Flume概述
Flume定义
Flume是一个高可用,高可靠,分布式的海量日志采集,聚合和传输的系统,基于流式架构,灵活多变。
Flume基础架构

Agent:是一个JVM进程,它以事件的形式将数据从数据源传输至目的地,包括Source,Channel,SInk。
Source:接收各种类型,各种格式的日志数据,常见的有:exec,avro,spooling directory,netcat,taildir等等。
SInk:从Channel中拉取数据,并将这些数据批量写入指定数据目的地,常见的子组件目的地有:HDFS,Kafka,Logger,avro,file,HBase等等。
Channel:位于Source和Sink之间的事件缓冲区,Channel是线程安全的,可以同时处理几个Source发来的事件数据和几个Sink的消费数据操作,常见的两种Channel:Memory Channel和File Channel。Memory Channel是内存中的队列,将数据存储在内存中,但出现集群出错,机器宕机等故障时,会发生数据丢失。File Channel将事件数据存储在磁盘中,当机器宕机,程序出错时,不会丢失数据。
Event:Flume 的数据传输单元,Flume将数据打包为Event形式,从数据源传输至数据目的地。Event包括两部分,header和body,header存储Event的一些属性,body存储数据,类型为字节数组。

Flume入门
本文Flume基于flume-1.8.0,安装部署略。
Flume官方入门案例:监控端口数据
1) 需求:
监控一个端口,并将数据打印至控制台。
2) 需求分析:
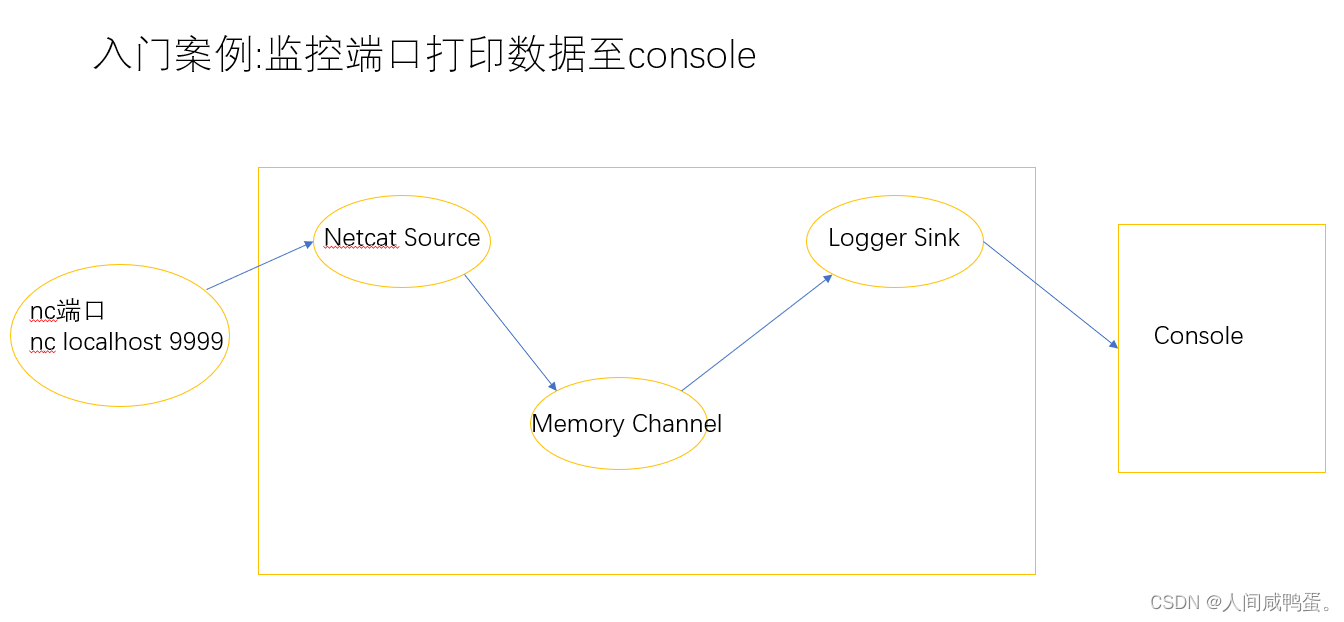
配置文件:
FileName: netcat-logger.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
使用步骤:
【1】 先启动Flume监听端口
【2】 开启端口,发送信息,等待Flume获取数据
实时监控单个追加文件
1) 案例需求:实时监控Hive日志信息,并上传至HDFS中
2) 需求分析图:
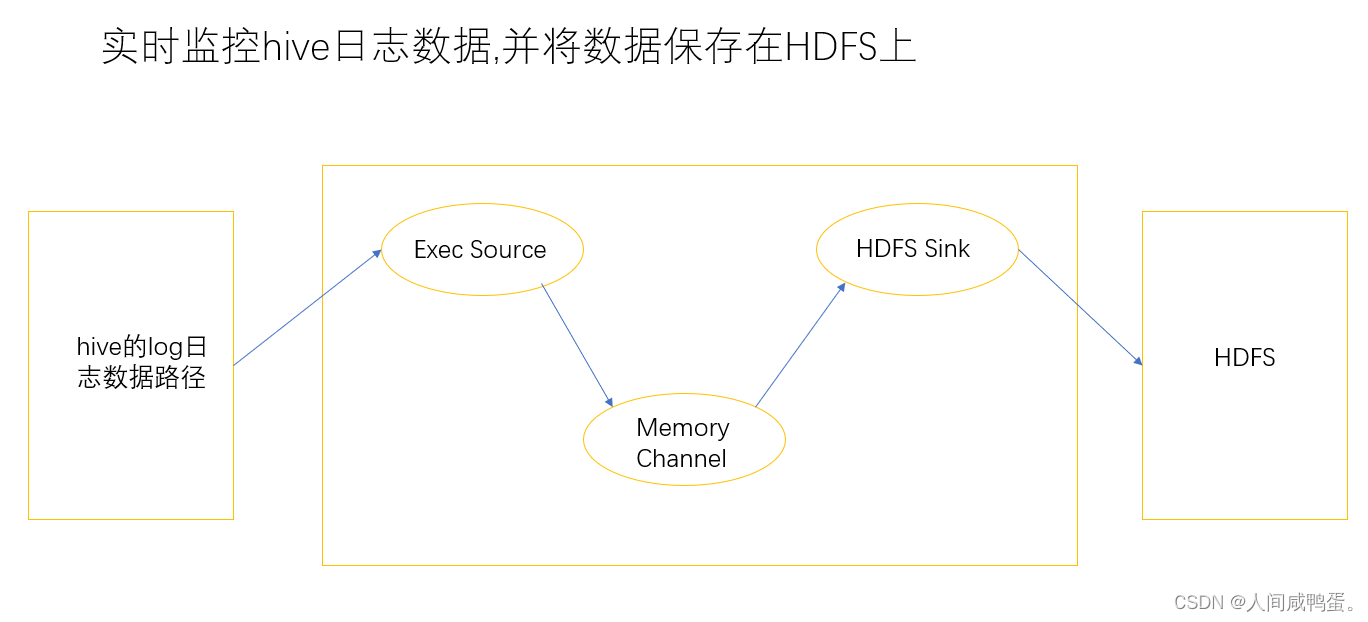
3) 配置文件
FileName: exec-hdfs.conf
a2.sources = r2
a2.channels = c2
a2.sinks = k2
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive-3.1.2/logs
# Describe the sink a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- 执行步骤:
【1】 启动Flume实现监控
【2】 开启hive,操作数据
【3】 在HDFS上查看文件的产生和变化
实时监控目录下多个新文件
1) 案例需求,使用Flume监控整个目录中的文件,并上传至HDFS
2) 需求分析图:
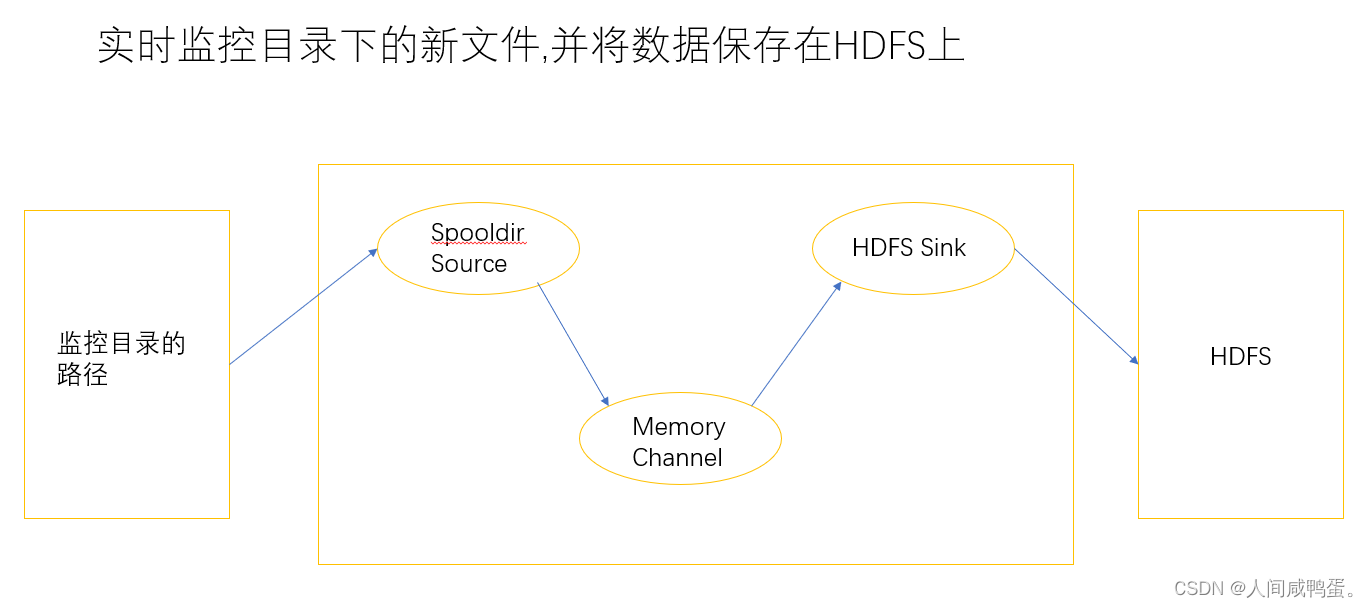
3) 配置文件
FileName:spoolDir-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/data
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path=hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
- 操作步骤:
【1】 启动flume监控目录
【2】 向指定目录中添加文件,使用touch命令,例如touch demo.txt
【3】 在HDFS上查看数据
实时监控目录下多个追加文件
1) 案例需求
使用Flume实时监控指定目录下的文件数据的波动与变化,并将数据保存至HDFS中。
2) 案例分析
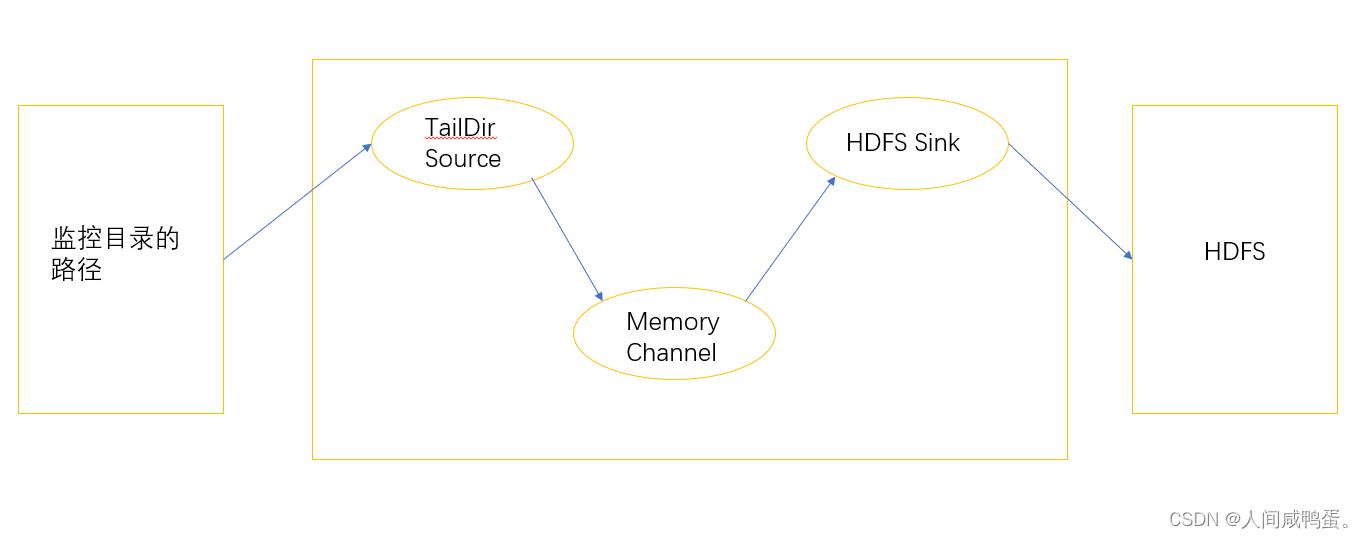
3) 配置文件
FIleName:tail-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/files
# create filegroups
a3.sources.r3.filegroups = f1 f2
# f1监控的文件类型
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
# f2监控的文件类型
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
4) 操作步骤
【1】 启动Flume监控指定目录
【2】 向指定目录中的文件添加数据,例如 echo hello>> file1.txt
【3】 在HDFs上查看数据变化情况
exec/spooldir/taildir Source比较
exec:用来监控目录数据变化,不能实现断点续传,当机器宕机后,并不能从当前断点继续监控,容易发生数据丢失。
spooldir:适用于同步新文件,但不适合对实时追加的日志文件进行监听和同步。
taildir:维护了一个json格式的position file,会定期往position file中更新每个文件读取到的最新位置,适合监听多个实时追加的文件,并且能够实现断点续传。
Flume进阶
Flume事务
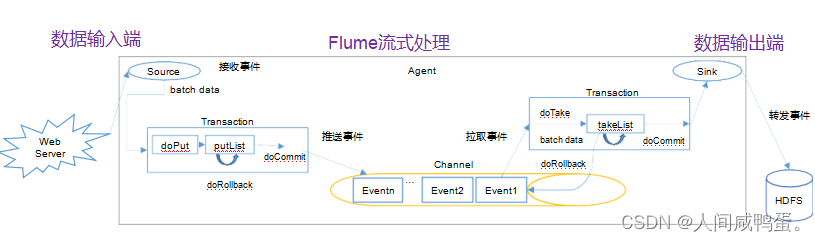
put事务
-doput:将数据线写入仅是缓冲区putList
-doCommit:检查channel内存队列是否能够合并
-doRollback:channel内存队列资源不足时,回滚数据
take事务:
-dotake:将数据拉取到takeList中,并将数据发送到HDFS
-doCommit:如果数据全部发送成功,则清楚临时缓冲区takeList中的数据
-doRollback:如果sink拉取数据时出现异常情况,rollBack将临时缓冲区数据归还给channel内存队列
Flume Agent内部原理
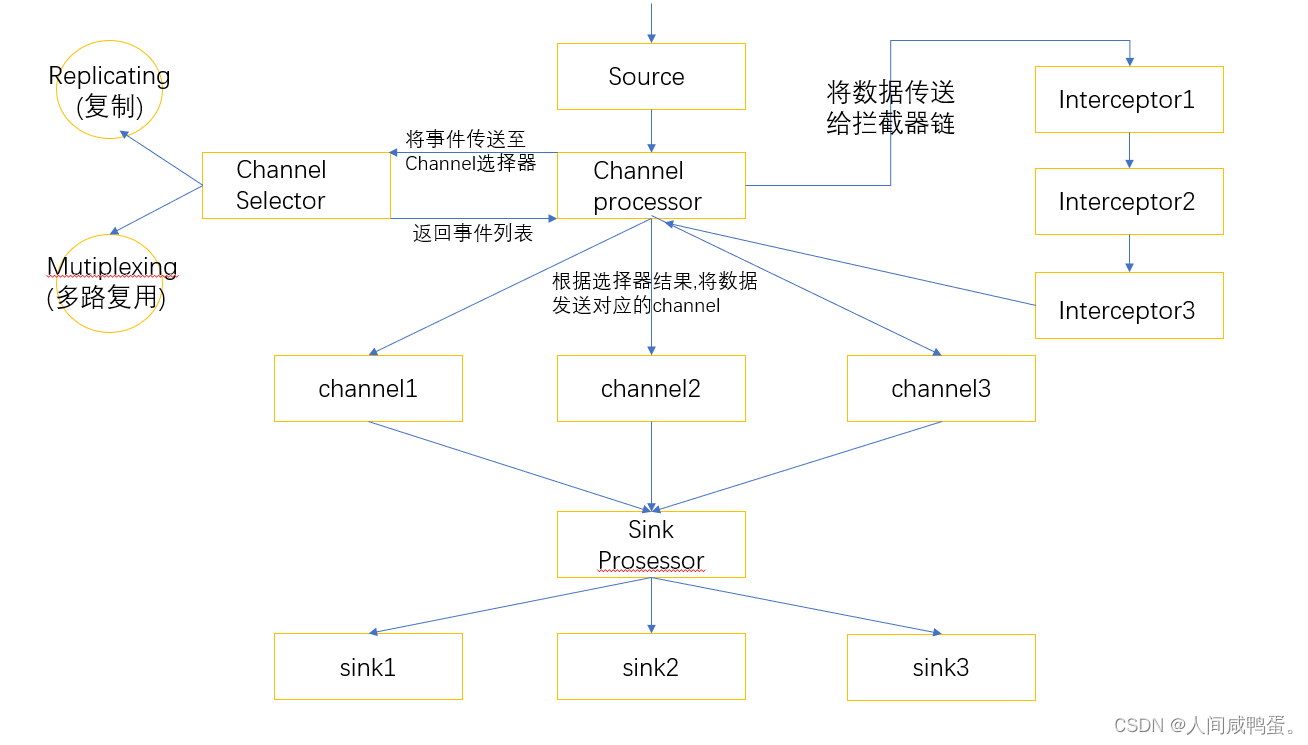
Channel selector:选出Event将要发往哪个channel,有两种类型,Replicating和Mutiplexing。Replicating会将Event发往所有的Channel,Mutiplexing会根据相应的原则,将不同的Event发往不同的Channel。
Sink Prosessor:总共有三种类型,分别为DefaultSinkProsessor,LoadBalancingSinkProsessor和FailoverSinkProsessor。
DEfaultSinkProsessor对应的是单个的Sink,LoadBalancingSinkProsessor和FailoverSinkProsessor对应的是Sink Group。LoadBalancingSinkProsessor可以实现负载均衡,FailoverSinkProsessor可以实现故障转移。
Flume拓扑结构
简单串联结构
在这里插入图片描述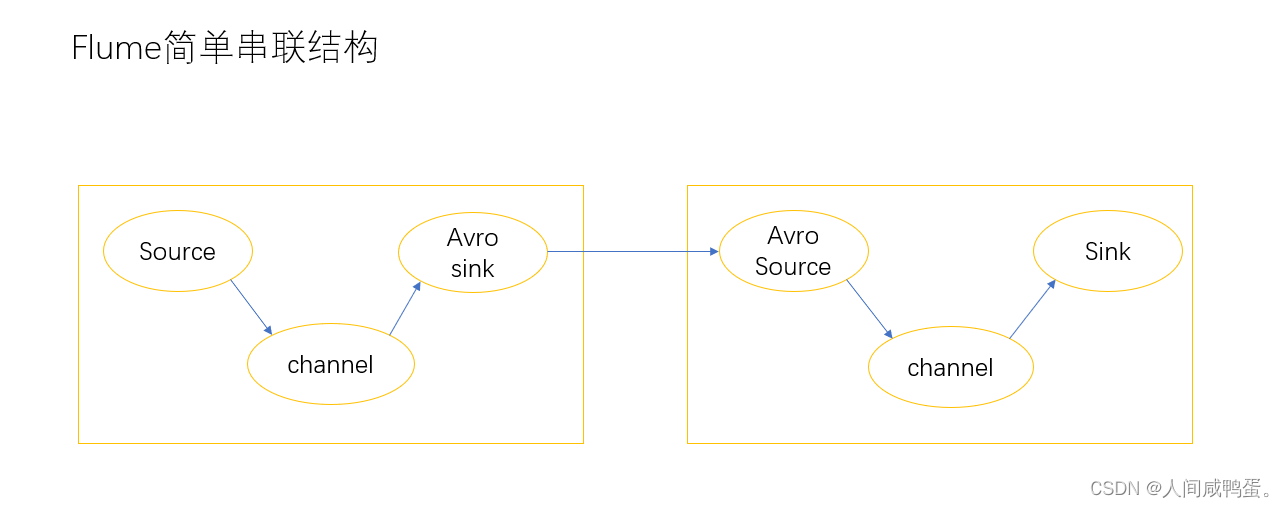
串联结构依托于avro sink 和avro source,avro sink 传出数据,avro source接收数据,并将数据发送给下一个channel,实现数据串联,但此模式下不宜过多桥接,flume数量过多不仅影响传输速率,当进群宕机时,会导致数据的丢失。
复制和多路复用
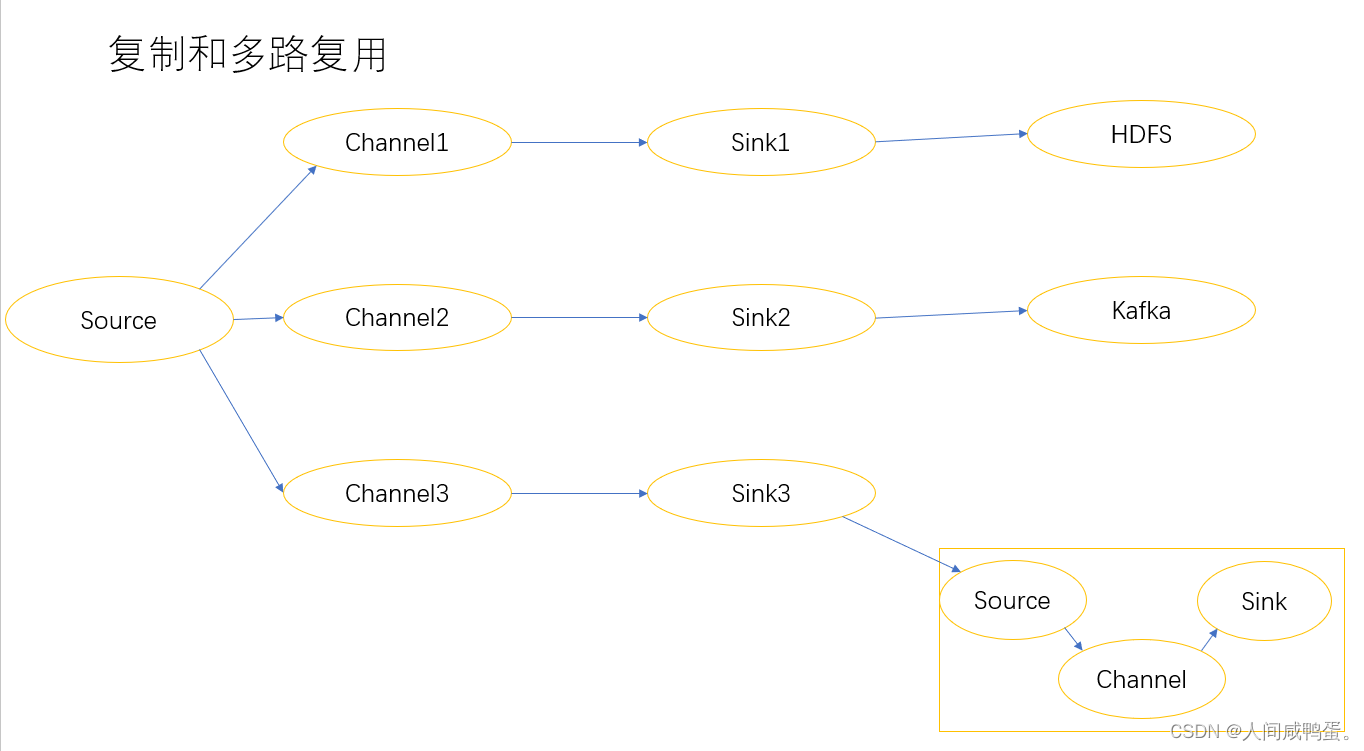
Flume支持将数据流向一个或多个目的地,这个模式可以将相同的数据复制到多个Channel中,或者将不同的数据分发到不同的Channel中,Sink可以选择数据的目的地。
负载均衡和故障转移
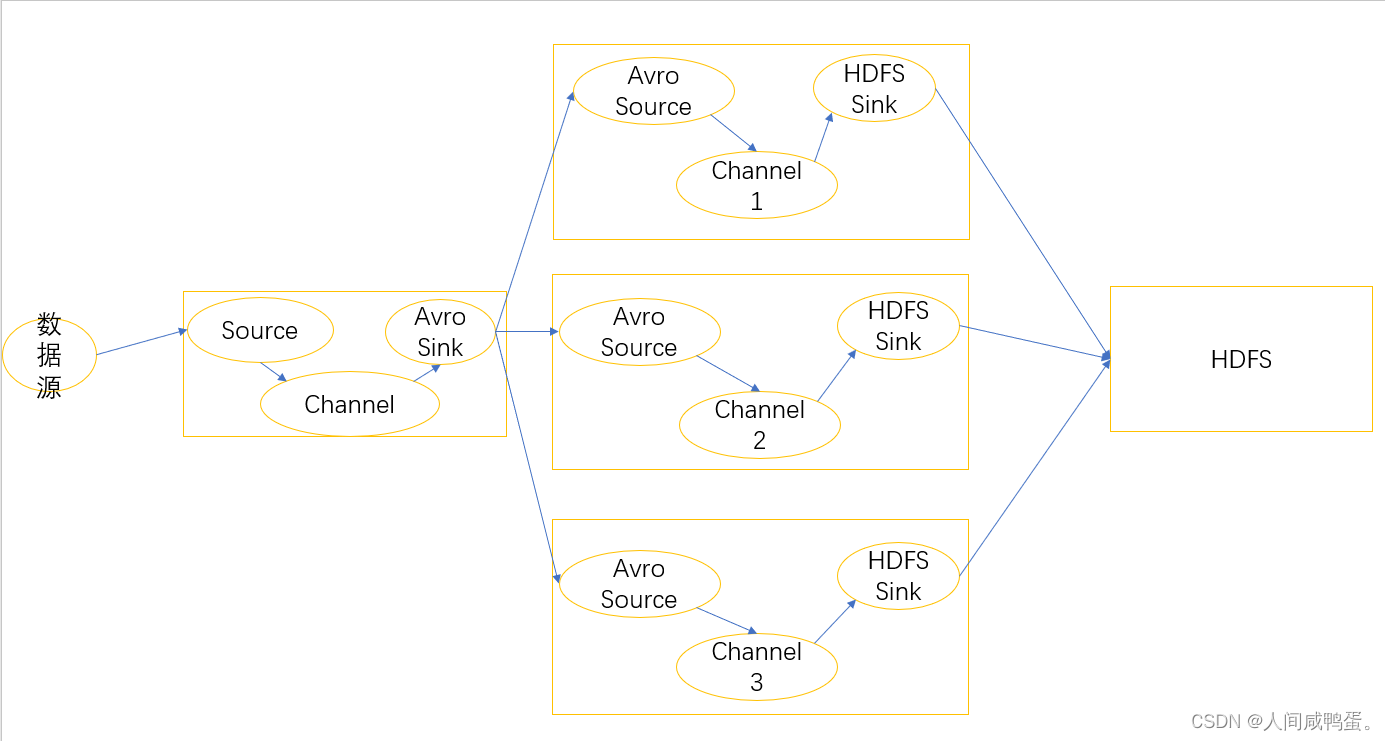
Flume支持使用将多个SInk逻辑上分到一个组中,使用故障转移时,当优先级高的Flume宕机之后,会将数据继续发往下一个优先级高的Flume中,使用负载均衡时,每一个Flume获取一份avro Sink的数据,保证数据的一致性,减少数据丢失。
聚合
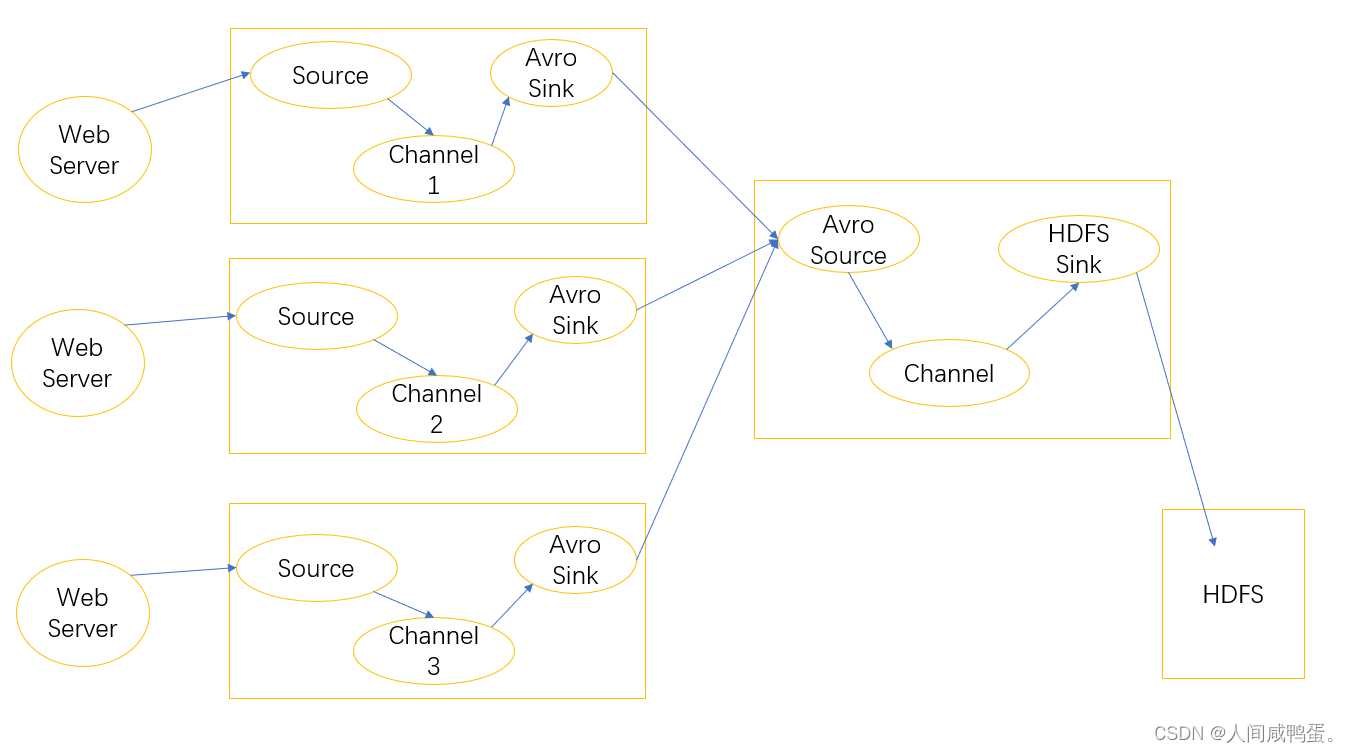
从不同的数据源中获取日志数据,并且从个各自的Flume,发送至同一Flume中,将数据汇集处理,最终将汇总数据发送至HDFS中持久化存储。
Flume自定义拦截器
在十级开发中,服务器产生的日志数据并不全都需要传送给数据目的地,要实现筛选功能,将无用的数据过滤, 减轻存储压力,因此需要使用拦截器实现数据的ETL操作。
自定义拦截器实现Interceptor接口
实现Event时间中包含行为信息(actonInfo)的数据传送至一个Flume,包含初始信息(startInfo)的数据传送至另一个Flume。
代码如下:
package com.atfan.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class DefineInterceptor implements Interceptor {
private ArrayList<Event> addEvents;
@Override
public void initialize() {
addEvents = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
// 获取headers
Map<String, String> headers = event.getHeaders();
// 获取body
String body = new String(event.getBody());
// 过滤数据
if (body.charAt(0) == '{' && body.charAt(body.length()-1) =='}'){
headers.put("info","actionInfo");
}else {
headers.put("info","startInfo");
}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
addEvents.clear();
for (Event event : list) {
addEvents.add(intercept(event));
}
return addEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new DefineInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
Source和Sink使用Apache官方文档提供的接口工具已经足够处理业务数据,使用自定义的函数相对少一些。在次便不在一一实现。
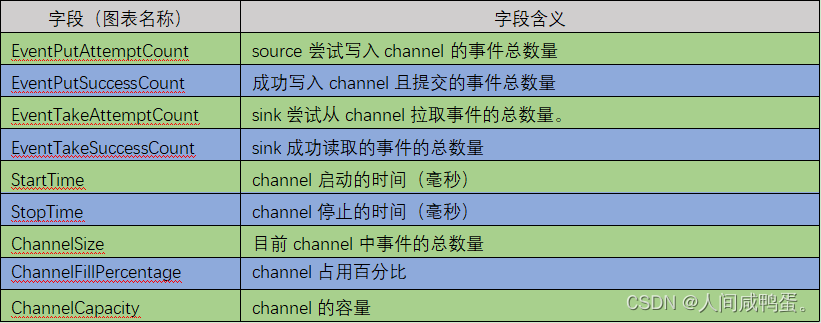
Flume监控
使用GangLia实现Flume监控,主要的字段信息如下。
Flume监控在生产环境下还是极为常用的,包括数据的变化,以及集群宕机后,数据的丢失等情况,提供友好的可视化界面,操作简易,带给用户舒心体验。