环形缓冲区底层实现
首先明白改过程发生在Map――Collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分片(通过调用Partitioner),并写入一个环形内存缓冲区中。

MapOutputBuffer内部使用了一个缓冲区暂时存储用户输出数据,当缓冲区使用率达到一定阈值后,再将缓冲区中的数据写到磁盘上。
数据缓冲区的设计方式直接影响到Map Task的写效率,而现有多种数据结构可供选择,最简单的是单向缓冲区,生产者向缓冲区中单向写入输出,当缓冲区写满后,一次性写到磁盘上,就这样,不断写缓冲区,直到所有数据写到磁盘上。单向缓冲区最大的问题是性能不高,不能支持同时读写数据。
双缓冲区是对单向缓冲区的一个改进,它使用两个缓冲区,其中一个用于写入数据,另一个将写满的数据 写到磁盘上,这样,两个缓冲区交替读写,进而提高效率。实际上,双缓冲区只能一定程度上让读写并行,仍会存在读写等待问题。
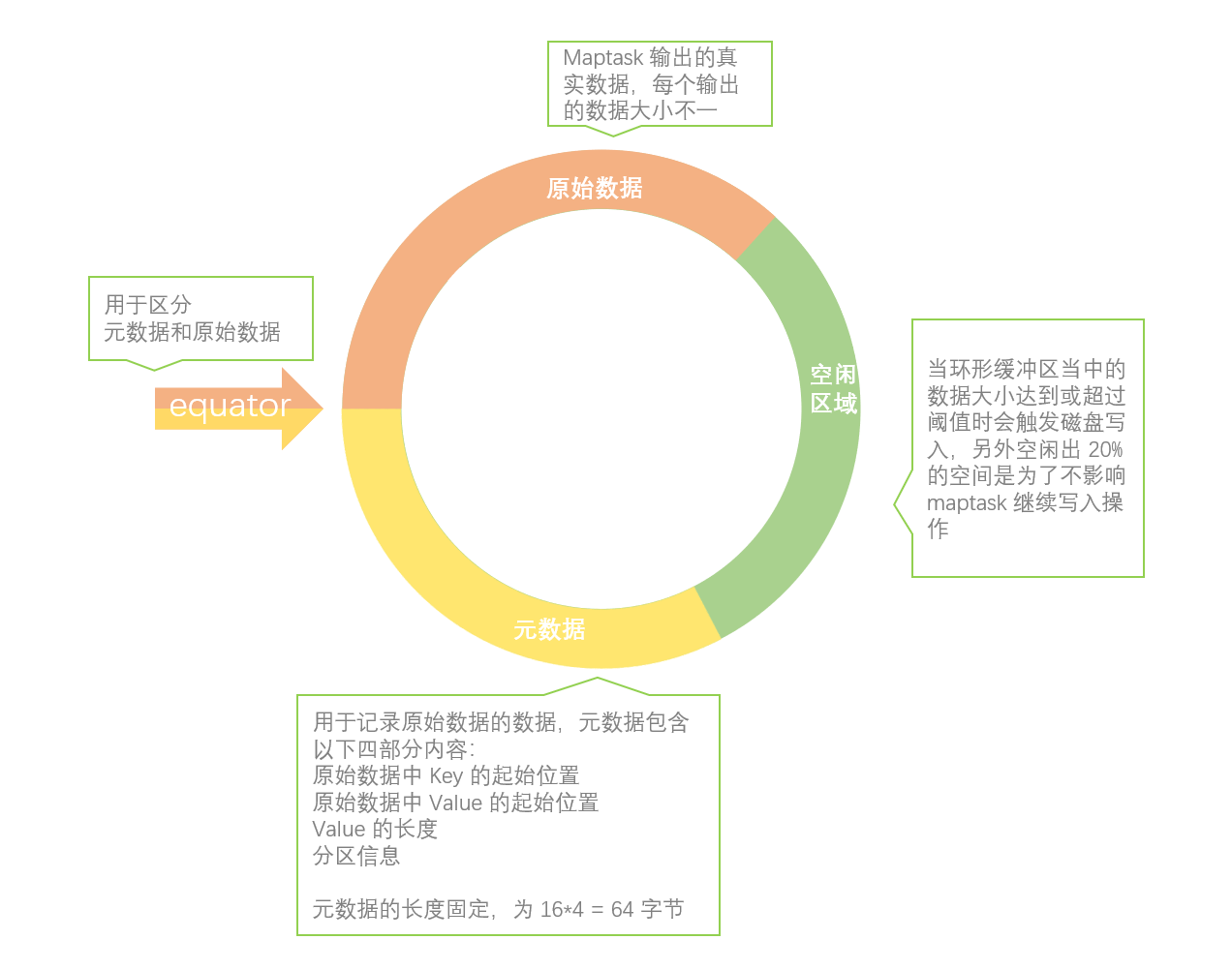
一种更好的缓冲区设计方式是采用环形缓冲区:当缓冲区使用率达到一定阈值后,便开始向磁盘上写入数据,同时,生产者仍可以向不断增加的剩余空间中循环写入数据,进而达到真正的读写并行。
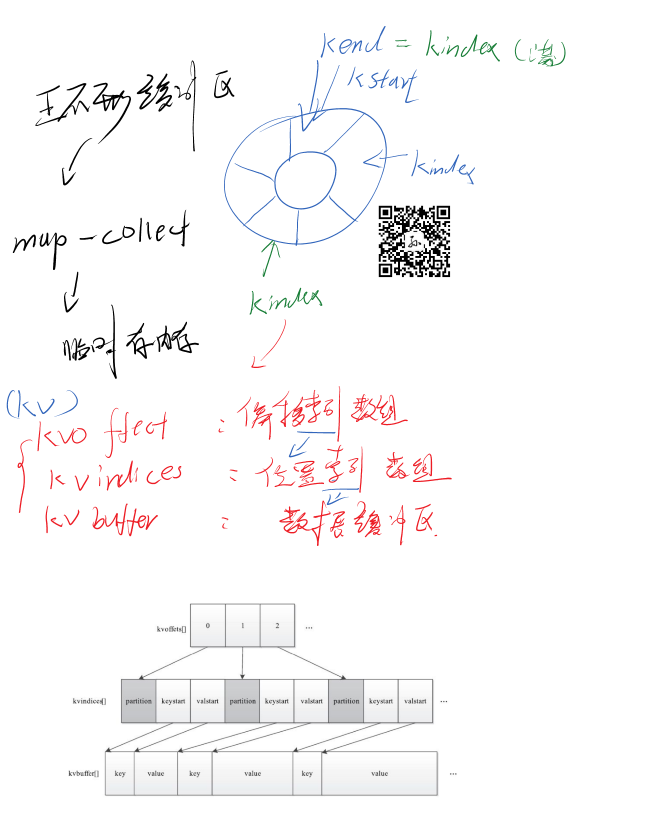
底层就是一个字节数组:数组前面记录关于KV的索引位置,数组后面记录KV数据。首尾相接构成一个环形的缓冲区,中间是赤道。用于数据spll溢出处理。
单生产者消费者模型,其中,MapOutputBuffer的collect方法和MapOutputBuffer.Buffer的write方法是生 产者,spillThread线程是消费者,它们之间同步是通过可重入的互斥锁spillLock和spillLock上的两个条件变量(spillDone和spillReady)完成 的.生产者主要代码如下
//取得下一个可写入的位置
spillLock.lock();
if(缓冲区使用率达到阈值){
//唤醒SpillThread线程,将缓冲区数据写入磁盘
spillReady.signal();
}
if(缓冲区满){
//等待SpillThread线程结束
spillDone.wait();
}
spillLock.lock();
//将数据写入缓冲区
MapOutputBuffer内部采用了两级索引结构,涉及三个环形内存缓冲区,分别是kvoffsets、kvindices和kvbuffer,这三个缓冲 区所占内存空间总大小为io.sort.mb(默认是100 MB)。
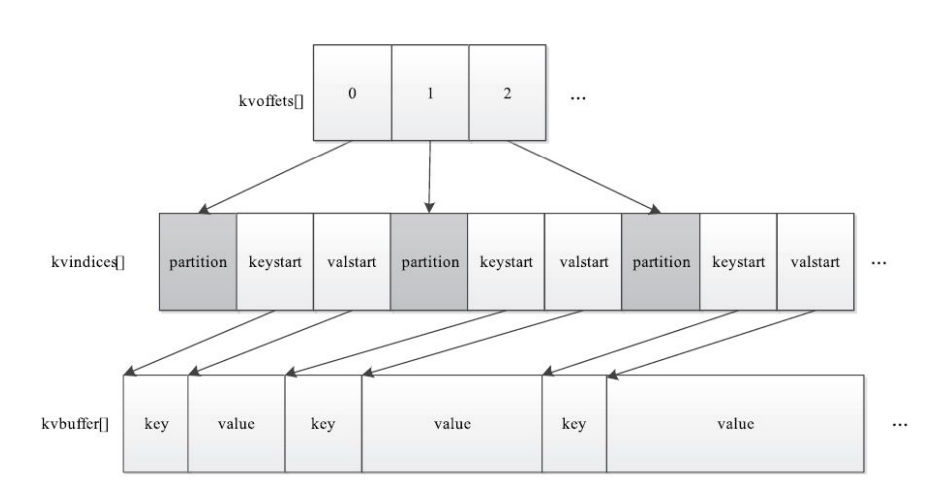
kvoffsets即偏移量索引数组,用于保存key/value信息在位置索引kvindices中的偏移量。考虑到一对key/value需占用数组kvoffsets的1个 int(整型)大小,数组kvindices的3个int大小(分别保存所在partition号、key开始位置和value开始位置),所以Hadoop按比例1:3将大小为 ${io.sort.record.percent}*${io.sort.mb}的内存空间分配给数组kvoffsets和kvindices,
该过 程由指针kvstart/kvend/kvindex控制,其中kvstart表示存有数据的内存段初始位置,kvindex表示未存储数据的内存段初始位置,而在正常写 入情况下,kvend=kvstart,一旦满足溢写条件,则kvend=kvindex,此时指针区间[kvstart, kvend)为有效数据区间。
kvindices即位置索引数组,用于保存key/value值在数据缓冲区kvbuffer中的起始位置。
kvbuffer即数据缓冲区,用于保存实际的key/value值,默认情况下最多可使用io.sort.mb中的95%,当该缓冲区使用率超过 io.sort.spill.percent(默认80%)后,便会触发线程SpillThread将数据写入磁盘。
更多的详细信息你可以参考《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理 》
你可以点这里扫描二维码(或者微信搜 :孙中明) 回复关键字 3006 获取相关书籍此类
{kind=link}