ФПТМ
RedisФкДцТњСЫдѕУДАь?дѕУДгХЛЏФкДц?
MySQLРяга2000wЪ§Он,redisжажЛДц20wЕФЪ§Он,ШчКЮБЃжЄredisжаЕФЪ§ОнЖМЪЧШШЕуЪ§Он
redisФкДцЪ§ОнМЏДѓаЁЩЯЩ§ЕНвЛЖЈДѓаЁЕФЪБКђ,ОЭЛсЪЉааЪ§ОнЬдЬВпТдЁЃ
RedisжївЊЯћКФЪВУДЮяРэзЪдД?
ФкДцЁЃ
RedisЕФФкДцгУЭъСЫЛсЗЂЩњЪВУД?
ШчЙћДяЕНЩшжУЕФЩЯЯо,RedisЕФаДУќСюЛсЗЕЛиДэЮѓаХЯЂ(ЕЋЪЧЖСУќСюЛЙПЩвде§ГЃЗЕЛиЁЃ)ЛђепФуПЩвдХфжУФкДцЬдЬЛњжЦ,ЕБRedisДяЕНФкДцЩЯЯоЪБЛсГхЫЂЕєОЩЕФФкШнЁЃ
ЬИЬИЛКДцЪ§ОнЕФЬдЬЛњжЦ
Redis ЛКДцгаФФаЉЬдЬВпТд?
- ВЛНјааЪ§ОнЬдЬЕФВпТд,жЛга noeviction етвЛжжЁЃ
ЛсНјааЬдЬЕФ 7 жжВпТд,ЮвУЧПЩвддйНјвЛВНИљОнЬдЬКђбЁЪ§ОнМЏЕФЗЖЮЇАбЫќУЧЗжГЩСНРр:
- дкЩшжУСЫЙ§ЦкЪБМфЕФЪ§ОнжаНјааЬдЬ,АќРЈ volatile-randomЁЂvolatile-ttlЁЂvolatile-lruЁЂvolatile-lfuЫФжжЁЃ
- дкЫљгаЪ§ОнЗЖЮЇФкНјааЬдЬ,АќРЈ allkeys-lruЁЂallkeys-randomЁЂallkeys-lfuШ§жжЁЃ
| ВпТд | Йцдђ |
|---|---|
| volatile-ttl | дкЩИбЁЪБ,ЛсеыЖдЩшжУСЫЙ§ЦкЪБМфЕФМќжЕЖд,ИљОнЙ§ЦкЪБМфЕФЯШКѓНјааЩОГ§,дНдчЙ§ЦкЕФдНЯШБЛЩОГ§ЁЃ |
| volatile-random | дкЩшжУСЫЙ§ЦкЪБМфЕФМќжЕЖджа,НјааЫцЛњЩОГ§ЁЃ |
| volatile-lru | ЪЙгУ LRU ЫуЗЈЩИбЁЩшжУСЫЙ§ЦкЪБМфЕФМќжЕЖд |
| volatile-lfu | ЪЙгУ LFU ЫуЗЈбЁдёЩшжУСЫЙ§ЦкЪБМфЕФМќжЕЖд |
| ВпТд | Йцдђ |
|---|---|
| allkeys-random | ДгЫљгаМќжЕЖджаЫцЛњбЁдёВЂЩОГ§Ъ§Он; |
| allkeys-lru | ЪЙгУ LRU ЫуЗЈдкЫљгаЪ§ОнжаНјааЩИбЁ |
| vallkeys-lfu | ЪЙгУ LFU ЫуЗЈдкЫљгаЪ§ОнжаНјааЩИбЁ |
ЬИЬИLRUЫуЗЈ
ЪЧАДеезюНќзюЩйЪЙгУЕФддђРДЩИбЁЪ§Он,зюВЛГЃгУЕФЪ§ОнЛсБЛЩИбЁГіРД,ЖјзюНќЦЕЗБЪЙгУЕФЪ§ОнЛсСєдкЛКДцжаЁЃ
ФЧОпЬхЪЧдѕУДЩИбЁЕФФи?LRU ЛсАбЫљгаЕФЪ§ОнзщжЏГЩвЛИіСДБэ,СДБэЕФЭЗКЭЮВЗжБ№БэЪО MRU ЖЫКЭ LRU ЖЫ,ЗжБ№ДњБэзюНќзюГЃЪЙгУЕФЪ§ОнКЭзюНќзюВЛГЃгУЕФЪ§ОнЁЃ
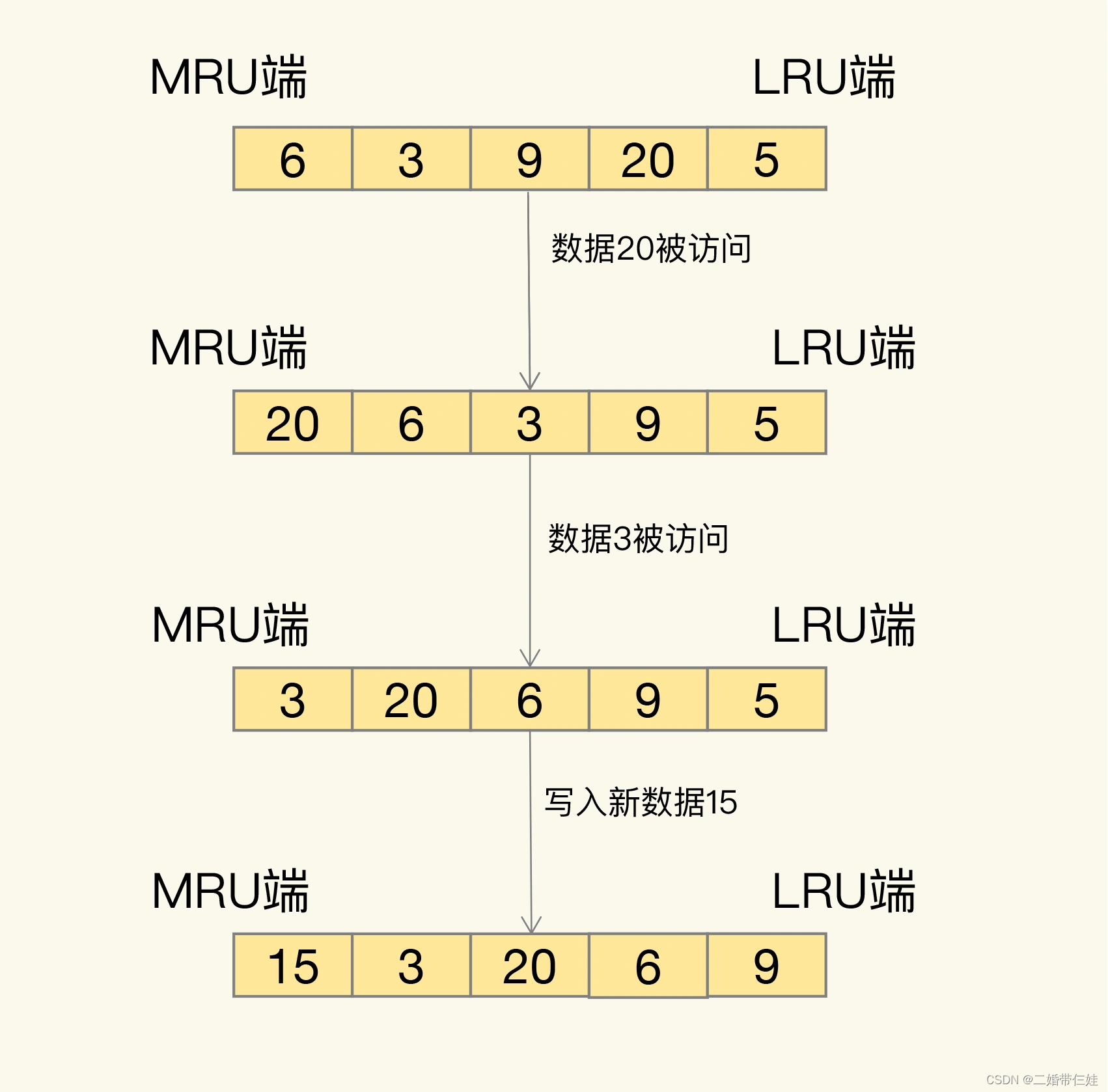
LRU ЫуЗЈБГКѓЕФЯыЗЈЗЧГЃЦгЫи:ЫќШЯЮЊИеИеБЛЗУЮЪЕФЪ§Он,ПЯЖЈЛЙЛсБЛдйДЮЗУЮЪ,ЫљвдОЭАбЫќЗХдк MRU ЖЫ;ГЄОУВЛЗУЮЪЕФЪ§Он,ПЯЖЈОЭВЛЛсдйБЛЗУЮЪСЫ,ЫљвдОЭШУЫќж№НЅКѓвЦЕН LRU ЖЫ,дкЛКДцТњЪБ,ОЭгХЯШЩОГ§ЫќЁЃ
ЮЪЬт:LRU ЫуЗЈдкЪЕМЪЪЕЯжЪБ,ашвЊгУСДБэЙмРэЫљгаЕФЛКДцЪ§Он,етЛсДјРДЖюЭтЕФПеМфПЊЯњЁЃЖјЧв,ЕБгаЪ§ОнБЛЗУЮЪЪБ,ашвЊдкСДБэЩЯАбИУЪ§ОнвЦЖЏЕН MRU ЖЫ,ШчЙћгаДѓСПЪ§ОнБЛЗУЮЪ,ОЭЛсДјРДКмЖрСДБэвЦЖЏВйзї,ЛсКмКФЪБ,НјЖјЛсНЕЕЭ Redis ЛКДцадФмЁЃ
НтОі:
дк Redis жа,LRU ЫуЗЈБЛзіСЫМђЛЏ,вдМѕЧсЪ§ОнЬдЬЖдЛКДцадФмЕФгАЯьЁЃОпЬхРДЫЕ,Redis ФЌШЯЛсМЧТМУПИіЪ§ОнЕФзюНќвЛДЮЗУЮЪЕФЪБМфДС(гЩМќжЕЖдЪ§ОнНсЙЙ RedisObject жаЕФ lru зжЖЮМЧТМ)ЁЃШЛКѓ,Redis дкОіЖЈЬдЬЕФЪ§ОнЪБ,ЕквЛДЮЛсЫцЛњбЁГі N ИіЪ§Он,АбЫќУЧзїЮЊвЛИіКђбЁМЏКЯЁЃНгЯТРД,Redis ЛсБШНЯет N ИіЪ§ОнЕФ lru зжЖЮ,Аб lru зжЖЮжЕзюаЁЕФЪ§ОнДгЛКДцжаЬдЬГіШЅЁЃ
ЕБашвЊдйДЮЬдЬЪ§ОнЪБ,Redis ашвЊЬєбЁЪ§ОнНјШыЕквЛДЮЬдЬЪБДДНЈЕФКђбЁМЏКЯЁЃетЖљЕФЬєбЁБъзМЪЧ:ФмНјШыКђбЁМЏКЯЕФЪ§ОнЕФ lru зжЖЮжЕБиаыаЁгкКђбЁМЏКЯжазюаЁЕФ lru жЕЁЃЕБгааТЪ§ОнНјШыКђбЁЪ§ОнМЏКѓ,ШчЙћКђбЁЪ§ОнМЏжаЕФЪ§ОнИіЪ§ДяЕНСЫ maxmemory-samples,Redis ОЭАбКђбЁЪ§ОнМЏжа lru зжЖЮжЕзюаЁЕФЪ§ОнЬдЬГіШЅЁЃ
ЪЙгУНЈвщ:
- гХЯШЪЙгУ allkeys-lru ВпТдЁЃетбљ,ПЩвдГфЗжРћгУ LRU етвЛОЕфЛКДцЫуЗЈЕФгХЪЦ,АбзюНќзюГЃЗУЮЪЕФЪ§ОнСєдкЛКДцжа,ЬсЩ§гІгУЕФЗУЮЪадФмЁЃШчЙћФуЕФвЕЮёЪ§ОнжагаУїЯдЕФРфШШЪ§ОнЧјЗж,ЮвНЈвщФуЪЙгУ allkeys-lru ВпТдЁЃ
- ШчЙћвЕЮёгІгУжаЕФЪ§ОнЗУЮЪЦЕТЪЯрВюВЛДѓ,УЛгаУїЯдЕФРфШШЪ§ОнЧјЗж,НЈвщЪЙгУ allkeys-random ВпТд,ЫцЛњбЁдёЬдЬЕФЪ§ОнОЭааЁЃ
- ШчЙћФуЕФвЕЮёжагажУЖЅЕФашЧѓ,БШШчжУЖЅаТЮХЁЂжУЖЅЪгЦЕ,ФЧУД,ПЩвдЪЙгУ volatile-lru ВпТд,ЭЌЪБВЛИјетаЉжУЖЅЪ§ОнЩшжУЙ§ЦкЪБМфЁЃетбљвЛРД,етаЉашвЊжУЖЅЕФЪ§ОнвЛжБВЛЛсБЛЩОГ§,ЖјЦфЫћЪ§ОнЛсдкЙ§ЦкЪБИљОн LRU ЙцдђНјааЩИбЁЁЃ
ШчКЮДІРэБЛЬдЬЕФЪ§Он?
вЛЕЉБЛЬдЬЕФЪ§ОнбЁЖЈКѓ,ШчЙћетИіЪ§ОнЪЧИЩОЛЪ§Он,ФЧУДЮвУЧОЭжБНгЩОГ§;ШчЙћетИіЪ§ОнЪЧдрЪ§Он,ЮвУЧашвЊАбЫќаДЛиЪ§ОнПтЁЃ
ФЧдѕУДХаЖЯвЛИіЪ§ОнЕНЕзЪЧИЩОЛЕФЛЙЪЧдрЕФФи?
- ИЩОЛЪ§ОнКЭдрЪ§ОнЕФЧјБ№ОЭдкгк,КЭзюГѕДгКѓЖЫЪ§ОнПтРяЖСШЁЪБЕФжЕЯрБШ,гаУЛгаБЛаоИФЙ§ЁЃИЩОЛЪ§ОнвЛжБУЛгаБЛаоИФ,ЫљвдКѓЖЫЪ§ОнПтРяЕФЪ§ОнвВЪЧзюаТжЕЁЃдкЬцЛЛЪБ,ЫќПЩвдБЛжБНгЩОГ§ЁЃ
- ЖјдрЪ§ОнОЭЪЧдјОБЛаоИФЙ§ЕФ,вбОКЭКѓЖЫЪ§ОнПтжаБЃДцЕФЪ§ОнВЛвЛжТСЫЁЃДЫЪБ,ШчЙћВЛАбдрЪ§ОнаДЛиЕНЪ§ОнПтжа,етИіЪ§ОнЕФзюаТжЕОЭЖЊЪЇСЫ,ОЭЛсгАЯьгІгУЕФе§ГЃЪЙгУЁЃ
МДЪЙЬдЬЕФЪ§ОнЪЧдрЪ§Он,Redis вВВЛЛсАбЫќУЧаДЛиЪ§ОнПтЁЃЫљвд,ЮвУЧдкЪЙгУ Redis ЛКДцЪБ,ШчЙћЪ§ОнБЛаоИФСЫ,ашвЊдкЪ§ОнаоИФЪБОЭНЋЫќаДЛиЪ§ОнПтЁЃЗёдђ,етИідрЪ§ОнБЛЬдЬЪБ,ЛсБЛ Redis ЩОГ§,ЖјЪ§ОнПтРявВУЛгазюаТЕФЪ§ОнСЫЁЃ
RedisдѕУДгХЛЏФкДц?
- 1ЁЂredisObjectЖдЯѓ
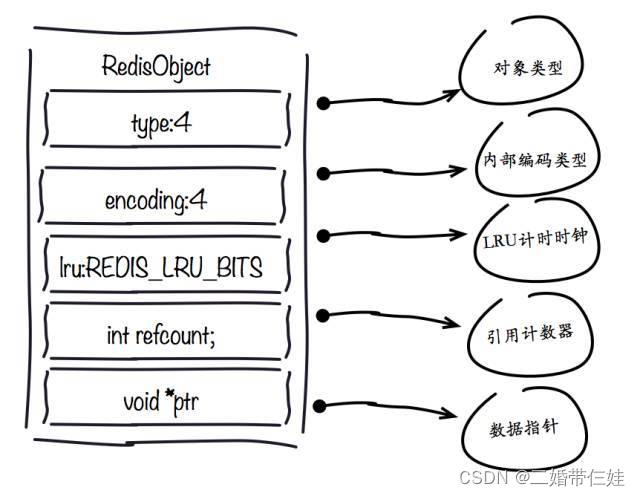
typeзжЖЮ:
РћгУМЏКЯРраЭЪ§Он,вђЮЊЭЈГЃЧщПіЯТКмЖраЁЕФKey-ValueПЩвдгУИќНєДеЕФЗНЪНДцЗХЕНвЛЦ№ЁЃОЁПЩФмЪЙгУЩЂСаБэ(hashes),ЩЂСаБэ(ЪЧЫЕЩЂСаБэРяУцДцДЂЕФЪ§Щй)ЪЙгУЕФФкДцЗЧГЃаЁ,ЫљвдФугІИУОЁПЩФмЕФНЋФуЕФЪ§ОнФЃаЭГщЯѓЕНвЛИіЩЂСаБэРяУцЁЃБШШчФуЕФwebЯЕЭГжагавЛИігУЛЇЖдЯѓ,ВЛвЊЮЊетИігУЛЇЕФУћГЦ,аеЪЯ,гЪЯф,УмТыЩшжУЕЅЖРЕФkey,ЖјЪЧгІИУАбетИігУЛЇЕФЫљгааХЯЂДцДЂЕНвЛеХЩЂСаБэРяУцЁЃ
encodingзжЖЮ:
ВЩгУВЛЭЌЕФБрТыЪЕЯжФкДцеМгУДцдкУїЯдВювь
lruзжЖЮ:
ПЊЗЂЬсЪО:ПЩвдЪЙгУscan + object idletime УќСюХњСПВщбЏФФаЉМќГЄЪБМфЮДБЛЗУЮЪ,евГіГЄЪБМфВЛЗУЮЪЕФМќНјааЧхРэНЕЕЭФкДцеМгУЁЃ
refcountзжЖЮ:
ЕБЖдЯѓЮЊећЪ§ЧвЗЖЮЇдк[0-9999]ЪБ,RedisПЩвдЪЙгУЙВЯэЖдЯѓЕФЗНЪНРДНкЪЁФкДцЁЃ
ptrзжЖЮ :
ПЊЗЂЬсЪО:ИпВЂЗЂаДШыГЁОАжа,дкЬѕМўдЪаэЕФЧщПіЯТНЈвщзжЗћДЎГЄЖШПижЦдк39зжНквдФк,МѕЩйДДНЈredisObjectФкДцЗжХфДЮЪ§ДгЖјЬсИпадФмЁЃ
-
2ЁЂЫѕМѕМќжЕЖдЯѓ
НЕЕЭRedisФкДцЪЙгУзюжБНгЕФЗНЪНОЭЪЧЫѕМѕМќ(key)КЭжЕ(value)ЕФГЄЖШЁЃ
ПЩвдЪЙгУЭЈгУбЙЫѕЫуЗЈбЙЫѕjson,xmlКѓдйДцШыRedis,ДгЖјНЕЕЭФкДцеМгУ -
3ЁЂЙВЯэЖдЯѓГи
ЖдЯѓЙВЯэГижИRedisФкВПЮЌЛЄ[0-9999]ЕФећЪ§ЖдЯѓГиЁЃДДНЈДѓСПЕФећЪ§РраЭredisObjectДцдкФкДцПЊЯњ,УПИіredisObjectФкВПНсЙЙжСЩйеМ16зжНк,ЩѕжСГЌЙ§СЫећЪ§здЩэПеМфЯћКФЁЃЫљвдRedisФкДцЮЌЛЄвЛИі[0-9999]ЕФећЪ§ЖдЯѓГи,гУгкНкдМФкДцЁЃ Г§СЫећЪ§жЕЖдЯѓ,ЦфЫћРраЭШчlist,hash,set,zsetФкВПдЊЫивВПЩвдЪЙгУећЪ§ЖдЯѓГиЁЃвђДЫПЊЗЂжадкТњзуашЧѓЕФЧАЬсЯТ,ОЁСПЪЙгУећЪ§ЖдЯѓвдНкЪЁФкДцЁЃ
ЕБЩшжУmaxmemoryВЂЦєгУLRUЯрЙиЬдЬВпТдШч:volatile-lru,allkeys-lruЪБ,RedisНћжЙЪЙгУЙВЯэЖдЯѓГиЁЃ
ЮЊЪВУДПЊЦєmaxmemoryКЭLRUЬдЬВпТдКѓЖдЯѓГиЮоаЇ?
LRUЫуЗЈашвЊЛёШЁЖдЯѓзюКѓБЛЗУЮЪЪБМф,вдБуЬдЬзюГЄЮДЗУЮЪЪ§Он,УПИіЖдЯѓзюКѓЗУЮЪЪБМфДцДЂдкredisObjectЖдЯѓЕФlruзжЖЮЁЃЖдЯѓЙВЯэвтЮЖзХЖрИів§гУЙВЯэЭЌвЛИіredisObject,етЪБlruзжЖЮвВЛсБЛЙВЯэ,ЕМжТЮоЗЈЛёШЁУПИіЖдЯѓЕФзюКѓЗУЮЪЪБМфЁЃШчЙћУЛгаЩшжУmaxmemory,жБЕНФкДцБЛгУОЁRedisвВВЛЛсДЅЗЂФкДцЛиЪе,ЫљвдЙВЯэЖдЯѓГиПЩвде§ГЃЙЄзїЁЃ
злЩЯЫљЪі,ЙВЯэЖдЯѓГигыmaxmemory+LRUВпТдГхЭЛ,ЪЙгУЪБашвЊзЂвтЁЃ
ЮЊЪВУДжЛгаећЪ§ЖдЯѓГи?
ЪзЯШећЪ§ЖдЯѓГиИДгУЕФМИТЪзюДѓ,ЦфДЮЖдЯѓЙВЯэЕФвЛИіЙиМќВйзїОЭЪЧХаЖЯЯрЕШад,RedisжЎЫљвджЛгаећЪ§ЖдЯѓГи,ЪЧвђЮЊећЪ§БШНЯЫуЗЈЪБМфИДдгЖШЮЊO(1),жЛБЃСєвЛЭђИіећЪ§ЮЊСЫЗРжЙЖдЯѓГиРЫЗбЁЃШчЙћЪЧзжЗћДЎХаЖЯЯрЕШад,ЪБМфИДдгЖШБфЮЊO(n),ЬиБ№ЪЧГЄзжЗћДЎИќЯћКФадФм(ИЁЕуЪ§дкRedisФкВПЪЙгУзжЗћДЎДцДЂ)ЁЃЖдгкИќИДдгЕФЪ§ОнНсЙЙШчhash,listЕШ,ЯрЕШадХаЖЯашвЊO(n2)ЁЃЖдгкЕЅЯпГЬЕФRedisРДЫЕ,етбљЕФПЊЯњЯдШЛВЛКЯРэ,вђДЫRedisжЛБЃСєећЪ§ЙВЯэЖдЯѓГиЁЃ
- 4ЁЂзжЗћДЎгХЛЏ
RedisУЛгаВЩгУдЩњCгябдЕФзжЗћДЎРраЭЖјЪЧздМКЪЕЯжСЫзжЗћДЎНсЙЙ,ФкВПМђЕЅЖЏЬЌзжЗћДЎ,МђГЦSDSЁЃ
зжЗћДЎНсЙЙ:
- ЬиЕу:
O(1)ЪБМфИДдгЖШЛёШЁ:зжЗћДЎГЄЖШ,вбгУГЄЖШ,ЮДгУГЄЖШЁЃ
ПЩгУгкБЃДцзжНкЪ§зщ,жЇГжАВШЋЕФЖўНјжЦЪ§ОнДцДЂЁЃ
ФкВПЪЕЯжПеМфдЄЗжХфЛњжЦ,НЕЕЭФкДцдйЗжХфДЮЪ§ЁЃ
ЖшадЩОГ§ЛњжЦ,зжЗћДЎЫѕМѕКѓЕФПеМфВЛЪЭЗХ,зїЮЊдЄЗжХфПеМфБЃСєЁЃ
дЄЗжХфЛњжЦ:
- ПЊЗЂЬсЪО:ОЁСПМѕЩйзжЗћДЎЦЕЗБаоИФВйзїШчappend,setrange, ИФЮЊжБНгЪЙгУsetаоИФзжЗћДЎ,НЕЕЭдЄЗжХфДјРДЕФФкДцРЫЗбКЭФкДцЫщЦЌЛЏЁЃ
зжЗћДЎжиЙЙ:ЛљгкhashРраЭЕФЖўМЖБрТыЗНЪНЁЃ
-
ЖўМЖБрТыдѕУДгУ?
ЖўМЖБрТыЗНЗЈжаВЩгУЕФ ID ГЄЖШЪЧгаНВОПЕФЁЃ
ЩцМАЕНвЛИіЮЪЬтЈCHash РраЭЕзВуНсЙЙаЁгкЩшЖЈжЕЪБЪЙгУбЙЫѕСаБэ,ДѓгкЩшЖЈжЕЪБЪЙгУЙўЯЃБэЁЃ
вЛЕЉДгбЙЫѕСаБэзЊЮЊСЫЙўЯЃБэ,Hash РраЭЛсвЛжБгУЙўЯЃБэНјааБЃДц,ЖјВЛЛсдйзЊЛибЙЫѕСаБэЁЃ
дкНкЪЁФкДцПеМфЗНУц,ЙўЯЃБэОЭУЛгабЙЫѕСаБэФЧУДИпаЇЁЃЮЊФмГфЗжЪЙгУбЙЫѕСаБэЕФОЋМђФкДцВМОж,вЛАувЊПижЦБЃДцдк Hash жаЕФдЊЫиИіЪ§ЁЃ -
5.БрТыгХЛЏ
ЪЙгУбЙЫѕСаБэziplistБрТыЕФhashРраЭвРШЛБШЪЙгУhashtableБрТыЕФМЏКЯНкЪЁДѓСПФкДцЁЃ -
6.ПижЦkeyЕФЪ§СП
ПЊЗЂЬсЪО:ЪЙгУziplist+hashгХЛЏkeysКѓ,ШчЙћЯыЪЙгУГЌЪБЩОГ§ЙІФм,ПЊЗЂШЫдБПЩвдДцДЂУПИіЖдЯѓаДШыЕФЪБМф,дйЭЈЙ§ЖЈЪБШЮЮёЪЙгУhscanУќСюЩЈУшЪ§Он,евГіhashФкГЌЪБЕФЪ§ОнЯюЩОГ§МДПЩЁЃ
ЕБRedisФкДцВЛзуЪБ,ЪзЯШПМТЧЕФЮЪЬтВЛЪЧМгЛњЦїзіЫЎЦНРЉеЙ,гІИУЯШГЂЪдзіФкДцгХЛЏЁЃЕБгіЕНЦПОБЪБ,дйШЅПМТЧЫЎЦНРЉеЙЁЃМДЪЙЖдгкМЏШКЛЏЗНАИ,ДЙжБВуУцгХЛЏвВЭЌбљживЊ,БмУтВЛБивЊЕФзЪдДРЫЗбКЭМЏШКЛЏКѓЕФЙмРэГЩБОЁЃ