����:kafka �ͻ���֮producer API������Ϣ�Լ���Դ�����
��Kafka 0.11��ʼ,KafkaProducer��֧������ģʽ:�ݵ������ߺ����������ߡ��ݵ�������ǿ��Kafka�Ľ�������,������һ�ν�������ȷһ�ν������ر��������ߵ����Խ����������ظ�������������������Ӧ�ó���ԭ�ӵؽ���Ϣ���͵��������(������)��
�ݵ���
Kafka�� 0.11 �汾������һ���ش�����,�ݵ��ԡ���ν���ݵ��Ծ���ָ Producer ������ Server ���Ͷ��ٴ��ظ�����,Server �˶�ֻ��־û�һ����
�� http ������˵,һ�λ�������,�õ�����Ӧ��һ�µ�(���糬ʱ���������),���仰˵,����ִ�ж�β�����ִ��һ�β�����Ӱ����һ���ġ�
���,ij��ϵͳ�Dz��߱��ݵ��Ե�,����û��ظ��ύ��ij������,�Ϳ��ܻ���ɲ���Ӱ�졣����:�û���������ϵ���˶���ύ������ť,���ں�̨���ɶ��һģһ���Ķ�����
�ݵ��Ի���ԭ��
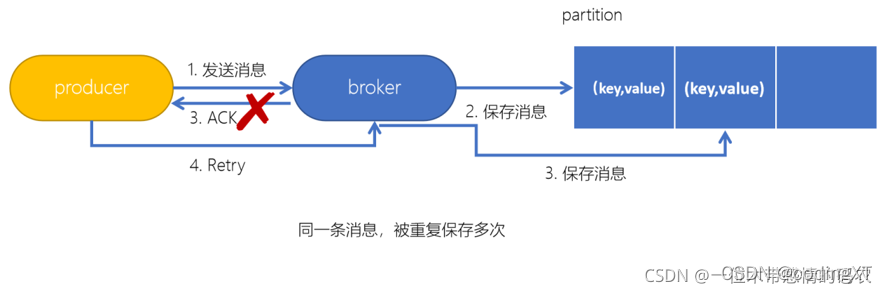
����Kafka��˵,Ҫ������������߷�����Ϣ���ݵ����⡣��������������Ϣʱ,������� retry ʱ,�п��ܻ�һ����Ϣ�������˶��,���Kafka���߱��ݵ��Ե�,���п��ܻ���partition�б������һģһ������Ϣ��
Ϊ��ʵ�������ߵ��ݵ���,Kafka ������ Producer ID(PID)�� Sequence Number �ĸ��
- PID:ÿ�� Producer �ڳ�ʼ��ʱ,�������һ��Ψһ�� PID,��� PID ���û���˵,������
- Sequence Number:���ÿ��������(��Ӧ PID )���͵�ָ�������������Ϣ����Ӧһ���� 0 ��ʼ������ Sequence Number,Server �˾��Ǹ������ֵ���ж������Ƿ��ظ�
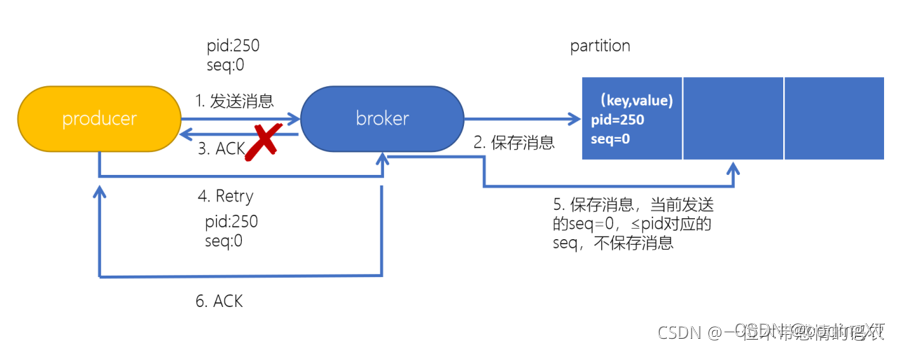
producer��ʼ������server������һ��PID,Ȼ����ÿ����Ϣ��������PID��sequence number,��server��,�ǰ���partitionͬ�����һ��sequence numbers ��Ϣ,ͨ���жϿͻ��˷�������sequence number��server��number+1��ֵ�����������Ƿ��ظ�����©����
�� Producer ������Ϣ�� Broker ʱ,Broker ���յ���Ϣ�������ӵ���Ϣ���С���ʱ,Broker ���� Ack �źŸ� Producer ʱ,�����쳣���� Producer ���� Ack �ź�ʧ�ܡ����� Producer ��˵,�ᴥ�����Ի���,����Ϣ�ٴη���,����,�����������ݵ���,��ÿ����Ϣ�и����� PID(Producer ID)��Sequence Number����ͬ�� PID �� Sequence Number ���� Broker,��֮ǰ Broker �����֮ǰ���͵���ͬ����Ϣ,��ô����Ϣ���е���Ϣ��ֻ��һ��,��������ظ����͵������
����PID������
//��ִ�д�������ʱ
Producer<String, String> producer = new KafkaProducer<String, String>(props);
//�ᴴ��һ��Sender,�������߳�,ִ������run����
Sender{
void run(long now) {
if (transactionManager != null) {
try {
........
if (!transactionManager.isTransactional()) {
// Ϊidempotent producer����һ��producer id
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
ΪʲôҪ�� MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION С�ڵ���5
ͨ�������Ϊ�˱�֤����˳����,���ǿ���ͨ��MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1����֤,���Ҳֻ����Ե�ʵ������kafka2.0+�汾��,ֻҪ�����ݵ���,���������������Ҳ�ܱ�֤�������ݵ�˳���ԡ�
��ʵ����,Ҫ�� MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION С�ڵ��� 5 ����Ҫԭ����:Server �˵� ProducerStateManager ʵ���Ỻ��ÿ�� PID ��ÿ�� Topic-Partition �Ϸ��͵���� 5 ��batch ����(��� 5 ��д����,����Ϊʲô�� 5,���ܸ������й�,���������ݵ���ʱ,���������Ϊ 5 ʱ,���������˵�ϸ�,��������һ����ز����ĵ�),������� 5,ProducerStateManager �ͻὫ��ɵ� batch ���������
����Ӧ�ý� MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION ����Ϊ 6,���跢�͵�����˳���� 1��2��3��4��5��6,��ʱ�� server ��ֻ�ܻ��� 2��3��4��5��6 �����Ӧ�� batch ����,��ʱ��������� 1 ����ʧ��,��Ҫ����,�����Ե�����������,�����ȼ���Ƿ�Ϊ�ظ��� batch,��ʱ����Ľ���Ƿ�,֮��Ὺʼ check �� sequence number ֵ,��ʱ��ֻ�᷵��һ�� OutOfOrderSequenceException �쳣,client ���յ�����쳣��,���ٴν�������,ֱ������������Դ������߳�ʱ,����������Ӱ�� Producer ����,�����ܸ� Server ����ѹ��(�൱��client ��������)��
�ݵ��Ե�ע������
- �ݵ��� Producer ֻ�ܱ�֤�������ϵ��ݵ���:��ֻ�ܱ�֤ij�������ϵ�һ�������ϲ������ظ���Ϣ,��ʵ�ֶ���������ݵ���
- �ݵ��� Producer ֻ��ʵ�ֵ��Ự�ϵ��ݵ���,����ʵ�ֿ�Ự���ݵ���
�Ự:Producer ���̵�һ������,������� Producer ����,����ʧ�ݵ��Ա�֤
�����ݵ���
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);
Ҫ�����ݵ�(idempotence),���뽫enable.idempotence��������Ϊtrue�� �������,��retries(����)���ý�Ĭ��ΪInteger.MAX_VALUE,acks���ý�Ĭ��Ϊall,������ԵĽ�acks����Ϊ0,-1,��ô���ᱨ����
����,���send(ProducerRecord)��ʹ���������Ե������Ҳ�᷵�ش���(������Ϣ�ڷ���ǰ�ڻ������й���),��ô����ر�������,���������������Ϣ������,��ȷ�������ظ������,������ֻ�ܱ�֤�����Ự�ڷ��͵���Ϣ���ݵ��ԡ�
Exactly Once����
���������� ACK ��������Ϊ-1,���Ա�֤ Producer �� Server ֮�䲻�ᶪʧ����,�� At Least Once(����һ��) ���塣��Ե�,�������� ACK ��������Ϊ 0,���Ա�֤������ÿ����Ϣֻ�ᱻ����һ��,��At Most Once(���һ��) ���塣
At Least Once ���Ա�֤���ݲ���ʧ,���Dz��ܱ�֤���ݲ��ظ�;��Ե�,At Most Once ���Ա�֤���ݲ��ظ�,���Dz��ܱ�֤���ݲ���ʧ������,����һЩ�dz���Ҫ����Ϣ,����˵��������,��������������Ҫ�����ݼȲ��ظ�Ҳ����ʧ,�� Exactly Once(�պ�һ��) ���塣�� 0.11 �汾��ǰ�� Kafka,�Դ�������Ϊ����,ֻ�ܱ�֤���ݲ���ʧ,�������������߶�������ȫ��ȥ�ء����ڶ������Ӧ�õ����,ÿ������Ҫ������ȫ��ȥ��,��Ͷ���������˺ܴ�Ӱ�졣
0.11 �汾�� Kafka,������һ���ش�����:�ݵ��ԡ��ݵ��Խ�� At Least Once ����,������ Kafka ��Exactly Once ���塣��:
At Least Once + �ݵ��� = Exactly Once
Kafka ���ݵ���ʵ����ʵ���ǽ�ԭ��������Ҫ����ȥ�ط������������Ρ�
����
�ݵ��Բ����ܿ�����������,����������ֲ����ȱ�ݡ�Kafka ������ 2017 �� Kafka 0.11 ����������ԡ����������ݿ������Kafka ����ָ������ Exactly Once ����Ļ�����,���������ѿ��Կ�����ͻỰ,������������Ϣ�Լ��������ύ offset �IJ���������һ��ԭ�Ӳ�����,Ҫô���ɹ�,Ҫô��ʧ�ܡ��������������ߡ������߲���ʱ,����ı���������Ҫ��(consumer-transform-producerģʽ)
�������ύƫ���������ظ�������Ϣ�ij���:��������������Ϣ����ύƫ����o2֮ǰ�ҵ���(����������ύ��ƫ������o1),��ʱִ���پ���ʱ,�����������ظ�������Ϣ(o1��o2֮�����Ϣ)��
�����Ӧ�����
��һ��ԭ�Ӳ�����,���ݰ����IJ�������,���Է�Ϊ�������:
- ֻ��Producer������Ϣ;
- ������Ϣ��������Ϣ����,�������������õ����,�������dz�˵�ġ�consume-transform-produce ��ģʽ
- ֻ��consumer������Ϣ
ǰ�����������������ij���,���һ�����û��ʹ�ü�ֵ(��ʹ���ֶ��ύЧ��һ��)��
�����������
ʹ��kafka������API ʱ��һЩע������:
- ��Ҫ�����ߵ��Զ�ģʽ����Ϊfalse,���Ҳ��������ֶ��Ľ���ִ��consumer#commitSync����consumer#commitAsyc
- ����������transaction.id����
- �����߲���Ҫ������enable.idempotence,��Ϊ���������transaction.id,���ʱenable.idempotence�ᱻ����Ϊtrue
- ��������Ҫ����Isolation.level����consume-trnasform-produceģʽ��ʹ������ʱ,��������ΪREAD_COMMITTED��
Producer����
Ϊ��ʵ�ֿ������Ự������,��Ҫ����һ��ȫ��Ψһ�� Transaction ID,���� Producer ��õ� PID �� Transaction ID �������� Producer ������Ϳ���ͨ�����ڽ��е�Transaction ID ���ԭ����PID��
Ϊ�˹��� Transaction,Kafka ������һ���µ���� Transaction Coordinator��Producer ����ͨ���� Transaction Coordinator ������� Transaction ID ��Ӧ������״̬��Transaction Coordinator ��������������д�� Kafka ��һ���ڲ� Topic,������ʹ������������,��������״̬�õ�����,�����е�����״̬���Եõ��ָ�,�Ӷ��������С�
Ҫʹ�����������ߺ�attendant API,��������transactional.id�����������transactional.id,�ݵ��Ի���ݵ�������������������һ���Զ����á�����,Ӧ�ö����������е�topic�����;������á��ر���,replication.factorӦ��������3,������Щtopic��min.insync.replicasӦ������Ϊ2�����,Ϊ��ʵ�ִӶ˵��˵������Ա�֤,������Ҳ��������Ϊֻ��ȡ���ύ����Ϣ��
transactional.id��Ŀ����ʵ�ֵ���������ʵ���Ķ���Ự֮�������ָ�����ͨ�����ɷ�������״̬��Ӧ�ó����еķ�Ƭ��ʶ�������ġ����,�������ڷ���Ӧ�ó��������е�ÿ��������ʵ����˵Ӧ����Ψһ�ġ�
�����µ�������API����������,���һ���ʧ��ʱ�׳��쳣��
Producer�ӿ����й�����ķ�������
//producer�ṩ������
/**
* ��ʼ��������Ҫע�����:
* 1��ǰ��
* ��Ҫ��֤transation.id���Ա����á�
* 2���������ִ������:
* (1)Ensures any transactions initiated by previous instances of the producer with the same
* transactional.id are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion,
* but not yet finished, this method awaits its completion.
* (2)Gets the internal producer id and epoch, used in all future transactional
* messages issued by the producer.
*
*/
public void initTransactions();
/**
* ��������
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* Ϊ�������ṩ�����������ύƫ�����IJ���
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException ;
/**
* �ύ����
*/
public void commitTransaction() throws ProducerFencedException;
/**
* ��������,���ƻع�����IJ���
*/
public void abortTransaction() throws ProducerFencedException ;
����������
����transactional.id����
public static Producer<String, String> createProducer() {
Properties properties = new Properties();
//�����ļ�����ı������Ǿ�̬final���͵�,���Ҷ���Ĭ�ϵ�ֵ
//���ڽ����� kafka ��Ⱥ���ӵ� host/port
//�̳е�hashtable,��֤���̰߳�ȫ
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"IP:9092");
/**
* producer ����ͼ��������Ϣ��¼,�Լ�������������⽫���� client �� server ֮������ܡ��������ÿ���Ĭ�ϵ�����������Ϣ�ֽ�����
* ������ͼ������������ֽ�������Ϣ�ֽ��������͵� brokers �������������������,���л������ÿ�� partition ��һ������
* ��С������������ֵ�Ƚ�����,���ҿ��ܽ���������(0 ��������������)���ϴ������������ֵ�����˷Ѹ����ڴ�ռ�,��������Ҫ������
* ������������ֵ���ڴ��С
**/
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384");
/**
* producer �齫������κ��������뷢��֮�䵽�����Ϣ��¼һ����������������ͨ����˵,��ֻ���ڼ�¼�����ٶȴ��ڷ����ٶȵ�ʱ���
* �ܷ�����Ȼ��,��ijЩ������,�ͻ��˽�ϣ���������������,�������͵��еȸ���һ�¡��������ý�ͨ������С���ӳ������--��,��������
* ����һ����¼,producer ����ȴ��������ӳ�ʱ��������������Ϣ��¼����,��Щ��Ϣ��¼���������������������Ϊ�� TCP �� Nagle ����
* �����ơ����������趨�����������ĸ��ߵ��ӳٱ߽�:һ�����ǻ��ij�� partition ��batch.size,�������������Ͷ�������������,
* Ȼ��������ǻ����Ϣ�ֽ�������������ҪС�Ķ�,������Ҫ��linger���ض���ʱ���Ի�ȡ�������Ϣ�� �������Ĭ��Ϊ 0,��û���ӳ١���
* �� linger.ms=5,����,�������������Ŀ,����ͬʱ������ 5ms ���ӳ�
**/
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
/**
* producer ���������������ݵ��ڴ��С��������ݲ����ٶȴ����� broker ���͵��ٶ�,����ľ��������ռ�,producer
* �����������׳��쳣,�ԡ�block.on.buffer.full�����������������ý��� producer �ܹ�ʹ�õ����ڴ����,��������һ��
* Ӳ�Ե�����,��Ϊ����producer ʹ�õ������ڴ涼�����ڻ��档һЩ������ڴ������ѹ��(�������ѹ������),ͬ������һЩ
* ����ά��������ռ�ľ�,�������͵��ý�������,����ʱ�����ֵͨ��max.block.ms�趨,֮�������׳�һ��TimeoutException��
**/
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432");
/**
* �����ÿ��� KafkaProducer's send(),partitionsFor(),inittransaction (),sendOffsetsToTransaction(),commitTransaction() "
* ��abortTransaction()����������������send(),�˳�ʱ�����˻�ȡԪ���ݺͷ��仺�������ܵȴ�ʱ��"
**/
properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG,"5000");
//����Ϣ���͵�kafka server, ���Կ϶���Ҫ�õ����л��IJ��� ��������͵���Ϣ��string���͵�,����ʹ��string�����л���
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//��������ID ���������transactional.id����,��enable.idempotence �ᱻ����Ϊtrue.
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"my-transactional-id");
return new KafkaProducer<>(properties);
}
����������
- �������е��Զ��ύ����(auto.commit)���йر�
- �����ڴ�������Ҳ����ʹ���ֶ��ύcommitSync( )����commitAsync( )
- ����isolation.level
/**
* ��Ҫ:
* 1���ر��Զ��ύ enable.auto.commit
* 2��isolation.levelΪ read_committed
* @return
*/
public static Consumer createConsumer() {
Properties properties = new Properties();
// bootstrap.servers��Kafka��Ⱥ��IP��ַ�����ʱ,ʹ�ö��Ÿ���
properties.put("bootstrap.servers", "IP:9092");
// ������Ⱥ��
properties.put("group.id", "groupxt");
// ���ø��뼶��
properties.put("isolation.level","read_committed");
// �ر��Զ��ύ
properties.put("enable.auto.commit", "false");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(properties);
}
ֻ��Producer������Ϣ
/*
Producer�첽���ʹ��ص�����(����) ��һ������ֻ��������Ϣ����
*/
public static void onlyProduceInTransaction(){
Producer<String,String> producer = ProducerTransaction.createProducer();
// 1.��ʼ������
producer.initTransactions();
try {
// 2.��������
producer.beginTransaction();
// 3.kafka�������
// 3.1 doҵ����
// 3.2 ������Ϣ
// ��Ϣ���� - ProducerRecoder
for(int i=0;i<10;i++){
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i);
//���Ƕഫ��һ���ص�ʵ��
/**
* �û�����ʵ�ֵĻص��ӿ�,�������������������ʱִ�С� ����ص�ͨ�����ں�̨ I/O �߳���ִ��,������Ӧ�úܿ졣
**/
producer.send(record, new Callback() {
/**
* �û�����ʵ�ֵĻص�����,���ṩ��������ɵ��첽������ �����͵��������ļ�¼��ȷ��ʱ,�����ô˷����� ���ص��е��쳣��Ϊ��ʱ,Ԫ���ݽ������� topicPartition ֮��������ֶε����� -1 ֵ,�⽫����Ч�ġ�
* ����:
* metadata �C �ѷ��ͼ�¼��Ԫ����(��������ƫ����)�� �����������,�����س� topicPartition ֮�����������ֶζ�Ϊ-1�� ��Ԫ����,
* exception �C �ڴ����˼�¼�ڼ��������쳣�� ���û�з�������,��Ϊ Null��
* �����׳����쳣����: ���������쳣(����,��Զ���ᷢ����Ϣ):
* InvalidTopicException OffsetMetadataTooLargeException RecordBatchTooLargeException RecordTooLargeException UnknownServerException UnknownProducerIdException InvalidProducerEpochException
* �������쳣(����ͨ������retries������): CorruptRecordException InvalidMetadataException NotEnoughReplicasAfterAppendException NotEnoughOutReplicasException Offset
**/
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(
"partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset());
}
});
}
// 3.3 do����ҵ����,�����Է�������topic����Ϣ��
// 4.�����ύ
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 5.��������
producer.abortTransaction();
}finally{
// ���е�ͨ������Ҫ�ر� close������Ὣ�������״̬��Ϊ�ر�,����io�߳̽��ڴ��е����ݷ���broker,�����������Ľ���ͻȻ�ҵ�,Ȼ���ڴ��������Ϣ��ʧ,�����������������ʱ��,����Ϣ���ݶ����ͳ�ȥ
producer.close();
}
}
ֻ��consumer������Ϣ
/**
* ��һ������ֻ����Ϣ����
*/
public static void onlyConsumeInTransaction() {
// 1.�����ϲ���
Producer<String,String> producer = ProducerTransaction.createProducer();
// 2.��ʼ������(����productId),����һ��������,ֻ��ִ��һ�γ�ʼ���������
producer.initTransactions();
// 3.���������ߺͶ�������
Consumer consumer = createConsumer();
consumer.subscribe(Arrays.asList("xt"));
while (true) {
// 4.��������
producer.beginTransaction();
// 5.1 ������Ϣ
Duration duration = Duration.ofMillis(500);
ConsumerRecords<String, String> records = consumer.poll(duration);
try {
// 5.2 doҵ����;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 ������Ϣ print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 5.2.2 ��¼�ύƫ����
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
}
// 6.�ύƫ����
producer.sendOffsetsToTransaction(commits, "groupxt");
// 7.�����ύ
producer.commitTransaction();
}catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 8.��������
System.out.println(e.getMessage());
producer.abortTransaction();
}finally{
producer.flush();
}
}
}
������Ϣ��������Ϣ����(consume-transform-produce)
��һ��������,����������Ϣ��������������Ϣ����,����˵��Consume-tansform-produceģʽ������ʵ������
/**
* ��һ��������,����������Ϣ����������Ϣ
*/
public static void consumeTransferProduce() {
// 1.�����ϲ���
Producer<String,String> producer = ProducerTransaction.createProducer();
// 2.��ʼ������(����productId),����һ��������,ֻ��ִ��һ�γ�ʼ���������
producer.initTransactions();
// 3.���������ߺͶ�������
Consumer consumer = createConsumer();
consumer.subscribe(Arrays.asList("xt"));
while (true) {
// 4.��������
producer.beginTransaction();
// 5.1 ������Ϣ
Duration duration = Duration.ofMillis(5000);
ConsumerRecords<String, String> records = consumer.poll(duration);
System.out.println(records.count());
try {
// 5.2 doҵ����;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 ��ȡ��Ϣ,��������Ϣ��print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 5.2.2 ��¼�ύ��ƫ����
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
// 6.�����µ���Ϣ��������������״̬����Ϣ,��������ɹ�,����Ҫ�����̼ҽ�ת��Ϣ��������Ա�������Ϣ
producer.send(new ProducerRecord<String, String>("xt", "data"));
}
// 7.�ύƫ����
producer.sendOffsetsToTransaction(commits, "groupxt");
// 8.�����ύ
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 7.��������
producer.abortTransaction();
}finally{
producer.flush();
}
}
}
Consumer����
�������������Ҫ�Ǵ� Producer ���濼��,���� Consumer ����,����ı�֤�ͻ���Խ���,����������֤ Commit ����Ϣ����ȷ���ѡ��������� Consumer ����ͨ�� offset ����������Ϣ,���Ҳ�ͬ�� Segment File �������ڲ�ͬ,ͬһ�������Ϣ���ܻ����������ɾ���������
��������ļ��ֶ�
Broker configs
| ������ | ���� |
|---|---|
| transactional.id.timeout.ms | transaction coordinatorû�д�������������յ��κ�����״̬���µĵȴ�ʱ��, ����ʱ��֮���������ʹ�����ߡ� Transactional Id����Ĭ��Ϊ604800000(7��)��������������ÿ�ܶ��ڹ�����ά�����ǵ�id |
| max.transaction.timeout.ms | �������������ʱʱ�䡣 ����ͻ������������ʱ�䳬�����ֵ,��ôbroker����InitPidRequest�з���һ��InvalidTransactionTimeout��������Է�ֹ�ͻ��˳�ʱʱ�����,����ᵼ�¿ͻ���ȡ�����а�����Topic ʱ����ͣ�١� Ĭ��Ϊ900000(15����)��������Ҫ����������Ϣ��ʱ��ı������ޡ� |
| transaction.state.log.replication.factor | ����״̬����ĸ���������Ĭ��Ϊ3 |
| transaction.state.log.num.partitions | ����״̬����ķ�������Ĭ��Ϊ50 |
| transaction.state.log.min.isr | ����״̬�����ÿ��������Ҫ�������ߵ�insync��������С������Ĭ��Ϊ2 |
| transaction.state.log.segment.bytes | ����״̬����Ķδ�С��Default: 104857600 bytes. |
Producer configs
| ������ | ���� |
|---|---|
| enable.idempotence | �Ƿ������ݵ�(Ĭ��Ϊfalse)�� �������,�����߽�������PID�ֶ�����������͵�ǰ�����߽��������С�ע��,Ϊ��ʹ������,���������ݵ��ԡ����ݵ�������ʱ,����ǿ��acks=all,retries > 1,����max. flight.requests.per.connection=1�� �����Щ����û����Щֵ,���ǾͲ��ܱ�֤�ݵ��ԡ� �����Щ����û�б�Ӧ�ó�����ʽ����,���ݵȹ�������ʱ,�����߽�����acks=all, retries=Integer.MAX_VALUE, max.inflight.requests.per.connection=1 |
| transaction.timeout.ms | ����Э������������ֹ���ڽ��е�����֮ǰ,�ȴ�����״̬���µ��ʱ��,�������ֵ����InitPidRequestһ���͵�����Э������ �����ֵ���ڴ��������õ�max.transaction.timeout.ms,������ʧ��,������InvalidTransactionTimeout���� Ĭ����60000ms����ʹ�����������������ѳ���һ����,����ʵʱӦ����ͨ���������ġ� |
| transactional.id | ����������TransactionalId�� ��֧�ֿ��������Ự�Ŀɿ�������,��Ϊ�������ͻ��˱�֤ʹ����ͬTransactionalId�������������κ�������֮ǰ�Ѿ���ɡ� ���û���ṩTransactionalId,��ô�����߽�������Ϊ�ݵȽ����� ���������transactional.id����,��enable.idempotence �ᱻ����Ϊtrue. |
Consumer configs
| ������ | ���� |
|---|---|
| isolation.level | (default is read_uncommitted) read_uncommitted:����ƫ����˳��ʹ�����ύ��δ�ύ����Ϣ�� read_committed:ֻʹ�÷���������Ϣ��ƫ��˳���ύ����������Ϣ��Ϊ�˱���ƫ��˳��,���������ζ�����DZ������������л�����Ϣ,ֱ�����ǿ������������е�������Ϣ�� |
�ݵ��Ժ������ԵĹ�ϵ
��������ʵ��ǰ�����ݵ���,����������������transaction idʱ,���뻹�������ݵ���;�����ݵ����ǿ��Զ���ʹ�õ�,����Ҫ�����������ԡ�
- �ݵ���������Porducer ID
- ��������������Transaction Id����
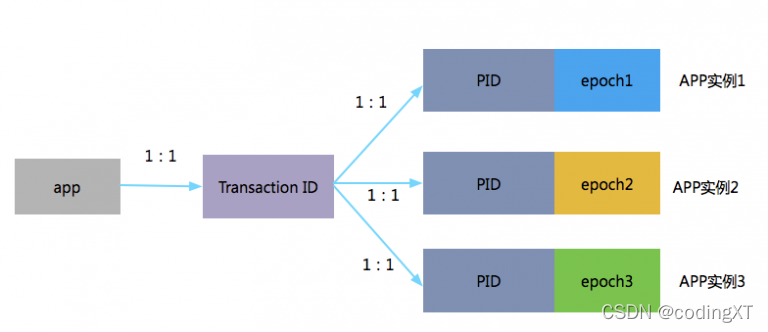
transactionalId ��producerId �� producerEpoch

һ��app��һ��tid,ͬһ��Ӧ�õIJ�ͬʵ��PID��һ����,ֻ��epoch��ֵ��ͬ��
����ͬһ������ID,�ȱ�֤epochС��producerִ��init-transaction��committransaction,Ȼ��epoch�ϴ��procuder���ܿ�ʼִ��init-transaction��commit-transaction,����˳��:
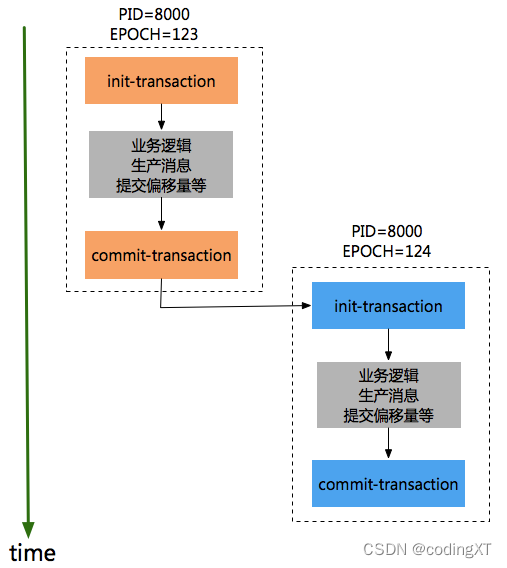
����transactionId��,Kafka�ɱ�֤:
��Session�������ݵȷ��͡���������ͬTransaction ID���µ�Producerʵ���������ҹ���ʱ,�ɵ���ӵ����ͬTransaction ID��Producer�����ٹ�����kafka��֤�˹���ͬһ�����������producer(һ��Ӧ���ж��ʵ��)���밴��˳���ʼ�������ύ����,����ͻ�������,�Ᵽ֤��ͬһ����ID����Ϣ�������(��ͬʵ���ð�˳��������ύ����)��
spring-kafka����������
kafka�ǿ�Session�������ݵȷ���,�����Ӧ�ò�����ʵ��ʱ����������org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer��s transaction has been expired by the broker.��,���뱣֤��Щʵ�������ߵ��ύ����˳��ʹ���˳��һ�²ſ���,��������ɹ�����ʵ,��ʵ����,���Ǹ���������ʵ�ֶ�Ӧ�õ�ʵ���������ԡ�����ͨ��spring-kafakaʵ��˼·��ѧϰ,��ÿ�δ��������߶�����һ����ͬ��transactionId��ֵ,���´���:
====================================
����:ProducerFactoryUtils
====================================
/**
* Obtain a Producer that is synchronized with the current transaction, if any.
* @param producerFactory the ConnectionFactory to obtain a Channel for
* @param <K> the key type.
* @param <V> the value type.
* @return the resource holder.
*/
public static <K, V> KafkaResourceHolder<K, V> getTransactionalResourceHolder(
final ProducerFactory<K, V> producerFactory) {
Assert.notNull(producerFactory, "ProducerFactory must not be null");
// 1.����ÿһ���̻߳�����һ��Ψһkey,Ȼ�����keyȥ����resourceHolder
@SuppressWarnings("unchecked")
KafkaResourceHolder<K, V> resourceHolder = (KafkaResourceHolder<K, V>) TransactionSynchronizationManager
.getResource(producerFactory);
if (resourceHolder == null) {
// 2.����һ��������
Producer<K, V> producer = producerFactory.createProducer();
// 3.��������
producer.beginTransaction();
resourceHolder = new KafkaResourceHolder<K, V>(producer);
bindResourceToTransaction(resourceHolder, producerFactory);
}
return resourceHolder;
}
��spring-kafka��,����һ���̴߳���һ��producer,�����ύ֮��,����ر����producer�����,����ͬһ���̻߳����µ��߳�����ִ������ʱ,��ʱ�ͻ����´���producer��
���������ߴ���
====================================
����:DefaultKafkaProducerFactory
====================================
protected Producer<K, V> createTransactionalProducer() {
Producer<K, V> producer = this.cache.poll();
if (producer == null) {
Map<String, Object> configs = new HashMap<>(this.configs);
// ����ÿһ������producerʱ,������һ����ͬ��transactionId
configs.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,
this.transactionIdPrefix + this.transactionIdSuffix.getAndIncrement());
producer = new KafkaProducer<K, V>(configs, this.keySerializer, this.valueSerializer);
// 1.��ʼ��������
producer.initTransactions();
return new CloseSafeProducer<K, V>(producer, this.cache);
}
else {
return producer;
}
}
Consume-transform-Produce ������ͼ
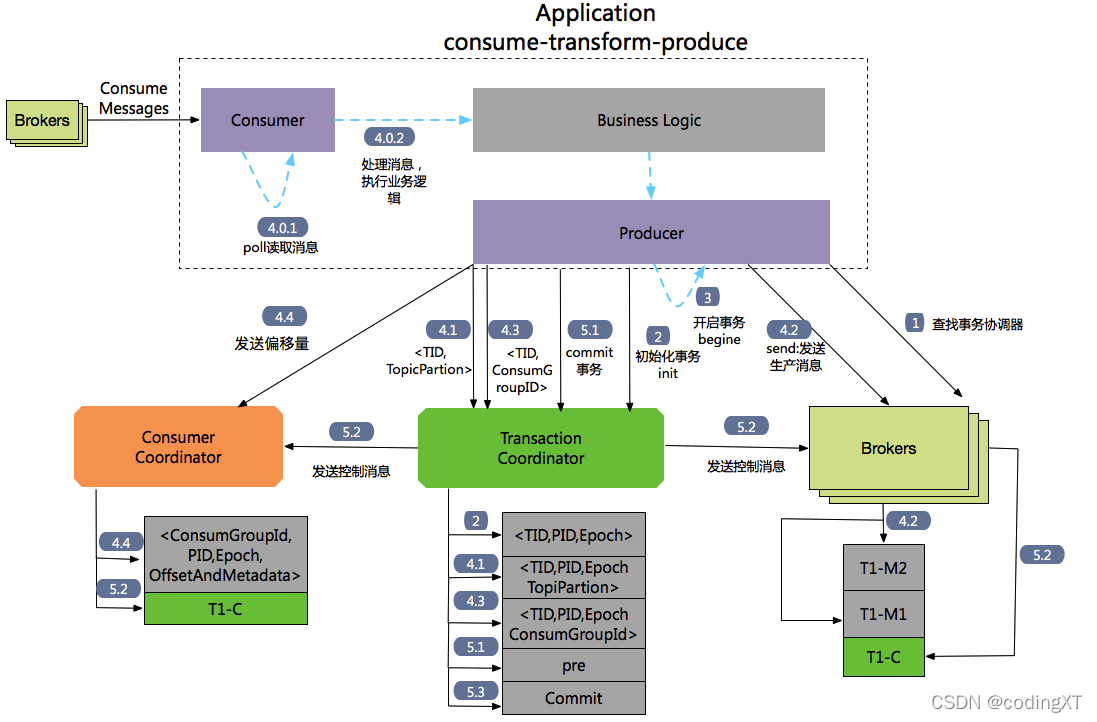
����1 :����Tranaction Corordinator��
Producer������һ��brokers���� FindCoordinatorRequest��������ȡTransaction Coordinator�ĵ�ַ��
����2:��ʼ������ initTransaction
Producer����InitpidRequest������Э����,��ȡһ��Pid��InitpidRequest�Ĵ���������ͬ��������,һ���õ�����ȷ����,Producer�Ϳ��Կ�ʼ�µ�����TranactionalIdͨ��InitpidRequest����Tranciton Corordinator,Ȼ����Tranaciton Log�м�¼��<TranacionalId,pid>��ӳ���ϵ�����˷���PID֮��,���������¹���:
��PID��Ӧ��epoch���е���,�������Ա�֤ͬһ��app�IJ�ͬʵ����Ӧ��PID��һ����,����epoch�Dz�ͬ�ġ�
�ع�֮ǰ��Producerδ��ɵ�����(�����)
����3: ��ʼ����beginTransaction
ִ��Producer��beginTransacion(),����������Producer�ڱ��ؼ�¼�����transaction��״̬Ϊ��ʼ״̬��
ע��:���������û��֪ͨTransaction Coordinator��
����4: Consume-transform-produce loop
����4.0: ͨ��Consumtor������Ϣ,����ҵ����
����4.1: producer��TransactionCordinantro����AddPartitionsToTxnRequest
��producerִ��send����ʱ,����ǵ�һ�θ�<topic,partion>��������,��ʱ����Trasaction Corrdinator����һ��AddPartitionsToTxnRequest����,Transaction Corrdinator����transaction log�м�¼��tranasactionId��<topic,partion>һ��ӳ���ϵ,����״̬��Ϊbegin��AddPartionsToTxnRequest�����ݽṹ����:
AddPartitionsToTxnRequest => TransactionalId PID Epoch [Topic [Partition]]
TransactionalId => string
PID => int64
Epoch => int16
Topic => string
Partition => int32
����4.2: producer#send���� ProduceRequst
�����߷�������,��Ȼû�л�û��ִ��commit����absrot,���Ǵ�ʱ��Ϣ�Ѿ����浽kafka��,���Ҽ�ʹ����ִ��abort,��ϢҲ����ɾ��,ֻ�Ǹ���״̬�ֶα�ʶ��ϢΪabort״̬��
����4.3: AddOffsetCommitsToTxnRequest
Producerͨ��KafkaProducer.sendOffsetsToTransaction ������Э����������һ��AddOffesetCommitsToTxnRequests:
AddOffsetsToTxnRequest => TransactionalId PID Epoch ConsumerGroupID
TransactionalId => string
PID => int64
Epoch => int16
ConsumerGroupID => string
��ִ�������ύʱ,���Ը���ConsumerGroupID���ƶ�_customer_offsets��������Ӧ��TopicPartions��Ϣ��������
����4.4: TxnOffsetCommitRequest
Producerͨ��KafkaProducer.sendOffsetsToTransaction������������Э����Cosumer Corrdinator����һ��TxnOffsetCommitRequest,������_consumer_offsets�б��������ߵ�ƫ������Ϣ��
TxnOffsetCommitRequest => ConsumerGroupID
PID
Epoch
RetentionTime
OffsetAndMetadata
ConsumerGroupID => string
PID => int64
Epoch => int32
RetentionTime => int64
OffsetAndMetadata => [TopicName [Partition Offset Metadata]]
TopicName => string
Partition => int32
Offset => int64
Metadata => string
����5: �����ύ�������ս�(��������)
ͨ�������ߵ�commitTransaction��abortTransaction�������ύ������ս�����,�������������ᷢ��һ��EndTxnRequest��Transaction Coordinator��
����5.1:EndTxnRequest��Producer����һ��EndTxnRequest��Transaction Coordinator,Ȼ��ִ�����²���:
- Transaction Coordinator���PREPARE_COMMIT or PREPARE_ABORT
��Ϣд�뵽transaction log�м�¼ - ִ������5.2
- ִ������5.3
����5.2:WriteTxnMarkerRequest
WriteTxnMarkersRequest => [CoorinadorEpoch PID Epoch Marker [Topic [Partition]]]
CoordinatorEpoch => int32
PID => int64
Epoch => int16
Marker => boolean (false(0) means ABORT, true(1) means COMMIT)
Topic => string
Partition => int32
- ����Producer��������Ϣ��Tranaction Coordinator�ᷢ��WriteTxnMarkerRequest����ǰ�����漰��ÿ��<topic,partion>��leader,leader�յ������,��д��һ��COMMIT(PID) ���� ABORT(PID)�Ŀ�����Ϣ��data log��
- ����������ƫ������Ϣ,�������������������_consumer-offsets���⡣Tranaction
Coordinator�ᷢ��WriteTxnMarkerRequest��Transaction Coordinartor,Transaction Coordinartor�յ������,��д��һ��COMMIT(PID) ����ABORT(PID)�Ŀ�����Ϣ�� data log�С�
����5.3:Transaction Coordinator�Ὣ����COMPLETE_COMMIT��COMPLETE_ABORT��Ϣд��Transaction Log���Ա��������������
- ֻ�ᱣ����������Ӧ��PID��timstamp��Ȼ��ѵ�ǰ�������������Ϣɾ����,����PID��tranactionId��ӳ���ϵ��
References:
- https://blog.csdn.net/weixin_44758876/article/details/120195566
- https://www.cnblogs.com/fnlingnzb-learner/p/13646390.html
- https://www.orchome.com/303
- https://blog.csdn.net/looo000ngname/article/details/107183144
- http://www.heartthinkdo.com/?p=2040#4
(д������Ҫ�Ƕ��Լ�ѧϰ�Ĺ�������,���ϴ���Դ���鼮���������Ϻ��Լ���ʵ��,��������,���������в���֮��,���д���,��������������ָ����ͬʱ��л����������������������������Դ�ͷ�����֪ʶ��)