����,ӳ��,�ĵ�,DSL��ɾ�IJ�
- һ)������
- ��)ES�Ļ�������
- ��)ES��������ɾ�IJ�
- ��)ES�ĵ�����ɾ�IJ�
- ��)ES�ĸ���ѯ
- ��) �ۺϰ���
- ����1 ͳ��������ɫ�ĵ����������
- ����2 ͳ��ÿ����ɫ����ƽ���۸�
- ����3 �����������
- ����4:�����metric
- ����5:���ַ�Χ histogram
- ����6:�������ڷ���ۺ�
- ����7 ͳ��ÿ����ÿ��Ʒ�Ƶ����۶�
- ����8 :������ۺϽ��,��ѯij��Ʒ�ư���ɫ����
- ����9 global bucket:����Ʒ��������Ʒ�������Ա�
- ����10:����+�ۺ�:ͳ�Ƽ۸����1200�ĵ���ƽ���۸�
- ����11 bucket filter:ͳ��Ʒ�����һ���µ�ƽ���۸�
- ����12 ����:��ÿ����ɫ��ƽ�����۶������
- ����13 ����:��ÿ����ɫ��ÿ��Ʒ��ƽ�����۶������
һ)������
1. ES�汾:7.12.1
2. SpringBoot�汾:2.5.8
<parent>
<artifactId>spring-boot-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.5.8</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
��)ES�Ļ�������
1. Elasticsearch ��ʲô
Elaticsearch,���Ϊ ES,ES ��һ����Դ�ĸ���չ�ķֲ�ʽȫ����������,������ Elastic Stack ����ջ�ĺ��ġ������Խ���ʵʱ�Ĵ洢����������;������չ�Ժܺ�,������չ���ϰ�̨������,���� PB ��������ݡ�

The Elastic Stack, ���� Elasticsearch��Kibana��Beats �� Logstash(Ҳ��Ϊ ELK Stack)���ܹ���ȫ�ɿ��ػ�ȡ�κ���Դ���κθ�ʽ������,Ȼ��ʵʱ�ض����ݽ��������������Ϳ��ӻ���
2. Eelasticsearch������
Elasticsearch��һ��dz�ǿ��Ŀ�Դ��������,�߱��dz���ǿ����,���������ǴӺ��������п����ҵ���Ҫ�����ݡ�
- ��GitHub��������
- ����������������������
- ���������վ������Ʒ
- ���������������ij���
3. Elasticsearch,Solr��Lucene����֮��Ĺ�ϵ
Ŀǰ���������е�������������,�����ľ�����:Elasticsearch �� Solr,������ǻ��� Lucene ���,���Զ������������������������������
Lucene��һ��Java���Ե������������,��Apache��˾�Ķ�����Ŀ,�ṩ��һ����ȴǿ���Ӧ�ó�ʽ�ӿ�,�ܹ���ȫ����������Ѱ��
Elasticsearch��Solr�Ա�
| ���� | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| �����Ϳ����� | Apache�������������֧�� | ��һ��ҵʵ�弰��Ա�� |
| �ڵ㷢�� | Apache Zookeeper.�ڴ�����Ŀ�г����Ҿ���ʵս���� | Zen������Elasticsearch����,��Ҫר�õ����ڵ���ܽ������Ա��� |
| ��Ƭ���� | �������Ǿ�̬,��Ҫ�ֶ�������Ǩ�Ʒ�Ƭ,��Solr 7��ʼ- AutoscalingAPI����һЩ��̬���� | ��̬,���Ը���Ⱥ��״̬�����ƶ���Ƭ |
| ���ٻ��� | ȫ��,ÿ���θ�����Ч | ÿ��,���ʺ϶�̬�������� |
| ������������ | �dz��ʺϾ�ȷ����ľ�̬���� | �����ȷ��ȡ�������ݷ��� |
| ȫ���������� | ����Lucene�����Է���,�ཨ��,ƴд���,�ḻ�ĸ�����ʾ֧�� | ����Lucene�����Է���,��һ����APIʵ��, ������ʾ���¼��� |
| DevOps֧�� | ��δ��ȫ,���������� | �dz��õ�API |
| ��ƽ�����ݴ��� | Ƕ���ĵ�����֧�� | Ƕ�Ͷ������͵���Ȼ֧��������������Ƕ��-��֧�� |
| ��ѯDSL | JSON (����),XML (����)��URL���� | JSON |
| ����ѧϰ | ����-�����ۺ�֮��,רע�����ع��ѧϰ��������ģ�� | ��ҵ����,רע���쳣���쳣ֵ�Լ�ʱ���������� |
4. Elasticsearch�������ṹ�C��������
���������ĸ����ǻ���MySQL�����������������Եġ�
��������
��ôʲô������������?������±�(tb_goods)�е�id��������:

����Ǹ���id��ѯ,��ôֱ��������,��ѯ�ٶȷdz��졣
������ǻ���title��ģ����ѯ,ֻ��������ɨ������,��������:
1)�û���������,������title����"%�ֻ�%"
2)���л�ȡ����,����idΪ1������
3)�ж������е�title�Ƿ�����û���������
4)����������������,�������������ص�����1
����ɨ��,Ҳ����ȫ��ɨ��,��������������,���ѯЧ��Ҳ��Խ��Խ�͡����������ﵽ������ʱ,����һ�����ѡ�
��������
�����������������dz���Ҫ�ĸ���:
- �ĵ�(
Document):��������������,���е�ÿһ�����ݾ���һ���ĵ�������һ����ҳ��һ����Ʒ��Ϣ�� - ����(
Term):���ĵ����ݻ��û���������,����ij���㷨�ִ�,�õ��ľ߱�����Ĵ�����Ǵ���������:�����й���,�Ϳ��Է�Ϊ:�ҡ��ǡ��й��ˡ��й������������ļ�������
�������������Ƕ�����������һ�������,��������:
- ��ÿһ���ĵ������������㷨�ִ�,�õ�һ��������
- ������,ÿ�����ݰ������������������ĵ�id��λ�õ���Ϣ
- ��Ϊ����Ψһ��,���Ը�������������,����hash���ṹ����
��ͼ:
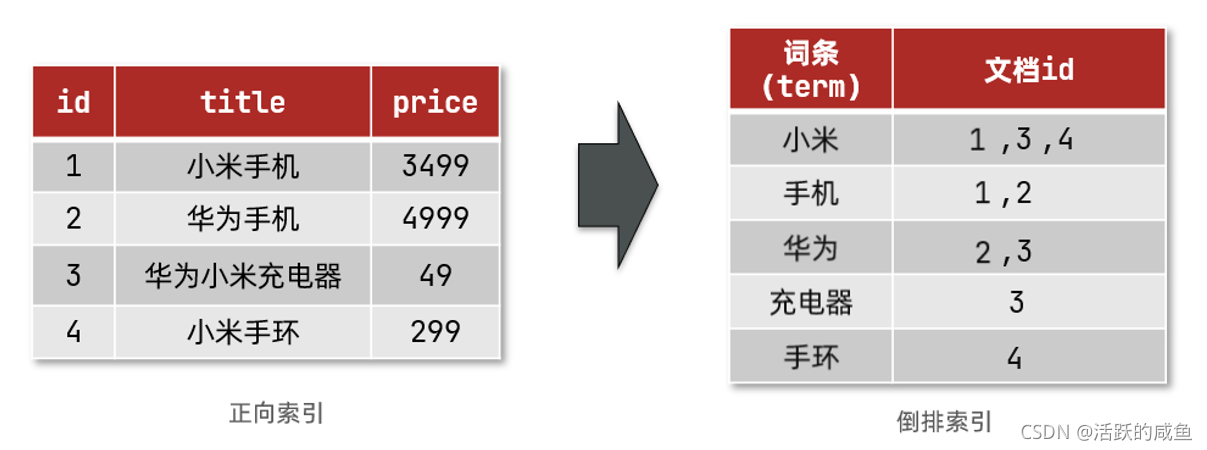
����������������������(������"��Ϊ�ֻ�"Ϊ��):
1)�û���������"��Ϊ�ֻ�"����������
2)���û����������ִ�,�õ�����:��Ϊ���ֻ���
3)���Ŵ����ڵ��������в���,���Եõ������������ĵ�id:1��2��3��
4)�����ĵ�id�����������в��Ҿ����ĵ���
��ͼ:

��ȻҪ�Ȳ�ѯ��������,�ٲ�ѯ��������,���������Ǵ����������ĵ�id������������,��ѯ�ٶȷdz���!����ȫ��ɨ�衣
���������͵��������Ƚ�
-
�����������ͳ��,����id�����ķ�ʽ�������ݴ�����ѯʱ,������������ȡÿ���ĵ�,Ȼ���ж��ĵ����Ƿ��������Ҫ�Ĵ���,�������ĵ��Ҵ����Ĺ�����
-
�������������෴,�����ҵ��û�Ҫ�����Ĵ���,���ݴ����õ������������ĵ���id,Ȼ�����id��ȡ�ĵ��������ݴ������ĵ��Ĺ�����
��������:
- �ŵ�:
- ���Ը�����ֶδ�������
- ���������ֶ������������ٶȷdz���
- ȱ��:
- ���ݷ������ֶ�,���������ֶ��еIJ��ִ�������ʱ,ֻ��ȫ��ɨ�衣
��������:
- �ŵ�:
- ���ݴ���������ģ������ʱ,�ٶȷdz���
- ȱ��:
- ֻ�ܸ�������������,�������ֶ�
- �������ֶ�������
5. ES�е�һЩ��������
elasticsearch���кܶ���еĸ���,��mysql�����в��,��Ҳ������֮����
���ͼ�Ⱥ
���(Node):ÿ��esʵ����Ϊһ���ڵ㡣�ڵ����Զ�����,Ҳ�����ֶ����á�
��Ⱥ(cluster):����һ������������esʵ���Ļ���Ⱥ��ͨ��һ̨������һ��esʵ����ͬһ������,����һ���Ķ��esʵ���Զ���ɼ�Ⱥ,�Զ������Ƭ����Ϊ��Ĭ�ϼ�Ⱥ��Ϊ��elasticsearch����
��Ƭ����
��Ƭ ( shard ): index���ݹ���ʱ,��index���������,��Ϊ���shard,�ֲ�ʽ�Ĵ洢�ڸ������������档����֧�ֺ������ݺ߲���,�������ܺ�������,������ö�̨������cpu��
����( replica ) : �ڷֲ�ʽ������,�κ�һ̨����������ʱ崻�,���崻�,index��һ����Ƭû��,���´�index��������������,Ϊ�˱�֤���ݵİ�ȫ,���ǻὫÿ��index�ķ�Ƭ���б���,�洢������Ļ����ϡ���֤��������崻�es��Ⱥ�Կ���������
�������ṩ��ѯ�Ͳ���ķ�Ƭ���ǽ�������Ƭ(primary shard),��������Ǿ����ǽ������ݵķ�Ƭ(replica shard)��
�ĵ����ֶ�
elasticsearch�������ĵ�(Document) �洢��,���������ݿ��е�һ����Ʒ����,һ��������Ϣ���ĵ����ݻᱻ���л�Ϊjson��ʽ��洢��elasticsearch��:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-4JWzZNSz-1633240596343)(assets/image-20210720202707797.png)]](https://img-blog.csdnimg.cn/2f4cddfb63354483b2c2cc52d9919a50.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5rS76LeD55qE5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
��Json�ĵ������������ܶ���ֶ�(Field),���������ݿ��е��С�
������ӳ��
����(Index),������ͬ���͵��ĵ��ļ��ϡ�
����:
- �����û��ĵ�,�Ϳ�����֯��һ��,��Ϊ�û�������;
- ������Ʒ���ĵ�,������֯��һ��,��Ϊ��Ʒ������;
- ���ж������ĵ�,������֯��һ��,��Ϊ����������;

���,���ǿ����������������ݿ��еı���
���ݿ�ı�����Լ����Ϣ,����������Ľṹ���ֶε����ơ����͵���Ϣ�����,�������о���ӳ��(mapping),���������ĵ����ֶ�Լ����Ϣ,���Ʊ��ĽṹԼ����
mysql��elasticsearch�Ƚ�
����ͳһ�İ�mysql��elasticsearch�ĸ�����һ�¶Ա�:
| MySQL | Elasticsearch | ˵�� |
|---|---|---|
| Table | Index | ����(index),�����ĵ��ļ���,�������ݿ�ı�(table) |
| Row | Document | �ĵ�(Document),����һ����������,�������ݿ��е���(Row),�ĵ�����JSON��ʽ |
| Column | Field | �ֶ�(Field),����JSON�ĵ��е��ֶ�,�������ݿ��е���(Column) |
| Schema | Mapping | Mapping(ӳ��)���������ĵ���Լ��,�����ֶ�����Լ�����������ݿ�ı��ṹ(Schema) |
| SQL | DSL | DSL��elasticsearch�ṩ��JSON�����������,��������elasticsearch,ʵ��CRUD |
�Dz���˵,����ѧϰ��elasticsearch�Ͳ�����Ҫmysql����?
���������,���߸������Լ����ó�֧��:
-
Mysql:�ó��������Ͳ���,����ȷ�����ݵİ�ȫ��һ����
-
Elasticsearch:�ó��������ݵ�����������������
�������ҵ��,���������߽��ʹ��:
- ��ȫ��Ҫ��ϸߵ�д����,ʹ��mysqlʵ��
- �Բ�ѯ����Ҫ��ϸߵ���������,ʹ��elasticsearchʵ��
- �����ٻ���ij�ַ�ʽ,ʵ�����ݵ�ͬ��,��֤һ����

����ͬ��˼·����
����������ͬ������������:
- ͬ������
- �첽֪ͨ
- ����binlog
1.ͬ������
����һ:ͬ������
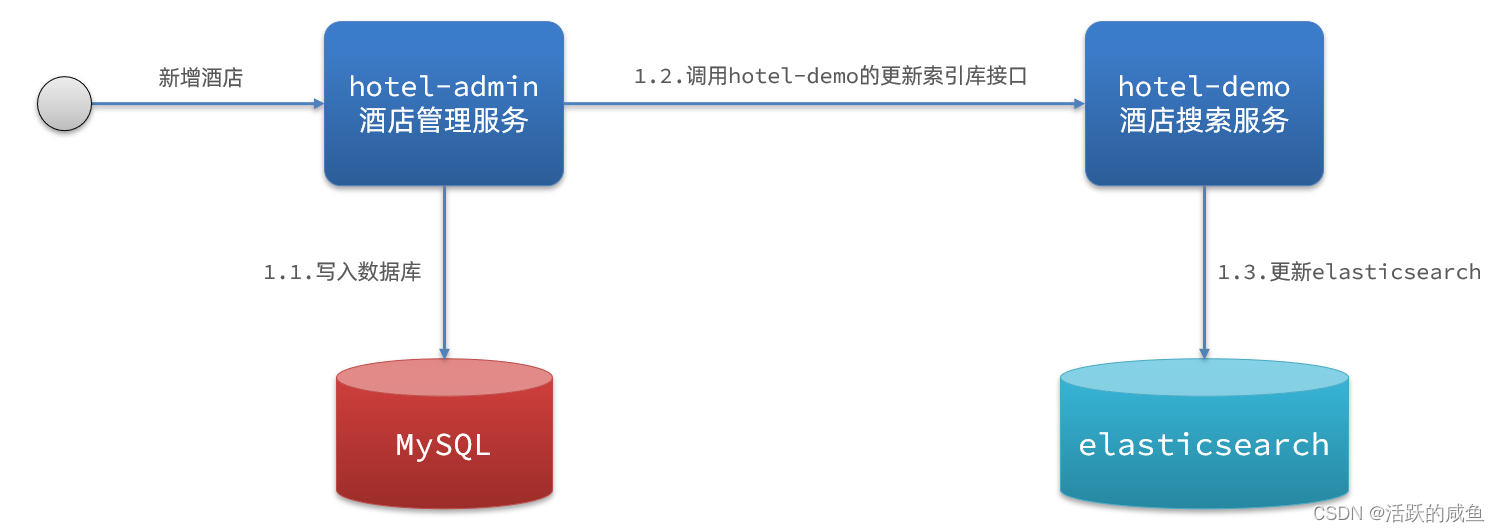
������������:
- hotel-demo�����ṩ�ӿ�,������elasticsearch�е�����
- �Ƶ����������������ݿ������,ֱ�ӵ���hotel-demo�ṩ�Ľӿ�,
2.�첽֪ͨ
������:�첽֪ͨ
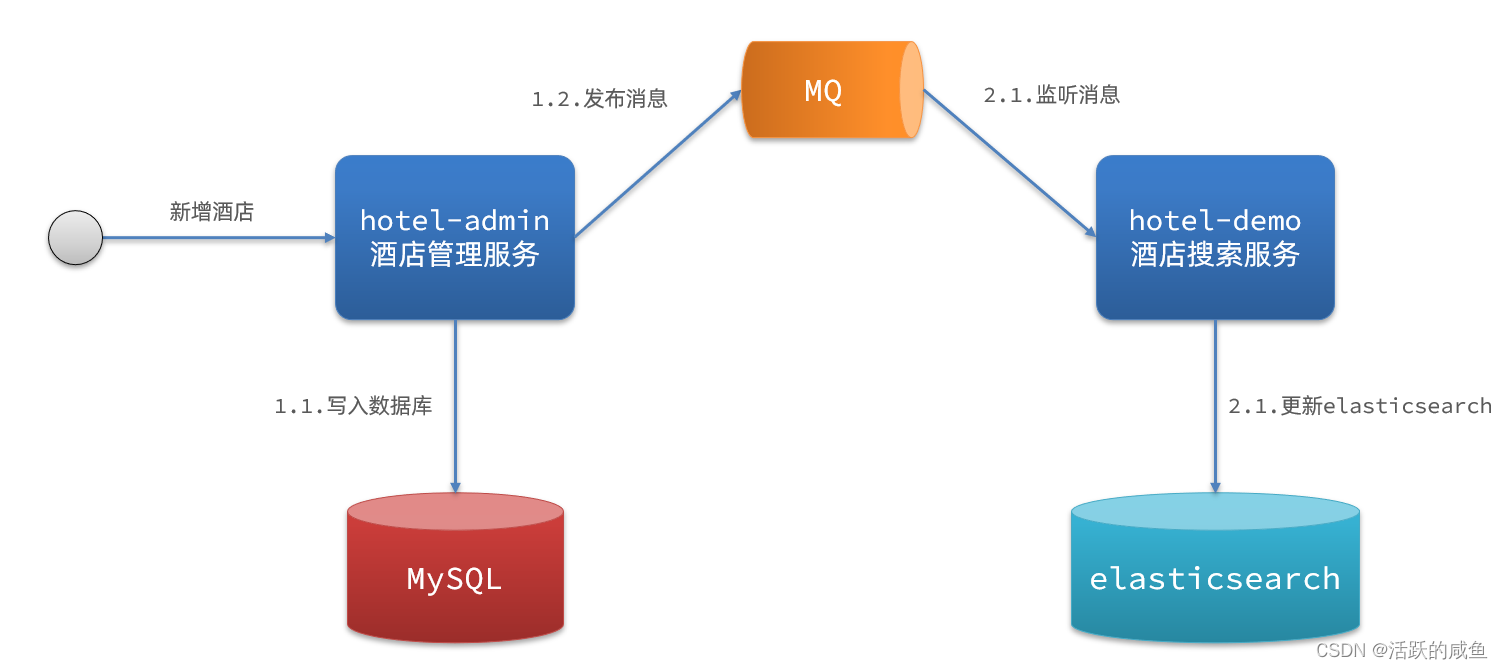
��������:
- hotel-admin��mysql���ݿ������������ɾ���ĺ�,����MQ��Ϣ
- hotel-demo����MQ,���յ���Ϣ�����elasticsearch������
3.����binlog
������:����binlog
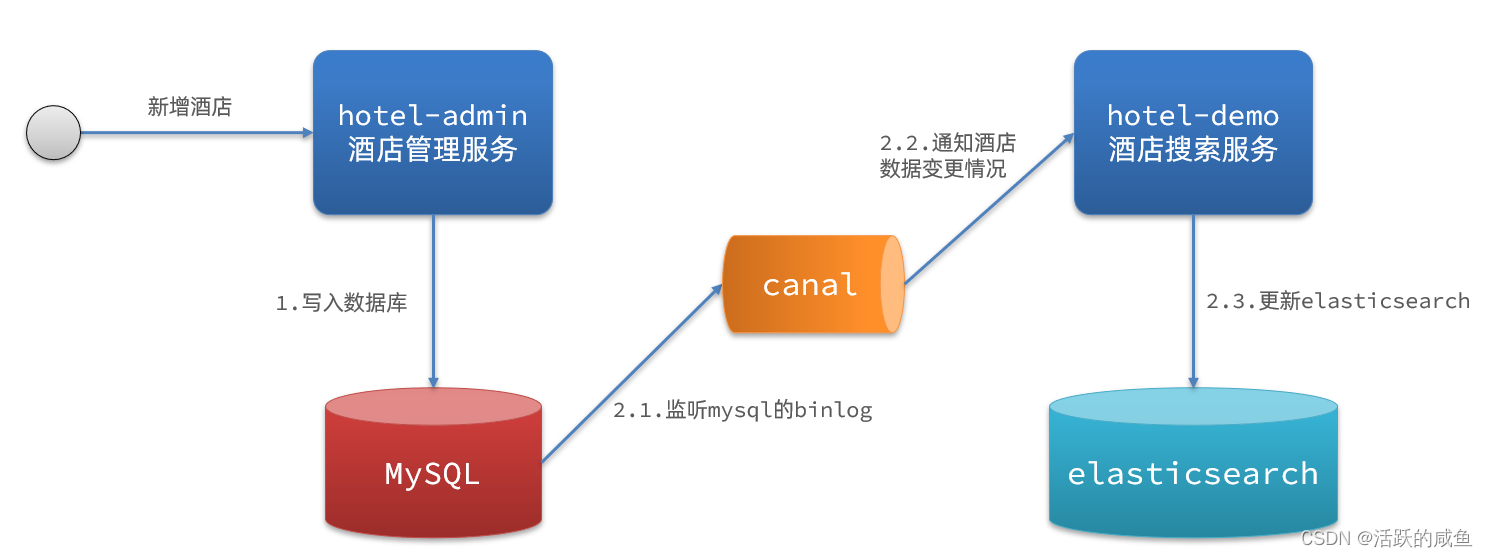
��������:
- ��mysql����binlog����
- mysql�������ɾ���IJ��������¼��binlog��
- hotel-demo����canal����binlog�仯,ʵʱ����elasticsearch�е�����
4.ѡ��
��ʽһ:ͬ������
- �ŵ�:ʵ�ּ�,�ֱ�
- ȱ��:ҵ����϶ȸ�
��ʽ��:�첽֪ͨ
- �ŵ�:�����,ʵ���Ѷ�һ��
- ȱ��:����mq�Ŀɿ���
��ʽ��:����binlog
- �ŵ�:��ȫ�����������
- ȱ��:����binlog�������ݿ⸺����ʵ�ָ��Ӷȸ�
��)ES��������ɾ�IJ�
��������������ݿ��,mappingӳ������Ʊ��Ľṹ������Ҫ��es�д洢����,�����ȴ������⡱�͡�������
1. mappingӳ������
mapping�Ƕ����������ĵ���Լ��,������mapping������:
- type:�ֶ���������,�����ļ�������:
- �ַ���:text(�ɷִʵ��ı�)��keyword(��ȷֵ,����:Ʒ�ơ����ҡ�ip��ַ)
- ��ֵ:long��integer��short��byte��double��float��
- ����:boolean
- ����:date
- ����:object
- index:�Ƿ�����,Ĭ��Ϊtrue
- analyzer:ʹ�����ִַ���
- store:�Ƿ����ݽ��ж����洢,Ĭ��Ϊ false
ԭʼ���ı���洢��_source ����,Ĭ�������������ȡ�������ֶζ����Ƕ����洢��,�Ǵ�_source ������ȡ�����ġ���Ȼ��Ҳ���Զ����Ĵ洢ij���ֶ�,ֻҪ����"store": true ����,��ȡ�����洢���ֶ�Ҫ�ȴ�_source �н�����ö�,����Ҳ��ռ�ø���Ŀռ�,����Ҫ����ʵ��ҵ�����������á� - properties:���ֶε����ֶ�
2. ������Ĵ���
�����:
- ����ʽ:PUT
- ����·��:/��������,�����Զ���
- �������:mappingӳ��
��ʽ:
PUT /����������
{
"mappings": {
"properties": {
"�ֶ���":{
"type": "text",
"analyzer": "ik_smart"
},
"�ֶ���2":{
"type": "keyword",
"index": "false"
},
"�ֶ���3":{
"properties": {
"���ֶ�": {
"type": "keyword"
}
}
},
// ...��
}
}
}
ʾ��:
PUT /xianyu
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... ��
}
}
}
RestAPI��������:
//1.��������
CreateIndexRequest request=new CreateIndexRequest("hotel");
//2.���������
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
//3.��������
client.indices().create(request, RequestOptions.DEFAULT);
1.ͬ������:
//������������
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book");
//����
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//ָ��ӳ��1
createIndexRequest.mapping(" {\n" +
" \t\"properties\": {\n" +
" \"name\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\":\"long\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\":\"text\",\n" +
" \"index\":false\n" +
" }\n" +
" \t}\n" +
"}", XContentType.JSON);
//ָ��ӳ��2
?```
// Map<String, Object> message = new HashMap<>();
// message.put("type", "text");
// Map<String, Object> properties = new HashMap<>();
// properties.put("message", message);
// Map<String, Object> mapping = new HashMap<>();
// mapping.put("properties", properties);
// createIndexRequest.mapping(mapping);
?```
//ָ��ӳ��3
?```
// XContentBuilder builder = XContentFactory.jsonBuilder();
// builder.startObject();
// {
// builder.startObject("properties");
// {
// builder.startObject("message");
// {
// builder.field("type", "text");
// }
// builder.endObject();
// }
// builder.endObject();
// }
// builder.endObject();
// createIndexRequest.mapping(builder);
?```
//����
createIndexRequest.alias(new Alias("itheima_index_new"));
// �������
//���ó�ʱʱ��
createIndexRequest.setTimeout(TimeValue.timeValueMinutes(2));
//�������ڵ㳬ʱʱ��
createIndexRequest.setMasterTimeout(TimeValue.timeValueMinutes(1));
//�ڴ�������API������Ӧ֮ǰ�ȴ��Ļ��Ƭ����������,��int��ʽ��ʾ
createIndexRequest.waitForActiveShards(ActiveShardCount.from(2));
createIndexRequest.waitForActiveShards(ActiveShardCount.DEFAULT);
//���������Ŀͻ���
IndicesClient indices = client.indices();
//ִ�д���������
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
//�õ���Ӧ(ȫ��)
boolean acknowledged = createIndexResponse.isAcknowledged();
//�õ���Ӧ ָʾ�Ƿ��ڳ�ʱǰΪ�����е�ÿ����Ƭ������������������Ƭ����
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();
System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!!!!" + acknowledged);
System.out.println(shardsAcknowledged);
}
2.�첽����:
//������������
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book2");
//����
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//ָ��ӳ��1
createIndexRequest.mapping(" {\n" +
" \t\"properties\": {\n" +
" \"name\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\":\"long\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\":\"text\",\n" +
" \"index\":false\n" +
" }\n" +
" \t}\n" +
"}", XContentType.JSON);
//��������
ActionListener<CreateIndexResponse> listener =
new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
System.out.println("!!!!!!!!���������ɹ�");
System.out.println(createIndexResponse.toString());
}
@Override
public void onFailure(Exception e) {
System.out.println("!!!!!!!!��������ʧ��");
e.printStackTrace();
}
};
//���������Ŀͻ���
IndicesClient indices = client.indices();
//ִ�д���������
indices.createAsync(createIndexRequest, RequestOptions.DEFAULT, listener);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
3.SpringData�Զ�����
// ����ͨ��ע��@Document @Filed @Setting ���Զ�������
@Document(indexName = "book")
@Data
public class Book {
// ������ id,����� id ��ȫ��Ψһ�ı�ʶ,��ͬ�� es �е�"_id"
@Id
private String id;
@Field(type = FieldType.Keyword, analyzer = "ik_max_word",searchAnalyzer= "ik_smart")
private String bookName;
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer= "ik_smart")
private String bookDesc;
@Field(type = FieldType.Double, index = false)
private Double bookPrice;
@Field(type = FieldType.Long, index = false)
private Integer bookNumber;
}
3. ��ѯ������
�����:
-
����ʽ:GET
-
����·��:/��������
-
�������:��
��ʽ:
GET /��������
ʾ��:
GET /xianyu
{
"xianyu"����������: {
"aliases"��������: {},
"mappings"��ӳ�䡿: {},
"settings"�����á�: {
"index"������ - ������: {
"creation_date"������ - ���� - ����ʱ�䡿: "1614265373911",
"number_of_shards"������ - ���� - ����Ƭ������: "1",
"number_of_replicas"������ - ���� - ����Ƭ������: "1",
"uuid"������ - ���� - Ψһ��ʶ��: "eI5wemRERTumxGCc1bAk2A",
"version"������ - ���� - �汾��: {
"created": "7080099"
},
"provided_name"������ - ���� - ���ơ�: "xianyu"
}
}
}
}
��ѯ���е�������
#��ѯ���е�������
GET /_cat/indices?v

| ��ͷ | ���� |
|---|---|
| health ��ǰ����������״̬: | green(��Ⱥ����) yellow(������������Ⱥ������)red(���㲻����) |
| status | �������ر�״̬ |
| index | ������ |
| uuid | ����ͳһ��� |
| pri | ����Ƭ���� |
| rep | �������� |
| docs.count | �����ĵ����� |
| docs.deleted | �ĵ�ɾ��״̬(��ɾ��) |
| store.size | ����Ƭ����Ƭ����ռ�ռ��С |
| pri.store.size | ����Ƭռ�ռ��С |
RestAPI
// ��ѯ���� - �������
GetIndexRequest request = new GetIndexRequest("hotel");
// ��������,��ȡ��Ӧ
GetIndexResponse response = client.indices().get(request,
RequestOptions.DEFAULT);
4. ��������
���������ṹ��Ȼ������,����һ�����ݽṹ�ı�(����ı��˷ִ���),����Ҫ���´�����������,���ֱ�����ѡ����������һ������,����mapping��
��Ȼ����mapping�����е��ֶ�,����ȴ���������µ��ֶε�mapping��,��Ϊ����Ե�����������Ӱ�졣
�˵��:
PUT /��������/_mapping
{
"properties": {
"���ֶ���":{
"type": "integer"
}
}
}
5. ɾ��������
�:
-
����ʽ:DELETE
-
����·��:/��������
-
�������:��
��ʽ:
DELETE /��������
RestAPI:
//����ɾ������
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
//��������
client.indices().delete(request,RequestOptions.DEFAULT);
�첽ɾ��
//ɾ����������
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("itheima_book2");
//���������Ŀͻ���
IndicesClient indices = client.indices();
//��������
ActionListener<AcknowledgedResponse> listener =
new ActionListener<AcknowledgedResponse>() {
@Override
public void onResponse(AcknowledgedResponse deleteIndexResponse) {
System.out.println("!!!!!!!!ɾ�������ɹ�");
System.out.println(deleteIndexResponse.toString());
}
@Override
public void onFailure(Exception e) {
System.out.println("!!!!!!!!ɾ������ʧ��");
e.printStackTrace();
}
};
//ִ��ɾ������
indices.deleteAsync(deleteIndexRequest, RequestOptions.DEFAULT, listener);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
6. �ر�������
OpenIndexRequest request = new OpenIndexRequest("itheima_book");
OpenIndexResponse openIndexResponse = client.indices().open(request, RequestOptions.DEFAULT);
boolean acknowledged = openIndexResponse.isAcknowledged();
System.out.println("!!!!!!!!!"+acknowledged);
CloseIndexRequest request = new CloseIndexRequest("index");
AcknowledgedResponse closeIndexResponse = client.indices().close(request, RequestOptions.DEFAULT);
boolean acknowledged = closeIndexResponse.isAcknowledged();
System.out.println("!!!!!!!!!"+acknowledged);
GetIndexRequest request = new GetIndexRequest("itheima_book");
request.local(false);//�����ڵ㷵�ر�����Ϣ�����״̬
request.humanReadable(true);//���ʺ�����ĸ�ʽ���ؽ��
request.includeDefaults(false);//�Ƿ�ÿ������������Ĭ������
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
��)ES�ĵ�����ɾ�IJ�
1. �����ĵ�
�:
POST /��������/_doc/�ĵ�id
{
"�ֶ�1": "ֵ1",
"�ֶ�2": "ֵ2",
"�ֶ�3": {
"������1": "ֵ3",
"������2": "ֵ4"
},
// ...
}
ʾ��:
POST /xianyu/_doc/1 ����id���������һ��id
{
"name":"����",
"age":23
}
{
"_index" : "xianyu", //������
"_type" : "_doc", //����
"_id" : "1", //Ψһ��ʶ ��������
"_version" : 1, //�汾
"result" : "created", //��� ��ʾ�����ɹ�
"_shards" : { //��Ƭ
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
RESTAPI
// 1.����id��ѯ�Ƶ�����
Hotel hotel = hotelService.getById(61083L);
// 2.ת��Ϊ�ĵ�����
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.��HotelDocתjson
String jsonString = JSON.toJSONString(hotelDoc);
// 1.��Request����
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.��Json�ĵ�
request.source(jsonString, XContentType.JSON);
// 3.��������
client.index(request, RequestOptions.DEFAULT);
ͬ��
// 1��������
IndexRequest request=new IndexRequest("test_posts");
request.id("3");
// =======================�����ĵ�============================
// ��������1
String jsonString="{\n" +
" \"user\":\"tomas J\",\n" +
" \"postDate\":\"2019-07-18\",\n" +
" \"message\":\"trying out es3\"\n" +
"}";
request.source(jsonString, XContentType.JSON);
// ��������2
// Map<String,Object> jsonMap=new HashMap<>();
// jsonMap.put("user", "tomas");
// jsonMap.put("postDate", "2019-07-18");
// jsonMap.put("message", "trying out es2");
// request.source(jsonMap);
// ��������3
// XContentBuilder builder= XContentFactory.jsonBuilder();
// builder.startObject();
// {
// builder.field("user", "tomas");
// builder.timeField("postDate", new Date());
// builder.field("message", "trying out es2");
// }
// builder.endObject();
// request.source(builder);
// ��������4
// request.source("user","tomas",
// "postDate",new Date(),
// "message","trying out es2");
//
// ========================��ѡ����===================================
//���ó�ʱʱ��
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//�Լ�ά���汾��
// request.version(2);
// request.versionType(VersionType.EXTERNAL);
// 2ִ��
//ͬ��
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
�첽
//�첽
// ActionListener<IndexResponse> listener=new ActionListener<IndexResponse>() {
// @Override
// public void onResponse(IndexResponse indexResponse) {
//
// }
//
// @Override
// public void onFailure(Exception e) {
//
// }
// };
// client.indexAsync(request,RequestOptions.DEFAULT, listener );
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// 3��ȡ���
String index = indexResponse.getIndex();
String id = indexResponse.getId();
//��ȡ���������
if(indexResponse.getResult()== DocWriteResponse.Result.CREATED){
DocWriteResponse.Result result=indexResponse.getResult();
System.out.println("CREATED:"+result);
}else if(indexResponse.getResult()== DocWriteResponse.Result.UPDATED){
DocWriteResponse.Result result=indexResponse.getResult();
System.out.println("UPDATED:"+result);
}
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if(shardInfo.getTotal()!=shardInfo.getSuccessful()){
System.out.println("�����ɹ��ķ�Ƭ�������ܷ�Ƭ!");
}
if(shardInfo.getFailed()>0){
for (ReplicationResponse.ShardInfo.Failure failure:shardInfo.getFailures()) {
String reason = failure.reason();//����DZ�ڵ�ʧ��ԭ��
System.out.println(reason);
}
}
}
2. ��ѯ�ĵ�
�:
GET /{����������}/_doc/{id}
GET /xianyu/_doc/1
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "����",
"age" : 23
}
}
RESTAPI
GetRequest request = new GetRequest("hotel","61083");
//�õ���Ӧ
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
//�����ĵ�
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//��������
GetRequest getRequest = new GetRequest("test_post", "1");
//========================��ѡ���� start======================
//Ϊ�ض��ֶ�����_source_include
// String[] includes = new String[]{"user", "message"};
// String[] excludes = Strings.EMPTY_ARRAY;
// FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
// getRequest.fetchSourceContext(fetchSourceContext);
//Ϊ�ض��ֶ�����_source_excludes
// String[] includes1 = new String[]{"user", "message"};
// String[] excludes1 = Strings.EMPTY_ARRAY;
// FetchSourceContext fetchSourceContext1 = new FetchSourceContext(true, includes1, excludes1);
// getRequest.fetchSourceContext(fetchSourceContext1);
//����·��
// getRequest.routing("routing");
// ========================��ѡ���� end=====================
//��ѯ ͬ����ѯ
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
//�첽��ѯ
// ActionListener<GetResponse> listener = new ActionListener<GetResponse>() {
// //��ѯ�ɹ�ʱ������ִ�еķ���
// @Override
// public void onResponse(GetResponse getResponse) {
// long version = getResponse.getVersion();
// String sourceAsString = getResponse.getSourceAsString();//�����ĵ�(String��ʽ)
// System.out.println(sourceAsString);
// }
//
// //��ѯʧ��ʱ������ִ�еķ���
// @Override
// public void onFailure(Exception e) {
// e.printStackTrace();
// }
// };
// //ִ���첽����
// client.getAsync(getRequest, RequestOptions.DEFAULT, listener);
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// ��ȡ���
if (getResponse.isExists()) {
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString();//�����ĵ�(String��ʽ)
System.out.println(sourceAsString);
byte[] sourceAsBytes = getResponse.getSourceAsBytes();//���ֽڽ���
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
System.out.println(sourceAsMap);
}else {
}
}
3. ɾ���ĵ�
�:
DELETE /{����������}/_doc/{id}
DELETE /xianyu/_doc/1
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
����ɾ���ĵ�
POST /xianyu/_delete_by_query
{
"query":{
"match":{
"age":23
}
}
}
RESTAPI
// 1.��Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.��������
client.delete(request, RequestOptions.DEFAULT);
4. ���ĵ�
�������ַ�ʽ:
- ȫ����:ֱ�Ӹ���ԭ�����ĵ�
- ������:���ĵ��еIJ����ֶ�
�:
PUT /{��������}/_doc/�ĵ�id
{
"�ֶ�1": "ֵ1",
"�ֶ�2": "ֵ2",
// ... ��
}
��������ֻ��ָ��idƥ����ĵ��еIJ����ֶΡ�
�:
POST /{��������}/_update/�ĵ�id
{
"doc": {
"�ֶ���": "�µ�ֵ",
}
}
POST /xianyu/_update/1
{
"doc": {
"no":"20183033523"
}
}
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
RESTAPI
// 1.��Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.���������
request.doc(
"price", "952",
"starName", "����"
);
// 3.��������
client.update(request, RequestOptions.DEFAULT);
1��������
UpdateRequest request = new UpdateRequest("test_posts", "3");
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("user", "tomas JJ");
request.doc(jsonMap);
//===============================��ѡ����==========================================
request.timeout("1s");//��ʱʱ��
//���Դ���
request.retryOnConflict(3);
//�����ڼ�������֮ǰ,���뼤��ķ�Ƭ��
// request.waitForActiveShards(2);
//���з�Ƭ����active״̬,�Ÿ���
// request.waitForActiveShards(ActiveShardCount.ALL);
// 2ִ��
// ͬ��
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
// �첽
// 3��ȡ����
updateResponse.getId();
updateResponse.getIndex();
//�жϽ��
if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {
DocWriteResponse.Result result = updateResponse.getResult();
System.out.println("CREATED:" + result);
} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
DocWriteResponse.Result result = updateResponse.getResult();
System.out.println("UPDATED:" + result);
}else if(updateResponse.getResult() == DocWriteResponse.Result.DELETED){
DocWriteResponse.Result result = updateResponse.getResult();
System.out.println("DELETED:" + result);
}else if (updateResponse.getResult() == DocWriteResponse.Result.NOOP){
//û�в���
DocWriteResponse.Result result = updateResponse.getResult();
System.out.println("NOOP:" + result);
}
5. ������ɾ���ĵ�
Bulk �������ͽ��ĵ�����ɾ�IJ�һЩ�в���,ͨ��һ������ȫ�����ꡣ�������紫�������
�:
POST /_bulk
{"action": {"metadata"}}
{"data"}
���²���,ɾ��5,����14,��2��
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }
{ "update": { "_index": "test_index", "_id": "2"} }
{ "doc" : {"test_field" : "bulk test"} }
// 1��������
BulkRequest request = new BulkRequest();
// request.add(new IndexRequest("post").id("1").source(XContentType.JSON, "field", "1"));
// request.add(new IndexRequest("post").id("2").source(XContentType.JSON, "field", "2"));
request.add(new UpdateRequest("post","2").doc(XContentType.JSON, "field", "3"));
request.add(new DeleteRequest("post").id("1"));
// 2ִ��
BulkResponse bulkResponse = client.bulk(request, RequestOptions.DEFAULT);
for (BulkItemResponse itemResponse : bulkResponse) {
DocWriteResponse itemResponseResponse = itemResponse.getResponse();
switch (itemResponse.getOpType()) {
case INDEX:
case CREATE:
IndexResponse indexResponse = (IndexResponse) itemResponseResponse;
indexResponse.getId();
System.out.println(indexResponse.getResult());
break;
case UPDATE:
UpdateResponse updateResponse = (UpdateResponse) itemResponseResponse;
updateResponse.getIndex();
System.out.println(updateResponse.getResult());
break;
case DELETE:
DeleteResponse deleteResponse = (DeleteResponse) itemResponseResponse;
System.out.println(deleteResponse.getResult());
break;
}
}
6. SpringData����ɾ�IJ�
```java
// Book : ʵ����
// String : ��������
@Repository
public interface BookRepository extends ElasticsearchRepository<Book,String> {
List<Book> findByBookNameLike(String bookName);
}
��)ES�ĸ���ѯ
1. DSL��ѯ����
Elasticsearch�ṩ�˻���JSON��DSL(Domain Specific Language)�������ѯ�������IJ�ѯ���Ͱ���:
-
��ѯ����:��ѯ����������,һ������á�����:match_all
-
ȫ�ļ���(full text)��ѯ:���÷ִ������û��������ݷִ�,Ȼ��ȥ������������ƥ�䡣����:
- match_query
- multi_match_query
-
��ȷ��ѯ:���ݾ�ȷ����ֵ��������,һ���Dz���keyword����ֵ�����ڡ�boolean�������ֶΡ�����:
- ids
- range
- term
-
����(geo)��ѯ:���ݾ�γ�Ȳ�ѯ������:
- geo_distance
- geo_bounding_box
-
����(compound)��ѯ:���ϲ�ѯ���Խ��������ֲ�ѯ�����������,�ϲ���ѯ����������:
- bool
- function_score
��ѯ�����:
GET /indexName/_search
{
"query": {
"��ѯ����": {
"��ѯ����": "����ֵ"
}
}
}
2. ��ѯ�����ĵ�
// ��ѯ����
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}

RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.matchAllQuery());
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
�������:
//����Ӧ�������
private void extractResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
//��ȡ������
long total = searchHits.getTotalHits().value;
System.out.println("�ĵ�������Ϊ"+total);
//��ȡ�ĵ�����
SearchHit[] hits = searchHits.getHits();
// Arrays.stream(hits).forEach(v-> JSON.parseObject(v.getSourceAsString(),HotelDoc.class));
for (SearchHit hit : hits) {
// ��ȡ�ĵ�source
String json = hit.getSourceAsString();
// �����л�
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
log.info("�Ƶ�����:{}",hotelDoc);
}
}
3. ȫ�ļ�����ѯ
ʹ�ó���
ȫ�ļ�����ѯ�Ļ�����������:
- ���û��������������ִ�,�õ�����
- ���ݴ���ȥ������������ƥ��,�õ��ĵ�id
- �����ĵ�id�ҵ��ĵ�,���ظ��û�
�Ƚϳ��õij�������:
- �̳ǵ����������
- �ٶ����������
��Ϊ�����Ŵ���ȥƥ��,��˲����������ֶ�Ҳ�����ǿɷִʵ�text���͵��ֶΡ�
�����
������ȫ�ļ�����ѯ����:
- match��ѯ:���ֶβ�ѯ
- multi_match��ѯ:���ֶβ�ѯ,����һ���ֶη�������������ϲ�ѯ����,�����ֶ�Խ��,�Բ�ѯ����Ӱ��Խ��,��˽������copy_to,Ȼ���ֶβ�ѯ�ķ�ʽ��
match��ѯ�����:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
#ƥ���ѯ
GET /hotel/_search
{
"query": {
"match": {
"city": "�Ϻ�"
}
}
}
RestAPI
//��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.matchQuery("city","�Ϻ�"));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
mulit_match�����:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
#���ֶ�ƥ���ѯ
ע��:���ֶ�ƥ�����ܽϵ�һ���漰�����ֶ�������ʹ��copyto��һ���ֶν��в�ѯ
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "��ͥ",
"fields": ["name","business"]
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.multiMatchQuery("��ͥ","name","business"));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
4. �ؼ��־�ȷ��ѯ
��ȷ��ѯһ���Dz���keyword����ֵ�����ڡ�boolean�������ֶΡ��������������������ִʡ���������:
- term:���ݴ�����ȷֵ��ѯ
- range:����ֵ�ķ�Χ��ѯ
- terms:���ݶ��������ȷ��ѯ
term��ѯ
��Ϊ��ȷ��ѯ���ֶ����Dz��ִʵ��ֶ�,��˲�ѯ������Ҳ���������ִ��Ĵ�������ѯʱ,�û���������ݸ��Զ�ֵ��ȫƥ��ʱ����Ϊ��������������û���������ݹ���,���������������ݡ�
�˵��:
// term��ѯ
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
#��ȷ��ѯ
GET /hotel/_search
{
"query": {
"term": {
"brand": {
"value": "��ͥ"
}
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.termQuery("city","�Ϻ�"));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
range��ѯ
��Χ��ѯ,һ��Ӧ���ڶ���ֵ��������Χ���˵�ʱ�������۸�Χ���ˡ�

�����:
// range��ѯ
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // �����gte�������ڵ���,gt���������
"lte": 20 // lte����С�ڵ���,lt�����С��
}
}
}
}
#��Χ��ѯ
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 300,
"lte": 400
}
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.rangeQuery("price").gt(200).lt(400));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
terms��ѯ
terms ��ѯ�� term ��ѯһ��,����������ָ����ֵ����ƥ�䡣�������ֶΰ�����ָ��ֵ�е��κ�һ��ֵ,��ô����ĵ���������,������ mysql �� in��
// term��ѯ
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": ["VALUE1","VALUE2"]
}
}
}
}
GET /hotel/_search
{
"query": {
"terms": {
"city": [
"�Ϻ�",
"����"
]
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.termsQuery("city","����","�Ϻ�"));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
exist query ��ѯ��ijЩ�ֶ�ֵ���ĵ�
GET /_search
{
"query": {
"exists": {
"field": "join_date"
}
}
}
5. ָ����ѯ�ֶ�
Ĭ�������,Elasticsearch �������Ľ����,����ĵ��б�����_source �������ֶζ����ء��������ֻ���ȡ���еIJ����ֶ�,���ǿ�������_source �Ĺ��ˡ�
#ָ��ɸѡ�ֶ�
GET /hotel/_search
{
"_source": ["address","city"] ,
"query": {
"term": {
"city": {
"value": "�Ϻ�"
}
}
}
}
- includes:��ָ����Ҫ��ʾ���ֶ�
- excludes:��ָ������Ҫ��ʾ���ֶ�
GET /hotel/_search
{
"_source": {
//"excludes": , ["address","city"],
"includes": ["brand","price"]
},
"query": {
"term": {
"city": {
"value": "�Ϻ�"
}
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//��ѯ�ֶι���
String[] includes={};
String[] excludes={"brand","location"};
//2.����DSL
request.source().query(QueryBuilders.termQuery("city","�Ϻ�")).fetchSource(includes,excludes);
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
6. ���������ѯ
��ν�ĵ��������ѯ,��ʵ���Ǹ��ݾ�γ�Ȳ�ѯ��
������ʹ�ó�������:
- Я��:�����Ҹ����ľƵ�
- �ε�:�����Ҹ����ij��
- ��:�����Ҹ�������
���η�Χ��ѯ
���η�Χ��ѯ,Ҳ����geo_bounding_box��ѯ,��ѯ��������ij�����η�Χ�������ĵ�:
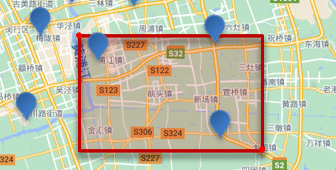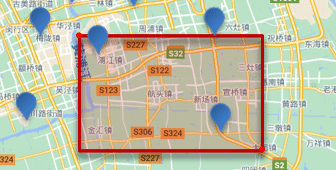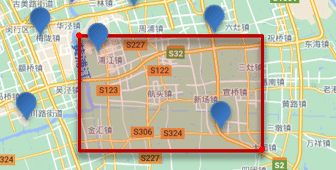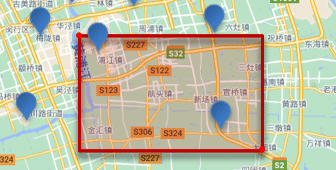
��ѯʱ,��Ҫָ�����ε����������������������,Ȼ��һ������,���ڸþ����ڵĶ��Ƿ��������ĵ㡣
�����:
// geo_bounding_box��ѯ
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // ���ϵ�
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // ���µ�
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
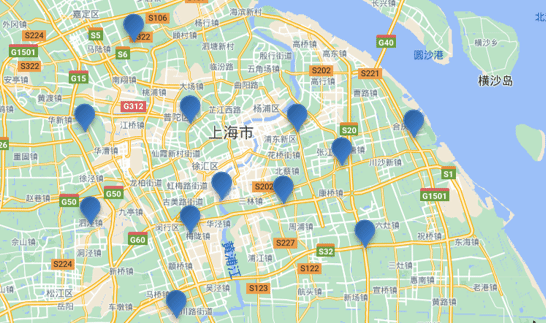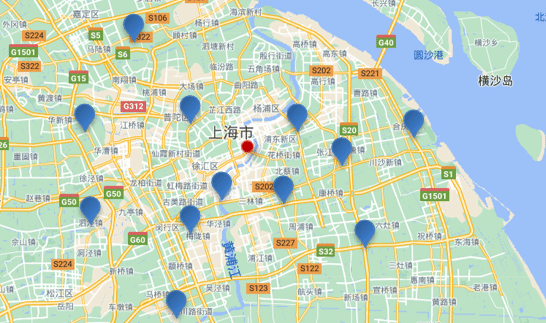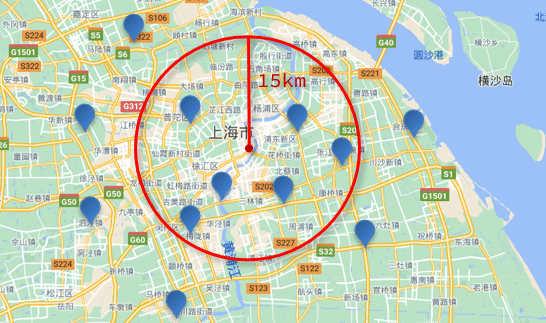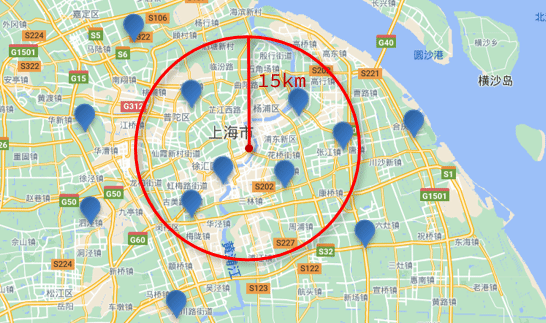
������ѯ
������ѯ,Ҳ���������ѯ(geo_distance):��ѯ��ָ�����ĵ�С��ij������ֵ�������ĵ���
���仰��˵,�ڵ�ͼ����һ������ΪԲ��,��ָ������Ϊ�뾶,��һ��Բ,����Բ�ڵ����궼���������:
�˵��:
// geo_distance ��ѯ
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // �뾶
"FIELD": "31.21,121.5" // Բ��
}
}
}
#���������ѯ �뾶5km��Χ�ڵ�
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": "31.21,121.5"
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders
.geoDistanceQuery("location")
.distance("5", DistanceUnit.KILOMETERS)
.point(31.21,121.5));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
7. ��ֺ�����ѯ
����(compound)��ѯ:���ϲ�ѯ���Խ�������ѯ�������,ʵ�ָ����ӵ���������������������:
- fuction score:��ֺ�����ѯ,���Կ����ĵ���������,�����ĵ�����
- bool query:������ѯ,��������ϵ��϶�������IJ�ѯ,ʵ�ָ�������
��������
����������match��ѯʱ,�ĵ��������������������Ĺ����ȴ��(_score),���ؽ��ʱ���շ�ֵ�������С�
����,�������� ��������ҡ�,�������:
[
{
"_score" : 17.850193,
"_source" : {
"name" : "������ҾƵ��治��",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "��̲��ҾƵ��治��",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "��ʿ����ҾƵ��治��",
}
}
]
��elasticsearch��,����ʹ�õĴ���㷨��TF-IDF�㷨,��ʽ����:

�ں�����5.1�汾������,elasticsearch���㷨�Ľ�ΪBM25�㷨,��ʽ����:

TF-IDF�㷨��һ��ȱ��,���Ǵ���Ƶ��Խ��,�ĵ��÷�Ҳ��Խ��,�����������ĵ�Ӱ��ϴ�BM25����õ��������������һ������,���߸���ƽ��:

��ֺ�����ѯ
������ضȴ���DZȽϺ���������,�������IJ�һ���Dz�Ʒ������Ҫ�ġ�
�ٶ�Ϊ��,�������Ľ����,��������ض�Խ������Խ��ǰ,����˭�͵�Ǯ��������Խ��ǰ��
Ҫ����Ϊ������������,����Ҫ����elasticsearch�е�function score ��ѯ�ˡ�
1)�˵��

function score ��ѯ�а����IJ�������:
- ԭʼ��ѯ����:query����,����������������ĵ�,���һ���BM25�㷨���ĵ����,ԭʼ���(query score)
- ��������:filter����,���ϸ��������ĵ��Ż��������
- ��ֺ���:����filter�������ĵ�Ҫ�����������������,�õ����������(function score),�����ֺ���
- weight:��������dz���
- field_value_factor:���ĵ��е�ij���ֶ�ֵ��Ϊ�������
- random_score:����������������
- script_score:�Զ�����ֺ����㷨
- ����ģʽ:��ֺ����Ľ����ԭʼ��ѯ����������,����֮������㷽ʽ,����:
- multiply:���
- replace:��function score�滻query score
- ����,����:sum��avg��max��min
function score��������������:
- 1)����ԭʼ������ѯ�����ĵ�,���Ҽ�����������,��Ϊԭʼ���(query score)
- 2)������������,�����ĵ�
- 3)���������������ĵ�,������ֺ�������,�õ��������(function score)
- 4)��ԭʼ���(query score)���������(function score)��������ģʽ������,�õ����ս��,��Ϊ�������֡�
���,���еĹؼ�����:
- ��������:������Щ�ĵ�����ֱ���
- ��ֺ���:����������ֵ��㷨
- ����ģʽ:����������ֽ��
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // ԭʼ��ѯ,��������������
"functions": [ // ��ֺ���
{
"filter": { // ���������,Ʒ�Ʊ��������
"term": {
"brand": "���"
}
},
"weight": 2 // ���Ȩ��Ϊ2
}
],
"boost_mode": "sum" // ��Ȩģʽ,���
}
}
}
RestAPI

8. ģ����ѯ
���ذ����������ִ����Ƶ��ִʵ��ĵ���
IDs
GET /book/_search
{
"query": {
"ids" : {
"values" : ["1", "4", "100"]
}
}
}
RestAPI
// 1������������
SearchRequest searchRequest = new SearchRequest("book");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.idsQuery().addIds("1","4","100"));
searchRequest.source(searchSourceBuilder);
//2ִ������
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//3��ȡ���
SearchHits hits = searchResponse.getHits();
prefix ǰ��ѯ
GET /book/_search
{
"query": {
"prefix": {
"description": {
"value": "spring"
}
}
}
}
regexp query �����ѯ
GET /book/_search
{
"query": {
"regexp": {
"description": {
"value": "j.*a",
"flags" : "ALL",
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
Fuzzy query
GET /hotel/_search
{
"query": {
"fuzzy": {
"name": {
"value": "�Ƶ�",
"fuzziness": 0.8
}
}
}
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source().query(QueryBuilders.fuzzyQuery("name","�Ƶ�").fuzziness(Fuzziness.AUTO));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
9. ���ϲ�ѯ
������ѯ��һ��������ѯ�Ӿ�����,ÿһ���Ӿ����һ���Ӳ�ѯ���Ӳ�ѯ����Ϸ�ʽ��:
- must:����ƥ��ÿ���Ӳ�ѯ,���ơ��롱
- should:ѡ����ƥ���Ӳ�ѯ,���ơ���
- must_not:���벻ƥ��,���������,���ơ��ǡ�
- filter:����ƥ��,���������
�����������Ƶ�ʱ,���˹ؼ���������,���ǻ����ܸ���Ʒ�ơ��۸��е��ֶ�������:
ÿһ����ͬ���ֶ�,���ѯ����������ʽ����һ��,�����Ƕ����ͬ�IJ�ѯ,��Ҫ�����Щ��ѯ,�ͱ�����bool��ѯ�ˡ�
��Ҫע�����,����ʱ,������ֵ��ֶ�Խ��,��ѯ������ҲԽ����������ֶ�������ѯʱ,����������:
- ������Ĺؼ�������,��ȫ�ļ�����ѯ,ʹ��must��ѯ,�������
- ������������,����filter��ѯ�����������
���ʾ:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "�Ϻ�" }}
],
"should": [
{"term": {"brand": "�ʹڼ���" }},
{"term": {"brand": "������" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
RestAPI
SearchRequest request = new SearchRequest("hotel");
// 2.1.��BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.rangeQuery("score").gte(45));
boolQuery.must(QueryBuilders.termQuery("city","�Ϻ�"));
boolQuery.should(QueryBuilders.termQuery("brand","������"));
boolQuery.should(QueryBuilders.termQuery("brand","�ʹڼ���"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").lte(500));
request.source().query(boolQuery);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//�������
extractResponse(response);
2)ʾ��
����:�������ְ�������ҡ�,�۸���400,������31.21,121.5��Χ10km��Χ�ڵľƵꡣ
����:
- ��������,����ȫ�ļ�����ѯ,Ӧ�ò�����֡��ŵ�must��
- �۸���400,��range��ѯ,���ڹ�������,��������֡��ŵ�must_not��
- ��Χ10km��Χ��,��geo_distance��ѯ,���ڹ�������,��������֡��ŵ�filter��
# ���ϲ�ѯ
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "���"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
RestAPI
SearchRequest request = new SearchRequest("hotel");
// 2.1.��BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders
.geoDistanceQuery("location")
.distance(10,DistanceUnit.KILOMETERS)
.point(31.21,121.5));
boolQuery.must(QueryBuilders.termQuery("brand","���"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").gt(500));
request.source().query(boolQuery);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//�������
extractResponse(response);
filter��query�Ա�
filter:����ֻ�ǰ��������������˳���Ҫ�����ݶ���,�������κ���ضȷ���,����ض�û���κ�Ӱ�졣
query:��ȥ����ÿ��document�����������������ض�,��������ضȽ�������
Ӧ�ó���:
һ����˵,��������ڽ�������,��Ҫ����ƥ�����������������ȷ���,��ô��query �����ֻ��Ҫ����һЩ����ɸѡ��һ��������,����ע������,��ô��filter
filter��query����
filter,����Ҫ������ضȷ���,����Ҫ������ضȷ�����������,ͬʱ�������õ��Զ�cache�ʹ��filter������
query,�෴,Ҫ������ضȷ���,���շ�����������,������cache���
10. ����
elasticsearchĬ���Ǹ�����ض����(_score)������,����Ҳ֧���Զ��巽ʽ������������������������ֶ�������:keyword���͡���ֵ���͡������������͡��������͵ȡ�
1.��ͨ���ֶ�����
keyword����ֵ��������������������һ�¡�
{
"query": {
...����
},
"sort": [{
"FIELD": {
"order":"desc"
}
}]
}
2.��ͨ���ֶ�����
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": {
"order": "asc"
},
"score": {
"order": "asc"
}
}
]
}
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source()
.query(QueryBuilders.matchAllQuery())
.sort("price",SortOrder.ASC)
.sort("score",SortOrder.ASC);
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
3.������������
�˵��:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "γ��,����", // �ĵ���geo_point���͵��ֶ�����Ŀ�������
"order" : "asc", // ����ʽ
"unit" : "km" // ����ľ��뵥λ
}
}
]
}
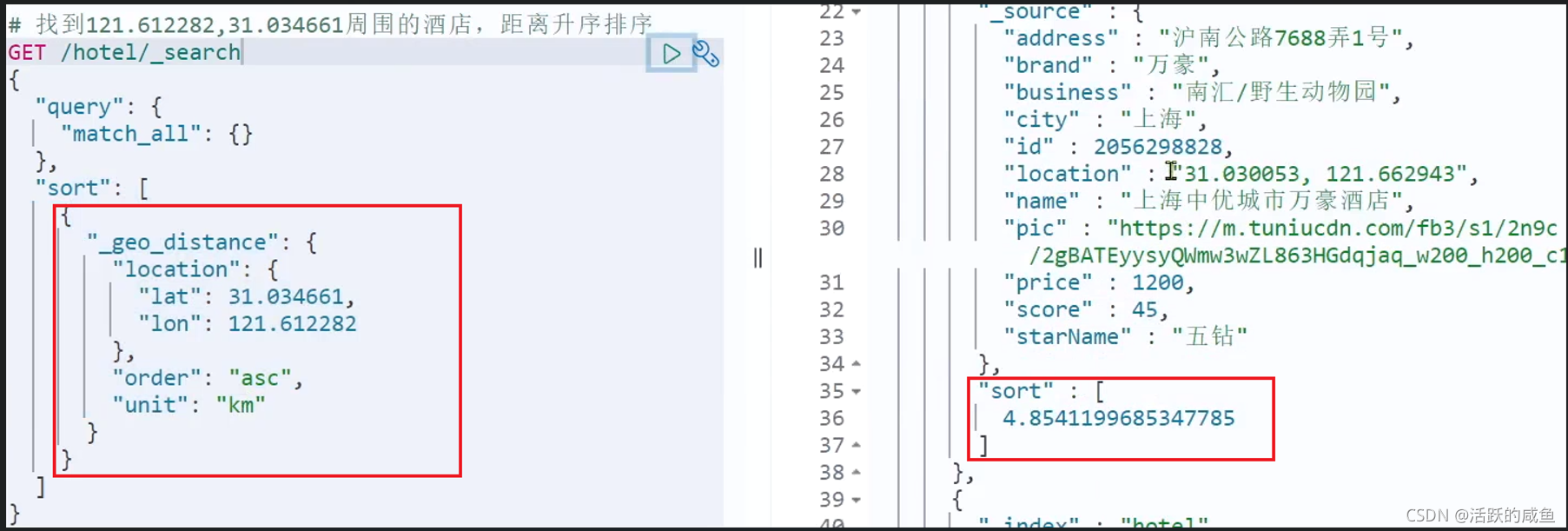
�����ѯ�ĺ�����:
- ָ��һ������,��ΪĿ���
- ����ÿһ���ĵ���,ָ���ֶ�(������geo_point����)������ ��Ŀ���ľ����Ƕ���
- ���ݾ�������
ʾ��: ��������:ʵ�ֶԾƵ����ݰ��յ����λ������ľ�����������
RestAPI
//1.��������
SearchRequest request = new SearchRequest("hotel");
//2.����DSL
request.source()
.query(QueryBuilders.matchAllQuery())
.sort(SortBuilders
.geoDistanceSort("location",31.5,121.5)
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS));
//3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.������Ӧ
extractResponse(response);
11. ��ҳ
elasticsearch Ĭ�������ֻ����top10�����ݡ������Ҫ��ѯ�������ݾ���Ҫ�ķ�ҳ�����ˡ�elasticsearch��ͨ����from��size����������Ҫ���صķ�ҳ���:
- from:�ӵڼ����ĵ���ʼ,Ĭ�ϴ� 0 ��ʼ�� from = (pageNum - 1) * size
- size:�ܹ���ѯ�����ĵ�
������mysql�е�limit ?, ?
������ҳ�:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // ��ҳ��ʼ��λ��,Ĭ��Ϊ0
"size": 10, // ������ȡ���ĵ�����
"sort": [
{"price": "asc"}
]
}
RestAPI
//��������
SearchRequest request = new SearchRequest("hotel");
//����DSL
request.source().query(QueryBuilders
.matchAllQuery())
.sort("price",SortOrder.ASC)
.from(0)
.size(10);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//������Ӧ
extractResponse(response);
��ȷ�ҳ����
����,��Ҫ��ѯ990~1000������,��ѯ��Ҫ��ôд:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // ��ҳ��ʼ��λ��,Ĭ��Ϊ0
"size": 10, // ������ȡ���ĵ�����
"sort": [
{"price": "asc"}
]
}
�����Dz�ѯ990��ʼ������,Ҳ���� ��990~��1000�� ���ݡ�
����,elasticsearch�ڲ���ҳʱ,�����Ȳ�ѯ 0~1000��,Ȼ���ȡ���е�990 ~ 1000����10��:

��ѯTOP1000,���es�ǵ���ģʽ,�Ⲣ��̫��Ӱ�졣
����elasticsearch����һ���Ǽ�Ⱥ,�����Ҽ�Ⱥ��5���ڵ�,��Ҫ��ѯTOP1000������,������ÿ���ڵ��ѯ200���Ϳ����ˡ�
��Ϊ�ڵ�A��TOP200,����һ���ڵ�����ŵ�10000�������ˡ�
���Ҫ���ȡ������Ⱥ��TOP1000,�����Ȳ�ѯ��ÿ���ڵ��TOP1000,���ܽ����,��������,���½�ȡTOP1000��
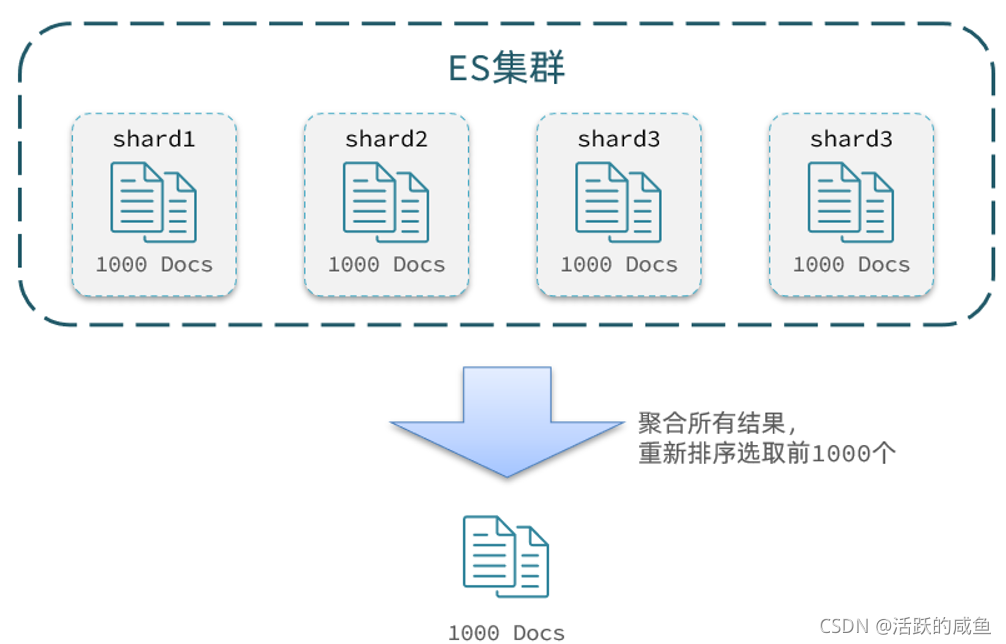
����ѯ��ҳ��Ƚϴ�ʱ,�������ݹ���,���ڴ��CPU������dz����ѹ��,���elasticsearch���ֹfrom+ size ����10000������
�����ȷ�ҳ,ES�ṩ�����ֽ������,�ٷ��ĵ�:
- search after:��ҳʱ��Ҫ����,ԭ���Ǵ���һ�ε�����ֵ��ʼ,��ѯ��һҳ���ݡ��ٷ��Ƽ�ʹ�õķ�ʽ��
- scroll:ԭ�����������ĵ�id�γɿ���,�������ڴ档�ٷ��Ѿ����Ƽ�ʹ�á�
��ҳ��ѯ�ij���ʵ�ַ����Լ���ȱ��:
-
from + size:- �ŵ�:֧�������ҳ
- ȱ��:��ȷ�ҳ����,Ĭ�ϲ�ѯ����(from + size)��10000
- ����:�ٶȡ��������ȸ衢�Ա������������ҳ����
-
after search:- �ŵ�:û�в�ѯ����(���β�ѯ��size������10000)
- ȱ��:ֻ�������ҳ��ѯ,��֧�������ҳ
- ����:û�������ҳ���������,�����ֻ����¹�����ҳ
-
scroll:- �ŵ�:û�в�ѯ����(���β�ѯ��size������10000)
- ȱ��:���ж����ڴ�����,������������Ƿ�ʵʱ��
- ����:�������ݵĻ�ȡ��Ǩ�ơ���ES7.1��ʼ���Ƽ�,������ after search������
12. ������ѯ
����ԭ��
ʲô�Ǹ�����ʾ��?
�����ڰٶ�,��������ʱ,�ؼ��ֻ��ɺ�ɫ,�Ƚ���Ŀ,��и�����ʾ:

������ʾ��ʵ�ַ�Ϊ����:
- 1)���ĵ��е����йؼ��ֶ�����һ����ǩ,����
<em>��ǩ - 2)ҳ���
<em>��ǩ��дCSS��ʽ
ʵ�ָ���
�������:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // ��ѯ����,����һ��Ҫʹ��ȫ�ļ�����ѯ
}
},
"highlight": {
"fields": { // ָ��Ҫ�������ֶ�
"FIELD": {
"pre_tags": "<em>", // ������Ǹ����ֶε�ǰ�ñ�ǩ
"post_tags": "</em>" // ������Ǹ����ֶεĺ��ñ�ǩ
}
}
}
}
ע��:
- �����ǶԹؼ��ָ���,�����������������йؼ���,�������Ƿ�Χ�����IJ�ѯ��
- Ĭ�������,�������ֶ�,����������ָ�����ֶ�һ��,����������
- ���Ҫ�Է������ֶθ���,����Ҫ����һ������:required_field_match=false

ResAPI
// 1.��Request
SearchRequest request = new SearchRequest("hotel");
// 2.��DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "���"));
// 2.2.����
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.������Ӧ
SearchHits searchHits = response.getHits();
// 4.1.��ȡ������
long total = searchHits.getTotalHits().value;
System.out.println("��������" + total + "������");
// 4.2.�ĵ�����
SearchHit[] hits = searchHits.getHits();
// 4.3.����
for (SearchHit hit : hits) {
// ��ȡ�ĵ�source
String json = hit.getSourceAsString();
// �����л�
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// ��ȡ�������
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// �����ֶ�����ȡ�������
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// ��ȡ����ֵ
String name = highlightField.getFragments()[0].string();
// ���ǷǸ������
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
13. �ۺϲ�ѯ
�ۺ�(aggregations)���������Ǽ��䷽���ʵ�ֶ����ݵ�ͳ�ơ����������㡣����:
- ʲôƷ�Ƶ��ֻ����ܻ�ӭ?
- ��Щ�ֻ���ƽ���۸���۸���ͼ۸�?
- ��Щ�ֻ�ÿ�µ�����������?
ʵ����Щͳ�ƹ��ܵı����ݿ��sqlҪ����Ķ�,���Ҳ�ѯ�ٶȷdz���,����ʵ�ֽ�ʵʱ����Ч����
�ۺϵ�����
�ۺϳ�����������:
-
Ͱ(Bucket)�ۺ�:�������ĵ�������
-
TermAggregation:�����ĵ��ֶ�ֵ����,���簴��Ʒ��ֵ���顢���չ��ҷ���
-
Date Histogram:�������ڽ��ݷ���,����һ��Ϊһ��,����һ��Ϊһ��
-
����(Metric)�ۺ�:���Լ���һЩֵ,����:���ֵ����Сֵ��ƽ��ֵ��
- Avg:��ƽ��ֵ
- Max:�����ֵ
- Min:����Сֵ
- Stats:ͬʱ��max��min��avg��sum��
-
�ܵ�(pipeline)�ۺ�:�����ۺϵĽ��Ϊ�������ۺ�
Bucket�ۺ������:
GET /hotel/_search
{
"size": 0, // ����sizeΪ0,����в������ĵ�,ֻ�����ۺϽ��
"aggs": { // ����ۺ�
"brandAgg": { //���ۺ��������
"terms": { // �ۺϵ�����,����Ʒ��ֵ�ۺ�,����ѡ��term
"field": "brand", // ����ۺϵ��ֶ�
"size": 20 // ϣ����ȡ�ľۺϽ������
}
}
}
}
���:
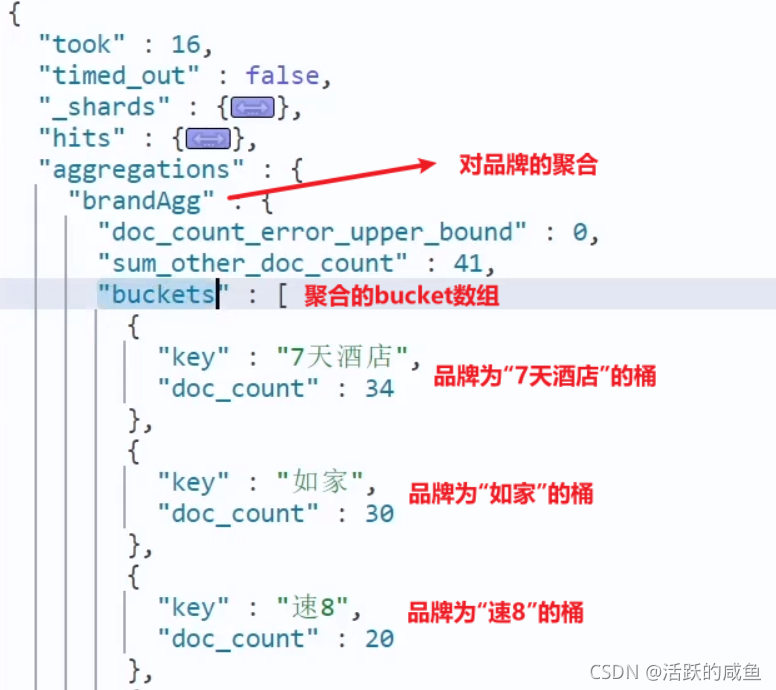
RestAPI

//��������
SearchRequest request = new SearchRequest("hotel");
//����DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//������Ӧ
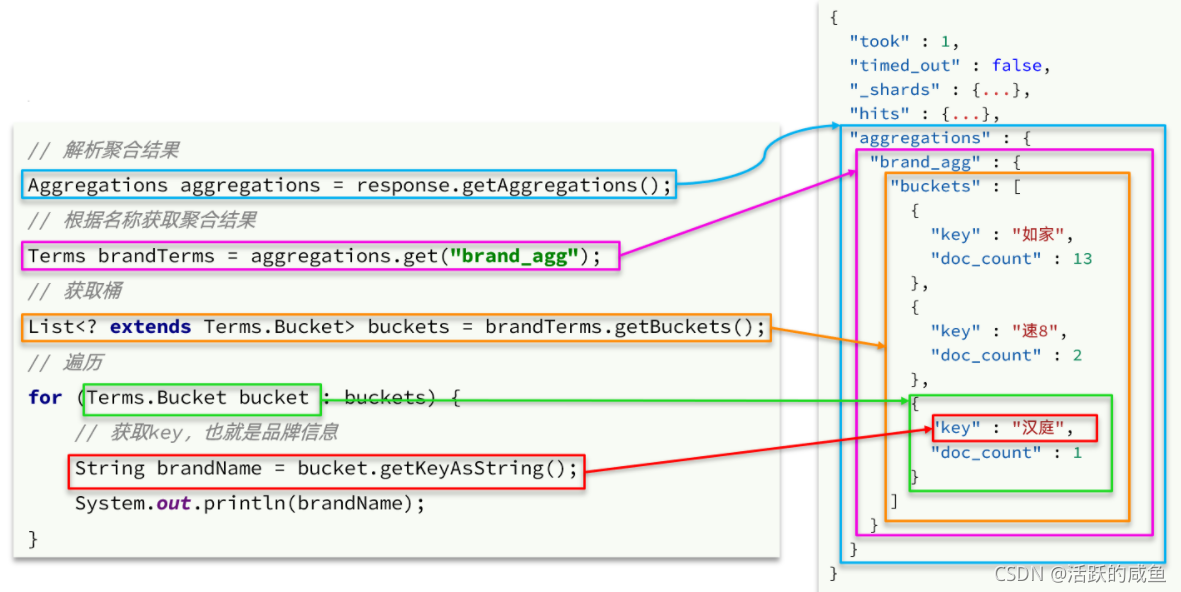
Aggregations aggregations = response.getAggregations();
//�������ƻ�ȡ���
Terms brand_agg = aggregations.get("brand_agg");
//�õ�Ͱ
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//����Ͱ
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}
�ۺϽ������
Ĭ�������,Bucket�ۺϻ�ͳ��Bucket�ڵ��ĵ�����,��Ϊ_count,���Ұ���_count��������
���ǿ���ָ��order����,�Զ���ۺϵ�����ʽ:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // ����_count��������
},
"size": 20
}
}
}
}
SearchRequest request = new SearchRequest("hotel");
//����DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0)
.sort("_count",SortOrder.ASC);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
���ۺϷ�Χ
Ĭ�������,Bucket�ۺ��Ƕ�������������ĵ����ۺ�,����ʵ������,�û���������������,��˾ۺϱ����Ƕ���������ۺϡ���ô�ۺϱ���������������
���ǿ�����Ҫ�ۺϵ��ĵ���Χ,ֻҪ����query��������:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // ֻ��200Ԫ���µ��ĵ��ۺ�
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
RestAPI
//��������
SearchRequest request = new SearchRequest("hotel");
//����DSL
request.source().query(QueryBuilders.rangeQuery("price").lte(200));
request.source()
.aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//������Ӧ
Aggregations aggregations = response.getAggregations();
//�������ƻ�ȡ���
Terms brand_agg = aggregations.get("brand_agg");
//�õ�Ͱ
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//����Ͱ
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}
Metric�ۺ��
���ǶԾƵ갴��Ʒ�Ʒ���,�γ���һ����Ͱ������������Ҫ��Ͱ�ڵľƵ�������,��ȡÿ��Ʒ�Ƶ��û����ֵ�min��max��avg��ֵ��
���Ҫ�õ�Metric�ۺ���,����stat�ۺ�:�Ϳ��Ի�ȡmin��max��avg�Ƚ����
�����:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": { // ��brands�ۺϵ��Ӿۺ�,Ҳ���Ƿ�����ÿ��ֱ����
"score_stats": { // �ۺ�����
"stats": { // �ۺ�����,����stats���Լ���min��max��avg��
"field": "score" // �ۺ��ֶ�,������score
}
}
}
}
}
}
��ε�score_stats�ۺ�����brandAgg�ľۺ��ڲ�Ƕ���Ӿۺϡ���Ϊ������Ҫ��ÿ��Ͱ�ֱ���㡣
����,���ǻ����Ը��ۺϽ����������,���簴��ÿ��Ͱ�ľƵ�ƽ����������:

RestAPI
//��������
SearchRequest request = new SearchRequest("hotel");
//����DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.subAggregation(AggregationBuilders.stats("score_stats").field("score"))
.size(20))
.size(0);
//��������
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//������Ӧ
Aggregations aggregations = response.getAggregations();
//�������ƻ�ȡ���
Terms brand_agg = aggregations.get("brand_agg");
//�õ�Ͱ
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//����Ͱ
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}
��) �ۺϰ���
���Ӱ���
����������ӳ��
PUT /tvs
PUT /tvs/_search
{
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date"
}
}
}
��������
POST /tvs/_bulk
{ "index": {}}
{ "price" : 1000, "color" : "��ɫ", "brand" : "����", "sold_date" : "2019-10-28" }
{ "index": {}}
{ "price" : 2000, "color" : "��ɫ", "brand" : "����", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 3000, "color" : "��ɫ", "brand" : "С��", "sold_date" : "2019-05-18" }
{ "index": {}}
{ "price" : 1500, "color" : "��ɫ", "brand" : "TCL", "sold_date" : "2019-07-02" }
{ "index": {}}
{ "price" : 1200, "color" : "��ɫ", "brand" : "TCL", "sold_date" : "2019-08-19" }
{ "index": {}}
{ "price" : 2000, "color" : "��ɫ", "brand" : "����", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 8000, "color" : "��ɫ", "brand" : "����", "sold_date" : "2020-01-01" }
{ "index": {}}
{ "price" : 2500, "color" : "��ɫ", "brand" : "С��", "sold_date" : "2020-02-12" }
����1 ͳ��������ɫ�ĵ����������
GET /tvs/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
��ѯ��������
size:ֻ��ȡ�ۺϽ��,����Ҫִ�оۺϵ�ԭʼ����
aggs:�̶��,Ҫ��һ������ִ�з���ۺϲ���
popular_colors:���Ƕ�ÿ��aggs,��Ҫ��һ������,
terms:�����ֶε�ֵ���з���
field:����ָ�����ֶε�ֵ���з���
����
{
"took" : 18,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "��ɫ",
"doc_count" : 4
},
{
"key" : "��ɫ",
"doc_count" : 2
},
{
"key" : "��ɫ",
"doc_count" : 2
}
]
}
}
}
���ؽ������
hits.hits:����ָ����size��0,����hits.hits���ǿյ�
aggregations:�ۺϽ��
popular_color:����ָ����ij���ۺϵ�����
buckets:��������ָ����field���ֳ���buckets
key:ÿ��bucket��Ӧ���Ǹ�ֵ
doc_count:���bucket������,�ж��ٸ�����
����,��ʵ����������ɫ������
ÿ����ɫ��Ӧ��bucket�е����ݵ�Ĭ�ϵ��������:����doc_count��������
����2 ͳ��ÿ����ɫ����ƽ���۸�
GET /tvs/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
��һ��aggsִ�е�bucket����(terms),ƽ����json�ṹ��,�ټ�һ��aggs,����ڶ���aggs�ڲ�,ͬ��ȡ������,ִ��һ��metric����,avg,��֮ǰ��ÿ��bucket�е����ݵ�ָ����field,price field,��һ��ƽ��ֵ
����:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "��ɫ",
"doc_count" : 4,
"avg_price" : {
"value" : 3250.0
}
},
{
"key" : "��ɫ",
"doc_count" : 2,
"avg_price" : {
"value" : 2100.0
}
},
{
"key" : "��ɫ",
"doc_count" : 2,
"avg_price" : {
"value" : 2000.0
}
}
]
}
}
}
buckets,����key��doc_count
avg_price:�����Լ�ȡ��metric aggs������
value:���ǵ�metric����Ľ��,ÿ��bucket�е����ݵ�price�ֶ���ƽ��ֵ��Ľ��
�൱��sql: select avg(price) from tvs group by color
����3 �����������
ÿ����ɫ��,ƽ���۸�ÿ����ɫ��,ÿ��Ʒ�Ƶ�ƽ���۸�
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"color_avg_price": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
����4:�����metric
count:bucket,terms,�Զ��ͻ���һ��doc_count,���൱����count
avg:avg aggs,��ƽ��ֵ
max:��һ��bucket��,ָ��fieldֵ�����Ǹ�����
min:��һ��bucket��,ָ��fieldֵ��С���Ǹ�����
sum:��һ��bucket��,ָ��fieldֵ���ܺ�
GET /tvs/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} },
"sum_price" : { "sum": { "field": "price" } }
}
}
}
}
����5:���ַ�Χ histogram
GET /tvs/_search
{
"size" : 0,
"aggs":{
"price":{
"histogram":{
"field": "price",
"interval": 2000
},
"aggs":{
"income": {
"sum": {
"field" : "price"
}
}
}
}
}
}
histogram:������terms,Ҳ�ǽ���bucket�������,����һ��field,�������field��ֵ�ĸ�����Χ����,����bucket�������
"histogram":{
"field": "price",
"interval": 2000
}
interval:2000,���ַ�Χ,02000,20004000,40006000,60008000,8000~10000,buckets
bucket����֮��,һ����,ȥ��ÿ��bucketִ��avg,count,sum,max,min,�ȸ���metric����,�ۺϷ���
����6:�������ڷ���ۺ�
date_histogram,��������ָ����ij��date���͵�����field,�Լ�����interval,����һ�������ڼ��,ȥ����bucket
min_doc_count:��ʹij������interval,2017-01-01~2017-01-31��,һ�����ݶ�û��,��ô�������Ҳ��Ҫ���ص�,��ȻĬ���ǻ���˵���������
extended_bounds,min,max:����bucket��ʱ��,�����������ʼ����,�ͽ�ֹ������
GET /tvs/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2019-01-01",
"max" : "2020-12-31"
}
}
}
}
}
����7 ͳ��ÿ����ÿ��Ʒ�Ƶ����۶�
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_sold_date": {
"date_histogram": {
"field": "sold_date",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2019-01-01",
"max": "2020-12-31"
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
},
"total_sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
����8 :������ۺϽ��,��ѯij��Ʒ�ư���ɫ����
������ۺϿ��Խ��������
sql select count(*)
from tvs
where brand like ��%��%��
group by color
es aggregation,scope,�κεľۺ�,�����������������Ľ��������֮��,�������,���ǾۺϷ���������scope
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "��"
}
}
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
}
}
}
}
����9 global bucket:����Ʒ��������Ʒ�������Ա�
aggregation,scope,һ���ۺϲ���,������query�����������Χ��ִ��
�����������,һ�����,�ǻ���query����������ۺϵ�; һ�����,�Ƕ���������ִ�оۺϵ�
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "��"
}
}
},
"aggs": {
"single_brand_avg_price": {
"avg": {
"field": "price"
}
},
"all": {
"global": {},
"aggs": {
"all_brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
����10:����+�ۺ�:ͳ�Ƽ۸����1200�ĵ���ƽ���۸�
����+�ۺ�
����+�ۺ�
GET /tvs/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 1200
}
}
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
����11 bucket filter:ͳ��Ʒ�����һ���µ�ƽ���۸�
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "��"
}
}
},
"aggs": {
"recent_150d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-150d"
}
}
},
"aggs": {
"recent_150d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_140d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-140d"
}
}
},
"aggs": {
"recent_140d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_130d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-130d"
}
}
},
"aggs": {
"recent_130d_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
aggs.filter,��Ե��Ǿۺ�ȥ����
�����query�����filter,��ȫ�ֵ�,������е����ݶ���Ӱ��
����,���,����˵,��Ҫͳ��,�������,���1���µ�ƽ��ֵ; ���3���µ�ƽ��ֵ; ���6���µ�ƽ��ֵ
bucket filter:�Բ�ͬ��bucket�µ�aggs,����filter
����12 ����:��ÿ����ɫ��ƽ�����۶������
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_price": "asc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
�൱��sql�ӱ������ֶο�������ʹ�á�
����13 ����:��ÿ����ɫ��ÿ��Ʒ��ƽ�����۶������
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}