目录
一. 前言
1. 背景
在我们的项目当中,虽然使用的是Quartz这个java标准定时任务框架,但Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能。通常只部署一台机器,在某个时间点上会有好多个定时间任务几乎同时执行,例如:订单提醒,服务器压力非常吃紧。如果部署多台机器,同一个任务会被执行多次,比如订单提醒会给用户发送多个app消息。只部署一台机器,可用性又无法保证。Elastic-Job框架可以帮助解决定时任务在集群部署情况下的协调调度问题,保证任务不重复不遗漏的执行。
2. 什么是分布式作业调度系统?
我理解有3点:
- 第一点是分布式:分布式的作用是运行这个作业,它可以在两台或者多台机器上去执行,这些机器在分布式执行的作业是一个整体的作业。
- 第二点是并行调度:假如有两台机器执行业务,每台执行二分之一,有三台就执行三分之一,而不是之前一台执行百分之百,调度是需要一个注册中心来做集中管理。
(中心化跟去中心化) - 第三点是支持弹性扩容:还有弹性扩容,两台机器挂掉一台,剩下一台承担 100% 的作业,而不是 50%,如果作业堆积很多,快速加机器,把作业快速地给分散开,原来有两台、三台机器,加到十台,原来执行 50% 的作业,现在执行十分之一的作业,可以做到弹性的扩容和缩容
二. Elastic-Job-Lite
1. 简介
Elastic-Job是当当网在2015年开源的一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper。
2. 基本了解
-
分片概念 (平均分片策略 demo演示)
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
-
失效转移
如果作业在一次作业执行中途宕机,允许将该次未完成的作业在另一作业节点上补偿执行,运行中的作业服务器崩溃不会导致重新分片,只会在下次作业启动时分片。启用失效转移功能可以在本次作业执行过程中,监测其他作业服务器空闲,抓取未完成的孤儿分片项执行。(demo代码演示)
-
分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系。
-
个性化参数的使用场景
个性化参数即shardingItemParameter,可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库A是北京的数据;数据库B是上海的数据;数据库C是广州的数据。 如果仅按照分片项配置,开发者需要了解0表示北京;1表示上海;2表示广州。 合理使用个性化参数可以让代码更可读,如果配置为0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
-
分布式调度
Elastic-Job-Lite并无作业调度中心点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。
注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
-
作业高可用
Elastic-Job-Lite提供最安全的方式执行作业。将分片总数设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。
一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业执行时奔溃,备机立即启动替补执行。
-
最大限度利用资源
Elastic-Job-Lite也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
3.架构图
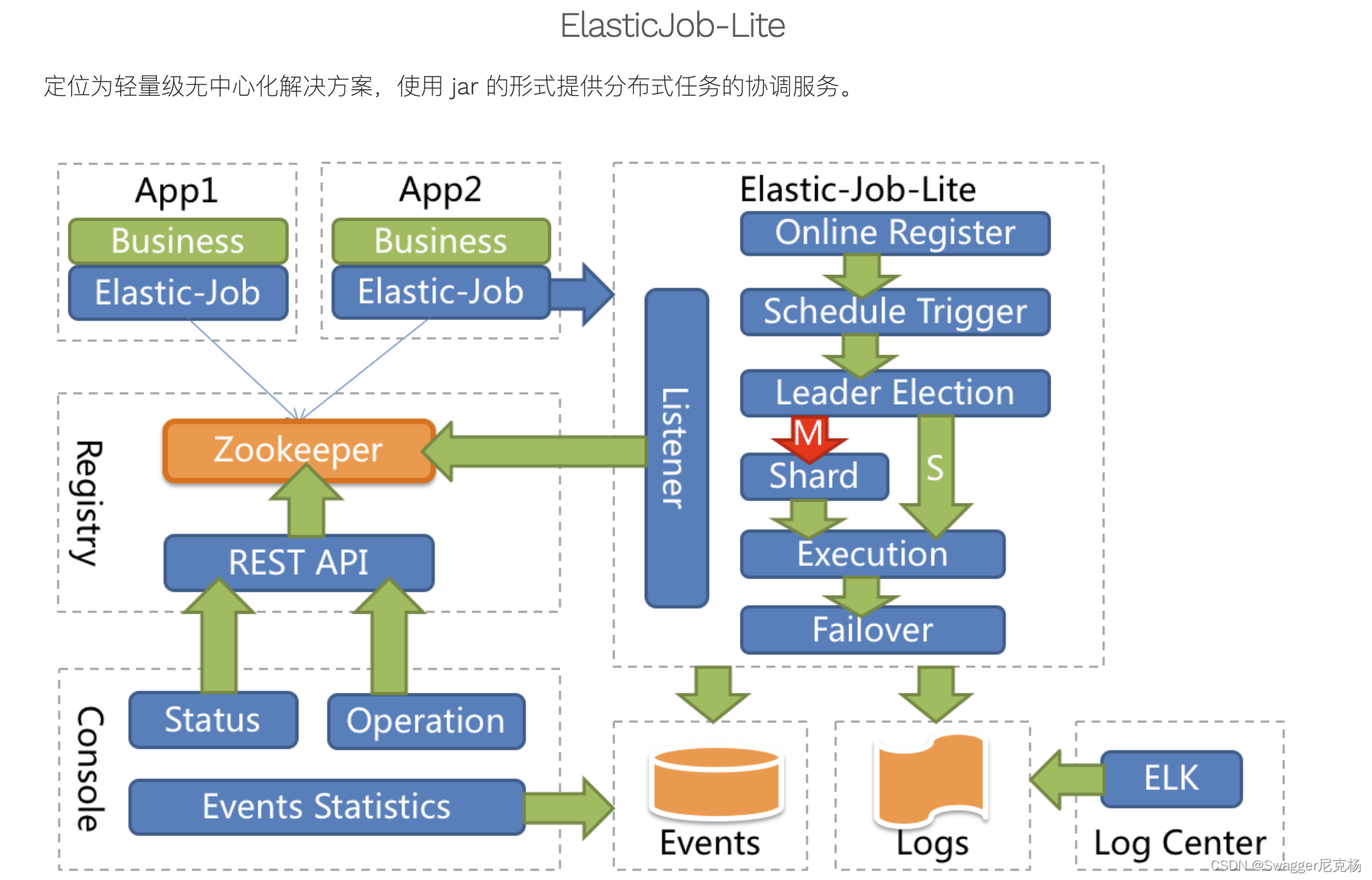
四. 快速入门
(1) 运维平台
- 解压缩elastic-job-lite-console-${version}.tar.gz并执行bin\start.sh。打开浏览器访问http://localhost:8899/即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端口号。
- 提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限。默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf\auth.properties修改管理员及访客用户名及密码。
(2) 3种作业类型
- Simple类型作业: 意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
public class MyElasticJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
// do something by sharding item 0
break;
case 1:
// do something by sharding item 1
break;
case 2:
// do something by sharding item 2
break;
// case n: ...
}
}
}
- Dataflow类型作业: Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。 (demo演示)
public class MyElasticJob implements DataflowJob<Foo> {
@Override
public List<Foo> fetchData(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
List<Foo> data = // get data from database by sharding item 0
return data;
case 1:
List<Foo> data = // get data from database by sharding item 1
return data;
case 2:
List<Foo> data = // get data from database by sharding item 2
return data;
// case n: ...
}
}
@Override
public void processData(ShardingContext shardingContext, List<Foo> data) {
// process data
// ...
}
}
- Script类型作业:Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。
(3) 作业分片策略(执行作业时分片)
- AverageAllocationJobShardingStrategy(平均分配算法的分片策略)
- OdevitySortByNameJobShardingStrategy(根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。)
- RotateServerByNameJobShardingStrategy(根据作业名的哈希值对服务器列表进行轮转的分片策略。)。(demo演示)
/**
* 基于平均分配算法的分片策略.
*
* <p>
* 如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
* 如:
* 1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
* 2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
* 3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
* </p>
*
*/
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {
// 先循环8/3
private Map<JobInstance, List<Integer>> shardingAliquot(final List<JobInstance> shardingUnits, final int shardingTotalCount) {
Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingTotalCount, 1);
int itemCountPerSharding = shardingTotalCount / shardingUnits.size();
int count = 0;
for (JobInstance each : shardingUnits) {
List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1);
for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) {
shardingItems.add(i);
}
result.put(each, shardingItems);
count++;
}
return result;
}
// 先循环8%3
private void addAliquant(final List<JobInstance> shardingUnits, final int shardingTotalCount, final Map<JobInstance, List<Integer>> shardingResults) {
int aliquant = shardingTotalCount % shardingUnits.size();
int count = 0;
for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) {
if (count < aliquant) {
entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count);
}
count++;
}
}
}
(4) 弹性扩容+失效转移 (demo演示)
(5) 作业监听器
- 可通过配置多个任务监听器,在任务执行前和执行后执行监听的方法。
@Component
public class MyElasticJobListener implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
// do something ...
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
// do something ...
}
}
<job:simple id="${simple.id}"
class="${simple.class}"
registry-center-ref="regCenter"
sharding-total-count="${simple.shardingTotalCount}"
cron="${simple.cron}"
sharding-item-parameters="${simple.shardingItemParameters}"
monitor-execution="${simple.monitorExecution}"
failover="${simple.failover}"
description="${simple.description}"
disabled="${simple.disabled}"
overwrite="${simple.overwrite}">
<job:listener class="com.bloom.bloomjob.common.MyElasticJobListener" />
</job:simple>
(6) 定制化处理
- 若job运行异常,可个性化异常处理器,进行异常干预
@Slf4j
public final class DefaultJobExceptionHandler implements JobExceptionHandler {
@Override
public void handleException(final String jobName, final Throwable cause) {
log.error(String.format("Job '%s' exception occur in job processing", jobName), cause);
}
}
(7) 机器挂掉重分片情况
分布式作业重复执行问题?
分布式调度协调
弹性扩容缩容
失效转移
错过执行作业重触发
作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
无中心化,意味着 Elastic-Job-Lite 不存在一个中心执行一些操作,例如:分配作业分片项。Elastic-Job-Lite 选举主节点,通过主节点进行作业分片项分配。目前,必须在主节点执行的操作有:分配作业分片项,调解分布式作业不一致状态。
五.局部分解
(1) 作业配置
-
关系图
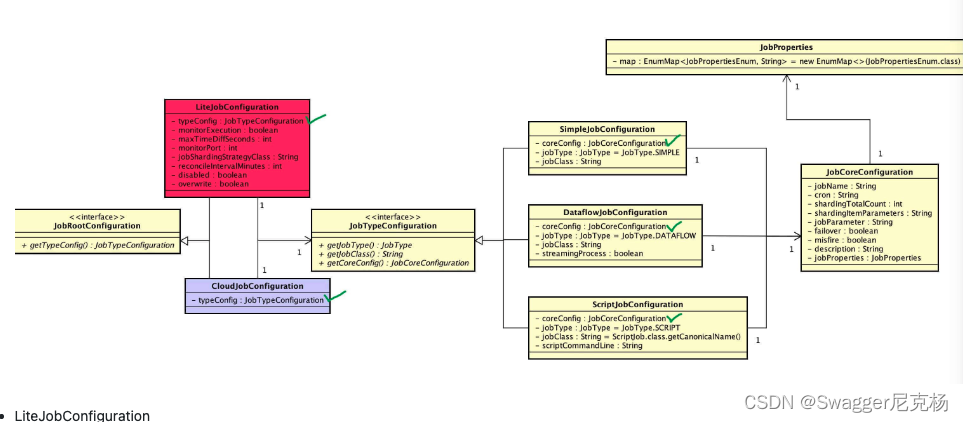
-
LiteJobConfiguration
public final class LiteJobConfiguration implements JobRootConfiguration {
private final JobTypeConfiguration typeConfig; //作业类型配置
private final String jobShardingStrategyClass; //作业分片策略实现类全路径
private final boolean monitorExecution; // 监控作业运行时状态。默认为 false
private final int monitorPort; // 作业监控端口
private final int maxTimeDiffSeconds; // 作业监控端口// 设置最大容忍的本机与注册中心的时间误差秒数。默认为 -1,不检查时间误差。选填。
private final int reconcileIntervalMinutes; // 修复作业服务器不一致状态服务调度间隔时间,配置为小于1的任意值表示不执行修复。默认为 10
private final boolean disabled; //作业是否禁用执行
private final boolean overwrite; // 本地配置覆盖注册中心作业配置
}
- JobCoreConfiguration
public final class JobCoreConfiguration {
private final String jobName; //作业名称
private final String cron; //作业定时任务
private final int shardingTotalCount; // 作业分片总数
private final String shardingItemParameters; // 分片序列号和参数 例如0=a,1=b,2=c
private final String jobParameter; //作业自定义参数
private final boolean failover; // 是否开启作业执行时效转移
private final boolean misfire; // 是否开启错误作业重新执行
private final String description; // 作业描述
private final JobProperties jobProperties; // 作业属性配置
}
- JobProperties
public final class JobProperties {
private EnumMap<JobPropertiesEnum, String> map = new EnumMap<>(JobPropertiesEnum.class);
public enum JobPropertiesEnum {
/**
* 作业异常处理器.
*/
JOB_EXCEPTION_HANDLER("job_exception_handler", JobExceptionHandler.class, DefaultJobExceptionHandler.class.getCanonicalName()),
/**
* 线程池服务处理器.
*/
EXECUTOR_SERVICE_HANDLER("executor_service_handler", ExecutorServiceHandler.class, DefaultExecutorServiceHandler.class.getCanonicalName());
private final String key;
private final Class<?> classType;
private final String defaultValue;
}
}
(2) 作业初始化
-
关系图
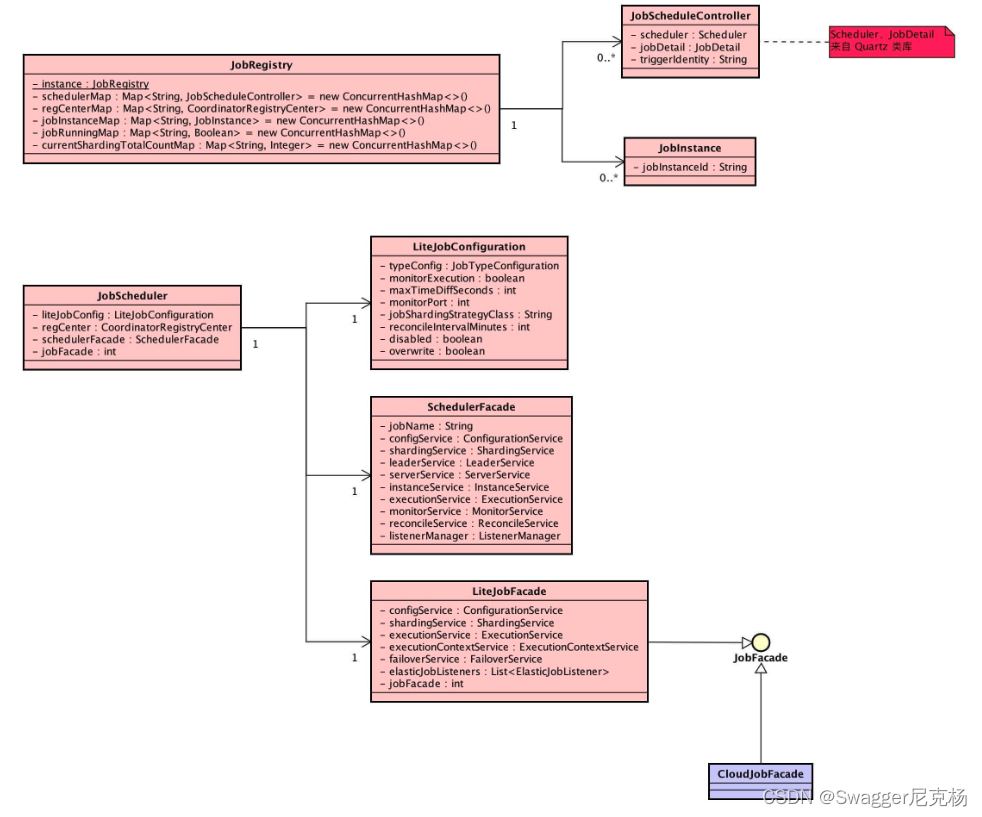
-
JobRegistry (作业注册表) 单例
public final class JobRegistry {
/**
* 单例
*/
private static volatile JobRegistry instance;
/**
* 作业调度控制器集合
* key:作业名称
*/
private Map<String, JobScheduleController> schedulerMap = new ConcurrentHashMap<>();
/**
* 注册中心集合
* key:作业名称
*/
private Map<String, CoordinatorRegistryCenter> regCenterMap = new ConcurrentHashMap<>();
/**
* 作业运行实例集合
* key:作业名称
*/
private Map<String, JobInstance> jobInstanceMap = new ConcurrentHashMap<>();
/**
* 运行中作业集合
* key:作业名字
*/
private Map<String, Boolean> jobRunningMap = new ConcurrentHashMap<>();
/**
* 作业总分片数量集合
* key:作业名字
*/
private Map<String, Integer> currentShardingTotalCountMap = new ConcurrentHashMap<>();
/**
* 获取作业注册表实例.(双重检验锁模式)
*
* @return 作业注册表实例
*/
public static JobRegistry getInstance() {
if (null == instance) {
synchronized (JobRegistry.class) {
if (null == instance) {
instance = new JobRegistry();
}
}
}
return instance;
}
// .... 省略方法
}
- JobSchedule (作业调度器)
public class JobScheduler {
/**
* Lite作业配置
*/
private final LiteJobConfiguration liteJobConfig;
/**
* 注册中心
*/
private final CoordinatorRegistryCenter regCenter;
/**
* 调度器门面对象
*/
@Getter
private final SchedulerFacade schedulerFacade;
/**
* 作业门面对象
*/
private final JobFacade jobFacade;
public JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration liteJobConfig, final ElasticJobListener... elasticJobListeners) {
this(regCenter, liteJobConfig, new JobEventBus(), elasticJobListeners);
}
public JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration liteJobConfig, final JobEventConfiguration jobEventConfig,
final ElasticJobListener... elasticJobListeners) {
this(regCenter, liteJobConfig, new JobEventBus(jobEventConfig), elasticJobListeners);
}
/**
* 创建作业调度器
*/
private JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration liteJobConfig, final JobEventBus jobEventBus, final ElasticJobListener... elasticJobListeners) {
// 添加 作业运行实例
JobRegistry.getInstance().addJobInstance(liteJobConfig.getJobName(), new JobInstance());
// 设置 Lite作业配置
this.liteJobConfig = liteJobConfig;
this.regCenter = regCenter;
// 设置 作业监听器
List<ElasticJobListener> elasticJobListenerList = Arrays.asList(elasticJobListeners);
setGuaranteeServiceForElasticJobListeners(regCenter, elasticJobListenerList);
// 设置 调度器门面对象
schedulerFacade = new SchedulerFacade(regCenter, liteJobConfig.getJobName(), elasticJobListenerList);
// 设置 作业门面对象
jobFacade = new LiteJobFacade(regCenter, liteJobConfig.getJobName(), Arrays.asList(elasticJobListeners), jobEventBus);
}
}
/**
* 初始化作业.
*/
public void init() {
// 更新 作业配置
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
// 设置 当前作业分片总数
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfigFromRegCenter.getJobName(), liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getShardingTotalCount());
// 创建 作业调度控制器
JobScheduleController jobScheduleController = new JobScheduleController(
createScheduler(), createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()), liteJobConfigFromRegCenter.getJobName());
// 添加 作业调度控制器
JobRegistry.getInstance().registerJob(liteJobConfigFromRegCenter.getJobName(), jobScheduleController, regCenter);
// 注册 作业启动信息
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
// 调度作业
jobScheduleController.scheduleJob(liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getCron());
}
(3) 选举主节点
- 为什么要选举主节点
Elastic-Job-Lite 定位为轻量级无中心化解决方案,使用 jar 包的形式提供分布式任务的协调服务。
无中心化,意味着 Elastic-Job-Lite 不存在一个中心执行一些操作,例如:分配作业分片项。Elastic-Job-Lite 选举主节点,通过主节点进行作业分片项分配。目前,必须在主节点执行的操作有:分配作业分片项,调解分布式作业不一致状态。
另外,主节点的选举是以作业为维度。例如:有一个 Elastic-Job-Lite 集群有三个作业节点 A、B、C,存在两个作业 a、b,可能 a 作业的主节点是 C,b 作业的主节点是 A。
-
关系图
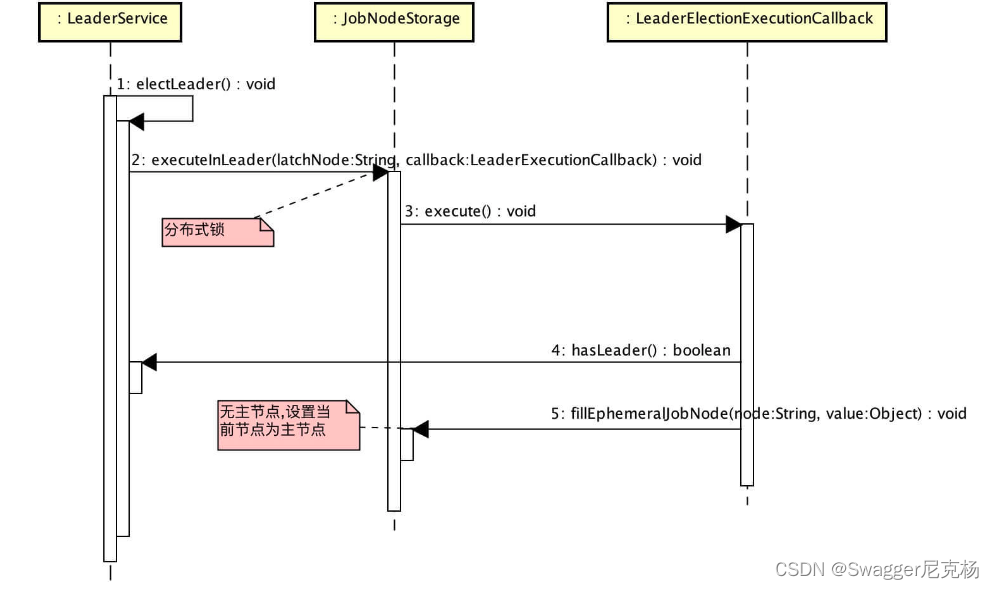
-
选举
// LeaderService.java
/**
* 选举主节点.
*/
public void electLeader() {
log.debug("Elect a new leader now.");
jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback());
log.debug("Leader election completed.");
}
// JobNodeStorage.java
public void executeInLeader(final String latchNode, final LeaderExecutionCallback callback) {
try (LeaderLatch latch = new LeaderLatch(getClient(), jobNodePath.getFullPath(latchNode))) {
latch.start();
latch.await();
callback.execute();
} catch (final Exception ex) {
handleException(ex);
}
}
// LeaderElectionExecutionCallback.java
class LeaderElectionExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
if (!hasLeader()) { // 当前无主节点
jobNodeStorage.fillEphemeralJobNode(LeaderNode.INSTANCE, JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
}
}
注:
使用 Curator LeaderLatch 分布式锁,保证同一时间有且仅有一个工作节点能够调用 LeaderElectionExecutionCallback#execute() 方法执行主节点设置
在 LeaderElectionExecutionCallback#execute() 为什么要调用 #hasLeader() 呢?LeaderLatch 只保证同一时间有且仅有一个工作节点,在获得分布式锁的工作节点结束逻辑后,第二个工作节点会开始逻辑,如果不判断当前是否有主节点,原来的主节点会被覆盖。
选举主节点时机 节点数据发生变化时
(4) 作业执行
-
关系图
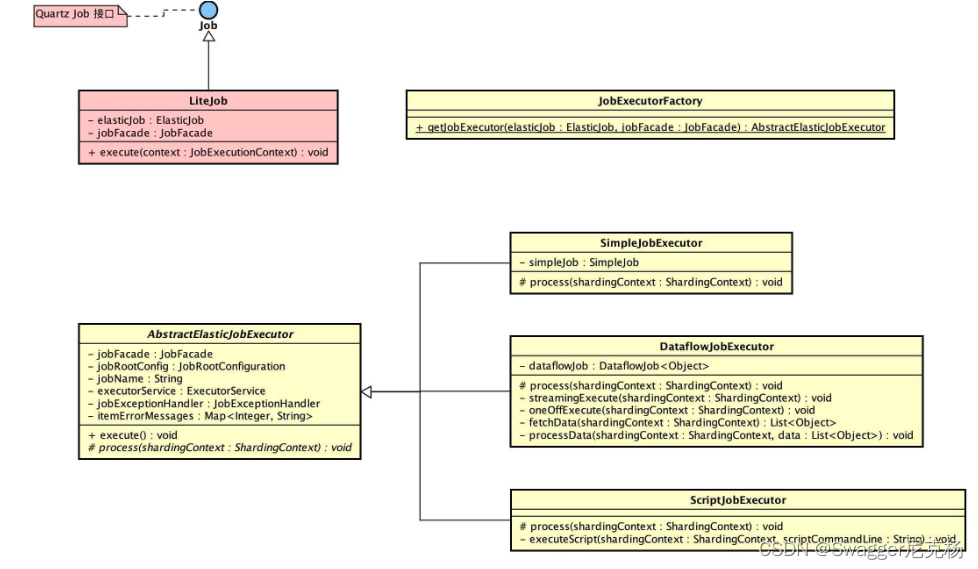
-
LiteJob
/**
* JobSchedule.java -> 生成Quartz的JobDetail对象
*/
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
=====================================================================
/**
* Job实体
*/
public final class LiteJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
}
// SimpleJobExecutor.java
public final class SimpleJobExecutor extends AbstractElasticJobExecutor {
/**
* 简单作业实现
*/
private final SimpleJob simpleJob;
public SimpleJobExecutor(final SimpleJob simpleJob, final JobFacade jobFacade) {
super(jobFacade);
this.simpleJob = simpleJob;
}
}
// DataflowJobExecutor.java
public final class DataflowJobExecutor extends AbstractElasticJobExecutor {
/**
* 数据流作业对象
*/
private final DataflowJob<Object> dataflowJob;
public DataflowJobExecutor(final DataflowJob<Object> dataflowJob, final JobFacade jobFacade) {
super(jobFacade);
this.dataflowJob = dataflowJob;
}
}
// ScriptJobExecutor.java
public final class ScriptJobExecutor extends AbstractElasticJobExecutor {
public ScriptJobExecutor(final JobFacade jobFacade) {
super(jobFacade);
}
}
- AbstractElasticJobExecutor
// AbstractElasticJobExecutor.java
public abstract class AbstractElasticJobExecutor {
/**
* 作业门面对象
*/
@Getter(AccessLevel.PROTECTED)
private final JobFacade jobFacade;
/**
* 作业配置
*/
@Getter(AccessLevel.PROTECTED)
private final JobRootConfiguration jobRootConfig;
/**
* 作业名称
*/
private final String jobName;
/**
* 作业执行线程池
*/
private final ExecutorService executorService;
/**
* 作业异常处理器
*/
private final JobExceptionHandler jobExceptionHandler;
/**
* 分片错误信息集合
* key:分片序号
*/
private final Map<Integer, String> itemErrorMessages;
protected AbstractElasticJobExecutor(final JobFacade jobFacade) {
this.jobFacade = jobFacade;
// 加载 作业配置
jobRootConfig = jobFacade.loadJobRootConfiguration(true);
jobName = jobRootConfig.getTypeConfig().getCoreConfig().getJobName();
// 获取 作业执行线程池
executorService = ExecutorServiceHandlerRegistry.getExecutorServiceHandler(jobName, (ExecutorServiceHandler) getHandler(JobProperties.JobPropertiesEnum.EXECUTOR_SERVICE_HANDLER));
// 获取 作业异常处理器
jobExceptionHandler = (JobExceptionHandler) getHandler(JobProperties.JobPropertiesEnum.JOB_EXCEPTION_HANDLER);
// 设置 分片错误信息集合
itemErrorMessages = new ConcurrentHashMap<>(jobRootConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(), 1);
}
// AbstractElasticJobExecutor.java
public final void execute() {
// 检查 作业执行环境
try {
jobFacade.checkJobExecutionEnvironment(); // maxTimeDiffSeconds:本机与注册中心的时间误差秒数不在允许范围则跑出异常
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
// 获取 当前作业服务器的分片上下文
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
// 发布作业状态追踪事件(State.TASK_STAGING)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_STAGING, String.format("Job '%s' execute begin.", jobName));
}
// 跳过 存在运行中的被错过作业
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
// 发布作业状态追踪事件(State.TASK_FINISHED)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format(
"Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName,
shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
// 执行 作业执行前的方法
try {
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
// 执行 普通触发的作业
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
// 执行 被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// 执行 作业失效转移
jobFacade.failoverIfNecessary();
// 执行 作业执行后的方法
try {
jobFacade.afterJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
}
}
- DataflowJobExecutor(数据流作业执行器)
public final class DataflowJobExecutor extends AbstractElasticJobExecutor {
/**
* 数据流作业对象
*/
private final DataflowJob<Object> dataflowJob;
@Override
protected void process(final ShardingContext shardingContext) {
DataflowJobConfiguration dataflowConfig = (DataflowJobConfiguration) getJobRootConfig().getTypeConfig();
if (dataflowConfig.isStreamingProcess()) { // 流式处理数据
streamingExecute(shardingContext);
} else {
oneOffExecute(shardingContext);
}
}
/**
* 流式处理
*
* @param shardingContext 分片上下文
*/
private void streamingExecute(final ShardingContext shardingContext) {
List<Object> data = fetchData(shardingContext);
while (null != data && !data.isEmpty()) {
processData(shardingContext, data);
if (!getJobFacade().isEligibleForJobRunning()) {
break;
}
data = fetchData(shardingContext);
}
}
/**
* 一次处理
*
* @param shardingContext 分片上下文
*/
private void oneOffExecute(final ShardingContext shardingContext) {
List<Object> data = fetchData(shardingContext);
if (null != data && !data.isEmpty()) {
processData(shardingContext, data);
}
}
}
(5) 执行被错过触发的作业
当作业执行过久,导致到达下次执行时间未进行下一次作业执行,Elastic-Job-Lite 会设置该作业分片项为被错过执行( misfired )。下一次作业执行时,会补充执行被错过执行的作业分片项。
- 标记作业被错过执行
// JobScheduler.java
private Scheduler createScheduler() {
Scheduler result;
// 监听被错过执行的作业分片项
result.getListenerManager().addTriggerListener(schedulerFacade.newJobTriggerListener());
return result;
}
private Properties getBaseQuartzProperties() {
// 置最大允许超过 1 毫秒,作业分片项即被视为错过执行。
result.put("org.quartz.jobStore.misfireThreshold", "1");
return result;
}
// JobScheduleController.class
private CronTrigger createTrigger(final String cron) {
return TriggerBuilder.newTrigger()
.withIdentity(triggerIdentity)
.withSchedule(CronScheduleBuilder.cronSchedule(cron)
//设置 Quartz 系统不会立刻再执行任务,而是等到距离目前时间最近的预计时间执行。重新执行被错过执行的作业交给 Elastic-Job-Lite 处理。
.withMisfireHandlingInstructionDoNothing())
.build();
}
- 跳过正在运行中的被错过执行的作业
// LiteJobFacade.java
@Override
public boolean misfireIfRunning(final Collection<Integer> shardingItems) {
return executionService.misfireIfHasRunningItems(shardingItems);
}
// ExecutionService.java
public boolean misfireIfHasRunningItems(final Collection<Integer> items) {
if (!hasRunningItems(items)) {
return false;
}
setMisfire(items);
return true;
}
public boolean hasRunningItems(final Collection<Integer> items) {
LiteJobConfiguration jobConfig = configService.load(true);
if (null == jobConfig || !jobConfig.isMonitorExecution()) {
return false;
}
for (int each : items) {
if (jobNodeStorage.isJobNodeExisted(ShardingNode.getRunningNode(each))) {
return true;
}
}
return false;
}
注:
当分配的作业分片项里存在任意一个分片正在运行中,设置分片项都被错过执行( misfired)并不执行这些作业分片。
如果不进行跳过,则可能导致同时运行某个作业分片。
该功能依赖作业配置监控作业运行时状态( LiteJobConfiguration.monitorExecution = true )时生效。
- 执行被错过执行的作业分片项(搭配3来讲)
// AbstractElasticJobExecutor.java
public final void execute() {
// .... 省略部分代码
// 执行 被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// .... 省略部分代码
}
// LiteJobFacade.java
@Override
public boolean isExecuteMisfired(final Collection<Integer> shardingItems) {
return isEligibleForJobRunning() // 合适继续运行
&& configService.load(true).getTypeConfig().getCoreConfig().isMisfire() // 作业配置开启作业被错过触发
&& !executionService.getMisfiredJobItems(shardingItems).isEmpty(); // 所执行的作业分片存在被错过( misfired )
}
@Override
public void clearMisfire(final Collection<Integer> shardingItems) {
executionService.clearMisfire(shardingItems);
}
(6) 作业失效转移
- 重新分片
当服务器节点从注册中心zk断开连接时,Elastic-job需要做的一件事情是需要在下次任务执行前进行重新分片,当zk节点数目发生变更时,会引发ListenServersChangedJobListener监听器调用,此监听器会调用shardingService的重新分片标志设置方法,这样再下次任务执行前会重新进行任务分片操作。
/**
* 当实例节点变更时会调用此监听器
*
*/
class ListenServersChangedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
//如果节点数目发生变更则设置重新分片标志,下次任务执行前会进行重新分片
if (!JobRegistry.getInstance().isShutdown(jobName) && (isInstanceChange(eventType, path) || isServerChange(path))) {
shardingService.setReshardingFlag();
}
}
private boolean isInstanceChange(final Type eventType, final String path) {
return instanceNode.isInstancePath(path) && Type.NODE_UPDATED != eventType;
}
private boolean isServerChange(final String path) {
return serverNode.isServerPath(path);
}
}
当节点任务失效时会调用JobCrashedJobListener监听器,此监听器会根据实例id获取所有的分片,然后调用FailoverService的setCrashedFailoverFlag方法,将每个分片id写到/jobName/leader/failover/items下
/**
* 任务失效时会调用这个监听器
*/
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType && instanceNode.isInstancePath(path)) {
String jobInstanceId = path.substring(instanceNode.getInstanceFullPath().length() + 1);
if (jobInstanceId.equals(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId())) {
return;
}
//会将所有的分片初始化到注册中心中
List<Integer> failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
for (int each : failoverItems) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
} else {
for (int each : shardingService.getShardingItems(jobInstanceId)) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}
在FailoverService方法中调用setCrashedFailoverFlag方法将需要任务转移的分片id进行实例化。
/**
* 设置失效的分片项标记.
*
* @param item 崩溃的作业项
*/
public void setCrashedFailoverFlag(final int item) {
if (!isFailoverAssigned(item)) {
jobNodeStorage.createJobNodeIfNeeded(FailoverNode.getItemsNode(item));
}
}
然后接下来调用FailoverService的failoverIfNessary方法,首先判断是否需要失败转移,如果可以需要则只需作业失败转移。
/**
* 如果需要失效转移, 则执行作业失效转移.
*/
public void failoverIfNecessary() {
if (needFailover()) {
jobNodeStorage.executeInLeader(FailoverNode.LATCH, new FailoverLeaderExecutionCallback());
}
}
五.demo
http://elasticjob.io/docs/elastic-job-lite/01-start/