1 基本Hadoop组件
- Hadoop Common
- HDFS
- YARN
- MR
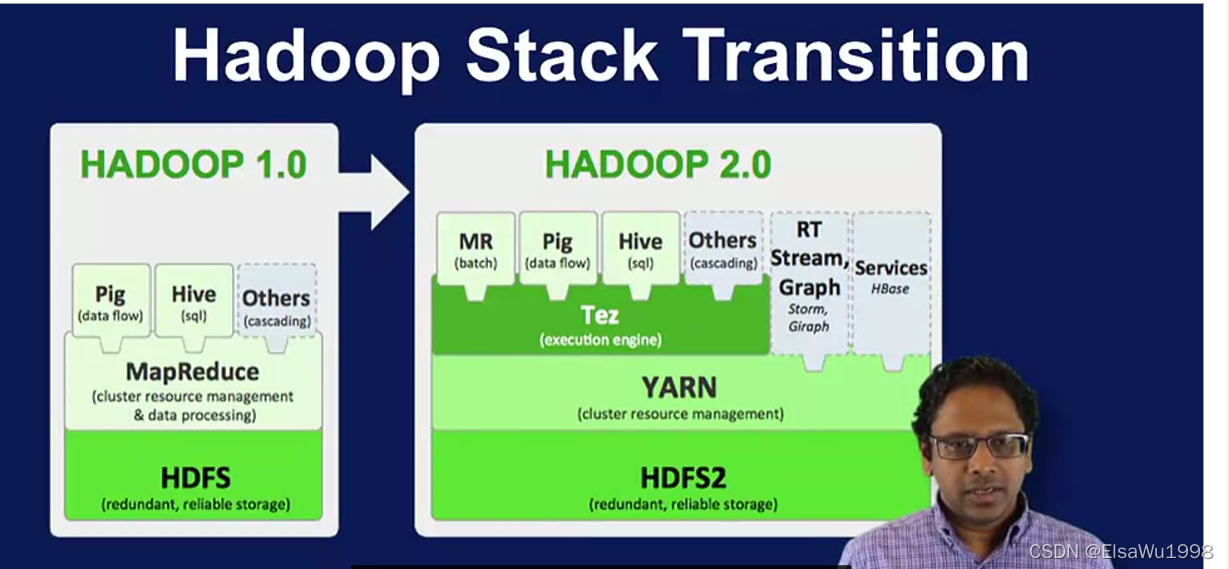
2 应用和框架(在基本组件之上)
- HBase
支持大型表的可扩展数据仓库 - Hive
数据仓库基础设施,提供数据摘要和即席查询 - Pig
高级数据流语言和并行计算执行框架 - Spark
快速通用的计算引擎,可以使用HDFS文件系统。
![![[Pasted image 20220213222106.png]]](https://img-blog.csdnimg.cn/426acaf374b24dff974c9cb11cba27ae.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
3 HDFS设计
最初的设计
- 可扩展的分布式文件系统
- 使用节点(nodes)将数据分布在本地磁盘上
- 多个低成本商品磁盘,高performance
goal:
- resilience(快速恢复的能力)(因为有多个磁盘工作,要防止其中的磁盘failure)
- 可扩展
- 本地应用
- 轻量级
设计
![![[Pasted image 20220213224304.png]]](https://img-blog.csdnimg.cn/6e8fc7523f894bc4a3ee100f8997e882.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
- 多个datanode,data存储在datanode中,默认会复制三份。作用:管理存储、为用户提供读写request,数据块的增删改
- 单个namenode
![![[Pasted image 20220213224547.png]]](https://img-blog.csdnimg.cn/eeb9c1fdfc894201a7fe2d0b36e18550.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
Hadoop2的HDFS
HDFS Federation
存在多个namenode,可以增加命名空间的可扩展性以及performance,同时可以隔离应用,这样在使用应用的时候就不会影响整个文件系统。
- 多个namemode server
- 多个命名空间(你真的知道什么是 “命名空间” 吗? - 知乎 (zhihu.com))
- 数据存在数据块池中(block pool)
- 高可用性(冗余namenode)
- 异构存储和归档存储(heterogeneous storage and archival storage)
![![[Pasted image 20220213230205.png]]](https://img-blog.csdnimg.cn/67ec9490aa1b42509d1b7072d32333a9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
4 MR框架和YARN
MR框架
mapreduce原理_mapreduce执行原理详解,各个阶段做了什么?_weixin_39583029的博客-CSDN博客
深入浅出讲解 MapReduce_哔哩哔哩_bilibili
MapReduce shuffle过程详解
![![[Pasted image 20220213230853.png]]](https://img-blog.csdnimg.cn/868461bdb14c46bcb4b32d5a1f08c379.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
- 软件框架――为了编写并行数据处理应用
![![[Pasted image 20220213232746.png]]](https://img-blog.csdnimg.cn/8d93ec02214940b2ae001304a8eb3f27.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
优点:
- MR计算和HDFS存储节点是same,直接在datanode上进行计算,不用移动data
最初的MR框架
- 单个 jobtracker
- 每个job一个tasktracker
![![[Pasted image 20220213233152.png]]](https://img-blog.csdnimg.cn/af48954992c54d03a4b54ac0a105da21.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
下一代:YARN
- 将资源管理和job计划&监控分离
- Global ResourceManager
- 每个节点都有NodeManager
- 每个应用都有ApplicationMaster
![![[Pasted image 20220213233530.png]]](https://img-blog.csdnimg.cn/287d7ce03f0b413f961396296e1662e7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARWxzYVd1MTk5OA==,size_20,color_FFFFFF,t_70,g_se,x_16)
YARN的其他特征
- 高可用的RM:备用RM
- TimeLine Server
- Cgroups:管理容器使用的资源
- Secure Container