????????扑街前言:继续上篇的内容接着来,上两篇说了zk 的服务端的启动流程和每一个线程所做的具体事情,本次我们讨论一下服务端的读写事件。
????????继续上篇的内容,当代码最后走到ScheduledWorkRequest 线程中时,进行了真正的IO 操作,而这部分操作就是放在了NIOServerCnxn 类的doIO方法里面,先看代码。
? ? ? ? 可以看到的是读写事件进行了分别的监听,我们一点点的分析,但是在说流程之前还需要先思考一下之前关于Ntty 学习时,遇到的粘包和拆包问题,当时的解决方案就是自定义上层协议,先读出开头的4个字节,这个4个字节中就是后面真正信息的大小长度,然后根据中这个大小再读取完整信息,这样就可以简单解决粘包拆包问题,channel 和buffer 不再过多赘述了。其实zk 也是通过这种方式解决了粘包拆包问题,就是封装行比我们之前讨论的要好很多。
/**
* Handles read/write IO on connection.
*/
void doIO(SelectionKey k) throws InterruptedException {
try {
if (!isSocketOpen()) {
LOG.warn("trying to do i/o on a null socket for session: 0x{}", Long.toHexString(sessionId));
return;
}
//读事件
if (k.isReadable()) {
/**
* 从SocketChannel 中读取数据到 incomingBuffer(ByteBuffer)
* incomingBuffer初始分配的容量为4个字节
* rc为读取并写入到incomingBuffer中的字节数
*/
int rc = sock.read(incomingBuffer);
if (rc < 0) {
handleFailedRead();
}
if (incomingBuffer.remaining() == 0) { //如果incomingBuffer不剩余容量,表明已从socketchannel中读取了4个字节的数据
boolean isPayload;//是否有数据包的标识
if (incomingBuffer == lenBuffer) { // start of next request
incomingBuffer.flip();
/**
* 读取payload数据包的长度:真正数据的长度
* 判断是否真正有数据,每次请求过来,读取四个字节,如果读取之后没有后续的数据,说明很有可能是四字命令;这里是个小细节,要注意
*/
isPayload = readLength(k);
incomingBuffer.clear();
} else {
// continuation
isPayload = true;
}
if (isPayload) { // not the case for 4letterword
/**
* 如果有数据包,则按照已读取出来的长度去读取数据包的内容
*/
readPayload();
} else {
// four letter words take care
// need not do anything else
/**
* 注释翻译:四个字母的单词注意不用做其他任何事情
* 即4字命令,在前面readLength函数中已处理过了
*/
return;
}
}
}
//写事件 服务端处理完请求后发送响应数据
if (k.isWritable()) {
/**
* 将该连接outgoingBuffers队列 中的ByteBuffer数据写回socket
*/
handleWrite(k);
if (!initialized && !getReadInterest() && !getWriteInterest()) {
throw new CloseRequestException("responded to info probe", DisconnectReason.INFO_PROBE);
}
}
} catch (CancelledKeyException e) {
LOG.warn("CancelledKeyException causing close of session: 0x{}", Long.toHexString(sessionId));
LOG.debug("CancelledKeyException stack trace", e);
close(DisconnectReason.CANCELLED_KEY_EXCEPTION);
} catch (CloseRequestException e) {
// expecting close to log session closure
close();
} catch (EndOfStreamException e) {
LOG.warn("Unexpected exception", e);
// expecting close to log session closure
close(e.getReason());
} catch (ClientCnxnLimitException e) {
// Common case exception, print at debug level
ServerMetrics.getMetrics().CONNECTION_REJECTED.add(1);
LOG.warn("Closing session 0x{}", Long.toHexString(sessionId), e);
close(DisconnectReason.CLIENT_CNX_LIMIT);
} catch (IOException e) {
LOG.warn("Close of session 0x{}", Long.toHexString(sessionId), e);
close(DisconnectReason.IO_EXCEPTION);
}
}读事件流程
????????首先从socketChannel 中读取前4个字节,只有当这个4个字节读满的时,才会去读取真正的信息内容,在下面的readLength() 方法中zk 用读取到的前4个字节内容,也就是真正消息体的大小,验证能不能读取出zk 定义好的消息体(因为zk 命令有一种特殊的四字命令),如果可以读取到的话,就会在下面的readPayload() 方法中开始真正的读取消息体,如果读不满消息体的大小,那么就下次再继续读取,直到读取到的消息完整后,再通过readRequest() 方法调用ZookeeperServer 类中的processPacket(ServerCnxn cnxn, ByteBuffer incomingBuffer) 方法解析消息体,封装为request 对象,然后请求提交给处理器链处理。
/** Reads the first 4 bytes of lenBuffer, which could be true length or
* four letter word.
* 读取lenBuffer的前4个字节,可以是真正的长度或四个字母的单词。
* @param k selection key
* @return true if length read, otw false (wasn't really the length)
* @throws IOException if buffer size exceeds maxBuffer size
*/
private boolean readLength(SelectionKey k) throws IOException {
// Read the length, now get the buffer
/**
* 读取首部4个字节,其值为数据内容的长度
*/
int len = lenBuffer.getInt();
/**
* 校验发送过来的数据是否是4字命令,两种情况
* 1、4字命令的情况,首部4个字节就是4个单词的客户端命令;比如熟知的:stat命令,
* 而4字命令大都是打印一些服务指标,实现比较简单;更多4字命令见:https://www.runoob.com/w3cnote/zookeeper-sc-4lw.html
*
* 2、非4字命令的情况,首部4个字节代表了数据包的长度
*/
if (!initialized && checkFourLetterWord(sk, len)) {
return false;
}
/**
* 如果数据长度太长,抛出异常
*/
if (len < 0 || len > BinaryInputArchive.maxBuffer) {
throw new IOException("Len error. "
+ "A message from " + this.getRemoteSocketAddress() + " with advertised length of " + len
+ " is either a malformed message or too large to process"
+ " (length is greater than jute.maxbuffer=" + BinaryInputArchive.maxBuffer + ")");
}
if (!isZKServerRunning()) {
throw new IOException("ZooKeeperServer not running");
}
// checkRequestSize will throw IOException if request is rejected
zkServer.checkRequestSizeWhenReceivingMessage(len);
/**
* 根据读处理的len分配ByteBuffer
*/
incomingBuffer = ByteBuffer.allocate(len);
return true;
}
/** Read the request payload (everything following the length prefix) */
private void readPayload() throws IOException, InterruptedException, ClientCnxnLimitException {
if (incomingBuffer.remaining() != 0) { // have we read length bytes?
//按照前面获取到的大小读取数据包的数据
int rc = sock.read(incomingBuffer); // sock is non-blocking, so ok
if (rc < 0) {
handleFailedRead();
}
}
if (incomingBuffer.remaining() == 0) { // have we read length bytes?
incomingBuffer.flip();
packetReceived(4 + incomingBuffer.remaining());
/**
* 判断是否初始化,
* 一个请求到底是建立连接会话的还是后续的命令处理 从这里区分
*/
if (!initialized) {
readConnectRequest();//读取连接请求
} else {
/**
* 读取命令请求
*/
readRequest();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
}
}写事件流程
? ? ? ? 相对上面的读流程, 写流程就比较简单,当检测到写事件发生,就将该连接outgoingBuffers队列 中的ByteBuffer数据写回socket即可,使用的也是上面第一个代码中的handleWrite() 方法。handleWrite() 方法代码如下。
? ? ? ? 这段代码的目的上面就说清楚了outgoingBuffers队列 中的ByteBuffer数据写回socket,具体流程也没有什么说的,很简单,具体需要注意的一点就是,当数据回写给socket 之后,会将队列的中的存值删除,避免重复触发。
/**
* 真正将outgoingBuffers中的数据依次写回socket
* @param k
* @throws IOException
*/
void handleWrite(SelectionKey k) throws IOException {
if (outgoingBuffers.isEmpty()) {
return;
}
/*
* This is going to reset the buffer position to 0 and the
* limit to the size of the buffer, so that we can fill it
* with data from the non-direct buffers that we need to
* send.
*/
ByteBuffer directBuffer = NIOServerCnxnFactory.getDirectBuffer();
if (directBuffer == null) {
ByteBuffer[] bufferList = new ByteBuffer[outgoingBuffers.size()];
// Use gathered write call. This updates the positions of the
// byte buffers to reflect the bytes that were written out.
sock.write(outgoingBuffers.toArray(bufferList));
// Remove the buffers that we have sent
ByteBuffer bb;
while ((bb = outgoingBuffers.peek()) != null) {
if (bb == ServerCnxnFactory.closeConn) {
throw new CloseRequestException("close requested", DisconnectReason.CLIENT_CLOSED_CONNECTION);
}
if (bb == packetSentinel) {
packetSent();
}
if (bb.remaining() > 0) {
break;
}
outgoingBuffers.remove();
}
} else {
directBuffer.clear();
for (ByteBuffer b : outgoingBuffers) {
if (directBuffer.remaining() < b.remaining()) {
/*
* When we call put later, if the directBuffer is to
* small to hold everything, nothing will be copied,
* so we've got to slice the buffer if it's too big.
*/
b = (ByteBuffer) b.slice().limit(directBuffer.remaining());
}
/*
* put() is going to modify the positions of both
* buffers, put we don't want to change the position of
* the source buffers (we'll do that after the send, if
* needed), so we save and reset the position after the
* copy
*/
int p = b.position();
directBuffer.put(b);
b.position(p);
if (directBuffer.remaining() == 0) {
break;
}
}
/*
* Do the flip: limit becomes position, position gets set to
* 0. This sets us up for the write.
*/
directBuffer.flip();
int sent = sock.write(directBuffer); //将缓冲区的数据写入socket
ByteBuffer bb;
// Remove the buffers that we have sent
while ((bb = outgoingBuffers.peek()) != null) {
if (bb == ServerCnxnFactory.closeConn) {
throw new CloseRequestException("close requested", DisconnectReason.CLIENT_CLOSED_CONNECTION);
}
if (bb == packetSentinel) {
packetSent();
}
if (sent < bb.remaining()) {
/*
* We only partially sent this buffer, so we update
* the position and exit the loop.
*/
bb.position(bb.position() + sent);
break;
}
/* We've sent the whole buffer, so drop the buffer */
sent -= bb.remaining();
outgoingBuffers.remove();
}
}
}处理器链
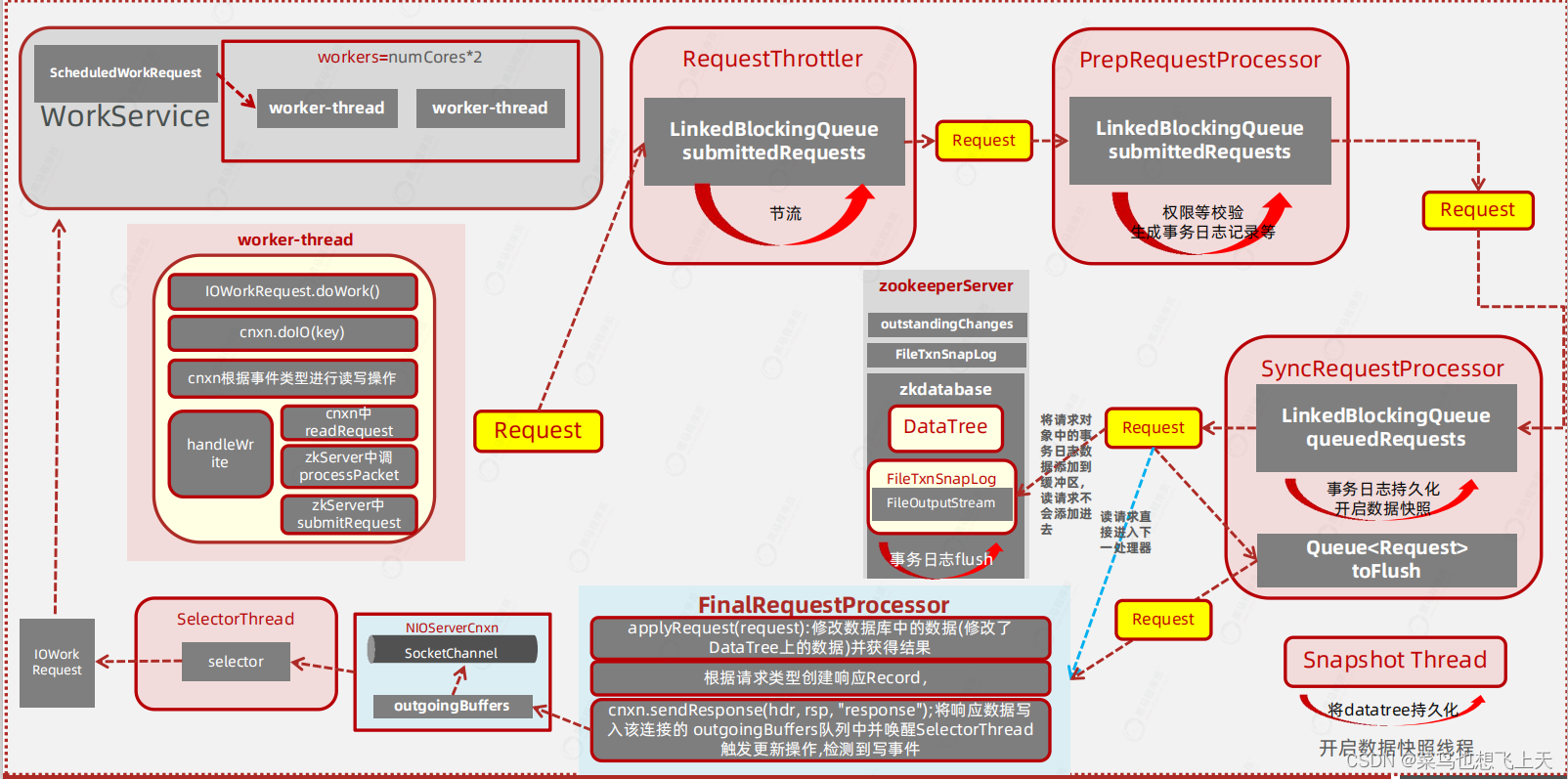
? ? ? ? 上面读事件进行最后是将请求提交了处理器链,那么什么是处理器链呢,先看下面的流程图。
? ? ? ? 从流程图中可以看出,当workService 类中workers 线程池找到了具体的ScheduleWorkRequest 线程执行读写监听之后,将request 对象提交给了RequestThrottler,然后是PrepRequestProcessor,然后是SyncRequestProcessor,最后是FinalRequestProcessor,后续就是会写的内容了。
? ? ? ? 这样就可以看出处理器链其实就是这四个不同类之间的流转组合。那我们先说下关于这个四个处理器之间的关系,然后就是这四个处理器是什么时候创建的。
????????
?创建和启动
? ? ? ? 在zk 系列文章的第一篇我有介绍zk 的主流程是怎么启动的,这里就不在赘述,现在可以看的是启动时有段代码cnxnFactory.startup(zkServer) 这个作用是启动zk 服务,这个可以跟到NIOServerCnxnFactory 类的startup 方法,这里最后有一段zks.startup() 的调用,这个的目的是:启动各组件开始工作: 各组件基本都独占一个线程。上代码。
? ? ? ? 很清楚的就可以看到启动处理器链的方法setupRequestProcessors(),这个方法中的内容也很简单,就是创建了一个类、两个线程并将他们关联在了一起,注意的是他们三个都是同一个父类RequestProcessor,他们分别是:FinalRequestProcessor 类、SyncRequestProcessor 线程、PrepRequestProcessor 线程,从代码中可以看到他们的创建顺序就是跟我目前列举的一样,但是在构建PrepRequestProcessor 线程的时候是将SyncRequestProcessor 线程就行了关联,SyncRequestProcessor线程是关联了FinalRequestProcessor 类,也就是他们的执行的先后顺序和创建顺序是相反的。
? ? ? ? 当处理器链创建关联好了之后,zk 继续创建了一个叫做RequestThrottler 的线程,它的作用就是为了zk 的限流。
public synchronized void startup() {
startupWithServerState(State.RUNNING);
}
/**
* 启动各个组件,开始工作
* @param state
*/
private void startupWithServerState(State state) {
if (sessionTracker == null) {
createSessionTracker();
}
/**
* 启动会话跟踪
*/
startSessionTracker();
/**
* 设置并启动请求处理器,RequestProcessor 并启动
*/
setupRequestProcessors();
/**
* 启动请求限流器
*/
startRequestThrottler();
registerJMX();
startJvmPauseMonitor();
registerMetrics();
setState(state);
requestPathMetricsCollector.start();
localSessionEnabled = sessionTracker.isLocalSessionsEnabled();
notifyAll();
}
protected void setupRequestProcessors() {
/**
* 设置并启动请求处理器链
* ------>PrepRequestProcessor------>SyncRequestProcessor------>FinalRequestProcessor
* 其中PrepRequestProcessor和SyncRequestProcessor 均未独立的线程
*/
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
protected void startRequestThrottler() {
/**
* RequestThrottler 是一个独立的线程
*/
requestThrottler = new RequestThrottler(this);
requestThrottler.start();
}触发和作用
? ? ? ? 从上面看,其实在zk 的主流程启动的时候,处理器链和限流线程就已经创建和启动了,那么在ScheduleWorkRequest 线程在真正处理读写事件的时候,就是直接将request 对象交给了他们,至于先交给了谁?以什么形式提交的?上代码。
? ? ? ? 当请求解析出来封装成request 对象之后,直接调用了ZookeeperServer 的submitRequest 方法,最后走了enqueueRequest 方法,下面代码中可以看到,首先是获取requestThrottler 线程,如果这个线程没有的话,就等一等,直到线程创建成功,之后调用该线程的submitRequest 方法,将request 请求对象添加到了名为submittedRequests 的LinkedBlockingQueue 队列中。ScheduleWorkRequest 线程到这里就已经结束了本次的任务了。后续的任务就是requestThrottler 线程的事情了。
? ? ? ? 还是跟之前一样,线程的话,先找run 方法,然后可以看到这里是从上面添加到的队列中获取到了任务,才开始执行的,注意的是,这里如果没有获取到任务会阻塞,直到获取到为止。这几个线程的代码都比较多,我就不在一句一句解读了,直接说作用。还有一点需要注意的就是这个三个线程之间的数据传输和线程触发都是使用的队列形式,原理跟requestThrottler 线程一样。
- RequestThrottler:限流,根据配置的需求开启,防止zk 同时访问量过大;
- PrepRequestProcessor:权限校验,生成事务日志记录等,这里提一个zk 的数据存储的简单概念:zk 的请求是要分类型的,比如set、del这些是事务请求,还有get 就是非事务请求,zk 对于事务请求跟mysql 是有点类似的,先生成事务日志,然后进行日志存储,最后再进行事务操作,后续如果操作失败了,就是根据记录的日志进行回滚。需要注意的就是当前线程做的只是生成事务日志记录,并没有存储;
- SyncRequestProcessor:这个线程就是为了将有事务日志的情况下,将事务日志进行存储,当存储完成之后再flush 到下个任务中,因为下个任务不是线程了,所以只能在这个线程中触发。同时呢,这个线程还会添加队列,开启Snapshot Thread 事务快照线程。
- FinalRequestProcessor:这一步就到了修改数据库,构建返回对象response 对象了,这里当返回对象构建完成之后,就会往outgoingBuffers 队列中写数据,这个队列就是写事件的触发队列了,这样整个流程就串通起来了。
public void enqueueRequest(Request si) {
if (requestThrottler == null) {
synchronized (this) {
try {
// Since all requests are passed to the request
// processor it should wait for setting up the request
// processor chain. The state will be updated to RUNNING
// after the setup.
/**
* 如上所述:requestThrottler是请求节流器,如果还未初始化完成,则等待启动服务器时的 setting up初始化请求处理器链
*/
while (state == State.INITIAL) {
wait(1000);
}
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption", e);
}
if (requestThrottler == null) {
throw new RuntimeException("Not started");
}
}
}
/**
* 提交请求Request对象到请求处理器的submittedRequests队列中
*/
requestThrottler.submitRequest(si);
}
private final LinkedBlockingQueue<Request> submittedRequests = new LinkedBlockingQueue<Request>();
public void submitRequest(Request request) {
if (stopping) {
LOG.debug("Shutdown in progress. Request cannot be processed");
dropRequest(request);
} else {
request.requestThrottleQueueTime = Time.currentElapsedTime();
/**
* 将请求对象添加到submittedRequests队列中
* submittedRequests是一个LinkedBlockingQueue
* 而 RequestThrottler 是一个独立的线程,直接来消费该队列中的请求数据即可
*/
submittedRequests.add(request);
}
}
@Override
public void run() {
try {
while (true) {
if (killed) {
break;
}
/**
* 从队列中获取一个请求对象 Request
*/
Request request = submittedRequests.take(); //阻塞获取
if (Request.requestOfDeath == request) {
break;
}
if (request.mustDrop()) {
continue;
}
// Throttling is disabled when maxRequests = 0
// 节流器工作时允许的未完成请求的最大数量。
if (maxRequests > 0) { //启用限流器
while (!killed) {
if (dropStaleRequests && request.isStale()) {
// Note: this will close the connection
dropRequest(request);
ServerMetrics.getMetrics().STALE_REQUESTS_DROPPED.add(1);
request = null;
break;
}
//在处理中的的请求数量低于maxRequests不作节流,否则进行限流,
if (zks.getInProcess() < maxRequests) {
break;
}
//节流的操作是 等待 stallTime 这么长时间,默认100毫秒
throttleSleep(stallTime);
}
}
if (killed) {
break;
}
// A dropped stale request will be null
if (request != null) {
if (request.isStale()) {
ServerMetrics.getMetrics().STALE_REQUESTS.add(1);
}
final long elapsedTime = Time.currentElapsedTime() - request.requestThrottleQueueTime;
ServerMetrics.getMetrics().REQUEST_THROTTLE_QUEUE_TIME.add(elapsedTime);
if (shouldThrottleOp(request, elapsedTime)) {
request.setIsThrottled(true);
ServerMetrics.getMetrics().THROTTLED_OPS.add(1);
}
/**
* 真正调用请求处理链处理该请求
*/
zks.submitRequestNow(request);
}
}
} catch (InterruptedException e) {
LOG.error("Unexpected interruption", e);
}
int dropped = drainQueue();
LOG.info("RequestThrottler shutdown. Dropped {} requests", dropped);
}? ? ? ? 总结一下,上面基本就是zk 对于读写事件的一个处理,还有就是zk 本身内容信息的一个流转,虽然最后的时候我没有详细再展示处理器链中每一个处理器的代码,但是具体操作和流程图其实就可以看出大体的东西,再后面的代码就得慢慢扣了,这个再深究就讲不完了。
? ? ? ? 后续zk 还有最后一篇文章,目前所有说的就是单点模式下的内容,最后一篇我们在讨论一下集成模式下的zk。