ѧϰĿ��
�������ָ����Դ����
��������(OLAP)�����ݿ�(OLTP)����
�������ֲַ�ܹ�˼��
����Apache Hive������ܹ����
����Apache HiveԶ��ģʽ����װ
���ݴ��
#���ݲֿ��������֪ʶ
1�����ݲֿ���ʲô Ϊ�ζ���?
Ϊ�˷������ݶ��� ���ݷ�����ƽ̨
2�����ݲֿ������
3�����ݲֿ�����ݿ������
OLTPϵͳ
OLAPϵͳ
ע��:����Ҫ���һ�����ĵ�����:���־����Ǵ������ݿ⡣ ��ô���������
4�����ݲֿ�ķֲ�ܹ�
�����������������ص� ���зֲ�
5��ETL��ELT����
#����������������������--Apache Hive
1��Hive��ʲô?
����Hadoop������ ��������Hadoop��ϵ?
������:
a�����ṹ���ļ�ӳ���Ϊһ�ű�(Table)
b�����ڱ��ṩ��SQL�������� (Hive SQL HQL,��SQL)
����:�û�HQL--->Hiveת��MR--->���ݷ���
2��Hive�ļܹ����
3��Hive�İ�װ����
metadata metastore����
���ֲ���ģʽ
�γ�ʹ��Զ��ģʽ����װ
�����ͻ���ʹ��
IDEA��PyCharm���ɲ���Hive
4��Hive�ij�����
Hive��������ʲô
01_���ݲֿ� ���λ����Դ����
(1)���ݲֿ�,���ļ�����֡�Ӣ�Ľ���Data WareHouse,���DW��
(2)���ݲֿ�����������ļ��ɻ�����ƽ̨,�����Ľ������ҵ�ṩ����֧��;

(3)���ݲֿⱾ������������;
�������������������ҵ��������Դ��
��ҵ�г���������Դ:
RDBMS��ϵ�����ݿ�--->ҵ������
log file----->��־�ļ�����
��������
��������
(4)���ݲֿⱾ��Ҳ����������;
������Ľ�����ⲿ��������Ӧ��(Data application)��ʹ�á�
Data visualization(DV)���ݿ��ӻ�
Data Report ���ݱ���
Data Mining(DM) �����ھ�
Ad-Hoc ��ϯ��ѯ
��ϯ��ѯ(Ad Hoc)���û������Լ�������,����ѡ���ѯ����,ϵͳ�ܹ������û���ѡ��������Ӧ��ͳ�Ʊ�������ϯ��ѯ����ͨӦ�ò�ѯ���IJ�ͬ����ͨ��Ӧ�ò�ѯ�Ƕ��ƿ�����,����ϯ��ѯ�����û��Զ����ѯ�����ġ�
(5)��ҵ��һ���������ݿ�,Ȼ�������ݲֿ�,����û�����ݲֿ�,���Dz���û�����ݿ⡣
(6)���ݲֿⲻ�Ǵ��͵����ݿ�,ֻ��һ�����ݷ�����ƽ̨��
02_���ݲֿ� �Ĵ��������
(1)����������(Subject-Oriented)
����(subject)��һ������ĸ��� �����ۺ��塣һ��������������Զ�Ӧ�������Դ��
�������п�չ����,����ȷ������������,Ȼ���������Ѱ�ҡ��ɼ���������ص����ݡ�
(2)������(Integrated)
���ֲ����������ݵ�ƽ̨ �����������ڸ�����ͬ������Դ
������ȷ������֮�� ����Ҫ�Ѻ�������ص����ݴӸ�������Դ���ɹ�����
��Ϊͬһ����������ݿ������Բ�ͬ������Դ ����֮�������Ų���(�칹����):�ֶ�ͬ����ͬ�⡢��λ��ͳһ�����벻ͳһ;
����ڼ��ɵĹ�������Ҫ����ETL(Extract��ȡ Transformת�� load����)
(3)���ɸ�����(Non-Volatile)
������������ݼ���û���IJ���,���Ƿ����IJ�����
�����Ƿ������ݹ��ɵ�ƽ̨ ���Ǵ������ݹ��ɵ�ƽ̨��
ע��:��ָ������֮��Ĺ��ɲ����ġ�
���·�����Щʱ��Ҳ����Ҫ�ĵ� ����У�������ݻ����仯��
#������ѧ�IJ������������� ���������ݶ�����ʷ���� ��ȥ������ t+1 t+7
#���滹��Ӵ�ʵʱ���� kafka+flink
(4)ʱ����(Time-Variant)
������һ������ά������Ķ�����
վ��ʱ��ĽǶ�,���ֵ����ݳ����α仯���¡�һ��һ����(T+1) һ��һ����(T+7)
���������ĸ���ƫ������������,���»��бȽϻ��ʵʱ���֡�
03_���ݲֿ� OLTP��OLAP����
���ݿ�����ݲֿ�������ʵ��������OLTP ��OLAPϵͳ������
-
OLTP ����������(On-Line Transaction Processing)
Transaction ���� ��������֧������ OLTPϵͳע�ص������ݰ�ȫ����������ӦЧ�ʡ�ͨ��ָ�ľ���RDBMS��ϵ�����ݿ⡣ #�������� ֧������ #RDBMS: MySQL ORACLE #ע�� ����NoSQL���ݿ� û������֧��: Redis HBase -
OLAP ������������(On-Line Analytical Processing) ���ķ���:ŷ����
Analytical ���� �������֧�ַ��� ��Ҫָ�������ݲֿ⡢���ݼ���(С�����ݲֿ�):Apache Hive��Apache Impala -
ע��:��ijЩ������,˵ORACLEҲ��OLAPϵͳ,�������?
�����RDBMSֻ�������ݷ�������,����OLAPϵͳ�� -
���ݲֿⲻ�Ǵ��͵����ݿ�,Ҳû��Ҫȡ�����ݿ��Ŀ��,ֻ��һ�����ݷ�����ƽ̨��
04_���ݲֿ� ���ֲַ�ܹ�(ODS��DW��DA)
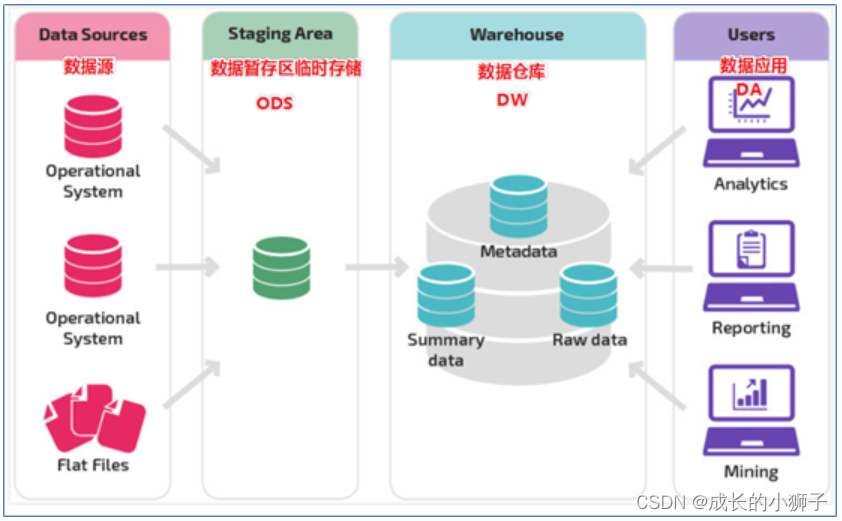
1)���ֱ�������������Ҳ����������,�������������������ص�,��ƽ̨���зֲ�
2)���������ĵ�3��ܹ�,��ҵʵ��Ӧ����,���Խ����Ҫ���Ӳ�ͬ�ֲ㡣
3)����3��ܹ�
(1)ODS ���������ݲ㡢Դ���ݲ㡢��ʱ�洢��
�����������ڸ�����ͬ������Դ ��ʱ�洢 ������Դ����� ֮���в��� һ�㲻ֱ�����ڷ���
(2)DW ���ݲֿ�
������������ODS��������ETL��ɸ���ģ�͵����� ���ݸɾ����� ͳһ
���ڸ���ģ�Ϳ�չ���ַ���
��ҵ�и���ҵ���Ӷ� ������DW�м��������Ӳ㡣 �洢�������м�����������������ODS�������ETL�ó� ��ҵ�п��Ը���������DW�м����ֲ㡣
(3)DA ����Ӧ�ò�
��������DW���ݵĸ���Ӧ�á�
4)�ֲ�ô�
(1)�������ݽṹ:ÿһ�����ݷֲ㶼������������,��ʹ�ñ���ʱ���ܸ�����ض�λ������
(2)����ѪԵ��:����˵,�������ո�ҵ����ֵ���һ����ֱ��ʹ��ҵ���,����������Դ�кܶ�,�����һ����Դ����������,����ϣ���ܹ�����ȷ�ض�λ������,���������Σ����Χ
(3)�����ظ�����:�淶���ݷֲ�,����һЩͨ�õ��м������,�ܹ����ټ�����ظ�����
(4)�Ѹ��������:��һ�����ӵ�����ֽ�ɶ�����������,ÿһ��ֻ������һ�IJ���,�Ƚϼ��������⡣���ұ���ά�����ݵ�ȷ��,�����ݳ�������֮��,���Բ��������е�����,ֻ��Ҫ��������IJ��迪ʼ��
(5)����ԭʼ���ݵ��쳣:����ҵ���Ӱ��,���ظ�һ��ҵ�����Ҫ���½�������
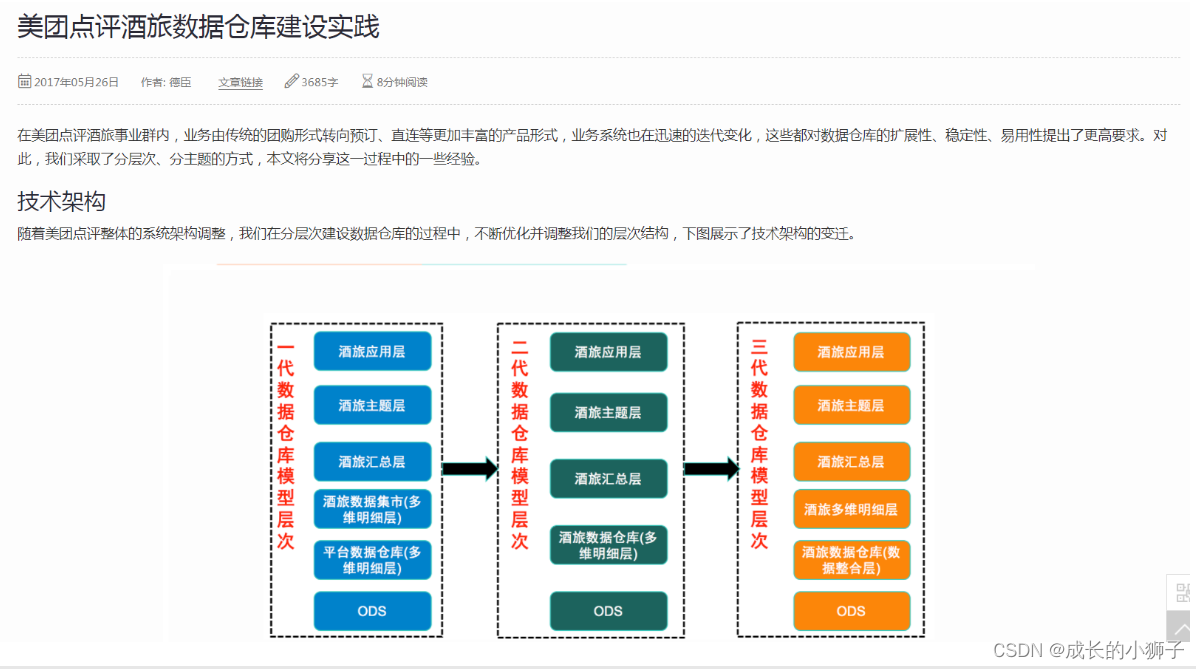
05_���ݲֿ� ����:���ֽ���ʵ��
https://tech.meituan.com/2017/05/26/hotel-dw-layer-topic.html
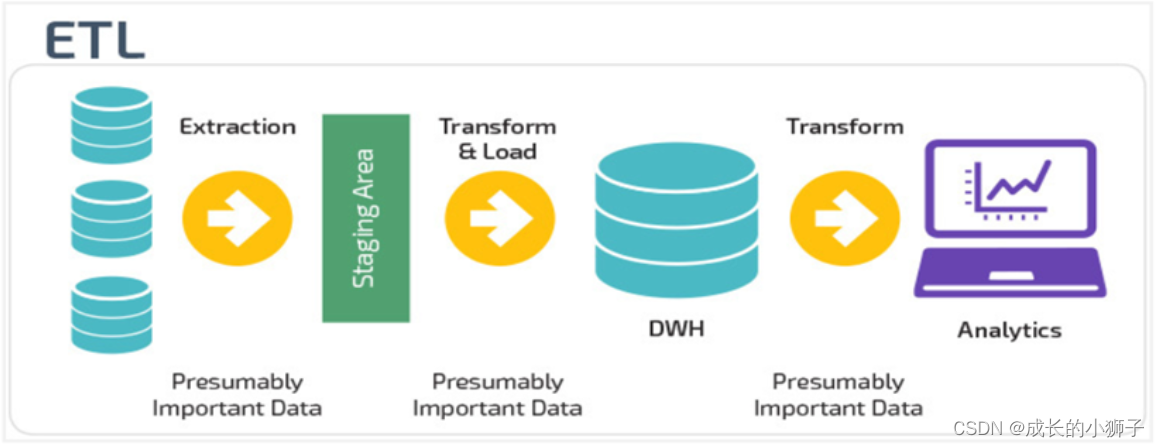
06_���ݲֿ� ETL��ELT����
���۹淶��ʵ�ʵ�Ӧ����,һ��Ҫ����ͨ����ͬ���������ֱ��档

07_Apache Hive ���������ܡ���Hadoop��ϵ
1)Hive��Facebook��Դ����,����������Apache����ּ��:��߷������ݵ��������ͷ������ݵĿ����ɱ���
2)Hive�ǻ��� Hadoop ��һ�����ݲֿ��,���ڷ������ݵġ�
Ϊʲô˵Hive�ǻ���Hadoop����?
#��Ϊһ�����ݲֿ�����,Ӧ��Ҫ�߱���Щ����?
�߱��洢���ݵ�����
�߱��������ݵ�����
Hive��Ϊ��������,��Ȼ�߱�������������?
#Hiveʹ��Hadoop HDFS��Ϊ���ݴ洢ϵͳ
#Hiveʹ��Hadoop MapReduce����������
���ڴ�˵Hive�ǻ���Hadoop������������
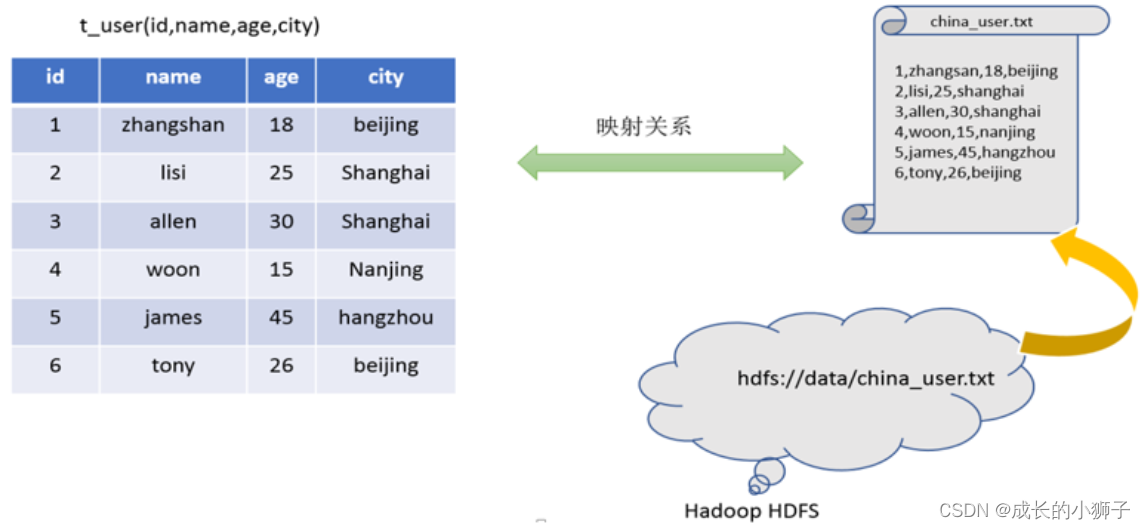
3)�ڴ˹�����,Hive����ʲô?����������������?
���Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ�� SQL ��ѯ���ܡ�
�ṹ������:����schemaԼ�������� ���ڳ���������
ӳ�� y=2X+1 ��x=1 y=3 ӳ���ʾ�ľ���һ�ֶ�Ӧ��ϵ��
ӳ���Ϊ��֮�� �ṩ����SQl��ѯ�������ܡ� SQL��������ʽ���,����Ա���ù�ϵ����,�������ݷ�����
08_Apache Hive ���ģ��ʵ��Hive��ʵ��
09_Apache Hive �ܹ����������MySQL�IJ���
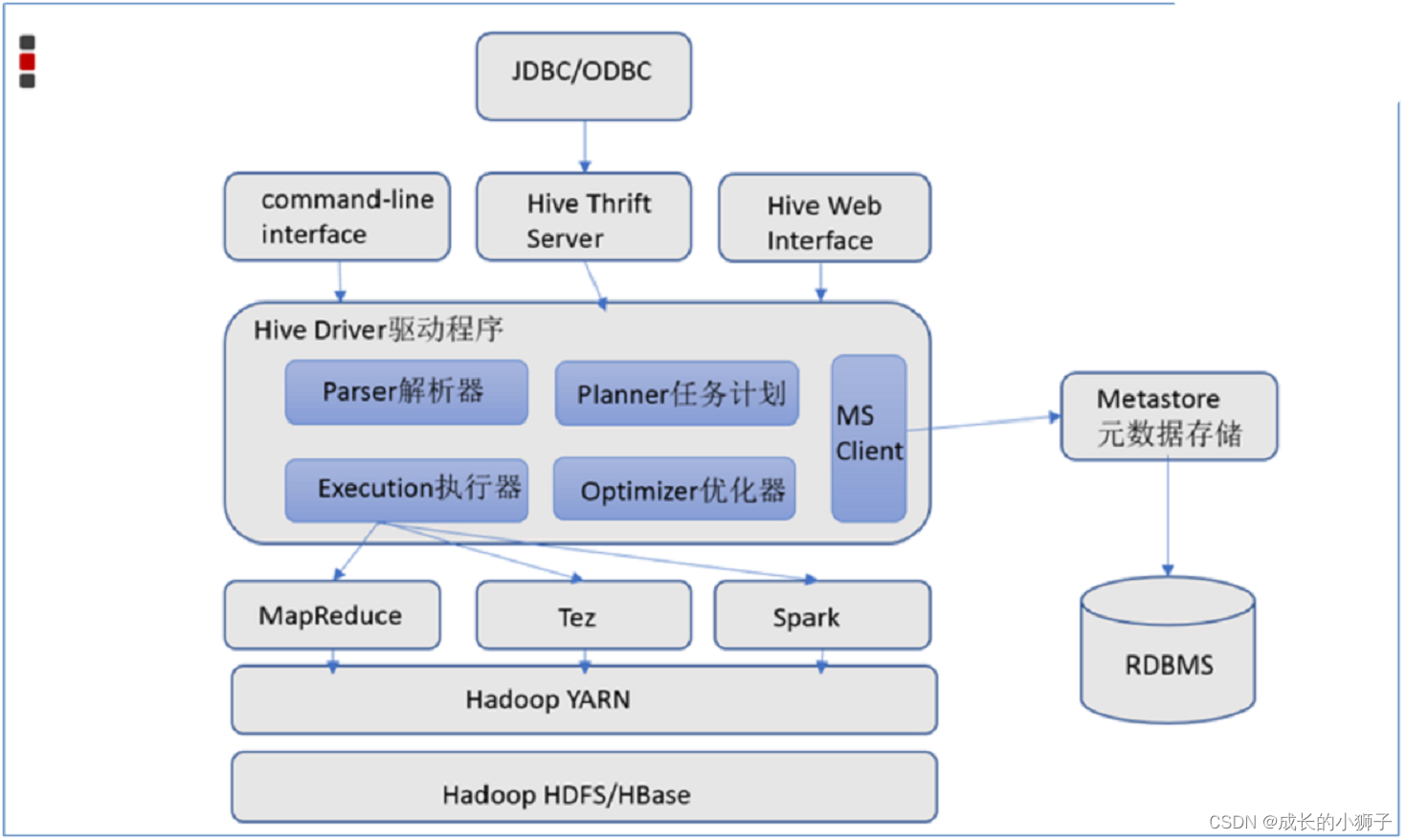
9.1 Hive�ļܹ����
(1)�ͻ����û��ӿ�
��ν�Ŀͻ���ָ���Ǹ��û�һ�ַ�ʽ��дHive SQL
Ŀǰ�����Ŀͻ���:CLI(�����нӿ� shell)��Web UI��JDBC|ODBC
(2)Hive Driver��������
hive���
��ɴӽ���HQL�������ΪMR����Ĺ��̡�
sql���� ���� У�� �Ż� �ƶ��ƻ�
(3)metadata
Ԫ���ݴ洢�� ���������ݡ�
����hive��˵,Ԫ����ָ���DZ����ļ�֮���ӳ���ϵ��
(4)Hadoop
HDFS �洢�ļ�
MapReduce ��������
YARN �������е���Դ����
������Q:Hive�Ƿֲ�ʽ��������?
Hive���Ƿֲ�ʽ������ֻ��Ҫ��һ̨�����ϲ���Hive����;
Hive�ķֲ�ʽ���������ǽ���Hadoop��ɵġ�HDFS�ֲ�ʽ�洢 MapReduce�ֲ�ʽ���㡣
9.2 Hive��Mysql������
(1)���������ʽģ�͡���������Ͽ� ,hive�����ݿ�(Mysql)������
(2)�ײ�Ӧ�ó�������ȫ��һ����
(3)hive����olapϵͳ ����������IJ��������ݷ���(select)
(4)���ݿ�����oltpϵͳ ����������� ����������ʱ�佻��(CRUD)
(5)Hive�����Ǵ������ݿ� Ҳ����Ϊ��Ҫȡ��MySQL���������ݿ�
10_Apache Hive metadata��metastore
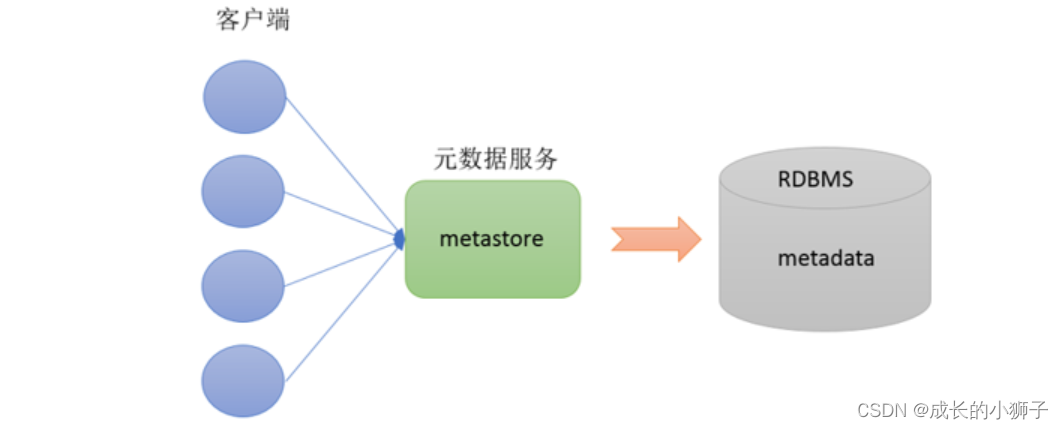
#Metadata Ԫ����
����hive��˵,Ԫ������Ҫָ���DZ����ļ�֮���ӳ���ϵ��
Ԫ����Ҳ������,�洢��������?Hive����֧�����ֵط��洢Ԫ���ݡ�
1���洢��Hive���õ�RDBSM��,Apache Derby(�ڴ漶����������ϵ�����ݿ�)
2���洢������������RDBMS��,����:MySQL�� ��ҵ�г��õķ�ʽ��
#metastore Ԫ���ݷ��ʷ���
ר�����ڲ�������metadata��һ�ַ���,���Ⱪ¶�����ַ��������ͬ�Ŀͻ���ʹ�÷���Hive��Ԫ���ݡ�
����ij�̶ֳ��ϱ�֤��metadata�İ�ȫ��
11_Apache Hive 3�ֲ���ģʽ(�Ƽ�����Զ��ģʽ)
11.1 �������,�ؼ�������������?
- metadataԪ�����Ǵ洢�������?����derby�������õ�Mysql
- metastore�����Ƿ���Ҫ��������,�����ֶ�����?
11.2 ������˵
11.2.1 ��Ƕģʽ
(1)Ԫ���ݴ洢�����õ�derby
(2)����Ҫ��������metastore Ҳ����Ҫ��������metastore����
(3)��װ����ѹ����ʹ�á�
(4)�ʺϲ������顣ʵ��������û���á��ʺϵ�������ʹ�á�
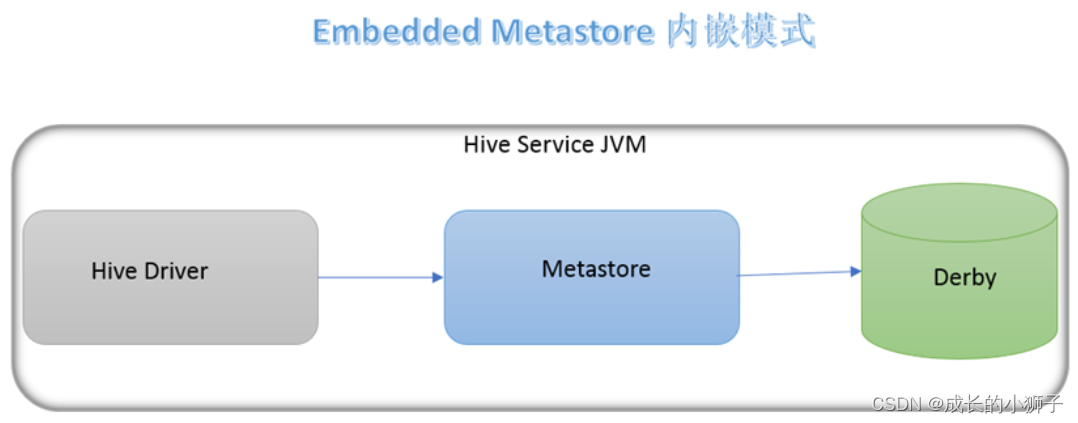
11.2.2 ����ģʽ
(1)Ԫ����ʹ�����õ�RDBMS,����ʹ��������MySQL��
(2)����Ҫ��������metastore Ҳ����Ҫ��������metastore����
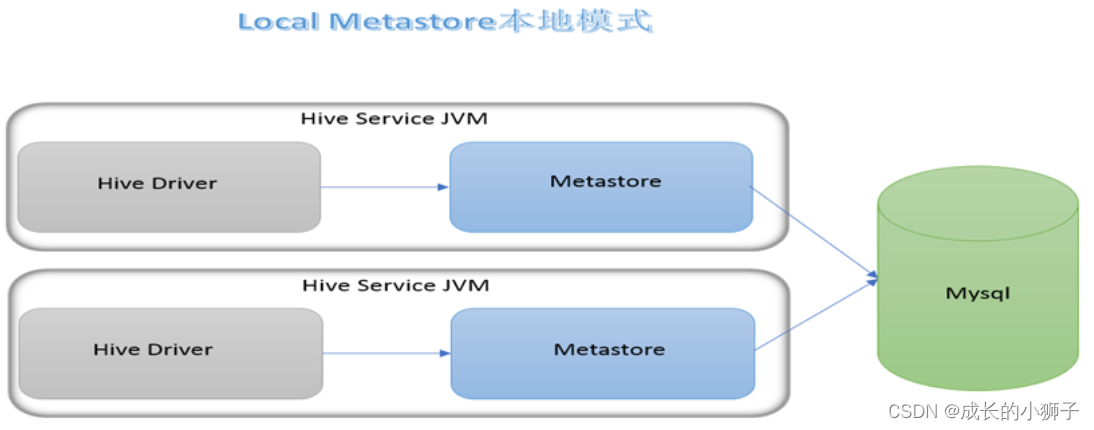
11.2.3 Զ��ģʽ
(1)Ԫ����ʹ�����õ�RDBMS,����ʹ��������MySQL��
(2)metastore�������� �����ֶ����� ȫ��Ψһ��
(3)�����Ļ������ͻ���ֻ��ͨ����һ��metastore�������Hive
(4)��ҵ����������ʹ�õ�ģʽ,֧�ֶ�ͻ���Զ�̲�����������Hive
Ҳ�����ǿγ���ʹ�õ�ģʽ��
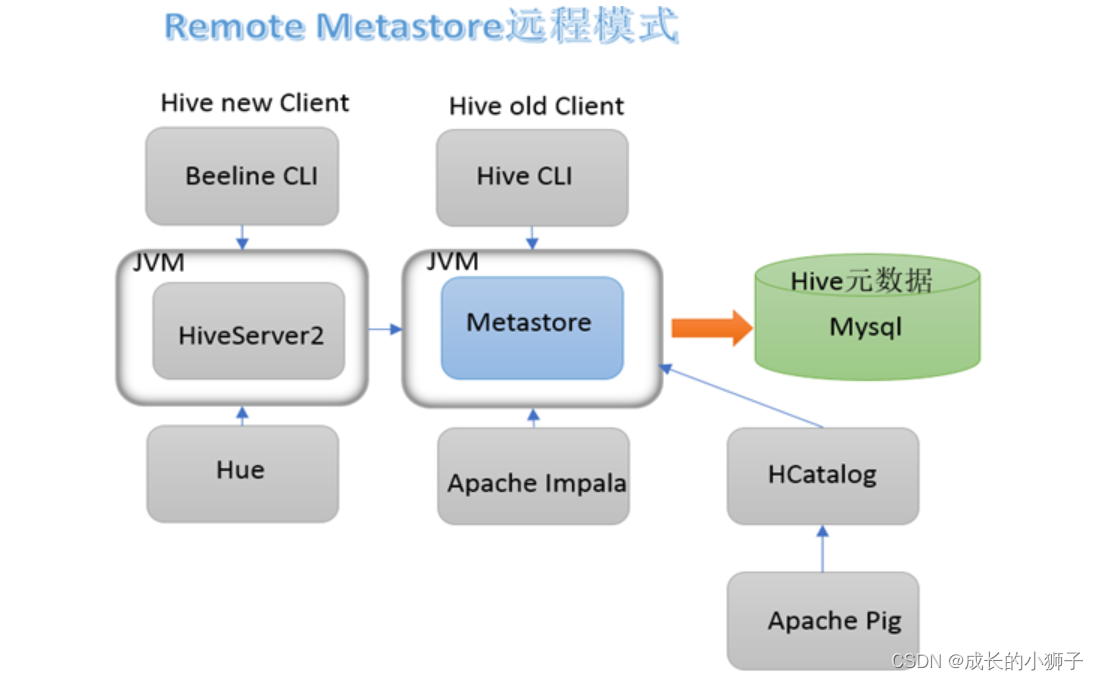
11.3 �Ա�
| metadata�洢���� | metastore������� | |
|---|---|---|
| ��Ƕģʽ | Derby | ����Ҫ�������� |
| ����ģʽ | MySQL | ����Ҫ�������� |
| Զ��ģʽ | MySQL | �������á��������� |
12_Apache Hive Զ��ģʽ��װ���� ������������Hadoop����
��װ�ο��ֲ�:
Python+������:hadoop���߽�\05�C���ݲֿ⡢Apache Hive\2������\hive 3.1.2\Hive3��װ.md
(1)��װHadoop
����hive֮ǰ,��Ҫ��֤Hadoop�����ҷ����������á���һ��,ʲô��������?
1���ȴ���ȫģʽ��������Hive
2����Hadoop�������û�����,ע��3̨��������Ҫ��,������Ч
vim etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
(2)��װMySQL
Linux�γ̽ΰ�װ��MySQL���ɡ�
��Ҫ���ǵľ���MySQL Hive�汾�ļ����� ��jdbc�����汾
��Centos7��������ΰ�װMySQL
13_Apache Hive Զ��ģʽ��װ���� �����ļ����ʼ��
(1)��װHive (ѡ��node1��װ)
#apache-hive-3.1.2-bin.tar.gz
�ϴ�����ѹ
tar zxvf apache-hive-3.1.2-bin.tar.gz
���������Hive��Hadoop֮��guava�汾����
cd /export/server/apache-hive-3.1.2-bin/
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
(2)hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
(3)hive-site.xml
vim hive-site.xml
<configuration>
<!-- �洢Ԫ����mysql������� -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- H2S���а�host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!-- Զ��ģʽ����metastore metastore��ַ -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<!-- �ر�Ԫ���ݴ洢��Ȩ -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
(4)�ϴ�Mysql jdbc������Hive��װ����LibĿ¼��
mysql-connector-java-5.1.32.jar
(5)�ֶ�ִ�������ʼ��Hive��Ԫ����
cd /export/server/apache-hive-3.1.2-bin/
bin/schematool -initSchema -dbType mysql -verbos
#��ʼ���ɹ�����mysql�д���74�ű�
(6)��hdfs����hive�洢Ŀ¼(��ѡ)
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
14_Apache Hive metastore������������һ���ͻ���
14.1 metastore����
(1)ǰ̨����
#ǰ̨����
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
#ǰ̨��������debug��־
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
#ǰ̨�����رշ�ʽ ctrl+c��������
(2)��̨��������
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
#��̨�������� ��������
ʹ��jps�鿴���� ʹ��kill -9 ɱ������
#nohup ����,��Ĭ�������(���ض���ʱ),�����һ������ nohup.out ���ļ�����ǰĿ¼��
14.2 Hive�Ŀͻ���
-
Hive�ĵ�һ���ͻ���
-
bin/hive
-
ֱ�ӷ���metastore����
-
����
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> </configuration> -
��:
��һ���ͻ�������shell�ű��ͻ��� �����Ѻð�ȫ������ڲ��� Hive�Ѿ����Ƽ�ʹ�� �ٷ�����ʹ�õڶ����ͻ���beeline
-
15_Apache Hive HS2����������beeline�ͻ���ʹ��
-
Hive�ĵڶ����ͻ���
-
bin/beeline
-
������metastore����,ֻ�ܹ�����Hiveserver2����
-
ʹ��
# ����node1�� hive��װ����beeline�ͻ��˻�����(node3) scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/ #1���ڰ�װhive�ķ������� ��������metastore���� ������hiveserver2���� nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore & nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #2�����������(��node3)��ʹ��beeline�ͻ��˷��� [root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 #jdbc����HS2���� Connecting to jdbc:hive2://node1:10000 Enter username for jdbc:hive2://node1:10000: root #�û��� Ҫ��߱�HDFS��дȨ�� Enter password for jdbc:hive2://node1:10000: #�������û��
-
16_Apache Hive ������ ��β���ӳ��ɹ��ļ�
(1)����Ŀ��:��hive����β��ܹ���һ�ݽṹ���������ļ�ӳ���Ϊһ�ű�,Ȼ��ʹ��SQL����?
--�ṹ���ļ�
1,allen,18
2,james,24
3,anna,45
--��hive���
create table t_1(id int,name string,age int);
(2)����1:ֻҪ��hive�д�����,��ô��HDFS�ͻ���һ���ļ�����֮��Ӧ��
(3)�ѵ��ѽṹ���ļ����������Ŀ¼��,����ӳ��ɹ���? ��һ��
```
/user/hive/warehouse/itcast.db/t_1
hadoop fs -put 1.txt /user/hive/warehouse/itcast.db/t_1
```
(4)����2:�ѵ�Ҫָ���ָ���? ��һ��
```sql
create table t_1(id int,name string,age int);
create table t_2(id int,name string,age int) row format delimited fields terminated by ','; --ָ���ָ���Ϊ����
```
(5)����3:������ʱ���ֶ�����Ҫ��Ҫ���ļ������ݱ���һ��? һ��Ҫ����һ��
(6)�����һ��,hive�᳢�Խ���ת��,���Dz���֤�ɹ�,������ɹ���ʾnull��
create table t_3(id int,name int,age string) row format delimited fields terminated by ',';
+---------+-----------+----------+--+
| t_3.id | t_3.name | t_3.age |
+---------+-----------+----------+--+
| 1 | NULL | 18 |
| 2 | NULL | 24 |
| 3 | NULL | 45 |
+---------+-----------+----------+--+
(7)������ӳ��ɹ�֮��,�����?
�Ϳ��Ի��ڱ�дHive SQL ��չ���ݷ���,���������̡���Ҳ����дMapReduce��
0: jdbc:hive2://node1:10000> select * from t_2 where age >18;
+---------+-----------+----------+--+
| t_2.id | t_2.name | t_2.age |
+---------+-----------+----------+--+
| 2 | james | 24 |
| 3 | anna | 45 |
+---------+-----------+----------+--+
2 rows selected (0.722 seconds)
0: jdbc:hive2://node1:10000>
0: jdbc:hive2://node1:10000> select count(*) from t_2 where age >18;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----+--+
| c0 |
+-----+--+
| 2 |
+-----+--+
1 row selected (67.76 seconds)