-
什么是分布式计算?
-
分布式程序:MapReduce、Spark、Flink程序
-
多进程:一个程序由多个进程来共同实现,不同进程可以运行在不同机器上
-
每个进程所负责计算的数据是不一样,都是整体数据的某一个部分
-
自己基于MapReduce或者Spark的API开发的程序:数据处理的逻辑
-
分逻辑
-
MR
-
・MapTask进程:分片规则:基于处理的数据做计算
-
判断:文件大小 / 128M > 1.1
-
大于:按照每128M分
-
小于:整体作为1个分片
-
-
大文件:每128M作为一个分片
-
一个分片就对应一个MapTask
-
-
ReduceTask进程:指定
-
-
Spark
-
Executor:指定
-
-
-
-
分布式资源:YARN、Standalone资源容器
-
将多台机器的物理资源:CPU、内存、磁盘从逻辑上合并为一个整体
-
YARN:ResourceManager、NodeManager【8core8GB】
-
每个NM管理每台机器的资源
-
RM管理所有的NM
-
-
Standalone:Master、Worker
-
-
实现统一的硬件资源管理:MR、Flink、Spark on YARN
-
-
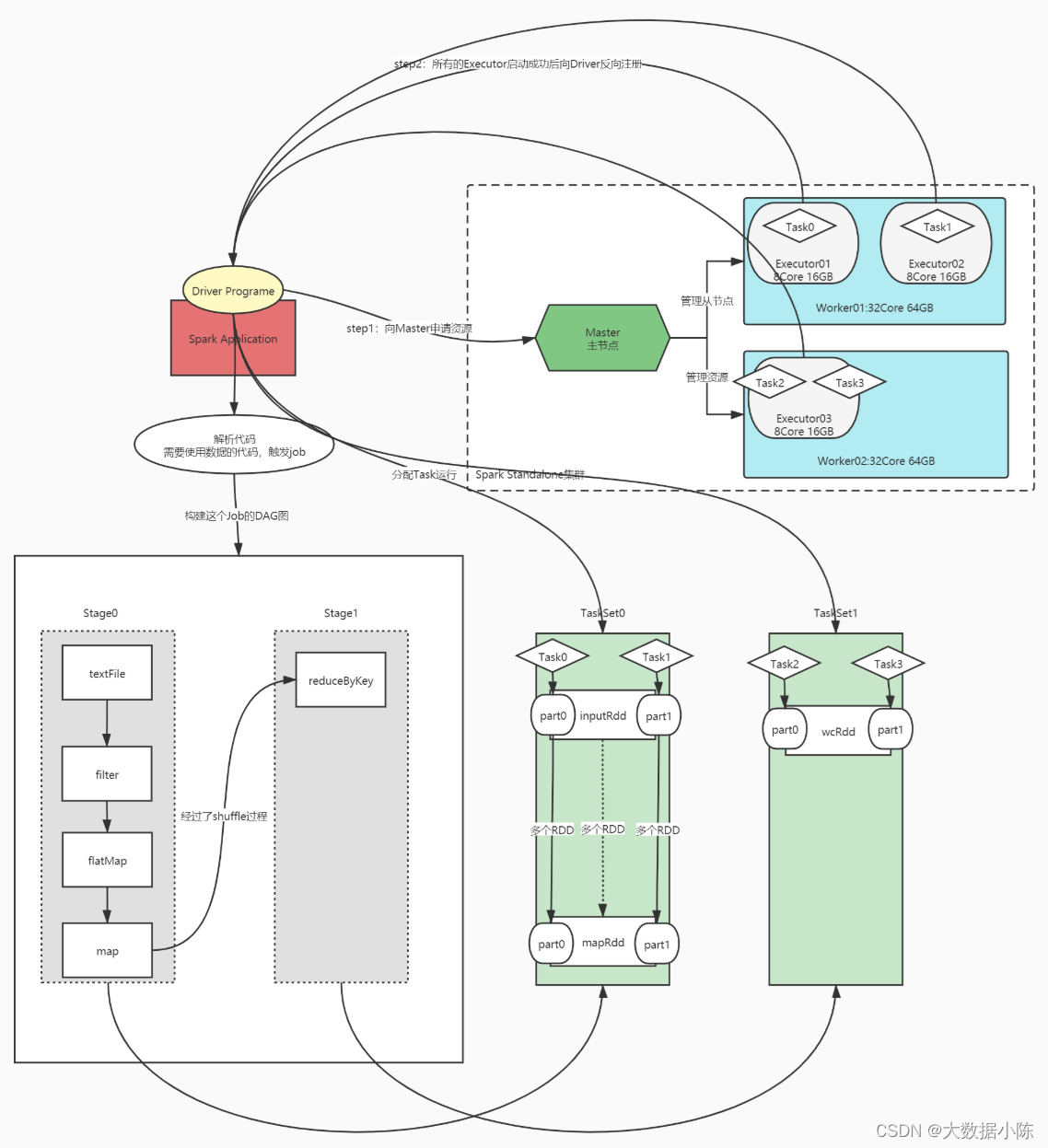
Spark程序的组成结构?
-
Application:程序
-
进程:一个Driver、多个Executor
-
运行:多个Job、多个Stage、多个Task
-
-
什么是Standalone?
-
Spark自带的集群资源管理平台
-
-
为什么要用Spark on YARN?
-
为了实现资源统一化的管理,将所有程序都提交到YARN运行
-
-
Master和Worker是什么?
-
分布式主从架构:Hadoop、Hbase、Kafka、Spark……
-
主:管理节点:Master
-
接客
-
管理从节点
-
管理所有资源
-
-
从:计算节点:Worker
-
负责执行主节点分配的任务
-
-
-
-
Driver和Executer是什么?
-
step1:启动了分布式资源平台
-
step2:开发一个分布式计算程序
-
sc = SparkContext(conf)
# step1:读取数据
inputRdd = sc.textFile(hdfs_path)
#step2:转换数据
wcRdd = inputRdd.filter.map.flatMap.reduceByKey
#step3:保存结果
wcRdd.foreach
sc.stop?step3:提交分布式程序到分布式资源集群运行
spark-submit xxx.py
executor个数和资源
driver资源配置?
-
-
先启动Driver进程
-
申请资源:启动Executor计算进程
-
Driver开始解析代码,判断每一句代码是否产生job
-
-
再启动Executor进程:根据资源配置运行在Worker节点上
-
所有Executor向Driver反向注册,等待Driver分配Task
-
-
-
Job是怎么产生的?
-
当用到RDD中的数据时候就会触发Job的产生:所有会用到RDD数据的函数称为触发算子
-
DAGScheduler组件根据代码为当前的job构建DAG图
-
-
DAG是怎么生成的?
-
算法:回溯算法:倒推
-
DAG构建过程中,将每个算子放入Stage中,如果遇到宽依赖的算子,就构建一个新的Stage
-
Stage划分:宽依赖
-
运行Stage:按照Stage编号小的开始运行
-
将每个Stage转换为一个TaskSet:Task集合
-
-
-
Task的个数怎么决定?
-
一核CPU = 一个Task = 一个分区
-
一个Stage转换成的TaskSet中有几个Task:由Stage中RDD的最大分区数来决定
-
-
Spark的算子分为几类?
-
转换:Transformation
-
返回值:RDD
-
为lazy模式,不会触发job的产生
-
map、flatMap
-
-
触发:Action
-
返回值:非RDD
-
触发job的产生
-
count、first
-
-