redis实现分布式锁要点速通_运气不好努力来凑-CSDN博客redis实现分布式锁的原理以及注意事项。看了这篇文章的都说简单https://blog.csdn.net/wai_58934/article/details/122609458?spm=1001.2014.3001.5501分布式下缓存Redis_运气不好努力来凑-CSDN博客redis作为缓存――基础知识扫盲
https://blog.csdn.net/wai_58934/article/details/122607462?spm=1001.2014.3001.5501
?
目录
Redis和mysql数据不一致问题
- 先更mysql,再更新redis。如果redis更新失败则之后可能读到老数据。
- 先删除redis,再更新mysql,再次查询时写入redis。高并发下性能较低。并且如果你删除redis之后,一个更新线程还没来得及更新就被一个查询线程查询了。写入redis的数据仍是老数据。
- 先删除redis,然后更新mysql,隔几百毫秒再删除redis缓存的数据。(延时双删,常用)
Redis数据结构以及使用场景
常用:string、list、set、hash、zset
- string:分布式锁的实现、计数器。
- list:可以用作栈和队列。可缓存消息流数据。
- set:可以找到交集、并集、差集。可实现共同好友、朋友圈点赞等功能。
- hash:适合存储对象。
- zset:有序、可以实现排行榜功能。
不常用:
- bitmap:布隆过滤器
- geohash:坐标
- hyperloglog:统计不重复数据,用于大数据基数统计
- streams:内存版kafka
Redis主从复制核心原理
- 集群启动,主从先建立连接。
- 主库数据同步给从库。依赖于内存快照RDB。
- 但是同步过程中主库仍会接收写操作。但是刚才的快照已经发过去了。所以采取补救措施,主库内存中会有replication buffer去专门记录同步过程中未同步的写操作。
- 再发送完快照之后,紧接着发送replication buffer,完成主从同步。
- 后续就将写操作给主库,之后增量同步给从库。
Redis为什么这么快
- IO多路复用,同时监听多个socket
- 单线程(网络事件处理器是单线程的),无需上下文切换(并不是说redis中没有其他线程。如从节点同步还需要额外的线程)
- 基于纯内存操作。
Redis过期键的删除策略
- 惰性过期:使用到才去删除。对cpu友好,对内存不友好(可能导致大量过期键堆积)
- 定期过期:间隔一段时间扫描过期字典里的部分key,去删除。
redis同时使用两种策略。
什么是缓存预热
提前将相关的缓存数据加载到缓存系统中,避免刚上线使用户有太多请求打到数据库上去
哨兵模式
-
通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
-
当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
单个哨兵也会出现问题,所以我们设置哨兵集群。哨兵不仅监控主从节点,哨兵之间还互相监控。
如果master节点挂了,单个哨兵会先认为主观下线,后面的哨兵也检测到主服务器不可用,并且数量达到一定值时切换选举的master,并且使用发布订阅模式切换主机,这叫做客观下线。
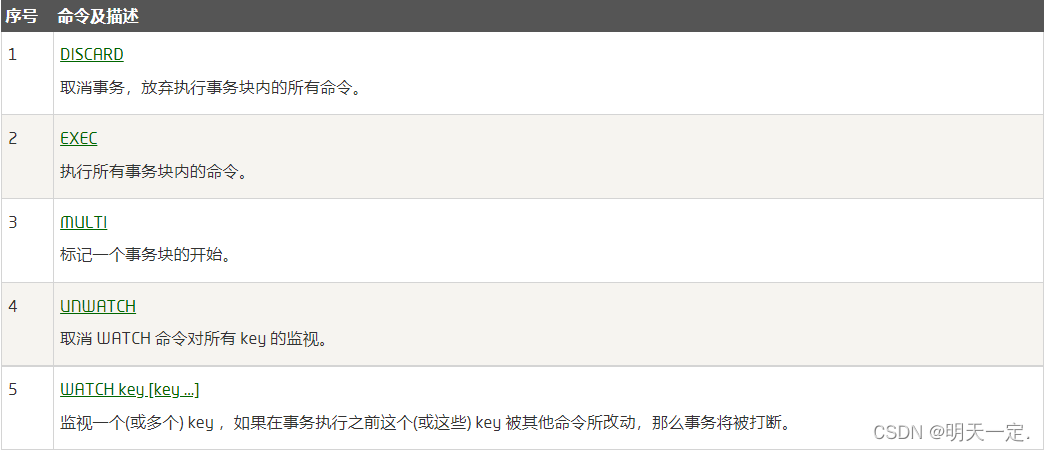
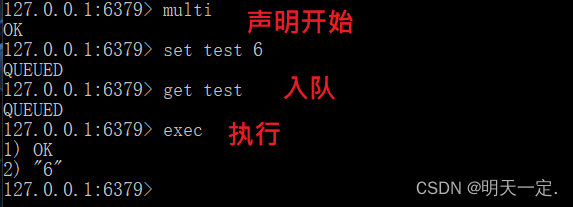
Redis事务是如何实现的
- 开始事务
- 命令入队
- 执行事务
注意:redis只能帮你检测语法的错误而不能检测逻辑的错误,如果逻辑有错误,除了有错误的地方,其他地方照常执行。
实例:
?
?为什么在6.x引入多线程
?Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率
?