目录
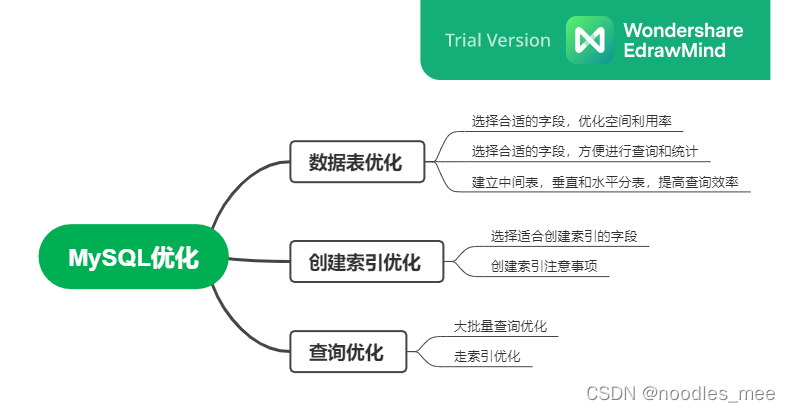
表设计优化
int(10),char(10),varchar(10)区别
int(10),固定长度,不足高位用0补充。char(5)固定长度,不足的使用空格补充。varchar(10),最大长度为10,实际占用空间大小以实际存储的字符数为准。char定长,在存储和取值速度高于varchar,varchar变长,扩张性更强。在执行查询语句时,MySQL通常会使用固定长度内存保存内部值,例如在进行排序时,会为varchar分配最大长度,因此varchar(M)中M值太大,对内存的消耗太大。
第一、节省空间,设置为可以为NULL的字段需要额外的一个字节,标志当前记录的null字段是否为空。
第二、null字段创建索引,统计、查询将变得复杂,例如使用用户表里面,name字段时空,使用count(name),本来要统计user所有记录数,但是count(name)只会对name不是null的记录进行统计。
表中字段为什么尽量设置为NOT NULL
UUID和数据库自增ID选择
使用mysql自增ID,ID连续,方便索引;UUID优点全局唯一,方便进行数据迁移和表合并时,缺点,UUID随机生成,长度较大,插入维护索引时,需要频繁移动数据。
数据量过多的表如何进行处理
第一、按照某个字段,例如店铺kdtId,埋点数据时间进行分片,实现水平拆分,具体数据记录根据分区字段进行取余路由选择分区,主要解决单表数据量太大问题。第二、建立中间表、主要保存表中的常用查询字段,用于校验判断,全量表保存记录所有信息,主要用于根据主键Id获得所有信息。第三、垂直拆分时将一个业务中多张表存储到不同的数据库中,主要为了缓解单台服务器的IO压力。
水平拆分和垂直拆分共同缺点是:第一、引入分布式事务、解决办法;跨库join,解决办法,分开查询,在业务代码中做筛选连接。跨节点排序,分开查,合并分页查询问题。
索引优化
适合创建索引的字段
为需要经常查询、group by、order by和distinct的字段创建索引。
同时还要判断字段的记录数据基数是否很大。
新添加的记录,需要索引维护,对频繁更新的字段也不宜创建索引
创建索引时注意事项
当索引字段太长时,使用前缀索引节约创建的索引的内存占用和维护。
在经常需要联合查询的字段上建立联合索引,同时注意每个字段的查询频率。
sql查询优化
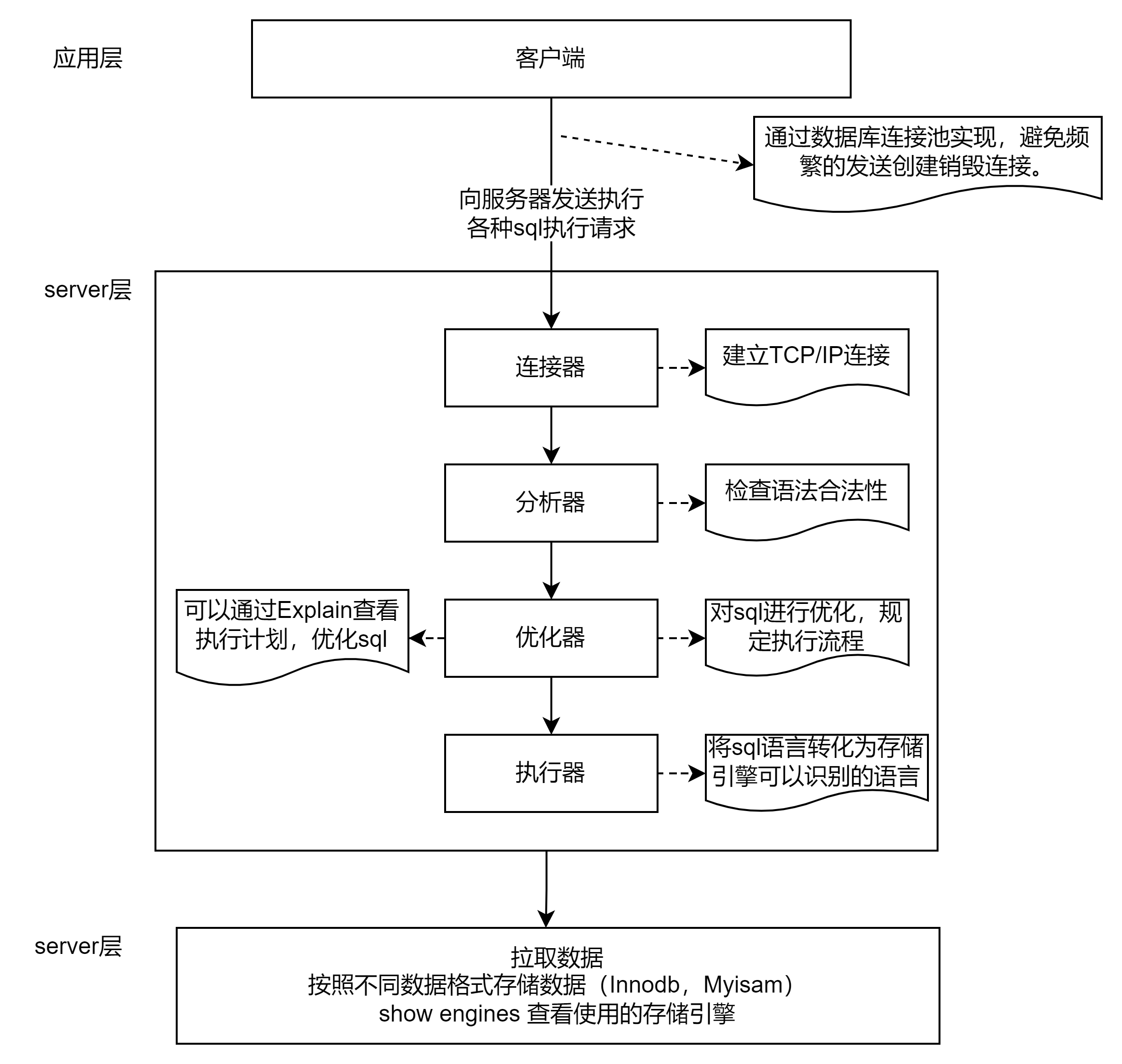
MySQL执行顺序 FROM -》ON-》JOIN-》where-》group by-》having-》select-》distinct-》order by,一条sql执行过程如下图:
MySQL中exits和in区别
-- 查询选修了心里学(cno =7)的所有学生信息
select * from student exits (
select * from selected_course where selected.con = 7 and selected_course.sno = student.sno;
);
select * from student student.sno in (
select * from selected_course where selected.cno = 7
);
exitst 是拿到外表的每一条记录到内表中查询;in是先查询内标,然后将内标每条记录到外表查询。
当外表记录较大,使用in查询;当内表记录较多,使用in查询,原则就是尽量减少内外表数据比较时查询次数。
慢查询日志
慢查询日志主要记录了查询时间超过指定阈值和没有走索引的查询语句。
slow_query_log:1-开启慢查询日志,0关闭慢查询日志。
slow_query_log_file:存储慢查询日志的目录
long_query_time:慢查询时间阈值
log_queries_not_using_indexs: on-开启没有走索引查询的sql,off-关闭。
log_output: “File”-慢查询日志存储为文件,“TABLE”-慢查询日志存储到表中。
处理慢查询日志:
(1)先对MySQL查询执行查询记录,查看走的索引类型和预估的命中数。
(2)如果命中索引,依然很慢,看索引创建是否合适,或者考虑进行水平分区。
(3)优化limit分页。
查询建议
(1)数据大数据量数据,进行分页处理,进行深分页是,可以使用上一页中最大记录id作为查询条件。
(2)查询中减少不必要字段的查询。
(3)复杂运算在客户端执行,减轻数据库引擎压力。
(4)尽量走索引,在where条件、on条件、group by order by中使用索引字段,尽量做到索引覆盖,where查询条件中,如有有非索引字段,无法做到索引覆盖。
(5)尽量避免索引失效,索引失效情况。
在索引执行函数操作。
在索引字段开头使用%模糊匹配。
使用!= ,<> ,is null 和is not null
联合索引中断