NosqlИХЪі
ЮЊЪВУДЪЙгУNosql
1ЁЂЕЅЛњMysqlЪБДњ

90ФъДњ,вЛИіЭјеОЕФЗУЮЪСПвЛАуВЛЛсЬЋДѓ,ЕЅИіЪ§ОнПтЭъШЋЙЛгУЁЃЫцзХгУЛЇдіЖр,ЭјеОГіЯжвдЯТЮЪЬт
- Ъ§ОнСПдіМгЕНвЛЖЈГЬЖШ,ЕЅЛњЪ§ОнПтОЭЗХВЛЯТСЫ
- Ъ§ОнЕФЫїв§(B+ Tree),вЛИіЛњЦїФкДцвВДцЗХВЛЯТ
- ЗУЮЪСПБфДѓКѓ(ЖСаДЛьКЯ),вЛЬЈЗўЮёЦїГаЪмВЛзЁЁЃ
2ЁЂMemcached(ЛКДц) + Mysql + ДЙжБВ№Зж(ЖСаДЗжРы)
ЭјеО80%ЕФЧщПіЖМЪЧдкЖС,УПДЮЖМвЊШЅВщбЏЪ§ОнПтЕФЛАОЭЪЎЗжЕФТщЗГ!ЫљвдЫЕЮвУЧЯЃЭћМѕЧсЪ§ОнПтЕФбЙСІ,ЮвУЧПЩвдЪЙгУЛКДцРДБЃжЄаЇТЪ!

гХЛЏЙ§ГЬОРњСЫвдЯТМИИіЙ§ГЬ:
-
гХЛЏЪ§ОнПтЕФЪ§ОнНсЙЙКЭЫїв§(ФбЖШДѓ)
-
ЮФМўЛКДц,ЭЈЙ§IOСїЛёШЁБШУПДЮЖМЗУЮЪЪ§ОнПтаЇТЪТдИп,ЕЋЪЧСїСПБЌеЈЪНдіГЄЪБКђ,IOСївВГаЪмВЛСЫ
-
MemCache,ЕБЪБзюШШУХЕФММЪѕ,ЭЈЙ§дкЪ§ОнПтКЭЪ§ОнПтЗУЮЪВужЎМфМгЩЯвЛВуЛКДц,ЕквЛДЮЗУЮЪЪБВщбЏЪ§ОнПт,НЋНсЙћБЃДцЕНЛКДц,КѓајЕФВщбЏЯШМьВщЛКДц,ШєгажБНгФУШЅЪЙгУ,аЇТЪЯджјЬсЩ§ЁЃ
3ЁЂЗжПтЗжБэ + ЫЎЦНВ№Зж + MySQLМЏШК
БОжЪ:Ъ§ОнПтЕФЖС+аД

4ЁЂШчНёзюНќЕФФъДњ
ШчНёаХЯЂСПОЎХчЪНдіГЄ,ИїжжИїбљЕФЪ§ОнГіЯж(гУЛЇЖЈЮЛЪ§Он,ЭМЦЌЪ§ОнЕШ),ДѓЪ§ОнЕФБГОАЯТЙиЯЕаЭЪ§ОнПт(RDBMS)ЮоЗЈТњзуДѓСПЪ§ОнвЊЧѓЁЃNosqlЪ§ОнПтОЭФмЧсЫЩНтОіетаЉЮЪЬтЁЃ
ФПЧАвЛИіЛљБОЕФЛЅСЊЭјЯюФП

ЮЊЪВУДвЊгУNoSQL ?
гУЛЇЕФИіШЫаХЯЂ,ЩчНЛЭјТч,ЕиРэЮЛжУЁЃгУЛЇздМКВњЩњЕФЪ§Он,гУЛЇШежОЕШЕШБЌЗЂЪНдіГЄ!
етЪБКђЮвУЧОЭашвЊЪЙгУNoSQLЪ§ОнПтЕФ,NosqlПЩвдКмКУЕФДІРэвдЩЯЕФЧщПі!
ЪВУДЪЧNosql
**NoSQL = Not Only SQL(ВЛНіНіЪЧSQL)**Q
Not Only Structured Query Language
ЙиЯЕаЭЪ§ОнПт:Са+аа,ЭЌвЛИіБэЯТЪ§ОнЕФНсЙЙЪЧвЛбљЕФЁЃ
ЗЧЙиЯЕаЭЪ§ОнПт:Ъ§ОнДцДЂУЛгаЙЬЖЈЕФИёЪН,ВЂЧвПЩвдНјааКсЯђРЉеЙЁЃ
NoSQLЗКжИЗЧЙиЯЕаЭЪ§ОнПт,ЫцзХweb2.0ЛЅСЊЭјЕФЕЎЩњ,ДЋЭГЕФЙиЯЕаЭЪ§ОнПтКмФбЖдИЖweb2.0ЪБДњ!гШЦфЪЧГЌДѓЙцФЃЕФИпВЂЗЂЕФЩчЧј,БЉТЖГіРДКмЖрФбвдПЫЗўЕФЮЪЬт,NoSQLдкЕБНёДѓЪ§ОнЛЗОГЯТЗЂеЙЕФЪЎЗжбИЫй,RedisЪЧЗЂеЙзюПьЕФЁЃ
NosqlЬиЕу
- ЗНБуРЉеЙ(Ъ§ОнжЎМфУЛгаЙиЯЕ,КмКУРЉеЙ!)
- ДѓЪ§ОнСПИпадФм(RedisвЛУыПЩвдаД8ЭђДЮ,ЖС11ЭђДЮ,NoSQLЕФЛКДцМЧТММЖ,ЪЧвЛжжЯИСЃЖШЕФЛКДц,адФмЛсБШНЯИп!)
- Ъ§ОнРраЭЪЧЖрбљаЭЕФ!(ВЛашвЊЪТЯШЩшМЦЪ§ОнПт,ЫцШЁЫцгУ)
- ДЋЭГЕФ RDBMS КЭ NoSQL
ДЋЭГЕФ RDBMS(ЙиЯЕаЭЪ§ОнПт)
- НсЙЙЛЏзщжЏ
- SQL
- Ъ§ОнКЭЙиЯЕЖМДцдкЕЅЖРЕФБэжа row col
- Вйзї,Ъ§ОнЖЈвхгябд
- бЯИёЕФвЛжТад
- ЛљДЁЕФЪТЮё
- Ё
Nosql
- ВЛНіНіЪЧЪ§Он
- УЛгаЙЬЖЈЕФВщбЏгябд
- МќжЕЖдДцДЂ,СаДцДЂ,ЮФЕЕДцДЂ,ЭМаЮЪ§ОнПт(ЩчНЛЙиЯЕ)
- зюжевЛжТад
- CAPЖЈРэКЭBASE
- ИпадФм,ИпПЩгУ,ИпРЉеЙ
- Ё
СЫНт3Vгы3Ип
ДѓЪ§ОнЪБДњЕФ3V :жївЊЪЧУшЪіЮЪЬтЕФ
КЃСПVelume
ЖрбљVariety
ЪЕЪБVelocity
ДѓЪ§ОнЪБДњЕФ3Ип : жївЊЪЧЖдГЬађЕФвЊЧѓ
ИпВЂЗЂ
ИпПЩРЉ
ИпадФм
еце§дкЙЋЫОжаЕФЪЕМљ:NoSQL + RDBMS вЛЦ№ЪЙгУВХЪЧзюЧПЕФ
АЂРяАЭАЭбнНјЗжЮі
ЭЦМідФЖС:АЂРядЦЕФетШКЗшзгhttps://yq.aliyun.com/articles/653511


# ЩЬЦЗаХЯЂ
- вЛАуДцЗХдкЙиЯЕаЭЪ§ОнПт:Mysql,АЂРяАЭАЭЪЙгУЕФMysqlЖМЪЧОЙ§ФкВПИФЖЏЕФЁЃ
# ЩЬЦЗУшЪіЁЂЦРТл(ЮФзжОгЖр)
- ЮФЕЕаЭЪ§ОнПт:MongoDB
# ЭМЦЌ
- ЗжВМЪНЮФМўЯЕЭГ FastDFS
- ЬдБІ:TFS
- Google: GFS
- Hadoop: HDFS
- АЂРядЦ: oss
# ЩЬЦЗЙиМќзж гУгкЫбЫї
- ЫбЫїв§Чц:solr,elasticsearch
- АЂРя:Isearch ЖрТЁ
# ЩЬЦЗШШУХЕФВЈЖЮаХЯЂ
- ФкДцЪ§ОнПт:Redis,Memcache
# ЩЬЦЗНЛвз,ЭтВПжЇИЖНгПк
- ЕкШ§ЗНгІгУ
NosqlЕФЫФДѓЗжРр
KVМќжЕЖд
- аТРЫ:Redis
- УРЭХ:Redis + Tair
- АЂРяЁЂАйЖШ:Redis + Memcache
ЮФЕЕаЭЪ§ОнПт(bsonЪ§ОнИёЪН):
- MongoDB(еЦЮе)
- ЛљгкЗжВМЪНЮФМўДцДЂЕФЪ§ОнПтЁЃC++БраД,гУгкДІРэДѓСПЮФЕЕЁЃ
- MongoDBЪЧЙиЯЕаЭЪ§ОнПтКЭЗЧЙиЯЕаЭЪ§ОнПтЕФжаМфВњЦЗЁЃMongoDBЪЧЗЧЙиЯЕаЭЪ§ОнПтжаЙІФмзюЗсИЛЕФ,NoSQLжазюЯёЙиЯЕаЭЪ§ОнПтЕФЪ§ОнПтЁЃ
- ConthDB
СаДцДЂЪ§ОнПт
- HBase(ДѓЪ§ОнБибЇ)
- ЗжВМЪНЮФМўЯЕЭГ
ЭМЙиЯЕЪ§ОнПт
ДцДЂЕФЪЧЙиЯЕ,БШШч:ХѓгбШІЩчНЛЙиЯЕ,ЙуИцЭЦМі
- Neo4jЁЂInfoGrid
| ЗжРр | ExamplesОйР§ | ЕфаЭгІгУГЁОА | Ъ§ОнФЃаЭ | гХЕу | ШБЕу |
|---|---|---|---|---|---|
| МќжЕЖд(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | ФкШнЛКДц,жївЊгУгкДІРэДѓСПЪ§ОнЕФИпЗУЮЪИКди,вВгУгквЛаЉШежОЯЕЭГЕШЕШЁЃ | Key жИЯђ Value ЕФМќжЕЖд,ЭЈГЃгУhash tableРДЪЕЯж | ВщевЫйЖШПь | Ъ§ОнЮоНсЙЙЛЏ,ЭЈГЃжЛБЛЕБзїзжЗћДЎЛђепЖўНјжЦЪ§Он |
| СаДцДЂЪ§ОнПт | Cassandra, HBase, Riak | ЗжВМЪНЕФЮФМўЯЕЭГ | вдСаДиЪНДцДЂ,НЋЭЌвЛСаЪ§ОнДцдквЛЦ№ | ВщевЫйЖШПь,ПЩРЉеЙадЧП,ИќШнвзНјааЗжВМЪНРЉеЙ | ЙІФмЯрЖдОжЯо |
| ЮФЕЕаЭЪ§ОнПт | CouchDB, MongoDb | WebгІгУ(гыKey-ValueРрЫЦ,ValueЪЧНсЙЙЛЏЕФ,ВЛЭЌЕФЪЧЪ§ОнПтФмЙЛСЫНтValueЕФФкШн) | Key-ValueЖдгІЕФМќжЕЖд,ValueЮЊНсЙЙЛЏЪ§Он | Ъ§ОнНсЙЙвЊЧѓВЛбЯИё,БэНсЙЙПЩБф,ВЛашвЊЯёЙиЯЕаЭЪ§ОнПтвЛбљашвЊдЄЯШЖЈвхБэНсЙЙ | ВщбЏадФмВЛИп,ЖјЧвШБЗІЭГвЛЕФВщбЏгяЗЈЁЃ |
| ЭМаЮ(Graph)Ъ§ОнПт | Neo4J, InfoGrid, Infinite Graph | ЩчНЛЭјТч,ЭЦМіЯЕЭГЕШЁЃзЈзЂгкЙЙНЈЙиЯЕЭМЦз | ЭМНсЙЙ | РћгУЭМНсЙЙЯрЙиЫуЗЈЁЃБШШчзюЖЬТЗОЖбАжЗ,NЖШЙиЯЕВщевЕШ | КмЖрЪБКђашвЊЖдећИіЭМзіМЦЫуВХФмЕУГіашвЊЕФаХЯЂ,ЖјЧветжжНсЙЙВЛЬЋКУзіЗжВМЪНЕФМЏШК |
redisШыУХ
redisЕФАВзА
WindowsАВзАRedis
https://github.com/dmajkic/redis
- НтбЙАВзААќ

- ПЊЦєredis-server.exe
- ЦєЖЏredis-cli.exeВтЪд

LinuxАВзА
-
ЯТдиАВзААќ!
redis-6.2.6tar.gz -
НтбЙRedisЕФАВзААќ!ГЬађвЛАуЗХдк
/optФПТМЯТ
-
ЛљБОЛЗОГАВзА
yum install gcc-c++ # ШЛКѓНјШыredisФПТМЯТжДаа make # ШЛКѓжДаа make install

-
redisФЌШЯАВзАТЗОЖ
/usr/local/bin
-
НЋredisЕФХфжУЮФМўИДжЦЕН ГЬађАВзАФПТМ
/usr/local/bin/my_configЯТ![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-hxvGQ47d-1597890996509)(ПёЩёЫЕ Redis.assets/image-20200813114000868.png)]](https://img-blog.csdnimg.cn/20200820104157817.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
-
redisФЌШЯВЛЪЧКѓЬЈЦєЖЏЕФ,ашвЊаоИФХфжУЮФМў!
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-dDdKTUgd-1597890996510)(ПёЩёЫЕ Redis.assets/image-20200813114019063.png)]](https://img-blog.csdnimg.cn/20200820104213706.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
-
ЭЈЙ§жИЖЈЕФХфжУЮФМўЦєЖЏredisЗўЮё
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-jOypL57Z-1597890996511)(ПёЩёЫЕ Redis.assets/image-20200813114030597.png)]](https://img-blog.csdnimg.cn/20200820104228556.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
-
ЪЙгУredis-cliСЌНгжИЖЈЕФЖЫПкКХВтЪд,RedisЕФФЌШЯЖЫПк6379,
-pбЁЯюФмЙЛжИЖЈСЌНгЕФЖЫПкКХ
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-LnDaISQ4-1597890996512)(ПёЩёЫЕ Redis.assets/image-20200813114045299.png)]](https://img-blog.csdnimg.cn/20200820104243223.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
-
ВщПДredisНјГЬЪЧЗёПЊЦє
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-9PhN1jC1-1597890996513)(ПёЩёЫЕ Redis.assets/image-20200813114103769.png)]](https://img-blog.csdnimg.cn/20200820104300532.png#pic_center)
-
ЙиБеRedisЗўЮё
shutdown![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-Y54EuOYm-1597890996514)(ПёЩёЫЕ Redis.assets/image-20200813114116691.png)]](https://img-blog.csdnimg.cn/20200820104314297.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
-
дйДЮВщПДНјГЬЪЧЗёДцдк
-
КѓУцЮвУЧЛсЪЙгУЕЅЛњЖрRedisЦєЖЏМЏШКВтЪд
ВтЪдадФм
**redis-benchmark:**RedisЙйЗНЬсЙЉЕФадФмВтЪдЙЄОп,ВЮЪ§бЁЯюШчЯТ:
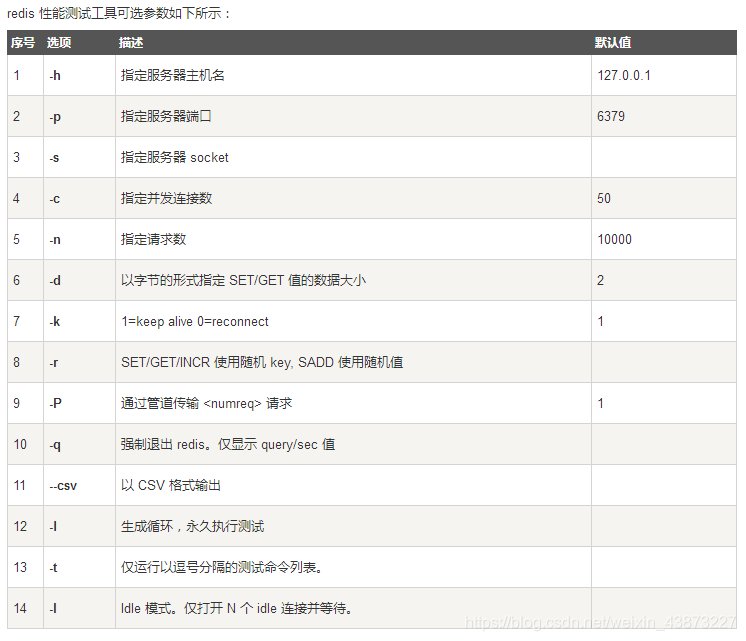
МђЕЅВтЪд:
# ВтЪд:100ИіВЂЗЂСЌНг 100000ЧыЧѓ
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-plMshjFg-1597890996515)(ПёЩёЫЕ Redis.assets/image-20200813114143365.png)]](https://img-blog.csdnimg.cn/20200820104343472.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
ЛљДЁжЊЪЖ
redisФЌШЯга16ИіЪ§ОнПт
![[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-v2S3n3Si-1597890996516)(ПёЩёЫЕ Redis.assets/image-20200813114158322.png)]](https://img-blog.csdnimg.cn/20200820104357466.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
ФЌШЯЪЙгУЕФЕк0ИіЪ§ОнПт
16ИіЪ§ОнПтЮЊ:DB 0~DB 15
ПЩвдЪЙгУselect nЧаЛЛЕНDB n,dbsizeПЩвдВщПДЕБЧАЪ§ОнПтЕФДѓаЁ,гыkeyЪ§СПЯрЙи,get databaseВщПДЕБЧАЪ§ОнПт
127.0.0.1:6379> config get databases # УќСюааВщПДЪ§ОнПтЪ§СПdatabases
1) "databases"
2) "16"
127.0.0.1:6379> select 8 # ЧаЛЛЪ§ОнПт DB 8
OK
127.0.0.1:6379[8]> dbsize # ВщПДЪ§ОнПтДѓаЁ
(integer) 0
# ВЛЭЌЪ§ОнПтжЎМф Ъ§ОнЪЧВЛФмЛЅЭЈЕФ,ВЂЧвdbsize ЪЧИљОнПтжаkeyЕФИіЪ§ЁЃ
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> SELECT 8
OK
127.0.0.1:6379[8]> get name # db8жаВЂВЛФмЛёШЁdb0жаЕФМќжЕЖдЁЃ
(nil)
127.0.0.1:6379[8]> DBSIZE
(integer) 0
127.0.0.1:6379[8]> SELECT 0
OK
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "name"
4) "key:__rand_int__"
5) "myset:__rand_int__"
127.0.0.1:6379> DBSIZE # sizeКЭkeyИіЪ§ЯрЙи
(integer) 5
keys * :ВщПДЕБЧАЪ§ОнПтжаЫљгаЕФkeyЁЃ
flushdb:ЧхПеЕБЧАЪ§ОнПтжаЕФМќжЕЖдЁЃ
flushall:ЧхПеЫљгаЪ§ОнПтЕФМќжЕЖдЁЃ
RedisЪЧЕЅЯпГЬЕФ,RedisЪЧЛљгкФкДцВйзїЕФЁЃ
ЫљвдRedisЕФадФмЦПОБВЛЪЧCPU,ЖјЪЧЛњЦїФкДцКЭЭјТчДјПэЁЃ
ФЧУДЮЊЪВУДRedisЕФЫйЖШШчДЫПьФи,адФметУДИпФи?QPSДяЕН10W+
RedisЮЊЪВУДЕЅЯпГЬЛЙетУДПь?
- ЮѓЧј1:ИпадФмЕФЗўЮёЦївЛЖЈЪЧЖрЯпГЬЕФ?
- ЮѓЧј2:ЖрЯпГЬ(CPUЩЯЯТЮФЛсЧаЛЛ!)вЛЖЈБШЕЅЯпГЬаЇТЪИп!
КЫаФ:RedisЪЧНЋЫљгаЕФЪ§ОнЗХдкФкДцжаЕФ,ЫљвдЫЕЪЙгУЕЅЯпГЬШЅВйзїаЇТЪОЭЪЧзюИпЕФ,ЖрЯпГЬ(CPUЩЯЯТЮФЛсЧаЛЛ:КФЪБЕФВйзї!),ЖдгкФкДцЯЕЭГРДЫЕ,ШчЙћУЛгаЩЯЯТЮФЧаЛЛаЇТЪОЭЪЧзюИпЕФ,ЖрДЮЖСаДЖМЪЧдквЛИіCPUЩЯЕФ,дкФкДцДцДЂЪ§ОнЧщПіЯТ,ЕЅЯпГЬОЭЪЧзюМбЕФЗНАИЁЃ
ЛљДЁЪ§ОнРраЭ
Redis ЪЧвЛИіПЊдД(BSDаэПЩ)ЕФ,ФкДцжаЕФЪ§ОнНсЙЙДцДЂЯЕЭГ,ЫќПЩвдгУзїЪ§ОнПтЁЂЛКДцКЭЯћЯЂжаМфМўMQЁЃ
ЫќжЇГжЖржжРраЭЕФЪ§ОнНсЙЙ,Шч зжЗћДЎ(strings), ЩЂСа(hashes), СаБэ(lists), МЏКЯ
(sets), гаађМЏКЯ(sorted sets) гыЗЖЮЇВщбЏ, bitmaps, hyperloglogs КЭ ЕиРэПеМф(geospatial) Ыїв§АыОЖВщбЏЁЃ
Redis ФкжУСЫ ИДжЦ(replication),LUAНХБО(Lua scripting), LRUЧ§ЖЏЪТМў(LRU eviction),ЪТЮё(transactions) КЭВЛЭЌМЖБ№ЕФ ДХХЬГжОУЛЏ(persistence), ВЂЭЈЙ§RedisЩкБј(Sentinel)КЭздЖЏ ЗжЧј(Cluster)ЬсЙЉИпПЩгУад(high availability)ЁЃ
Redis-keyЕФВйзї
ВщПДredisжаЫљгаЕФМќ
keys * # ВщПДЕБЧАЫљгаЕФkey
ЩшжУМќжЕ
set key value # ЩшжУМќЮЊвЛИіаТЕФжЕ
ХаЖЯkeyЪЧЗёДцдк
EXISTS key # ХаЖЯЕБЧАЕФkeyЪЧЗёДцдк,ШчЙћДцдкЗЕЛи 1
вЦГ§вЛИіkey
move key database # бЁдёвЛИіЪ§ОнПт вЦГ§ИУПтжаЕФkeyжЕ
ЩшжУвЛИіkeyЕФЙ§ЦкЪБМф,ЕЅЮЛЪЧУы
EXPIRE key time # ШУвЛИіkeyЕФЪЃгрЪБМфЮЊtime,ЪЃгрЪБМфЮЊ0ЪЧИУkeyБЛЩОГ§
ВщПДвЛИіkeyЕФЙ§ЦкЪБМф
ttl key # ШчЙћИУkeyУЛгаЩшжУЙ§ЦкЪБМф,ЗЕЛивЛИіИКЪ§
ВщПДkeyЕФОпЬхРраЭ
type key # ЗЕЛиkeyЕФОпЬхРраЭ
ОйР§ЫЕУї
127 .0.0.1:6379> keys * # ВщПДЫљгаЕФkey
(empty list or set)
127 .0.0.1:6379> set name lisen # set key
OK
127 .0.0.1:6379> keys *
1 ) "name"
127 .0.0.1:6379> set age 1
OK
127 .0.0.1:6379> keys *
1 ) "age"
2 ) "name"
127 .0.0.1:6379> EXISTS name # ХаЖЯЕБЧАЕФkeyЪЧЗёДцдк
(integer) 1
127 .0.0.1:6379> EXISTS name
(integer) 0
127 .0.0.1:6379> move name 1 # вЦГ§ЕБЧАЕФkey
(integer) 1
127 .0.0.1:6379> keys *
1 ) "age"
127 .0.0.1:6379> set name lisen
OK
127 .0.0.1:6379> keys *
1 ) "age"
2 ) "name"
127 .0.0.1:6379> clear
127 .0.0.1:6379> keys *
1 ) "age"
2 ) "name"
127 .0.0.1:6379> get name
"qinjiang"
127 .0.0.1:6379> EXPIRE name 10 #ЩшжУkeyЕФЙ§ЦкЪБМф,ЕЅЮЛЪЧУы
(integer) 1
127 .0.0.1:6379> ttl name # ВщПДЕБЧАkeyЕФЪЃгрЪБМф
(integer) 4
127 .0.0.1:6379> ttl name
(integer) 3
127 .0.0.1:6379> ttl name
(integer) 2
127 .0.0.1:6379> ttl name
(integer) 1
127 .0.0.1:6379> ttl name
(integer) -
127 .0.0.1:6379> get name # ОЭЛсздЖЏЩОГ§ keys *вВОЭУЛСЫ
(nil)
127 .0.0.1:6379> type name # ВщПДЕБЧАkeyЕФвЛИіРраЭ!string
127 .0.0.1:6379> type age # string
ЮхДѓЛљБОЪ§ОнРраЭ
String(зжЗћДЎ)
StringРраЭЕФЪЙгУГЁОА:valueГ§СЫзжЗћДЎЛЙПЩвдЪЧЪ§зж,НјааЪ§зжЕФВйзїгыдЫЫу!
- МЦЪ§Цї
- ЭГМЦЖрЕЅЮЛЕФЪ§СП
uid - ЗлЫПЪ§zasszz
ЛљБОЪЙгУ
зЗМгзжЗћДЎ
APPEND key str # НЋstrзЗМгЕНkeyМќЖдгІзжЗћДЎжЎКѓ
ЛёШЁзжЗћДЎГЄЖШ
STRLEN key # ЛёШЁзжЗћДЎГЄ
Ъ§зжВйзї
incr key # keyЖдгІЕФжЕ++
decr key # keyЖдгІЕФжЕ--
INCRBY key value # keyЖдгІЕФжЕ+=value
DECRBY key value # keyЖдгІЕФжЕ-=value
НиШЁзжЗћДЎ
GETRANGE key start end
ИУУќСюФмЙЛНиШЁзгДЎ,ЗЖЮЇЮЊ:[start,end],ШчЙћend=-1ДњБэНиШЁжСзюКѓвЛИізжЗћ
зжЗћДЎЬцЛЛ
SETRANGE key offset value
ДгoffsetЫїв§ЮЛжУПЊЪМЕФзжЗћДЎЬцЛЛЮЊvalue
ЩљУїгыИГжЕ
setex key time value # ЩљУївЛИіkeyЦфжЕЮЊvalue,ЩшжУtimeУыКѓЙ§Цк
setnx key value # ШчЙћkeyетИіМќВЛДцдк,дђДДНЈkey
setnxУќСюЭЈГЃдкЗжВМЪНжаЪЙгУ,зїЮЊРжЙлЫјЕФвЛжжЪЕЯжЗНЗЈ!
mset key1 value1 key2 value2 .... # mset ФмЙЛвЛДЮЩљУїЖрИіkey-value
msetnx key1 value1 key2 value2 ... # ЭЌбљЪЧЖрДЮЩљУї
# гыжЎЖдгІЕФ вЛДЮадЛёШЁЖрИіМќжЕ
mget key1 key2 key3 ...
msetnxЪЧвЛИідзгВйзї,ШчЙћЦфжагавЛИіkeyдкЪ§ОнПтжаДцдк,ФЧУДЦфгрЩљУїОљВЛЛсжДаа!
getset key new_value # ЯШЛёШЁkeyЕФvalue,дйНЋnew_valueаоИФЮЊkeyЕФvalue
ШчЙћдРДkeyВЛДцдк,getset ЗЕЛиnull
ОйР§ЫЕУї
127.0.0.1:6379> set key1 v1 # ЩшжУжЕ
OK
127.0.0.1:6379> get key1 # ЛёЕУжЕ
"v1"
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> EXISTS key1 #ХаЖЯЪЧЗёДцдк
(integer) 1
127.0.0.1:6379> APPEND key1 hello,world # зЗМгЕНФЉЮВ
(integer) 13
127.0.0.1:6379> get key1
"v1hello,world"
127.0.0.1:6379> STRLEN key1 # ЛёШЁИУзжЗћДЎЕФГЄЖШ
(integer) 13
127.0.0.1:6379>
#######################################################################
# Ъ§жЕМЦЫу
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> incr views # діМг1
(integer) 1
127.0.0.1:6379> decr views # МѕЩй1
(integer) 0
127.0.0.1:6379> incrby views 10 # діМг10
(integer) 10
127.0.0.1:6379> decrby views 10 # МѕЩй10
(integer) 0
#######################################################################
# НиШЁзжЗћ
127.0.0.1:6379> set key1 hello,world
OK
127.0.0.1:6379> get key1
"hello,world"
127.0.0.1:6379> getrange key1 0 1
"he"
127.0.0.1:6379> getrange key1 0 -1
"hello,world"
#######################################################################
# ЬцЛЛзжЗћ
127.0.0.1:6379> setrange key1 0 HELLO
(integer) 11
127.0.0.1:6379> get key1
"HELLO,world"
127.0.0.1:6379>
#######################################################################
# ЩљУїзжЗћДЎ
127.0.0.1:6379> setex name 100 cjx # ЩљУївЛИіkey 'name' ЦфжЕЮЊcjx,дк100sКѓНЋЙ§Цк
OK
127.0.0.1:6379> ttl name
(integer) 91
127.0.0.1:6379> keys *
1) "name"
2) "key1"
127.0.0.1:6379> setnx name cjx2 # ДЫЪБnameШдШЛДцдк,ЩљУїЪЇАм
(integer) 0
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> setnx name cjx2 # ДЫЪБnameЙ§Цк,ЩљУїГЩЙІ!
(integer) 1
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # ЭЌЪБЩшжУЖрИіжЕ
OK
################
127.0.0.1:6379> keys *
1) "name"
2) "key1"
3) "k3"
4) "k2"
5) "k1"
127.0.0.1:6379> mget k1 k2 k3 # ЭЌЪБЛёШЁЖрИіжЕ
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k3 v33 k4 v4 # ПЩвдПДЕНmsetnxЪЧвЛИідзгВйзї,вЊУДЖМГЩЙІвЊУДЖМВЛГЩЙІ
(integer) 0
127.0.0.1:6379> keys *
1) "name"
2) "key1"
3) "k3"
4) "k2"
5) "k1"
################
127.0.0.1:6379> getset db INNODB # ЯШЛёШЁжЕ,дкЩшжУжЕ
(nil)
127.0.0.1:6379> get db # ЛёШЁаТЕФжЕ
"INNODB"
List(СаБэ)
redisжа,ListПЩвдзїЮЊ:ЖбеЛЁЂЖгСаЁЂзшШћЖгСа!
ЫљгаЕФListУќСюЖМЪЧвд ЁЏ l 'ПЊЭЗЕФ
ВхШыдЊЫи
LPUSH key value # НЋvalueЭЦШыkeyЖдгІЕФlistЕФЭЗВП,РрЫЦгкpush_front
RPUSH key value # НЋvlaueжЕЭЦШыlistЕФЮВВП,РрЫЦгкpush_back
# НЋvalueВхШыЕНpreValueжЎЧАЛђжЎКѓ,жЛЛсдкЕквЛИіЦЅХфдЊЫиКѓУцВхШы
Linsert key before|after preValue value
ЛёШЁдЊЫи
LINDEX key index # ЛёШЁindexЯТБъЕФжЕ,ВЛДцдкМДЗЕЛиnil
LRANGE key start end # ЛёШЁжИЖЈЗЖЮЇЕФжЕ
LRANGE РрЫЦгкgetRangeУќСю,ЛёШЁЕН[start,end]ЕФдЊЫи,ШчЙћend==-1,дђЛёШЁжСЖгЮВЕФдЊЫиЁЃ
вЦГ§дЊЫи
# БпНчвЦГ§
LPOP key # вЦГ§keyЖдгІlistЕФЭЗВПдЊЫи
RPOP key # вЦГ§listЕФЮВВПдЊЫи
# ЩОГ§жИЖЈЕФvalue,ЩОГ§ИіЪ§ЮЊcount
lrem key count value
rpoplpush list1 list2 # вЦГ§list1гвВрдЊЫиЬэМгЕНlist2зѓВр
ЪЙгУLPOPЁЂRPOPУќСювЦГ§ЕФдЊЫиЛсБЛЗЕЛи!
lremжИСюЛсЩОГ§ count ИіvalueдЊЫи,ШчЙћcountЮЊ0дђЩОГ§listжаЫљгажЕЮЊvalueдЊЫиЁЃ
ЗЕЛиГЄЖШ
LLen key # ФмЙЛЗЕЛиlistЕФГЄЖШ
НиШЁдЊЫи
ltrim key start end
ltrimУќСюФмЙЛШУдСаБэНиШЁ[start,end]ЕФВПЗжВЂИГжЕИјдlist
ЬцЛЛдЊЫи
LSET key index value # НЋkeyЖдгІlistСаБэжИЖЈindexжЕЬцЛЛЮЊvalue
ашвЊзЂвт:ШчЙћСаБэВЛДцдкЛђСаБэindexЫїв§ЮЛжУЮЊПе,дђЛсБЈДэ!
ОйР§ЫЕУї
######################################################################
# ЛёШЁдЊЫигыВхШыдЊЫи
127.0.0.1:6379> LPUSH list1 one two three # дкЭЗВПЬэМг one two three дЊЫи
(integer) 3
127.0.0.1:6379> LRANGE list1 0 -1 # ВщПДЫљгадЊЫи
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> RPUSH list1 zero # дкЮВВПЬэМг zero дЊЫи
(integer) 4
127.0.0.1:6379> LRANGE list1 0 -1
1) "three"
2) "two"
3) "one"
4) "zero"
# Lindex
127.0.0.1:6379> LINDEX list1 1
"two"
# Linsert
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "three"
3) "fout"
127.0.0.1:6379> linsert list before "two" one # дкtwoжЎЧАВхШыone
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "one"
2) "two"
3) "three"
4) "fout"
#######################################################################
# вЦГ§дЊЫи
127.0.0.1:6379> LPOP list1
"three"
127.0.0.1:6379> LRANGE list1 0 -1
1) "two"
2) "one"
3) "zero"
127.0.0.1:6379> RPOP list1
"zero"
127.0.0.1:6379> LRANGE list1 0 -1
1) "two"
2) "one"
# ЦЅХфЩОГ§
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "twoo"
3) "twoo"
4) "twoo"
127.0.0.1:6379> lrem list 0 twoo # ЩОГ§ЫљгажЕЮЊ twoo ЕФЯю
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "two"
#######################################################################
# НиШЁдЊЫи
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "three"
3) "fout"
4) "five"
127.0.0.1:6379> ltrim list 0 2
OK
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "three"
3) "fout"
Set(МЏКЯ)
гыJavaвЛбљ,RedisжаЕФsetЮоађЁЂВЛжиИД
ЬэМгдЊЫи
sadd key value... # ЬэМгШЮвтИіvalueдЊЫи
ВщПДдЊЫи
smembers key # ВщПДжИЖЈSetЕФЫљгажЕ
sismember key value # ХаЖЯФГвЛИіжЕЪЧЗёдкsetжа
ВщПДдЊЫиИіЪ§
scard key # ВщПДsetжаЕФдЊЫиИіЪ§
вЦГ§дЊЫи
srem key value # вЦГ§setжаЕФvalueдЊЫи
ЫцЛњВйзї
srandmember key # ЫцЛњГщГівЛИідЊЫи
spop key # ЫцЛњЩОГ§вЛИідЊЫиВЂЗЕЛи
вЦЖЏдЊЫи
smove set1 set2 value # НЋset1жаЕФvalueвЦЖЏЕНset2
МЏКЯВйзї
# ВюМЏ
SDIFF key1 key2 # ЗЕЛиkey1гЕгаЕЋЪЧkey2УЛгаЕФдЊЫи
# ВЂМЏ
SINTER key1 key2
# НЛМЏ
SUNION key1 key2
МЏКЯВйзїдЪаэЖрМЏКЯдЫЫу,ШчЙћжЛгавЛИіМЏКЯзїЮЊВЮЪ§ФЧУДЦфБШНЯЖдЯѓОЭЪЧздМКЁЃ
ОйР§ЫЕУї
---------------SADD--SCARD--SMEMBERS--SISMEMBER--------------------
127.0.0.1:6379> SADD myset m1 m2 m3 m4 # ЯђmysetжадіМгГЩдБ m1~m4
(integer) 4
127.0.0.1:6379> SCARD myset # ЛёШЁМЏКЯЕФГЩдБЪ§ФП
(integer) 4
127.0.0.1:6379> smembers myset # ЛёШЁМЏКЯжаЫљгаГЩдБ
1) "m4"
2) "m3"
3) "m2"
4) "m1"
127.0.0.1:6379> SISMEMBER myset m5 # ВщбЏm5ЪЧЗёЪЧmysetЕФГЩдБ
(integer) 0 # ВЛЪЧ,ЗЕЛи0
127.0.0.1:6379> SISMEMBER myset m2
(integer) 1 # ЪЧ,ЗЕЛи1
127.0.0.1:6379> SISMEMBER myset m3
(integer) 1
---------------------SRANDMEMBER--SPOP----------------------------------
127.0.0.1:6379> SRANDMEMBER myset 3 # ЫцЛњЗЕЛи3ИіГЩдБ
1) "m2"
2) "m3"
3) "m4"
127.0.0.1:6379> SRANDMEMBER myset # ЫцЛњЗЕЛи1ИіГЩдБ
"m3"
127.0.0.1:6379> SPOP myset 2 # ЫцЛњвЦç€ЗЕЛи2ИіГЩдБ
1) "m1"
2) "m4"
# НЋsetЛЙдЕН{m1,m2,m3,m4}
---------------------SMOVE--SREM----------------------------------------
127.0.0.1:6379> SMOVE myset newset m3 # НЋmysetжаm3ГЩдБвЦЖЏЕНnewsetМЏКЯ
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "m4"
2) "m2"
3) "m1"
127.0.0.1:6379> SMEMBERS newset
1) "m3"
127.0.0.1:6379> SREM newset m3 # ДгnewsetжавЦГ§m3дЊЫи
(integer) 1
127.0.0.1:6379> SMEMBERS newset
(empty list or set)
-----------------------------SDIFF------------------------------------
# ЯТУцПЊЪМЪЧЖрМЏКЯВйзї,ЖрМЏКЯВйзїжаШєжЛгавЛИіВЮЪ§ФЌШЯКЭздЩэНјаадЫЫу
# setx=>{m1,m2,m4,m6}, sety=>{m2,m5,m6}, setz=>{m1,m3,m6}
127.0.0.1:6379> SDIFF setx sety setz # ЕШМлгкsetx-sety-setz
1) "m4" #етОЭЪЧПДsetxжагыЦфЫћМЏКЯжагаВЛвЛбљЕФСаГіРД жЛеыЖдsetxжаЕФСаГіРД
127.0.0.1:6379> SDIFF setx sety # setx - sety
1) "m4"
2) "m1"
127.0.0.1:6379> SDIFF sety setx # sety - setx
1) "m5"
-------------------------SINTER---------------------------------------
# ЙВЭЌЙизЂ(НЛМЏ)
127.0.0.1:6379> SINTER setx sety setz # Чѓ setxЁЂsetyЁЂsetxЕФНЛМЏ
1) "m6"
127.0.0.1:6379> SINTER setx sety # Чѓsetx setyЕФНЛМЏ
1) "m2"
2) "m6"
-------------------------SUNION---------------------------------------
127.0.0.1:6379> SUNION setx sety setz # setx sety setzЕФВЂМЏ
1) "m4"
2) "m6"
3) "m3"
4) "m2"
5) "m1"
6) "m5"
127.0.0.1:6379> SUNION setx sety # setx sety ВЂМЏ
1) "m4"
2) "m6"
3) "m2"
4) "m1"
5) "m5"
Hash(ЙўЯЃМЏКЯ)
MapМЏКЯ,key-MapМЏКЯ,етЪБКђжЕЪЧвЛИіMapМЏКЯЁЃУПвЛИіkeyЖдгІзХвЛИіHashMap,HashMapДцЗХЕФМќжЕЖдОљЪЧStringРраЭ
ЬэМгдЊЫи
hset key key_map value # ЬэМгвЛИіМќжЕЖд key_map--value ЬэМгЕНkeyЖдгІЕФHashMapжа
hmset key key_map1 value1 key_map2 value2 ... # дЪаэЬэМгЖрИіМќжЕЖд
hsetnx key key_map value # ШчЙћИУМќВЛДцдкдђЩшжУ
ЛёШЁдЊЫи
# МќжЕЖдЛёШЁ
hget key key_map # ЛёШЁkeyЖдгІЕФMapжаЛёШЁkey_mapЖдгІЕФМќжЕЖд
hmget key key_map1 key_map2 ... # ЛёШЁЖрИіМќжЕЖд
hgetall key # ЛёШЁШЋВПЕФМќжЕЖд
# МќЛёШЁ
hkeys key # ЛёШЁШЋВПЕФМќ
# жЕЛёШЁ
hvals key # ЛёШЁШЋВПЕФжЕ
ЩОГ§дЊЫи
hdel key key_map # ЩОГ§hashжИЖЈЕФзжЖЮ,ЦфvalueвВЛсБЛЩОГ§
ЛёШЁЪ§СП
hlen key # ЛёШЁhashБэЕФзжЖЮЪ§СП
ХаЖЯЪЧЗёДцдк
HEXISTS key key_map # ХаЖЯhashжаkey_map ЪЧЗёДцдк
Ъ§зжВйзї
HINCRBY key key_map value # key_mapЖдгІЕФжЕ+=value
HDECRBY key key_map value # key_mapЖдгІЕФжЕ-=value
------------------------HSET--HMSET--HSETNX----------------
127.0.0.1:6379> HSET studentx name sakura # НЋstudentxЙўЯЃБэзїЮЊвЛИіЖдЯѓ,ЩшжУnameЮЊsakura
(integer) 1
127.0.0.1:6379> HSET studentx name gyc # жиИДЩшжУfieldНјааИВИЧ,ВЂЗЕЛи0
(integer) 0
127.0.0.1:6379> HSET studentx age 20 # ЩшжУstudentxЕФageЮЊ20
(integer) 1
127.0.0.1:6379> HMSET studentx sex 1 tel 15623667886 # ЩшжУsexЮЊ1,telЮЊ15623667886
OK
127.0.0.1:6379> HSETNX studentx name gyc # HSETNX ЩшжУвбДцдкЕФfield
(integer) 0 # ЪЇАм
127.0.0.1:6379> HSETNX studentx email 12345@qq.com
(integer) 1 # ГЩЙІ
----------------------HEXISTS--------------------------------
127.0.0.1:6379> HEXISTS studentx name # nameзжЖЮдкstudentxжаЪЧЗёДцдк
(integer) 1 # Дцдк
127.0.0.1:6379> HEXISTS studentx addr
(integer) 0 # ВЛДцдк
-------------------HGET--HMGET--HGETALL-----------
127.0.0.1:6379> HGET studentx name # ЛёШЁstudentxжаnameзжЖЮЕФvalue
"gyc"
127.0.0.1:6379> HMGET studentx name age tel # ЛёШЁstudentxжаnameЁЂageЁЂtelзжЖЮЕФvalue
1) "gyc"
2) "20"
3) "15623667886"
127.0.0.1:6379> HGETALL studentx # ЛёШЁstudentxжаЫљгаЕФfieldМАЦфvalue
1) "name"
2) "gyc"
3) "age"
4) "20"
5) "sex"
6) "1"
7) "tel"
8) "15623667886"
9) "email"
10) "12345@qq.com"
--------------------HKEYS--HLEN--HVALS--------------
127.0.0.1:6379> HKEYS studentx # ВщПДstudentxжаЫљгаЕФfield
1) "name"
2) "age"
3) "sex"
4) "tel"
5) "email"
127.0.0.1:6379> HLEN studentx # ВщПДstudentxжаЕФзжЖЮЪ§СП
(integer) 5
127.0.0.1:6379> HVALS studentx # ВщПДstudentxжаЫљгаЕФvalue
1) "gyc"
2) "20"
3) "1"
4) "15623667886"
5) "12345@qq.com"
-------------------------HDEL--------------------------
127.0.0.1:6379> HDEL studentx sex tel # ЩОГ§studentx жаЕФsexЁЂtelзжЖЮ
(integer) 2
127.0.0.1:6379> HKEYS studentx
1) "name"
2) "age"
3) "email"
-------------HINCRBY--HINCRBYFLOAT------------------------
127.0.0.1:6379> HINCRBY studentx age 1 # studentxЕФageзжЖЮЪ§жЕ+1
(integer) 21
127.0.0.1:6379> HINCRBY studentx name 1 # ЗЧећЪ§зжаЭзжЖЮВЛПЩгУ
(error) ERR hash value is not an integer
127.0.0.1:6379> HINCRBYFLOAT studentx weight 0.6 # weightзжЖЮдіМг0.6
"90.8"
Zset(гаађМЏКЯ)
дкSetМЏКЯЕФЛљДЁЩЯ,діМгСЫвЛИіжЕScore,гУгкХХађЁЃШчЙћScoreЯрЭЌ,ОЭАДееvalueНјаазжЕфХХађЁЃ
ЬэМгдЊЫи
zadd key score value... # ЬэМгvalueНјШыkeyМЏКЯ,ЦфХХађжЕЮЊScore,ПЩЬэМгЖрИіжЕ
ЪфГі
# вде§ађЪфГідЊЫи,ИљОнЫїв§ПижЦЪ§Он
zrange key min max [BYSCORE|BYLEX] [WITHSCORE] [limit offset count]
- BYSCORE:ИљОнscoreжЕХХађ
- BYLEX:ИљОнvalueжЕХХађ,ШчЙћЪЧзжЗћДЎОЭИљОнзжЕфађХХађ
# ИљОнScoreХХађВЂвде§ађЪфГідЊЫи,ИљОнЪ§ОнЗЖЮЇПижЦ
zRangeByScore key min max [WITHSCORES] [limit offset count]
- minЁЂmax:ЪфГіЪ§ОнЕФЗЖЮЇ,дкИУЗЖЮЇЕФЯюВХФмВЮгыХХађ,вЛАуЪЙгУ
-inf +infБэЪОЫљгаЯюОљВЮгыХХађ - WITHSCORES:ЭЌЪБЯдЪОvalueгыscore
- limit ЁЂoffsetЁЂcount:РрЫЦгкsqlгяОф
# ХХађВЂвдФцађЪфГідЊЫи
zRevRange key start stop [WITHSCORES]
ЪфГі[start,stop]Ыїв§ЕФдЊЫи,ШчЙћstopЮЊ-1,ЕШМлгкЪфГіжСзюКѓвЛИідЊЫи
вЦГ§дЊЫи
zrem key value # вЦГ§zsetжаЕФvalueдЊЫи
ВщбЏ
zcard key # ВщПДsetжадЊЫизмЪ§
zcount key min max # ЭГМЦscore ЮЛгк[min,max]ЕФдЊЫиИіЪ§
zrank key member # ВщбЏmemberдЊЫиЮЛгкsortedsetЕФЫїв§ЮЛжУ
zscore key member # ВщбЏmemberдЊЫиЕФscore
МЏКЯВйзї
# ВюМЏ
ZDIFF key1 key2 # ЗЕЛиkey1гЕгаЕЋЪЧkey2УЛгаЕФдЊЫи
# ВЂМЏ
ZINTER key1 key2
# НЛМЏ
ZUNION key1 key2
# ВюМЏВЂДцДЂ
ZDIFFSTORE ФПБъМЏКЯ numbers key1 key2 key3...
# ВЂМЏВЂДцДЂ
ZUNIONSTORE ФПБъМЏКЯ numbers key1 key2 key3...
ZDIFFУќСюФмЙЛИљОнkey1дЊЫиБШНЯkey2ЁЂkey3ЪфШыМЏКЯЧѓГіВюМЏВЂДцДЂгыФПБъМЏКЯжа,ЪфШыМЏКЯЪ§СПгЩnumbersИјЖЈ
-------------------ZADD--ZCARD--ZCOUNT--------------
127.0.0.1:6379> ZADD myzset 1 m1 2 m2 3 m3 # ЯђгаађМЏКЯmyzsetжаЬэМгГЩдБm1 score=1 вдМАГЩдБm2 score=2..
(integer) 2
127.0.0.1:6379> ZCARD myzset # ЛёШЁгаађМЏКЯЕФГЩдБЪ§
(integer) 2
127.0.0.1:6379> ZCOUNT myzset 0 1 # ЛёШЁscoreдк [0,1]ЧјМфЕФГЩдБЪ§СП
(integer) 1
127.0.0.1:6379> ZCOUNT myzset 0 2
(integer) 2
----------------ZINCRBY--ZSCORE--------------------------
127.0.0.1:6379> ZINCRBY myzset 5 m2 # НЋГЩдБm2ЕФscore +5
"7"
127.0.0.1:6379> ZSCORE myzset m1 # ЛёШЁГЩдБm1ЕФscore
"1"
127.0.0.1:6379> ZSCORE myzset m2
"7"
--------------ZRANK--ZRANGE-----------------------------------
127.0.0.1:6379> ZRANK myzset m1 # ЛёШЁГЩдБm1ЕФЫїв§,Ыїв§АДееscoreХХађ,scoreЯрЭЌЫїв§жЕАДзжЕфЫГађЫГађдіМг
(integer) 0
127.0.0.1:6379> ZRANK myzset m2
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 1 # ЛёШЁЫїв§дк 0~1ЕФГЩдБ
1) "m1"
2) "m3"
127.0.0.1:6379> ZRANGE myzset 0 -1 # ЛёШЁШЋВПГЩдБ
1) "m1"
) "m3"
3) "m2"
#testset=>{abc,add,amaze,apple,back,java,redis} scoreОљЮЊ0
------------------ZRANGEBYLEX---------------------------------
# ЧјМфгУЗЈ
127.0.0.1:6379> zadd testset 0 abc 0 add 0 amaze 0 apple 0 back 0 java 0 redis
(integer) 7
127.0.0.1:6379> ZRANGEBYLEX testset - + # ЗЕЛиЫљгаГЩдБ - +ДњБэЫљгаЕФЧјМф
1) "abc"
2) "add"
3) "amaze"
4) "apple"
5) "back"
6) "java"
7) "redis"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 0 3 # ЗжвГ АДЫїв§ЯдЪОВщбЏНсЙћЕФ 0,1,2ЬѕМЧТМ
1) "abc"
2) "add"
3) "amaze"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 3 3 # ЯдЪО 3,4,5ЬѕМЧТМ
1) "apple"
2) "back"
3) "java"
127.0.0.1:6379> ZRANGEBYLEX testset (- [apple # ЯдЪО (-,apple] ЧјМфФкЕФГЩдБ ОЭЪЧеЙЪОappleМАЧАУцЕФЪ§Он
1) "abc"
2) "add"
3) "amaze"
4) "apple"
127.0.0.1:6379> ZRANGEBYLEX testset [apple [java # ЯдЪО [apple,java]зжЕфЧјМфЕФГЩдБ
1) "apple"
2) "back"
3) "java"
# ЦфЪЕОЭЪЧзѓПЊгвПЊ ЕЋЪЧ-ДњБэЫљгаЫљвд( [ЖМЪЧвЛбљЕФ
127.0.0.1:6379> ZRANGEBYLEX testset (- (apple
1) "abc"
2) "add"
3) "amaze"
------------------ZREM--ZREMRANGEBYLEX--ZREMRANGBYRANK--ZREMRANGEBYSCORE--------------------------------
127.0.0.1:6379> ZREM testset abc # вЦГ§ГЩдБabc
(integer) 1
127.0.0.1:6379> ZREMRANGEBYLEX testset [apple [java # вЦГ§зжЕфЧјМф[apple,java]жаЕФЫљгаГЩдБ
(integer) 3
127.0.0.1:6379> ZREMRANGEBYRANK testset 0 1 # вЦГ§ХХУћ0~1ЕФЫљгаГЩдБ
(integer) 2
127.0.0.1:6379> ZREMRANGEBYSCORE myzset 0 3 # вЦГ§scoreдк [0,3]ЕФГЩдБ
(integer) 2
# testset=> {abc,add,apple,amaze,back,java,redis} scoreОљЮЊ0
# myzset=> {(m1,1),(m2,2),(m3,3),(m4,4),(m7,7),(m9,9)}
----------------ZREVRANGE--ZREVRANGEBYSCORE--ZREVRANGEBYLEX-----------
# ЯШЕЙХХађ дйЩИбЁ
# ZREVRANGE ОЭЪЧzset reverse range ЗДзЊИљОнЫїв§еЙЪО
127.0.0.1:6379> zadd myset 1 m1 2 m2 3 m3 4 m4 7 m7 9 m9
127.0.0.1:6379> ZRANGE myset 0 -1
1) "m1"
2) "m2"
3) "m3"
4) "m4"
5) "m7"
6) "m9"
127.0.0.1:6379> ZREVRANGE myset 0 3 # АДscoreЕнМѕХХађ,ШЛКѓАДЫїв§,ЗЕЛиНсЙћЕФ 0~3
1) "m9"
2) "m7"
3) "m4"
4) "m3"
127.0.0.1:6379> ZREVRANGE myset 2 4 # ЗЕЛиХХађНсЙћЕФ Ыїв§ЕФ2~4
1) "m4"
2) "m3"
3) "m2"
# АДscoreЕнМѕЫГађ ЗЕЛиМЏКЯжаЗжЪ§дк[2,6]жЎМфЕФГЩдБ
127.0.0.1:6379> ZREVRANGEBYSCORE myset 6 2
1) "m4"
2) "m3"
3) "m2"
127.0.0.1:6379> ZREVRANGEBYSCORE myset 2 6
(empty list or set) # етбљаДЪЧБЈДэЕФ вђЮЊВЛДцдк
127.0.0.1:6379> ZREVRANGEBYLEX testset [java (add # АДзжЕфЕЙађ ЗЕЛиМЏКЯжа(add,java]зжЕфЧјМфЕФГЩдБ
1) "java"
2) "back"
3) "apple"
4) "amaze"
-----------------------------ВЙГф---------------------------
# ВЙГфетИіЪЧздЖЏХХађЕФИљОнЪззжФИ ШчЙћscoreзюаЁОЭзюЧАУц ЗёдђдкКѓУц
127.0.0.1:6379> ZRANGE testset 0 -1
1) "java"
2) "redis"
# етБпЗЂЯжЬэМгЕФСНИіЖМЪЧscoreЮЊ0ЕФИљОнЪззжФИХХађСЫ
127.0.0.1:6379> ZADD testset 0 hehe 0 xixi
(integer) 2
127.0.0.1:6379> ZRANGE testset 0 -1
1) "hehe"
2) "java"
3) "redis"
4) "xixi"
# ШЛКѓЩшжУСЫscoreЮЊ1ЕФ aaaЪЕдкзюКѓ
127.0.0.1:6379> ZADD testset 1 aaa
(integer) 1
127.0.0.1:6379> ZRANGE testset 0 -1
1) "hehe"
2) "java"
3) "redis"
4) "xixi"
5) "aaa"
-------------------------ZREVRANK------------------------------
# ZREVRANK ОЭЪЧЯШЕЙХХ дйИљОнжЕевЫїв§ ЮЛжУ
127.0.0.1:6379> ZREVRANK myset m7 # АДscoreЕнМѕЫГађ,ЗЕЛиГЩдБm7Ыїв§
(integer) 1
127.0.0.1:6379> ZREVRANK myset m2
(integer) 4
# mathscore=>{(xm,90),(xh,95),(xg,87)} аЁУїЁЂаЁКьЁЂаЁИеЕФЪ§бЇГЩМЈ
# enscore=>{(xm,70),(xh,93),(xg,90)} аЁУїЁЂаЁКьЁЂаЁИеЕФгЂгяГЩМЈ
-------------------ZINTERSTORE--ZUNIONSTORE---------------------------------
127.0.0.1:6379> ZRANGE mathscore 0 -1
1) "xg"
2) "xm"
3) "xh"
127.0.0.1:6379> ZRANGE enscore 0 -1
1) "xm"
2) "xg"
3) "xh"
127.0.0.1:6379> ZRANGE enscore 0 -1 withscores
1) "xm"
2) "70"
3) "xg"
4) "90"
5) "xh"
6) "93"
# НЋmathscore enscoreНјааКЯВЂ НсЙћДцЗХЕНsumscore
127.0.0.1:6379> ZINTERSTORE sumscore 2 mathscore enscore
(integer) 3
# КЯВЂКѓЕФscoreЪЧжЎЧАМЏКЯжаЫљгаscoreЕФКЭ
127.0.0.1:6379> ZRANGE sumscore 0 -1 withscores
1) "xm"
2) "160"
3) "xg"
4) "177"
5) "xh"
6) "188"
# ОЭЪЧШЁ СНИіЪ§ОнЕФзюаЁЕФжЕеЙЪО ДјscoreХХађЕФ
127.0.0.1:6379> ZUNIONSTORE lowestscore 2 mathscore enscore AGGREGATE MIN # ШЁСНИіМЏКЯЕФГЩдБscoreзюаЁжЕзїЮЊНсЙћЕФ
(integer) 3
127.0.0.1:6379> ZRANGE lowestscore 0 -1 withscores
1) "xm"
2) "70"
3) "xg"
4) "87"
5) "xh"
6) "93"
Ш§жжЬиЪтЪ§ОнРраЭ
geospatial ЕиРэЮЛжУ
ЬэМгЕиРэЮЛжУ (geoadd)
# keyМќ ОЖШ ЮГЖШ УћГЦ(ГЧЪаЁЂШЫУћЕШЕШ)
geoadd key latitude(ЮГЖШ) longitude(ОЖШ) name ...
Йцдђ:СНМЖЮоЗЈжБНгЬэМг,ЮвУЧвЛАуЛсЯТдиГЧЪаЪ§Он,жБНгЭЈЙ§javaГЬађвЛДЮадЕМШы!
-
гааЇЕФОЖШДг-180ЖШЕН180ЖШЁЃ
-
гааЇЕФЮГЖШДг-85.05112878ЖШЕН85.05112878ЖШЁЃ
ЕБзјБъЮЛжУГЌГіЩЯЪіжИЖЈЗЖЮЇЪБ,ИУУќСюНЋЛсЗЕЛивЛИіДэЮѓЁЃ
ЛёШЁЕиРэЮЛжУ(geopos)
geopos key member [member...] # ЛёШЁМЏКЯжавЛИі/ЖрИіГЩдБзјБъ
ЗЕЛиЕФвЛЖЈЪЧвЛИізјБъ!
ЗЕЛиСНИіЮЛжУжБЯпОрРы(geodist)
geodist key member1 member2 [unit]
ИУжИСюФЌШЯЪЧвдУзЮЊЕЅЮЛ,ЭЈЙ§аоИФunitИФБфЪфГіЕЅЮЛ,ПЩЪфШыжЕЮЊ:
- Уз m
- ЧЇУз km
- гЂУз mi
- гЂГп mt
ИјЖЈЕФОЮГЖШЮЊжааФ,евГіФГвЛАыОЖФкЕФдЊЫи(georadius )
georadius key longitude latitude radius [unit] [withcoord] [count] [withdist] [count n]
- unit : ЕЅЮЛ,ЪЙгУЙцдђЕШЭЌ
geodist - withcoord :ЯдЪООЖШгыЮГЖШ
- withdist:ЯдЪООрРы,ЕЅЮЛгыАыОЖЕЅЮЛЯрЭЌ
- count n :жЛЯдЪОЧАnИіЪ§Он,АДееОрРыЕндіХХађ
ИјЖЈзјБъЮЊжааФ,евГіФГвЛАыОЖФкЕФдЊЫи(georadiusbymember)
georadiusbyMember key member radius [unit] [withcoord] [count] [withdist] [count n]
GEOЕзВуЕФЪЕЯждРэЪЧZset,ПЩвдЪЙгУZsetЕФВйзїДІРэGEOЪ§Он
127.0.0.1:6379[13]> ZRANGE china:city 0 -1 # ВщПДЫљгадЊЫи
1) "chongqin"
2) "shenzheng"
3) "hangzhou"
4) "jiangsu"
5) "shanghai"
6) "tianjing"
7) "beijing"
127.0.0.1:6379[13]> ZRANGEBYLEX china:city - + # ХХађЪфГі
1) "chongqin"
2) "shenzheng"
3) "hangzhou"
4) "jiangsu"
5) "shanghai"
6) "tianjing"
7) "beijing"
127.0.0.1:6379[13]> ZREM china:city jiangsu # вЦГ§дЊЫи
(integer) 1
127.0.0.1:6379[13]> ZRANGE china:city 0 -1
1) "chongqin"
2) "shenzheng"
3) "hangzhou"
4) "shanghai"
5) "tianjing"
6) "beijing"
ОйР§ЫЕУї
geoadd
127.0.0.1:6379[13]> GEOADD china:city 116.41667 39.91667 beijing
(integer) 1
127.0.0.1:6379[13]> GEOADD china:city 121.43333 34.50000 shanghai
(integer) 1
127.0.0.1:6379[13]> GEOADD china:city 117.20000 39.13333 tianjing
(integer) 1
127.0.0.1:6379[13]> GEOADD china:city 118.78333 32.05000 jiangsu
127.0.0.1:6379[13]> ZRANGE china:city 0 -1
1) "jiangsu"
2) "shanghai"
3) "tianjing"
4) "beijing"
geopos
127.0.0.1:6379[13]> GEOPOS china:city jiangsu # ЛёШЁjiangsuЕФОЮГЖШЮЛжУ
1) 1) "118.78332942724227905"
2) "32.04999907785209956"
# ПЩаДЖрИі
127.0.0.1:6379[13]> GEOPOS china:city jiangsu shanghai
1) 1) "118.78332942724227905"
2) "32.04999907785209956"
2) 1) "121.4333304762840271"
2) "34.49999971716130887"
geodist
# еХМвНчЪаЕНЮїАВЪаЕФжБЯпОрРы
127.0.0.1:6379> GEODIST china:city zhangjiajie xian
"589959.2719"
georadius
# дйМгЩЯМИИіГЧЪа
127.0.0.1:6379[13]> geoadd china:city 114.06667 22.61667 shenzheng
(integer) 1
127.0.0.1:6379[13]> geoadd china:city 120.20000 30.26667 hangzhou
(integer) 1
127.0.0.1:6379[13]> geoadd china:city 106.45000 29.56667 chongqin
(integer) 1
127.0.0.1:6379[13]> GEORADIUS china:city 110 30 1000 km
1) "chongqin"
2) "shenzheng"
3) "hangzhou"
4) "jiangsu"
127.0.0.1:6379[13]> GEORADIUS china:city 110 30 500 km
1) "chongqin"
# withdist ЯдЪОЕНжаМфОрРыЕФЮЛжУ withcoord ЯдЪОЫћШЫЕФЖЈЮЛаХЯЂ(зјБъ)
127.0.0.1:6379[13]> GEORADIUS china:city 110 30 1000 km withcoord withdist
1) 1) "chongqin"
2) "346.0548"
3) 1) "106.4500012993812561"
2) "29.56666939001875249"
2) 1) "shenzheng"
2) "915.6424"
3) 1) "114.06667023897171021"
2) "22.61666928352524764"
3) 1) "hangzhou"
2) "981.3098"
3) 1) "120.20000249147415161"
2) "30.2666706589875858"
4) 1) "jiangsu"
2) "867.3741"
3) 1) "118.78332942724227905"
2) "32.04999907785209956"
# ДјЩЯcount 1 ОЭЪЧдкЩИбЁжЎЩЯ бЁдёвЛИіеЙЪО 2ОЭЪЧЧАСНИі...
127.0.0.1:6379[13]> GEORADIUS china:city 110 30 1000 km withcoord withdist count 1
1) 1) "chongqin"
2) "346.0548"
3) 1) "106.4500012993812561"
2) "29.56666939001875249"
hyperloglog
ЪЪгУГЁОА: ЭјеОUVСПЁЃДЋЭГгУsetЭГМЦ,ЕЋШєДцдкДѓСПгУЛЇid,дђЬЋЯћКФФкШнЧвТщЗГ,ШєжЛЮЊМЦЪ§ЧвдЪаэгаДэЮѓТЪ(0.81%),дђПЩаа,ЗёдђЛЙЪЧгУsetЭГМЦ
ЛљЪ§:МЏКЯжаВЛжиИДдЊЫиИіЪ§ЁЃШч{1, 3, 5, 5 ,7}дђЮЊ{1,3,5,7},ЛљЪ§ЮЊ4
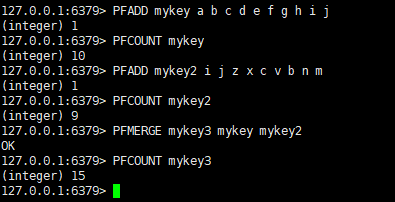
| УќСю | УшЪі |
|---|---|
| PFADD key element1 [elememt2Ё] | ЬэМгжИЖЈдЊЫиЕН HyperLogLog жа |
| PFCOUNT key [key] | ЗЕЛиИјЖЈ HyperLogLog ЕФЛљЪ§ЙРЫужЕЁЃ |
| PFMERGE destkey sourcekey [sourcekeyЁ] | НЋЖрИі HyperLogLog КЯВЂЮЊвЛИі HyperLogLog |
127.0.0.1:6379> PFADD mykey a b c d e f g h i j #ЩшжУmykey МЏКЯ
(integer) 1
127.0.0.1:6379> PFCOUNT mykey #ЭГМЦmykey МЏКЯЛљЪ§Ъ§СП
(integer) 10
127.0.0.1:6379> PFADD mykey2 i j z x c v b n m
(integer) 1
127.0.0.1:6379> PFCOUNT mykey2
(integer) 9
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 #2ИіМЏКЯШЁВЂМЏ
OK
127.0.0.1:6379> PFCOUNT mykey3
(integer) 15
127.0.0.1:6379>
Bitmaps
BitmapsЭЈГЃДцДЂСНИізДЬЌЕФЪ§Он,Р§Шч:ЕЧТМЛђЮДЕЧТМЁЂДђПЊЛђЮДДђПЈЁ
bitmapsЕФОпЬхЪЕЯжРрЪЧStringРраЭ
ГЃМћжИСю
| УќСю | УшЪі |
|---|---|
| setbit key offset value | ЮЊжИЖЈkeyЕФoffsetЮЛЩшжУжЕ |
| getbit key offset | ЛёШЁoffsetЮЛЕФжЕ |
| bitcount key [start end] | ЭГМЦзжЗћДЎБЛЩшжУЮЊ1ЕФbitЪ§,вВПЩвджИЖЈЭГМЦЗЖЮЇАДзжНк |
| bitop operration destkey key[keyЁ] | ЖдвЛИіЛђЖрИіБЃДцЖўНјжЦЮЛЕФзжЗћДЎ key НјааЮЛдЊВйзї,ВЂНЋНсЙћБЃДцЕН destkey ЩЯЁЃ |
| BITPOS key bit [start] [end] | ЗЕЛизжЗћДЎРяУцЕквЛИіБЛЩшжУЮЊ1Лђеп0ЕФbitЮЛЁЃstartКЭendжЛФмАДзжНк,ВЛФмАДЮЛ |
ОйР§ЫЕУї
------------setbit--getbit--------------
127.0.0.1:6379> setbit sign 0 1 # ЩшжУsignЕФЕк0ЮЛЮЊ 1
(integer) 0
127.0.0.1:6379> setbit sign 2 1 # ЩшжУsignЕФЕк2ЮЛЮЊ 1 ВЛЩшжУФЌШЯ ЪЧ0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> type sign
string
127.0.0.1:6379> getbit sign 2 # ЛёШЁЕк2ЮЛЕФЪ§жЕ
(integer) 1
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4 # ЮДЩшжУФЌШЯЪЧ0
(integer) 0
-----------bitcount----------------------------
# ЭГМЦетжмЕФДђПЈМЧТМ,ОЭПЩвдПДЕНЪЧЗёгаШЋЧк
127.0.0.1:6379> BITCOUNT sign # ЭГМЦsignжаЮЊ1ЕФЮЛЪ§
(integer) 4
127.0.0.1:6379[13]> get sign
"\xb4"
redisЛљДЁ
ЪТЮё
дкSQLжаЪТЮёЭЈГЃгаЫФДѓЬиад:дзгад(A)ЁЂвЛжТад?ЁЂИєРыад(I)ЁЂГжОУад(D)
RedisЕЅЬѕУќСюБЃДцдзгад,ЕЋЪЧRedisЪТЮёВЛБЃеЯдзгад!
RedisЪТЮёУЛгаИєРыМЖБ№,вВОЭЪЧУЛгаИєРыад!
RedisЪТЮёБОжЪ:вЛзщУќСюЕФМЏКЯЁЃ
----------------- ЖгСа set set set жДаа -------------------
ЪТЮёжаУПЬѕУќСюЖМЛсБЛађСаЛЏ,жДааЙ§ГЬжаАДЫГађжДаа,ВЛдЪаэЦфЫћУќСюНјааИЩШХЁЃ
вЛДЮад
ЫГађад
ХХЫћад
1 RedisЪТЮёУЛгаИєРыМЖБ№ЕФИХФю
2 RedisЕЅЬѕУќСюЪЧБЃжЄдзгадЕФ,ЕЋЪЧЪТЮёВЛБЃжЄдзгад!
RedisЪТЮёВйзїЙ§ГЬ
- ПЊЦєЪТЮё(
multi) - УќСюШыЖг
- жДааЪТЮё(
exec)
ЫљвдЪТЮёжаЕФУќСюдкМгШыЖгСаЪБУЛгаБЛжДаа,жЛгаЬсНЛЪБВХЛсПЊЪМжДааВЂвЛДЮадЭъГЩ
# етЪЧе§ГЃСїГЬ
127.0.0.1:6379> multi # ПЊЦєЪТЮё
OK
127.0.0.1:6379> set k1 v1 # УќСюШыЖг
QUEUED
127.0.0.1:6379> set k2 v2 # ..
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec # ЪТЮёжДаа
1) OK
2) OK
3) "v1"
4) OK
5) 1) "k3"
2) "k2"
3) "k1"
ЗХЦњЪТЮё(
discard)
# етЪЧШЁЯћЪТЮё ЪжЖЏШЁЯћЕФ
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> DISCARD # ЗХЦњЪТЮё
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI # ЕБЧАЮДПЊЦєЪТЮё
127.0.0.1:6379> get k1 # БЛЗХЦњЪТЮёжаУќСюВЂЮДжДаа
(nil)
RedisЪТЮёвьГЃ
RedisЪТЮёДцдкСНжжвьГЃ:дЫааЪБвьГЃЁЂБрвыЪБвьГЃ
БрвыЪБвьГЃ
БрвыЪБвьГЃГіДэ,ЫљгаЕФУќСюЖМВЛЛсжДаа!
# етЪЧБрвыЪБЕФДэЮѓ гяЗЈДэЮѓ ЫљгаУќСюВЛЩњаЇ
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> error k1 # етЪЧвЛЬѕФЃФтгяЗЈДэЮѓУќСю
(error) ERR unknown command `error`, with args beginning with: `k1`, # ЛсБЈДэЕЋЪЧВЛгАЯьКѓајУќСюШыЖг
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors. # жДааБЈДэ
127.0.0.1:6379> get k1
(nil) # ЦфЫћУќСюВЂУЛгаБЛжДаа
дЫааЪБвьГЃ
дЫааЪБвьГЃГіДэ,ДэЮѓЕФУќСюВЛЛсжДаа,ЦфгрУќСюОљПЩвде§ГЃжДаа!RedisЪТЮёВЛБЃжЄдзгад!
# дЫааЪББЈДэ е§ГЃЕФУќСюЪЧжДааЭъСЫ ЫљвдВЛБЃжЄдзгад
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> INCR k1 # етЬѕУќСюТпМДэЮѓ(ЖдзжЗћДЎНјаадіСП)
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range # дЫааЪББЈДэ
4) "v2" # ЦфЫћУќСюе§ГЃжДаа
# ЫфШЛжаМфгавЛЬѕУќСюБЈДэСЫ,ЕЋЪЧКѓУцЕФжИСювРОЩе§ГЃжДааГЩЙІСЫЁЃ
# ЫљвдЫЕRedisЕЅЬѕжИСюБЃжЄдзгад,ЕЋЪЧRedisЪТЮёВЛФмБЃжЄдзгадЁЃ
RedisЪТЮёЫфШЛЫЕЪЧЪТЮё,ЕЋЪЧЦфИќЯёЪЧвЛжжХњДІРэЁЃ
РжЙлЫј
РжЙлЫјЕФЦеЭЈЪЕЯжЗНЪНЪЧЖЈвхвЛИіversionзжЖЮ,ЕБФГвЛИіЯпГЬаоИФФГИіВЮЪ§ЪБ,ШУversionЕФзжЖЮздЖЏИФБфЁЃЧыЧѓЕНДяЪБЪзЯШЛсВщбЏЕБЧАversion,ЕБаоИФЪ§ОнЪБдйвЛДЮВщбЏversion,ШчЙћversionЧАКѓВЛвЛжТЫЕУїгаЦфЫћЯпГЬВЮгыСЫаоИФ,аоИФЪЇАмЁЃ
RedisжаРжЙлЫјПЩвдЪЙгУЙиМќзжwatchМрЬ§versionзжЖЮ,УПвЛДЮаоИФЖМЛсБШЖдЧАКѓЕФversionЪЕЯжРжЙлЫјЁЃ
watch key # МрЬ§keyЕФversionзжЖЮ
unwatch key # НтГ§keyМќЕФМрЬ§
ОйР§ЫЕУї
е§ГЃжДааГЩЙІ
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # МрЪг money ЖдЯѓ
OK
127.0.0.1:6379> multi # ЪТЮёе§ГЃНсЪј,Ъ§ОнЦкМфУЛгаЗЂЩњБфЖЏ,етИіЪБКђОЭе§ГЃжДааГЩЙІ!
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY out 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
ФЃФтЖрЯпГЬаоИФжЕ,ЪЙгУwatchЪЕЯжРжЙлЫјВйзї!
# ЕквЛИіПЭЛЇЖЫ ЯШБ№жДааexec вђЮЊДЫЪБwatchКѓЕФжЕЛЙЪЧдРДЕФжЕ
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
127.0.0.1:6379> watch money # МрЪг money КѓЕкЖўПЭЛЇЖЫаоИФmoney
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 10
QUEUED
127.0.0.1:6379> INCRBY out 10
QUEUED
# ЕБЕкЖўИіПЭЛЇЖЫжДааЭъКѓ ЮвдйжДааexec ОЭБЈДэСЫ
127.0.0.1:6379> exec #жДаажЎЧА,СэЭтвЛИіЯпГЬ,аоИФСЫЮвУЧЕФжЕ,етИіЪБКђ,ОЭЛсЕМжТЪТЮёжДааЪЇАм!
(nil)
#ЕкЖўИіПЭЛЇЖЫ
127.0.0.1:6379> set money 80
OK
ЮоТлЪЧдЫааГЩЙІЛЙЪЧаоИФЪЇАмЛђепЕїгУdiscardЭЫГіЪТЮё,ИУЯпГЬЛсздЖЏЗХЦњЫјЁЃ
ХаЖЯЮЊЪЇАмЕФЧщПі
# ЛёШЁзюаТЕФжЕ,дйДЮМрЪг,select version
127.0.0.1:6379[13]> watch money
OK
127.0.0.1:6379[13]> MULTI
OK
127.0.0.1:6379[13]> DECRBY money 20
QUEUED
127.0.0.1:6379[13]> INCRby out 20
QUEUED
# БШЖдМрЪгЕФжЕЪЧЗёЗЂЩњСЫБфЛЏ,ШчЙћУЛга,жДааГЩЙІ,ШчЙћБфСПЕФАцБОБфЛЏСЫ,жДааЪЇАм
127.0.0.1:6379[13]> exec
1) (integer) 60
2) (integer) 20
Jedis
Jedis ЪЧ Redis ЙйЗНЭЦМіЕФ javaСЌНгПЊЗЂЙЄОп! ЪЙгУJava ВйзїRedis жаМфМў!
ЕМШыЖдгІЕФвРРЕ
<!--ЕМШыjedisЕФАќ-->
<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
БрТыВтЪд:
- СЌНгЪ§ОнПт
- ВйзїУќСю
- ЖЯПЊСЌНг!
import redis.clients.jedis.Jedis;
public class TestPing {
public static void main(String[] args) {
// 1ЁЂ new Jedis ЖдЯѓМДПЩ
Jedis jedis = new Jedis("127.0.0.1",6379);
// jedis ЫљгаЕФУќСюОЭЪЧЮвУЧжЎЧАбЇЯАЕФЫљгажИСю!ЫљвджЎЧАЕФжИСюбЇЯАКмживЊ!
System.out.println(jedis.ping());
}
}
ГЃгУЕФAPI
- String
- List
- Set
- Hash
- Zset
ЫљгаЕФapiУќСю,ОЭЪЧЮвУЧЖдгІЕФЩЯУцбЇЯАЕФжИСю,вЛИіЖМУЛгаБфЛЏ!
етРяУЛгаеЙЪО
ЪЙгУЪТЮё
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("39.99.xxx.xx", 6379);
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello", "world");
jsonObject.put("name", "kuangshen");
// ПЊЦєЪТЮё
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(user1)
try {
multi.set("user1", result);
multi.set("user2", result);
// жДааЪТЮё
multi.exec();
}catch (Exception e){
// ЗХЦњЪТЮё
multi.discard();
} finally {
// ЙиБеСЌНг
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close();
}
}
}
SpringBootећКЯRedis
БИзЂ:ДгSpringBoot2.xжЎКѓ,дЯШЪЙгУЕФJedisБЛlettuceЬцДњ
Jedis:ВЩгУжБСЌ,ФЃФтЖрИіЯпГЬВйзїЛсГіЯжАВШЋЮЪЬтЁЃЮЊБмУтДЫЮЪЬт,ашвЊЪЙгУJedis PoolСЌНгГи!РрЫЦгкBIOФЃЪН
lettuce:ВЩгУnettyЭјТчПђМм,ЖдЯѓПЩвддкЖрИіЯпГЬжаБЛЙВЯэ,ЭъУРБмУтЯпГЬАВШЋЮЪЬт,МѕЩйЯпГЬЪ§Он,РрЫЦгкNIOФЃЪН
ЪзЯШЯШВщПДRedisAutoConfigurationжаЕФдДТы
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
// АѓЖЈЕФХфжУРр RedisProperties.class
@EnableConfigurationProperties(RedisProperties.class)
// ХфжУСНИіРр
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
// БэЪОгУЛЇФмЙЛздЖЈвхRedisTemplate
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
// ФЌШЯЕФRedisTemplateжБНгЪЙгУДЫРрФкВПФЌШЯЩшжУВйзїЪ§Он,ЕЋЪЧRedisЖдЯѓашвЊађСаЛЏ
// ЗКаЭЖМЪЧObject,КѓУцЪЙгУЕФЛА,ДѓЖМЪЧRedisTemplate<String, Object>
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
// StringРраЭдкredisЪЙгУзюЖр,StringRedisTemplateДІРэStringЪ§Он
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
ЩЯУцЕФ@ImportзЂНтЕМШыСЫСНИіХфжУРр,гаLettuceКЭJedis,ПЩвдЕуПЊетСНИіРрВщПД


ЖдБШвЛЯТПЩвдЗЂЯж,JedisХфжУРржагаСНИіРрЪЧФЌШЯВЛДцдкЕФ,ВЛДцдкОЭЮоЗЈЪЙгУ
1ЁЂЕМШывРРЕ
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2ЁЂЪєадХфжУ
# ХфжУRedis
spring.redis.host=127.0.0.1
spring.redis.port=6379
БИзЂ:етБпЕФХфжУ,ашвЊзЂвтЕФЪЧ,SpringBootећКЯЕФЪЧLettuce,ШчЙћдкХфжУЮФМўжаЬэМгЖюЭтЕФХфжУ,БШШчRedisЕФзюДѓЕШД§ЪБМфЁЂГЌЪБЪБМфЕШ,дкЖдгІЕФRedisPropertiesРрЫљгГЩфЕФХфжУЮФМўжа,ЪєадУћГЦвЛЖЈвЊМгЩЯДјгаlettuce,ШчЙћМгЩЯjedis,ЫќФЌШЯВЛЛсЩњаЇ


3ЁЂВтЪдСЌНг
@Test
void contextLoads() {
ValueOperations ops = redisTemplate.opsForValue();
redisTemplate.opsForGeo();
ops.set("k1", "xiaohuang");
Object o = ops.get("k1");
System.out.println(o);
}
ВтЪдСЫжЎКѓдкПижЦЬЈПЩвдГЩЙІЛёШЁ

ЕЋЪЧдкLinuxжаЕФRedisЛёШЁНсЙћЕУЕНЕФШДЪЧТвТы
127.0.0.1:6379> keys *
1) "\xac\xed\x00\x05t\x00\x02k1"
етгыRedisTemplateФЌШЯађСаЛЏгаЙи,JavaЕФФЌШЯађСаЛЏЙцдђRedisЮоЗЈЪЖБ№,вђДЫЪфШыЕФЪ§ОнЮоЗЈБЛRedisЗДађСаЛЏЪфГіЕФОЭЪЧТвТыЁЃ
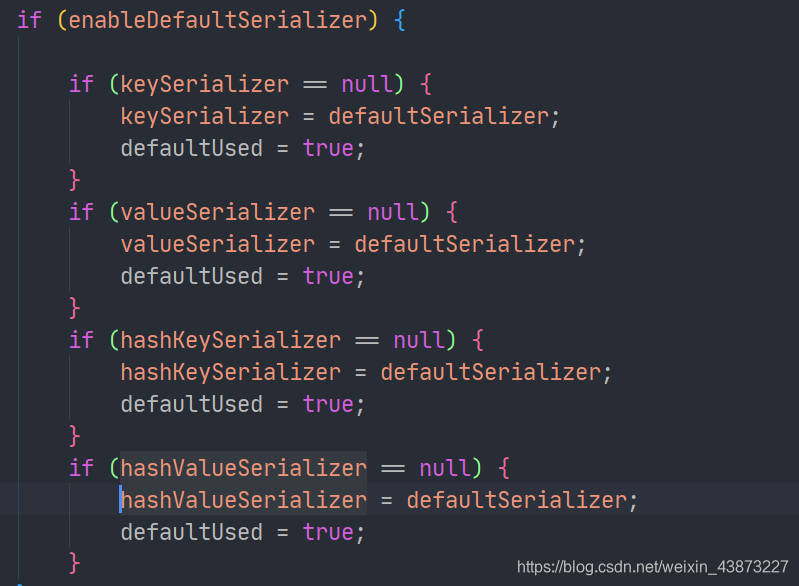
ЯШеЙЪОRedisTemplateЕФВПЗждДТы
// етаЉЪЧRedisTemplateЕФађСаЛЏХфжУ
private @Nullable RedisSerializer keySerializer = null;
private @Nullable RedisSerializer valueSerializer = null;
private @Nullable RedisSerializer hashKeySerializer = null;
private @Nullable RedisSerializer hashValueSerializer = null;
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
boolean defaultUsed = false;
if (defaultSerializer == null) {
// етБпФЌШЯЪЙгУJDKЕФађСаЛЏЗНЪН,ПЩвдздЖЈвхвЛИіХфжУРр,ВЩгУЦфЫћЕФађСаЛЏЗНЪН
defaultSerializer = new JdkSerializationRedisSerializer(
classLoader != null ? classLoader : this.getClass().getClassLoader());
}
}
}
ЖјФЌШЯЕФRedisTemplateжаЕФЫљгаађСаЛЏЦїЖМЪЧЪЙгУетИіађСаЛЏЦї:
здЖЈвхRedisTemplate
// здЖЈвхRedisTemplate
// етЪЧRedisTemplateЕФвЛИіФЃАх
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
// ЮЊСЫПЊЗЂЗНБу,ПЩвджБНгЪЙгУ<String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<>();
// ађСаЛЏХфжУ
Jackson2JsonRedisSerializer serializer =new Jackson2JsonRedisSerializer(Object.class);
template.setDefaultSerializer(serializer);
// ФЌШЯЕФжБНгаДОЭаа
template.setConnectionFactory(redisConnectionFactory);
// зЊвх
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance);
serializer.setObjectMapper(om);
// StringађСаЛЏ
StringRedisSerializer srs = new StringRedisSerializer();
// ЖдгкStringКЭHashРраЭЕФKey,ПЩвдВЩгУStringЕФађСаЛЏЗНЪН
template.setKeySerializer(srs);
template.setHashKeySerializer(srs);
// StringКЭHashРраЭЕФvalueПЩвдЪЙгУjsonЕФЗНЪННјааађСаЛЏ
template.setValueSerializer(serializer);
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
redisНјНз
redis.confНтЮі
RedisЕФЦєЖЏБиаывЊгУЕНХфжУЮФМў!
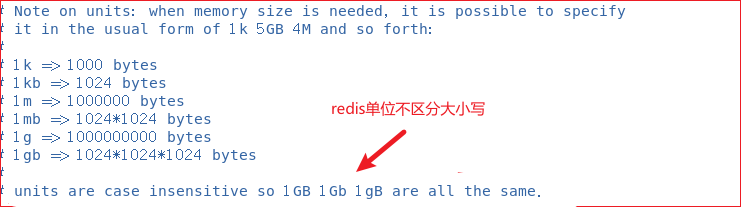
Units ЕЅЮЛ
ШнСПЕЅЮЛВЛЧјЗжДѓаЁаД,ЭЌЪБзЂвт:k!=kb
includes АќКЌ
ПЩвдЪЙгУ include АќКЌЖрИіХфжУЮФМў
? 
network ЭјТч
ЭјТч,БэЪОRedisЦєЖЏЪБПЊЗХЕФЖЫПкФЌШЯгыБОЛњАѓЖЈ
bind 127.0.0.1
RedisжИЖЈМрЬ§ЖЫПк,ФЌШЯЮЊ6379
port 6379
БэЪОЗўЮёЦїЯажУЖрГЄЪБМф(Уы)КѓБЛЙиБе,ШчЙћетИіетИіЪ§жЕЮЊ0,БэЪОетИіЙІФмВЛЦ№зїгУ
timeout 300
ЪЧЗёПЊЦєБЃЛЄФЃЪН,RedisФЌШЯПЊЦє,ШчЙћУЛгаЩшжУbindЕФIPЕижЗКЭRedisУмТы,ФЧУДЗўЮёОЭЛсФЌШЯжЛФмдкБОЛњдЫаа
protected-mode yes
General ЭЈгУ
ЪЧЗёвдЪиЛЄНјГЬЕФЗНЪНдЫаа,МДКѓЬЈдЫаа,вЛАуФЌШЯЮЊno,ашвЊЪжЖЏИФЮЊyesЗёдђЮоЗЈКѓЬЈдЫаа
daemonize yes
ШчЙћвдЪиЛЄНјГЬЕФЗНЪНдЫаа,ОЭашвЊжИЖЈвЛИіpidЮФМў,дкRedisЦєЖЏЪБДДНЈ,ЭЫГіЪБЩОГ§
pidfile /var/run/redis_6379.pid # pidЮФМўЕФБЃДцЮЛжУ
ХфжУШежОЕШМЖ,ШежОЕШМЖЕФПЩбЁЯюШчЯТ:
- debug:ДђгЁЕФаХЯЂНЯЖр,дкЙЄзїжажївЊгУгкПЊЗЂКЭВтЪд
- verbose:ДђгЁЕФаХЯЂНіДЮгкdebug,ЕЋЪЧИёЪННЯЮЊЙЄећ
- notice:RedisФЌШЯХфжУ,дкЩњВњЛЗОГжаЪЙгУ
- warning:жЛДђгЁвЛаЉживЊаХЯЂ,БШШчОЏИцКЭДэЮѓ
loglevel notice
ДђгЁЕФШежОЮФМўУћГЦ,ШчЙћЮЊПе,БэЪОБъзМЪфГі,дкХфжУЪиЛЄНјГЬЕФФЃЪНЯТЛсНЋЪфГіаХЯЂБЃДцЕН/dev/null
logfile ""
Ъ§ОнПтжЇГжЪ§СП,16Иі
databases 16
SNAPSHOTTING Пьее(RDBХфжУ)
жаЮФЗвыЮЊПьее,ШчЙћдкЙцЖЈЕФЪБМфФк,Ъ§ОнЗЂЩњСЫМИДЮИќаТ,ФЧУДОЭЛсНЋЪ§ОнЭЌВНБИЗнЕНвЛИіЮФМўжа
RedisЕФГжОУЛЏгаСНжжЗНЪН,вЛжжЪЧRDB,вЛжжЪЧAOFЁЃSNAPSHOTTINGжївЊеыЖдЕФЪЧRedisГжОУЛЏжаЕФRDB
RedisЪЧвЛИіФкДцЪ§ОнПт,ШчЙћВЛВЩгУГжОУЛЏЖдЪ§ОнНјааБЃДц,ФЧУДОЭЛсГіЯжЖЯЕчМДЪЇЕФоЯоЮГЁУц
# дк900УыФк,жСЩйгавЛИіkeyБЛаоИФ(ЬэМг),ОЭЛсНјааГжОУЛЏВйзї
save 900 1
# дк300УыФк,жСЩйга10ИіkeyБЛаоИФ,ОЭЛсНјааГжОУЛЏВйзї
save 300 10
# дк60УыФк,жСЩйга1ЭђИіkeyБЛаоИФ,ОЭЛсНјааГжОУЛЏВйзї
save 60 10000
top-writes-on-bgsave-error yes # ШчЙћRedisдкНјааГжОУЛЏЕФЪБКђГіЯжДэЮѓ,ЪЧЗёЭЃжЙаДШы,ФЌШЯЮЊЪЧ
rdbcompression yes # ЪЧЗёдкНјааЪ§ОнБИЗнЪБбЙЫѕГжОУЛЏЮФМў,ФЌШЯЮЊЪЧ,етИіВйзїЛсКФЗбCPUзЪдД,ПЩвдЩшжУЮЊno
rdbchecksum yes # дкБЃДцГжОУЛЏЮФМўЕФЭЌЪБ,ЖдЮФМўФкШнНјааЪ§ОнаЃбщ
dir ./ # ГжОУЛЏЮФМўБЃДцЕФФПТМ,ФЌШЯБЃДцдкЕБЧАФПТМЯТ
Security АВШЋ

М§ЭЗДІАДее:requirepass УмТыЕФИёЪНЩшжУЕЧТМУмТы,ЪЙгУжИСювВЭЌбљПЩвдЪЕЯж,ВЛЙ§ашвЊБЃДцжИСюБЃДцХфжУ,жИСюИёЪНШчЯТ:
127.0.0.1:6379> CONFIG GET requirepass # ВщПДУмТыЩшжУ
1) "requirepass"
2) ""
127.0.0.1:6379> CONFIG SET requirepass "123456" # ЩшжУУмТыЮЊ123456
OK
127.0.0.1:6379> set name "cjx"
OK
127.0.0.1:6379> get name "cjx" # УЛгаЗУЮЪШЈЯо
Invalid argument(s)
127.0.0.1:6379> AUTH "123456" # ЕЧТМ
OK
127.0.0.1:6379> get name
"cjx22"
Client ПЭЛЇЖЫ
maxclients 10000 # зюДѓПЭЛЇЖЫЪ§СП
maxmemory <bytes> # зюДѓФкДцЯожЦ
maxmemory-policy noeviction # ФкДцДяЕНЯожЦжЕЕФДІРэВпТд
redis жаЕФФЌШЯЕФЙ§ЦкВпТдЪЧ volatile-lru ЁЃ
ЩшжУЗНЪН
config set maxmemory-policy volatile-lru
maxmemory-policy ВпТд
# volatile-lru -> Evict(Ч§ж№) using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
**1ЁЂvolatile-lru:**жЛЖдЩшжУСЫЙ§ЦкЪБМфЕФkeyНјааLRU(ФЌШЯжЕ)
2ЁЂallkeys-lru : ЩОГ§lruЫуЗЈЕФkey
**3ЁЂvolatile-random:**ЫцЛњЩОГ§МДНЋЙ§Цкkey
**4ЁЂallkeys-random:**ЫцЛњЩОГ§
5ЁЂvolatile-ttl : ЩОГ§зюНќМДНЋЙ§ЦкЕФ
6ЁЂnoeviction : гРВЛЙ§Цк,ЗЕЛиДэЮѓ
AOFХфжУ 

RedisГжОУЛЏ
УцЪдКЭЙЄзї,ГжОУЛЏЖМЪЧжиЕу!
Redis ЪЧФкДцЪ§ОнПт,ШчЙћВЛНЋФкДцжаЕФЪ§ОнПтзДЬЌБЃДцЕНДХХЬ,ФЧУДвЛЕЉЗўЮёЦїНјГЬЭЫГі,ЗўЮёЦїжаЕФЪ§ОнПтзДЬЌвВЛсЯћЪЇЁЃЫљвд Redis ЬсЙЉСЫГжОУЛЏЙІФм!
RDB(Redis DataBase)
ЪВУДЪЧRDB

дкжИЖЈЕФЪБМфМфИєФкНЋФкДцжаЕФЪ§ОнМЏПьееаДШыДХХЬ,вВОЭЪЧааЛАНВЕФSnapshotПьее,ЫќЛжИДЪБЪЧНЋПьееЮФМўжБНгЖСЕНФкДцРяЁЃ
RedisЛсЕЅЖРДДНЈ(fork)вЛИізгНјГЬРДНјааГжОУЛЏ,ЛсЯШНЋЪ§ОнаДШыЕНвЛИіСйЪБЮФМўжа,Д§ГжОУЛЏЙ§ГЬЖМНсЪјСЫ,дйгУетИіСйЪБЮФМў**ЬцЛЛ**ЩЯДЮГжОУЛЏКУЕФЮФМўЁЃећИіЙ§ГЬжа,жїНјГЬЪЧВЛНјааШЮКЮIOВйзїЕФЁЃетОЭШЗБЃСЫМЋИпЕФадФмЁЃШчЙћашвЊНјааДѓЙцФЃЪ§ОнЕФЛжИД,ЧвЖдгкЪ§ОнЛжИДЕФЭъећадВЛЪЧЗЧГЃУєИа,ФЧRDBЗНЪНвЊБШAOFЗНЪНИќМгЕФИпаЇЁЃRDBЕФШБЕуЪЧзюКѓвЛДЮГжОУЛЏКѓЕФЪ§ОнПЩФмЖЊЪЇЁЃЮвУЧФЌШЯЕФОЭЪЧRDB,вЛАуЧщПіЯТВЛашвЊаоИФетИіХфжУ!
гаЪБКђдкЩњВњЛЗОГЮвУЧЛсНЋетИіЮФМўНјааБИЗн!
rdbБЃДцЕФЮФМўЪЧdump.rdb ЖМЪЧдкЮвУЧЕФХфжУЮФМўжаПьеежаНјааХфжУЕФ!
ДЅЗЂЛњжЦ
- 1ЁЂsaveЙцдђТњзуЕФЧщПіЯТ,ЛсздЖЏДЅЗЂrdbЙцдђ
- 2ЁЂжДаа flushall УќСю,вВЛсДЅЗЂЮвУЧЕФrdbЙцдђ!
- 3ЁЂЭЫГіredis,вВЛсВњЩњ rdb ЮФМў!
БИЗнОЭздЖЏЩњГЩвЛИі dump.rdb
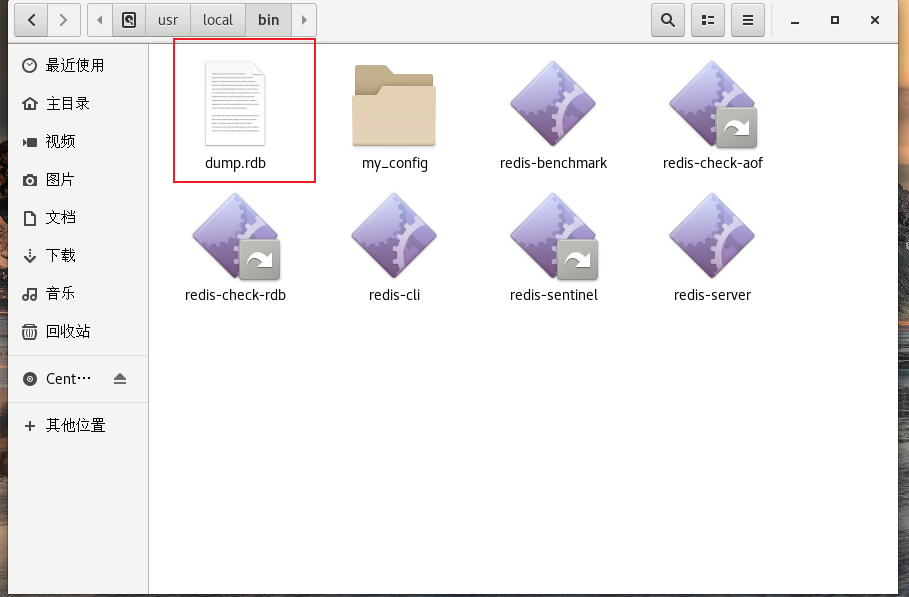
ШчЙћЛжИДrdbЮФМў!
1ЁЂжЛашвЊНЋrdbЮФМўЗХдкЮвУЧredisЦєЖЏФПТМОЭПЩвд,redisЦєЖЏЕФЪБКђЛсздЖЏМьВщdump.rdb ЛжИДЦфжаЕФЪ§Он!
2ЁЂВщПДашвЊДцдкЕФЮЛжУ
127.0.0.1:6379> config get dir
1) "dir"
2) "./" # ШчЙћдкетИіФПТМЯТДцдк dump.rdbЮФМў,ЦєЖЏОЭЛсздЖЏЛжИДЦфжаЕФЪ§Он
МИКѕОЭЫћздМКФЌШЯЕФХфжУОЭЙЛгУСЫ,ЕЋЪЧЮвУЧЛЙЪЧашвЊШЅбЇЯА!
гХЕу:
- 1ЁЂЪЪКЯДѓЙцФЃЕФЪ§ОнЛжИД!
- 2ЁЂЖдЪ§ОнЕФЭъећадвЊЧѓВЛИп!
ШБЕу:
- 1ЁЂашвЊвЛЖЈЕФЪБМфМфИєНјГЬВйзї!ШчЙћredisвтЭтхДЛњСЫ,етИізюКѓвЛДЮаоИФЪ§ОнОЭУЛгаЕФСЫ!
- 2ЁЂforkНјГЬЕФЪБКђ,ЛсеМгУвЛЖЈЕФФкШнПеМф!!
AOF(Append Only File)
НЋЮвУЧЕФЫљгаУќСюЖММЧТМЯТРД,history,ЛжИДЕФЪБКђОЭАбетИіЮФМўШЋВПдкжДаавЛБщ!
ЪВУДЪЧAOF?

вдШежОЕФаЮЪНРДМЧТМУПИіаДВйзї,НЋRedisжДааЙ§ЕФЫљгажИСюМЧТМЯТРД(ЖСВйзїВЛМЧТМ),жЛаэзЗМгЮФМўЕЋВЛПЩвдИФаДЮФМў,redisЦєЖЏжЎГѕЛсЖСШЁИУЮФМўжиаТЙЙНЈЪ§Он,ЛЛбджЎ,redisжиЦєЕФЛАОЭИљОнШежОЮФМўЕФФкШнНЋаДжИСюДгЧАЕНКѓжДаавЛДЮвдЭъГЩЪ§ОнЕФЛжИДЙЄзї
AofБЃДцЕФЪЧ appendonly.aof ЮФМў
ЪВУДЪЧAOF
ПьееЙІФм(RDB)ВЂВЛЪЧЗЧГЃФЭОУ(durable): ШчЙћ RedisвђЮЊФГаЉдвђЖјдьГЩЙЪеЯЭЃЛњ,ФЧУДЗўЮёЦїНЋЖЊЪЇзюНќаДШыЁЂвдМАЮДБЃДцЕНПьеежаЕФФЧаЉЪ§ОнЁЃ Дг 1.1 АцБОПЊЪМ, Redis діМгСЫвЛжжЭъШЋФЭОУЕФГжОУЛЏЗНЪН: AOF ГжОУЛЏЁЃ
ШчЙћвЊЪЙгУAOF,ашвЊаоИФХфжУЮФМў

appendonly no yesдђБэЪОЦєгУAOF
ФЌШЯЪЧВЛПЊЦєЕФ,ЮвУЧашвЊЪжЖЏХфжУ,ШЛКѓжиЦєredis,ОЭПЩвдЩњаЇСЫ!
ШчЙћетИіaofЮФМўгаДэЮѓ,етЪБКђredisЪЧЦєЖЏВЛЦ№РДЕФ,ЮвашвЊаоИФетИіaofЮФМў
redisИјЮвУЧЬсЙЉСЫвЛИіЙЄОпredis-check-aofаоИД,аоИДДњТыЮЊ:redis-check-aof --fix appendonly.aof,етбљЕФаоИДПЩФмЛсдьГЩФГаЉЪ§ОнЕФЖЊЪЇЁЃ
жиаДЙцдђЫЕУї
aof ФЌШЯОЭЪЧЮФМўЕФЮоЯозЗМг,ЮФМўЛсдНРДдНДѓ

ШчЙћ aof ЮФМўДѓгк 64m,ЬЋДѓСЫ! forkвЛИіаТЕФНјГЬРДНЋЮвУЧЕФЮФМўНјаажиаД!
AOF ЮФМўжиаДЕФЪЕЯж
- AOFжиаДВЂВЛашвЊЖддгаAOFЮФМўНјааШЮКЮЕФЖСШЁ,аДШы,ЗжЮіЕШВйзї,етИіЙІФмЪЧЭЈЙ§ЖСШЁЗўЮёЦїЕБЧАЕФЪ§ОнПтзДЬЌРДЪЕЯжЕФЁЃ
# МйЩшЗўЮёЦїЖдМќlistжДааСЫвдЯТУќСюs;
127.0.0.1:6379> RPUSH list "A" "B"
(integer) 2
127.0.0.1:6379> RPUSH list "C"
(integer) 3
127.0.0.1:6379> RPUSH list "D" "E"
(integer) 5
127.0.0.1:6379> LPOP list
"A"
127.0.0.1:6379> LPOP list
"B"
127.0.0.1:6379> RPUSH list "F" "G"
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "C"
2) "D"
3) "E"
4) "F"
5) "G"
- ЕБЧАСаБэМќlistдкЪ§ОнПтжаЕФжЕОЭЮЊ
["C", "D", "E", "F", "G"]ЁЃвЊЪЙгУОЁСПЩйЕФУќСюРДМЧТМlistМќЕФзДЬЌ,зюМђЕЅЕФЗНЪНВЛЪЧШЅЖСШЁКЭЗжЮіЯжгаAOFЮФМўЕФФкШн,,ЖјЪЧжБНгЖСШЁlistМќдкЪ§ОнПтжаЕФЕБЧАжЕ,ШЛКѓгУвЛЬѕRPUSH list "C" "D" "E" "F" "G"ДњЬцЧАУцЕФ6ЬѕУќСюЁЃ
гХЕу:
- 1ЁЂУПвЛДЮаоИФЖМЭЌВН,ЮФМўЕФЭъећЛсИќМгКУ!
- 2ЁЂУПУыЭЌВНвЛДЮ,ПЩФмЛсЖЊЪЇвЛУыЕФЪ§Он
- 3ЁЂДгВЛЭЌВН,аЇТЪзюИпЕФ!
ШБЕу:
- 1ЁЂЯрЖдгкЪ§ОнЮФМўРДЫЕ,aofдЖдЖДѓгк rdb,аоИДЕФЫйЖШвВБШ rdbТ§!
- 2ЁЂAof дЫаааЇТЪвВвЊБШ rdb Т§,ЫљвдЮвУЧredisФЌШЯЕФХфжУОЭЪЧrdbГжОУЛЏ
RDBКЭAOFбЁдё
| гаЕу | RDB | AOF |
|---|---|---|
| ЦєЖЏгХЯШМЖ | ЕЭ | Ип |
| ЬхЛ§ | аЁ | Дѓ |
| ЛжИДЫйЖШ | Пь | Т§ |
| Ъ§ОнАВШЋад | ЖЊЪ§Он | ИљОнВпТдОіЖЈ |
ШчКЮбЁдёЪЙгУФФжжГжОУЛЏЗНЪН?
ШчЙћНіНіЪЧЪЙгУRedisЕБзіЛКДц,ФЧУДЩѕжСПЩвдВЛгУГжОУЛЏ!ЕЋЪЧвЛАуРДЫЕ, ШчЙћЯыДяЕНзувдцЧУР PostgreSQL ЕФЪ§ОнАВШЋад, ФугІИУЭЌЪБЪЙгУСНжжГжОУЛЏЙІФмЁЃ
ШчЙћФуЗЧГЃЙиаФФуЕФЪ§Он, ЕЋШдШЛПЩвдГаЪмЪ§ЗжжгвдФкЕФЪ§ОнЖЊЪЇ, ФЧУДФуПЩвджЛЪЙгУ RDB ГжОУЛЏЁЃ
гаКмЖргУЛЇЖМжЛЪЙгУ AOF ГжОУЛЏ, ЕЋВЂВЛЭЦМіетжжЗНЪН: вђЮЊЖЈЪБЩњГЩ RDB Пьее(snapshot)ЗЧГЃБугкНјааЪ§ОнПтБИЗн, ВЂЧв RDB ЛжИДЪ§ОнМЏЕФЫйЖШвВвЊБШ AOF ЛжИДЕФЫйЖШвЊПьЁЃ
ЗЂВМЖЉдФ
Redis ЗЂВМЖЉдФ(pub/sub)ЪЧвЛжжЯћЯЂЭЈаХФЃЪН:ЗЂЫЭеп(pub)ЗЂЫЭЯћЯЂ,ЖЉдФеп(sub)НгЪеЯћЯЂЁЃЮЂаХЁЂЮЂВЉЁЂЙизЂЯЕЭГ!
Redis ПЭЛЇЖЫПЩвдЖЉдФШЮвтЪ§СПЕФЦЕЕРЁЃ
ЖЉдФ/ЗЂВМЯћЯЂЭМ:
ЕквЛИі:ЯћЯЂЗЂЫЭеп, ЕкЖўИі:ЦЕЕР ЕкШ§Иі:ЯћЯЂЖЉдФеп!

ЯТЭМеЙЪОСЫЦЕЕР channel1 , вдМАЖЉдФетИіЦЕЕРЕФШ§ИіПЭЛЇЖЫ ЁЊЁЊ client2 ЁЂ client5 КЭ client1 жЎМфЕФЙиЯЕ:

ЕБгааТЯћЯЂЭЈЙ§ PUBLISH УќСюЗЂЫЭИјЦЕЕР channel1 ЪБ,етИіЯћЯЂОЭЛсБЛЗЂЫЭИјЖЉдФЫќЕФШ§ИіПЭЛЇЖЫ:

УќСю
| УќСю | УшЪі |
|---|---|
| PSUBSCRIBE pattern [patternЁ] | ЖЉдФвЛИіЛђЖрИіЗћКЯИјЖЈФЃЪНЕФЦЕЕРЁЃ |
| PUNSUBSCRIBE pattern [patternЁ] | ЭЫЖЉвЛИіЛђЖрИіЗћКЯИјЖЈФЃЪНЕФЦЕЕРЁЃ |
| PUBSUB subcommand [argument[argument]] | ВщПДЖЉдФгыЗЂВМЯЕЭГзДЬЌЁЃ |
| PUBLISH channel message | ЯђжИЖЈЦЕЕРЗЂВМЯћЯЂ |
| SUBSCRIBE channel [channelЁ] | ЖЉдФИјЖЈЕФвЛИіЛђЖрИіЦЕЕРЁЃ |
| UNSUBSCRIBE channel [channelЁ] | ЭЫЖЉвЛИіЛђЖрИіЦЕЕР |
------------ЖЉдФЖЫ----------------------
127.0.0.1:6379> SUBSCRIBE sakura # ЖЉдФsakuraЦЕЕР
Reading messages... (press Ctrl-C to quit) # ЕШД§НгЪеЯћЯЂ
1) "subscribe" # ЖЉдФГЩЙІЕФЯћЯЂ
2) "sakura"
3) (integer) 1
1) "message" # НгЪеЕНРДздsakuraЦЕЕРЕФЯћЯЂ "hello world"
2) "sakura"
3) "hello world"
1) "message" # НгЪеЕНРДздsakuraЦЕЕРЕФЯћЯЂ "hello i am sakura"
2) "sakura"
3) "hello i am sakura"
--------------ЯћЯЂЗЂВМЖЫ-------------------
127.0.0.1:6379> PUBLISH sakura "hello world" # ЗЂВМЯћЯЂЕНsakuraЦЕЕР
(integer) 1
127.0.0.1:6379> PUBLISH sakura "hello i am sakura" # ЗЂВМЯћЯЂ
(integer) 1
-----------------ВщПДЛюдОЕФЦЕЕР------------
127.0.0.1:6379> PUBSUB channels
1) "sakura"
дРэ
УПИі Redis ЗўЮёЦїНјГЬЖМЮЌГжзХвЛИіБэЪОЗўЮёЦїзДЬЌЕФ redis.h/redisServer НсЙЙ, НсЙЙЕФ pubsub_channels ЪєадЪЧвЛИізжЕф,етИізжЕфОЭгУгкБЃДцЖЉдФЦЕЕРЕФаХЯЂ,Цфжа,зжЕфЕФМќЮЊе§дкБЛЖЉдФЕФЦЕЕР, ЖјзжЕфЕФжЕдђЪЧвЛИіСДБэ, СДБэжаБЃДцСЫЫљгаЖЉдФетИіЦЕЕРЕФПЭЛЇЖЫЁЃ

ПЭЛЇЖЫЖЉдФ,ОЭБЛСДНгЕНЖдгІЦЕЕРЕФСДБэЕФЮВВП,ЭЫЖЉдђОЭЪЧНЋПЭЛЇЖЫНкЕуДгСДБэжавЦГ§ЁЃ
ШБЕу
- ШчЙћвЛИіПЭЛЇЖЫЖЉдФСЫЦЕЕР,ЕЋздМКЖСШЁЯћЯЂЕФЫйЖШШДВЛЙЛПьЕФЛА,ФЧУДВЛЖЯЛ§бЙЕФЯћЯЂЛсЪЙredisЪфГіЛКГхЧјЕФЬхЛ§БфЕУдНРДдНДѓ,етПЩФмЪЙЕУredisБОЩэЕФЫйЖШБфТ§,ЩѕжСжБНгБРРЃЁЃ
- етКЭЪ§ОнДЋЪфПЩППадгаЙи,ШчЙћдкЖЉдФЗНЖЯЯп,ФЧУДЫћНЋЛсЖЊЪЇЫљгадкЖЬЯпЦкМфЗЂВМепЗЂВМЕФЯћЯЂЁЃ
гІгУ
- ЯћЯЂЖЉдФ:ЙЋжкКХЖЉдФ,ЮЂВЉЙизЂЕШЕШ(Ц№ЪМИќЖрЪЧЪЙгУЯћЯЂЖгСаРДНјааЪЕЯж)
- ЖрШЫдкЯпСФЬьЪвЁЃ
етБпЯћЯЂЖгСаЕФЙІФмЯрБШMQжЎРрЕФОЭВюКмЖрСЫ,ЫљвдЩдЮЂИДдгЕФГЁОА,ЮвУЧОЭЛсЪЙгУЯћЯЂжаМфМўMQДІРэЁЃ
жїДгИДжЦгыМЏШКДюНЈ
ЛљДЁИХФю
жїДгИДжЦ,ЪЧжИНЋвЛЬЈRedisЗўЮёЦїЕФЪ§Он,ИДжЦЕНЦфЫћЕФRedisЗўЮёЦїЁЃЧАепГЦЮЊжїНкЕу(Master/Leader),КѓепГЦЮЊДгНкЕу(Slave/Follower), Ъ§ОнЕФИДжЦЪЧЕЅЯђЕФ!жЛФмгЩжїНкЕуИДжЦЕНДгНкЕу(жїНкЕувдаДЮЊжїЁЂДгНкЕувдЖСЮЊжї)ЁЃ
ФЌШЯЧщПіЯТ,УПЬЈRedisЗўЮёЦїЖМЪЧжїНкЕу,вЛИіжїНкЕуПЩвдга0ИіЛђепЖрИіДгНкЕу,ЕЋУПИіДгНкЕужЛФмгЩвЛИіжїНкЕуЁЃЭЈГЃЧщПіЯТжїЛњгУгкаДЪ§Он,ДгЛњгУгкЖСШЁЪ§Он,вђЮЊецЪЕЧщПіЯТЖСШЁЕФЧыЧѓЪ§СПдЖдЖИпгкаДШыЕФЧыЧѓЪ§СП
МЏШКзїгУ
- Ъ§ОнШпгр:жїДгИДжЦЪЕЯжСЫЪ§ОнЕФШШБИЗн,ЪЧГжОУЛЏжЎЭтЕФвЛжжЪ§ОнШпгрЕФЗНЪНЁЃ
- ЙЪеЯЛжИД:ЕБжїНкЕуЙЪеЯЪБ,ДгНкЕуПЩвдднЪБЬцДњжїНкЕуЬсЙЉЗўЮё,ЪЧвЛжжЗўЮёШпгрЕФЗНЪН
- ИКдиОљКт:дкжїДгИДжЦЕФЛљДЁЩЯ,ХфКЯЖСаДЗжРы,гЩжїНкЕуНјаааДВйзї,ДгНкЕуНјааЖСВйзї,ЗжЕЃЗўЮёЦїЕФИКди;гШЦфЪЧдкЖСЖраДЩйЕФГЁОАЯТ,ЭЈЙ§ЖрИіДгНкЕуЗжЕЃИКди,ЬсИпВЂЗЂСПЁЃ
- ИпПЩгУЛљЪЏ:жїДгИДжЦЛЙЪЧЩкБјКЭМЏШКФмЙЛЪЕЪЉЕФЛљДЁЁЃ
ЮЊЪВУДЪЙгУМЏШК
- ЕЅЬЈЗўЮёЦїФбвдИКдиДѓСПЕФЧыЧѓ
- ЕЅЬЈЗўЮёЦїЙЪеЯТЪИп,ЯЕЭГБРЛЕИХТЪДѓ
- ЕЅЬЈЗўЮёЦїФкДцШнСПгаЯоЁЃ
ЛЗОГХфжУ
ВщПДЕБЧАПтЕФаХЯЂ:info replication
127.0.0.1:6379> info replication
# Replication
role:master # НЧЩЋ
connected_slaves:0 # ДгЛњЪ§СП
master_replid:3b54deef5b7b7b7f7dd8acefa23be48879b4fcff
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
МШШЛашвЊЦєЖЏЖрИіЗўЮё,ОЭашвЊЖрИіХфжУЮФМўЁЃУПИіХфжУЮФМўЖдгІаоИФвдЯТаХЯЂ:
- ЖЫПкКХ:
port - pidЮФМўУћ:
pidfile - ШежОЮФМўУћ:
logfile - rdbЮФМўУћ:
dbfilename
ЦєЖЏЕЅЛњЖрЗўЮёМЏШК:
ps -ef | grep redis ВщПДЕБЧАЦєЖЏЕФЗўЮёНјГЬ,ПЩвдПДЕНМЏШКДюНЈЭъБЯ:

вЛжїЖўДгХфжУ
ФЌШЯЧщПіЯТ,УПЬЈRedisЗўЮёЦїЖМЪЧжїНкЕу,вђДЫЮвУЧвЛАуЧщПіЯТжЛгУХфжУДгЛњОЭКУСЫ!
ШЯРЯДѓ!вЛжї(79)ЖўДг(80,81)
ЪЙгУSLAVEOF host portУќСюОЭПЩвдЮЊДгЛњХфжУжїЛњСЫЁЃ


ШЛКѓжїЛњЩЯвВФмПДЕНДгЛњЕФзДЬЌ:

ЮвУЧетРяЪЧЪЙгУУќСюДюНЈ,ЪЧднЪБЕФ,ецЪЕПЊЗЂжагІИУдкДгЛњЕФХфжУЮФМўжаНјааХфжУ,етбљЕФЛАЪЧгРОУЕФ

ЪЙгУЙцдђ??
- ДгЛњжЛФмЖС,ВЛФмаД,жїЛњПЩЖСПЩаДЕЋЪЧЖргУгкаДЁЃжїЛњаДШыЕФЪ§ОндкЫљгаДгЛњжаОљФмЙЛЖСШЁ!
##################################ДгЛњВйзї#####################################
127.0.0.1:6381> set name sakura # ДгЛњ6381аДШыЪЇАм
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380> set name sakura # ДгЛњ6380аДШыЪЇАм
(error) READONLY You can't write against a read only replica.
##################################жїЛњВйзї#####################################
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> get name
"sakura"
-
ЕБжїЛњЖЯЕчхДЛњКѓ,ФЌШЯЧщПіЯТДгЛњЕФНЧЩЋВЛЛсЗЂЩњБфЛЏ ,МЏШКжажЛЪЧЪЇШЅСЫаДВйзї,ЕБжїЛњЛжИДвдКѓ,гжЛсСЌНгЩЯДгЛњЛжИДдзДЁЃ
-
ЕБДгЛњЖЯЕчхДЛњКѓ,ШєВЛЪЧЪЙгУХфжУЮФМўХфжУЕФДгЛњ,дйДЮЦєЖЏКѓзїЮЊжїЛњЪЧЮоЗЈЛёШЁжЎЧАзїЮЊДгЛњЪБЕФЪ§ОнЕФ,ШєДЫЪБжиаТХфжУЮЊДгЛњ,гжПЩвдЛёШЁЕНжїЛњЕФЫљгаЪ§ОнЁЃетРяОЭвЊЬсЕНвЛИіИДжЦдРэЁЃ
-
ЕкЖўЬѕжаЬсЕН,ФЌШЯЧщПіЯТ,жїЛњЙЪеЯКѓ,ВЛЛсГіЯжаТЕФжїЛњ,гаСНжжЗНЪНПЩвдВњЩњаТЕФжїЛњ:
- ДгЛњЪжЖЏжДааУќСю
slaveof no one,етбљжДаавдКѓДгЛњЛсЖРСЂГіРДГЩЮЊвЛИіжїЛњ - ЪЙгУЩкБјФЃЪН(здЖЏбЁОй)
- ДгЛњЪжЖЏжДааУќСю
ШчЙћжїЛњЖЯПЊСЫСЌНг,ЮвУЧПЩвдЪЙгУSLAVEOF no oneШУздМКБфГЩжїЛњ!ЦфЫћЕФНкЕуОЭПЩвдЪжЖЏСЌНгЕНзюаТЕФжїНкЕу(ЪжЖЏ)!ШчЙћетИіЪБКђРЯДѓаоИДСЫ,ФЧУДОЭФмжиаТСЌНг!
ИДжЦдРэ
SlaveЦєЖЏГЩЙІСЌНгЕН masterКѓЛсЗЂЫЭвЛИіsyncЭЌВНУќСю
MasterНгЪеЕНИУУќСюКѓ,ЦєЖЏКѓЬЈЕФДцХЬНјГЬ,ЭЌЪБЪжЛњЫљгаНгЪеЕНЕФгУгкаоИФЪ§ОнМЏУќСю,дкКѓЬЈНјГЬжДааЭъБЯКѓ,masterНЋДЋЫЭећИіЪ§ОнЮФМўЕНSlaveжа,ВЂЭъвЛДЮЭъШЋЭЌВН
ШЋСПИДжЦ:SlaveЗўЮёдкНгЪеЕНЪ§ОнПтЮФМўКѓ,НЋЦфДцХЬВЂМгдиЕНФкДцжа,ГЃГіЯждкгыжїЛњГЩЙІСЌНгЪБЁЃ
діСПИДжЦ:MasterМЬајНЋЫљгаЪеМЏЕНЕФаоИФУќСювРДЮДЋЫЭИјSlave,ЭъГЩЭЌВН,ГЃГіЯждкжїЛњжДаааоИФУќСюКѓЁЃ
жЛвЊЪЧжиаДСЌНгmaster,ШЋСПИДжЦОЭЛсздЖЏжДаа!
ЩкБјФЃЪН
ИХФю
дкжїДгФЃЪНжа,жїЛњГіЯжхДЛњЕФЧщПіЛсЕМжТМЏШКЮоЗЈжДаааДВйзї,Й§ШЅашвЊЪжЖЏИќИФДгЛњЕФХфжУЪЙЦфГЩЮЊаТЕФжїЛњ,етбљВЛНіТщЗГЧвШнвзГіДэ,ЭЈГЃЮЊСЫздЖЏМрПижїЛњдЫааЧщПігыжїЛњхДЛњЪБЪЕЯжжїДгЧаЛЛ,ЛсХфжУЩкБјНјГЬМрЪгжїЛњ,ГЩЮЊЩкБјФЃЪНЁЃ

етРяЕФЩкБјгаСНИізїгУ
- ЭЈЙ§ЗЂЫЭУќСю,ШУRedisЗўЮёЦїЗЕЛиМрПиЦфдЫаазДЬЌ,АќРЈжїЗўЮёЦїКЭДгЗўЮёЦїЁЃ
- ЕБЩкБјМрВтЕНmasterхДЛњ,ЛсздЖЏНЋslaveЧаЛЛГЩmaster,ШЛКѓЭЈЙ§ЗЂВМЖЉдФФЃЪНЭЈжЊЦфЫћЕФДгЗўЮёЦї,аоИФХфжУЮФМў,ШУЫќУЧЧаЛЛжїЛњЁЃ
ШЛЖјвЛИіЩкБјНјГЬЖдRedisЗўЮёЦїНјааМрПи,ПЩФмЛсГіЯжЮЪЬт,ЮЊДЫ,ЮвУЧПЩвдЪЙгУЖрИіЩкБјНјааМрПиЁЃИїИіЩкБјжЎМфЛЙЛсНјааМрПи,етбљОЭаЮГЩСЫ**ЖрЩкБјФЃЪН**ЁЃ

ШчЙћФГвЛИіЩкБјМрВтЕНжїЛњхДЛњ,ДЫЪБИУЩкБјВЛЛсСЂМДжДаажїДгЧаЛЛЖЏзї,ДЫЪБНіНіЪЧЩкБј1жїЙлШЯЮЊжїЛњЮоЗЈЪЙгУ,етИіЯжЯѓГЩЮЊжїЙлЯТЯпЁЃШчЙћЖрИіЩкБјОљМрВтЕНжїЛњЮоЗЈЪЙгУЪБ,ЩкБјжЎМфЛсНјаавЛДЮЭЖЦБ,ЭЖЦБЛсИљОнвЛЖЈЕФЫуЗЈОіЖЈГіШУФФвЛИіДгЛњГЩЮЊаТЕФжїЛњ,ВЂНјааfailover(ЙЪеЯзЊвЦ)Вйзї,ВЂЧвУПИіЩкБјЛсздЖЏаоИФЦфМрЪгЗўЮёЦїЮЊаТжїЛњ,ДЫЙ§ГЬГЩЮЊПЭЙлЯТЯпЁЃ
ЪЕЯжЩкБјФЃЪН
УПвЛИіЩкБјЦфЪЕЪЧвЛИіredisЗўЮёНјГЬ,ЦєЖЏЪБвВашвЊИјЖЈЦфХфжУЮФМў,ЩкБјФЃЪНЕФХфжУЮФМўЪЧsentinel.conf
1ЁЂЩкБјФЃЪНХфжУЮФМў
# sentinel monitor БЛМрПиЕФУћГЦ(ШЮвт) host port 1
sentinel monitor myredis 127.0.0.1 6379 1
КѓУцЕФетИіЪ§зж1,ДњБэжїЛњЙвСЫ,slaveЭЖЦБПДШУЫНгЬцГЩЮЊжїЛњ,ЦБЪ§зюЖрЕФ,ОЭЛсГЩЮЊжїЛњ!
2ЁЂЦєЖЏЩкБј
redis-sentinel xxx/sentinel.conf # ГЩЙІЦєЖЏЩкБјФЃЪН
reids-sentinelЭЌбљЪЧвЛИіПЩжДааЗўЮё

ПЩвдПДЕНСЌНгГЩЙІ!

ДЫЪБЩкБјМрЪгзХЮвУЧЕФжїЛњ6379,ЕБЮвУЧЖЯПЊжїЛњКѓ:

ЩкБјФЃЪНгХШБЕу
гХЕу:
- ЩкБјМЏШК,ЛљгкжїДгИДжЦФЃЪН,ЫљгажїДгИДжЦЕФгХЕу,ЫќЖМга
- жїДгПЩвдЧаЛЛ,ЙЪеЯПЩвдзЊвЦ,ЯЕЭГЕФПЩгУадИќКУ
- ЩкБјФЃЪНЪЧжїДгФЃЪНЕФЩ§МЖ,ЪжЖЏЕНздЖЏ,ИќМгНЁзГ
ШБЕу:
- RedisВЛКУдкЯпРЉШн,МЏШКШнСПвЛЕЉДяЕНЩЯЯо,дкЯпРЉШнОЭЪЎЗжТщЗГ
- ЪЕЯжЩкБјФЃЪНЕФХфжУЦфЪЕЪЧКмТщЗГЕФ,РяУцгаКмЖрХфжУЯю
ЩкБјФЃЪНЕФШЋВПХфжУ
ЭъећЕФЩкБјФЃЪНХфжУЮФМў sentinel.conf
# Example sentinel.conf
# ЩкБјsentinelЪЕР§дЫааЕФЖЫПк ФЌШЯ26379
port 26379
# ЩкБјsentinelЕФЙЄзїФПТМ
dir /tmp
# ЩкБјsentinelМрПиЕФredisжїНкЕуЕФ ip port
# master-name ПЩвдздМКУќУћЕФжїНкЕуУћзж жЛФмгЩзжФИA-zЁЂЪ§зж0-9 ЁЂетШ§ИізжЗћ".-_"зщГЩЁЃ
# quorum ЕБетаЉquorumИіЪ§sentinelЩкБјШЯЮЊmasterжїНкЕуЪЇСЊ ФЧУДетЪБ ПЭЙлЩЯШЯЮЊжїНкЕуЪЇСЊСЫ
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# ЕБдкRedisЪЕР§жаПЊЦєСЫrequirepass foobared ЪкШЈУмТы етбљЫљгаСЌНгRedisЪЕР§ЕФПЭЛЇЖЫЖМвЊЬсЙЉУмТы
# ЩшжУЩкБјsentinel СЌНгжїДгЕФУмТы зЂвтБиаыЮЊжїДгЩшжУвЛбљЕФбщжЄУмТы
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# жИЖЈЖрЩйКСУыжЎКѓ жїНкЕуУЛгагІД№ЩкБјsentinel ДЫЪБ ЩкБјжїЙлЩЯШЯЮЊжїНкЕуЯТЯп ФЌШЯ30Уы
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# етИіХфжУЯюжИЖЈСЫдкЗЂЩњfailoverжїБИЧаЛЛЪБзюЖрПЩвдгаЖрЩйИіslaveЭЌЪБЖдаТЕФmasterНјаа ЭЌВН,
# етИіЪ§зждНаЁ,ЭъГЩfailoverЫљашЕФЪБМфОЭдНГЄ,
# ЕЋЪЧШчЙћетИіЪ§зждНДѓ,ОЭвтЮЖзХдН ЖрЕФslaveвђЮЊreplicationЖјВЛПЩгУЁЃ
# ПЩвдЭЈЙ§НЋетИіжЕЩшЮЊ 1 РДБЃжЄУПДЮжЛгавЛИіslave ДІгкВЛФмДІРэУќСюЧыЧѓЕФзДЬЌЁЃ
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# ЙЪеЯзЊвЦЕФГЌЪБЪБМф failover-timeout ПЩвдгУдквдЯТетаЉЗНУц:
#1. ЭЌвЛИіsentinelЖдЭЌвЛИіmasterСНДЮfailoverжЎМфЕФМфИєЪБМфЁЃ
#2. ЕБвЛИіslaveДгвЛИіДэЮѓЕФmasterФЧРяЭЌВНЪ§ОнПЊЪММЦЫуЪБМфЁЃжБЕНslaveБЛОРе§ЮЊЯђе§ШЗЕФmasterФЧРяЭЌВНЪ§ОнЪБЁЃ
#3.ЕБЯывЊШЁЯћвЛИіе§дкНјааЕФfailoverЫљашвЊЕФЪБМфЁЃ
#4.ЕБНјааfailoverЪБ,ХфжУЫљгаslavesжИЯђаТЕФmasterЫљашЕФзюДѓЪБМфЁЃВЛЙ§,МДЪЙЙ§СЫетИіГЌЪБ,slavesвРШЛЛсБЛе§ШЗХфжУЮЊжИЯђmaster,ЕЋЪЧОЭВЛАДparallel-syncsЫљХфжУЕФЙцдђРДСЫ
# ФЌШЯШ§Зжжг
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#ХфжУЕБФГвЛЪТМўЗЂЩњЪБЫљашвЊжДааЕФНХБО,ПЩвдЭЈЙ§НХБОРДЭЈжЊЙмРэдБ,Р§ШчЕБЯЕЭГдЫааВЛе§ГЃЪБЗЂгЪМўЭЈжЊЯрЙиШЫдБЁЃ
#ЖдгкНХБОЕФдЫааНсЙћгавдЯТЙцдђ:
#ШєНХБОжДааКѓЗЕЛи1,ФЧУДИУНХБОЩдКѓНЋЛсБЛдйДЮжДаа,жиИДДЮЪ§ФПЧАФЌШЯЮЊ10
#ШєНХБОжДааКѓЗЕЛи2,ЛђепБШ2ИќИпЕФвЛИіЗЕЛижЕ,НХБОНЋВЛЛсжиИДжДааЁЃ
#ШчЙћНХБОдкжДааЙ§ГЬжагЩгкЪеЕНЯЕЭГжаЖЯаХКХБЛжежЙСЫ,дђЭЌЗЕЛижЕЮЊ1ЪБЕФааЮЊЯрЭЌЁЃ
#вЛИіНХБОЕФзюДѓжДааЪБМфЮЊ60s,ШчЙћГЌЙ§етИіЪБМф,НХБОНЋЛсБЛвЛИіSIGKILLаХКХжежЙ,жЎКѓжиаТжДааЁЃ
#ЭЈжЊаЭНХБО:ЕБsentinelгаШЮКЮОЏИцМЖБ№ЕФЪТМўЗЂЩњЪБ(БШШчЫЕredisЪЕР§ЕФжїЙлЪЇаЇКЭПЭЙлЪЇаЇЕШЕШ),НЋЛсШЅЕїгУетИіНХБО,
#етЪБетИіНХБОгІИУЭЈЙ§гЪМў,SMSЕШЗНЪНШЅЭЈжЊЯЕЭГЙмРэдБЙигкЯЕЭГВЛе§ГЃдЫааЕФаХЯЂЁЃЕїгУИУНХБОЪБ,НЋДЋИјНХБОСНИіВЮЪ§,
#вЛИіЪЧЪТМўЕФРраЭ,
#вЛИіЪЧЪТМўЕФУшЪіЁЃ
#ШчЙћsentinel.confХфжУЮФМўжаХфжУСЫетИіНХБОТЗОЖ,ФЧУДБиаыБЃжЄетИіНХБОДцдкгкетИіТЗОЖ,ВЂЧвЪЧПЩжДааЕФ,ЗёдђsentinelЮоЗЈе§ГЃЦєЖЏГЩЙІЁЃ
#ЭЈжЊНХБО
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# ПЭЛЇЖЫжиаТХфжУжїНкЕуВЮЪ§НХБО
# ЕБвЛИіmasterгЩгкfailoverЖјЗЂЩњИФБфЪБ,етИіНХБОНЋЛсБЛЕїгУ,ЭЈжЊЯрЙиЕФПЭЛЇЖЫЙигкmasterЕижЗвбОЗЂЩњИФБфЕФаХЯЂЁЃ
# вдЯТВЮЪ§НЋЛсдкЕїгУНХБОЪБДЋИјНХБО:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# ФПЧА<state>змЪЧЁАfailoverЁБ,
# <role>ЪЧЁАleaderЁБЛђепЁАobserverЁБжаЕФвЛИіЁЃ
# ВЮЪ§ from-ip, from-port, to-ip, to-portЪЧгУРДКЭОЩЕФmasterКЭаТЕФmaster(МДОЩЕФslave)ЭЈаХЕФ
# етИіНХБОгІИУЪЧЭЈгУЕФ,ФмБЛЖрДЮЕїгУ,ВЛЪЧеыЖдадЕФЁЃ
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
ЛКДцДЉЭИгыбЉБР
ЗўЮёЕФИпПЩгУЮЪЬт
RedisЛКДцЕФЪЙгУ,МЋДѓЕФЬсЩ§СЫгІгУГЬађЕФадФмКЭаЇТЪ,ЬиБ№ЪЧЪ§ОнВщбЏЗНУцЁЃЕЋЭЌЪБ,ЫќвВДјРДСЫвЛаЉЮЪЬтЁЃЦфжа,зювЊКІЕФЮЪЬт,ОЭЪЧЪ§ОнЕФвЛжТадЮЪЬт(ЪТЮёдкдЫааЪБВЛФмБЃжЄдзгад),ДгбЯИёвтвхЩЯНВ,етИіЮЪЬтЮоНтЁЃШчЙћЖдЪ§ОнЕФвЛжТадвЊЧѓКмИп,ФЧУДОЭВЛФмЪЙгУЛКДцЁЃ
СэЭтЕФвЛаЉЕфаЭЮЪЬтОЭЪЧ,ЛКДцДЉЭИЁЂЛКДцбЉБРКЭЛКДцЛїДЉЁЃФПЧА,вЕНчвВЖМгаБШНЯСїааЕФНтОіЗНАИЁЃ

ЛКДцДЉЭИ
ИХФю
ЛКДцДЉЭИЕФИХФюКмМђЕЅ,гУЛЇЯывЊВщбЏвЛИіЪ§Он,ЗЂЯжredisФкДцЪ§ОнПтУЛга,вВОЭЪЧЛКДцУЛгаУќжа,гкЪЧЯђГжОУВуЪ§ОнПтВщбЏЁЃЗЂЯжвВУЛга,гкЪЧБОДЮВщбЏЪЇАмЁЃЕБгУЛЇКмЖрЕФЪБКђ,ЛКДцЖМУЛгаУќжа(УыЩБ!),гкЪЧЖМШЅЧыЧѓСЫГжОУВуЪ§ОнПтЁЃетЛсИјГжОУВуЪ§ОнПтдьГЩКмДѓЕФбЙСІ,етЪБКђОЭЯрЕБгкГіЯжСЫЛКДцДЉЭИЁЃКщЫЎЙЅЛїЁЃЪ§ОнПтвВВщВЛЕНОЭУЛгаЛКДц,ОЭЛсвЛжБгыЪ§ОнПтЗУЮЪЁЃ
НтОіЗНАИ
1.ВМТЁЙ§ТЫЦї
ЖдЫљгаПЩФмВщбЏЕФВЮЪ§вдHashЕФаЮЪНДцДЂ,вдБуПьЫйШЗЖЈЪЧЗёДцдкетИіжЕ,дкПижЦВуЯШНјааРЙНиаЃбщ,аЃбщВЛЭЈЙ§жБНгДђЛи,МѕЧсСЫДцДЂЯЕЭГЕФбЙСІЁЃ

2.ЛКДцПеЖдЯѓ
вЛДЮЧыЧѓШєдкЛКДцКЭЪ§ОнПтжаЖМУЛевЕН,ОЭдкЛКДцжаЗНвЛИіПеЖдЯѓгУгкДІРэКѓајетИіЧыЧѓЁЃ

1ЁЂШчЙћПежЕФмЙЛБЛЛКДцЦ№РД,етОЭвтЮЖзХЛКДцашвЊИќЖрЕФПеМфДцДЂИќЖрЕФМќ,вђЮЊетЕБжаПЩФмЛсгаКмЖрЕФПежЕЕФМќ;
2ЁЂМДЪЙЖдПежЕЩшжУСЫЙ§ЦкЪБМф,ЛЙЪЧЛсДцдкЛКДцВуКЭДцДЂВуЕФЪ§ОнЛсгавЛЖЮЪБМфДАПкЕФВЛвЛжТ,етЖдгкашвЊБЃГжвЛжТадЕФвЕЮёЛсгагАЯь
ЛКДцЛїДЉ(СПЬЋДѓ ЛКДцЙ§Цк)
ИХЪі
ЯрНЯгкЛКДцДЉЭИ,ЛКДцЛїДЉЕФФПЕФадИќЧП,вЛИіДцдкЕФkey,дкЛКДцЙ§ЦкЕФвЛПЬ,ЭЌЪБгаДѓСПЕФЧыЧѓ,етаЉЧыЧѓЖМЛсЛїДЉЕНDB,дьГЩЫВЪБDBЧыЧѓСПДѓЁЂбЙСІжшдіЁЃетОЭЪЧЛКДцБЛЛїДЉ,жЛЪЧеыЖдЦфжаФГИіkeyЕФЛКДцВЛПЩгУЖјЕМжТЛїДЉ,ЕЋЪЧЦфЫћЕФkeyвРШЛПЩвдЪЙгУЛКДцЯьгІЁЃ
БШШчШШЫбХХааЩЯ,вЛИіШШЕуаТЮХБЛЭЌЪБДѓСПЗУЮЪОЭПЩФмЕМжТЛКДцЛїДЉЁЃ
НтОіЗНАИ
1.ЩшжУШШЕуЪ§ОнгРВЛЙ§Цк
етбљОЭВЛЛсГіЯжШШЕуЪ§ОнЙ§ЦкЕФЧщПі,ЕЋЪЧЕБRedisФкДцПеМфТњЕФЪБКђвВЛсЧхРэВПЗжЪ§Он,ЖјЧвДЫжжЗНАИЛсеМгУПеМф,вЛЕЉШШЕуЪ§ОнЖрСЫЦ№РД,ОЭЛсеМгУВПЗжПеМфЁЃ
2.МгЛЅГтЫј(ЗжВМЪНЫј)
дкЗУЮЪkeyжЎЧА,ВЩгУSETNX(set if not exists)РДЩшжУСэвЛИіЖЬЦкkeyРДЫјзЁЕБЧАkeyЕФЗУЮЪ,ЗУЮЪНсЪјдйЩОГ§ИУЖЬЦкkeyЁЃБЃжЄЭЌЪБПЬжЛгавЛИіЯпГЬЗУЮЪЁЃетбљЖдЫјЕФвЊЧѓОЭЪЎЗжИпЁЃ
ЛКДцбЉБР
ЛКДцИХФю
ДѓСПЕФkeyЩшжУСЫЯрЭЌЕФЙ§ЦкЪБМф,ЕМжТдкЛКДцдкЭЌвЛЪБПЬШЋВПЪЇаЇ,дьГЩЫВЪБDBЧыЧѓСПДѓЁЂбЙСІжшді,в§Ц№бЉБРЁЃ

НтОіЗНАИ
redisИпПЩгУ
етИіЫМЯыЕФКЌвхЪЧ,МШШЛredisгаПЩФмЙвЕє,ФЧЮвЖрдіЩшМИЬЈredis,етбљвЛЬЈЙвЕєжЎКѓЦфЫћЕФЛЙПЩвдМЬајЙЄзї,ЦфЪЕОЭЪЧДюНЈЕФМЏШК
ЯоСїНЕМЖ
етИіНтОіЗНАИЕФЫМЯыЪЧ,дкЛКДцЪЇаЇКѓ,ЭЈЙ§МгЫјЛђепЖгСаРДПижЦЖСЪ§ОнПтаДЛКДцЕФЯпГЬЪ§СПЁЃБШШчЖдФГИіkeyжЛдЪаэвЛИіЯпГЬВщбЏЪ§ОнКЭаДЛКДц,ЦфЫћЯпГЬЕШД§ЁЃ
Ъ§ОндЄШШ
Ъ§ОнМгШШЕФКЌвхОЭЪЧдке§ЪНВПЪ№жЎЧА,ЮвЯШАбПЩФмЕФЪ§ОнЯШдЄЯШЗУЮЪвЛБщ,етбљВПЗжПЩФмДѓСПЗУЮЪЕФЪ§ОнОЭЛсМгдиЕНЛКДцжаЁЃдкМДНЋЗЂЩњДѓВЂЗЂЗУЮЪЧАЪжЖЏДЅЗЂМгдиЛКДцВЛЭЌЕФkey,ЩшжУВЛЭЌЕФЙ§ЦкЪБМф,ШУЛКДцЪЇаЇЕФЪБМфЕуОЁСПОљдШЁЃ