步骤
-
开启 kafka 集群
# 三台节点都要开启 kafka
[root@node01 kafka]# bin/kafka-server-start.sh -daemon config/server.properties? ??2. 使用 kafka tool 连接 kafka 集群,创建 topic
?
# 第1种方式通过命令
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic vehicledata --replication-factor 2 --partitions 3
# 查看 kafka topic 的列表
[root@node01 kafka]# bin/kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --list
# 第2种 kafka tool 工具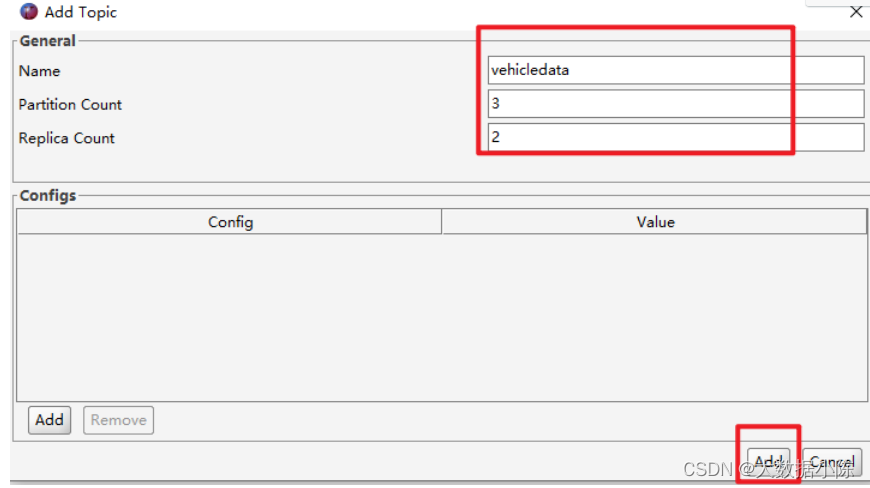
? ?3.通过 flink 将解析后的报文 json 字符串推送到 kafka 中 ?
package cn.itcast.flink.json.producer;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.FileProcessingMode;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.util.Properties;
/**
* 主要用于将解析后的报文json字符串写入到 kafka 集群
* 开发步骤:
* todo 1.flink创建流执行环境,设置并行度
* todo 2.设置开启checkpoint
* todo 3.设置重启策略 不重启
* todo 4.读取File数据源,初始化 FlinkKafkaProducer及必须配置
* todo 5.添加数据源
* todo 6.写入到kafka集群
* todo 7.执行流环境
*/
public class FlinkKafkaWriter {
public static void main(String[] args) throws Exception {
//todo 1.flink创建流执行环境,设置并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//todo 2.设置开启checkpoint
env.enableCheckpointing(5000);
//todo 3.设置重启策略 不重启
env.setRestartStrategy(RestartStrategies.noRestart());
//todo 4.读取File数据源,
DataStreamSource<String> source = env.readFile(
new TextInputFormat(null),
"C:\\Users\\69407\\IdeaProjects\\CarNetworkingSystem\\data\\sourcedata.txt",
FileProcessingMode.PROCESS_CONTINUOUSLY,
60 * 1000
);
//todo 5.初始化 FlinkKafkaProducer及必须配置
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, 5 + "");
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
"vehicledata",
new KafkaSerializationSchema<String>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) {
return new ProducerRecord<byte[], byte[]>(
"vehicledata",
element.getBytes()
);
}
},
props,
FlinkKafkaProducer.Semantic.NONE
);
//todo 6.写入到kafka集群
source.addSink(producer);
//todo 7.执行流环境
env.execute();
}
}
?
?