0 前言
大家好,我是小林!
至今,我们已经聊了 Spark 中什么叫 RDD,为什么要提出 RDD 这个概念,RDD 转换的本质其实是数据形态的转换;第二篇文章提到:一个 Spark application 如何生成 Job 逻辑执行图,如何转换为 Job 物理执行;第三篇文章手把手教大家如何搭建 Spark 分布计算环境,简单分析了常见的进程模型。以上三篇文章,点击下方链接直达:
今天针对**持久化算子、groupByKey 和 reduceByKey、 coalesce 和 repartition **这几种类型的算子作个讲解,并对它们作一个区分。本文概览如下:

1 持久化算子是干嘛的?
在实际工程当中,每一个 Job 的 computing chain (数据依赖)会很长,计算某些 RDD 的时候可能会非常耗时。如果在 task 运行中途出现失败的情况,那么会导致整个 computing chain 重新计算,这样代价非常高。
因此,非常有必要将那些计算耗时的 RDD 进行持久化,这样,当下游 RDD 计算出错时,就不用从头开始计算,只需要从持久化的 RDD 开始就行。
此外,对于需要重复使用的 RDD 也可进行持久化,当下次使用时便可以复用。目前,Spark 的持久化算子有 cache()、persist(),持久化的单位是 partition。
1.1 cache & persist 算子
cache 和 persist 这两个算子的执行原理一样,cache 的底层实现仍然是 persist,persist 提供了不同的存储级别。这里特别要注意的是:
//三种使用方式等价
cache() = persist() = persist(MEMORY_ONLY)
从下面源码来看,cache() 函数的源码,其实调的就是 persist(), 而 persist() 调的则是 persist(StorageLevel.MEMORY_ONLY)。
/**
* 1.当用户调用 cache 时,其实调的就是 persist(),
*/
def cache(): this.type = persist()
/**
* 2.然而,persist() 函数其实调用的是 persist(StorageLevel.MEMORY_ONLY)
* 使用的缓存级别为 MEMORY_ONLY ,也就是内存缓存
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
1.2 Spark 缓存级别
关于缓存级别, Spark 官方基于以下 3 个方面进行衡量:
- 存储位置。在 Spark 的存储级别中,既可以存储在内存,也可以存储在磁盘。对于
MEMORY_ONLY默认级别,当内存不够时,剩下的 partition 便不会进行缓存,使用的时候需要重新计算。 - 是否序列化缓存数据。对缓存数据进行序列化,可以减少存储空间的开销,但是在反序列化的时会带来一定的延时。
- 缓存数据是否进行备份。把缓存数据复制多份存储到其它节点上,解决了单节点缓存数据失效问题,但会消耗更多的存储空间。
根据上述 3 个方面组合,Spark 一共提供了以下 12 种存储级别,你可以根据我的注释去理解。
val NONE = new StorageLevel(false, false, false, false) // 不存储
val DISK_ONLY = new StorageLevel(true, false, false, false) //只存储在磁盘,不序列化,副本为 1
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) //只存储在磁盘,不序列化,副本为 2
val MEMORY_ONLY = new StorageLevel(false, true, false, true) //只存储在内存,不序列化,副本为 1
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) //只存储在内存,不序列化,副本为 2
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) //只存储在内存,序列化,副本为 1
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) //只存储在内存,序列化,副本为 2
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) //内存 + 磁盘,不序列化,副本为 1
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) //内存 + 磁盘,不序列化,副本为 2
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) //内存 + 磁盘,序列化,副本为 1
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) //内存 + 磁盘,序列化,副本为 2
val OFF_HEAP = new StorageLevel(false, false, true, false) //存储在堆外内存
在实际生产环境中,缓存级别该如何选择?
不同的缓存级别所对应的需求也不同,我们在选择时主要考虑以下两个问题:
-
是否有足够内存、磁盘空间进行缓存?没有足够的内存、磁盘空间但又需要进行数据缓存,可以选择 MEMORY_AND_DISK 或者MEMORY_AND_DISK_SER 级别缓存数据。
-
如果数据缓存到磁盘上,那么读取缓存数据的时间是否大于重新计算出该数据的时间。如果是,可以不缓存或者分配更大的内存来进行缓存。
1.3 cache & persist 实现原理
什么样的 RDD 需要被 cache ?
小林先给出答案,再论证:缓存的目的就是加速 Spark 的快速计算,所以对于那些会被经常使用到的,但是又不能太大的 RDD 可以进行缓存。
小林拿 第一篇 文章中的 WordCount 例子介绍下 Spark cache() 的概念。在原有代码的基础上,我作了一点修改,代码中增加了一个行动算子,所以 Spark 在运行时,也会增加一个 Job。代码如下:
object WordCount {
def main(args:Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(conf)
//读取文件内容
val lineRDD:RDD[String] = sc.textFile("./data/words.txt",2)
//以行为单位进行分词
val wordsRDD: RDD[String] = lineRDD.flatMap(line=>{line.split(" ")})
//把 RDD 元素转换为(key,value) 的形式
val kvRDD: RDD[(String, Int)] = wordsRDD.map(word=>{new Tuple2(word,1)})
//调用缓存算子
kvRDD.cache()
//把相同的单词作为一组,并计算
val reduceRDD: RDD[(String, Int)] = kvRDD.reduceByKey((v1, v2)=>{v1+v2})
reduceRDD.foreace(println)
//把相同的单词作为一组,并计算
val groupRDD: RDD[(String, Int)] = kvRDD.groupByKey(3).mapValues(item => item.toList)
groupRDD.foreach(println)
}
}
我们先假设,如果代码中没有调用 cache(),它的逻辑执行图是怎样的?因为代码中会产生 2 个 Job ,其执行流程图如下:

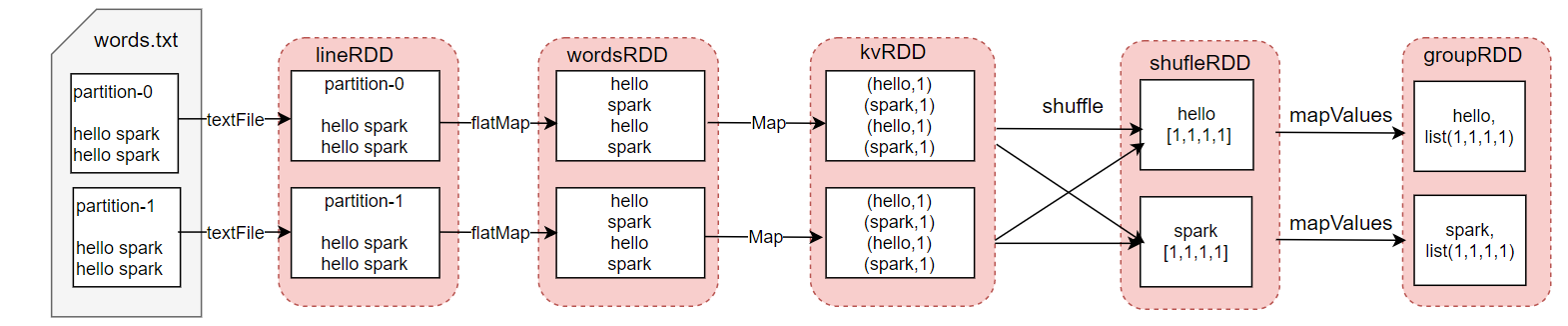
从上述执行流程图可以看出,这 2 个 job 之间有重叠计算的部分。那么对于第二个 job 来说 ,从 kvRDD 到最开始的输入数据,这期间是否可以不用重复计算呢?
我们再来看下,代码中实际调用了 cache() 函数后,它的执行流程图如下:

把 kvRDD 缓存后,便可以使得第二个 job 不用重复计算 kvRDD 之前的数据了,但是需要消耗存储空间。所以 RDD 的缓存机制是利用了空间换时间的思想。如果存储的数据量非常大,那便需要比较从头开始计算到 kvRDD 的时间和读取缓存的 kvRDD 的时间,孰大孰小,且缓存所消耗的存储代价是否可以接受。因此,什么时候 RDD 应该被缓存,其实是计算和存储权衡的结果。
用户调用 cache 后,系统是怎么对 RDD 进行 cache 的?
关于它的实现原理,我们只针对 persist(StorageLevel.MEMORY_ONLY) 这一种情况进行分析。假设用户在业务程序中调用了 cache() ,它底层实际会调用下面这个函数:
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// 处理存储级别变化的情况
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
//如果当前 RDD 是第一次被持久化,需要在 SparkContext 中注册资源清理函数,这只执行一次
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
//把要缓存的 RDD 存到一个 Map(id,RDD) 的数据结构中
sc.persistRDD(this)
}
//为 RDD 指定缓存级别
storageLevel = newLevel
this
}
从上述源码来看,实际上用户在使用 cache() 算子进行缓存时,此时只是把分区数据,打上了一个存储级别标记(每一个 RDD 都有一个 storageLevel 变量,初始默认为 NONE),而并没有真正立马执行 RDD 缓存,这个算子是一个懒加载执行,只有当 RDD 真正被计算时,RDD 才会被缓存。一旦存储级别被指定了之后,在相同的 SparkContext 下就不能修改。
那会在什么时候真正执行缓存这个动作呢?
当用户程序调用 Action 算子触发计算,task 便会在计算 Partition 时,判断该 Partition 是否是需要 cache,如果需要被缓存,则先把 Partition 结果计算出来,计算完后立马缓存到内存。
在 RDD 的抽象类中,提供了一个迭代器函数 iterator(),通过这个迭代器函数便可以访问到 RDD 中的分区数据,也就是从这里开始进行计算数据。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
//遍历数据时,先判断 RDD 的存储级别是否为 NONE,如果用户在某一个 RDD 执行了 cache 或者
//persist,此时 RDD 中 storagelevel 已经被修改,所以会从缓存中获取,获取不到则重新计算
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
//如果还是默认的存储级别 NONE,迭代要么从 checkpoint 的目录中读取,要么重新计算
computeOrReadCheckpoint(split, context)
}
}
在 iterator() 源码中,先判断当前分区数据的存储级别,如果用户之前调用了 cache() 算子,此时分区数据的存储级别应该不为 NONE 这个级别。因此,便会调用 getOrCompute() 函数。
getOrCompute 函数
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
//先获取 RDD 的 block id
val blockId = RDDBlockId(id, partition.index)
var readCachedBlock = true
//先根据 blockId 从 blockManager 查看是否已经被缓存了
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
}) match {
.....
}
}
当 RDD.iterator() 被调用时, 也就是要计算该 RDD 中某个 partition 的时候。 首先,会生成一个 blockId, 表明是要存哪个 RDD 的哪个 partition。
注意:这个 blockId 类型是 RDDBlockId,它是由 rddid + partitionId 组成 。
之后,会把计算出来的 partition 数据放到 BlockManager 中的 MemoryStore 中,MemoryStorye 维护了一个 LinkedHashMap[blockId,memoryEntry] ,key 是 blockId,value 是当前缓存的数据。因此,缓存的分区数据最后会存放在LinkedHashMap 数据结构中,LinkedHashMap 是基于双向链表实现的。
2 groupByKey 和 reduceByKey 有什么区别?
从这两个算子的字面意思来看,groupByKey 是先按照 key 进行分组,然后把相同的 key 收集到一起;reduceByKey( f ),把相同的 key 进行聚合,聚合的逻辑由传入 f 函数所指定。
这两个算子,只针对 kv 格式的 RDD 才能使用。在前几篇文章中说了,每调一个算子,都是一次 RDD 的转换,也是一次数据形态的转换。既然有 RDD 的转换,那么就会有数据依赖形成。下面分别来看看它们所形成的数据依赖是什么依赖。
2.1 reduceByKey
我们先来温习下,下面这段代码,这是我从 wordcount 中截取的代码,带你们重新熟悉下 reduceByKey 的用法。
//生成 kv 格式的 RDD
val kvRDD: RDD[(String, Int)] = wordsRDD.map(word=>{new Tuple2(word,1)})
//把相同的单词作为一组,并计算
val reduceRDD: RDD[(String, Int)] = kvRDD.reduceByKey((v1, v2)=>{v1+v2},2)
这里最重要的就是 (v1, v2)=>{v1+v2} 匿名函数,在 reduceByKey 中,我们管这个函数叫聚合函数。因为要把相同的 key 的数据进行聚合,所以会产生 Shuffle,但是会在 Map 端默认开启 combine() 。会先在 Map 端调用 mapPartitions 进行 map 端聚合,然后通过shuffle 把数据拉到指定节点上得到 shuffleRDD,再进行 reduce 端聚合,其数据依赖图如下:

值得提醒的是:在 map 端的聚合和 reduce 端的聚合统一由聚合函数 f 指定。
2.2 groupByKey
我们通过下面这个代码片段,熟悉下 groupByKey 的用法。
//把相同的数字作为一组,并收集
val reduceRDD: RDD[(Int, String)] = kvRDD.groupByKey(2)
从上述用法来看,相较于 rduceByKey ,groupByKey 的实现会简单一点,只需要把相同的 key 进行分组再收集。把相同 key 的数据进行 shuffle 到一个节点上,然后通过mapPartitions() 把相同 key 的数据放在一个集合里并返回。groupByKey 没有在 Map 端进行 combine() ,因此,在数据量较大的情况下,其性能会比较差,实际生产环境使用较少。这里我通过一个简单案例,给大家画了一个 groupByKey 数据依赖图:

groupByKey 和 reduceByKey 区别:
-
reduceByKey 是一个分组聚合类算子,在 Map 端默认开启聚合,且聚合逻辑必须与 Reduce 端一致,即由传进来聚合函数 f 指定;
-
groupByKey 是一个分组收集类算子,在 Map 端不会产生
combine(),只是把相同的 key 的数据进行收集到一起,不会接收类似 f 的函数形参。
3 coalesce 和 repartition 有什么不同?
coalesce 和 repartition 这两个算子都是用于数据重分布、调整任务的并行度,以便提升 CPU 的使用效率。
在实际开发过程中,我们可以用某个 RDD 调用 repartition(n) ,来增大或减少 RDD 的并行度,其中 n 必须是大于 0 的正整数。
val lineRDD:RDD[String] = sc.textFile("./data/words.txt",2)
lineRDD.partitions.length // 2
lineRDD.repartion(4)
lineRDD.partitions.length // 4
lineRDD.repartition(3)
lineRDD.partition.length //3
从上述代码来看,repartition 算子非常灵活,可以随意的调整 RDD 的并行度,用法简单。但是它有个致命的缺陷,无论是增加分区数还是减少分区数,repartition 算子都是通过 shuffle 实现的,shuffle 就是把数据打乱,将数据重新分发,可以结合下面这张图理解。shuffle 势必就会导致磁盘 IO 和 网络 IO 开销较大,性能也就会下降。

那有没有在减少分区时,不产生 shuffle 的算子,相信你也猜到了,就是 coalesce。coalesce 在用法上和 repartition 一致,coalesce 会多一个参数 coalesce(n,shuffle) ,这个 shuffle 是一个 Boolean 类型,表示是否开启 shuffle 。
如果你深入到源码中去看,其实 repartion(n) = coalesce(n,true) , 也可以看到repartiton(n) 的底层调的就是 coalesce(n,true) 函数。
coalesce 既可以开启 shuffle ,也可以不开启 shuffle 。但是,如果你是增加分区,也就是调大 RDD 的并行度,必须通过开启 shuffle 来实现。那么在减少分区时,可以选择使用 coalesce(n,false) 实现,因为他是通过把同一个 Executor 内的不同数据分区进行合并,如此一来,不需要跨 Executor 、跨节点分发数据,也就不会引入 shuffle 。可以结合下面这张图理解:
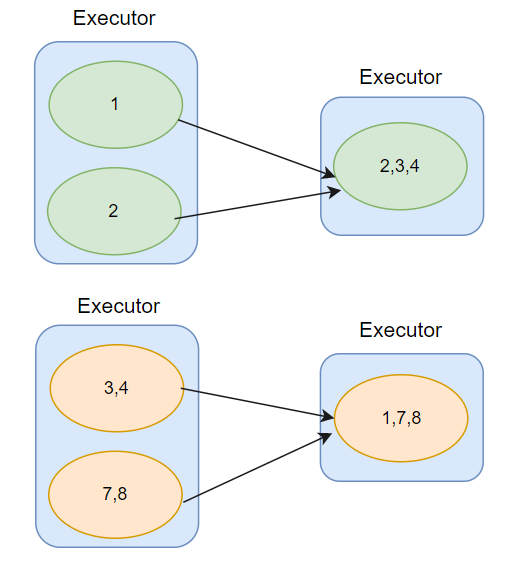
coalesce 和 repartition 区别:
- coalesce shuffle 机制可以配置,但只针对降低 RDD 的并行度这种情况,如果增加并行度必须通过 shuffle 实现
- repartition 的底层是调用
coalesce(n,true)实现的,无论是增加或减少并行度,都会产生shuffle。
4 总结
本文主要从持久化算子、groupByKey&reduceByKey、coalesce&repartition 三个方面去切入,展开说了三类常见算子的使用及实现原理。持久化算子的意义在于加速 Spark 的计算,但是在决定是否使用缓存算子时,要同时权衡计算代价和存储代价。groupByKey 是分组收集类算子,reduceByKey 是分组聚合类算子。coalesce 和 repartition 区别在于 shuffle 是否可以配置。
好了,今天的文章到这里,我们下期再见。小林写一篇文章真的很不容易,还请各位点赞、在看吧,小林谢谢啦。如果你能分享到朋友圈,我感激不尽!你们的鼓励,是我最大的动力。