Redis的持久化方案
? 由于本人之前项目主要使用redis进行业务场景的设计,并且也涉及到了redis的持久化方案。特此写这篇文章来归纳总结。由于之前有对Redis的大体介绍,因此在此对Redis的其他问题不做过多的研究,本篇文章专注于对于Redis持久化方案的研讨。
一、Redis的持久化简介
? 顾名思义,就是将Redis中存的数据存在磁盘当中。这样的好处是当Redis宕机时,就不再需要去数据库中读取数据存入Redis中了,就只需要加载持久化文件即可。除此之外,再部署Redis集群的时候,从机也是通过复制文件的方式进行数据的同步。当然既然存在了磁盘当中,那肯定也会占用一定量的磁盘空间。但目前互联网对于时间空间的抉择策略,一般都会去浪费一些空间去提升一些时间。
二、Redis持久化的方式
? 在Redis官网中介绍到,Redis的持久化方案分为RDB和AOF两种形式(有点MySQL那味儿了)。以下会对Redis持久化的两种方案分别进行讲解。
(1).RDB
? RDB持久化方式就是对你Redis当中的数据进行快照,用更通俗的话来说,假设将Redis当中所有的数据都写在一张纸上,然后用照相机给这张纸拍个照片。将图片放到磁盘上就是持久化后的.rdb文件了。那如果纸上的数据会进行改动怎么办呢?那就再拍一张照片呗。那怎么知道数据会进行改动呢?那就定时每隔一段时间拍一次呗。因此,要是在Redis宕机前更改了数据但是没有拍照,那么这些数据的更改操作将会丢失,所以说RDB持久化的方式可能会导致数据的丢失,因此有了AOF的方式(下文会提到)。
? 那么计算机是怎么对Redis中的数据"拍一张照"呢?
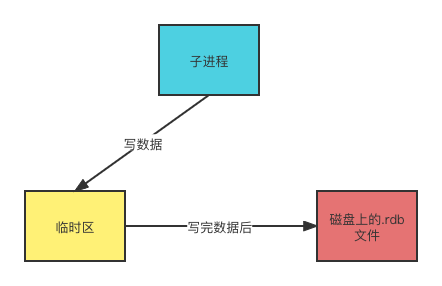
- 操作系统首先会fork()一个进程来单独进行持久化的操作,父进程就不需要管持久化的事情了,该怎么操作就怎么操作。因此RDB的持久化方式能最大化Redis的性能。
- 子进程将Redis当中的数据写入到一个临时的RDB文件中
- 当子进程将Redis中的数据写完时,Redis用临时RDB文件替换原来的RDB文件,并删除旧的RDB文件
? 那么为什么要使用临时的RDB文件而不在原来的RDB文件上进行更改呢?
? 很简单,要是在写RDB文件的时候Redis突然宕机呢,如果不使用临时文件,请问你如何进行回滚的操作呢?如果不回滚,等复原Redis的时候RDB怎么知道写到哪里呢?答案显而易见。
? 除此之外,使用这种方式,还可以从Linux系统中的写时复制机制中获利。在fork()的过程中,由于Linux有着写时复制机制,在复制父进程的时候,子进程并没有自己独立的物理空间,即父子进程的物理空间共享,虚拟空间不同罢了,做到了空间上的优化。

(2).AOF
? 由于RDB持久化方案可能会造成数据的丢失,这个时候AOF的持久化方式就氤氲而生。.rdb文件中的内容十分的简单粗暴,就是Redis中数据的二进制类型。而.aof文件中的内容是每次进行写操作的指令,这里有点类似MySQL当中的binlog。和二进制文件相比,指令文件确实占用的空间较大,因此.aof文件的大小也会存在上限,这里又跟MySQL中的redolog存在checkpoint机制类似,MySQL会重写redolog然后使用binlog进行脏页落盘,而Redis也会对.aof文件进行重写。
? 这个时候您可能会有问题了,要是在重写.aof文件的时候又执行了写操作,这个时候这个写操作是否会在.aof文件中丢失呢?
? 好问题!当然Redis作者肯定也考虑到了这个问题,更巧合的事,他采取的方式和.rdb文件类似,也开辟了一部分空间的缓存,进行.aof文件的重写。在特殊情况时重写的步骤如下:
- fork()一个进程单独进行AOF文件的重写,这里和RDB类似,也享受到了Linux写时复制机制的红利
- 将写命令追加到AOF文件中
- 将写命令追加到AOF过程中创建的缓存中
- 当子进程完成AOF后,它会向父进程发送一个完成信号,父进程接到信号后,就会调用一个信号处理函数完成(5)、(6)步
- 将AOF所创建的缓存中的内容写入到新的AOF文件中,写完这个AOF文件就和Redis目前的状态相同了
- 对新的AOF文件进行改名,覆盖掉原来的AOF文件

? 更有意思的事,你还可以去配置.aof文件什么时候往磁盘上面去写数据。Redis提供了三种方式供您选择。
- 每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全
- 每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
- 从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。
? 推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
? 有了.aof文件之后,如果Redis宕机了想要恢复数据,便可将文件中的指令执行,即可恢复最完整的数据集。
? 那有了AOF就不要RDB了吗?想啥呢渣男!RDB的文件中存储的是二进制文件,比指令所占用的空间小的多,并且RDB进行恢复大数据集时的表现要比AOF更快一些。
三、Redis持久化方案的选择
? 小孩才做选择,大人我全都要!!!
以下均为参考Redis官网的建议:
- 一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
- 如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
- 有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免AOF 程序的 bug 。
- 因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。
? 除此之外,在重启Redis要进行恢复数据时,往往都会采取AOF的方式进行恢复,因为RDB的方式有可能会造成数据的丢失。但是AOF恢复数据的性能比RDB低,这个时候我们即想拥有RDB的速度,又想拥有AOF的准确,这该怎么办呢?
? ”人的欲望是无穷无尽的“,Redis4.0为了解决这个问题,带来了一个新的持久化方案――混合持久化。
? 混合持久化同样也是通过开启AOF完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将AOF重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据。在redis重启的时候,加载 aof 文件进行恢复数据:先加载 rdb 内容再加载剩余的 aof。