CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '����',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '����',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT 'ְλ',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '��ְʱ��',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Ա����¼��';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
Mysql���ѡ����ʵ�����
mysql> EXPLAIN select * from employees where name > 'a';

�����name������Ҫ����name�ֶ�����������,Ȼ����Ҫ���ݱ�������������ֵȥ��������������ȥ�����������,�ɱ���ȫ��ɨ�� ����,�����ø��������Ż�,����ֻ��Ҫ����name�ֶε����������������õ����н��,����:
mysql> EXPLAIN select name,age,position from employees where name > 'a' ;
 ?
?
mysql> EXPLAIN select * from employees where name > 'zzz' ;
 ?
?
�������������� name>'a' �� name>'zzz' ��ִ�н��,mysql�����Ƿ�ѡ������������һ�ű��漰�������,mysql�� �����ѡ������,���ǿ�����trace������һ�龿��,����trace����Ӱ��mysql����,����ֻ����ʱ����sqlʹ��,�� ��֮�������ر�
trace�����÷�:?
mysql> set session optimizer_trace="enabled=on",end_markers_in_json=on; �\�\����trace
mysql> select * from employees where name > 'a' order by position;
mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE;
�鿴trace�ֶ�:
{
"steps": [
{
"join_preparation": { �\�\��һ��:SQL����
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`empl
oyees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from
`employees` where (`employees`.`name` > 'a') order by `employees`.`position`"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { �\�\�ڶ���:SQL�Ż���
"select#": 1,
"steps": [
{
"condition_processing": { �\�\��������
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'a')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'a')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ �\�\����������
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ �\�\Ԥ�����ķ��ʳɱ�
{
"table": "`employees`",
"range_analysis": {
"table_scan": { �\�\ȫ��ɨ�����
"rows": 10123, �\�\ɨ������
"cost": 2054.7 �\�\��ѯ�ɱ�
} /* table_scan */,
"potential_range_indexes": [ �\�\��ѯ����ʹ�õ�����
{
"index": "PRIMARY", �\�\��������
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_name_age_position", �\�\��������
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": { �\�\������������ʹ�óɱ�
"range_scan_alternatives": [
{
"index": "idx_name_age_position",
"ranges": [
"a < name" �\�\����ʹ�÷�Χ
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, �\�\ʹ�ø�������ȡ�ļ�¼�Ƿ�����������
"using_mrr": false,
"index_only": false, �\�\�Ƿ�ʹ�ø�������
"rows": 5061, �\�\����ɨ������
"cost": 6074.2, �\�\����ʹ�óɱ�
"chosen": false, �\�\�Ƿ�ѡ�������
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { �\�\���ŷ���·��
"considered_access_paths": [ �\�\����ѡ��ķ���·��
{
"rows_to_scan": 10123,
"access_type": "scan", �\�\��������:Ϊscan,ȫ��ɨ��
"resulting_rows": 10123,
"cost": 2052.6,
"chosen": true, �\�\ȷ��ѡ��
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 10123,
"cost_for_plan": 2052.6,
"sort_cost": 10123,
"new_cost_for_plan": 12176,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'a')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'a')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"clause_processing": {
"clause": "ORDER BY",
"original_clause": "`employees`.`position`",
"items": [
{
"item": "`employees`.`position`"
}
] /* items */,
"resulting_clause_is_simple": true,
"resulting_clause": "`employees`.`position`"
} /* clause_processing */
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"steps": [
] /* steps */,
"index_order_summary": {
"table": "`employees`",
"index_provides_order": false,
"order_direction": "undefined",
"index": "unknown",
"plan_changed": false
} /* index_order_summary */
} /* reconsidering_access_paths_for_index_ordering */
},
{
"refine_plan": [
{
"table": "`employees`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": { �\�\������:SQLִ�н�
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}
����:ȫ��ɨ��ijɱ���������ɨ��,����mysql����ѡ��ȫ��ɨ��
mysql> select * from employees where name > 'zzz' order by position;
mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE;
�鿴trace�ֶο�֪����ɨ��ijɱ�����ȫ��ɨ��,����mysql����ѡ������ɨ��
mysql> set session optimizer_trace="enabled=off"; �\�\�ر�trace?����sql�����Ż�
Order by��Group by�Ż�
Case1:

����:
��������ǰ����:�м��ֶβ��ܶ�,��˲�ѯ�õ���name����,��key_len=74Ҳ�ܿ���,age�������������������,��ΪExtra�ֶ���û��using filesort?
Case 2:

����:
��explain��ִ�н������:key_len=74,��ѯʹ����name����,��������position��������,������ age,������Using filesort��?
Case 3:

?����:
����ֻ�õ�����name,age��position��������,��Using filesort��
Case 4:
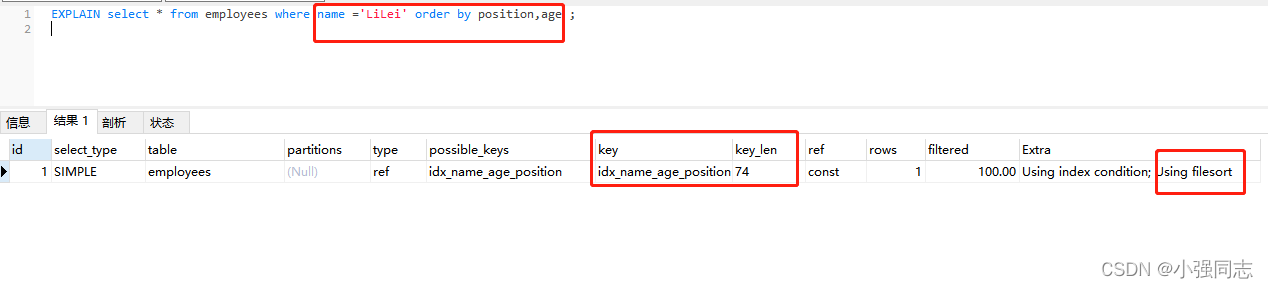
����:
��Case 3��explain��ִ�н��һ��,���dz�����Using filesort,��Ϊ�����Ĵ���˳��Ϊ name,age,position,���������ʱ��age��position�ߵ�λ���ˡ�?
Case 5:

����:
��Case 4�Ա�,��Extra�в�δ����Using filesort,��ΪageΪ����,�������б��Ż�,��������δ�ߵ�, �������Using filesort��?
Case 6:

����:
��Ȼ������ֶ���������˳��һ��,��order byĬ������,����position desc����˽���,������������ ����ʽ��ͬ,�Ӷ�����Using filesort��Mysql8���ϰ汾�н�����������֧�ָ��ֲ�ѯ��ʽ��?
Case 7:

����: ����������˵,����������Ҳ�Ƿ�Χ��ѯ
Case 8:?

�����ø��������Ż�
 ?
?
�Ż��ܽ�:
1��MySQL֧�����ַ�ʽ������filesort��index,Using index��ָMySQLɨ�����������������index Ч�ʸ�,filesortЧ�ʵ͡�
2��order by�������������ʹ��Using index��
1) order by���ʹ����������ǰ�С�
2) ʹ��where�Ӿ���order by�Ӿ����������������������ǰ�С�
3�����������������������,��ѭ��������(����������˳��)ʱ������ǰ����
4�����order by������������������,�ͻ����Using filesort��
5�����ø������������ø�������
6��group by��order by������,��ʵ��������������,������������˳�������ǰ������group by���Ż��������Ҫ����Ŀ��Լ���order by null��ֹ����ע��,where����having,��д��where�� ���������Ͳ�Ҫȥhaving���ˡ�
Using filesort�ļ�����ԭ�����
filesort�ļ�����ʽ
��·����:��һ����ȡ�����������е������ֶ�,Ȼ����sort buffer�н�������;��trace���߿� �Կ���sort_mode��Ϣ����ʾ< sort_key, additional_fields >����< sort_key, packed_additional_fields >
˫·����(�ֽлر�����ģʽ):�����ȸ�����Ӧ������ȡ����Ӧ�������ֶκͿ���ֱ�Ӷ�λ�� ���ݵ��� ID,Ȼ���� sort buffer �н�������,���������Ҫ�ٴ�ȡ��������Ҫ���ֶ�;��trace���� ���Կ���sort_mode��Ϣ����ʾ< sort_key, rowid >
MySQL ͨ���Ƚ�ϵͳ���� max_length_for_sort_data(Ĭ��1024�ֽ�) �Ĵ�С����Ҫ��ѯ���ֶ��ܴ�С�� �ж�ʹ����������ģʽ��
��� max_length_for_sort_data �Ȳ�ѯ�ֶε��ܳ��ȴ�,��ôʹ�� ��·����ģʽ;
��� max_length_for_sort_data �Ȳ�ѯ�ֶε��ܳ���С,��ôʹ�� ˫·����ģʽ��
ʾ����֤�¸�������ʽ:?

�鿴������sql��Ӧtrace�������(ֻչʾ����):
mysql> set session optimizer_trace="enabled=on",end_markers_in_json=on; �\�\����trace
mysql> select * from employees where name = 'LiLei' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;
trace���ֽ��:
"join_execution": { �\�\Sqlִ�н�
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { �\�\�ļ�������Ϣ
"rows": 10000, �\�\Ԥ��ɨ������
"examined_rows": 10000, �\�\�����������
"number_of_tmp_files": 3, �\�\ʹ����ʱ�ļ��ĸ���,���ֵ���Ϊ0����ȫ��ʹ�õ�sort_buffer�ڴ�����,����ʹ�õ�
�����ļ�����
"sort_buffer_size": 262056, �\�\����Ĵ�С
"sort_mode": "<sort_key, packed_additional_fields>" �\�\����ʽ,�����õĵ�·����
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
mysql> set max_length_for_sort_data = 10; �\�\employees�������ֶγ����ܺͿ϶�����10�ֽ�
mysql> select * from employees where name = 'LiLei' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;
trace���ֽ��:
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"rows": 10000,
"examined_rows": 10000,
"number_of_tmp_files": 2,
"sort_buffer_size": 262136,
"sort_mode": "<sort_key, rowid>" �\�\����ʽ,�����õ�˫·����
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
mysql> set session optimizer_trace="enabled=off"; �\�\�ر�trace
?�����ȿ���·�������ϸ����:
1. ������name�ҵ���һ������ name = ��LiLei�� ���������� id
2. �������� id ȡ������,ȡ�������ֶε�ֵ,���� sort_buffer ��
3. ������name�ҵ���һ������ name = ��LiLei�� ���������� id
4. �ظ����� 2��3 ֱ�������� name = ��LiLei��
5. �� sort_buffer �е����ݰ����ֶ� position ��������
6. ���ؽ�����ͻ���
�����ٿ���˫·�������ϸ����:
1. ������ name �ҵ���һ������ name = ��LiLei�� ������id
2. �������� id ȡ������,�������ֶ� position ������ id �������ֶηŵ� sort buffer ��
3. ������ name ȡ��һ������ name = ��LiLei�� ��¼������ id
4. �ظ� 3��4 ֱ�������� name = ��zhuge��
5. �� sort_buffer �е��ֶ� position ������ id �����ֶ� position ��������
6. ��������õ� id ���ֶ� position,���� id ��ֵ�ص�ԭ����ȡ�� �����ֶε�ֵ���ظ��ͻ���
��ʵ�Ա���������ģʽ,��·������������Ҫ��ѯ���ֶζ��ŵ� sort buffer ��,��˫·����ֻ������� ����Ҫ������ֶηŵ� sort buffer �н�������,Ȼ����ͨ�������ص�ԭ����ѯ��Ҫ���ֶΡ�
��� MySQL �����ڴ����õıȽ�С����û����������������,�����ʵ��� max_length_for_sort_data �� ��С��,���Ż���ѡ��ʹ��˫·�����㷨,������sort_buffer ��һ������������,ֻ����Ҫ�ٸ������� �ص�ԭ��ȡ���ݡ� ��� MySQL �����ڴ��������������ñȽϴ�,�����ʵ����� max_length_for_sort_data ��ֵ,���Ż��� ����ѡ��ȫ�ֶ�����(��·����),����Ҫ���ֶηŵ� sort_buffer ��,���������ͻ�ֱ�Ӵ��ڴ��ﷵ�ز� ѯ����ˡ�
����,MySQLͨ�� max_length_for_sort_data �����������������,�ڲ�ͬ����ʹ�ò�ͬ������ģʽ, �Ӷ���������Ч�ʡ�
ע��,���ȫ��ʹ��sort_buffer�ڴ�����һ�������Ч�ʻ���ڴ����ļ�����,��������Ϊ���������� ��sort_buffer(Ĭ��1M),mysql�ܶ�������ö��������Ż���,��Ҫ������