一、分组(统计) 查询
1、语法 :
select [distinct] *| 分组字段1[别名] [,分组字段2[别名],…] | 统计函数
from 表名 [别名]
[where 条件(s)]
[group by 分组字段1[,分组字段2]]
[having 分组后的过滤条件(可以使用统计函数)]
[order by 排序字段 asc|desc[,排序字段 asc|desc]];
2、注意分组的细节:
? 分组查询:select 后的字段必须是**分组字段**(跟在group by 后面的字段) 或 统计函数字段
#错误使用分组(统计)查询【查询的字段不是分组字段】
select empno, count(empno) from emp;
? 不能在where 子句中限制组,即**不能在where子句中使用组函数(统计函数)。**
#错误使用分组(统计)查询【组函数出现在where的子句中】
select avg(sal) from emp where avg(sal) > 2000 group by deptno;
? 对分组的结果进行限制(过滤)―使用having对组进行筛选
#查询各个部门的平均工资
select deptno, avg(sal) from emp group by deptno;
#查询平均工资高于2000的部门和其平均工资 ('平均工资高于2000'是分组之后的筛选条件)
select avg(sal) from emp group by deptno having avg(sal) > 2000;
? 并列分组:
-
单列分组:水果分为苹果、香蕉、葡萄。一共分为3个组。
-
什么是并列分组:水果分为苹果、香蕉、葡萄;然后苹果又可以分为红富士、丑苹果;香蕉又分为芭蕉、小米蕉;葡萄又分为红提、青提。一共分成6个组。
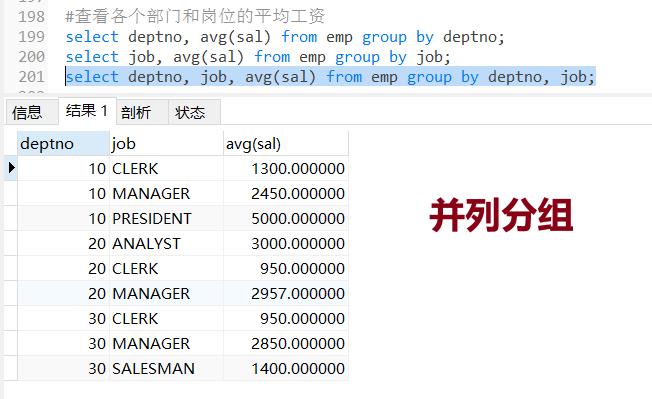
#查看各个部门和岗位的平均工资
select deptno, job, avg(sal) from emp group by deptno, job;
■ sql语句的执行顺序:从哪张表过滤掉不合法数据,然后分组(对分组结果再过滤一下)显示出来,进行排序、分页。
? from where group by having select order by limit
■ where 和 having 执行的先后:
① where 是在分组之前进行筛选,先过滤掉不合法数据, 在 where 之中不能使用统计函数(组函数)。
② having 是在分组之后进行筛选,对组的结果进行过滤。