文章目录
1、为什么InnoDB表必须要建主键,且推荐使用整型自增主键
InnoDB表数据是使用B+ Tree进行存储,需要一个具有唯一性的字段组织形成B+ Tree。
如果没有建主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引;
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引。
为避免MySQL消耗宝贵的资源维护隐性的索引,最好为每个InnoDB表设置主键。
为什么推荐使用整型索引呢?
在定位某一个索引时,需要进行多次的数据比较,才能确定索引我位置,
在比较速度上来说,整型的明显快于字符串。
从空间消耗上来说,字符串消耗的空间一般比整型大。
为什么推荐使用自增呢?
InnoDB数据文件的存储形式本事就是B+ Tree,叶子节点的存储是有顺序的。
如果不使用自增,需要在叶子节点中找到合适的位置,进行节点拆分并插入;
而使用自增时,只需要在叶子结点的最后面追加一个节点即可。
2、为什么非主键索引的叶子结点存储的是主键索引?
1)保持数据的一致性(当数据发生修改时,只需修改主键索引B+ Tree中的数据);
2)节省存储空间,相比于存储数据来说,存储主键索引明显更加节省空间。
3、索引B+ Tree
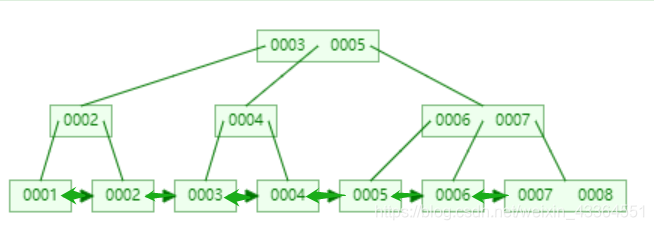
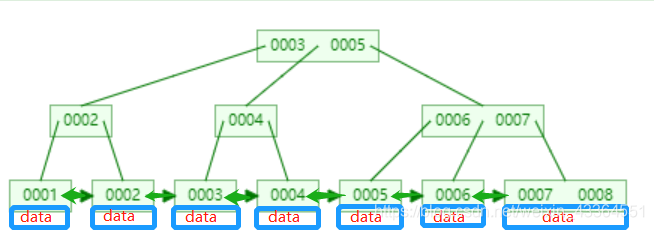
4、为什么使用B+ Tree?
- 对于有序的数据插入时,二叉树会退化成链表
- 红黑树:树的高度不可控
5、B Tree与B+ Tree
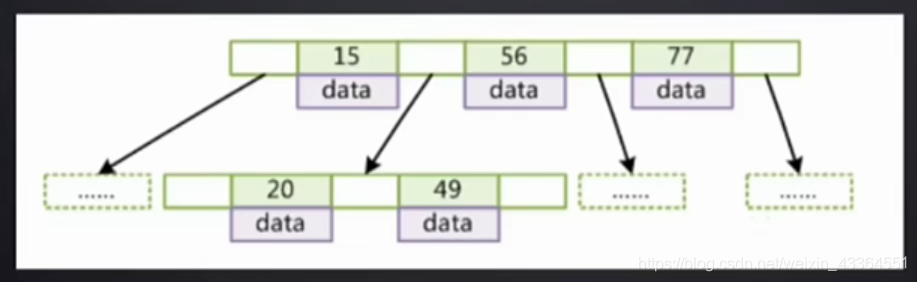
-
B Tree
- 叶结点高度相同,叶结点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
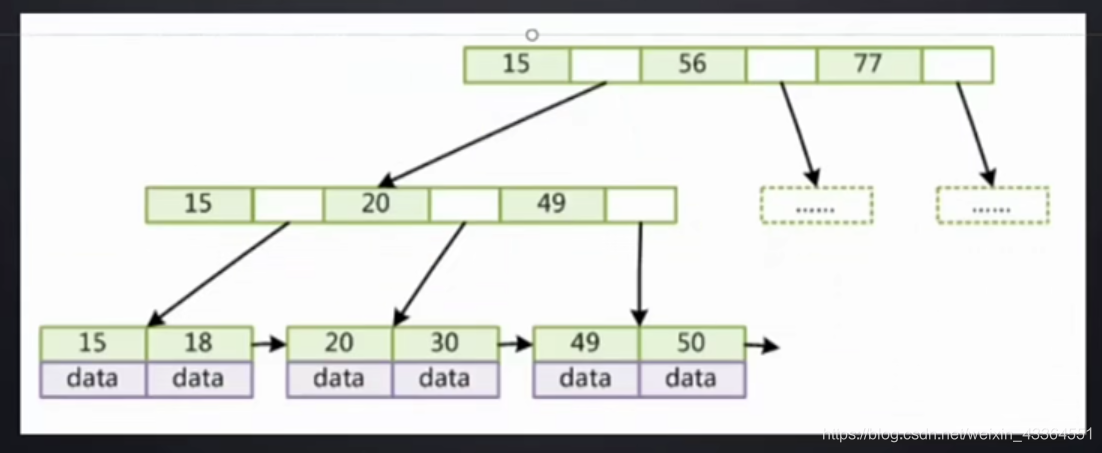
-
B+ Tree
- 非叶子节点不存储data,只存储索引,为了可以节省空间,一个大节点(默认16KB)可以放更多的节点
- 叶子节点包含所有索引字段
- 叶子节点间用双向指针连接,可以提高区间访问的性能。
6、Hash索引的局限性
无法进行范围查找,模糊查找,以及order by也无法走索引