Redis
ʲô��NoSQL
NoSQL:(Not Only SQL)��������SQL
��ָ�ǹ�ϵ�����ݿ�,����web2.0�������ĵ���!��ͳ�Ĺ�ϵ�����ݿ���ѶԸ�web2.0ʱ��!�����dz����ģ�ĸ߲�������!��¶�����ܶ����Կ˷�������,NoSQL�ڵ��´����ݻ����ķ�չʮ��Ѹ��,Redis�Ƿ�չ����,�DZ���Ҫ���յļ���
�ܶ�����������û��ĸ�����Ϣ,�罻����,����λ�á���Щ�������͵Ĵ洢����Ҫһ���̶��ĸ�ʽ,����Ҫ����IJ����Ϳ��Ժ�����չ
NoSQL�ص�
��ź
1��������չ(����֮��û�й�ϵ,�ܺ���չ)
2����������������(Redisÿ����Զ�ȡ11���,д8���,NoSQL�Ļ����¼��,��һ��ϸ���ȵĻ���,���ܻ�Ƚϸ�)
3���������ͷḻ(����Ҫ����������ݿ�!��������ݿ���ʮ�ִ�ı�,�ܶ��˾��������)
4����ͳRDBMS��NoSQL
��ͳ��RDBMS
- �ṹ����֯
- SQL
- ���ݺ�ϵ�����ڵ����ı���
- ��������,���ݶ�������
- �ϸ��һ����
- ����������
- ����������
NoSQL
- ������������
- û�й̶��IJ�ѯ����
- ��ֵ�Դ洢,�д洢,�ĵ��洢,ͼ�����ݿ�(�罻��ϵ)
- ����һ����
- CAP���� �� BASE����(��ض��)
- ��֤�����ܡ��߿��á��߿���չ
- ��������
�˽�:3V+3��
������ʱ����3V:��Ҫ�����������
- ����Volume
- ����Variety
- ʵʱVelocity
������ʱ����3��:�Գ����Ҫ��
- �߲���
- �߿���(��ʱ����ˮƽ��չ,���ӷ�����)
- ������(��֤�û����������)
�����ڹ�˾��ʵ��:NoSQL + RDBMSһ��ʹ�ò�����ǿ��
NoSQL�Ĵ����
KV��ֵ��:
- ����:Redis
- ����:Redis + Tair
- ����ٶ�:Redis + mamecache
�ĵ������ݿ�(bson��ʽ��jsonһ��):
- MongoDB(һ���������)
- MongoDB��һ�����ڷֲ�ʽ�ļ��洢�����ݿ�,C++��д,��Ҫ���������������ĵ�
- MongoDB��һ�����ڹ�ϵ�����ݿ�ͷǹ�ϵ�����ݿ��м�IJ�Ʒ,��NoSQL�й�����ḻ,�����ϵ�����ݿ���
�д洢���ݿ�
- HBase
- �ֲ�ʽ�ļ�ϵͳ
ͼ��ϵ���ݿ�
- ����ͼ,��ŵ��ǹ�ϵ,����:����Ȧ�罻����,����Ƽ�
- Neo4j,InfoGrid
| ���� | Examples���� | ����Ӧ�ó��� | ����ģ�� | �ŵ� | ȱ�� |
|---|---|---|---|---|---|
| ��ֵ��(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | ���ݻ���,��Ҫ���ڴ����������ݵĸ߷��ʸ���,Ҳ����һЩ��־ϵͳ�ȵȡ� | Key ָ�� Value �ļ�ֵ��,ͨ����hash table��ʵ�� | �����ٶȿ� | �����ṹ��,ͨ��ֻ�������ַ������߶��������� |
| �д洢���ݿ� | Cassandra, HBase, Riak | �ֲ�ʽ���ļ�ϵͳ | ���д�ʽ�洢,��ͬһ�����ݴ���һ�� | �����ٶȿ�,����չ��ǿ,�������зֲ�ʽ��չ | ������Ծ��� |
| �ĵ������ݿ� | CouchDB, MongoDb | WebӦ��(��Key-Value����,Value�ǽṹ����,��ͬ�������ݿ��ܹ��˽�Value������) | Key-Value��Ӧ�ļ�ֵ��,ValueΪ�ṹ������ | ���ݽṹҪ���ϸ�,���ṹ�ɱ�,����Ҫ���ϵ�����ݿ�һ����ҪԤ�ȶ�����ṹ | ��ѯ���ܲ���,����ȱ��ͳһ�IJ�ѯ��� |
| ͼ��(Graph)���ݿ� | Neo4J, InfoGrid, Infinite Graph | �罻����,�Ƽ�ϵͳ�ȡ�רע�ڹ�����ϵͼ�� | ͼ�ṹ | ����ͼ�ṹ����㷨���������·��Ѱַ,N�ȹ�ϵ���ҵ� | �ܶ�ʱ����Ҫ������ͼ��������ܵó���Ҫ����Ϣ,�������ֽṹ��̫�����ֲ�ʽ�ļ�Ⱥ |
Redis����
����
Redis��ʲô
Redis(Remote Dictionary Server) Զ���ֵ����
��Զ���ֵ����,��һ����Դ��ʹ��ANSI C���Ա�д��֧�����硢�ɻ����ڴ���ɳ־û�����־�͡�Key-Value���ݿ�,���ṩ�������Ե�API,redis�������ԵİѸ��µ�����д����̻��߰��IJ���д���ӵļ�¼�ļ�,�����ڴ˻�����ʵ����master-slave(����)ͬ����
��ѺͿ�Դ!�ǵ��������ŵ�NoSQL����֮һ!Ҳ�����dz�Ϊ�ṹ���ݿ�!
Redis�ܸ���
- �ڴ�洢���־û�,�ڴ��Ƕϵ缴ʧ��,����˵�־û�����Ҫ(RDB��AOF)
- Ч�ʸ�,�������ڸ��ٻ���
- ��������ϵͳ
- ��ͼ��Ϣ����
- ��ʱ����������(�����!)
- ����������
����
-
��������������
-
�־û�
-
��Ⱥ
-
����
����������
ѧϰ����Ҫ�õ��Ķ���
- Redis����https://redis.io/
- Redis������http:/www./redis.cn/
- ���ص�ַ:ͨ����������(Windows�汾��Github������)
Redisһ�㶼�ǰ�װ��Linuxϵͳ�ϵ�,���ǻ���Linuxѧϰ
Windows��װ
���ص�ַ:https://github.com/dmajkic/redis
-
��ѹ��װ��
-
����redis-server.exe
-
����redis-cli.exe����

Linux��װ
-
���ذ�װ��!
redis-5.0.8.tar.gz -
��ѹRedis�İ�װ��!����һ�����
/optĿ¼�� -
����������װ
yum install gcc-c++ # Ȼ�����redisĿ¼��ִ�� make # Ȼ��ִ�� make installʹ�õ���5.0.8�汾,�߰汾���д���
-
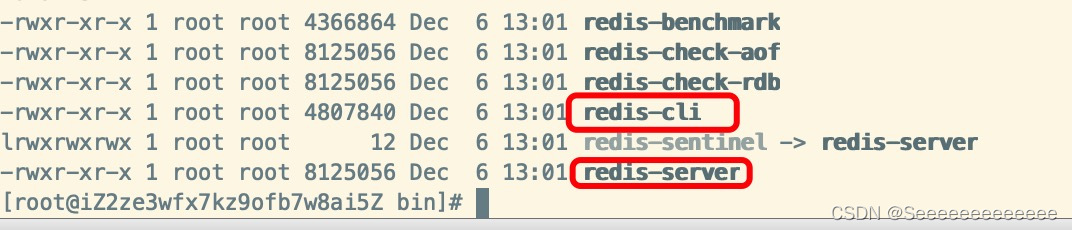
redisĬ�ϰ�װ·��
/usr/local/bin
-
��redis�������ļ����Ƶ� ����װĿ¼
/usr/local/bin/redisconfig��,�Ժ�ʹ����������ļ����� -
redisĬ�ϲ��Ǻ�̨����,��Ҫ�������ļ�
�������ļ��е�
daemonize��ԭ����no��Ϊyes���� -
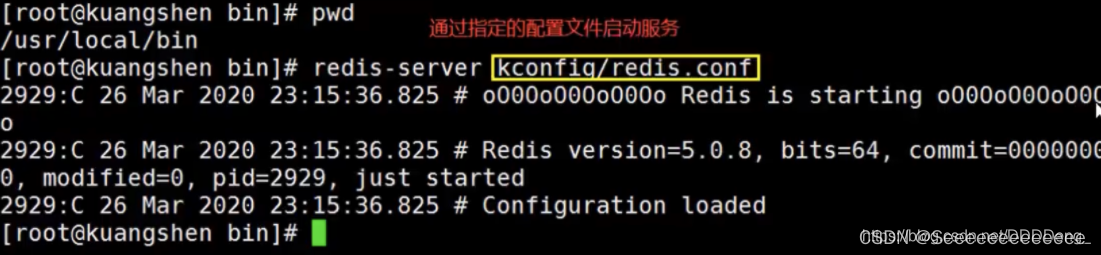
ͨ���ƶ��������ļ�����redis����
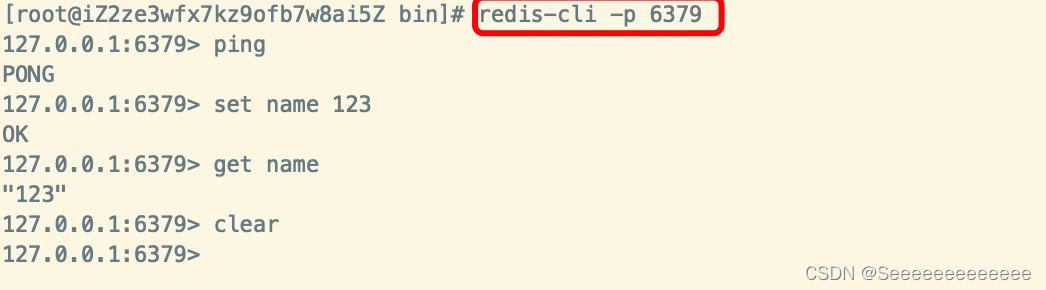
- ʹ��
redis-cli��������
- �鿴redis�Ľ����Ƿ���

- �ر�Redis����

- �ٴβ鿴�����Ƿ����

���Է��ֿͻ��˽����Ѿ�����,ֻʣ����redis�ķ���
��������
| ��� | ѡ�� | ���� | Ĭ��ֵ |
| 1 | -h | ָ�������������� | 127.0.0.1 |
| 2 | -p | ָ���������˿� | 6379 |
| 3 | -s | ָ�������� socket | |
| 4 | -c | ָ������������ | 50 |
| 5 | -n | ָ�������� | 10000 |
| 6 | -d | ���ֽڵ���ʽָ�� SET/GET ֵ�����ݴ�С | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR ʹ����� key, SADD ʹ�����ֵ | |
| 9 | -P | ͨ���ܵ����� ���� | 1 |
| 10 | -q | ǿ���˳� redis������ʾ query/sec ֵ | |
| 11 | �Ccsv | �� CSV ��ʽ��� | |
| 12 | -l | ����ѭ��,����ִ�в��� | |
| 13 | -t | �������Զ��ŷָ��IJ��������б��� | |
| 14 | -I | Idle ģʽ������ N �� idle ���Ӳ��ȴ��� |
����:
����100���������� 1000000������
redis-benchmark -h locl -p 6379 -c 100 -n 1000000
Redis��������
redisĬ����16�����ݿ�
select 1 #�л����ݿ�
dbsize #�鿴���ݿ��С
Set name haiyang #�������
get name #��ȡ����
keys * #�鿴���е�key
flushdb #��յ�ǰ���ݿ�
flushall #����������ݿ�
Exist name #�ж�һ��key�Ƿ����
move name #�Ƴ�һ��key
expire name 10 #����Ԫ��10������
type name #�鿴Ԫ�ص�����
append name 123 #�ڵ�ǰԪ�غ�����,���key�����ھ��½�һ��key
strlen key #��ȡ�ַ����ij���
incr views #��������
decr views #�����Լ�
incrby views 10 #����10
decrby views 10 #�Լ�10
getrange name 0 3 #��ȡ�ַ����±��0��3(������)
gerrange name 0 -1 #��ȡȫ���ַ���
setrange name 1 xx #���±�1��ʼ�滻Ϊxx
setex name 30 "hello" #���ù���ʱ��
setnx name "abc" #��������ڽ�������,������ڷ���0 (�ֲ�ʽ���л᳣��ʹ��)
mset k1 v1 k2 v2 k3 v3 #���ö��Ԫ��
mget k1 k2 k3 #��ȡ���ֵ
msetnx k1 v1 k4 v4 #���ö��ֵͬʱ,��������ڷ���0
mset user:1:name zhangsan user:1:age 10
mget user:1:name user:1:age
getset name zhangsan #��get��set,���������,����null,�������,��ȡԭ����ֵ,�������µ�ֵ
Ϊʲôredis��6379,redis��ʼ�˵�ż��
redis�ǵ��̵߳�!
Redis�ǻ����ڴ������,CPU����Redis������ƿ��,Redis��ƽ���Ǹ��ݻ������ڴ���������,����redisʹ�õ��߳�
Redis��C����д��,�ٷ�����,ÿ��10w+ QPS,����Memecache��!
RedisΪʲô���̻߳���ô��?
���̲߳����������л�,CPU�������л��ܺķ�����
����:�����е�����ȫ�������ڴ��е�,������ʹ�õ��̲߳���Ч�ʾ�����ߵ�,���߳�
(CPU�������л�,�Ǻ�ʱ�IJ���),�����ڴ�ϵͳ��˵,û���������л�Ч�ʾ�����ߵġ�
Redis�����������
Redis ��һ����Դ(BSD����)��,�ڴ��е����ݽṹ�洢ϵͳ,�������������ݿ⡢�������Ϣ�м���� ��֧�ֶ������͵����ݽṹ,�� �ַ���(strings), ɢ��(hashes), �б�(lists), ����(sets), ����(sorted sets) �뷶Χ��ѯ, bitmaps, hyperloglogs �� �����ռ�(geospatial) �����뾶��ѯ�� Redis ������ ����(replication),LUA�ű�(Lua scripting), LRU�����¼�(LRU eviction),����(transactions) �Ͳ�ͬ����� ���̳־û�(persistence), ��ͨ�� Redis�ڱ�(Sentinel)���Զ� ����(Cluster)�ṩ�߿�����(high availability)��
String(�ַ���)
String���͵�ʹ�ó���:value�������ַ���������������!
- ������
- ͳ�ƶλ������
- ����洢
List
��������������,�б�
��Redis����,���ǿ���List����ջ�����С���������������
���е�List�����L����R
LPUSH list 1 #��������һ������ֵ
LPUSH list 2
LPUSH list 3
LRANGE list 0 -1 #ȡ��������
LRANGE list 0 1 #ȡ0��1��������
######################################################
RPUSH list 1 #���Ҳ����һ������ֵ
######################################################
Lpop list #�Ƴ�list��ߵ�һ��Ԫ��
Rpop list #�Ƴ�list���ұ�һ��Ԫ��
######################################################
Lindex list 1 #��ȡ�±�Ϊ1��ֵ
Llen list #��ѯlist�ij���
######################################################
Lrem list 1 value #�Ƴ�list�е�1��value
Lrem list 2 value #�Ƴ�list�е�2��value
######################################################
trim list 1 2 #ͨ���±��ȡָ���ij���,���list�Ѿ����ı���,ֻʣ�½�ȡ��Ԫ��
rpoplpush list1 list2 #��list1���һ��ȡ���ŵ�list2��ͷ��
lset list 0 123 #��list���±�Ϊ0��Ԫ������Ϊ123(����������б��ᱨ��)
######################################################
linsert list before "hello" "other" #��һ��Ԫ��ǰ�����һ��Ԫ��
linsert list after "hello" "other" #��һ��Ԫ�غ������һ��Ԫ��
��
- Redis�е�Listʵ������һ������,������ǰ��ͺ��涼���Բ���ֵ
- ���������,�����µ�����
- ���key����,��������
- ����Ƴ������е�ֵ,������,Ҳ����������
- �����߲�����߸Ķ�ֵЧ�����,���м����Ч�ʻ��һ��
��Ϣ����,����(lpush rpop),ջ(lpush lpop)
Set(����)
set�е�ֵ�����ظ�
sadd myset "hello" #����һ��Ԫ��
smembers myset #�鿴����Ԫ��
sismember myset "hello" #�ж�myset���Ƿ����"hello"
scard myset #�鿴set��Ԫ�صĸ���
srem myset "hello" #ɾ��ָ��Ԫ��
#################################################
srandmember myset #�����ȡһ��Ԫ��
spop myset #���ɾ��һ��Ԫ��
#################################################
smove myset myset2 "hello" #��һ��ָ����ֵ�ƶ�������һ��������
sdiff key1 key2 #�鿴key1�д��ڶ�key2�в����ڵ�ֵ
sinter key1 key2 #�鿴key1�к�key2�ж��е�ֵ
sunion key1 key2 #�鿴key1��key2�����е�ֵ,��ȥ��
Hash(��ϣ)
Map����,key-map ���ʱ�����ֵ��һ��map����,hash���ʺ�String����û��̫������,����һ����key-value
hset myhash field1 123 #set һ������ key-value
hget myhash field1
hset myhash field1 hello field2 world #������key-value
hget myhash field1 field2 #��ȡ�����ֶ�ֵ
hgetall myhash #��ȡ�����ֶ�ֵ
hdel myhash field1 #ɾ��myhash��field1�Ͷ�Ӧ��value
hlen myhash #�鿴����
hexists myhash field1 #�ж�hash��ָ���ֶ��Ƿ����
hkeys myhash #ֻ������е�key
hvalues myhash #ֻ������е�value
hincrby myhash field3 1 #ʹָ��key��Ӧ��value����1
hdecrby myhash field3 1 #ʹָ��key��Ӧ��value�Լ�1
hsetnx myhash field4 hello #����һ��key-value�����������
hash��������� user name age �������û���Ϣ,�����䶯����Ϣ!hash�����ʺ϶���Ĵ洢,��String���ʺ��ַ����Ĵ洢
ZSet(����)
��set�Ļ�����,������һ��ֵ,set k1 v1 set k1 score1 v1
zadd myset 1 one #����һ��ֵ
zrange myset 0 -1 #�鿴����ֵ
#################################################
zrangebyscore salary -inf +inf whithscores ##��ʾȫ������,����������
zrangebyscore salary -inf 2500 whithscores #��ʾscoreС��2500,����������
zrevrange salary 0 -1 ##��ʾȫ������,����������
#################################################
zrem salary xiaohong #�Ƴ������е�ָ��Ԫ��
zcard salary #��ȡ������Ԫ�ظ���
zcount myset 1 3 #��ȡָ�������Ԫ������
�����һЩAPI,�������������Ҫ,���Բ鿴�ٷ��ĵ�
����˼·:set ���� �洢�༶�ɼ���,���ʱ�����,���а�Ӧ��ʵ��
��ͨ��Ϣ,1 ,��Ҫ��Ϣ 2,��Ȩ�ؽ����ж�
����������������
geospatial �����
Redis��Geo��Redis3.2�汾���Ƴ���,������ܿ����������λ�õ���Ϣ,����֮��ľ���,��Բ����ľ���
���Բ�ѯһЩ����λ������:https://jingweidu.bmcx.com
Geoֻ��6������
geoadd china:city 116.40 39.90 beijing #���뱱���ĵ���λ��(��γ��)
#������ϱ���λ��������,����һ������س�������,ͨ��java����ֱ��һ���Ե���
#����ֵ(����,γ��,����)
#��Ч�ľ��ȴ�-180�ȵ�180�ȡ�
#��Ч��γ�ȴ�-85.05112878�ȵ�85.05112878�ȡ�
geopos china:city beijing #��ȡָ���ľ�γ��
����֮��ľ���
geodist china:city beijing shanghai #�鿴����֮���ֱ�߾���
��������(������и������˵ĵ�ַ,��λ!)ͨ���뾶����ѯ
georadius china:city 116.40 39.90 1000 km withdist withcoord count 1 #�Ը����ľ�γ��Ϊ����,�ҳ������ij���WITHDIST: �ڷ���λ��Ԫ�ص�ͬʱ, ��λ��Ԫ��������֮��ľ���Ҳһ�����ء� ����ĵ�λ���û������ķ�Χ��λ����һ�¡�WITHCOORD: ��λ��Ԫ�صľ��Ⱥ�ά��Ҳһ�����ء�WITHHASH: �� 52 λ�з�����������ʽ, ����λ��Ԫ�ؾ���ԭʼ geohash ��������Ϸ�ֵ�� ���ѡ����Ҫ���ڵײ�Ӧ�û��ߵ���, ʵ���е����ò���������Ĭ�Ϸ���δ�����λ��Ԫ�ء� ͨ��������������, �û�����ָ��������λ��Ԫ�ص�����ʽ:ASC: �������ĵ�λ��, ���մӽ���Զ�ķ�ʽ����λ��Ԫ�ء�DESC: �������ĵ�λ��, ���մ�Զ�����ķ�ʽ����λ��Ԫ�ء�COUNT: ɸѡ���̶�������Ԫ��
�ҳ�λ��ָ��Ԫ����Χ������Ԫ��!(���ڵ�ͼ)
georadiusbymember china:city beijing 1000 km
geohash(����11λ��GeoHash�ַ���)
#����ά�ľ�γ��ת��Ϊһά���ַ���,��������ַ���Խ��Խ�ӽ�geohash chin:city beijing shanghai
Geo�ĵײ�ʵ��ԭ������ZSet,ɾ��ZSet�е�Ԫ��Geo�е�Ԫ��Ҳ��ɾ����
Hyperloglog
ʲô�ǻ���? �����������ݼ���ȥ�غ��Ԫ�ظ���
A{1,2,3,4,5,6,7}
B{3,5,6,8,9,0,0}
A�Ļ�����7,B�Ļ�����6
���
Redis 2.8.9������Hyperloglog���ݽṹ!
Redis Hyperloglog����ͳ�Ƶ��㷨
�ŵ�:ռ�õ��ڴ��ǹ̶���,2^64��ͬ��Ԫ�ػ���,ֻ��Ҫռ��12KB�ڴ�!���ڴ�Ƕȿ���Hyperloglog����ѡ
��ҳ��UV(һ���˷�����վ���,��������һ����)
��ͳ��ʽ,��set�����û���id,ͳ��set�е�Ԫ��������Ϊ���ж�!
�����ʽ�������������û�id,�ͻ�Ƚ��鷳!Ŀ����Ϊ�˼���,�����DZ���id
0.81%������!ͳ��UV����,���Ժ��Բ���
PFadd mykey a b c d e f c q #����Ԫ��PFadd mykey2 3 2123 323 22 23 5 9 6 4PFcount mykey #ͳ��Ԫ�ػ�������pmerge mykey3 mykey2 mykey #�ϲ����鵽mykey3
��������ݴ�,��һ������ʹ��Hyperloglog
����������ݴ�,��ʹ��set���ϻ������������ͼ���
Bitmap
λ�洢
ͳ�������Ⱦ����:0 1 0 0 0 1
ͳ���û���Ϣ,��Ծ,����Ծ!��½��δ��¼!��,365��!����״̬�Ķ�����ʹ��Bitmaps
Bitmaps λͼ,���ݽṹ!���в������Dz���������λ�����м�¼,��ֻ��0��1����״̬
365�� = 365bit 1�ֽ�=8bit 46���ֽ�����!
����
setbit sign 0 0setbit sign 1 1setbit sign 2 1setbit sign 3 1setbit sign 4 0setbit sign 5 0setbit sign 6 1 #��¼��һ�����յĴ�getbit sign 1 #�鿴�ܶ��Ĵ����
ͳ�Ʋ���
bitcount sign #ͳ�Ʊ��ܴ�¼
����
����ı���:һ������ļ���!һ�������е���������ᱻ���л�,������ִ�й����лᰴ��˳��ִ��
һ���ԡ�˳���ԡ�������!ִ��һϵ�е�����!
Redis������û�и��뼶��ĸ���
����������������,��û��ֱ�ӱ�ִ��!ֻ�з���ִ�������ʱ��Ż�ִ��!Execute
Redis���������DZ�֤ԭ���Ե�,��������֤ԭ����
redis������
- ��������(multi)
- �������(��)
- ִ������(execute)
����ִ������!
multi #��������#�������set k1 v1set k2 v2exec #ִ������
��������
multi #��������#�������set k1 v1set k2 v2discard #��������
Redis�������������쳣(�����д���,���벻ͨ��)
Redis��������ʱ�쳣(����ͨ��,���б���)�����������д����������,���쳣�������׳��쳣,������Ӱ���������ִ��
���! Watch
������:
- �ܱ���,��Ϊʲôʱ�������,������ʲô�������!
�ֹ���:
- ���ֹ�,��Ϊʲôʱ�����������,���Բ�������!�������ݵ�ʱ��ȥ�ж�һ��,�ڴ��ڼ��Ƿ������Ĺ�����
- ��ȡversion
- ���µ�ʱ��Ƚ�version
Redis���Ӳ���
set money 100set out 0watch money #����money����multidecrby money 20incrby out 20exec
���Զ��߳���ֵ,ʹ��watch���Ե�redis���ֹ�������
set money 100watch moneymultidecrby money 10incrby out 10exec #��execִ��֮ǰ,��һ���߳���money��ֵ,����ִ�л�ʧ��,����(nil)
����ִ��ʧ�ܻ��߳ɹ����Զ���������
�����ʧ��,��ȡ���µ�ֵ�ͺ�
Redis��watch���ӵ��Ƕ�ӦԪ�ص�version,������ֵ,���Լ��㷢��ABA����(��è��̫��),����ִ�л��ǻᱨ��
Jedis
����Ҫ��java������Redis
ʲô��jedis,��Redis�ٷ��Ƽ���java���ӿ�������!ʹ��java����Redis�м��!�����Ҫʹ��java����redis,��ôһ��Ҫ��jedisʮ�ֵ���Ϥ!
����
��������:
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
����:
Jedis jedis = new Jedis("codekitty.cn", 6379);
ʹ��:
public static void main(String[] args) {
Jedis jedis = new Jedis("codekitty.cn", 6379);
String set = jedis.set("key1", "value1");
System.out.println(set);
String key1 = jedis.get("key1");
System.out.println(key1);
}
������API
��֮ǰ��Linux������һ��,ֻ�ǻ����˷���,�˴�ʡ��
Jedis��������(�������������)
Jedis jedis = new Jedis("codekitty.cn", 6379);
jedis.flushDB(); //���������keys
System.out.println(jedis.ping());
Transaction multi = jedis.multi();
try {
multi.set("key1","value1");
multi.set("key2","value2");
int i = 1/0; //����һ���쳣
multi.set("key3","value3");
multi.exec();
}catch (Exception e){
multi.discard(); //��������쳣���������
e.printStackTrace();
}finally {
System.out.println(jedis.keys("*"));
System.out.println(jedis.get("key1"));
jedis.close(); //���չر�jedis����
}
SpringBoot����
SpringBoot��������:spring-data jpa jdbc mongdb redis!
SpringDataҲ�Ǻ�SpringBoot��������Ŀ!
��SpringBoot2.x֮��ԭ��ʹ�õ�Jedis��lettuce�滻��?
jedis:���õ���ֱ��,����̲߳�������ȫ,�����Ҫ���ⲻ��ȫ��,Ҫʹ��jedis pool���ӳ�!BIO
lettuce:����netty,ʵ�������ڶ���߳��й���,�������̲߳���ȫ�����!���Լ����߳�����,NIO
Դ�����:
@Bean
@ConditionalOnMissingBean(name = "redisTemplate") //��������ڿ�����û���Լ�������������Ч
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {//Ĭ�ϵ�Redistemplateû�й��������,redis������Ҫ���л���
//�������Ͷ���Object����,����ʹ��ʱ��Ҫǿ��ת��,���ǿ���֮�ʴ���һ��RedisTemlplate�����Ĭ�ϵ�
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {//����String��Redis������õ�����,���Ե�������һ������
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
���ϲ���
1����������:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2����д�����ļ�:
spring: #����redis
redis:
host: codekitty.cn
port: 6379
# lettuce: �����Ҫ�������ӳ�,����ʹ��lettuce��������
3�����Ӳ���
@Autowired
RedisTemplate redisTemplate;
@Test
void contextLoads() {
//��������
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
try {
connection.flushDb();
connection.flushAll();
//����Ԫ��
redisTemplate.opsForValue().set("key1", "value1");
redisTemplate.opsForList().leftPush("list1","value");
//��������
redisTemplate.watch("key1");
redisTemplate.multi();
redisTemplate.exec();
}catch (Exception e){
redisTemplate.discard();
e.printStackTrace();
}finally {
connection.close();
}
}
�Զ���RedisTemplate
����RedisConfig.java����Դ���е����ÿ�������,Ȼ����,�����Լ���Ҫ������
@Configurationpublic class RedisConfig { /** * �̶�ģ�� * @param factory * @return */ @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { Jackson2JsonRedisSerializer<Object> objectJackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class); //Ϊ��ʹ�÷���,ֱ��ʹ��<String,Object> RedisTemplate<String, Object> template = new RedisTemplate<>(); ObjectMapper objectMapper = new ObjectMapper(); objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); objectJackson2JsonRedisSerializer.setObjectMapper(objectMapper); //key�����л�ʹ��string��ʽ template.setKeySerializer(stringRedisSerializer); template.setConnectionFactory(factory); //value�����л�ʹ��jackon��ʽ template.setValueSerializer(objectJackson2JsonRedisSerializer); //hash ��keyҲʹ��string�����л���ʽ template.setHashKeySerializer(stringRedisSerializer); //hash ��valueҲʹ��jackon�����л���ʽ template.setHashValueSerializer(objectJackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; }}
��ҵ���������Է�װRedisUtil����ʹ��
Redis.conf����
redis������ʱ��ͨ�������ļ�������
��λ
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
�����ļ��Դ�Сд������
����
################################## INCLUDES ###################################
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Note that option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
################################## MODULES #####################################
�������������ļ����ù���
����
################################## NETWORK #####################################
bind 127.0.0.1 -::1
# Protected mode is a layer of security protection, in order to avoid that
# Redis instances left open on the internet are accessed and exploited.
#
# When protected mode is on and if:
#
# 1) The server is not binding explicitly to a set of addresses using the
# "bind" directive.
# 2) No password is configured.
#
# The server only accepts connections from clients connecting from the
# IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain
# sockets.
#
# By default protected mode is enabled. You should disable it only if
# you are sure you want clients from other hosts to connect to Redis
# even if no authentication is configured, nor a specific set of interfaces
# are explicitly listed using the "bind" directive.
protected-mode yes #�Ƿ��ܱ���
port 6000 #�˿�
ͨ������
################################# GENERAL #####################################
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
# When Redis is supervised by upstart or systemd, this parameter has no impact.
daemonize yes #�ػ��̷߳�ʽ�Ƿ���(��̨����)
pidfile /var/run/redis_6379.pid #����Ժ�̨��ʽ����,���Ǿ���Ҫָ��һ��pid�ļ�
# ��־
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing) һ�����ڿ������Խ�
# verbose (many rarely useful info, but not a mess like the debug level) ��debug����
# notice (moderately verbose, what you want in production probably) ����������־����
# warning (only very important / critical messages are logged) �ؼ���Ϣ�Ż��ӡ
loglevel notice #��־����
# Specify the log file name. Also the empty string can be used to force
# Redis to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile "" #��־���ļ�λ����
databases 16 #Ĭ�ϵ����ݿ�����
# By default Redis shows an ASCII art logo only when started to log to the
# standard output and if the standard output is a TTY and syslog logging is
# disabled. Basically this means that normally a logo is displayed only in
# interactive sessions.
#
# However it is possible to force the pre-4.0 behavior and always show a
# ASCII art logo in startup logs by setting the following option to yes.
always-show-logo yes #�Ƿ���ʾlogo
set-proc-title yes
proc-title-template "{title} {listen-addr} {server-mode}"
����
�ڹ涨��ʱ���ڽ����˶��ٴβ�����־û��� .RDB .AOF
redis���ڴ����ݿ�,û�г־û��ͻ�ϵ缴ʧ
save 3600 1 #���3600������һ��key��������,�ͽ��г־û�����
save 300 100 #300�����г���100��key��������,�ͽ��г־û�����
save 60 10000 #............
#֮��ѧϰ�־û��ᰴ�Լ���ʵ�������������
stop-writes-on-bgsave-error yes #����־û��������Ƿ�Ҫ��������!
rdbcompression yes #�Ƿ�ѹ��RDB�ļ�,��Ҫ����һЩCPU����Դ
rdbchecksum yes #�Ƿ��ڱ���RDB�ļ���ʱ����м��У��
dir ./ #RDB�ļ������Ŀ¼
���Ӹ��� REPLICATION
################################# REPLICATION #################################
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
replicaof <masterip> <masterport> #��������
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the replica to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the replica request.
#
masterauth <master-password> #������������
��ȫ
requirepass 123456 #�������� Ĭ��û������
config set requirepass "123456" #��������������
auth 123456 #ʹ��������е�¼
�ͻ�������
maxclients 10000 #�����������������
maxmemory <bytes> #���������ڴ�����
maxmemory-policy noeviction #�ڴ�����֮��ľܾ�����
1��volatile-lru:ֻ�������˹���ʱ���key����LRU(Ĭ��ֵ)
2��allkeys-lru : ɾ��lru�㷨��key
3��volatile-random:���ɾ����������key
4��allkeys-random:���ɾ��
5��volatile-ttl : ɾ���������ڵ�
6��noeviction : ��������,���ش���
append only AOF����
appendonly no #Ĭ�ϲ�����(Ĭ��ʹ��RDB��ʽ�־û�)
appendfilename "appendonly.aof" #�־û����ļ���
# appendfsync always #ÿ���Ķ���ͬ��,��������
appendfsync everysec #ÿ��ִ��һ�� ���ܻᶪʧ��1���ֵ
# appendfsync no #��ִ��
Redis�־û�
Redis���ڴ����ݿ�,һ���ϵ�,���ݼ�ʧȥ,����RedisҲ�ṩ�����ݳ־û�����
RDB(Redis DataBase)
ʲô��RDB
��ָ����ʱ�����ڽ��ڴ��е����ݼ�����д�����,Ҳ�����л�����Snapshot����,���ָ�ʱ�ǽ������ļ�ֱ�Ӷ����ڴ��
Redis�ᵥ������(fork)һ���ӽ��������г־û�,���Ƚ�����д�뵽һ����ʱ�ļ���,���־û�����
��������,���������ʱ�ļ��滻�ϴγ־û��õ��ļ�������������,�������Dz������κ�IO�����ġ�
���ȷ���˼��ߵ����ܡ������Ҫ���д��ģ���ݵĻָ�,�Ҷ������ݻָ��������Բ��Ƿdz�����,��
RDB��ʽҪ��AOF��ʽ���ӵĸ�Ч��RDB��ȱ�������һ�γ־û�������ݿ��ܶ�ʧ������Ĭ�ϵľ���
RDB,һ������²���Ҫ���������!
dbfilename dump.rdb #rdbĬ���ļ���
save 60 5 #60��������5�ξͻ���г־û�
��������
- save�Ĺ�������ʱ�ᴥ��rdb����
- flushall�ᴥ��rdb����
- �˳�redis�ᴥ��rdb����
��λָ�rdb�ļ�
ֻ�轫rdb�ļ�����redis����Ŀ¼�Ϳ�����,redis������ʱ����Զ��ָ�rdb�ļ�������
127.0.0.1:6379> config get dir
1) "dir"
2) "/Users/mac" #��������Ŀ¼����dump.rdb�ļ�,edis������ʱ����Զ��ָ����е�����
Ĭ�����ü���
�������������rdb�ļ����б���!
�ŵ�:
- �ʺϴ��ģ�Ļָ�
- �����ݵ�������Ҫ��
ȱ��:
- ��Ҫһ����ʱ�������в���,���redis����崻���,���һ���ĵ����ݾ�û����
- fork���̵�ʱ���ռ��һ���ռ�
AOF (Append Only File)
����־��ʽ�����в�����¼��������Ϊ.aof�ļ�,�ָ���ʱ��Ͱ�����ļ�ȫ��ִ��һ��
��ʲô
aof����:
############################## APPEND ONLY MODE ###############################
appendonly no #Ĭ�ϲ�����,��Ҫ�ֶ�����Ϊyes
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# appendfsync always #�־û�����,ÿ���Ķ�д��
appendfsync everysec #�־û�����,ÿ��д��
# appendfsync no #�־û�����,��д��
no-appendfsync-on-rewrite no #�Ƿ���д,����д���Ա�֤��ȫ��
auto-aof-rewrite-percentage 100 #Ĭ�ϼ���
auto-aof-rewrite-min-size 64mb #���ļ�����64mb�ᴴ��һ���µ��ļ�
��appendonly��Ϊyes��Ϊ����aof
��������:
shutdown
redis-server ./redis.conf
д����.aof�ļ�����,��������redis-server����,redis�ṩ������һ������(Redis-check-aof)
redis-check-aof --fix appendonly.aof #ִ�д�������Զ���.aof�ļ�,����ɾ�������������!!
�ŵ��ȱ��
�ŵ�:
- ÿһ���Ķ�ͬ��,���ļ��������Ը���
ȱ��:
- �����ÿ��ͬ��һ��,�ᶪʧһ�������
- �����ļ����ԶԶ����rdb,��Ҳ��rdb��,����redisĬ�ϵ�������rdb,������aof
��չ:
-
rdb�־û���ʽ�ܹ���ָ����ʱ�����ڶ����ݽ��п��մ洢
-
aof�־û���ʽ��¼ÿ�ζԷ�����д�IJ���,����������ʱ,����ִ���������ָ�ԭʼ����,�����ļ�ĩβ,�ܶ�aof�ļ�������д,�����������
-
���ֻ�����治��Ҫʹ���κγ־û�
-
ͬʱ�������ֳּƻ���ʽ,����ʱ��������aof�ļ����ָ�����
ֻ����aof�ļ�,�����Ƽ�ֻʹ��rdb���ڱ���,�ܿ�������,���Ҳ�����aof����DZ�ڵ�bug
���ܽ��� -
rdb�ļ�ֻ������;,����ֻ��slave�ϳ־û�rdb�ļ�,15���ӱ���һ��,ʹ��save 900 1 ����
-
ʹ��aof,����������ӵĻ�����Ҳ���ᶪʧ����2�������
-
����:������io
rewrite �����в�����������д�����ļ���ɵ��������ɱ���,��������rewrite��Ƶ�� -
��ʹ��aof,Ҳ����ͨ��Master-Slave Replication ʵ�ָ߿�����Ҳ����,��ʡȥһ���io,����rewrite������ϵͳ����
����:���Master-Slave ͬʱ����,�ض�ʧʮ�����ӵ�����,�����ű�ҲҪ�Ƚ�Master-Slave�е�rdb�ļ�,ѡ�����µ��ļ�,�����µ�,���������ּܹ�
��������
Redis��������(pub/sub)��һ��ͨ��ģʽ:������(pub)������Ϣ,������(sub)������Ϣ,��,�š�����
Redis�ͻ��˿��Զ����κ�������Ƶ��
����������Ϣͼ:
1����Ϣ������
2��Ƶ��
3����Ϣ������
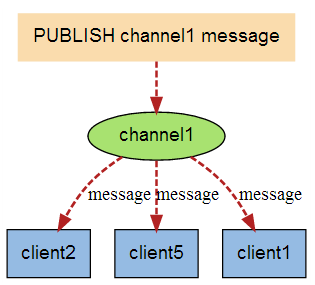
Redis ������������
�±��г��� redis �������ij�������:
| ��� | ������� |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ��] ����һ���������ϸ���ģʽ��Ƶ���� |
| 2 | [PUBSUB subcommand argument [argument ��]] �鿴�����뷢��ϵͳ״̬�� |
| 3 | PUBLISH channel message ����Ϣ���͵�ָ����Ƶ���� |
| 4 | [PUNSUBSCRIBE pattern [pattern ��]] �˶����и���ģʽ��Ƶ���� |
| 5 | [SUBSCRIBE channel channel ��] ���ĸ�����һ������Ƶ������Ϣ�� |
| 6 | [UNSUBSCRIBE channel [channel ��]] ָ�˶�������Ƶ���� |
����
127.0.0.1:6379> psubscribe mychannel #����Ƶ��
Reading messages... (press Ctrl-C to quit) #�ȴ���ȡ���͵���Ϣ
127.0.0.1:6379> publish mychannel "send a message" #������Ϣ
#���Ķ˽��յ���Ϣ
1) "pmessage" #��Ϣ
2) "mychannel" #�ĸ�Ƶ������Ϣ
3) "mychannel"
4) "send a message" #��Ϣ������
ԭ��
ÿ��Redis ���������̶�ά����һ����ʾ������״̬�� redis.h/redisServer �ṹ, �ṹ�� pubsub_channels ������һ���ֵ�, ����ֵ�����ڱ��涩��Ƶ������Ϣ,����,�ֵ�ļ�Ϊ���ڱ����ĵ�Ƶ��, ���ֵ��ֵ����һ������, �����б��������ж������Ƶ���Ŀͻ��ˡ�
ʹ�ó���
- ʵʱ��Ϣϵͳ
- ʵʱ����(Ƶ����Ϊ������)
- ���ġ���עϵͳ
�����ӵij�����ʹ����Ϣ�м������(RabbitMQ��)
���Ӹ���
����
���Ӹ���,��ָ��һ̨Redis������������,���Ƶ�������Redis��������ǰ�߳�Ϊ���ڵ�(Master/Leader),���߳�Ϊ�ӽڵ�(Slave/Follower), ���ݵĸ����ǵ����!ֻ�������ڵ㸴�Ƶ��ӽڵ�(���ڵ���дΪ�����ӽڵ��Զ�Ϊ��)��
Ĭ�������,ÿ̨Redis�������������ڵ�,һ�����ڵ������0�����߶���ӽڵ�,��ÿ���ӽڵ�ֻ����һ�����ڵ㡣
����
- ��������:���Ӹ���ʵ�������ݵ��ȱ���,�dz־û�֮���һ����������ķ�ʽ��
- ���ϻָ�:�����ڵ����ʱ,�ӽڵ������ʱ������ڵ��ṩ����,��һ�ַ�������ķ�ʽ
- ���ؾ���:�����Ӹ��ƵĻ�����,��϶�д����,�����ڵ����д����,�ӽڵ���ж�����,�ֵ��������ĸ���;�������ڶ����д�ij�����,ͨ������ӽڵ�ֵ�����,��߲�������
- �߿��û�ʯ:���Ӹ��ƻ����ڱ��ͼ�Ⱥ�ܹ�ʵʩ�Ļ�����
����ֻʹ��һ̨redis��ԭ��:
- �ӽṹ�Ͻ�,����redis�������ᷢ���������,һ̨��������Ҫ������������,ѹ����
- �������Ͻ�,����redis�������ڴ���������,���Ҳ�����ȫʹ��ȫ�����ڴ�,��̨redis������ڴ治Ӧ�ó���20g
ͨ���ĵ�����վ����һ���ϴ���,���������,����д�� ,���Ӹ���,��д����,80%��������ڽ��ж�����,����һ������
ֻҪ���ڹ�˾��ʹ��,���Ӹ��Ʊ���ʹ��,������ʹ�õ���
��������
ֻ���ôӿ�,������������
redis-server #����������
info replication #�鿴��ǰ�ڵ���Ϣ
# Replication
role:master #��ǰ�ڵ���Ϣ
connected_slaves:0 #�ӻ�����
master_failover_state:no-failover
master_replid:906a84bfb098cf9ddfc3cfc39b5b26419a644a77
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
�������������ļ�,�Ķ�Ӧ������Ϣ
- �˿ں�
- pid
- ��־��
- ������
���������redis����
redis-server ./redis.conf
...
���Ӹ�������
Ĭ�������ÿ���ڵ㶼�����ڵ�,һ��ֻҪ���ôӻ��Ϳ�����
����
slaveof 127.0.0.1 6000 #�����ڵ�����Ϊ����6000�˿ڵĴӻ�
��ʵ����������Ӧ���������ļ�����,����ʹ�õ�������,������ʧЧ,���ù�����֮ǰ��Redis.conf�½�
ϸ��
- ��������д,�ӻ������!�����е��������ݶ��ᱻ�ӻ�����,�ӻ�д�ᱨ��
- ���������ӻ��ᱣ������
- ����������������֮��,�ӻ���Ȼ���Զ�ȡ������set��ֵ
- ���ʹ����������������,������Ĭ����Ϊ��������,��������Ϊ�����Ĵӻ�����Զ�ͬ������(ȫ������),����������ļ�����������,����ʱ�Զ�ͬ������������
�ӻ���һ�����ӻ�ͬ����������:ȫ������
������ÿһ�β���ͬ�����ӻ�:��������
���Ӹ��Ƶ�����ʵ��
��һ��Master������һ��Slave(�ȵ������ֵ��ӻ�,����ʱ����ڵ㲻��д��,ֻ�������ڵ�ҵ�֮��,ʹ��slaveof no one��������øýڵ���Ϊ���ڵ����д��)
�����ڱ�ģʽû�г��ֵ�ʱ��ķ���
�ڱ�ģʽ
����
�����л������ķ�����:����������崻���,��Ҫ�ֶ���һ̨�ӷ������л�Ϊ��������,�����Ҫ�˹���Ԥ,���·���,�������һ��ʱ���ڷ����á��ⲻ��һ���Ƽ��ķ�ʽ,����ʱ��,�������ȿ����ڱ�ģʽ��
�����ڱ�ģʽ
�ڱ�������:
- ͨ����������,��Redis���������ؼ��������״̬,�������������ʹӷ�������
- ���ڱ���master崻�,���Զ���slave�л���master,Ȼ��ͨ����������ģʽ֪ͨ�����Ĵӷ�����,�������ļ�,�������л�������
���ڱ�ģʽ
����master崻�,sentinel�ȼ�������,ϵͳ���������Ͻ���failover(�����л���ʧЧ��Ԯ)��������Ϊ��������,��������ڱ�Ҳ����������������,sentinel֮��ᷢ��һ��ͶƱ,ͶƱ�Ľ�������һ��sentinel����,����failover����,�õ�sentinelƱ�����slave�ܳɹ��л�Ϊmaster,�л��ɹ���,ͨ����������ģʽ,�ø����ڱ����Լ���صķ�����ʵ���л�����,������̳�Ϊ��������
����
Ŀǰ��״̬��һ������
- �����ڱ������ļ�sentinel.conf
##sentinel monitor ��ص����� ��صĵ�ַ ��صĶ˿� 1
sentinel monitor myredis 127.0.0.1 6000 1
�����1����������������ôӻ�ͶƱ,��Ʊ��ѡ��������
- �����ڱ�
redis-sentinel ./conf/sentinel.conf #�������ļ������ڱ�
- �ڱ���ص�����Ϣ:
3128:X 03 Apr 2021 16:14:53.825 # +monitor master myredis 127.0.0.1 6000 quorum 1 #����Ϊ����6000�˿�
#�������ӻ� �ֱ�Ϊ����6001�˿ں�6002�˿�
3128:X 03 Apr 2021 16:14:53.827 * +slave slave 127.0.0.1:6001 127.0.0.1 6001 @ myredis 127.0.0.1 6000
3128:X 03 Apr 2021 16:14:53.828 * +slave slave 127.0.0.1:6002 127.0.0.1 6002 @ myredis 127.0.0.1 6000
- ���������������
#�ڱ���־:
3128:X 03 Apr 2021 16:19:57.771 # +failover-end master myredis 127.0.0.1 6000 ��ص�6000�˿ڶϿ�����
3128:X 03 Apr 2021 16:19:57.771 # +switch-master myredis 127.0.0.1 6000 127.0.0.1 6002 �Զ�ͶƱѡ��,6002ѡ��Ϊ����
3128:X 03 Apr 2021 16:19:57.771 * +slave slave 127.0.0.1:6001 127.0.0.1 6001 @ myredis 127.0.0.1 6002 #��6001����������Ϊ6002
3128:X 03 Apr 2021 16:19:57.771 * +slave slave 127.0.0.1:6000 127.0.0.1 6000 @ myredis 127.0.0.1 6002 #��6000����������Ϊ6002,��6000�˿���������ʱ����ֱ��ͬ������������
��������ҵ�����������,ԭ������������Ϊ�ӻ�
�ŵ�:
- �ڱ���Ⱥ�������Ӹ���,�����������õ��ŵ�,������
- ���ӿ����л�,���Ͽ���ת��,ϵͳ�Ŀ����Ծͻ����
- �ڱ�ģʽ��������ģʽ������,���ֶ����Զ�,���ӽ�׳
ȱ��:
- redis��������������,��Ⱥ�����ﵽ����,������չ�dz��鷳
- ʵ���ڱ�ģʽ��������ʵ�Ǻ��鷳��,�����кܶ�����
�ڱ���ȫ������
# Example sentinel.conf
# �ڱ�sentinelʵ�����еĶ˿� Ĭ��26379 ������ڱ���Ⱥ,����Ҫ����ÿ���ڱ��Ķ˿�
port 26379
# �ڱ�sentinel�Ĺ���Ŀ¼
dir /tmp
# �ڱ�sentinel��ص�redis���ڵ�� ip port
# master-name �����Լ����������ڵ����� ֻ������ĸA-z������0-9 ���������ַ�".-_"��ɡ�
# quorum ����Щquorum����sentinel�ڱ���Ϊmaster���ڵ�ʧ�� ��ô��ʱ ������Ϊ���ڵ�ʧ����
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# ����Redisʵ���п�����requirepass foobared ��Ȩ���� ������������Redisʵ���Ŀͻ��˶�Ҫ�ṩ����
# �����ڱ�sentinel �������ӵ����� ע�����Ϊ��������һ������֤����
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# ָ�����ٺ���֮�� ���ڵ�û��Ӧ���ڱ�sentinel ��ʱ �ڱ���������Ϊ���ڵ����� Ĭ��30��
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# ���������ָ�����ڷ���failover�����л�ʱ�������ж��ٸ�slaveͬʱ���µ�master���� ͬ��,
�������ԽС,���failover�����ʱ���Խ��,
��������������Խ��,����ζ��Խ ���slave��Ϊreplication�������á�
����ͨ�������ֵ��Ϊ 1 ����֤ÿ��ֻ��һ��slave ���ڲ��ܴ������������״̬��
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# ����ת�Ƶij�ʱʱ�� failover-timeout ��������������Щ����:
#1. ͬһ��sentinel��ͬһ��master����failover֮��ļ��ʱ�䡣
#2. ��һ��slave��һ�������master����ͬ�����ݿ�ʼ����ʱ�䡣ֱ��slave������Ϊ����ȷ��master����ͬ������ʱ��
#3.����Ҫȡ��һ�����ڽ��е�failover����Ҫ��ʱ�䡣
#4.������failoverʱ,��������slavesָ���µ�master��������ʱ�䡣����,��ʹ���������ʱ,slaves��Ȼ�ᱻ��ȷ����Ϊָ��master,���ǾͲ���parallel-syncs�����õĹ�������
# Ĭ��������
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#���õ�ijһ�¼�����ʱ����Ҫִ�еĽű�,����ͨ���ű���֪ͨ����Ա,���統ϵͳ���в�����ʱ���ʼ�֪ͨ�����Ա��
#���ڽű������н�������¹���:
#���ű�ִ�к�1,��ô�ýű��Ժᱻ�ٴ�ִ��,�ظ�����ĿǰĬ��Ϊ10
#���ű�ִ�к�2,���߱�2���ߵ�һ������ֵ,�ű��������ظ�ִ�С�
#����ű���ִ�й����������յ�ϵͳ�ж��źű���ֹ��,��ͬ����ֵΪ1ʱ����Ϊ��ͬ��
#һ���ű������ִ��ʱ��Ϊ60s,����������ʱ��,�ű����ᱻһ��SIGKILL�ź���ֹ,֮������ִ�С�
#֪ͨ�ͽű�:��sentinel���κξ��漶����¼�����ʱ(����˵redisʵ��������ʧЧ�Ϳ�ʧЧ�ȵ�),����ȥ��������ű�,
#��ʱ����ű�Ӧ��ͨ���ʼ�,SMS�ȷ�ʽȥ֪ͨϵͳ����Ա����ϵͳ���������е���Ϣ�����øýű�ʱ,�������ű���������,
#һ�����¼�������,
#һ�����¼���������
#���sentinel.conf�����ļ�������������ű�·��,��ô���뱣֤����ű����������·��,�����ǿ�ִ�е�,����sentinel�����������ɹ���
#֪ͨ�ű�
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# �ͻ��������������ڵ�����ű�
# ��һ��master����failover�������ı�ʱ,����ű����ᱻ����,֪ͨ��صĿͻ��˹���master��ַ�Ѿ������ı����Ϣ��
# ���²��������ڵ��ýű�ʱ�����ű�:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# Ŀǰ<state>���ǡ�failover��,
# <role>�ǡ�leader�����ߡ�observer���е�һ����
# ���� from-ip, from-port, to-ip, to-port�������;ɵ�master���µ�master(���ɵ�slave)ͨ�ŵ�
# ����ű�Ӧ����ͨ�õ�,�ܱ���ε���,��������Եġ�
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
��������һ������ά������
���洩��������ѩ��
����Ĵ���������ѩ�����Ƿ������ĸ߿�������
���洩(�鲻��)
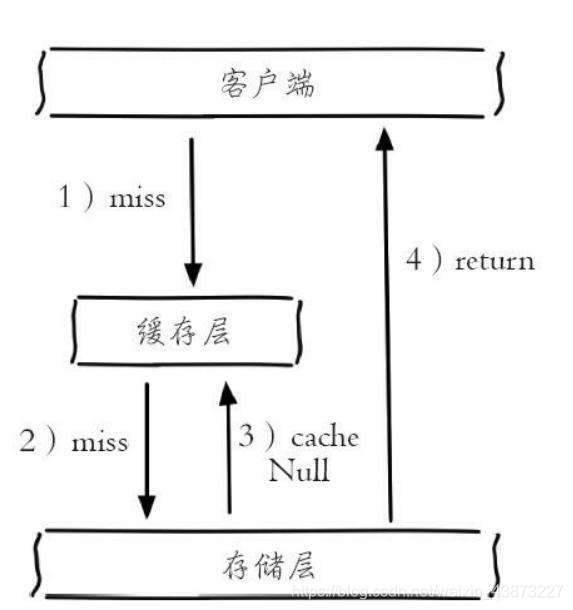
����
��Ĭ�������,�û���������ʱ,�����ڻ���(Redis)�в���,��û�ҵ�������δ����,�������ݿ��н��в���,�����ٿ������ⲻ��,����һ����������������(������ɱ����)���涼û�����еĻ�,�ͻ�ȫ��ת�Ƶ����ݿ���,������ݿ⼫���ѹ��,���п��ܵ������ݿ���������簲ȫ��Ҳ���˶���ʹ�������ֶν��й�������Ϊ��ˮ������
�������
-
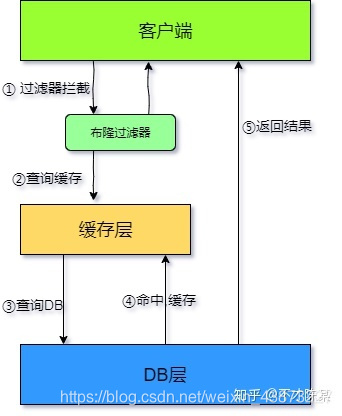
��¡������
�����п��ܲ�ѯ�IJ�����Hash����ʽ�洢,�Ա����ȷ���Ƿ�������ֵ,�ڿ��Ʋ��Ƚ�������У��,У�鲻ͨ��ֱ�Ӵ��,�����˴洢ϵͳ��ѹ����
- �����ֵ
�������(��̫��,һ����Ļ������)
����
����ڻ��洩,���������Ŀ���Ը�ǿ,һ�����ڵ�key,�ڻ�����ڵ�һ��,ͬʱ�д���������,��Щ���������DB,���˲ʱDB��������ѹ������������ǻ��汻����,ֻ���������ij��key�Ļ��治���ö����»���,����������key��Ȼ����ʹ�û�����Ӧ��
��������������,һ���ȵ����ű�ͬʱ�������ʾͿ��ܵ��»��������
�������
�����ȵ�������������
�����Ͳ�������ȵ����ݹ��ڵ����,���ǵ�Redis�ڴ�ռ�����ʱ��Ҳ��������������,���Ҵ��ַ�����ռ�ÿռ�,һ���ȵ����ݶ�������,�ͻ�ռ�ò��ֿռ䡣
�ӻ�����(�ֲ�ʽ��)
�ڷ���key֮ǰ,����SETNX(set if not exists)��������һ������key����ס��ǰkey�ķ���,���ʽ�����ɾ���ö���key����֤ͬʱ��ֻ��һ���̷߳��ʡ�����������Ҫ���ʮ�ָߡ�
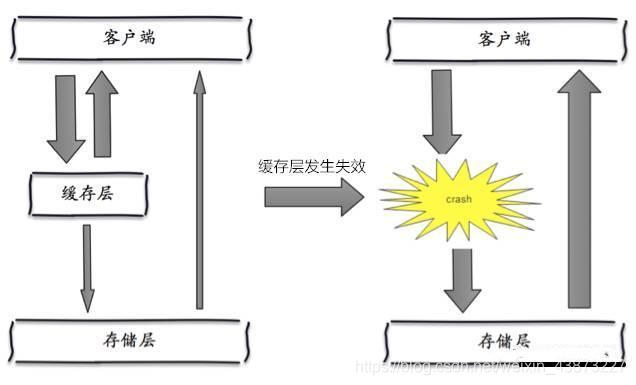
����ѩ��(������ijһʱ�仺�漯��ʧЧ)
����
����ѩ����ԭ��֮һ,���û���Ĵ��ʱ��϶�,������ʱ�պö�����,ֱ�ӷ��������ݿ�,�����ݿ����,�����������ѹ������,����ʱ���ݿ���ܻ�崻�
˫ʮһʱ��ͣ��һЩ����,��֤��Ҫ��һЩ�������,����:�˿����
�������:
-
��ض��
���Ӽ�Ⱥ�з���������
-
��������
����ʧЧ��,ͨ���������߶��������ƶ����ݿ�д������߳�����,��ij��keyֻ����һ���̲߳�ѯ���ݺ�д����,�����̵߳ȴ� -
����Ԥ��
��ʽ����֮ǰ,�ѿ��ܵ�������ǰ����һ��,���ܴ������ʵ����ݾͻ���ص�������,���ز�ͬ��key,���ò�ͬ�Ĺ���ʱ��,�û���ʱ�価������