2多表查询分类
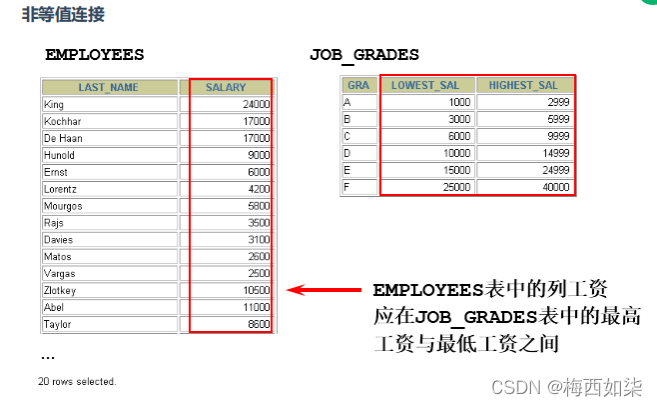
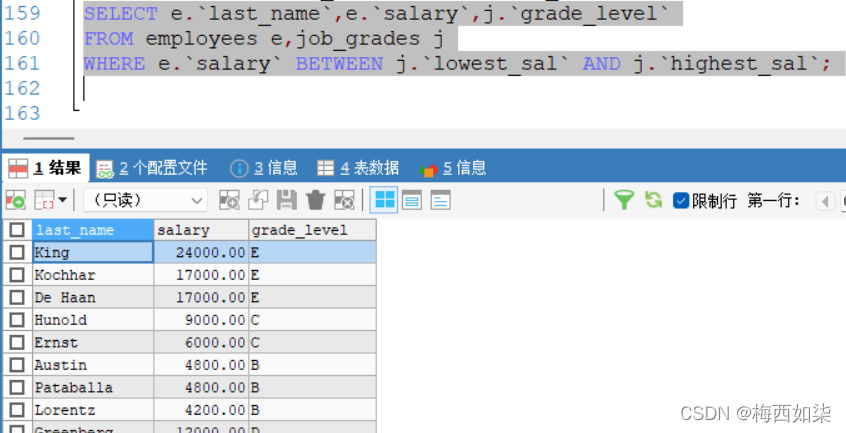
1.等值连接VS非等值连接
就是把两个表对应的两个列,假设对应的值相等,那么就把这两个表连接成一个表
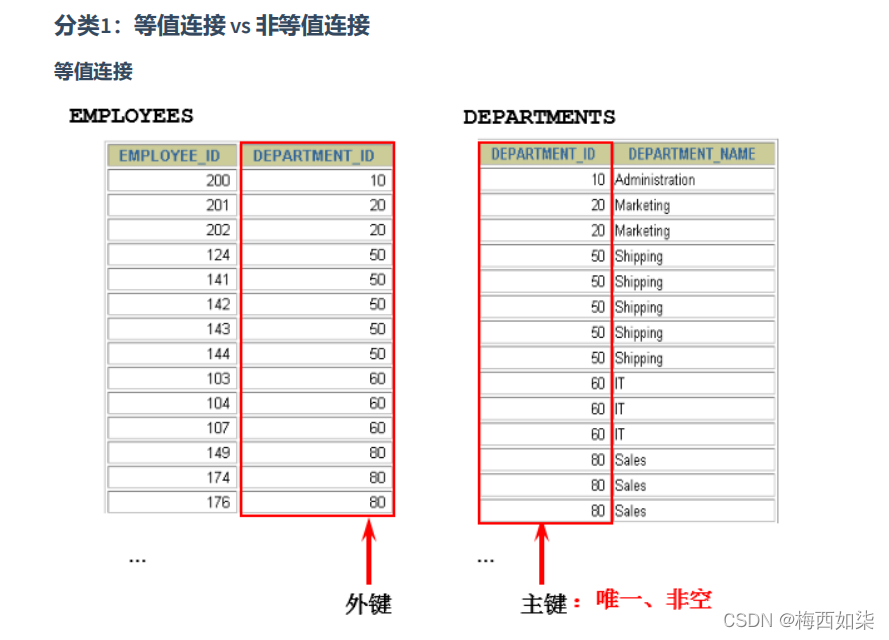
?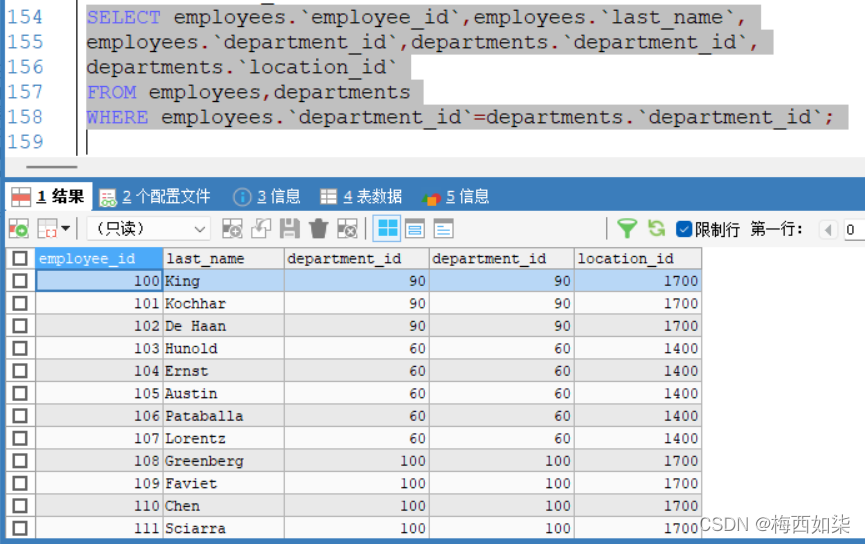
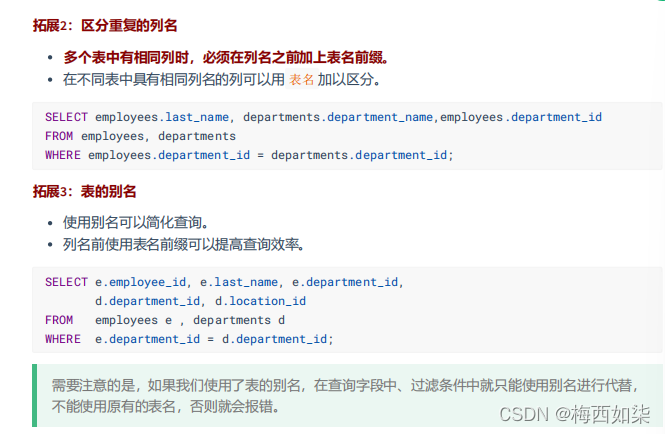
?
2.自连接和非自连接
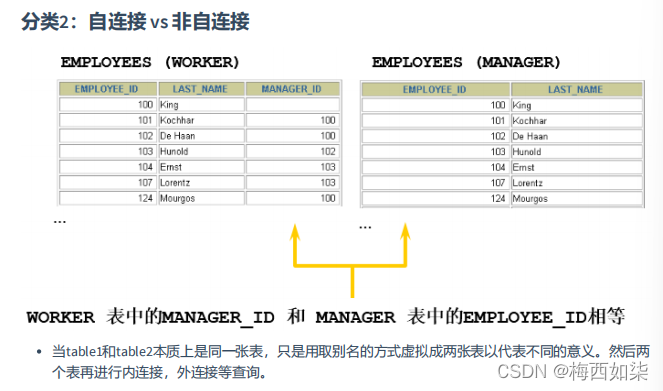
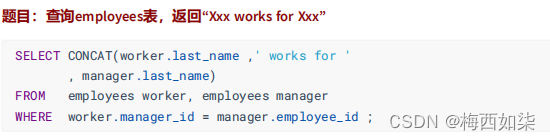
?
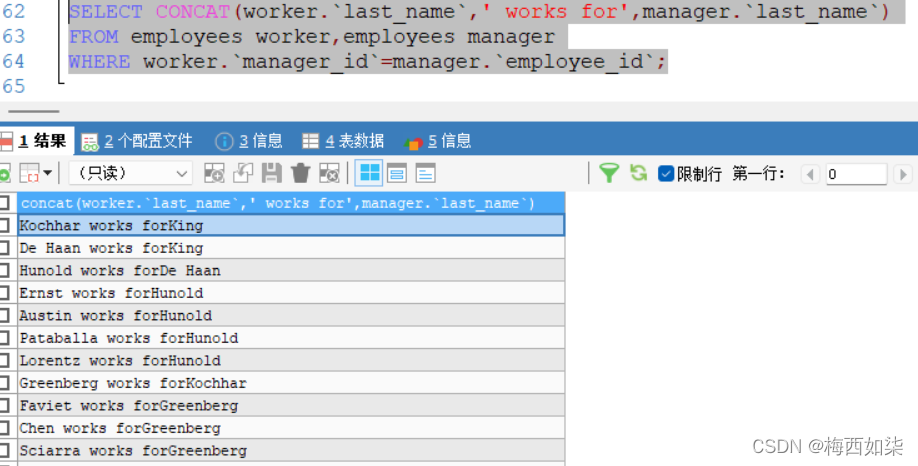
3.内连接vs外连接
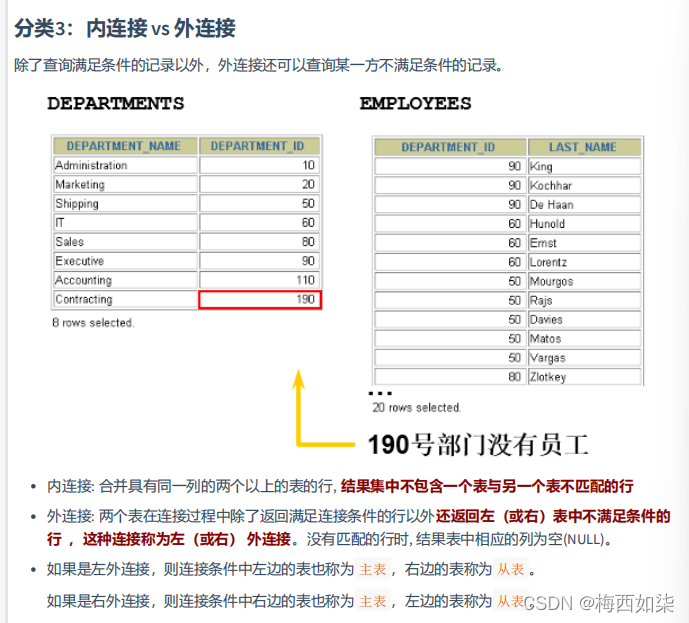
内连接就好像是取交集
外连接分为左外连接和右外连接,
左外连接就是交集+左边不满足的集合。同理右外连接就是?交集+右边不满足的集合
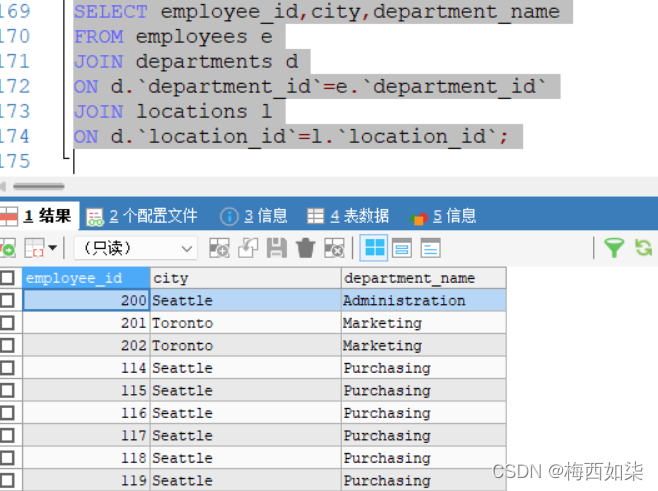
?我们使用SQL99语法实现:
?
 ?例子2:当需要两个条件满足时,必须居住城市和工作地点都应该一样,那么才能进行合并连接
?例子2:当需要两个条件满足时,必须居住城市和工作地点都应该一样,那么才能进行合并连接
?左外连接:
左表中的数据全部显现出来,但是右表中数据只显示与左表相匹配的数据,与左表不匹配的数据我们置为NULL
?我们可以这样想,左外连接=交集+左边不满足的集合
那么就好像这里是把左边的垫高了一层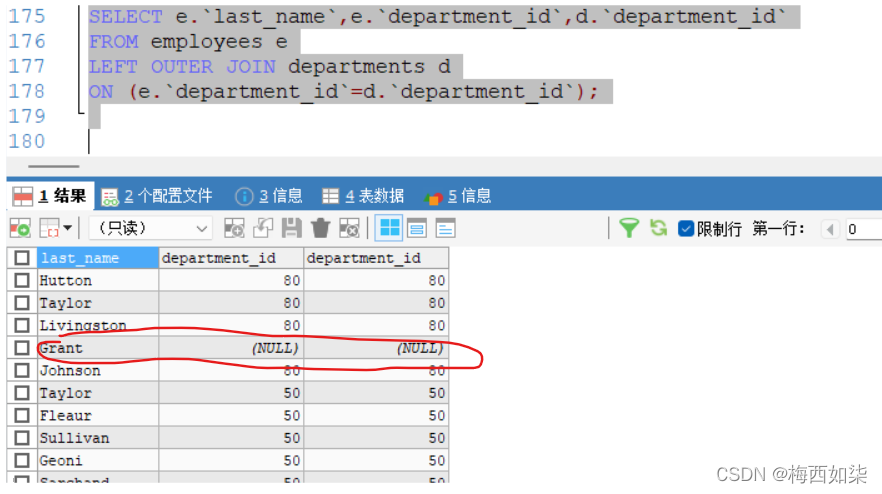
右外连接:
右表中的数据全部显现出来,但是左表中数据只显示与左表相匹配的数据,与右表不匹配的数据我们置为NULL
?
同理左外连接,相当于右边被垫高了
右外连接=交集+不满足条件的右边集合

UNION

?UNION 操作符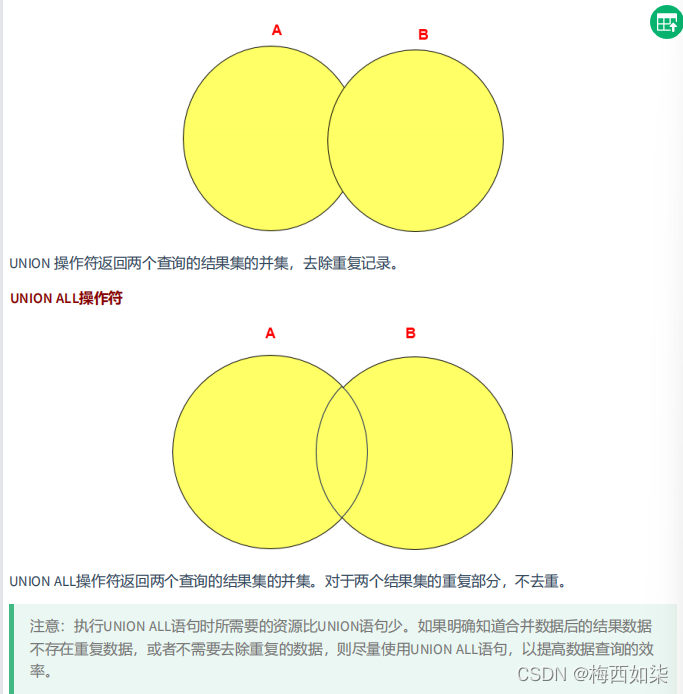
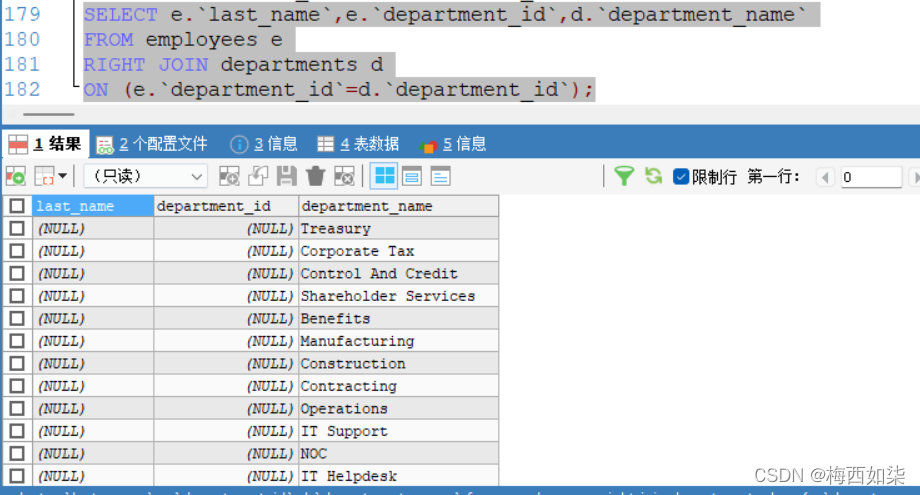
7种SQL JOINS的实现【重点】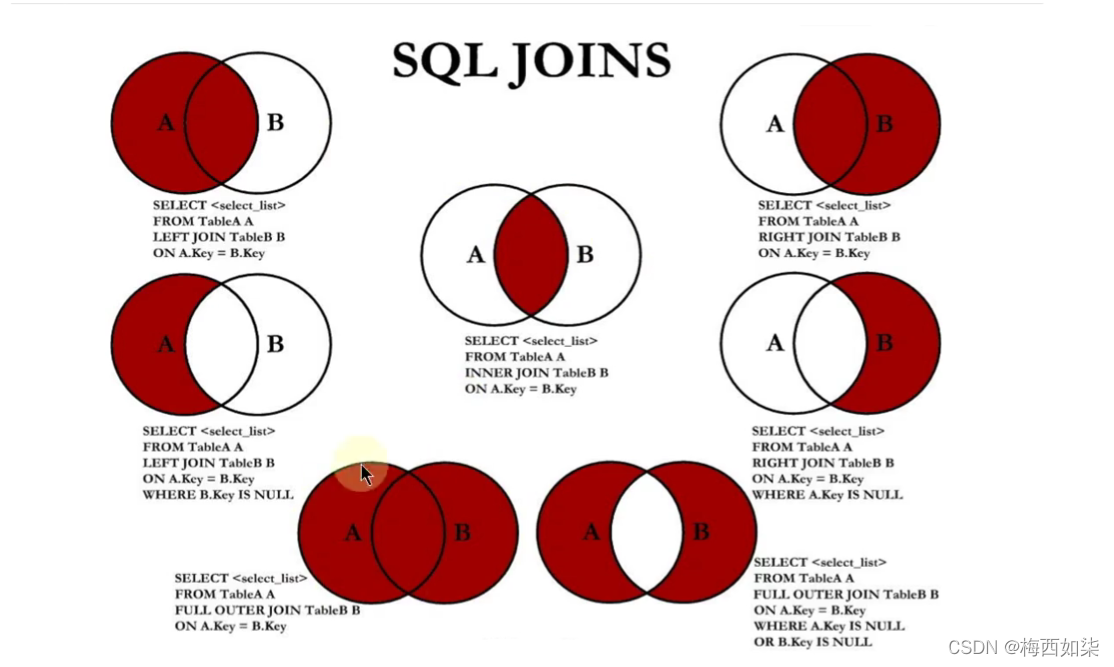
#左上角:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`;
#右上角:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`;
#中图
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id`=d.`department_id`;
#左中图:A集合-AB交集
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`;
WHERE d.'department_id' IS NULL;
#右中图:B集合-AB交集
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`;
WHERE e.department_id IS NULL;
#左下图,满外连接 左上图+右上图
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`;
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`;
#右下图,左中图+右中图
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id`=d.`department_id`;
WHERE d.'department_id' IS NULL;
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id`=d.`department_id`;
WHERE e.department_id IS NULL;
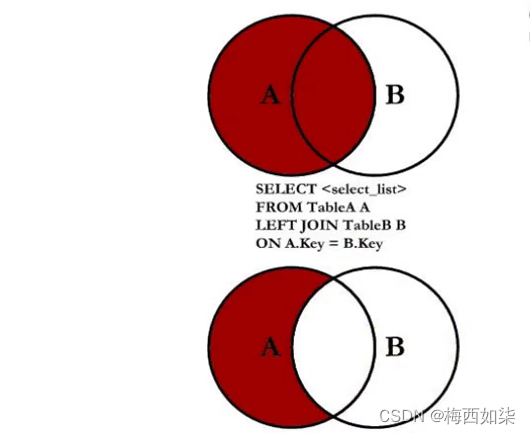
#左中图:A集合-AB交集
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`;
以上三句表示的意思就是左外连接
WHERE d.'department_id' IS NULL;
但是加上第四句之后,就变成如图所示的图片了;
解析:首先看概念,左外连接表示的就是,左表中的数据全部应当展现出来,但是右表中的数据只会展现出和左表对应的数据,右表中不匹配的数据我们使用NULL进行代替
那么这个时候,我们找左下图这个情况的时候,就是当右表为NULL时对应的数据
聚合函数
组函数是什么?
组函数又叫做聚集函数(aggregation function),它在一个行的集合(一组行)上进行操作,对每个组给一个结果。每个组函数接受一个参数。参数expr通常是列或表达式。默认情况下,组函数忽略列值为null的行,不把它们拿来参与计算。
COUNT 细节
?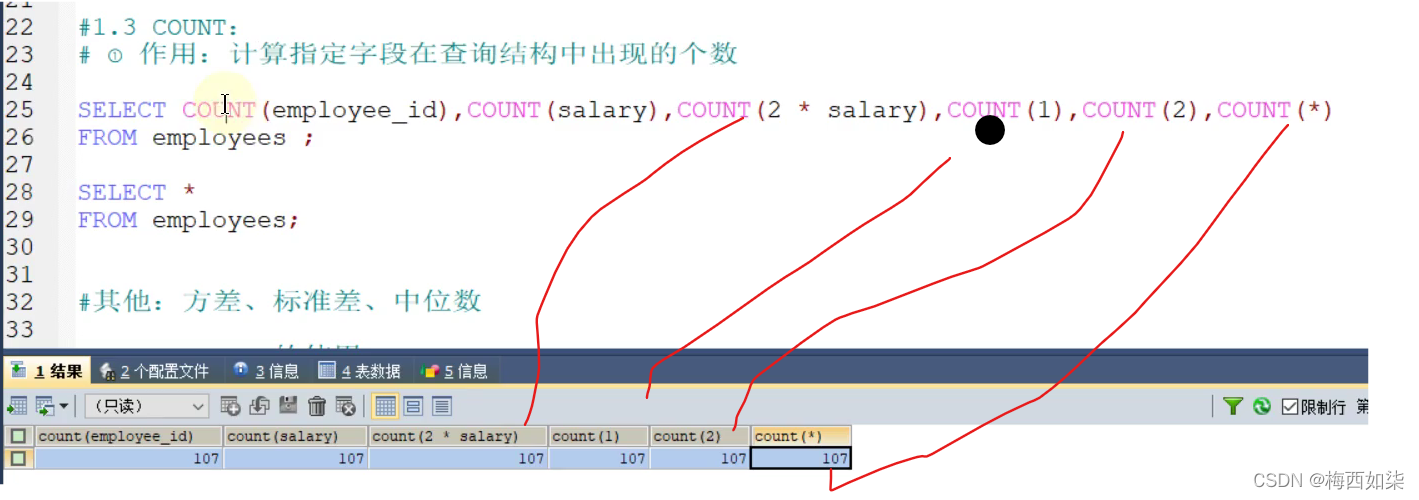
这里COUNT(1)==COUNT(2)==表中数据的总数量(例子中数量为107)
 1.COUNT(字段)返回的是字段不为空的记录总数
1.COUNT(字段)返回的是字段不为空的记录总数
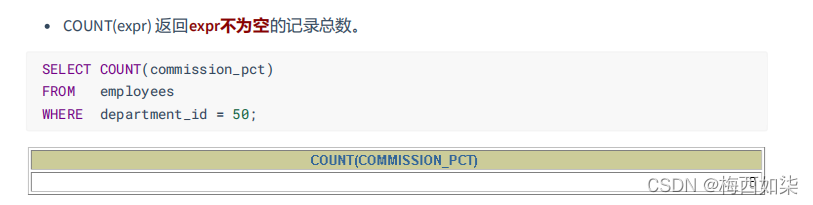
?2.但是COUNT(*)是返回的总数,无论是NULL还是非NULL?

?
对于字段来说,加减运算是没有任何的实际意义的,但是可以比较大小是有意义的
SUM ,AVG,COUNT等方法都是自动进行过滤NULL值的
?练习:对于查询公司中的平均中奖率进行编码实现

?SUM,AVG,等等的方法都是自动进行过滤了NULL值 ,因此我们不可以直接进行AVG(commission_pct),他会过滤掉NULL的情况
但是下面两种正确的情况分析一下:
SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct,0)),我们知道SUM等方法自动过滤NULL值,
所以分子只进行计算了非NULL的值的总和,又因为NULL的值还是没有,与最终想要的结果意义不大。
分母:我们采用的是IFNULL判别,如果为NULL,那么就是COUNT(0),我们前面知道这个值就是1,当查询下一行的时候再进行判断,如果不为NULL,那么就返回commission_pct的值。
AVG(IFNULL(commission_pct,0))这种方法差不多意思,分析即可
如果需要统计表的记录数,使用COUNT(*),COUNT(1),COUNT(具体字段)哪个效率更高?
因情况而定,
如果使用的是MyISAM存储引擎,则三者的效率相同,都是O(1)。因为这种引擎内部有一计数器在维护着行数。
如果使用的是InnoDB存储引擎,则三者效率:COUNT(*)=COUNT(1)>COUNT(字段)。因为对于这种引擎我们知道真的要一行行去数,所以前两者的效率为O(n)。但是要优于COUNT(字段)的效率
GROUP BY 细节
1.这个表示只有当department_id相等的时候,才可以分为一组
GROUP BY department_id2.只有当job_id和department_id都相等的时候,我们才可以把它们分为一组
GROUP BY job_id,department_id;重点规则:
#错误的!
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id;
结论:
1.SELECT中出现的非组函数的字段必须声明在GROUP BY中,反之,GROUP BY中声明的字段可以不出现在SELECT中?。原因就是为了可视化强,否则就会不规则,我们需要遵循这一点的要求
2.顺序:
GROUP BY 声明在FROM后面、WHERE后面,ORDER BY 前面、LIMIT前面
WHITH ROLLUP和ORDER BY相互排斥

HAVING


分析1:不包含聚合函数的过滤条件我们不可以放在HAVING中,
首先我们要明白一点,先执行GROUP BY分组然后才会执行HAVING函数
如果有10万个数据,假设我们直接上去进行GROUP BY分组的话,那么任务量巨大
但是当我们把不包含聚合函数的过滤条件放到where中优先执行,那么把这10万条数据进行优先过滤一次,那么当我们进行分组的时候就任务量相对减少了
分析2:包含聚合函数的过滤条件我们要放在HAVING函数中,不能在where中使用
首先我们知道,聚合函数条件的执行必须先分组
那么假设放在where中,我们还没有进行GROUP分组呢,怎么进行包含聚合函数的条件
因为HAVING一定是执行包含聚合函数条件的函数
并且是使用了GROUP BY函数之后才进行使用的,
WHERE和HAVING的对比
where和having总结:
开发中的选择:
SELECT的执行过程
#sql99语法:
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
#4.2 SQL语句的执行过程:
#FROM ...,...-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY ->
HAVING -> SELECT -> DISTINCT ->ORDER BY -> LIMIT
8)DISTINCT:去重
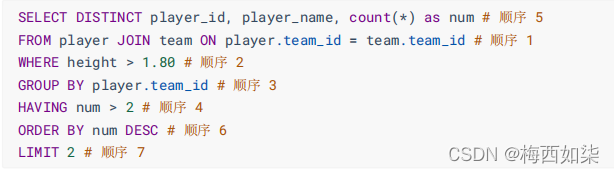
?结论:当我们执行这些SELECT语句的时候,每一个步骤都会产生一个虚拟表。我们把每一个步骤产生的虚拟表作为输入传入到下一个步骤。这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。