һ��ǰ��
�ȿ�һ���Ƚ�����˼�İ���
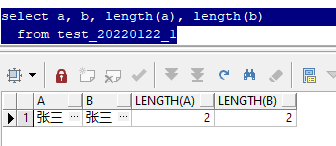
�������sql,��ѯ��a��b�����ֶ�,��Ϊ"����"��������,����ʹ��length�������,���Ⱦ�Ϊ2��
����,���㿴�������⼸��sql��������ʱ,���п��ܵ�һ��Ӧ��:
"������������?"
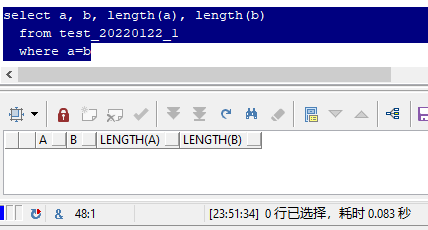
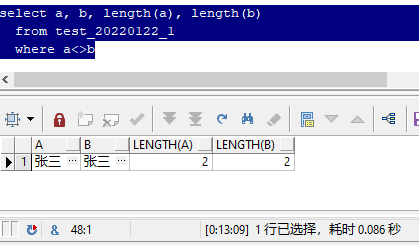
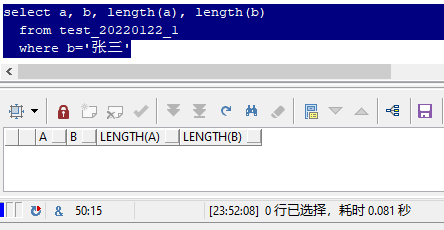
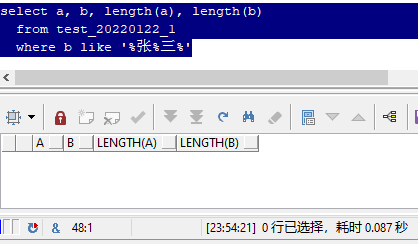
��ʵ,��������������"����",��ȷ������һģһ��,������ȥ��Ҳ�����ܿ�������
��Ϊʲôa��b�������?
������Ϊ������ǵijɷֲ�һ��,����ɷ־��� �ַ���
����ʲô���ַ���?
�ٶȰٿ�
����˵,
�ַ�(Character)�Ǹ������ֺͷ��ŵ��ܳ�,�������������֡������š�ͼ�η��š����ֵȡ�
�ַ���(Character set)�Ƕ���ַ��ļ���
������֪,�����ϵͳ�ײ����ɶ�����1��0��ɵ�,�������1��0Ҳ�����DZ�ʾ���źŵ�"ͨ"��"��",�����Ͳ������κ��ַ����ַ�����ʵ��������Ϊһ�����������ֵ�,����ָ���Ķ���������,ȥ������ֵ��Ӧλ�õ��ַ���ʲô,Ȼ����ַ�������������ѡ����������ʾ������
�������������"1011000010100001"(ʮ������Ϊ"B0A1"),��GB2312�ַ�����,��Ӧ����"��"��
������Ӣ����ĸ������,Ҳͬ��Ҳ���������ַ���,�������������"1100001"(ʮ������Ϊ"61"),��ʾСд��ĸ"a",��Ȼ,Ŀǰ�������е��ַ�����,������������ݶ���ʾa��
����,��������Ŀǰ�������õļ����ϵͳ,���Ҫʶ���ַ�,����ʹ������ַ��Ķ���������ȥ��ijһ���ض��ַ���,Ѱ�Ҷ�Ӧ���ַ�,����Ҵ����ַ���,�ҵ��Ŀ��ܾ��������ˡ�
����ORACLE���ݿ���ַ���
oracle���ݿ��ڰ�װʱ,���и�ѡ��,ѡ�����ݿ���ַ���,��������DBA��֪��,Ҳ���ö�˵��
����Ŀǰ�ܶ�����ͨ�������ϵ�����ȥ�˽�oracle�ַ�����ʱ��,�����ᱻŪ��һͷ��ˮ:
AL32UTF8��ʲô?Ϊʲô����UTF8?
�������������õ�SIMPLIFIED CHINESE_CHINA.ZHS16GBK��ʲô?Ϊʲô��ֱ����GBK?
�����ݿ���ĸ�����ͼ��鵽���ַ��������ǿͻ��˵Ļ������ݿ��?
I.�ַ�������
ORACLE�е��ַ�������,��������Ŀǰͨ�õ��ַ������ơ����������ٷ��ṩ��
ORACLE�ַ�����ͨ���ַ������ձ�
��ʵ������������е�"Description"�����˽,Ŀǰ��Щͨ�õ��ַ������ƶ�̫����,�Һ�����,������Ϊ����ʹ��;���һ�����һЩ�������,����"JA16EUCTILDE"��"JA16EUC"�����ַ���,ʵ���϶���"EUC 24-bit Japanese",ֻ�в����߲�һ��,�ͷֳ��������ַ�����
����oracle�����Լ��ٶ���Щ�ַ�������һ��ͳһ����,�������"AL32UTF8"�Լ�"ZHS16GBK"�������ַ�������
II.NLS_LANG
��ϵͳ��������(��ע���)"NLS_LANG"��,������������������������ֵ
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
AMERICAN_AMERICA.AL32UTF8
��ʵ�������������3���������
<Language>_<territory>.<character>
��
����_����.�ַ���
ֻ�����һ�ز���������ʾ�ַ���
����"SIMPLIFIED CHINESE_CHINA.ZHS16GBK"��ʾ:���������ġ�_���й�������.��16λGBK�������ġ�
ͬ��,"AMERICAN_AMERICA.AL32UTF8"��ʾ:����ʽӢ�_������������.��Unicode12.1ͨ���ַ���UTF-8���뷽������
��Ȼ,�ڻ���������,��3������ȫ������,������������ "_.AL32UTF8"��ʾʹ�����ݿ�Ĭ�ϵ����Ժ͵���,���ͻ���ʹ����ָ�����ַ���;�� "_AMERICA."ָֻ���ͻ��˵���,����ʹ�øõ�����Ĭ������,�ַ���ʹ�øõ���Ĭ�����Զ�Ӧ���ַ�����
---��ѯ����ʱ����������
DECLARE
retval UTL_I18N.STRING_ARRAY;
cnt INTEGER;
BEGIN
retval := UTL_I18N.GET_LOCAL_LANGUAGES('BELGIUM');
for i in 0..retval.count-1 loop
DBMS_OUTPUT.PUT_LINE(retval(i));
END LOOP;
END;
/
---��ѯ�����Ĭ���ַ���
select UTL_I18N.GET_DEFAULT_CHARSET('French') from dual;
---��ISO�����Դ���ת����ORACLE�е����� �� ����
select UTL_I18N.MAP_LANGUAGE_FROM_ISO('en_US') ,
UTL_I18N.MAP_TERRITORY_FROM_ISO('en_US') from dual;
---��ORACLE���� �� ����ת���ɱ�ISO�����Դ���
select UTL_I18N.MAP_LOCALE_TO_ISO('American','America') from dual;
ʵ���û�������,һ���������Բ�ֹ��һ������,һ���ַ���Ҳ���Ա�ʾ�����������֡�ͨ��������������������,���������ݿ�Ը���������ʱ�������ԡ����ҡ����ֵȵļ����Ը��á�
����,������ֻ�����:
���Ƕ�˵Ҫ�����ݿ�Ļ��������Ϳͻ��˵Ļ�����������һ��ô?
��,û��,��ȷ���鱣��һ��,���Ⲣ�Ǿ��ԡ�Ŀǰ����Ҷ����ԵĹ�˾���ȥ��,��ʹ��ͬһ�����ݿ�ʱ,�϶����в�ͬ����Ҫ��
��������
A.����
����,��������,�������������IJ���:
- ���ݿⰲװʱ,����ѡ����"AMERICAN",Ȼ��ͻ��˻���������"NLS_LANG"���ó�"SIMPLIFIED CHINESE_CHINA.AL32UTF8",�ͻ�������,�������ݿ��ִ��һ�δ����sql
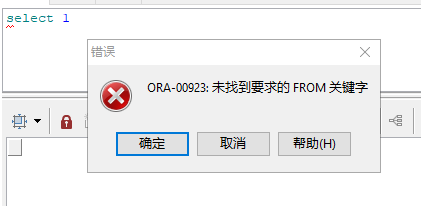
- Ȼ��ѿͻ��˻���������"NLS_LANG"�ij�"AMERICAN_CHINA.AL32UTF8",�����´ͻ�������,�������ݿ��ִ��ͬ����sql
��,�ͻ��˻���������������Ծ��������������,�����ڿͻ�����ʾ��ͬ���Եı���������ʾ��Ϣ,�������������ó�������߷���,��Щϵͳ��ʾ��Ϣ�����ݿ��ڲ��������м�¼�������Եġ�����,Ҳ����ͨ�����ݿ��Դ�plsql��"UTL_LMS"����Ӧ��ϵͳ��ʾ��Ϣת���ɷǿͻ������õ����ԡ�
DECLARE
s varchar2(200);
i pls_integer;
BEGIN
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'french', s);
dbms_output.put_line('���� : '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'AMERICAN', s);
dbms_output.put_line('��ʽӢ�� is: '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'SIMPLIFIED CHINESE', s);
dbms_output.put_line('�������� is: '||s);
END;
/
���Ϊ:
���� : Type %d non pris en charge pour l��expression SQL sur la colonne %s.
��ʽӢ�� : Unsupported type %d for SQL expression on column %s.
�������� : ��֧�� SQL ����ʽ���� %d (λ�� %s ��)��
��Ȼ,����Ҳ�ÿ�Ŀǰ���ַ����Ƿ�֧�ֵ�ǰ����,�ɲο��ٷ��ĵ�
ORACLE���Ժ�֧�ֵ��ַ������ձ�
B.����
���ڵ���,��������˵����,��û���������Ե�ʱ��ȡ������Ĭ���������������,��Ӱ��ʱ�������ҡ����ڸ�ʽ,����뱾ƪ��ϵ����,���Թ��ˡ�
C.�ַ���
�������������һ������,�ַ���
��ͨ�������ϵ�����,�Լ��Լ������ݿ��е�����,�õ�������Щsql,���Բ�ѯ���ԡ��������ַ���
select * from nls_database_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from nls_instance_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from nls_session_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from v$parameter;
select * from v$nls_parameters;
select * from v$system_parameter where name like 'nls%';
select name,substr(value$, 1, 64) from x$props where name like 'NLS%';
select userenv('language') from dual;
select sys_context('USERENV','LANGUAGE') from dual;
����,����һ������,��Щsql�ֱ����������֪�����ݿ�Ϳͻ�����ʹ�õ����Լ�����,���Ƕ����ַ���,Ҫôû��,Ҫô��ʾΪ���ݿ��ַ���,���ͻ��˻������������õ��ַ���ͨ���κ�һ��sql���鲻��!
����Oracle�ٷ��ĵ���Ҳ�ж�Ӧ��˵��
FAQ-NLS-LANG
SELECT USERENV (��language��) FROM DUAL; gives the session��s _ but the DATABASE character set not the client, so the value returned is not the client��s complete NLS_LANG setting!
SELECT USERENV (��language��) FROM DUAL;�õ���ǰ�Ự�� ����_���� �Լ� ���ݿ��ַ���,���ǿͻ��˵��ַ���,���������ص�ֵ���������Ŀͻ���NLS_LANG����!
�Ȳ�����ΪʲôORACLE���ṩ�ͻ����ַ��������ݿ��еIJ�ѯ��ʽ,�����ص�������,�ַ�����һ�����������Щ���⡣
�Ҵ�����һ�ű�,�������ֶ�,�ֱ�Ϊ�кš�ֵ��Ȼ���д��4���ı��ļ�,����ִ��insert into һ����¼�������,�кŷֱ�Ϊ1��2��3��4,ֵ��Ϊ"����"�����Գ����������������
��������
| �к� | ���ݿ����� | ���ݿ��ַ��� | �ͻ������� | �ͻ����ַ��� | ����sql���ļ����� | ���ݿ��ڵ�ʮ���������� | ��plsql developer�еĿɼ��ַ� |
|---|---|---|---|---|---|---|---|
| 1 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | ZHS16GBK | UTF-8 | E5AFAEE78AB1E7AC81 | 张三 |
| 2 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | ZHS16GBK | ANSI | E5BCA0E4B889 | ���� |
| 3 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | AL32UTF8 | UTF-8 | E5BCA0E4B889 | ���� |
| 4 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | AL32UTF8 | ANSI | D5C5C8FD | ���� |
(ʵ��,��plsql developerѡ����������unicodeʱ,�ͻ����ַ�����Ӱ����������ʾ)
��sqlplus��ѯ����
| �ͻ����ַ��� | �к� | �ɼ��ַ�(chcp 936) | �ɼ��ַ�(chcp 65001) |
|---|---|---|---|
| AL32UTF8 | 1 | 寮犱� | 张三 |
| AL32UTF8 | 2 | 张三 | ���� |
| AL32UTF8 | 3 | 张三 | ���� |
| AL32UTF8 | 4 | ���� | ���� |
| �ͻ����ַ��� | �к� | �ɼ��ַ�(chcp 936) | �ɼ��ַ�(chcp 65001) |
|---|---|---|---|
| ZHS16GBK | 1 | 张三 | ���� |
| ZHS16GBK | 2 | ���� | |
| ZHS16GBK | 3 | ���� | |
| ZHS16GBK | 4 | ?? |
������������,���Եõ����¼���
- �ڲ�������ʱ,�����ļ����ַ���Ҫ��֤�Ϳͻ����ַ���һ��,�ɱ�������(��Ҫ��Ӧ�������������ַ����ж�����),��������ݿ��ַ�����һ��Ҳû��ϵ(�����2�к͵�3�о���ȷ��һ��)
- �ڲ�������ʱ,�ͻ����ַ����������ļ��ַ�����һ��ʱ,���ܻ��������(��1��),Ҳ���ܲ�����(��4��),���Ƿ�����ֻ��"��ʾЧ��",����ֵ��ij���������Ǵ���
- ��ѯʱ,�ͻ����ַ��������ݿ��ַ�������һ��,�������ȷ��ʾ���ֵĸ���
- ��ѯʱ,����ҳ(chcp)�Ϳͻ����ַ�������һ��,�������ȷ��ʾ���ֵĸ���
- ����ҳ(chcp)�������ļ�������һ�ֶ���,Ҳ����˵,��������漰����ֻ��3������,���ݿ��ַ������ͻ����ַ��������ݱ���(�ܴ���ҳ���ļ�����Ӱ��)
- Ҫ�������̶��ϼ���"����"���ʵķ���,��Ҫ���ݿ��ַ������ͻ����ַ��������ݱ������߶�����һ��
- �������������һ��,�������ݿ��ַ������ɿ�ʱ,ҲӦ�þ����ÿͻ����ַ��������ݱ��뱣��һ��
- ���ݿ��ַ����Ϳͻ����ַ�����һ�µ������,�������ݿ��ַ���ΪZHS16GBK,���ͻ����ַ���ΪAL32UTF8,��ô�ͻ��˲�������ʱ,���ܲ�������������ת��(UTF-8���ֱ�GBK��),�����������ⲻ��,ֻҪȷ������ͬһ�����ݵ����пͻ��˵��ַ���ͳһ
������Oracle�л�ԭ����
��ǰҪȷ���ַ���һ��,�ɱ�������,�������ǰû�б�֤�ַ���һ��,���²���������,�º���������������������?
�����������ͨ�����·�ʽ���л�ԭ
select utl_i18n.raw_to_char(UTL_I18N.string_to_raw('张三', 'ZHS16GBK'),
'AL32UTF8')
from dual;
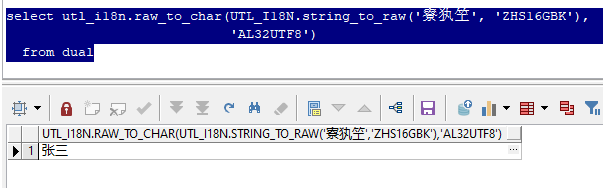
�����Ͻ�����ֻ��ZHS16GBK��AL32UTF8�����о���,ʵ�ʳ�������������������ȵ�,Ҫ�ж�һ�����뵽�����ĸ��ַ���ת�ĸ��ַ�����������,��ʵ���ѡ�
�����ҿ�����һ��plsql��,���ת��,���һ������,�û��������Ų���������ô������(Ϊ���������������,�����ijһ�������������ַ������������)
create or replace package charset_util_pkg is
type convert_any_charset_type is RECORD(
original_str varchar2(4000),
original_HEX RAW(32767),
to_str varchar2(4000),
to_hex raw(32767),
from_charset varchar2(50),
to_charset varchar2(50),
sql_text varchar2(200));
type convert_any_charset_table is table of convert_any_charset_type;
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
PIPELINED;
end charset_util_pkg;
/
create or replace package body charset_util_pkg is
charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('JA16EUC',
--'JA16EUCTILDE',
'JA16SJIS',
--'JA16SJISTILDE',
'KO16MSWIN949',
'TH8TISASCII',
'VN8MSWIN1258',
'ZHS16GBK',
'ZHT16HKSCS',
--'ZHT16MSWIN950',
'ZHT32EUC',
'BLT8ISO8859P13',
'BLT8MSWIN1257',
'CL8ISO8859P5',
'CL8MSWIN1251',
'EE8ISO8859P2',
'EL8ISO8859P7',
'EL8MSWIN1253',
'EE8MSWIN1250',
'NE8ISO8859P10',
'NEE8ISO8859P4',
'WE8ISO8859P15',
'WE8MSWIN1252',
'AR8ISO8859P6',
'AR8MSWIN1256',
'IW8ISO8859P8',
'IW8MSWIN1255',
'TR8MSWIN1254',
'WE8ISO8859P9',
'AL32UTF8');
ASIA_charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('JA16EUC',
-- 'JA16EUCTILDE',
'JA16SJIS',
-- 'JA16SJISTILDE',
'KO16MSWIN949',
'TH8TISASCII',
'VN8MSWIN1258',
'ZHS16GBK',
'ZHT16HKSCS',
--'ZHT16MSWIN950',
'ZHT32EUC');
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
PIPELINED is
to_str varchar2(4000);
begin
for rec in (select f.column_value from_charset,
t.column_value to_charset
from table(charsetlist) f, table(charsetlist) t
where f.column_value <> t.column_value
AND (F.column_value IN
(SELECT column_value FROM TABLE(ASIA_charsetlist)) OR
T.column_value IN
(SELECT column_value FROM TABLE(ASIA_charsetlist)))) loop
begin
to_str := utl_i18n.raw_to_char(UTL_I18N.string_to_raw(original_str,
rec.from_charset),
rec.to_charset);
exception
when others then
begin
to_str := utl_i18n.raw_to_char(UTL_I18N.string_to_raw(original_str ||
chr(0),
rec.from_charset),
rec.to_charset);
exception
when others then
to_str := 'convert error!';
end;
end;
if to_str in (rpad(chr(63), length(original_str), chr(63)),
rpad(UTL_RAW.cast_to_varchar2('C2BF'),
length(original_str),
UTL_RAW.cast_to_varchar2('C2BF'))) then
CONTINUE;
end if;
PIPE ROW(convert_any_charset_type(original_str,
UTL_RAW.cast_to_raw(original_str),
to_str,
UTL_RAW.cast_to_raw(to_str),
rec.to_charset,
rec.from_charset,
'utl_i18n.raw_to_char(UTL_I18N.string_to_raw(%s,''' ||
rec.from_charset || '''),''' ||
rec.to_charset || ''')'));
end loop;
end;
end charset_util_pkg;
/
select A.* from charset_util_pkg.convert_any_charset('张三') A;
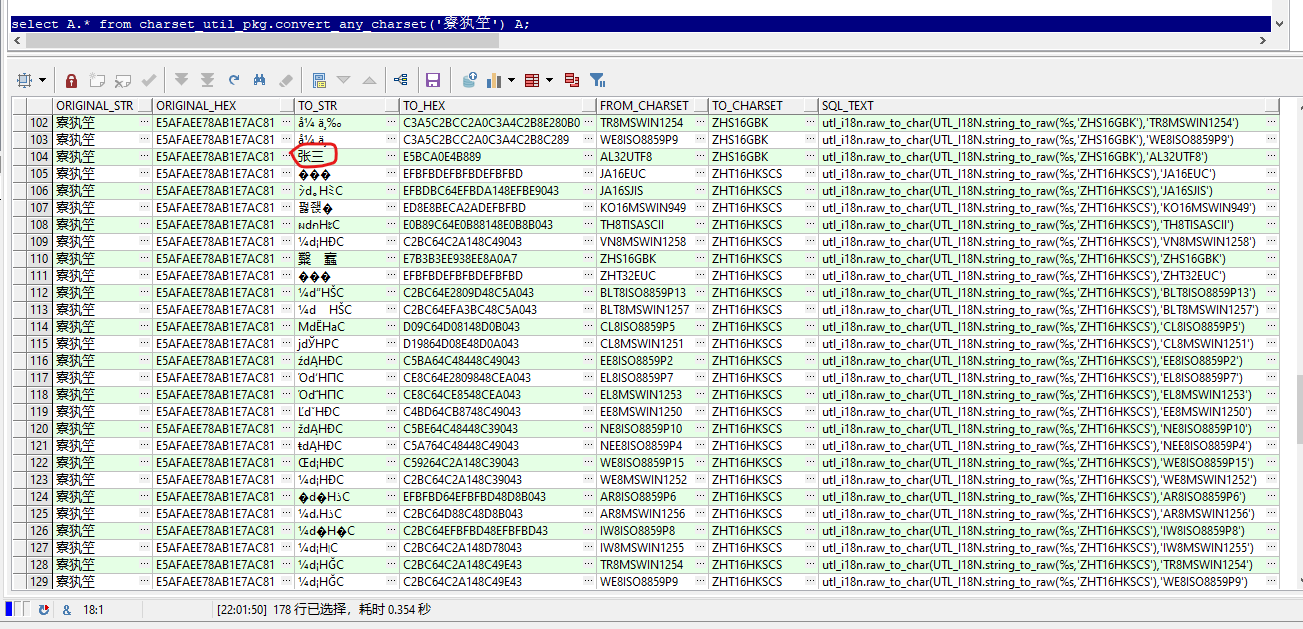
��������ǰ���ݿ��ַ����Լ�����Ŀ
select A.*
from charset_util_pkg.convert_any_charset('张三') A
where from_charset =
(select value
from nls_database_parameters
where parameter = 'NLS_CHARACTERSET');
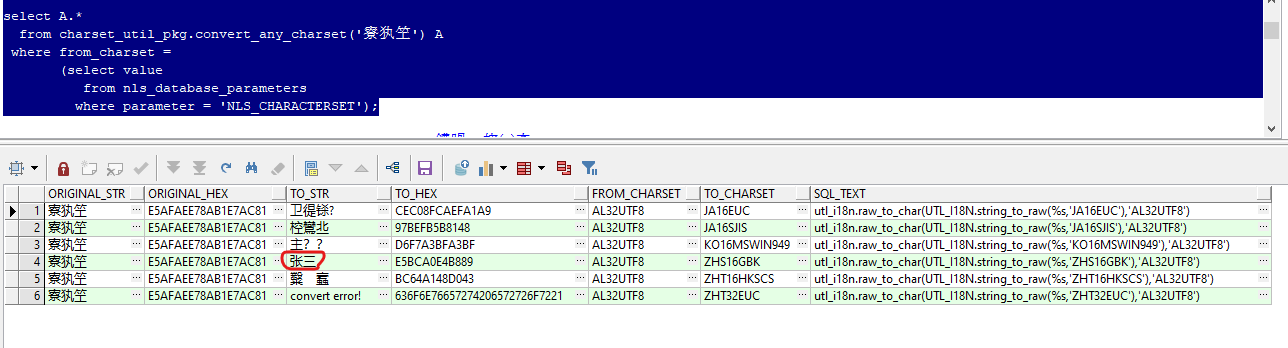
����ʹ������Ϊ�������
select A.*
from test_20220122_1 b,charset_util_pkg.convert_any_charset(b.b) A
where b.b='张三' and from_charset =
(select value
from nls_database_parameters
where parameter = 'NLS_CHARACTERSET');
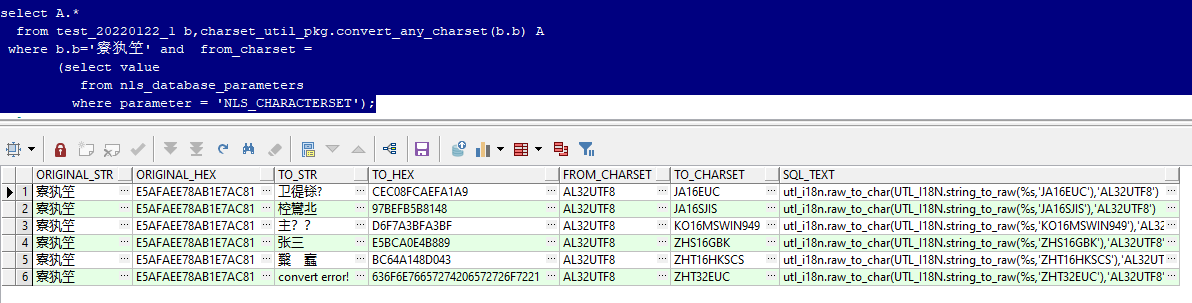
����,�����Դӽ���и������Ӧ��sql_text�Կ��ٻ����ȷ��ת�����롣
�ܽ�
���������о����Ե�֪,���������Ӧ����Ŀ����,��Ӧ�ÿ�����ԱӦ��ռ��Ҫ����,��Ϊ�ͻ����ַ��������ݱ��붼���ɿ�����Աָ����,��һ��ֻ��Ӧ���������ݵ����ݿ���,���������ݿ��ַ����Ĺ�ϵ������(�������ݿⰲװʱָ����һ��ƫ�ŵ��ַ���)��
�����Ӧ����Ŀ����ʱ��ע���ַ�����ͳһ,�ͻ���ָ�����ֵ�����,���粻�������ܲ鵽����,�����Ǹ�ֵ��Ϊ����ȥ���ֲ鲻��;���и�����ֵ����롣
�ص���ͷ���Ǹ�����,��ʵa��b����ֵ����������������еĵ�3�к͵�4�е�ֵ,��Ȼ��ʾһ��,��ʵ��һ����UTF8����,һ����GBK���롣
����ͷ�IJ������ݼ�sql:
create table test_20220122_1 as
select utl_raw.cast_to_varchar2('E5BCA0E4B889') a,
utl_raw.cast_to_varchar2('D5C5C8FD') b
from dual;
select a,
b,
length(a),
length(b),
lengthb(a),
lengthb(b),
UTL_RAW.cast_to_raw(a),
UTL_RAW.cast_to_raw(B)
from test_20220122_1;
ע:���Ͻ����ORACLE���ݿ�,�������ݿ���������������
- ��������: DarkAthena
- ��������: https://www.darkathena.top/archives/about-oracle-charset
- ��Ȩ����: �������������³��ر�������,������CC BY-NC-SA 3.0 ����Э�顣ת����ע������!