ǰ��
? ? ? ?��һЩC��ҵ��,���ɱ����Ҫ����һ���������������ݿ��ѹ�����Ҽ���ҵ����Ӧʱ��,��ʵÿ������һ���м������������ͬʱ,��Ȼ������ܶ��µ�������Ҫע��,������ƪ���¡����ݿ��뻺��һ����ʵս�����ᵽ������������һ���ԡ���ô��ʵ������һЩ�����������ʹ��Redis��Ϊһ������ʱ���ܴ�������key����key������,�������Ǿ���key(hot key)����������,��κ����Ľ����key���⡣
����
����
? ? ? ? ��key��ʲô����,��ε��µ�?
? ? ? ? һ����˵,����ʹ�õĻ���Redis���Ƕ�ڵ�ļ�Ⱥ��,��ij��key���ж�дʱ,����ݸ�key��hash�������Ӧ��slot,�������slot�����ҵ���֮��Ӧ�ķ�Ƭ(һ��master�Ͷ��slave��ɵ�һ��redis��Ⱥ)����ȡ��K-V��������ʵ��Ӧ�ù�����,����ijЩ�ض�ҵ�����һЩ�ض���ʱ��(�������ҵ�����Ʒ��ɱ�),���ܻᷢ���������������ͬһ��key�����е�����(�����������д�����dz���)�����䵽ͬһ��redis server��,��redis�ĸ��ؾͻ����ؼӾ�,��ʱ����ϵͳ������redisʵ��Ҳû���κ��ô�,��Ϊ����hash�㷨,ͬһ��key�������ǻ��䵽ͬһ̨�»�����,�û�����Ȼ���Ϊϵͳƿ��2,�������������Ⱥ崵�,�����ȵ�key��value Ҳ�Ƚϴ�,Ҳ����������ﵽƿ��,���������Ϊ ����key�� ���⡣
? ? ? ? ����ͼ1��2��ʾ,�ֱ�������redis cluster��Ⱥ��ʹ��һ��proxy������redis ��Ⱥkey���ʡ�
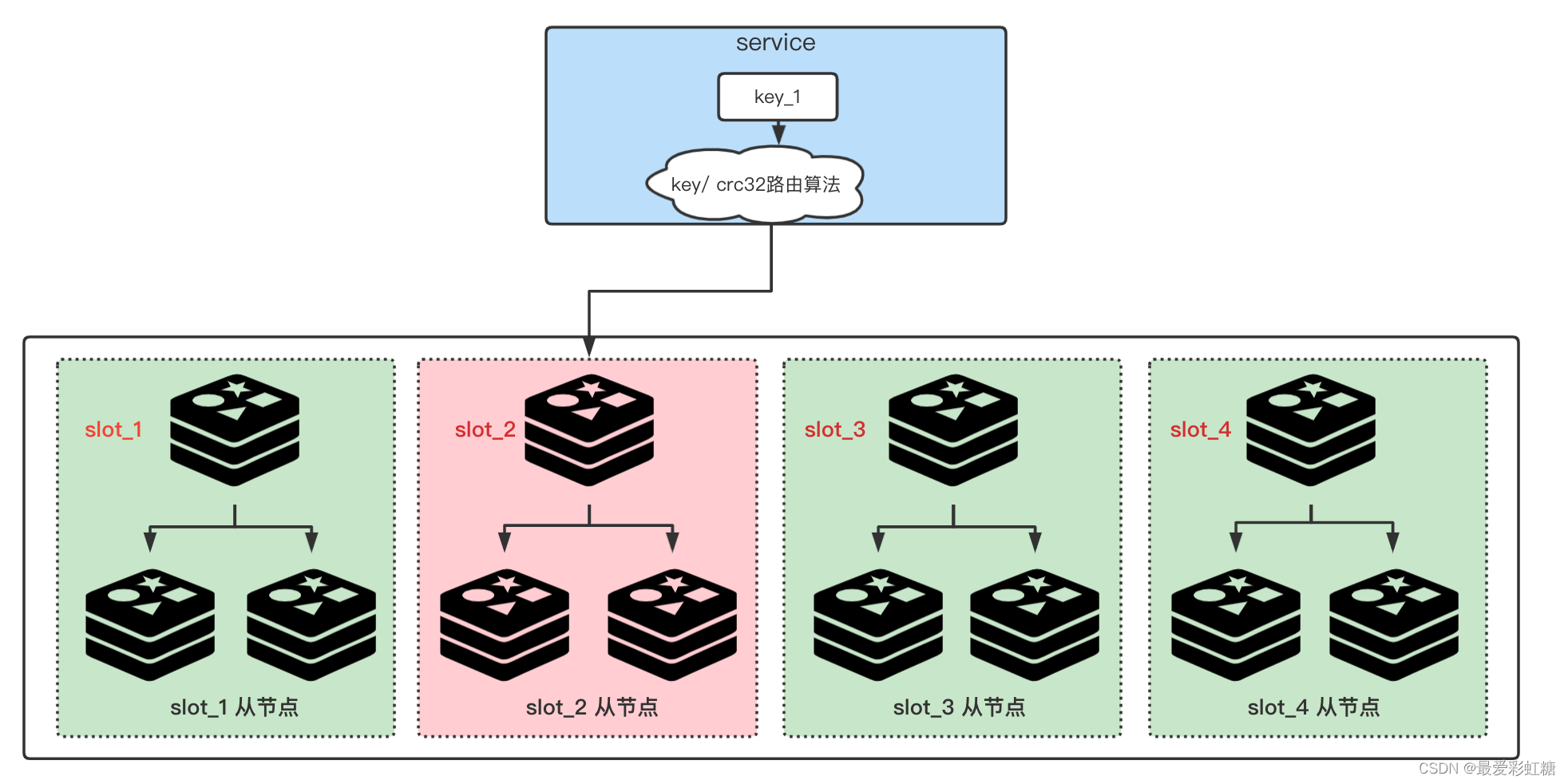

? ? ? ? ������˵,��key�����Ⱥ�е��ٲ��ֽڵ�������ߵĸ���ѹ��,�������ȷ����,��ô��Щ�ڵ�崻����п���,�Ӷ���Ӱ���������漯Ⱥ������,������DZ��뼰ʱ������key�������key���⡣
1.��key̽��
? ? ? ? ��key̽��,��������redis��Ⱥ�ķ�ɢ���Լ��ȵ�key������һЩ����Ӱ��,���ǿ���ͨ���ɴּ�ϸ��˼�����������ȵ�key̽��ķ�����
1.1 ��Ⱥ��ÿ��slot��qps���
? ? ? ? ��key�����Ե�Ӱ��������redis��Ⱥ�е�qps��û����ô���ǰ����,�����ֲ��ڼ�Ⱥ��slot����������,��ô���ǿ��������뵽�ľ��Ƕ���ÿ��slot�е����������,�ϱ�֮����ÿ��slot�������Ա�,��������key����ʱ����Ӱ�쵽�ľ���slot����Ȼ��������Ϊ����,�������ȹ��ڴ���,��������ǰ�ڼ�Ⱥ��ط���,���������ھ�̽���key�ij�����
1.2 proxy�Ĵ���������Ϊ�����������ͳ��
? ? ? ? �������ʹ�õ���ͼ2��redis��Ⱥproxy����ģʽ,�������е������ȵ�proxy�ٵ������slot�ڵ�,��ô����ȵ�key��̽��ͳ�ƾͿ��Է���proxy����,��proxy�л���ʱ�们������,��ÿ��key������,Ȼ��ͳ�Ƴ�������Ӧ��ֵ��key��Ϊ�˷�ֹ���������ͳ��,�������趨һЩ����,��ͳ�ƶ�Ӧǰ�����͵�key�����ַ�ʽ��Ҫ������proxy�Ĵ�������,����redis�ܹ���Ҫ��
1.3 redis����LFU���ȵ�key���ֻ���
? ? ? ? redis 4.0���ϵİ汾֧����ÿ���ڵ��ϵĻ���LFU���ȵ�key���ֻ���,ʹ��redis-cli �Chotkeys����,ִ��redis-cliʱ���ϨChotkeysѡ����Զ�ʱ�ڽڵ���ʹ�ø����������ֶ�Ӧ�ȵ�key��
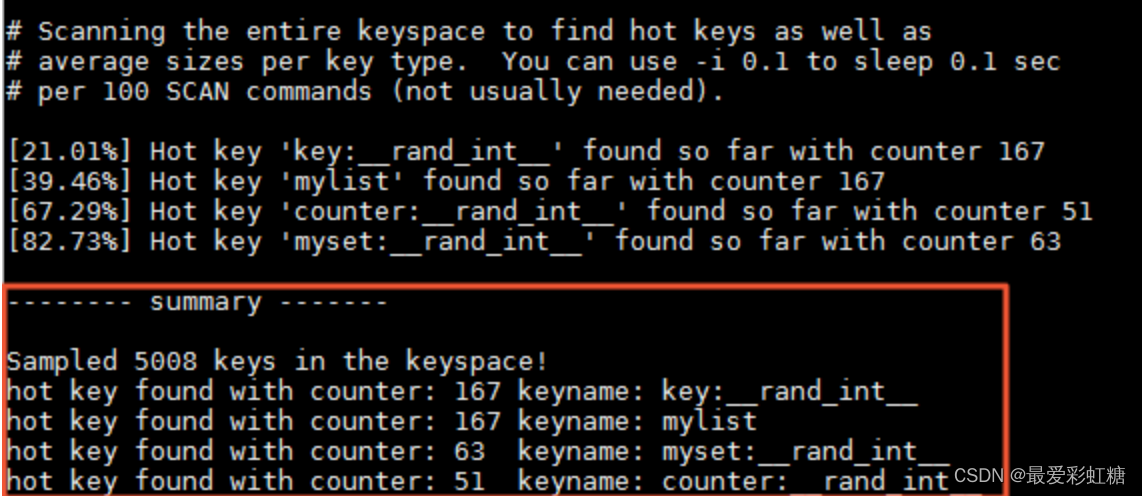
? ? ? ? ������ʾ,���Կ���redis-cli �Chotkeys��ִ�н��,��key��ͳ����Ϣ,��������ִ��ʱ��ϳ�,�������ö�ʱִ����ͳ�ơ�
1.4 ����Redis�ͻ�����̽��
? ? ? ? ����redis������ÿ�ζ��Ǵӿͻ��˷���,���ڴ����ǿ�����redis client��һЩ���봦����ͳ�Ƽ���,ÿ��client������ʱ�们�����ڵ�ͳ��,����һ������ֵ֮���ϱ���server,Ȼ��ͳһ��server�·�������client,�������ö�Ӧ�Ĺ���ʱ�䡣
? ? ? ? �����ʽ������������,��ʵ��һЩӦ�ó����в�������ô����,��Ϊ��client����һ��ĸ���,������еĽ��̴���������ڴ濪��,��ֱ�ӵ���˵,����Java��goLang�����Զ��ڴ����������,�����Ƶ���Ĵ�������,�Ӷ�����gc���½ӿ���Ӧ��ʱ���ӵ�����,��������Dz�̫����Ԥ�ϵ������顣
? ? ? ? ���տ���ͨ��������˾�Ļ���,������Ӧ��ѡ��
2.��key���
? ? ? ? ͨ���������ַ�ʽ����̽��˶�Ӧ��key������slot,��ô���Ǿ�Ҫ�����Ӧ����key���⡣�����keyҲ�кü���˼·���Բο�,����һ��һ����һ�¡�
2.1 ���ض�key��slot������
? ? ? ? һ����ֱ��ķ�ʽ,�����ض���slot������key������,����������Զ���ҵ����˵�������,���Խ���ֻ���ڳ�����������,��Ҫֹ���ʱ������ض���������
2.2 ʹ�ö���(����)����
? ? ? ? ���ػ���Ҳ��һ����õĽ������,��Ȼ���ǵ�һ�����濸��ס��ô���ѹ��,���ټ�һ����������ɡ�����ÿ����������service������,��������������service�����ٺ��ʲ�����,��˿����ڷ����ÿ�λ�ȡ����Ӧ��keyʱ,ʹ�ñ��ػ���洢һ��,�ȱ��ػ�����ں�����������,����redis��Ⱥѹ������javaΪ��,guavaCache�����ֳɵĹ��ߡ�����ʾ��:
//���ػ����ʼ���Լ�����
private static LoadingCache<String, List<Object>> configCache
= CacheBuilder.newBuilder()
.concurrencyLevel(8) //������д�ļ���,��������cpu����
.expireAfterWrite(10, TimeUnit.SECONDS) //д�����ݺ��ù���
.initialCapacity(10) //��ʼ��cache��������С
.maximumSize(10)//cache���������
.recordStats()
// build�����п���ָ��CacheLoader,�ڻ��治����ʱͨ��CacheLoader��ʵ���Զ����ػ���
.build(new CacheLoader<String, List<Object>>() {
@Override
public List<Object> load(String hotKey) throws Exception {
}
});
//���ػ����ȡ
Object result = configCache.get(key);
? ? ? ? ���ػ���������ǵ�����Ӱ��������ݲ�һ�µ�����,�������ö�Ļ������ʱ��,�ͻᵼ����ж�õ��������ݲ�һ������,�������ʱ����Ҫ���������ļ�Ⱥѹ���Լ�ҵ����ܵ����һ��ʱ�䡣
2.3 ��key
? ? ? ? ��μ��ܱ�֤��������key����,���ܾ����ı�֤����һ������?��keyҲ��һ���õĽ��������
? ? ? ? �����ڷ��뻺��ʱ�ͽ���Ӧҵ��Ļ���key��ֳɶ����ͬ��key������ͼ��ʾ,���������ڸ��»����һ��,��key���N��,����һ��key���ֽ���"good_100",�����ǾͿ���������ķ�,��good_100_copy1������good_100_copy2������good_100_copy3������good_100_copy4��,ÿ�θ��º�����ʱ����Ҫȥ�Ķ���N��key,��һ�����Dz�key��
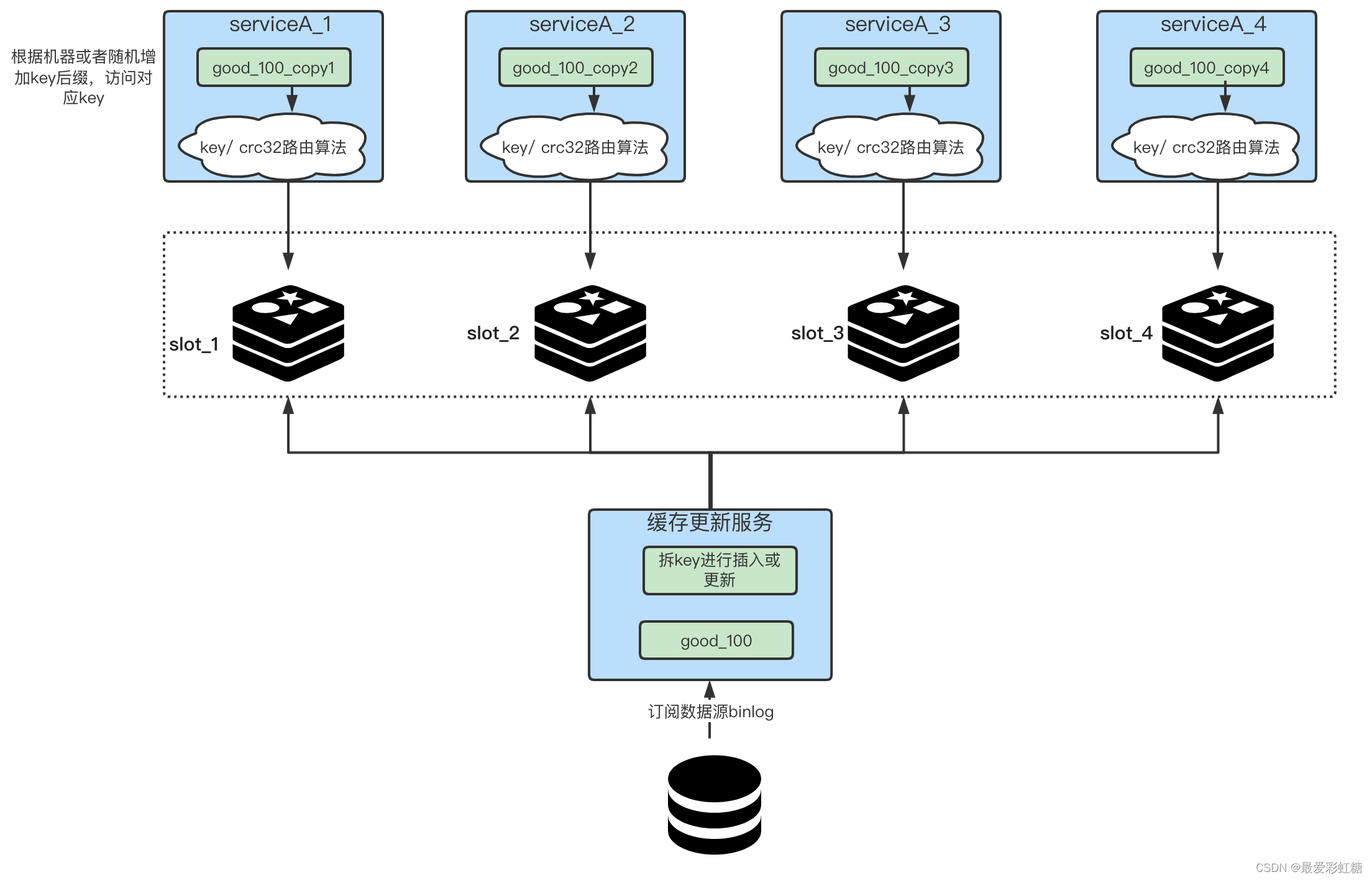
? ? ? ? ����service������,���Ǿ���Ҫ��취�������Լ����ʵ������㹻�ľ���,��θ��Լ��������ʵ���key�ϼ���������ְ취,���ݱ�����ip��mac��ַ��hash,֮���ֵ���key��������ȡ��,���վ���ƴ�ӳ�ʲô����key��,�Ӷ�����̨������;��������ʱ��һ��������Բ�key��������ȡ�ࡣ
2.4 ���ػ��������һ��˼· ��������
? ? ? ? ������Ϥ�����������ĵĻ������,���ǵ�˼·�������������ĵ�һ����ת��һ�¡���nacos������,������������ֲ�ʽ������һ���Ե�,������Ӧ�ٶȺܿ�?�����ǿ��Խ������������,����ȥ����
? ? ? ? ����ѯ+���ػ������á����ȷ�������ʱ���ʼ��ȫ��������,Ȼ��ʱ��������ѯȥ��ѯ��ǰ���������������û�б��,����б��,����ѯ�����������̷���,���±�������;���û�б��,�������е�ҵ����붼��ʹ�ñ��ص��ڴ滺�����á��������ܱ�֤�ֲ�ʽ�Ļ�������ʱЧ����һ���ԡ�
2.5 ����������ǰ����Ԥ��
? ? ? ? �����ÿһ����������Զ�����ȥ�����key����,��ô����������������ҵ������ʱ,��ʵ���кܳ���ʱ������������ķ�����ơ�һЩ���˵���ɱ������������key����,�������Ԥ�����,����ֱ���������ҵ����롢redis���漯Ⱥ�ĸ���,����Ӱ�쵽����ҵ���ͬʱ,Ҳ�������ʱ��ȡ���õ����֡�������ʩ��
һЩ���ϵķ���
? ? ? ? Ŀǰ�������Ѿ����˲��ٹ���hotKey���������Ӧ�ü��������,���о������ⷽ���п�Դ��hotkey����,ԭ��������client��������,Ȼ���ϱ���Ӧhotkey,server�˼���,����Ӧhotkey�·�����Ӧ����������ػ���,����������ػ�����Զ�̶�Ӧ��key���º�,��ͬ������,�Ѿ���Ŀǰ��Ϊ������Զ�̽����key���ֲ�ʽһ���Ի����������,����������key��

�ܽ�
? ? ? ? ���Ͼ��DZ��ߴ���˽��ʵ�����ĵ����Ӧ����key��һЩ����,�ӷ�����key�������key�������ؼ������Ӧ�ԡ�ÿһ������������ȱ��,��������ҵ��IJ�һ����,ʵʩ������Ϊ���ѵȵ�,���Ը���Ŀǰ����ҵ����ص㡢�Լ�Ŀǰ��˾�Ļ���ȥ����Ӧ�ĵ����ı䡣
? ? ? ? �������ũ������ĵ�һ����������,ϣ����Ҷ��ܽ������彡��,��ְ��н��