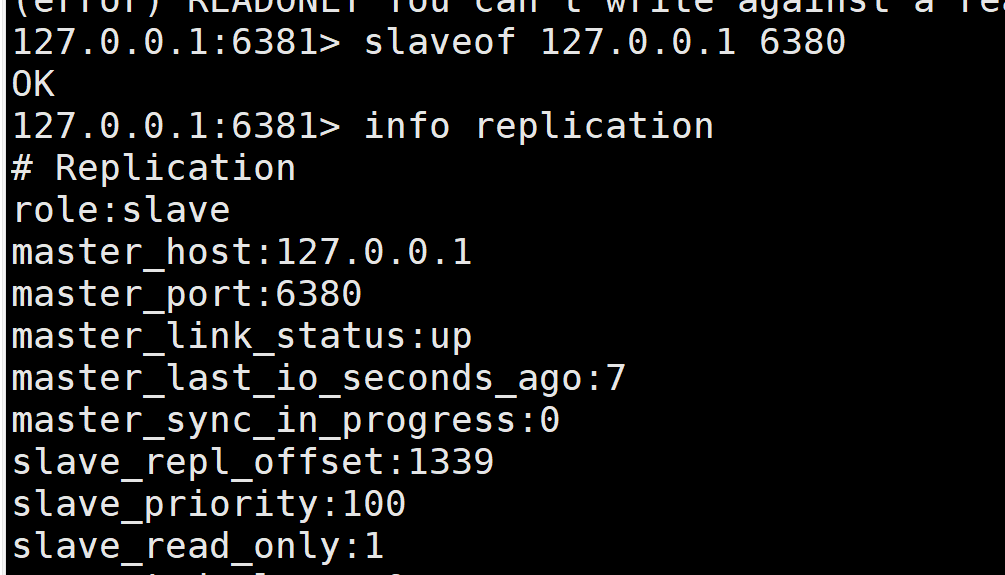
ШчЙћУЛгаРЯДѓСЫ,етИіЪБКђФмВЛФмбЁдёвЛИіРЯДѓГіРДФи? ЪжЖЏ!
ФБГЏДлЮЛ
ШчЙћжїЛњЖЯПЊСЫСЌНг,ЮвУЧПЩвдЪЙгУ SLAVEOF no one ШУздМКБфГЩжїЛњ!ЦфЫћЕФНкЕуОЭПЩвдЪжЖЏСЌНгЕНзюаТЕФетИіжїНкЕу(ЪжЖЏ)!ШчЙћетИіЪБКђРЯДѓаоИДСЫ,ФЧОЭжЛФмжиаТСЌНг!
ЩкБјФЃЪН
(здЖЏбЁОйРЯДѓЕФФЃЪН)
ИХЪі
жїДгЧаЛЛММЪѕЕФЗНЗЈЪЧ:ЕБжїЗўЮёЦїхДЛњКѓ,ашвЊЪжЖЏАбвЛЬЈДгЗўЮёЦїЧаЮЊжїЗўЮёЦї,етОЭашвЊШЫЙЄИЩдЄ,ЗбЪТЗбСІ,ЛЙЛсдьГЩвЛЖЮЪБМфФкЗўЮёВЛПЩМіЕФЗНЪН,ИќЖрЪБКђ,ЮвУЧгХЯШПМТЧЩкБјФЃЪНЁЃRedisДг2.8ПЊЪМе§ЪНЬсЙЉСЫSentinel(ЩкБј) МмЙЙРДНтОіетИіЮЪЬтЁЃ
ФБГЏДлЮЛЕФздЖЏАц,ФмЙЛКѓЬЈМрПижїЛњЪЧЗёЙЪеЯ,ШчЙћЙЪеЯСЫИљОнЭЖЦБЪ§здЖЏНЋДгПтзЊЛЛЮЊжїПтЁЃ
ЩкБјФЃЪНЪЧвЛжжЬиЪтЕФФЃЪН,ЪзЯШRedisЬсЙЉСЫЩкБјЕФУќСю,ЩкБјЪЧвЛИіЖРСЂЕФНјГЬ,зїЮЊНјГЬ,ЫќЛсЖРСЂдЫааЁЃЦфдРэЪЧЩкБјЭЈЙ§ЗЂЫЭУќСю,ЕШД§RedisЗўЮёЦїЯьгІ,ДгЖјМрПидЫааЕФЖрИіRedisЪЕР§ЁЃ
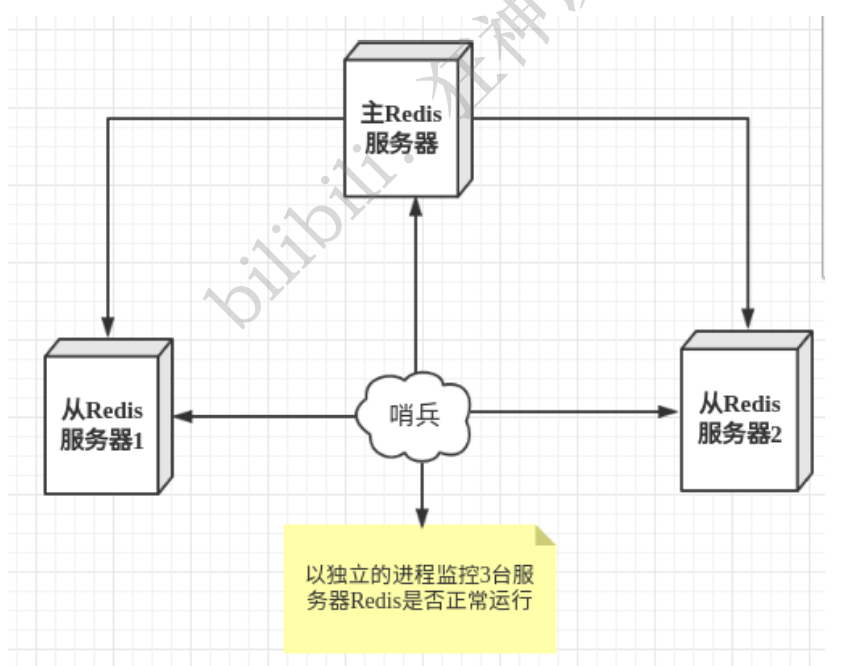
етРяЕФЩкБјгаСНИізїгУ
- ЭЈЙ§ЗЂЫЭУќСю,ШУRedisЗўЮёЦїЗЕЛиМрПиЦфдЫаазДЬЌ,АќРЈжїЗўЮёЦїКЭДгЗўЮёЦїЁЃ
- ЕБЩкБјМрВтЕНmasterхДЛњ,ЛсздЖЏНЋslaveЧаЛЛГЩmaster,ШЛКѓЭЈЙ§ЗЂВМЖЉдФФЃЪНЭЈжЊЦфЫћЕФДгЗў ЮёЦї,аоИФХфжУЮФМў,ШУЫќУЧЧаЛЛжїЛњЁЃ
ШЛЖјвЛИіЩкБјНјГЬЖдRedisЗўЮёЦїНјааМрПи,ПЩФмЛсГіЯжЮЪЬт,ЮЊДЫ,ЮвУЧПЩвдЪЙгУЖрИіЩкБјНјааМрПиЁЃ ИїИіЩкБјжЎМфЛЙЛсНјааМрПи,етбљОЭаЮГЩСЫЖрЩкБјФЃЪНЁЃ
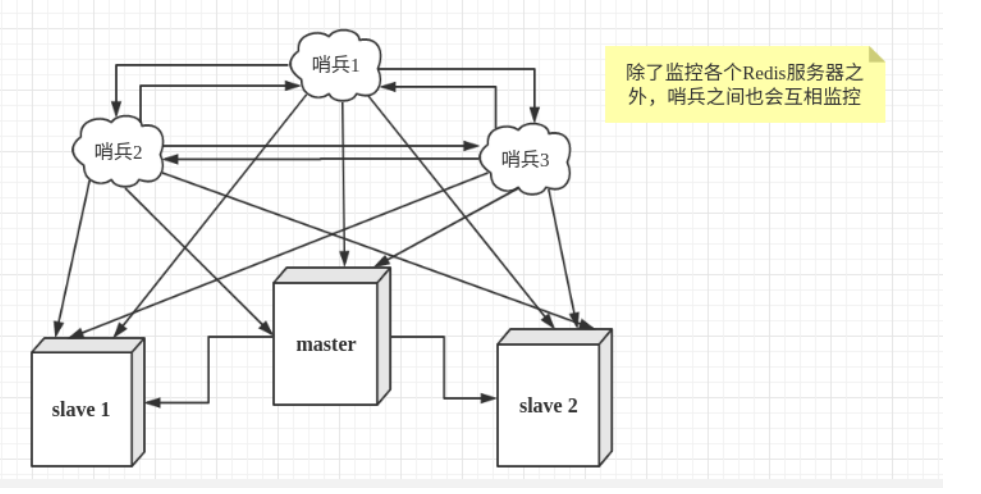
МйЩшжїЗўЮёЦїхДЛњ,ЩкБј1ЯШМьВтЕНетИіНсЙћ,ЯЕЭГВЂВЛЛсТэЩЯНјааfailoverЙ§ГЬ,НіНіЪЧЩкБј1жїЙлЕФШЯ ЮЊжїЗўЮёЦїВЛПЩгУ,етИіЯжЯѓГЩЮЊ жїЙлЯТЯп ЁЃЕБКѓУцЕФЩкБјвВМьВтЕНжїЗўЮёЦїВЛПЩгУ,ВЂЧвЪ§СПДяЕНвЛ ЖЈжЕЪБ,ФЧУДЩкБјжЎМфОЭЛсНјаавЛДЮЭЖЦБ,ЭЖЦБЕФНсЙћгЩвЛИіЩкБјЗЂЦ№,Нјааfailover[ЙЪеЯзЊвЦ]ВйзїЁЃ ЧаЛЛГЩЙІКѓ,ОЭЛсЭЈЙ§ЗЂВМЖЉдФФЃЪН,ШУИїИіЩкБјАбздМКМрПиЕФДгЗўЮёЦїЪЕЯжЧаЛЛжїЛњ,етИіЙ§ГЬГЦЮЊ ПЭЙлЯТЯпЁЃ
ВтЪд!
ЮвУЧФПЧАЕФзДЬЌЪЧ вЛжїЖўДг!
- ХфжУЩкБјХфжУЮФМў sentinel.conf
# sentinel monitor БЛМрПиЕФУћГЦ host port 1
sentinel montitor myredis 127.0.0.1 6379 1
КѓУцЕФетИіЪ§зж1,ДњБэжїЛњЙвСЫ,slaveЭЖЦБПДШУЫНгЬцГЩЮЊжїЛњ,ЦБЪ§зюЖрЕФ,ОЭЛсГЩЮЊжїЛњ!
- ЦєЖЏЩкБј!
[root@kuangshen bin]# redis-sentinel kconfig/sentinel.conf
26607:X 31 Mar 2020 21:13:10.027 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
26607:X 31 Mar 2020 21:13:10.027 # Redis version=5.0.8, bits=64,
commit=00000000, modified=0, pid=26607, just started
26607:X 31 Mar 2020 21:13:10.027 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.8 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, )` _.-'| Running in sentinel mode
|`-._`-...-` __...-.``-._|' Port: 26379
| `-._ `._ / _.-' | PID: 26607
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
26607:X 31 Mar 2020 21:13:10.029 # WARNING: The TCP backlog setting of 511
cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value
of 128.
26607:X 31 Mar 2020 21:13:10.031 # Sentinel ID is
4c780da7e22d2aebe3bc20c333746f202ce72996
26607:X 31 Mar 2020 21:13:10.031 # +monitor master myredis 127.0.0.1 6379 quorum
1
26607:X 31 Mar 2020 21:13:10.031 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @
myredis 127.0.0.1 6379
26607:X 31 Mar 2020 21:13:10.033 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @
myredis 127.0.0.1 6379
ШчЙћMaster НкЕуЖЯПЊСЫ,етИіЪБКђОЭЛсДгДгЛњжаЫцЛњбЁдёвЛИіЗўЮёЦї! (етРяУцгавЛИіЭЖЦБЫуЗЈ!)
ЩкБјШежО!
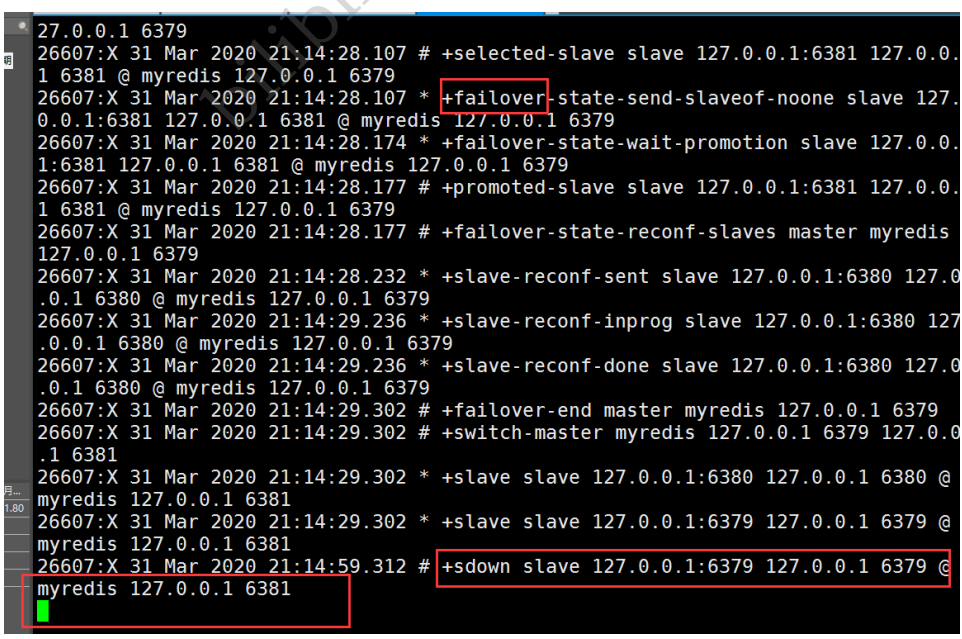
ШчЙћжїЛњДЫЪБЛиРДСЫ,жЛФмЙщВЂЕНаТЕФжїЛњЯТ,ЕБзіДгЛњ,етОЭЪЧЩкБјФЃЪНЕФЙцдђ!
ЩкБјФЃЪНЕФгХШБЕу
гХЕу:
- ЩкБјМЏШК,ЛљгкжїДгИДжЦФЃЪН,ЫљгаЕФжїДгХфжУгХЕу,ЫќШЋга
- жїДгПЩвдЧаЛЛ,ЙЪеЯПЩвдзЊвЦ,ЯЕЭГЕФПЩгУадОЭЛсИќКУ
- ЩкБјФЃЪНОЭЪЧжїДгФЃЪНЕФЩ§МЖ,ЪжЖЏЕНздЖЏ,ИќМгНЁзГ!
ШБЕу:
- Redis ВЛКУдкЯпРЉШнЕФ,МЏШКШнСПвЛЕЉЕНДяЩЯЯо,дкЯпРЉШнОЭЪЎЗжТщЗГ!
- ЪЕЯжЩкБјФЃЪНЕФХфжУЦфЪЕЪЧКмТщЗГЕФ,РяУцгаКмЖрбЁдё!
ЩкБјФЃЪНЕФШЋВПХфжУ!
# Example sentinel.conf
# ЩкБјsentinelЪЕР§дЫааЕФЖЫПк ФЌШЯ26379
port 26379
# ЩкБјsentinelЕФЙЄзїФПТМ
dir /tmp
# ЩкБјsentinelМрПиЕФredisжїНкЕуЕФ ip port
# master-name ПЩвдздМКУќУћЕФжїНкЕуУћзж жЛФмгЩзжФИA-zЁЂЪ§зж0-9 ЁЂетШ§ИізжЗћ".-_"зщГЩЁЃ
# quorum ХфжУЖрЩйИіsentinelЩкБјЭГвЛШЯЮЊmasterжїНкЕуЪЇСЊ ФЧУДетЪБПЭЙлЩЯШЯЮЊжїНкЕуЪЇСЊСЫ
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379
# ЕБдкRedisЪЕР§жаПЊЦєСЫrequirepass foobared ЪкШЈУмТы етбљЫљгаСЌНгRedisЪЕР§ЕФПЭЛЇЖЫЖМвЊЬсЙЉУмТы
# ЩшжУЩкБјsentinel СЌНгжїДгЕФУмТы зЂвтБиаыЮЊжїДгЩшжУвЛбљЕФбщжЄУмТы
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# жИЖЈЖрЩйКСУыжЎКѓ жїНкЕуУЛгагІД№ЩкБјsentinel ДЫЪБ ЩкБјжїЙлЩЯШЯЮЊжїНкЕуЯТЯп ФЌШЯ30Уы
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# етИіХфжУЯюжИЖЈСЫдкЗЂЩњfailoverжїБИЧаЛЛЪБзюЖрПЩвдгаЖрЩйИіslaveЭЌЪБЖдаТЕФmasterНјаа ЭЌВН,етИіЪ§зждНаЁ,ЭъГЩfailoverЫљашЕФЪБМфОЭдНГЄ,ЕЋЪЧШчЙћетИіЪ§зждНДѓ,ОЭвтЮЖзХдНЖрЕФslaveвђЮЊreplicationЖјВЛПЩгУЁЃПЩвдЭЈЙ§НЋетИіжЕЩшЮЊ 1 РДБЃжЄУПДЮжЛгавЛИіslave ДІгкВЛФмДІРэУќСюЧыЧѓЕФзДЬЌЁЃ
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# ЙЪеЯзЊвЦЕФГЌЪБЪБМф failover-timeout ПЩвдгУдквдЯТетаЉЗНУц:
#1. ЭЌвЛИіsentinelЖдЭЌвЛИіmasterСНДЮfailoverжЎМфЕФМфИєЪБМфЁЃ
#2. ЕБвЛИіslaveДгвЛИіДэЮѓЕФmasterФЧРяЭЌВНЪ§ОнПЊЪММЦЫуЪБМфЁЃжБЕНslaveБЛОРе§ЮЊЯђе§ШЗЕФmasterФЧРяЭЌВНЪ§ОнЪБЁЃ
#3.ЕБЯывЊШЁЯћвЛИіе§дкНјааЕФfailoverЫљашвЊЕФЪБМфЁЃ
#4.ЕБНјааfailoverЪБ,ХфжУЫљгаslavesжИЯђаТЕФmasterЫљашЕФзюДѓЪБМфЁЃВЛЙ§,МДЪЙЙ§СЫетИіГЌЪБ,
slavesвРШЛЛсБЛе§ШЗХфжУЮЊжИЯђmaster,ЕЋЪЧОЭВЛАДparallel-syncsЫљХфжУЕФЙцдђРДСЫ
# ФЌШЯШ§Зжжг
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#ХфжУЕБФГвЛЪТМўЗЂЩњЪБЫљашвЊжДааЕФНХБО,ПЩвдЭЈЙ§НХБОРДЭЈжЊЙмРэдБ,Р§ШчЕБЯЕЭГдЫааВЛе§ГЃЪБЗЂгЪМўЭЈжЊ
ЯрЙиШЫдБЁЃ
#ЖдгкНХБОЕФдЫааНсЙћгавдЯТЙцдђ:
#ШєНХБОжДааКѓЗЕЛи1,ФЧУДИУНХБОЩдКѓНЋЛсБЛдйДЮжДаа,жиИДДЮЪ§ФПЧАФЌШЯЮЊ10
#ШєНХБОжДааКѓЗЕЛи2,ЛђепБШ2ИќИпЕФвЛИіЗЕЛижЕ,НХБОНЋВЛЛсжиИДжДааЁЃ
#ШчЙћНХБОдкжДааЙ§ГЬжагЩгкЪеЕНЯЕЭГжаЖЯаХКХБЛжежЙСЫ,дђЭЌЗЕЛижЕЮЊ1ЪБЕФааЮЊЯрЭЌЁЃ
#вЛИіНХБОЕФзюДѓжДааЪБМфЮЊ60s,ШчЙћГЌЙ§етИіЪБМф,НХБОНЋЛсБЛвЛИіSIGKILLаХКХжежЙ,жЎКѓжиаТжДааЁЃ
#ЭЈжЊаЭНХБО:ЕБsentinelгаШЮКЮОЏИцМЖБ№ЕФЪТМўЗЂЩњЪБ(БШШчЫЕredisЪЕР§ЕФжїЙлЪЇаЇКЭПЭЙлЪЇаЇЕШЕШ),НЋЛсШЅЕїгУетИіНХБО,етЪБетИіНХБОгІИУЭЈЙ§гЪМў,SMSЕШЗНЪНШЅЭЈжЊЯЕЭГЙмРэдБЙигкЯЕЭГВЛе§ГЃдЫааЕФаХЯЂЁЃЕїгУИУНХБОЪБ,НЋДЋИјНХБОСНИіВЮЪ§,вЛИіЪЧЪТМўЕФРраЭ,вЛИіЪЧЪТМўЕФУшЪіЁЃШчЙћsentinel.confХфжУЮФМўжаХфжУСЫетИіНХБОТЗОЖ,ФЧУДБиаыБЃжЄетИіНХБОДцдкгкетИіТЗОЖ,ВЂЧвЪЧПЩжДааЕФ,ЗёдђsentinelЮоЗЈе§ГЃЦєЖЏГЩЙІЁЃ
#ЭЈжЊНХБО
# shellБрГЬ
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# ПЭЛЇЖЫжиаТХфжУжїНкЕуВЮЪ§НХБО
# ЕБвЛИіmasterгЩгкfailoverЖјЗЂЩњИФБфЪБ,етИіНХБОНЋЛсБЛЕїгУ,ЭЈжЊЯрЙиЕФПЭЛЇЖЫЙигкmasterЕижЗвбОЗЂЩњИФБфЕФаХЯЂЁЃ
# вдЯТВЮЪ§НЋЛсдкЕїгУНХБОЪБДЋИјНХБО:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# ФПЧА<state>змЪЧЁАfailoverЁБ,
# <role>ЪЧЁАleaderЁБЛђепЁАobserverЁБжаЕФвЛИіЁЃ
# ВЮЪ§ from-ip, from-port, to-ip, to-portЪЧгУРДКЭОЩЕФmasterКЭаТЕФmaster(МДОЩЕФslave)ЭЈаХЕФ
# етИіНХБОгІИУЪЧЭЈгУЕФ,ФмБЛЖрДЮЕїгУ,ВЛЪЧеыЖдадЕФЁЃ
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # вЛАуЖМЪЧгЩдЫЮЌРДХфжУ!
ЩчЛсФПЧАГЬађдББЅКЭ(ГѕМЖКЭжаМЖ)ЁЂИпМЖГЬађдБжиН№ФбЧѓ!(ЬсЩ§здМК!)
RedisЛКДцДЉЭИКЭбЉБР
ЗўЮёЕФИпПЩгУЮЪЬт!
дкетРяЮвУЧВЛЛсЯъЯИЕФЧјЗжЮіНтОіЗНАИЕФЕзВу!
RedisЛКДцЕФЪЙгУ,МЋДѓЕФЬсЩ§СЫгІгУГЬађЕФадФмКЭаЇТЪ,ЬиБ№ЪЧЪ§ОнВщбЏЗНУцЁЃЕЋЭЌЪБ,ЫќвВДјРДСЫвЛ аЉЮЪЬтЁЃЦфжа,зювЊКІЕФЮЪЬт,ОЭЪЧЪ§ОнЕФвЛжТадЮЪЬт,ДгбЯИёвтвхЩЯНВ,етИіЮЪЬтЮоНтЁЃШчЙћЖдЪ§Он ЕФвЛжТадвЊЧѓКмИп,ФЧУДОЭВЛФмЪЙгУЛКДцЁЃ
СэЭтЕФвЛаЉЕфаЭЮЪЬтОЭЪЧ,ЛКДцДЉЭИЁЂЛКДцбЉБРКЭЛКДцЛїДЉЁЃФПЧА,вЕНчвВЖМгаБШНЯСїааЕФНтОіЗНАИЁЃ
ЛКДцДЉЭИ(ВщВЛЕН)
ИХФю
ЛКДцДЉЭИЕФИХФюКмМђЕЅ,гУЛЇЯывЊВщбЏвЛИіЪ§Он,ЗЂЯжredisФкДцЪ§ОнПтУЛга,вВОЭЪЧЛКДцУЛгаУќжа,гкЪЧЯђГжОУВуЪ§ОнПтВщбЏЁЃЗЂЯжвВУЛга,гкЪЧБОДЮВщбЏЪЇАмЁЃЕБгУЛЇКмЖрЕФЪБКђ,ЛКДцЖМУЛгаУќжа(УыЩБ!),гкЪЧЖМШЅЧыЧѓСЫГжОУВуЪ§ОнПтЁЃетЛсИјГжОУВуЪ§ОнПтдьГЩКмДѓЕФбЙСІ,етЪБКђОЭЯрЕБгкГіЯжСЫЛКДцДЉЭИЁЃ
НтОіЗНАИ
ВМТЁЙ§ТЫЦї
ВМТЁЙ§ТЫЦїЪЧвЛжжЪ§ОнНсЙЙ,ЖдЫљгаПЩФмВщбЏЕФВЮЪ§вдhashаЮЪНДцДЂ,дкПижЦВуЯШНјаааЃбщ,ВЛЗћКЯдђЖЊЦњ,ДгЖјБмУтСЫЖдЕзВуДцДЂЯЕЭГЕФВщбЏбЙСІ;
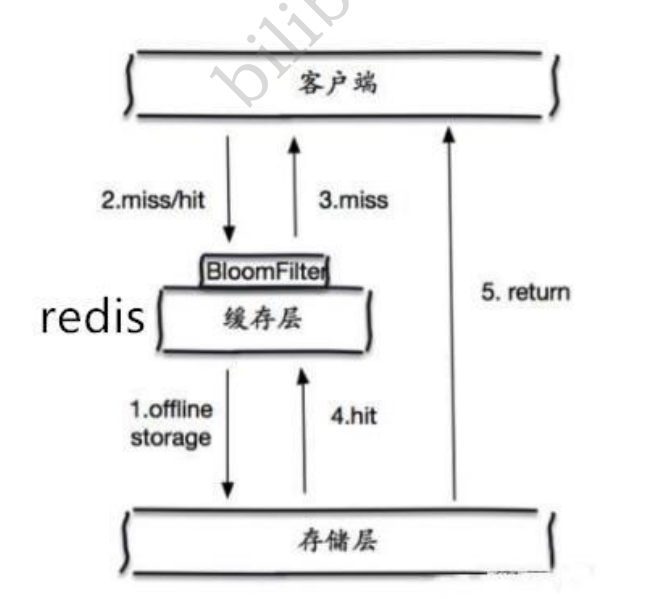
ЛКДцПеЖдЯѓ
ЕБДцДЂВуВЛУќжаКѓ,МДЪЙЗЕЛиЕФПеЖдЯѓвВНЋЦфЛКДцЦ№РД,ЭЌЪБЛсЩшжУвЛИіЙ§ЦкЪБМф,жЎКѓдйЗУЮЪетИіЪ§ ОнНЋЛсДгЛКДцжаЛёШЁ,БЃЛЄСЫКѓЖЫЪ§ОндД;
ЕЋЪЧетжжЗНЗЈЛсДцдкСНИіЮЪЬт:
- ШчЙћПежЕФмЙЛБЛЛКДцЦ№РД,етОЭвтЮЖзХЛКДцашвЊИќЖрЕФПеМфДцДЂИќЖрЕФМќ,вђЮЊетЕБжаПЩФмЛсгаКмЖр ЕФПежЕЕФМќ;
- МДЪЙЖдПежЕЩшжУСЫЙ§ЦкЪБМф,ЛЙЪЧЛсДцдкЛКДцВуКЭДцДЂВуЕФЪ§ОнЛсгавЛЖЮЪБМфДАПкЕФВЛвЛжТ,етЖдгк ашвЊБЃГжвЛжТадЕФвЕЮёЛсгагАЯьЁЃ
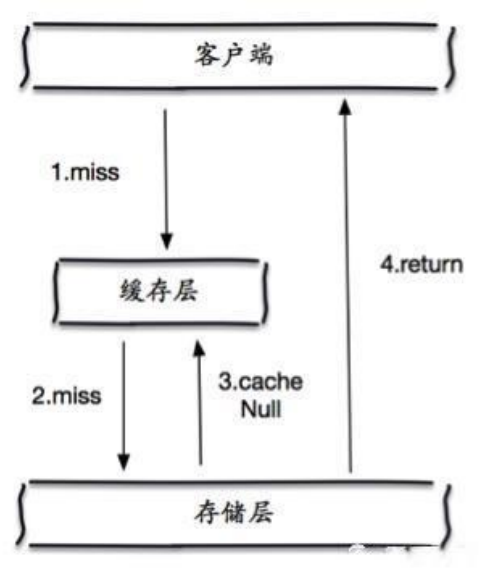
ЛКДцЛїДЉ(СПЬЋДѓ,ЛКДцЙ§Цк!)
ИХЪі
етРяашвЊзЂвтКЭЛКДцЛїДЉЕФЧјБ№,ЛКДцЛїДЉ,ЪЧжИвЛИіkeyЗЧГЃШШЕу,дкВЛЭЃЕФПИзХДѓВЂЗЂ,ДѓВЂЗЂМЏжа ЖдетвЛИіЕуНјааЗУЮЪ,ЕБетИіkeyдкЪЇаЇЕФЫВМф,ГжајЕФДѓВЂЗЂОЭДЉЦЦЛКДц,жБНгЧыЧѓЪ§ОнПт,ОЭЯёдквЛ ИіЦСеЯЩЯдфПЊСЫвЛИіЖДЁЃ
ЕБФГИіkeyдкЙ§ЦкЕФЫВМф,гаДѓСПЕФЧыЧѓВЂЗЂЗУЮЪ,етРрЪ§ОнвЛАуЪЧШШЕуЪ§Он,гЩгкЛКДцЙ§Цк,ЛсЭЌЪБЗУ ЮЪЪ§ОнПтРДВщбЏзюаТЪ§Он,ВЂЧвЛиаДЛКДц,ЛсЕМЪЙЪ§ОнПтЫВМфбЙСІЙ§ДѓЁЃ
НтОіЗНАИ
ЩшжУШШЕуЪ§ОнгРВЛЙ§Цк
ДгЛКДцВуУцРДПД,УЛгаЩшжУЙ§ЦкЪБМф,ЫљвдВЛЛсГіЯжШШЕу key Й§ЦкКѓВњЩњЕФЮЪЬтЁЃ
МгЛЅГтЫј
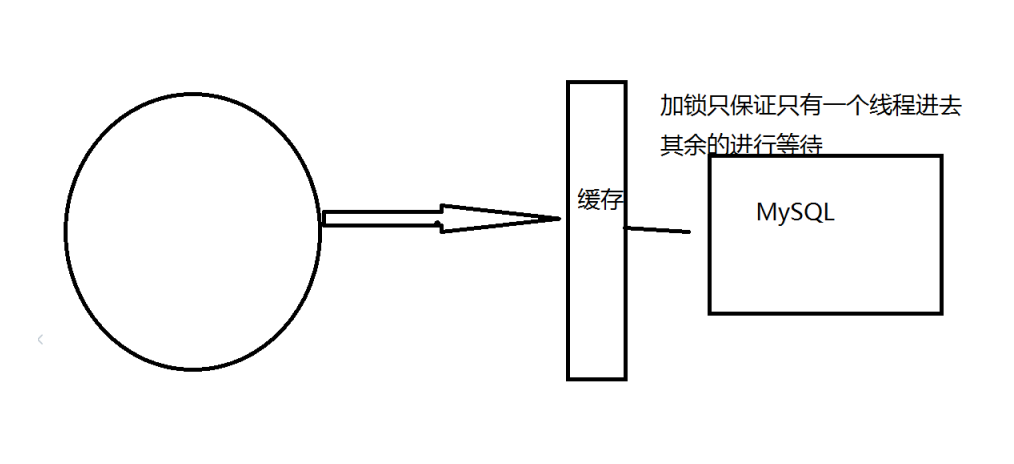
ЗжВМЪНЫј:ЪЙгУЗжВМЪНЫј(setnx),БЃжЄЖдгкУПИіkeyЭЌЪБжЛгавЛИіЯпГЬШЅВщбЏКѓЖЫЗўЮё,ЦфЫћЯпГЬУЛгаЛёЕУЗжВМЪНЫјЕФШЈЯо,вђДЫжЛашвЊЕШД§МДПЩЁЃетжжЗНЪННЋИпВЂЗЂЕФбЙСІзЊвЦЕНСЫЗжВМЪНЫј,вђДЫЖдЗжВМЪНЫјЕФПМбщКмДѓЁЃ
ЛКДцбЉБР
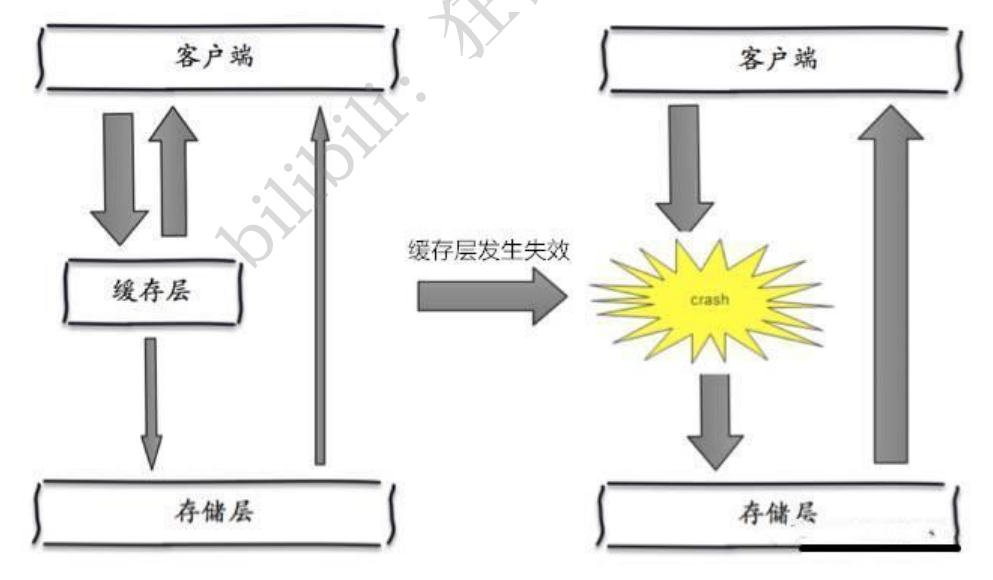
ИХФю
ЛКДцбЉБР,ЪЧжИдкФГвЛИіЪБМфЖЮ,ЛКДцМЏжаЙ§ЦкЪЇаЇЁЃRedis хДЛњ!
ВњЩњбЉБРЕФдвђжЎвЛ,БШШчдкаДБОЮФЕФЪБКђ,ТэЩЯОЭвЊЕНЫЋЪЎЖўСуЕу,КмПьОЭЛсгРДвЛВЈЧРЙК,етВЈЩЬЦЗЪБМфБШНЯМЏжаЕФЗХШыСЫЛКДц,МйЩшЛКДцвЛИіаЁЪБЁЃФЧУДЕНСЫСшГПвЛЕужгЕФЪБКђ,етХњЩЬЦЗЕФЛКДцОЭЖМЙ§ЦкСЫЁЃЖјЖдетХњЩЬЦЗЕФЗУЮЪВщбЏ,ЖМТфЕНСЫЪ§ОнПтЩЯ,ЖдгкЪ§ОнПтЖјбд,ОЭЛсВњЩњжмЦкадЕФбЙСІВЈЗхЁЃгкЪЧЫљгаЕФЧыЧѓЖМЛсДяЕНДцДЂВу,ДцДЂВуЕФЕїгУСПЛсБЉді,дьГЩДцДЂВувВЛсЙвЕєЕФЧщПіЁЃ
ЦфЪЕМЏжаЙ§Цк,ЕЙВЛЪЧЗЧГЃжТУќ,БШНЯжТУќЕФЛКДцбЉБР,ЪЧЛКДцЗўЮёЦїФГИіНкЕухДЛњЛђЖЯЭјЁЃвђЮЊздШЛ аЮГЩЕФЛКДцбЉБР,вЛЖЈЪЧдкФГИіЪБМфЖЮМЏжаДДНЈЛКДц,етИіЪБКђ,Ъ§ОнПтвВЪЧПЩвдЖЅзЁбЙСІЕФЁЃЮоЗЧОЭ ЪЧЖдЪ§ОнПтВњЩњжмЦкадЕФбЙСІЖјвбЁЃЖјЛКДцЗўЮёНкЕуЕФхДЛњ,ЖдЪ§ОнПтЗўЮёЦїдьГЩЕФбЙСІЪЧВЛПЩдЄжЊ ЕФ,КмгаПЩФмЫВМфОЭАбЪ§ОнПтбЙПхЁЃ
НтОіЗНАИ
redisИпПЩгУ етИіЫМЯыЕФКЌвхЪЧ,МШШЛredisгаПЩФмЙвЕє,ФЧЮвЖрдіЩшМИЬЈredis,етбљвЛЬЈЙвЕєжЎКѓЦфЫћЕФЛЙПЩвдМЬај ЙЄзї,ЦфЪЕОЭЪЧДюНЈЕФМЏШКЁЃ(вьЕиЖрЛю!)
ЯоСїНЕМЖ(дкSpringCloudНВНтЙ§!)
етИіНтОіЗНАИЕФЫМЯыЪЧ,дкЛКДцЪЇаЇКѓ,ЭЈЙ§МгЫјЛђепЖгСаРДПижЦЖСЪ§ОнПтаДЛКДцЕФЯпГЬЪ§СПЁЃБШШчЖд ФГИіkeyжЛдЪаэвЛИіЯпГЬВщбЏЪ§ОнКЭаДЛКДц,ЦфЫћЯпГЬЕШД§ЁЃ
Ъ§ОндЄШШ
Ъ§ОнМгШШЕФКЌвхОЭЪЧдке§ЪНВПЪ№жЎЧА,ЮвЯШАбПЩФмЕФЪ§ОнЯШдЄЯШЗУЮЪвЛБщ,етбљВПЗжПЩФмДѓСПЗУЮЪЕФЪ§ОнОЭЛсМгдиЕНЛКДцжаЁЃдкМДНЋЗЂЩњДѓВЂЗЂЗУЮЪЧАЪжЖЏДЅЗЂМгдиЛКДцВЛЭЌЕФkey,ЩшжУВЛЭЌЕФЙ§ЦкЪБМф,ШУЛКДцЪЇаЇЕФЪБМфЕуОЁСПОљдШЁЃ