JDBC
一、JDBC的概述
二、获取数据库连接
1.连接方式一
import org.junit.Test;
import java.sql.Connection;
import java.sql.Driver;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ConnectionText {
@Test
public void test1() throws SQLException{
Driver driver= new com.mysql.jdbc.Driver ();
DriverManager.registerDriver (driver);
String url ="jdbc:mysql://localhost:3306/test";
String user ="root";
String password ="fan1116.";
Connection connection = DriverManager.getConnection (url,user,password);
System.out.println (connection);
}
}
2.连接方式二(反射)
@Test
public void test2() throws SQLException, ClassNotFoundException, IllegalAccessException, InstantiationException {
String className ="com.mysql.jdbc.Driver";
Class classzz=Class.forName (className);
Driver driver= (Driver) classzz.newInstance ();
DriverManager.registerDriver (driver);
String url ="jdbc:mysql://localhost:3306/bjpowernode";
String user ="root";
String password ="fan1116.";
Connection connection = DriverManager.getConnection (url,user,password);
System.out.println (connection);
}
3.连接方式三
@Test
public void test3() throws SQLException, ClassNotFoundException, IllegalAccessException, InstantiationException {
String className ="com.mysql.jdbc.Driver";
String url ="jdbc:mysql://localhost:3306/bjpowernode";
String user ="root";
String password ="fan1116.";
Class.forName (className);
Connection connection = DriverManager.getConnection (url,user,password);
System.out.println (connection);
}
***4.连接方式四(配置文件)
className=com.mysql.jdbc.Driver
url =jdbc:mysql://localhost:3306/bjpowernode
user =root
password =fan1116.
@Test
public void test4() throws IOException, ClassNotFoundException, SQLException {
Properties properties=new Properties ();
InputStream is= ClassLoader.getSystemClassLoader ().getResourceAsStream ("jdbc.properties");
properties.load(is);
String className= properties.getProperty ("className");
String url= properties.getProperty ("url");
String user= properties.getProperty("user");
String password= properties.getProperty ("password");
Class.forName (className);
Connection connection = DriverManager.getConnection (url,user,password);
System.out.println (connection);
}
三、数据库连接池
1.使用数据库连接池的好处?
1.更方便的获取连接对象,效率高
2.资源可以更好的重复利用
3.便于进行必要的管理
2.有哪些数据库连接池技术呢?
DBCP :速度快,不稳定
C3Pe:稳定、速度慢
Druid:兼具二者兼备
Datasource通常被称为数据源,它包含连接池和连接池管理两个部分,习惯上也经常把Datasource称为连接池
3.使用Druid获取连接的方式1
import com.alibaba.druid.pool.DruidDataSource;
import org.junit.Test;
import java.sql.Connection;
import java.sql.SQLException;
public class DruidTest {
@Test
public void test1() throws SQLException {
DruidDataSource source = new DruidDataSource ();
source.setUsername ("root");
source.setPassword ("fan1116.");
source.setUrl ("jdbc:mysql://localhost:3306/bjpowernode");
source.setDriverClassName ("com.mysql.jdbc.Driver");
Connection connection=source.getConnection ();
System.out.println (connection);
source.setMaxActive (6);
}
}
4.使用Druid获取连接的方式2(将数据库连接的基本信息声明在配置文件中)
DriverClassName=com.mysql.jdbc.Driver
url =jdbc:mysql://localhost:3306/bjpowernode
username =root
password =fan1116.
@Test
public void test2() throws Exception {
Properties pros=new Properties ();
InputStream is= ClassLoader.getSystemClassLoader ().getResourceAsStream ("Druid.properties");
pros.load (is);
DataSource dataSource = DruidDataSourceFactory.createDataSource (pros);
System.out.println (dataSource.getConnection ());
}
***5.生成JDBCUtils
package util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCUtils {
public static Connection getconnection() throws Exception {
Properties pros = new Properties ();
InputStream is = ClassLoader.getSystemClassLoader ().getResourceAsStream ("Druid.properties");
pros.load (is);
DataSource dataSource = DruidDataSourceFactory.createDataSource (pros);
Connection connection = dataSource.getConnection ();
return connection;
}
public static void close(Connection connection) {
if(connection!=null){
try {
connection.close ();
} catch (SQLException e) {
e.printStackTrace ();
}
}
}
}
package test;
import org.junit.Test;
import util.JDBCUtils;
import java.sql.Connection;
public class JDBCUtilsTest {
@Test
public void test1() throws Exception{
Connection connection= JDBCUtils.getconnection ();
System.out.println (connection);
}
}
三、数据表的增添查改
1.使用QueryRunner向数据表中插入数据
连接 JDBCUtils 类
package crud;
import org.apache.commons.dbutils.QueryRunner;
import org.junit.Test;
import util.JDBCUtils;
import java.sql.Connection;
public class UpdateTest {
@Test
public void test1() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="insert into copy(ename,sal)values('霸王花',9999)";
QueryRunner runner=new QueryRunner ();
int count = runner.update (getconnection,sql);
System.out.println ("添加了"+count+"记录");
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close(getconnection);
}
}
}
2.使用带占位符的sql添加记录
package crud;
import org.apache.commons.dbutils.QueryRunner;
import org.junit.Test;
import util.JDBCUtils;
import java.sql.Connection;
public class UpdateTest {
@Test
public void test2() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="insert into copy(ename,sal)values(?,?)";
QueryRunner runner=new QueryRunner ();
int count = runner.update (getconnection,sql,"fan",990);
System.out.println ("添加了"+count+"记录");
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close(getconnection);
}
}
}
package util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCUtils {
public static Connection getconnection() throws Exception {
Properties pros = new Properties ();
InputStream is = ClassLoader.getSystemClassLoader ().getResourceAsStream ("Druid.properties");
pros.load (is);
DataSource dataSource = DruidDataSourceFactory.createDataSource (pros);
Connection connection = dataSource.getConnection ();
return connection;
}
public static void close(Connection connection) {
if(connection!=null){
try {
connection.close ();
} catch (SQLException e) {
e.printStackTrace ();
}
}
}
}
3.删除记录的操作
@Test
public void test3() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="delete from copy where sal > ?";
QueryRunner runner=new QueryRunner ();
int count = runner.update (getconnection,sql,1000);
System.out.println ("删除了"+count+"记录");
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close(getconnection);
}
}
4.修改记录的操作
@Test
public void test4() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="update copy set ename=? where sal=?";
QueryRunner runner=new QueryRunner ();
int count = runner.update (getconnection,sql,"fan",666);
System.out.println ("删除了"+count+"记录");
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close(getconnection);
}
}
5.BeanHandle和BeanListHandle查询表中的记录
package crud;
import bean.Customer;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import util.JDBCUtils;
import java.sql.Connection;
import java.util.List;
public class QueryTest {
@Test
public void test1() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="select ename from copy where ename=?";
QueryRunner runner=new QueryRunner ();
BeanHandler<Customer> handler=new BeanHandler (Customer.class);
Customer customer = runner.query (getconnection, sql, handler, "fan");
System.out.println (customer);
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close (getconnection);
}
}
@Test
public void test2() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="select sal from copy where sal>?";
QueryRunner runner=new QueryRunner ();
BeanListHandler<Customer> handler=new BeanListHandler (Customer.class);
List<Customer> customerList = runner.query (getconnection, sql, handler, 100);
customerList.forEach (System.out::println);
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close (getconnection);
}
}
}
package bean;
public class Customer<varchar> {
private varchar ename;
private double sal;
public varchar getEname() {
return ename;
}
public void setEname(varchar ename) {
this.ename = ename;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public Customer() {
}
public Customer(varchar ename, double sal) {
this.ename = ename;
this.sal = sal;
}
@Override
public String toString() {
return "Customer{" + "ename=" + ename + ", sal=" + sal + '}';
}
}
6.MapHandler_MapListHandler_ScalarHandler的使用
import bean.Customer;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.ResultSetHandler;
import org.apache.commons.dbutils.handlers.*;
import org.junit.Test;
import util.JDBCUtils;
import java.sql.Connection;
import java.util.List;
import java.util.Map;
public class QueryTest {
@Test
public void test3() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="select ename,sal from copy where sal>?";
QueryRunner runner=new QueryRunner ();
ResultSetHandler<Map<String,Object>> mapHandler = new MapHandler ();
Map<String, Object> map= runner.query (getconnection, sql, mapHandler, 100);
System.out.println (map);
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close (getconnection);
}
}
@Test
public void test4() {
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="select ename,sal from copy where sal>?";
QueryRunner runner=new QueryRunner ();
ResultSetHandler< List<Map<String, Object>> > mapListHandler = new MapListHandler ();
List<Map<String, Object>> mapList = runner.query (getconnection, sql, mapListHandler, 100);
mapList.forEach (System.out::println);
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close (getconnection);
}
}
@Test
public void test5(){
Connection getconnection = null;
try {
getconnection = JDBCUtils.getconnection ();
String sql="select count(*) from copy";
QueryRunner runner=new QueryRunner ();
ScalarHandler<Object> handler = new ScalarHandler<> ();
long count = (long) runner.query (getconnection, sql, handler);
System.out.println ("一共查询到"+count +"条数据");
} catch (Exception e) {
e.printStackTrace ();
} finally {
JDBCUtils.close (getconnection);
}
}
}
}
}
7.属性名和字段名不一致的情况――使用别名
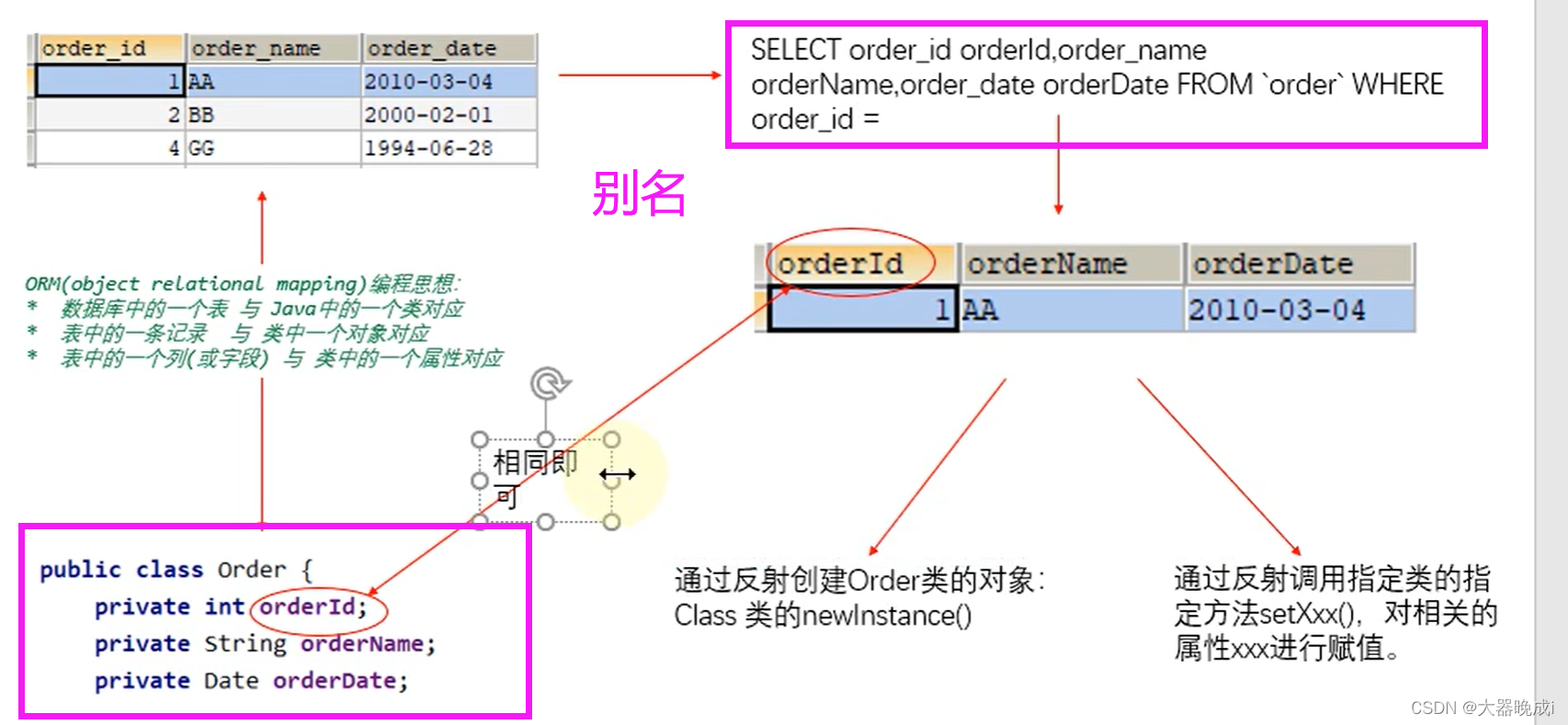
如果表中的字段名与类中的属性名不一致,为了查询操作结果的准确性,我们需要编写sqL时,使用类的属性名作为select后字段的别名出现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6tSMINQB-1643371823229)(C:\Users\86173\AppData\Roaming\Typora\typora-user-images\image-20211115230548012.png)]
String sql="select count(*) from copy";
//3.创建QueryRunner的实例
QueryRunner runner=new QueryRunner ();
//4.通过QueryRunner的实例,调用其query()
ScalarHandler<Object> handler = new ScalarHandler<> ();
long count = (long) runner.query (getconnection, sql, handler);
System.out.println ("一共查询到"+count +"条数据");
} catch (Exception e) {
e.printStackTrace ();
} finally {
//5.关闭资源
JDBCUtils.close (getconnection);
}
}
}
}
}
## 7.属性名和字段名不一致的情况――使用别名
> 如果表中的字段名与类中的属性名不一致,为了查询操作结果的准确性,我们需要编写sqL时,使用类的属性名作为select后字段的别名出现。
|